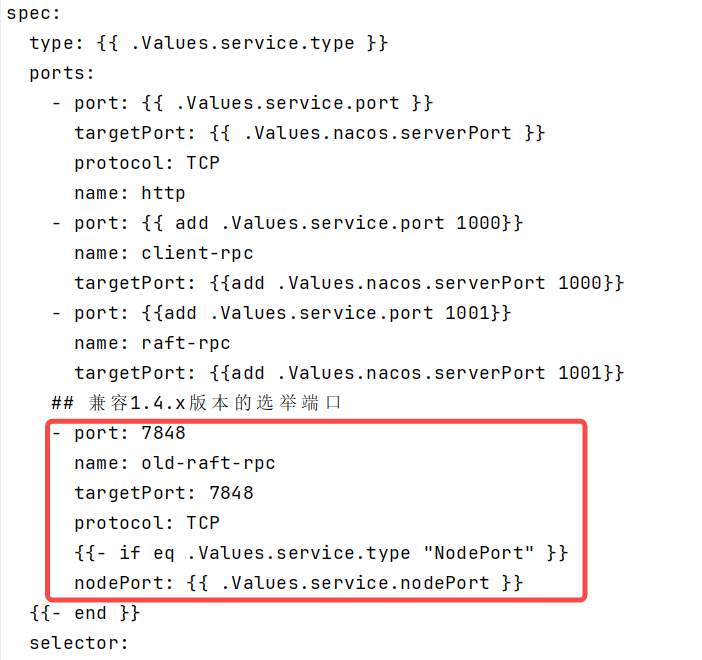
背景:
在刷Leetcode过程中,需要初始化一个与另一个矩阵(如 matrix)尺寸相同的二维列表(如 f),并填充初始值(如 0)。一开始用的是这种方法试图创建一个所有元素均为 0 的二维列表:
f = [[0] * len(matrix[0])] * len(matrix)
这段代码旨在生成一个与 matrix 维度相同的矩阵 f。虽然从表面上看这段代码似乎实现了目标,但实际运行中会出现意想不到的问题。
遇到的问题:
原理是代码中 f 矩阵的所有行都引用了同一个列表对象。结果是,当修改 f 中某一行的某个元素时,所有行的相同位置的元素都会同步发生变化。问题的核心原因在于 Python 中的列表引用机制。
- 示例:
matrix = [[100, -42, -46, -41], [31, 97, 10, -10], [-58, -51, 82, 89], [51, 81, 69, -51]]
f = [[0] * len(matrix[0])] * len(matrix)
f[0][0] = 1
print(f)
- 输出:
[[1, 0, 0, 0], [1, 0, 0, 0], [1, 0, 0, 0], [1, 0, 0, 0]]
如上所示,修改 f[0][0] 的值会导致所有行的第一个元素同步更新。这是因为所有行实际上引用的是同一个列表对象。
问题的原因:
在 [[0] * len(matrix[0])] * len(matrix) 这段代码中,[0] * len(matrix[0]) 生成了一行包含 len(matrix[0]) 个元素的列表。随后,* len(matrix) 只是将同一个列表引用多次复制,导致每一行都是同一个列表的引用。如果查看他的地址的话会发现每个每一行所存储的数据地址是同一个。因此,任何对某一行元素的修改都会影响其他所有行的相同位置。
- 查看物理地址
matrix = [[100, -42, -46, -41], [31, 97, 10, -10], [-58, -51, 82, 89], [51, 81, 69, -51]]
f = [[0] * len(matrix[0])] * len(matrix)
print(id(f[0]))
print(id(f[1]))
print(id(f[2]))
print(id(f[3]))
实验的结果也表明存到了相同的物理地址

应对方案:
要解决这个问题,我们需要确保每一行都是独立的列表,而不是对同一个列表的引用。我们可以使用列表推导式来初始化二维列表:
f = [[0] * len(matrix[0]) for _ in range(len(matrix))]
这种方法通过 for 循环,每次都生成一个新的列表。这样,每一行都是一个独立的对象,修改某一行不会影响其他行。
示例:
- 实验代码
matrix = [[100, -42, -46, -41], [31, 97, 10, -10], [-58, -51, 82, 89], [51, 81, 69, -51]]
f = [[0] * len(matrix[0]) for _ in range(len(matrix))]
#使用列表推导式来初始化二位列表
f[0][0] = 1
print(f)
- 输出:
[[1, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
现在,修改 f[0][0] 只会影响第一行,其他行不会被改变。
总结:
在初始化二维列表时,直接使用 [[0] * n] * m 的方式会导致所有行引用同一个列表对象。这种行为在修改二维列表中的元素时会造成每一行的列表会存储到相同的物理地址。
解决该问题的最佳方法是使用列表推导式生成独立的行对象,确保每一行都是互相独立的,从而避免修改一个元素时影响其他元素。





![[晕事]今天做了件晕事44 wireshark 首选项IPv4:Reassemble Fragented IPv4 datagrams](https://i-blog.csdnimg.cn/direct/dacc8abc55934d598b791cf1d8e2882a.png)