文章目录
- 零、说在前面
- 一、CAS原理
- 1.1 CAS简介
- 1、线程安全的实现方案
- 2、什么是CAS
- 1.2 CAS使用案例
- 1.3 CAS存在的问题
- 1、ABA问题
- 2、只能保证一个共享变量之间的原子性操作
- 3、无效CAS会带来开销问题
- 4、总线风暴问题
- 1.4 CAS在JDK中的应用
- 二、Unsafe类详解
- 2.1 Unsafe类介绍
- 2.2 Unsafe类的使用
- 1、获取 Unsafe 实例
- 2、调用Unsafe的CAS方法
- 3、Unsafe计算偏移量相关
- 4、使用Unsafe进行无锁编程
- 5、使用无锁编程实现轻量级安全自增
- 2.3 Unsafe其他功能
- 三、JUC原子类详解
- 3.1 原子类分类
- 1、基本原子类
- 2、数组原子类
- 3、引用原子类
- 4、字段更新原子类
- 3.2 基本原子类-AtomicInteger
- 1、AtomicInteger 的方法介绍
- 2、AtomicInteger使用案例
- 3、AtomicInteger线程安全原理
- 3.3 数组原子类-AtomicIntegerArray
- 1、AtomicIntegerArray 的方法介绍
- 2、AtomicIntegerArray 使用案例
- 3.4 引用类型原子类-AtomicReference,AtomicMarkableReferencr,AtomicStampedRefernce
- 1、AtomicReference:引用类型原子类
- 2、AtomicMarkableReferencr解决ABA问题
- 3、AtomicMarkableReferencr方法介绍
- 4、AtomicMarkableReferencr使用案例
- 5、AtomicStampedRefernce解决ABA问题
- 6、AtomicStampedRefernce方法介绍
- 7、AtomicStampedRefernce使用案例
- 3.5 属性更新原子类-AtomicIntegerFieldUpdater
- 四、LongAdder:优化CAS操作性能
- 4.1 LongAdder介绍
- 4.2 LongAdder使用案例
- 4.3 LongAdder 的原理
- 1、LongAdder基类Striped64
- 2、LongAdder重要属性
- 3、LongAdder 的 add()方法
零、说在前面
有必要为友友们推荐一款极简的原生态AI:阿水AI6,需不需要都点点看看:👇👇👇
https://ai.ashuiai.com/auth/register?inviteCode=XT16BKSO3S
先看看美景养养眼,再继续以下乏味的学习,内容有点多,建议收藏分多次食用。

一、CAS原理
1.1 CAS简介
1、线程安全的实现方案

- 互斥同步:synchronized 和 lock等
- 非阻塞同步:CAS,原子类de等
- 无同步方案:栈封闭,ThreadLocal等
于JVM的synchronized重量级锁涉及操作系统(如Linux)内核态下的互斥锁的使用,其线程阻塞和唤醒都涉及进程在用户态和到内核态的频繁切换,导致重量级锁开销大、性能低。而JVM的synchronized轻量级锁使用CAS(Compare And Swap,比较并交换)进行自旋抢锁,CAS是CPU指令级的原子操作并处于用户态下,所以JVM轻量级锁开销较小。
CAS 方式为乐观锁,synchronized 为悲观锁。因此使用 CAS 解决并发问题通常情况下性能更优。
2、什么是CAS
CAS的全称为Compare-And-Swap,直译就是对比交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值,其实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM只是封装了汇编调用,那些AtomicInteger类便是使用了这些封装后的接口。 简单解释:CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下在旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
CAS操作是原子性的,所以多线程并发使用CAS更新数据时,可以不使用锁。JDK中大量使用了CAS来更新数据而防止加锁(synchronized 重量级锁)来保持原子更新。
JDK 5所增加的JUC(java.util.concurrent)并发包对操作系统的底层CAS原子操作进行了封装,为上层Java程序提供了CAS操作的API。
1.2 CAS使用案例
如果不使用CAS,在高并发下,多线程同时修改一个变量的值我们需要synchronized加锁
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}
java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}
1.3 CAS存在的问题
使用CAS乐观锁编程存在的问题:
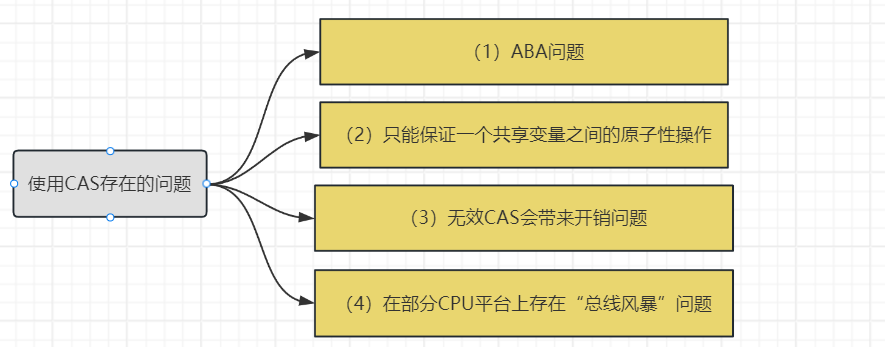
1、ABA问题
问题描述:
使用CAS操作内存数据时,如果第一个线程对共享数据做了A=>B=>A这种序列的改变,第二个线程来对共享数据进行修改时,发现共享数据的值是A,这个时候线程2能修改成功,但是其实共享数据中的A已经不是原来的A了,这就是ABA问题。
解决方案:
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候将版本号加1,那么操作序列A==>B==>A的就会变成A1==>B2==>A3,如果将A1当作A3的预期数据,就会操作失败。
JDK提供了两个类AtomicStampedReference和AtomicMarkableReference来解决ABA问题。比较常用的是AtomicStampedReference类,该类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,以及当前印戳是否等于预期印戳,如果全部相等,就以原子方式将引用和印戳的值一同设置为新的值。
2、只能保证一个共享变量之间的原子性操作
问题描述:
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
解决方案:
把多个共享变量合并成一个共享变量来操作。JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个AtomicReference实例后再进行CAS操作。比如有两个共享变量i=1、j=2,可以将二者合并成一个对象,然后用CAS来操作该合并对象的AtomicReference引用。
3、无效CAS会带来开销问题
问题描述:
自旋CAS如果长时间不成功(不成功就一直循环执行,直到成功为止),就会给CPU带来非常大的执行开销。
解决方案:
自适应自旋
4、总线风暴问题
问题描述:
CAS操作和volatile一样也需要CPU进行通过MESI协议各个内核的“Cache一致性”,会通过CPU的BUS(总线)发送大量MESI协议相关的消息,产生“Cache一致性流量”。因为总线被设计为固定的“通信能力”,如果Cache一致性流量过大,总线将成为瓶颈,这就是所谓的“总线风暴”。
1.4 CAS在JDK中的应用
- 原子类中
- AQS及其显式锁中
- CurrentHashMap等并发容器中
二、Unsafe类详解
2.1 Unsafe类介绍
Unsafe是位于sun.misc包下的一个类,主要提供一些用于执行低级别、不安全的底层操作,如直接访问系统内存资源、自主管理内存资源等,Unsafe大量的方法都是原生(native)方法,基于C++语言实现,这些方法在提升Java运行效率、增强Java语言底层资源操作能力方面起到了很大的作用。
但由于Unsafe类使Java语言拥有了类似C语言指针一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过度、不正确使用Unsafe类会使得程序出错的概率变大,使得Java这种安全的语言变得不再“安全”,因此对Unsafe的使用一定要慎重。
Unsafe类总体功能如下:
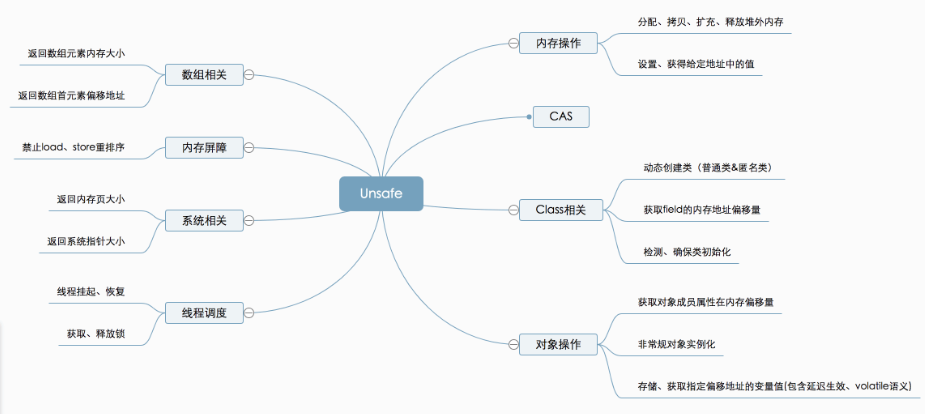
Unsafe提供的API大致可分为内存操作、CAS、Class相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类。
在 Unsafe 类里,包含着 CAS 的操作函数。它采用无锁的乐观策略,由于其非阻塞性,它对死锁问题天生免疫,并且,线程间的相互影响也远远比基于锁的方式要小得多。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销。因此,它要比基于锁的方式拥有更优越的性能。
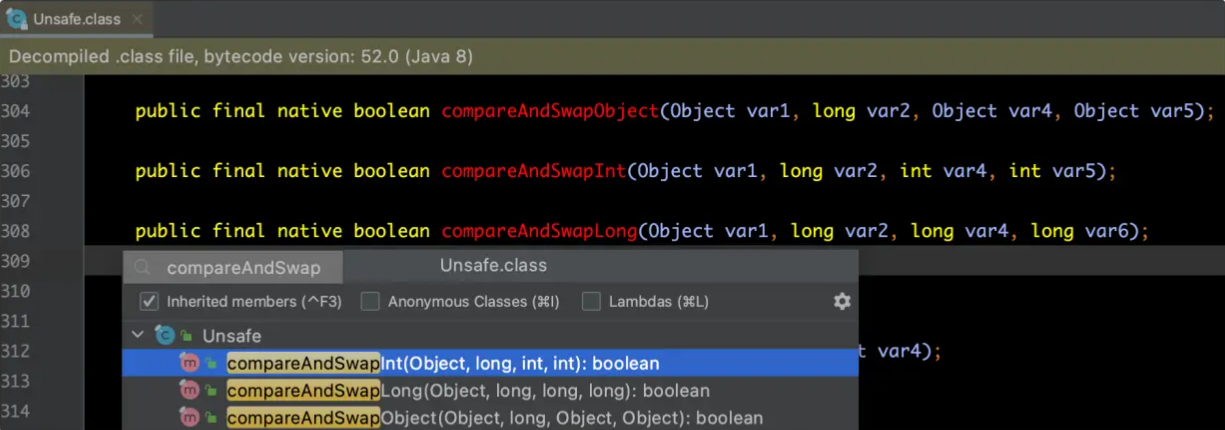
2.2 Unsafe类的使用
操作系统层面的CAS是一条CPU的原子指令(cmpxchg指令),正是由于该指令具备了原子性,因此使用CAS操作数据时不会造成数据不一致的问题,Unsafe提供的CAS方法直接通过native方式(封装C++代码)调用了底层的CPU指令cmpxchg。完成Java应用层的CAS操作主要涉及的Unsafe方法调用,具体如下:
1、获取 Unsafe 实例
Unsafe类是一个final修饰的不允许继承的最终类,而且其构造函数是private类型的方法。
public final class Unsafe {
//构造方法私有化,不能通过new关键字创建Unsafe类型实例
private Unsafe() {
}
}
Unsafe提供了一个getUnsafe方法获取Unsafe实例,但是,如果这个类的ClassLoader不为null,就直接抛出异常,拒绝工作。因为我们知道,只有系统类加载器才会返回null。因此,这也使得我们自己的应用程序无法直接使用Unsafe类。它是一个JDK内部使用的专属类。
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
无法在外部对Unsafe进行实例化,可以通过反射的方式获取Unsafe实例的辅助方法,代码如下:
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
2、调用Unsafe的CAS方法
Unsafe提供的CAS方法主要如下:
/**
* 定义在Unsafe类中的三个“比较并交换”原子方法
* @param o 需要操作的字段所处的对象
* @param offset 需要操作的字段的偏移量(相对的,相对于对象头)
* @param expected 期望值(旧的值)
* @param update 更新值(新的值)
* @return true 更新成功 | false 更新失败
*/
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
Unsafe提供的CAS方法包含4个操作数——字段所处的对象、字段内存位置、预期原值及新值。在执行Unsafe的CAS方法时,这些方法首先将内存位置的值与预期值(旧的值)比较,如果相匹配,那么处理器会自动将该内存位置的值更新为新值,并返回true;如果不匹配,处理器不做任何操作,并返回false。
Unsafe的CAS操作会将第一个参数(对象的指针、地址)与第二个参数(字段偏移量)组合在一起,计算出最终的内存操作地址。
3、Unsafe计算偏移量相关
Unsafe提供的获取字段(属性)偏移量的相关操作主要如下:
/**
* 定义在Unsafe类中的几个获取字段偏移量的方法
* @param o 需要操作字段的反射
* @return 字段的偏移量
*/
// staticFieldOffset方法用于获取静态属性Field在Class对象中的偏移量
public native long staticFieldOffset(Field field);
// objectFieldOffset()方法用于获取非静态Field(非静态属性)在Object实例中的偏移量,
public native long objectFieldOffset(Field field);
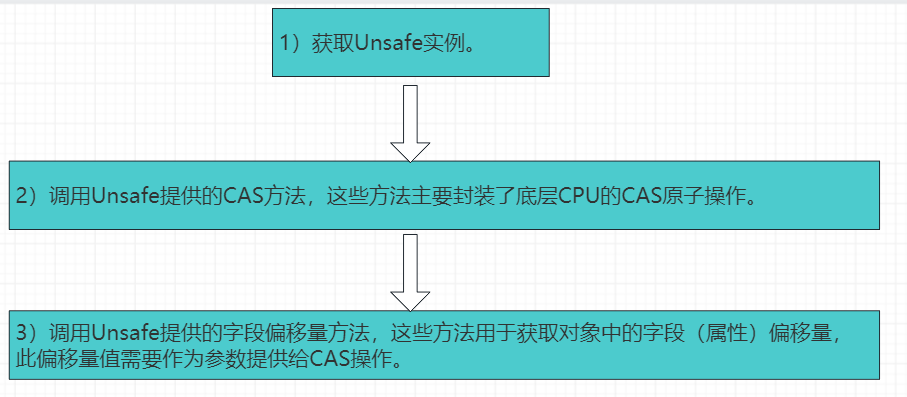
4、使用Unsafe进行无锁编程
使用CAS进行无锁编程的步骤大致如下:
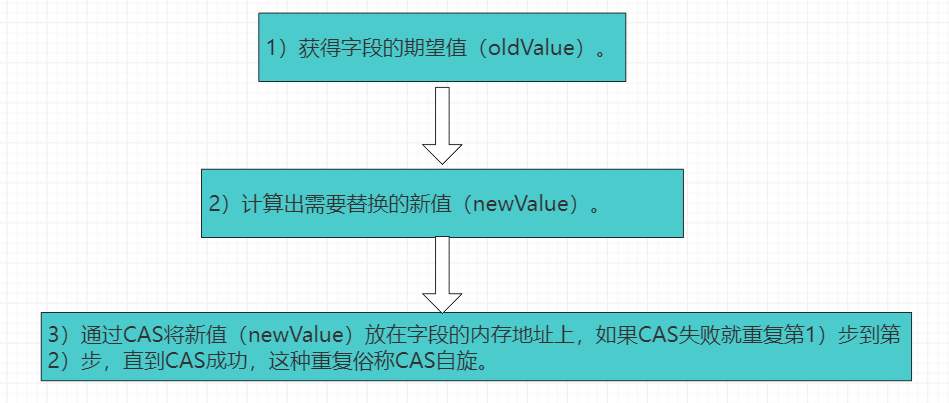
5、使用无锁编程实现轻量级安全自增
使用CAS无锁编程算法实现一个轻量级的安全自增实现版本:总计10个线程并行运行,每条线程通过CAS自旋对一个共享数据进行自增运算,并且每个线程需要成功自增运算1000次。
基于CAS无锁编程的安全自增实现版本的具体代码如下:
public class TestCompareAndSwap {
// 模拟CAS 算法
static class OptimisticLockingPlus {
private static final int THREAD_COUNT = 10;
//值
volatile private int value;
//不安全类
private static final Unsafe unsafe = JvmUtil.getUnsafe();
//value 的内存偏移(相对于对象头)
private static final long valueOffset;
private static final AtomicLong failure = new AtomicLong(0);
static {
try {
//取得内存偏移
valueOffset = unsafe.objectFieldOffset(
OptimisticLockingPlus.class.getDeclaredField("value"));
Print.tco("valueOffset:=" + valueOffset);
} catch (Exception ex) {
throw new Error(ex);
}
}
public final boolean unSafeCompareAndSet(int oldValue, int newValue) {
return unsafe.compareAndSwapInt(this, valueOffset, oldValue, newValue);
}
// 无锁编程:安全的自增方法
public void selfPlus() {
// 获取旧值
int oldValue = value;
int i = 0;
//如果操作失败则自旋,一直到操作成功
do {
oldValue = value;
//统计无效的自旋次数
if (i++ > 1) {
failure.incrementAndGet();
}
} while (!unSafeCompareAndSet(oldValue, oldValue + 1));
}
public static void main(String[] args) throws InterruptedException {
final OptimisticLockingPlus cas = new OptimisticLockingPlus();
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++) {
// 创建10个线程,模拟多线程环境
ThreadUtil.getMixedTargetThreadPool().submit(() ->
{
for (int j = 0; j < 1000; j++) {
cas.selfPlus();
}
latch.countDown();
});
}
latch.await();
Print.tco("累加之和:" + cas.value);
Print.tco("失败次数:" + cas.failure.get());
}
}
}
2.3 Unsafe其他功能
详情请看:Java魔法类:Unsafe
三、JUC原子类详解
3.1 原子类分类
JUC并发包中原子类都存放在java.util.concurrent. atomic类路径下:
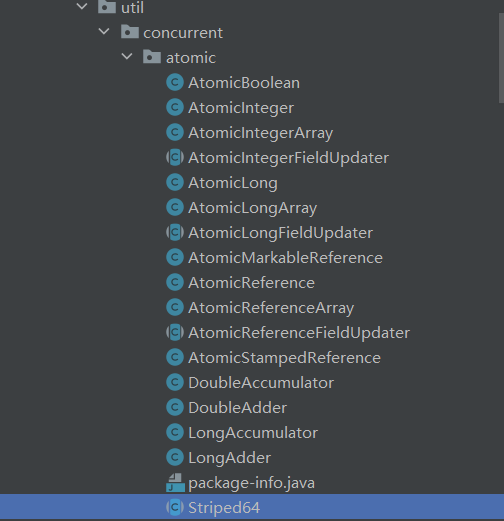
根据操作的目标数据类型,可以将JUC包中的原子类分为4类:基本原子类、数组原子类、原子引用类和字段更新原子类。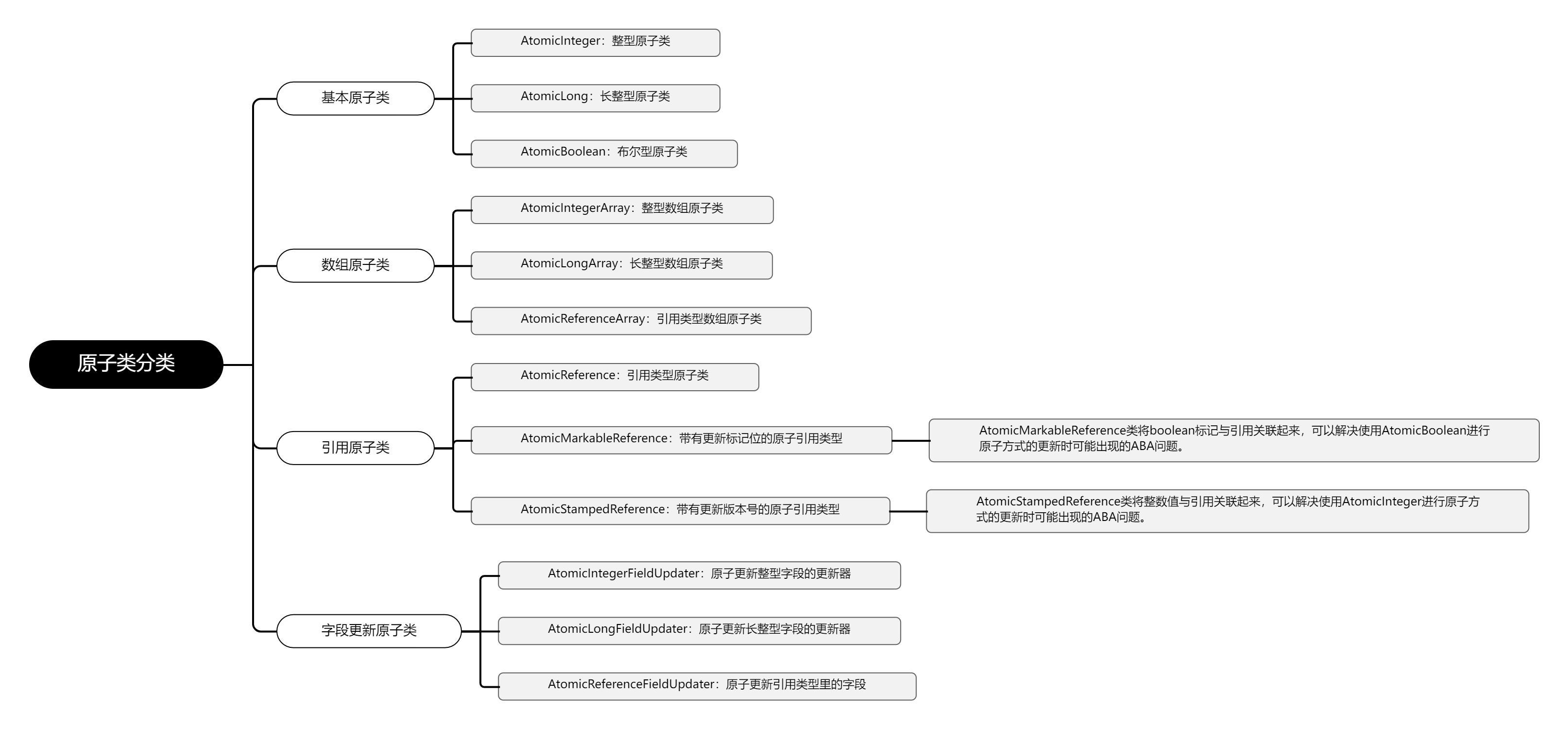
1、基本原子类
基本原子类的功能是通过原子方式更新Java基础类型变量的值。基本原子类主要包括以下三个:
- AtomicInteger:整型原子类。
- AtomicLong:长整型原子类。
- AtomicBoolean:布尔型原子类。
2、数组原子类
数组原子类的功能是通过原子方式更新数组中的某个元素的值。数组原子类主要包括了以下三个:
- AtomicIntegerArray:整型数组原子类。
- AtomicLongArray:长整型数组原子类。
- AtomicReferenceArray:引用类型数组原子类。
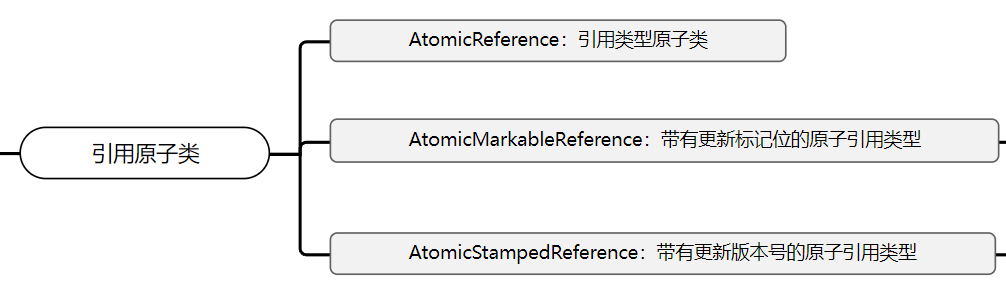
3、引用原子类
引用原子类主要包括以下三个:
- AtomicReference:引用类型原子类。
- AtomicMarkableReference:带有更新标记位的原子引用类型。AtomicMarkableReference类将boolean标记与引用关联起来,可以解决使用AtomicBoolean进行原子方式的更新时可能出现的ABA问题。
- AtomicStampedReference:带有更新版本号的原子引用类型。AtomicStampedReference类将整数值与引用关联起来,可以解决使用AtomicInteger进行原子方式的更新时可能出现的ABA问题。
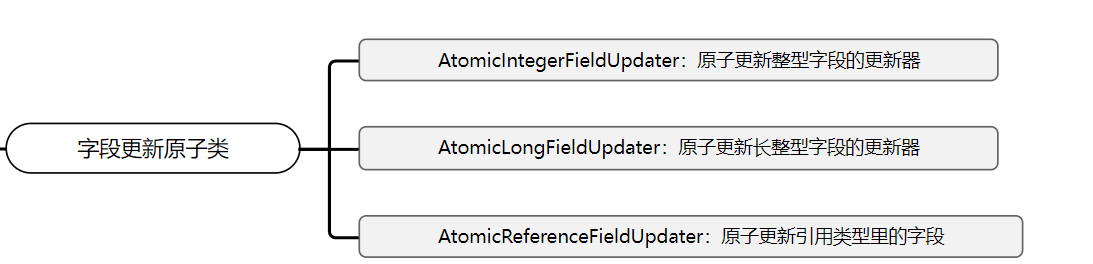
4、字段更新原子类
字段更新原子类主要包括以下三个:
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
3.2 基本原子类-AtomicInteger
AtomicInteger、AtomicLong、AtomicBoolean三个基础原子类所提供的方法几乎相同,因此这里以AtomicInteger为例来介绍
1、AtomicInteger 的方法介绍
基础原子类AtomicInteger常用的方法主要如下:
源码如下
public class AtomicInteger extends Number implements java.io.Serializable {
//获取当前值
public final int get();
//设置值
public final void set(int newValue);
//获取当前值并设置新值
public final int getAndSet(int newValue);
//通过CAS方式设置整数值
public final boolean compareAndSet(int expect, int update);
//获取当前值并自增1
public final int getAndIncrement();
//获取当前值并自减1
public final int getAndDecrement();
//获取当前值并加上一个数
public final int getAndAdd(int delta);
//自增1后获取最后结果
public final int incrementAndGet();
//自减1后获取最后结果
public final int decrementAndGet();
//加上一个数后获取最终结果
public final int addAndGet(int delta);
//......
}
2、AtomicInteger使用案例
基本方法使用示例
@Test
public void atomicIntegerTest() {
int temvalue = 0;
//定义一个整数原子类实例,赋值到变量 i
AtomicInteger i = new AtomicInteger(0);
//取值,然后设置一个新值
temvalue = i.getAndSet(3);
//输出
Print.fo("temvalue:" + temvalue + "; i:" + i.get());//temvalue:0; i:3
//取值,然后自增
temvalue = i.getAndIncrement();
//输出
Print.fo("temvalue:" + temvalue + "; i:" + i.get());//temvalue:3; i:4
//取值,然后增加5
temvalue = i.getAndAdd(5);
//输出
Print.fo("temvalue:" + temvalue + "; i:" + i.get());//temvalue:4; i:9
//CAS交换
boolean flag = i.compareAndSet(9, 100);
//输出
Print.fo("flag:" + flag + "; i:" + i.get());//flag:true; i:100
}
多线程环境下实现安全自增的示例
在多线程环境下,如果涉及基本数据类型的并发操作,不建议采用synchronized重量级锁进行线程同步,而是建议优先使用基础原子类保障并发操作的线程安全性。
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
//定义一个整数原子类实例,赋值到变量 i
AtomicInteger atomicInteger = new AtomicInteger(0);
for (int i = 0; i < THREAD_COUNT; i++) {
// 创建10个线程,模拟多线程环境
ThreadUtil.getMixedTargetThreadPool().submit(() ->
{
for (int j = 0; j < 1000; j++) {
atomicInteger.getAndIncrement();
}
latch.countDown();
});
}
latch.await();
Print.tco("累加之和:" + atomicInteger.get());
}
3、AtomicInteger线程安全原理
基础原子类(以AtomicInteger为例)主要通过CAS自旋+volatile相结合的方案实现,既保障了变量操作的线程安全性,又避免了synchronized重量级锁的高开销,使得Java程序的执行效率大为提升。
AtomicInteger源码如下:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// unsafe 实例对象
private static final Unsafe unsafe = Unsafe.getUnsafe();
//value属性值的地址偏移量
private static final long valueOffset;
static {
try {
//调用unsafe的方法计算value的偏移位置
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// 内部value值,使用volatile保证可见性
private volatile int value;
// 构造方法
public AtomicInteger(int initialValue) {
value = initialValue;
}
public AtomicInteger() {
}
//获取当前值
public final int get() {
return value;
}
//设置值
public final void set(int newValue) {
value = newValue;
}
/**
* Eventually sets to the given value.
*
* @param newValue the new value
* @since 1.6
*/
public final void lazySet(int newValue) {
unsafe.putOrderedInt(this, valueOffset, newValue);
}
//获取当前值并设置新值
public final int getAndSet(int newValue) {
// CAS
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
//方法:封装底层的CAS操作,对比expect(期望值)与value,若不同则返回false
//若expect与value相同,则将新值赋给value,并返回true
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndDecrement() {
return unsafe.getAndAddInt(this, valueOffset, -1);
}
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int decrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, -1) - 1;
}
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
//...
}
3.3 数组原子类-AtomicIntegerArray
使用原子的方式更新数组中的某个元素:
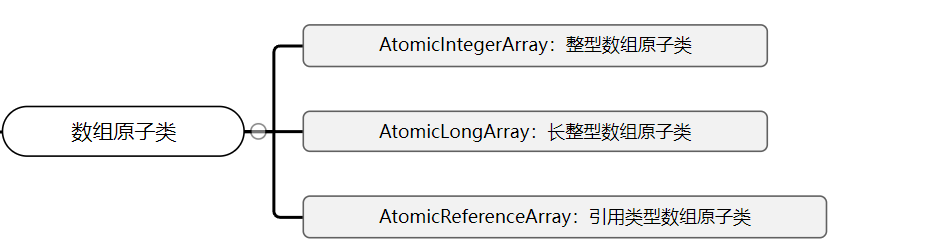
上面三个类提供的方法几乎相同,所以我们这里以AtomicIntegerArray为例来介绍
1、AtomicIntegerArray 的方法介绍
AtomicIntegerArray 如下:
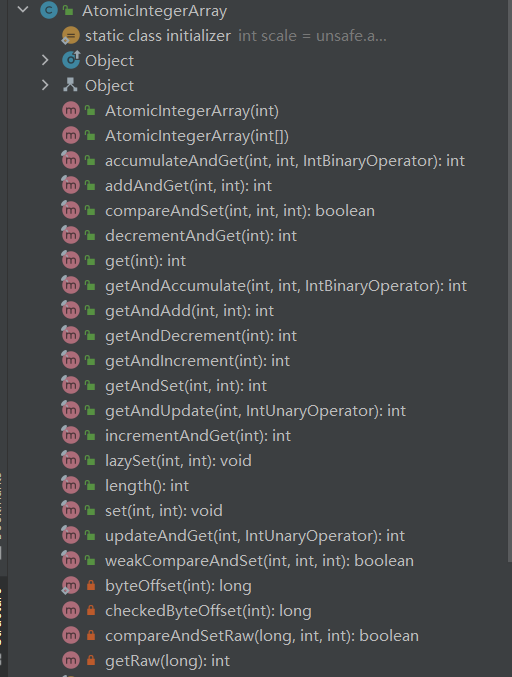
源码如下:
//获取 index=i 位置元素的值
public final int get(int i)
//返回index=i位置的当前的值,并将其设置为新值:newValue
public final int getAndSet(int i, int newValue)
//获取index=i位置元素的值,并让该位置的元素自增
public final int getAndIncrement(int i)
//获取index=i位置元素的值,并让该位置的元素自减
public final int getAndDecrement(int i)
//获取index=i位置元素的值,并加上预期的值
public final int getAndAdd(int delta)
//如果输入的数值等于预期值,就以原子方式将位置i的元素值设置为输入值(update)
boolean compareAndSet(int index,int expect, int update)
//最终将位置i的元素设置为newValue
//lazySet方法可能导致其他线程在之后的一小段时间内还是可以读到旧的值
public final void lazySet(int i, int newValue)
从源码看,对原子数组的操作都带有位置信息,即原子操作的时候,需要指定某个位置的元素进行操作。
2、AtomicIntegerArray 使用案例
AtomicIntegerArray 的基本使用代码如下:
@Test
public void testAtomicIntegerArray() {
int tempvalue = 0;
//建立原始的数组
int[] array = {1, 2, 3, 4, 5, 6};
//包装为原子数组
AtomicIntegerArray i = new AtomicIntegerArray(array);
//获取第0个元素,然后设置为2
tempvalue = i.getAndSet(0, 2);
//输出 tempvalue:1; i:[2, 2, 3, 4, 5, 6]
Print.fo("tempvalue:" + tempvalue + "; i:" + i);
//获取第0个元素,然后自增
tempvalue = i.getAndIncrement(0);
//输出 tempvalue:2; i:[3, 2, 3, 4, 5, 6]
Print.fo("tempvalue:" + tempvalue + "; i:" + i);
//获取第0个元素,然后增加一个delta 5
tempvalue = i.getAndAdd(0, 5);
//输出 tempvalue:3; i:[8, 2, 3, 4, 5, 6]
Print.fo("tempvalue:" + tempvalue + "; i:" + i);
}
3.4 引用类型原子类-AtomicReference,AtomicMarkableReferencr,AtomicStampedRefernce
基础的原子类型只能保证一个变量的原子操作,当需要对多个变量进行操作时,CAS无法保证原子性操作,这时可以用AtomicReference(原子引用类型)保证对象引用的原子性。
简单来说,如果需要同时保障对多个变量操作的原子性,就可以把多个变量放在一个对象中进行操作。
1、AtomicReference:引用类型原子类
AtomicReference类的使用示例如下:
1.定义一个POJO类
@Slf4j
public class User implements Serializable {
String uid;
String devId;
String token;
String nickName;
transient PLATTYPE platform;
int intPlatFrom;
public volatile int age; //年龄
public User() {
nickName = "nickName";
setPlatform(PLATTYPE.ANDROID);
}
public User(String uid, String nickName) {
this.uid = uid;
this.nickName = nickName;
}
// windows,mac,android, ios, web , other
public enum PLATTYPE {
WINDOWS, MAC, ANDROID, IOS, WEB, OTHER;
}
private String sessionId;
@JSONField(serialize = false)
public void setPlatform(PLATTYPE platform) {
this.platform = platform;
this.intPlatFrom = platform.ordinal();
}
@JSONField(serialize = false)
public PLATTYPE getPlatform() {
if (null == platform) {
this.platform = PLATTYPE.values()[intPlatFrom];
}
return platform;
}
@JSONField(name = "intPlatFrom")
public int getIntPlatFrom() {
this.platform = PLATTYPE.values()[intPlatFrom];
return intPlatFrom;
}
@JSONField(name = "intPlatFrom")
public void setIntPlatFrom(int code) {
this.intPlatFrom = code;
this.platform = PLATTYPE.values()[code];
}
@Override
public String toString() {
return "User{" +
"uid='" + getUid() + '\'' +
", nickName='" + getNickName() + '\'' +
", age=" + age +
", platform=" + getPlatform() +
", intPlatFrom=" + getIntPlatFrom() +
'}';
}
public static User fromMsg(ProtoMsg.LoginRequest info) {
User user = new User();
user.uid = new String(info.getUid());
user.devId = new String(info.getDeviceId());
user.token = new String(info.getToken());
user.setIntPlatFrom(info.getPlatform());
log.info("登录中: {}", user.toString());
return user;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getDevId() {
return devId;
}
public void setDevId(String devId) {
this.devId = devId;
}
public String getToken() {
return token;
}
public void setToken(String token) {
this.token = token;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public String getSessionId() {
return sessionId;
}
public void setSessionId(String sessionId) {
this.sessionId = sessionId;
}
}
2.使用AtomicReference对User的引用进行原子性修改
@Test
public void testAtomicReference() throws InterruptedException {
//包装的原子对象
AtomicReference<User> userRef = new AtomicReference<User>();
//待包装的User对象
User user = new User("1", "张三");
//为原子对象设置值
userRef.set(user);
Print.tco("userRef is:" + userRef.get());
//要使用CAS替换的User对象
User updateUser = new User("2", "李四");
//使用CAS替换
boolean success = userRef.compareAndSet(user, updateUser);
Print.tco(" cas result is:" + success);
Print.tco(" after cas,userRef is:" + userRef.get());
}
以上代码首先创建了一个User对象,然后把User对象包装到一个AtomicReference类型的引用userRef中,如果要修改userRef的包装值,就需要调用compareAndSet()方法才能完成。该方法就是通过CAS操作userRef,从而保证操作的原子性。
注意: 使用原子引用类型AtomicReference包装了User对象之后,只能保障User引用的原子操作,对被包装的User对象的字段值修改时不能保证原子性
2、AtomicMarkableReferencr解决ABA问题
很多乐观锁的实现版本都是使用版本号(Version)方式来解决ABA问题。乐观锁每次在执行数据的修改操作时都会带上一个版本号,版本号和数据的版本号一致就可以执行修改操作并对版本号执行加1操作,否则执行失败。因为每次操作的版本号都会随之增加,所以不会出现ABA问题,因为版本号只会增加不会减少。
AtomicStampReference在CAS的基础上增加了一个Stamp(印戳或标记),使用这个印戳可以用来觉察数据是否发生变化,给数据带上了一种实效性的检验。
AtomicStampReference的compareAndSet()方法首先检查当前的对象引用值是否等于预期引用,并且当前印戳标志是否等于预期标志,如果全部相等,就以原子方式将引用值和印戳标志的值更新为给定的更新值。
3、AtomicMarkableReferencr方法介绍
public class AtomicStampedReference<V> {
//构造函数:V表示要引用的原始数据,initialStamp表示最初的版本印戳(版本号)
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
}
//获取封装的reference
public V getReference() {
return pair.reference;
}
//获取封装的版本印戳 stamp
public int getStamp() {
return pair.stamp;
}
/*
CAS操作的定义如下:进行CAS操作时,若当前引用值等于预期引用值,并且当前印戳值等于预期印戳值,则以原
子方式将引用值和印戳值更新为给定的更新值。
1.expectedReference 预期引用值
2.newReference 更新后的引用值
3.expectedStamp 预期印戳标志值
4.newStamp 更新后的印戳标志值
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
}
4、AtomicMarkableReferencr使用案例
@Test
public void testAtomicStampedReference() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(2);
AtomicStampedReference<Integer> atomicStampedRef =
new AtomicStampedReference<Integer>(1, 0);
ThreadUtil.getMixedTargetThreadPool().submit(new Runnable() {
@Override
public void run() {
boolean success = false;
int stamp = atomicStampedRef.getStamp();
Print.tco("before sleep 500: value=" + atomicStampedRef.getReference()
+ " stamp=" + atomicStampedRef.getStamp());
//等待500毫秒
sleepMilliSeconds(500);
success = atomicStampedRef.compareAndSet(1, 10,
stamp, stamp + 1);
Print.tco("after sleep 500 cas 1: success=" + success
+ " value=" + atomicStampedRef.getReference()
+ " stamp=" + atomicStampedRef.getStamp());
//增加标记值
stamp++;
success = atomicStampedRef.compareAndSet(10, 1,
stamp, stamp + 1);
Print.tco("after sleep 500 cas 2: success=" + success
+ " value=" + atomicStampedRef.getReference()
+ " stamp=" + atomicStampedRef.getStamp());
latch.countDown();
}
});
ThreadUtil.getMixedTargetThreadPool().submit(new Runnable() {
@Override
public void run() {
boolean success = false;
int stamp = atomicStampedRef.getStamp();
// stamp = 0
Print.tco("before sleep 1000: value=" + atomicStampedRef.getReference()
+ " stamp=" + atomicStampedRef.getStamp());
//等待1000毫秒
sleepMilliSeconds(1000);
//stamp = 1
Print.tco("after sleep 1000: stamp = " + atomicStampedRef.getStamp());
success = atomicStampedRef.compareAndSet(1, 20, stamp, stamp++);
Print.tco("after cas 3 1000: success=" + success
+ " value=" + atomicStampedRef.getReference()
+ " stamp=" + atomicStampedRef.getStamp());
latch.countDown();
}
});
latch.await();
}
5、AtomicStampedRefernce解决ABA问题
AtomicMarkableReference是AtomicStampedReference的简化版,不关心修改过几次,仅仅关心是否修改过。因此,其标记属性mark是boolean类型,而不是数字类型,标记属性mark仅记录值是否修改过。
AtomicMarkableReference适用于只要知道对象是否被修改过的场景,而不适用于对象被反复修改的场景。
6、AtomicStampedRefernce方法介绍
public class AtomicMarkableReference<V> {
//构造函数,传入的标记位是boolean类型
public AtomicMarkableReference(V initialRef, boolean initialMark) {
pair = Pair.of(initialRef, initialMark);
}
//获取被封装的引用值
public V getReference() {
return pair.reference;
}
//获取修改标志
public boolean isMarked() {
return pair.mark;
}
// CAS操作
public boolean compareAndSet(V expectedReference,
V newReference,
boolean expectedMark,
boolean newMark) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedMark == current.mark &&
((newReference == current.reference &&
newMark == current.mark) ||
casPair(current, Pair.of(newReference, newMark)));
}
}
7、AtomicStampedRefernce使用案例
@Test
public void testAtomicMarkableReference() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(2);
AtomicMarkableReference<Integer> atomicRef =
new AtomicMarkableReference<Integer>(1, false);
ThreadUtil.getMixedTargetThreadPool().submit(new Runnable() {
@Override
public void run() {
boolean success = false;
int value = atomicRef.getReference();
boolean mark = getMark(atomicRef);
Print.tco("before sleep 500: value=" + value
+ " mark=" + mark);
//等待500毫秒
sleepMilliSeconds(500);
success = atomicRef.compareAndSet(1, 10,
mark, !mark);
Print.tco("after sleep 500 cas 1: success=" + success
+ " value=" + atomicRef.getReference()
+ " mark=" + getMark(atomicRef));
latch.countDown();
}
});
ThreadUtil.getMixedTargetThreadPool().submit(new Runnable() {
@Override
public void run() {
boolean success = false;
int value = atomicRef.getReference();
boolean mark = getMark(atomicRef);
Print.tco("before sleep 1000: value=" + atomicRef.getReference()
+ " mark=" + mark);
//等待1000毫秒
sleepMilliSeconds(1000);
Print.tco("after sleep 1000: mark = " + getMark(atomicRef));
success = atomicRef.compareAndSet(1, 20, mark, !mark);
Print.tco("after cas 3 1000: success=" + success
+ " value=" + atomicRef.getReference()
+ " mark=" + getMark(atomicRef));
latch.countDown();
}
});
latch.await();
}
3.5 属性更新原子类-AtomicIntegerFieldUpdater
如果需要保障对象某个字段(或者属性)更新操作的原子性,需要用到属性更新原子类。属性更新原子类有以下三个:
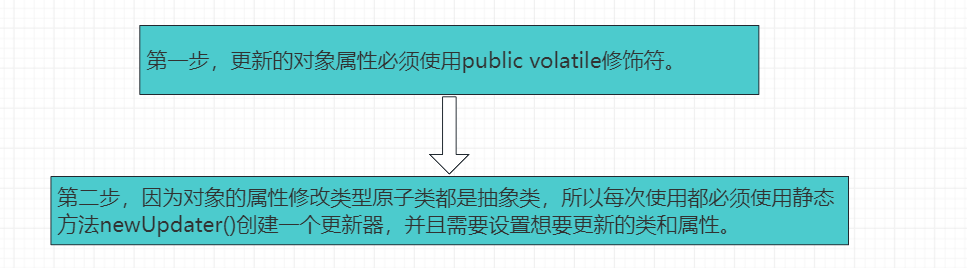
由于上面三个类提供的方法几乎相同,所以我们这里以AtomicIntegerFieldUpdater为例来介绍。使用属性更新原子类保障属性安全更新的流程大致需要两步:
AtomicIntegerFieldUpdater类的使用示例
@Test
public void testAtomicIntegerFieldUpdater() throws InterruptedException {
AtomicIntegerFieldUpdater<User> a =
AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
User user = new User("1", "张三");
Print.tco(a.getAndIncrement(user));// 1
Print.tco(a.getAndAdd(user, 100));// 101
Print.tco(a.get(user));// 101
}
四、LongAdder:优化CAS操作性能
在争用激烈的场景下,会导致大量的CAS空自旋。比如,在大量的线程同时并发修改一个AtomicInteger时,可能有很多线程会不停地自旋,甚至有的线程会进入一个无限重复的循环中。大量的CAS空自旋会浪费大量的CPU资源,大大降低了程序的性能。
4.1 LongAdder介绍
LongAdder是JDK8提供的一个以空间换时间的方式提升高并发场景下CAS操作性能的类。在竞争非常激烈的情况下,可以使用LongAdder替换ActomicInteger。

过LongAdder将内部操作对象从单个value值“演变”成一系列的数组元素,从而减小了内部竞争的粒度。LongAdder的演变如图
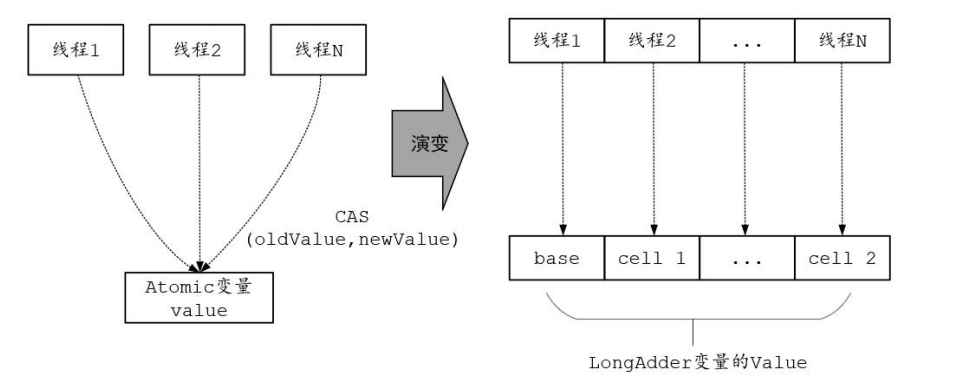
4.2 LongAdder使用案例
@org.junit.Test
public void testLongAdder() {
// 并发任务数
final int TASK_AMOUNT = 10;
//线程池,获取CPU密集型任务线程池
ExecutorService pool = ThreadUtil.getCpuIntenseTargetThreadPool();
//定义一个LongAdder 对象
LongAdder longAdder = new LongAdder();
// 线程同步倒数闩
CountDownLatch countDownLatch = new CountDownLatch(TASK_AMOUNT);
long start = System.currentTimeMillis();
for (int i = 0; i < TASK_AMOUNT; i++) {
pool.submit(() ->
{
try {
for (int j = 0; j < TURNS; j++) {
longAdder.add(1);
}
// Print.tcfo("本线程累加完成");
} catch (Exception e) {
e.printStackTrace();
}
//倒数闩,倒数一次
countDownLatch.countDown();
});
}
try {
//等待倒数闩完成所有的倒数操作
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
Print.tcfo("运行的时长为:" + time);
Print.tcfo("累加结果为:" + longAdder.longValue());
}
4.3 LongAdder 的原理
1、LongAdder基类Striped64
LongAdder继承于Striped64类,基类Striped64源码如下:
abstract class Striped64 extends Number {
/**
* 成员一:存放Cell的哈希表,大小为2的幂
* 如果有竞争的话,会将要累加的数累加到Cells数组中
* 的某个cell元素里面。所以Striped64的整体值value为 base+∑[0~n]cells。
*/
transient volatile Cell[] cells;
/**
* 成员二:基础值
* 1. 在没有竞争时会更新这个值
* 2. 在cells初始化时,cells不可用,也会尝试将通过cas操作值累加到base
* 在没有竞争的
* 情况下,要累加的数通过CAS累加到base上
*/
transient volatile long base;
/**
* 成员三:自旋锁,
* 通过CAS操作加锁,为0表示cells数组没有处于创建、扩容阶段
* 为1用于表示正在创建或者扩展Cell数组,不能进行新Cell元素的设置操作
*/
transient volatile int cellsBusy;
}
2、LongAdder重要属性
LongAdder继承了Striped64中的3个重要属性如下:
transient volatile Cell[] cells;
transient volatile long base;
transient volatile int cellsBusy;
LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽(元素)中,各个线程只对自己槽中的那个值进行CAS操作。这样热点就被分散了,冲突的概率就小很多。使用LongAdder,即使线程数再多也不担心,各个线程会分配到多个元素上去更新,增加元素个数就可以降低 value的“热度”,AtomicLong中的恶性CAS空自旋就解决了。
一个LongAdder实例的内部结构,具体如图
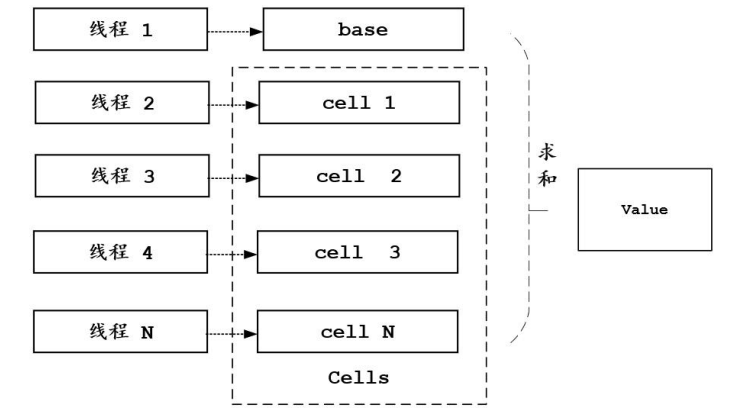
LongAdder的内部成员包含一个base值和一个cells数组。在最初无竞争时,只操作base的值;当线程执行CAS失败后,才初始cells数组,并为线程分配所对应的元素。
3、LongAdder 的 add()方法
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/*
* 1.cells!=null :表示存在竞争,在不存在争用的时候,cells数组一定为null,一旦对base的cas操作失败,才会初始化cells数组
* 2.!casBase(b = base, b + x):表示如果cells数组为null,表示之前不存在争用,并且此次casBase执行成功,
* 则表示基于base成员累加成功,add方法直接返回;如果casBase方法执行失败,说明产生了
* 第一次争用冲突,需要对cells数组初始化,此时即将进入内层if块。
* */
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
/*
* 3.as == null || (m = as.length - 1)<0代表cells没有初始化
* 4.(a = as[getProbe() & m]) == null:指当前线程的哈希值在cells数组映射位置的Cell对象为空,
* 意思是还没有其他线程在同一个位置做过累加操作。
* 5. !(uncontended = a.cas(v = a.value, v + x)):指当前线程的哈希值在cells数组映射位置的Cell对象不为空,然后在该Cell对象上进行CAS操作,
* 设置其值为v+x(x为该Cell需要累加的值),但是CAS操作失败,表示存在争用。
* */
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
//以上三个条件语句3、4、5 有一个为真,就进入longAccumulate方法
longAccumulate(x, null, uncontended);
}
}
参考
https://pdai.tech/md/java/thread/java-thread-x-key-synchronized.html
https://tech.meituan.com/2019/02/14/talk-about-java-magic-class-unsafe.html
《极致经典(卷2):Java高并发核心编程(卷2 加强版)》 作者:尼恩