hello,我是大都督周瑜,这篇文章带你用十张图“拿捏”MySQL中B+树的生成过程。
更多干货技术文章、面试题,欢迎关注我的公众号:IT周瑜
当MySQL接收到一条以下SQL时,表示要从t1表中查询数据:
select * from t1 where id = 3;
那表的数据存在哪呢?
自然是磁盘文件,每个表创建的时候都需要专门创建一个文件来存表的一行一行数据,这个文件叫做用户表空间文件,也就是ibd文件。
当执行insert语句时,比如:
insert into t1(id, a, b) values(3, 1, 'zhouyu');
MySQL需要将insert语句解析为一行数据,比如以上insert对应的一行记录为

但是这是逻辑层面的,这一行记录真正要存到磁盘,需要转成二进制。
id和a字段都是int类型,占4个字节,只需要将十进制转成二进制即可,b字段是字符,需要根据设置的字符编码来转成二进制,如果是ascii,那么每个字符对应一个字节。
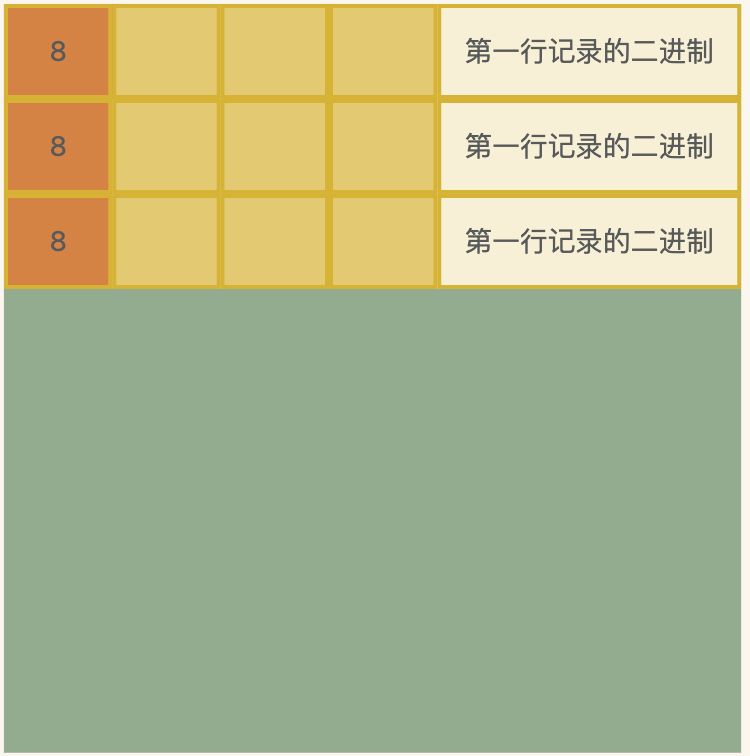
最终这行记录对应的二进制为

把记录转成二进制之后,就需要存在到文件中了,也就是

如果多存储几行,那就是

这么看其实还是逻辑的,真正在磁盘中行和行之间是没有框框的,而是

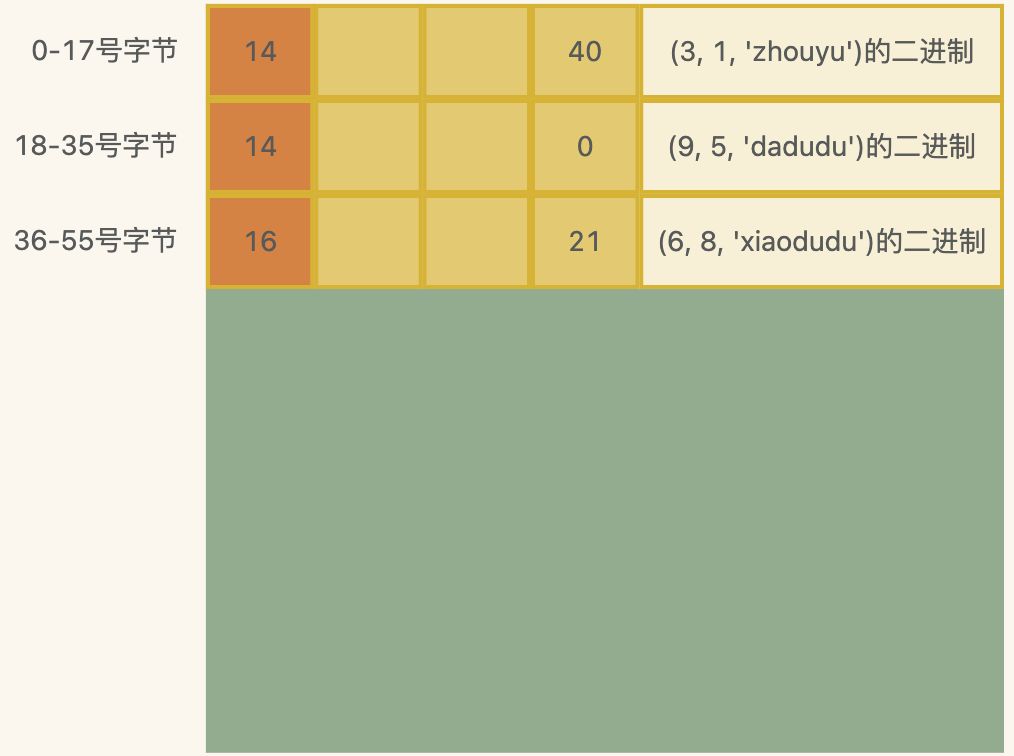
因此,当插入了多行数据行后,如果行和行之间没有指定的分割符,那在获取数据的时候就不好区分各行的数据了,因此需要明确定义好行的格式,我们可以在每行记录前定义一个记录头,固定占4个字节,其中一个字节用来存当前记录的长度,也就是字节数,另外三个字节先空着。
如果依次插入的是:
insert into t1(id, a, b) values(3, 1, 'zhouyu');
insert into t1(id, a, b) values(9, 5, 'dadudu');
insert into t1(id, a, b) values(6, 8, 'xiaodudu');
那么对应的就是

不过,不知道大家发现问题没有,现在插入的数据并没有按id升序排序,我们先不管为什么要按id排序,我们先想如何按id进行升序排序,难道移动记录的物理位置吗?
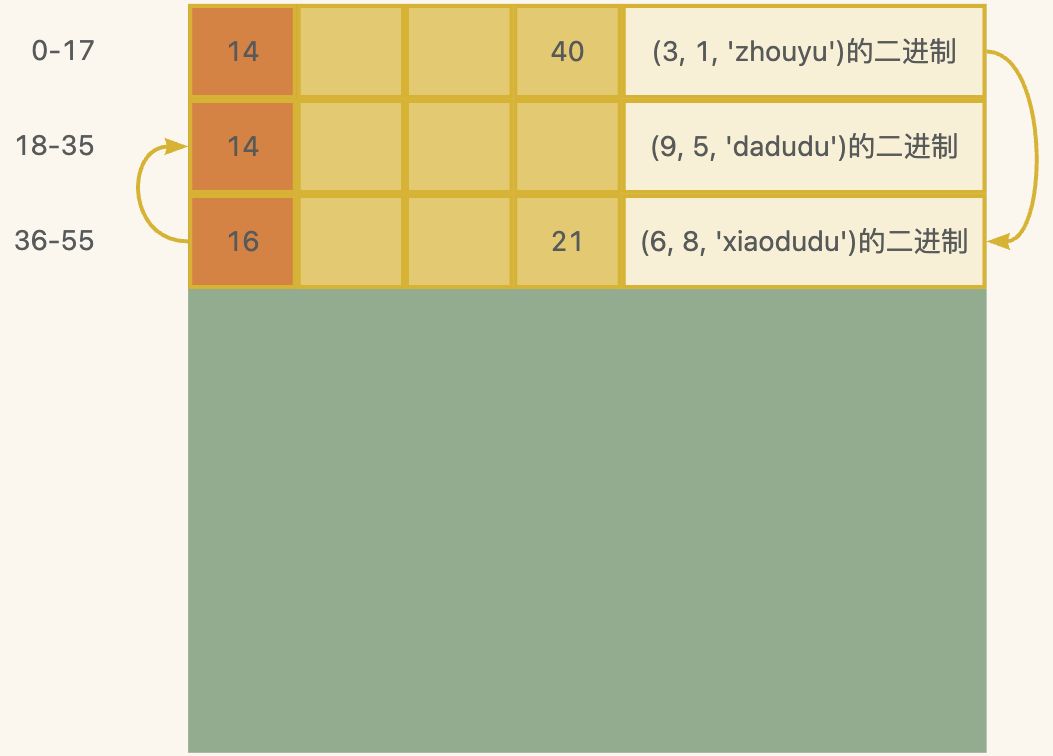
当然不用这么麻烦,我们可以在每行记录再新增一个隐藏字段,叫做next_record,相当于链表节点的指针,这样就可以通过这个next_record来控制记录的逻辑顺序了,而不用移动物理位置。
所谓的记录的指针,就是对应记录在文件中字节的编号,或者叫做偏移量,比如40就是表示文件中第40个字节是当前记录的下一条记录,在InnoDB的设计中是指向了记录的中间,这样既方便获取记录的字段,又方便获取记录的next_record,为了好理解,我们还是把指针箭头画出来
还有一个更严重的问题,假如现在执行where查询,比如:
select * from t1 where b = 'dadudu';
需要遍历每行记录进行判断,那难道每次从文件中获取一行记录进行判断吗?那当然不行,记录多了那得做很多次IO。
因此有了页,每页默认16KB,不过一页能存多少条记录就不是固定的了。

我们假如一页只能存三条,那么现在要存9条记录,就需要3页,也就是3个16KB。

注意,每页中可能有空隙的,所以页和页之间我都留了一点空隙。
innodb每次都会取16kb的数据出来,然后遍历这16kb数据中的每行记录,可是如何知道有没有下一页呢?因此每页除开会存数据行之外,还额外有一个page header的固定空间,用来存page_no和next_page,page_no表示页号,从0开始,next_page表示下一页,存的就是下一页的页号,因为每页固定是16KB,因此只要知道page_no就能从文件中定位到具体页的物理位置,从而读取该页的内容,比如要获取page_no=2的页内容,那就直接从第2*16384个字节开始取,取16384个字节就是page_no=2的页的内容。
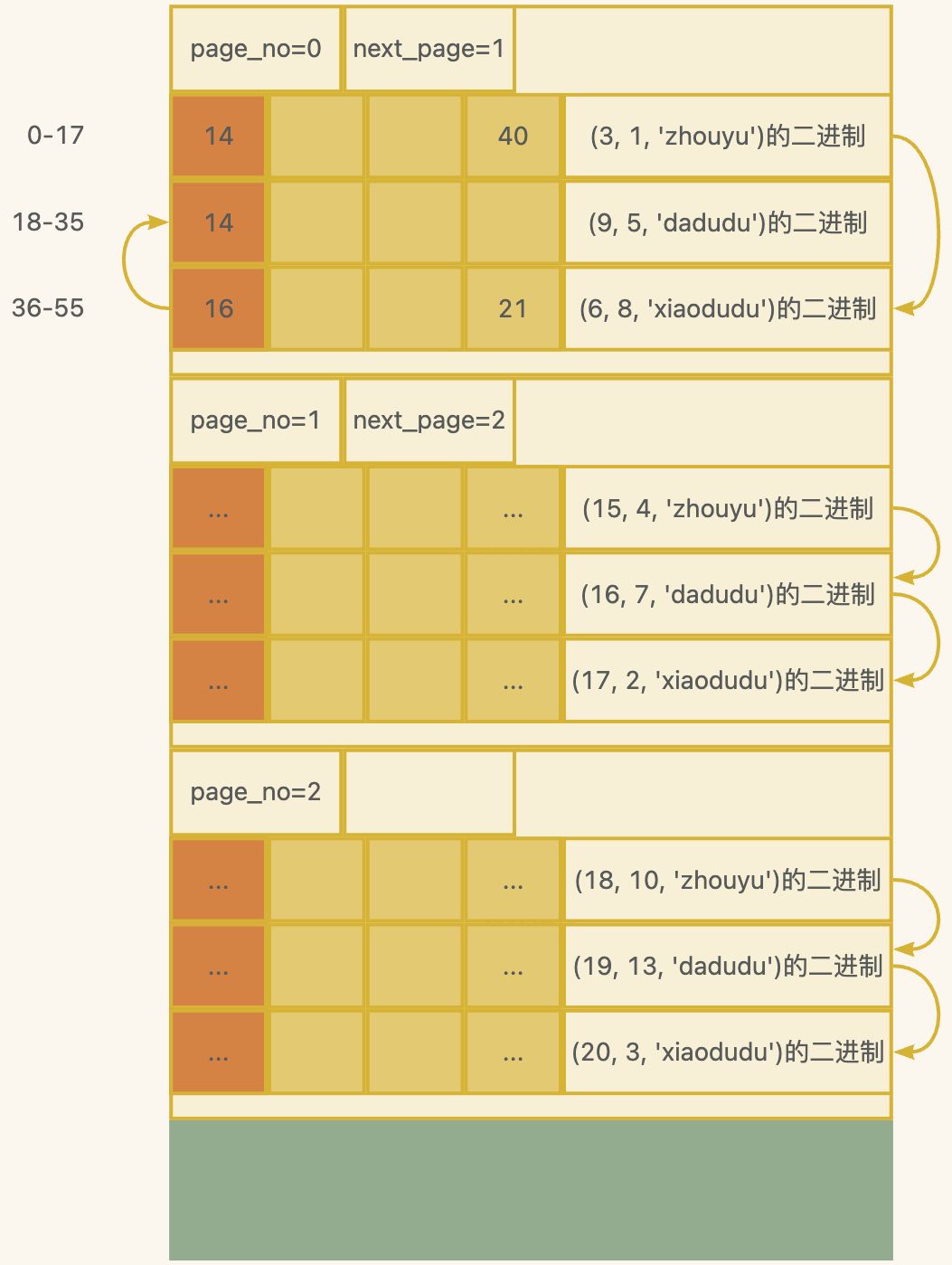
那如果数据越来越多呢?有很多页呢?此时执行where查询也需要进行很多次io,性能也不高了。
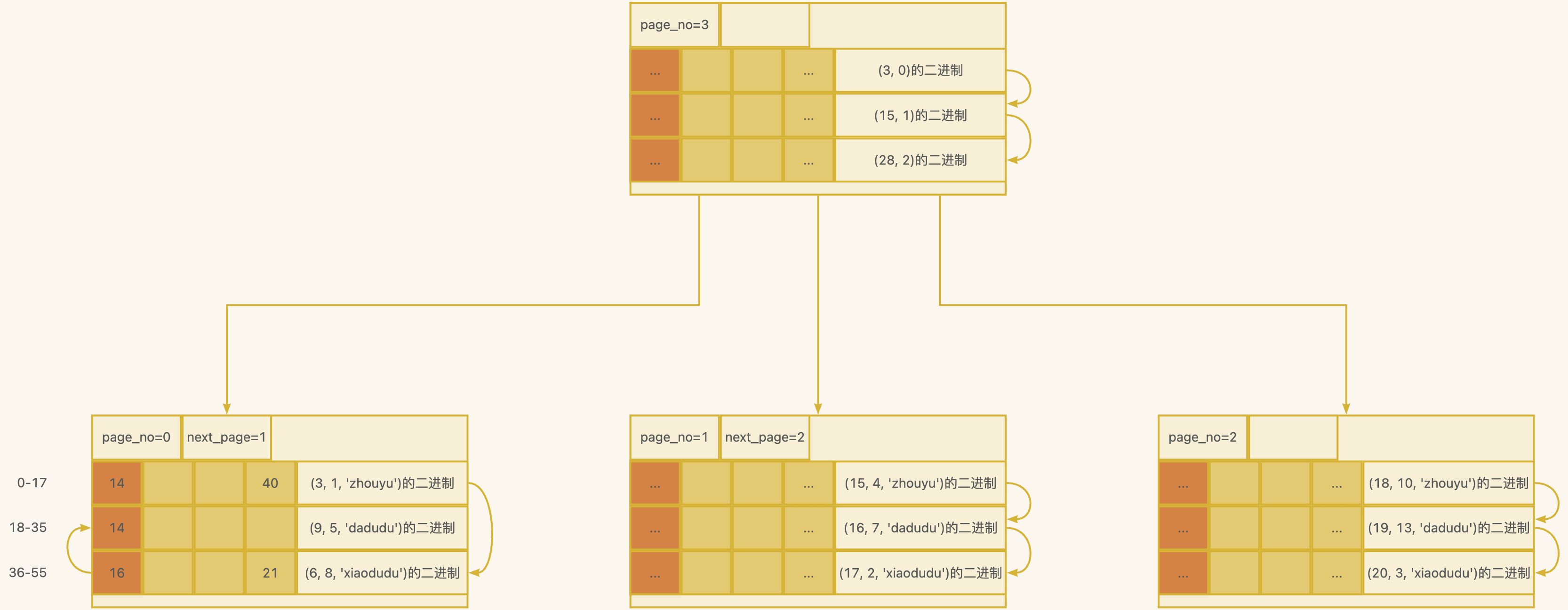
此时就需要用到索引了,索引的本质就是排序,我们可以额外再开辟16kb,也就是一个新页,page_no=3,该页中记录其他页的页号和最小的id值。
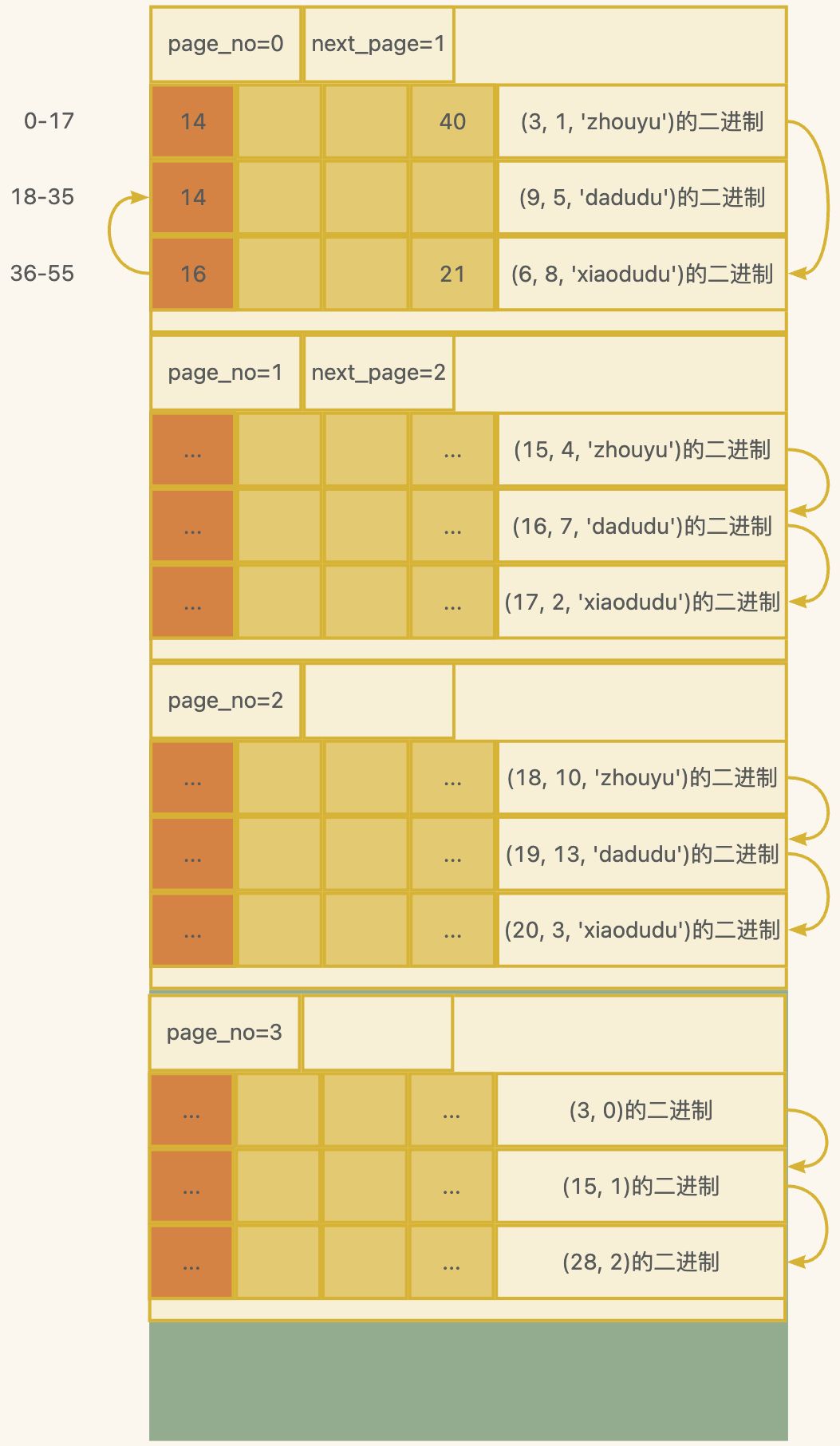
- (3,0)记录表示指向page_no=0的页,并且该页中最小的id为3
- (15,1)记录表示指向page_no=1的页,并且该页中最小的id为15
- (28,2)记录表示指向page_no=2的页,并且该页中最小的id为28
以上其实就是一颗B+树了,只不过如果换成以下这样更容易理解,但真正的实现是上图。
本文旨在描述MySQL中B+树大概的生成过程,忽略了很多细节,比如表空间具体的格式、记录行具体的格式、页的具体格式、B+树的根页转换过程、页的拆分过程、页的重组过程等等,大家如果对这些感兴趣,可以关注我的公众号:IT周瑜。
本文主要内容就分享到这里,希望能得到大家的点赞和分享。


















![[AHK]Listbox with incremental search](https://i-blog.csdnimg.cn/direct/1711392f2fc941188071f7676937423a.png)