1. 模块
1.1 import导入
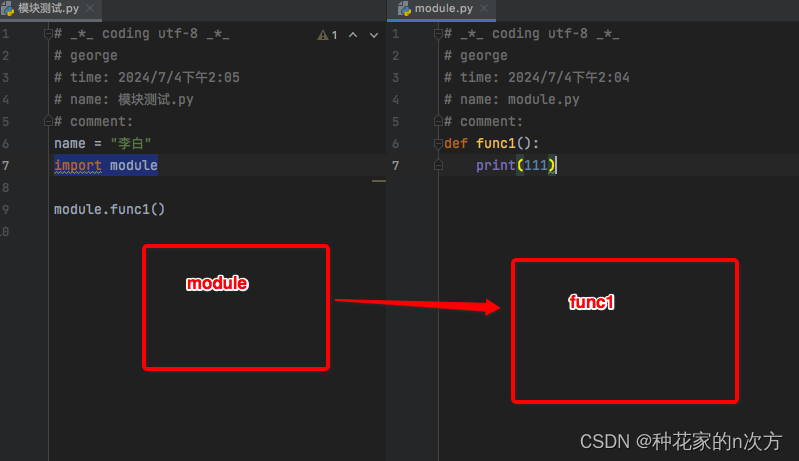
1) 模块:是一系列功能的集合体,模块名.功能名,就可以使用模块的功能
2) 首次导入模块,就会立即执行模块里面的内容
3) 当前名称空间会产生一个名字module,指向module.py产生的名称空间.我们可以使用module.name/函数名,来调用module.py里面的内容.
modlue.py文件的内存地址引用变为0的时候,该名称空间才会被回收.就是模块测试.py文件运行完毕的时候
4) 在函数内部导入模块,这个模块名是属于函数局部名称空间的,其他地方是访问不到的.
5) 当module.py被直接运行的时候,__name__的值为__main__,当modlue.py作为模块导入时,__name__的值为模块名module.
1.2 from..import..导入
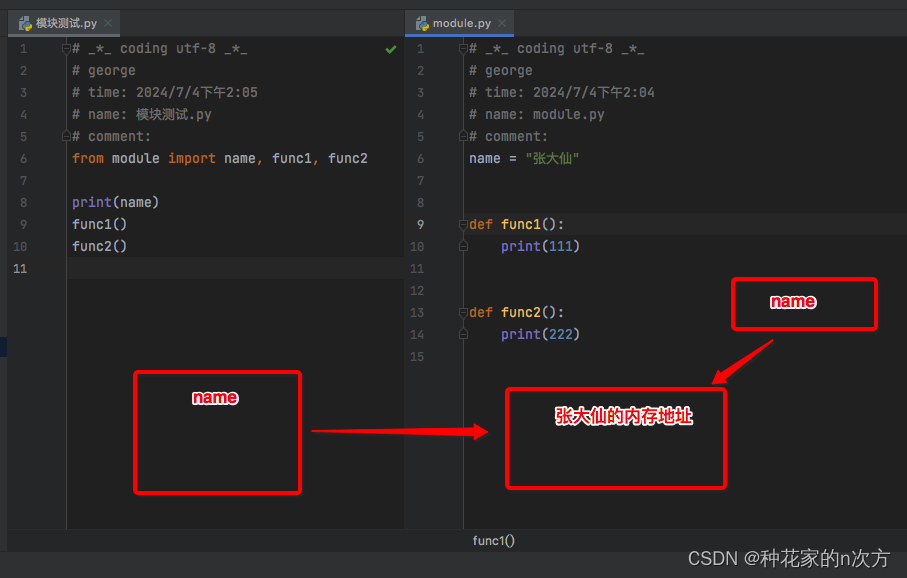
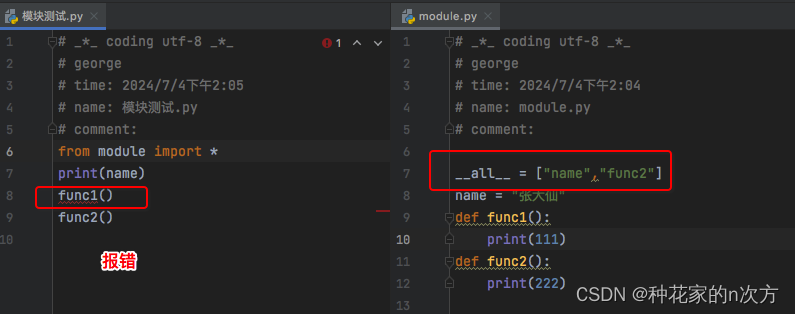
1) import导入后需要加模块名来调用模块里面的属性和功能.使用from导入后,就避免写前缀了.它会直接指向模块里面对应的功能或是变量值的内存地址.也就是说当前模块的name指向的是"张大仙"的内存地址,而不是name.
2) from modlue import *,默认导入的就是__all__里面的名字.我们可以通过控制__all__的内容来控制导入的内容.
1.3 模块的查找顺序
1)现在内存找,内存找不到就到硬盘找。内存的查找路径是按照sys.path的列表里面依次查找的
 2)如果导入的模块和当前运行的程序不是在同一文件夹,那么可以将模块所在的文件夹,添加进入sys.path.再导入模块的时候,就可以被识别到。
2)如果导入的模块和当前运行的程序不是在同一文件夹,那么可以将模块所在的文件夹,添加进入sys.path.再导入模块的时候,就可以被识别到。
3)只要在文件中间添加了此行代码,那么直接使用文件名就可以运行文件,不用再加python解释器。

2.包
2.1 包的概念
1)包就是一个含有__init__.py文件的文件夹
2)导包的流程和导入模块的流程是一样的(导入包pack)
——创建名称空间(pack的名称空间)
——执行python文件(运行pack.py但是没有只能运行__init__.py)
——在执行的名称空间中产生一个名字,指向前面的名称空间(所以当前名称空间里面的pack指向的是__init__.py的名称空间)
2.2 绝对导入


1)所有被导入的文件的sys.path参照的都是执行文件的sys.path.也就是说__init__.py文件的执行路径也是'D:\\PythonData\\pythonProject\\module-7'.我们直接导入running.在sys.path里面是找不到的。它的路径下面只有game.所以导入的时候是从包的起始位置game进行导入。
但是所有的前提都是,使用者要将game所在的路径添加到环境变量里面去,不管是包被嵌套了多少层。
'D:\\PythonData\\pythonProject\\module-7\\mm\\tt“

2)导入规则
入包时凡是带.的,.的左边必须是一个包


2.3 相对导入
. 表示当前文件所在的文件夹就是__init__.py文件所在的文件夹。

.. 表示上一层文件夹
pay的当前文件夹是gg,上一层文件夹是game.从game找walking.
相对导入的范围不可超出顶级包game.

2.4 补充
如果在__init__.py文件里面并没有导入包下面的模块名,调用的时候可以直接导入logging.config,此时会先检索__init__.py里面有没有config,没有再找模块名.但是调用的时候就必须加上前缀logging.config.

3.日志
3.1 日志基本配置
1) 日志的默认输出级别就是warning,warning以下的内容就不会输出.可以通过控制日志等级来控制日志输出
2) 日志的基本配置包括(1.日志级别,2.日志格式,3.asctime,4.日志输出位置)
import logging
logging.basicConfig(
# 1.日志级别
# DEBUG:10
# INFO:20
# WARNING:30
# ERROR:40
# CRITICAL:50
level=10,
# 2.日志输出格式
# %(asctime)s -> 获取当前时间
# %(name)s -> 当前日志的名字
# %(pathname)s -> 产生日志文件的名字
# %(lineno)d -> 产生日日志的行
# %(levelname)s -> 产生日志的等级
# %(message)s -> 日志的详细内容
format='%(asctime)s %(name)s [%(pathname)s line:%(lineno)d] %(levelname)s %(message)s',
# 3、asctime的时间格式
datefmt="%Y-%m-%d %H:%M:%S",
# 4、日志输出位置:终端|文件,不指定此项配置,默认输出到终端
filename="user.log"
)
# 日志的输出级别是可以设置的
logging.debug("debug")
logging.info("info")
logging.warning("warning")
logging.error("error")
logging.critical("critical")输出日志的时候没有指定字符编码,所以默认使用的就是系统的编码方式.windows使用的gbk,mac和linux默认的就是UTF-8.pycharm默认是使用UTF-8打开的,所以对于windows电脑可能会出现乱码.
2024-07-05 08:58:30 root [/Users/f7692281/PycharmProjects/other-stydy/日志/日志测试.py line:34] DEBUG debug
2024-07-05 08:58:30 root [/Users/f7692281/PycharmProjects/other-stydy/日志/日志测试.py line:35] INFO info
2024-07-05 08:58:30 root [/Users/f7692281/PycharmProjects/other-stydy/日志/日志测试.py line:36] WARNING warning
2024-07-05 08:58:30 root [/Users/f7692281/PycharmProjects/other-stydy/日志/日志测试.py line:37] ERROR error
2024-07-05 08:58:30 root [/Users/f7692281/PycharmProjects/other-stydy/日志/日志测试.py line:38] CRITICAL critical3.2 日志配置字典
日志的基本配置可能会出现乱码的问题,并且不同将日志同时输出到文件和终端.
1) loggers负责产生不同级别的日志,handlers负责处理不同级别的log,是输出到文件/终端,以..形式来产生log.formatters则是负责控制log的输出格式

2) 因为logging这个包在使用的时候,没有将congfig导入到__init__.py里面所以只能够使用logging.config()


3) 可以使用没有名字的日志记录器,将多个log记录到同一个log里面.

4) 日志轮转
# _*_ coding utf-8 _*_
# george
# time: 2024/1/9上午10:46
# name: settings.py
# comment:
import logging
LOGGING_DIC = {
"version": 1.0,
"disable_existing_log": False,
# 日志格式,这里可以指定多种日志格式,这里的standard...就是对应日志名字
"formatters": {
"standard": {
"format": '%(asctime)s %(name)s [%(pathname)s line:%(lineno)d] %(levelname)s %(message)s',
"datefmt": "%Y-%m-%d %H:%M:%S"},
"simple": {
"format": '%(asctime)s %(name)s %(levelname)s %(message)s',
"datefmt": "%Y-%m-%d %H:%M:%S"},
"test": {"format": '%(asctime)s %(message)s'}
},
"filters": {},
# 日志处理器:将记录的日志进行处理(输出到文件/显示到控制台)
# 可以设置多个handler不同的handler做不同的处理,做不同的配置
"handlers": {
"console_debug_handler": {
"level": 20, # 日志处理的级别限制
"class": "logging.StreamHandler", # 输出到终端
"formatter": "simple", # 日志格式
},
"file_info_handler": {
"level": "INFO",
'class': "logging.handlers.RotatingFileHandler",
"filename": "deal.log",
# 日志大小,10M,日志文件达到10M的时候进行轮转
# 默认单位为字节,1KB 1024 Byte,1MB为1024KB
"maxBytes": 800,
"backupCount": 10, # 日志文件保存数量的限制
"encoding":"utf-8",
"formatter":"standard"
},
"file_debug_handler": {
"level": 10,
"class": "logging.FileHandler", # 保存到文件
"filename": "test.log", # 日志存放的路径
"encoding": "utf-8", # 日志文件的编码
"formatter": "test" # 日志格式
},
"file_deal_handler": {
"level": 20,
"class": "logging.FileHandler", # 保存到文件
"filename": "deal.log", # 日志存放的路径
"encoding": "utf-8", # 日志文件的编码
"formatter": "standard" # 日志格式
},
"file_operate_handler": {
"level": 20,
"class": "logging.FileHandler", # 保存到文件
"filename": "operate.log", # 日志存放的路径
"encoding": "utf-8", # 日志文件的编码
"formatter": "standard" # 日志格式
}
},
# 日志记录器
"loggers": {
"logger1": { # 导入时logging.getLogger时使用的app_name
"handlers": ["console_debug_handler","file_info_handler"], # 日志将要分配给哪个handler进行日志处理
"level": "DEBUG", # 日志记录的级别限制,和handlers里面的日志一起组成两层日志过滤
"propagate": False # 默认为True,向更高级别的日志进行传递
},
"logger2": {
"handlers": ["console_debug_handler", "file_debug_handler"], # 日志将要分配给哪个handler进行日志处理
"level": "INFO", # 日志记录的级别限制,和handlers里面的日志一起组成两层日志过滤
"propagate": False # 默认为True,向更高级别的日志进行传递
},
"": {
"handlers": ["file_deal_handler","file_info_handler"], # 日志将要分配给哪个handler进行日志处理
"level": "INFO", # 日志记录的级别限制,和handlers里面的日志一起组成两层日志过滤
"propagate": False # 默认为True,向更高级别的日志进行传递
},
"用户操作": {
"handlers": ["file_operate_handler"], # 日志将要分配给哪个handler进行日志处理
"level": "INFO", # 日志记录的级别限制,和handlers里面的日志一起组成两层日志过滤
"propagate": False # 默认为True,向更高级别的日志进行传递
}
}
}
4.configparser模块的读写
这个模块是用来加载一种特定格式的配置文件的.配置文件的后缀名为ini或是cfg是什么名字其实并不重要,只要让别人一看就知道你这是配置文件就可以了

- [default]是这一部分配置的标题,名字可以随便起.是这个配置文件section.每个section里面的这些配置被叫做option.
- 这些option的表现形式可以是=,也可以是:这两种做法都是被支持的.
- 在这里写入的是什么就会被读取到什么.添加"",""也会被读取到.所以如果定义的option为空时,直接=后面什么都不加就可以了.
4.1 config模块的读取
# settings.ini配置
from configparser import ConfigParser
config = ConfigParser()
CONFIG_PATH = os.path.join(Base_Dir,"settings.ini")
config.read(CONFIG_PATH,encoding="utf-8")
login_user = config.get('default',"LOGIN_USER")
login_type = config.get('default',"LOGIN_TYPE")4.2 config模块的写入
# -5.1 记录登陆的用户名和用户类型
settings.config.set("default", "LOGIN_USER", name)
settings.config.set("default", "LOGIN_TYPE", user_type)
with open(settings.CONFIG_PATH, mode="w", encoding="utf-8") as f:
settings.config.write(f)5.eval和exec
5.1 eval
eval主要是用来执行表达式的,它执行的代码需要一个返回结果

5.2 globals和locals
globals()和locals()
globals()获取的是全局名称空间里面所有的名字.
loacls()获取的是局部名称空间里面所有的名字,如果locals()在全局里面使用的话,拿到的结果和globals()是一致的,我们当前在全局,所以当前的局部就是全局.


5.3 eval剩余两个参数
- g代表全局名称空间
- l代表局部名称空间
- 现在可以将eval执行的代码想象为一段函数的子代码,g就是它能够访问到的全局名称空间,l就是它的全局名称空间.这两个参数其实都是为了往里面传参数的.如果不传全局名称空间的话,默认就会将所有全局空间里面的名字都传递进去


- 我们不传第2和第3个参数的时候eval()是可以执行的,也就是说我们不定制全局名称空间和局部名称空间的时候.它默认会把所有全局的名字都传进去,就是globals()和locals().如果而我们定制了第2个参数,它只会传我们自定义的名字以及python内置的名字


- 表达式必须有返回值,如果没有返回值会直接报错

5.4 exec
- exec主要是用来执行代码块的,它的用法和eval是类似的,只是它是没有返回值的.
- exec只会将字符串里面产生的名字,存到第三个参数里面如果我们直接在全局打印a是会报错的
- 如果不传后面的两个参数,默认传递的就是globals()和locals(),字符串里面产生的名字会保存到locals()里面,而当前就是在全局,也就是说globals()就是locals()
- globals()绑定了全局名称空间,locals()并没有绑定当前局部名称空间,只是一个拷贝版本的字典