关联比赛: “新内容 新交互”全球视频云创新挑战赛--算法挑战赛道
Richardzuo比赛攻略
赛题背景与理解
视频物体分割(Video Object Segmentation)是计算机视觉最近两三年兴起的⼀个研究领域,其⽬的是从视频所有图像帧中把感兴趣的物体区域的分割出来。与视频物体跟踪不同,视频物体跟踪只要求得到每帧图像中感兴趣物体的包围框,⽽视频物体分割必须精确到图像的每个像素,因此是⽬前计算机视觉领域最难的任务之⼀。
目前的视频物体分割可以分为三个类别:半监督视频物体分割、无监督视频物体分割和交互式视频物体分割。其中,半监督视频物体分割是给定用户感兴趣物体在视频第一帧图片上的分割区域,算法来获取在后续帧上的物体分割区域。无监督视频物体分割是全自动的视频物体分割,除了视频外,没有其他任何输入。其目的是全自动分割出视频中显著性的物体区域。交互式视频物体分割的输入不是第一帧物体的掩码,而是某帧图像上少量用户交互信息,算法需要根据用户交互信息在整个视频中分割处感兴趣物体。在这三个类别中,半监督视频物体分割算法是所有视频物体分割的基础,无监督视频物体分割最具有挑战性。
⼀般来说,⼈是视频中最重要的内容,精确地分割出视频中的⼈体区域在各个领域中均有着重要应⽤前景,如切换⼈物背景、合成⼴告、抠图等。可以说,视频⼈物分割对视频的⼆次创作有着极为重要的意义,⾼精度的视频⼈物分割算法结合⼴⼤⽤户们⽆限的想象⼒会创造出众多意想不到的玩法与应⽤,也会为企业创造许多有趣、有意义、有价值的商业应⽤空间。

较于⼀般的VOS任务,专注于⼈体区域的分割算法难度更⼤,主要原因在于:
-
⼈体往往有各种各样的⼿持物(如杯⼦、球拍、⻝物、餐具等)与附属物(如项链、帽⼦、⼤⾐、提包)等,这些附属物的语义信息与纹理信息与⼈体有着较⼤差异,⽽且附属物类别众多,尺度不⼀,如何准确地识别出各种附属物是本任务的难点之⼀;
-
⼈体动作幅度、类型变化较⼤。不同于DAVIS等数据集中的其他物体,如⾃⾏⻋、⻜机、汽⻋等刚性物体,⼈体是柔性的,这意味着在⼀段视频⾥同⼀个⼈体的外观与形态会有较⼤的差异;此外,⼈体可能还会有较⼤的动作幅度,如跳舞、运动等类型的视频,肢体的动作幅度远远⼤于其他常⻅动物。
-
当⼈物背景较为复杂或者区域内⼈体较多时,会出现严重的遮挡情形。如何处理这些复杂情况仍是⼀个难以解决的问题。

就精度来说,半监督算法的精度明显⾼于⽆监督算法的精度,这是由于视频第⼀帧的GT信息已经包含了⾮常丰富的先验信息,包括⼈体数量、⼈体区域、背景区域等,⽽且是精确到像素级别的先验信息。就实⽤性程度来说,⽆监督算法的实⽤性与应⽤前景则远⾼于半监督算法,毕竟标注精确到像素级别程度的⼈体区域是⼀项⾮常耗时且枯燥的⼯作,费时费⼒,⽽且需要有专业的标注⼯具,这会严重限制算法的应⽤场景。由于⽆监督的视频分割算法应⽤前景更加⼴泛,已经有越来越多的学者致⼒于此研究。⽬前⽐较常⻅的思路是先使⽤图像分割算法处理视频的第⼀帧图像,⽣成接近于GT的Mask分割结果,以此作为伪标签来将⽆监督分割任务转化为半监督分割任务。这种做法充分利⽤了⽬前⽐较成熟的图⽚分割算法与半监督视频分割算法,将⼆者结合起来进⾏解决⽆监督视频分割任务,实现过程简单可靠,有着较好的发展前景,这也是本次竞赛中采用的思路。
核心算法
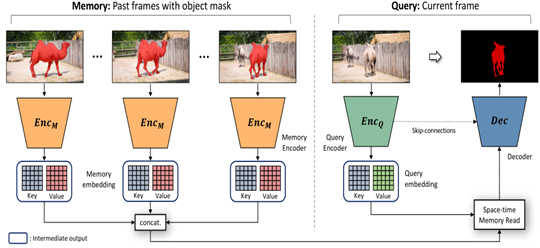
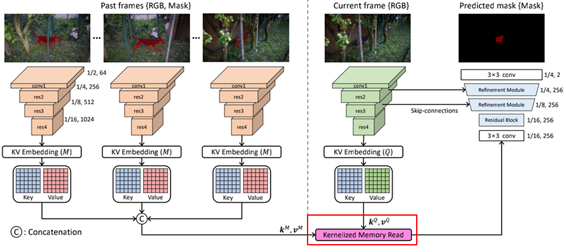
STM算法在VOS领域取得了较大的成功,其使用记忆力网络来存储过去帧的检测特征,并利用时空注意力机制将过去帧特征与当前帧特征的每个像素点进行匹配,这充分利用了之前检测结果的先验信息,对于遮挡情形以及剧烈运动情形有着很好的处理能力。
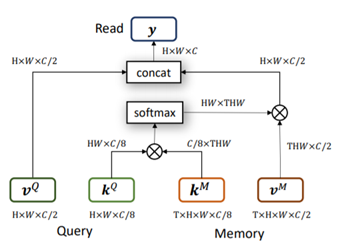
然而,STM算法也存在许多问题,其Non-local匹配机制虽然可以很好的利用之前帧检测结果的特征,但也很容易出现一个目标匹配到多个目标的问题,特别是不同目标之间有着相似外观的时候。对此KMN网络提出了kernelized memory reader方法。具体来说,该方法首先筛选出Memory特征中与当前帧特征最匹配的一个点,以此为中心点构建高斯核,以此抑制远离该点区域的特征响应。这种Memory reader可以有效抑制外观相似目标的错误响应,防止STM算法检测出多个相似目标。
KMN存在有空间不连续的问题。当不同目标具有相似外观时,得到的最匹配特征点很容易出现在其他目标区域,出现目标匹配错误情形。

总结如下STM,KMN算法的主要问题如下:
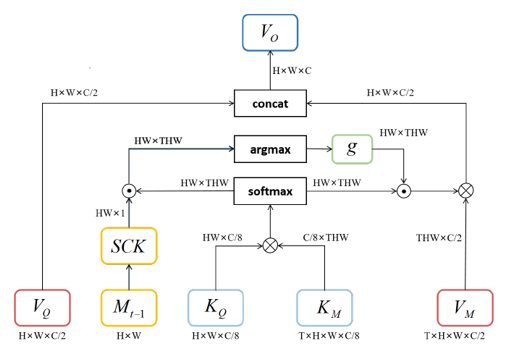
- 特征缺少空间连续性: Memory reader的Non-local注意力机制忽略了特征的空间连续性
- 训练速度慢: 由于视频段物体数量不同,STM使用单块GPU跑一个视频,造成显存分配不均衡。目标数量过多时显存不够,过少时显存又过剩。经过实测,一个720x1280的视频段,目标数量大于4且图片数量大于100帧时,只有32GB的V100 才能满足训练要求
- 误差累积: 由于训练视频段只有3帧图片,推理视频段却有上百帧的图片。如此大的gap会导致STM算法在推理时鲁棒性很差,易造成误差的累积与放大
对此,我们的解决思路是:
- 使用带有spacial-constrain的kernelized memory reader模块来提高特征的空间连续性,提高目标的匹配精度。其结构如图:

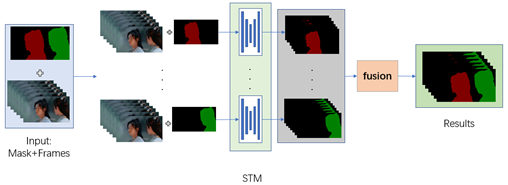
其次,提出将STM算法改进为更纯粹的单目标分割算法,在加载数据时便将视频段的多个目标拆解为单个目标,而不是在模型计算的时候在模型内部拆分。这样做的好处是可以确保模型接触的视频段全部为单目标视频段,目标数目固定,方便了网络的训练与推理。确保可以根据显存数量来自由设置batchsize。原STM算法,在训练天池的人物分割数据集时,在不改变原分辨率(720x1280)的情况下,只有32G显存的v100可以跑得动一个视频段,除此以外任何一张显卡也不行,哪怕是总显存已经超过32G的多张卡并联也不可以。
改进后的单目标STM算法只负责模型计算,将多目标拆分工作交给了数据集加载部分,将多目标聚合工作交给了推理代码。这种更加纯粹的单目标STM算法使得模型更加关注计算本身,而无需负责多目标的拆分与聚合。使得模型可以自由的根据显存大小设置batchsize,同时也可以使用多张显存不大的显卡并行训练或推理。结构如图:
经过实测,当使用720P分辨率的天池人物分割数据集时,原始STM算法的训练和推理过程只能使用32G显存的V100显卡来进行,除此之外使用任何一张显存小一点的显卡都不行,而经过改进后的单目标STM算法可以自由选择选择,使用4x3090进行训练时,设置batchsize=8,即每个显卡负责训练两个目标,训练速度远远超过单张v100的训练速度。
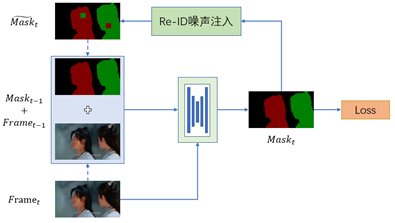
最后,在训练阶段引入re-id噪声,让网络主动适应这种混淆噪声,以提高算法的鲁棒性。具体过程为,在生成当前帧的预测结果之后,随机选取一个50x50的区域,将此区域内的背景、前景倒换,以模仿模型在推理过程中的混淆问题。
这种引入re-id噪声来进行对抗训练的方法有效地避免了STM算法过度信任Memory中的缓存帧,防止了误差的累计与放大,显著的提高了单目标STM算法的精度。训练策略如下:
比赛经验总结和感想
阿里云&intel 举办的本次比赛定义为算法赛道,团队在参赛过程中发现无监督的Video Object Segmentation算法十分依赖实例分割的先验与时序Propagation网络的相互配合,比赛过程中,团队研究并选取了Propagation效果较好的STM网络并对其空间限制缺失的情况进行改善,利用历史memory产生Spatial-Constrain Kernel对人物出现的空间位置进行限制,最终能够解决绝大部分的ID Switch的情况,其次团队选取了分割边界较为好的SOLOv2作为实例分割的网络,产生很好的实例分割结果,最后团队借鉴Video Object Tracking的思路,建立Tracking Score来决定最终的显著性目标及初始帧,将Propagation和Segmentation很好的结合在了一起。
其次,本次比赛在工程方面,团队使用了intel提供的BF16加速指令,使得模型推理速度提升200%+,通过对CPU计算能力与网络大小的均衡,团队指定出了最佳的推理策略,并针对数据集每段视频Object数量不同造成的负载不均衡问题进行了解决,最终团队以第二名的分数进入总决赛,无多模型、分辨率融合的情形下,Mean J&F达到88.8,200段视频的CPU推理时间仅为4个小时!
视频是跨向通用视觉AI的一道门槛,当AI算法能够真正理解视频的时候,它或许才能够理解人类视觉的原理,视频技术将成为新视觉AI一个亟待攻克的难关,团队将一直关注并尝试解决视频领域已知的难题,希望推动通用视觉AI的发展与进步。
查看更多内容,欢迎访问天池技术圈官方地址:全球视频云创新挑战赛算法赛道第一名比赛攻略_天池技术圈-阿里云天池