1、分组函数
1. 分组函数语法
分组函数也叫聚合函数。是对表中一组记录进行操作,每组只返回一个结果。我们只讲如下5个常用的分组函数:
| 分组函数 | 含义 |
| MAX | 求最大值 |
| MIN | 求最小值 |
| SUM | 求和 |
| AVG | 求平均值 |
| COUNT | 求个数 |
分组函数的语法如下:
SELECT 列名, 分组函数
FROM 表名
WHERE 条件表达式
ORDER BY 列名;
说明:
1、分组函数写在SELECT子句上
2、WHERE、ORDER BY子句可以省略不写
2. MIN函数和MAX函数
MIN和MAX函数主要是返回每组的最小值和最大值,语法如下:
MIN( [ DISTINCT | ALL ] 列名 | 表达式 )
MAX( [ DISTINCT | ALL ] 列名 | 表达式 )
说明:
1、MIN和MAX可以用于任何数据类型
2、DISTINCT表示去掉组中的重复值,ALL表示不去掉重复值,省略不写默认为ALL
3、既可以写列名,也可以写表达式,通常写列名。
4、MIN和MAX函数会忽略掉NULL值后,再进行运算。
例:查询员工入职的最早日期和最晚日期
SELECT MIN(hiredate), MAX(hiredate)
FROM emp;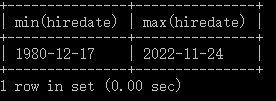
例:查询最低工资和最高工资
SELECT MIN(sal), MAX(sal)
FROM emp;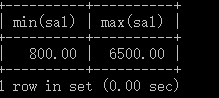
3. SUM函数和AVG函数
SUM和AVG函数分别返回每组的总和及平均值,语法如下:
SUM( [ DISTINCT | ALL ] 列名 | 表达式 )
AVG( [ DISTINCT | ALL ] 列名 | 表达式 )
说明:
1、SUM和AVG函数只能够对数值类型的列或表达式操作。
2、SUM和AVG函数会忽略掉NULL值后,再进行运算。
例:查询职位以SALES开头的所有员工 工资和、平均工资。
SELECT SUM(sal), AVG(sal)
FROM emp
WHERE job LIKE 'SALES%';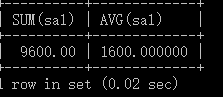
4. COUNT函数
COUNT函数用来返回满足条件的每组记录个数,语法如下:
1、COUNT(*):返回满足条件的每组记录个数。
2、COUNT( [ DISTINCT | ALL ] 列名 | 表达式 ):返回满足条件的每组非空记录个数。
说明:
5个分组函数,除COUNT(*)不忽略掉空值外,其余函数都是忽略掉空值再进行运算。
例:查询部门30有多少个员工,可以有如下两种写法:
方法1:
SELECT COUNT(*)
FROM emp
WHERE deptno = 30;
方法2:
SELECT COUNT(empno) --不建议写COUNT(*)
FROM emp
WHERE deptno = 30; 
例:查询部门30有多少个员工有津贴
SELECT COUNT(comm)
FROM emp
WHERE deptno = 30;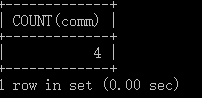
通过这个例子可以看出,COUNT(comm) 是忽略掉空值的。
5. 分组函数中的DISTINCT
DISTINCT会消除重复记录后再使用分组函数
例:查询有员工的部门数量。
SELECT COUNT(DISTINCT deptno)
FROM emp;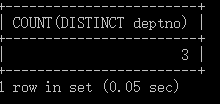
6. 分组函数中空值处理
刚才已经说过,除了COUNT(*)之外,其它所有分组函数都会忽略列中的空值,然后再进行运算。如果想让空值参与运算,那应该如何处理呢。在MySQL中提供了IFNULL函数,用法如下:
IFNULL(表达式1,表达式2):表示如果表达式1的值是NULL则取表达式2的值,如果表达式1不为NULL则用表达式1本身值。
例:查询所有员工的平均津贴,没有津贴的按0处理。
SELECT AVG(comm) , COUNT(comm)
FROM emp;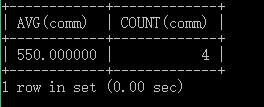
以上方式,并没有把没有津贴的员工按0处理,参与求平均值的是4个员工。
SELECT AVG(IFNULL(comm,0)) , COUNT(IFNULL(comm,0))
FROM emp;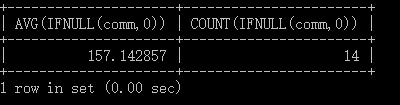
以上方式,通过使用IFNULL函数,把津贴是NULL的员工,按照0来处理,参与求平均值的是14个员工。
2、分组查询
1. 分组查询语法
上面的案例都是把一个表中的所有行做为一组来处理。如果想查询每个部门有多少人,每种岗位有多少人等等类似需求,就需要先把结果集按照某个列进行分组,然后再进行查询。
在SQL中,可以通过GROUP BY 子句,将表中满足WHERE条件的记录按照指定的列划分成若干个小组,划分的规则是:把满足条件的记录,在该列上相同的值做为一组。
语法如下:
SELECT 列名, 分组函数(列名)
FROM 表名
WHERE 条件表达式
GROUP BY 列名
ORDER BY 列名;
说明:
1、GROUP BY子句写在WHERE子句之后,其后的列名表示按照哪列进行分组
2、WHERE子句、ORDER BY 子句都可以省略不写
例:查询每个部门的编号,以及该部门所有员工的平均工资
SELECT deptno, AVG(sal)
FROM emp
GROUP BY deptno;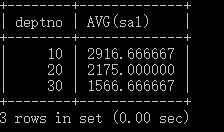
例:查询每种岗位上有多少个员工
SELECT job , COUNT(empno)
FROM emp
GROUP BY job;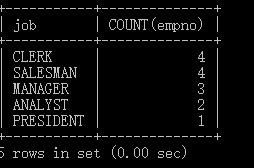
2. 分组语句的错误写法
分析如下SQL的执行结果
SELECT job , COUNT(empno) , sal
FROM emp
GROUP BY job;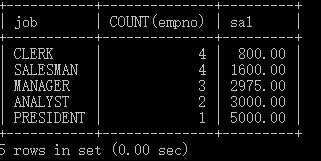
本SQL的查询结果集前两列显示的每个职位下的员工个数,第三个列显示的哪个员工的工资呢?在MySLQ中默认显示的该组中第一个员工的工资,放在这里没有任何实际意义。在Oracle数据库中,这种写法会提示语法错误。因此,当有GROUP BY子句时,SELECT子句后面只能写:被分组的列、分组函数,这两类元素才有实际意义。
3. 按多列分组查询
分组查询不但可以按照某一列进行分组,也可以按照多列进行分组。
例:查询每个部门每个岗位的工资总和。
SELECT deptno, job, sum(sal)
FROM emp
GROUP BY deptno, job; 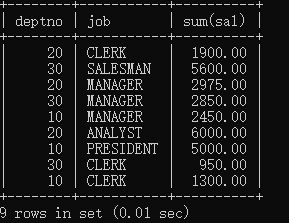
4. 多表查询分组查询
分组语句也可以和多表查询同时使用。
例:查询每个部门的部门编号,部门名称,部门人数,最高工资。
SELECT dept.deptno, dname, count(empno), max(sal)
FROM emp ,dept
WHERE emp.deptno = dept.deptno
GROUP BY dept.deptno,dname; 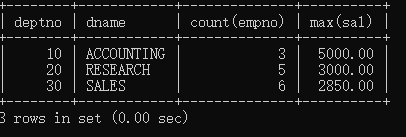
注意:此处emp表和dept表都有deptno列,需要在列名前加上表名。
3、过滤分组结果
1. HAVING子句
思考如下问题:查询部门人数大于3人的部门编号、部门人数。
"部门人数大于3"是一个条件,尝试一下是否可以写在WHERE子句中。
SELECT deptno,count(empno)
FROM emp
WHERE count(empno) >3
GROUP BY deptno; 
该SQL执行结束后,出现错误提示"Invalid use of group function",表示组函数应用无效。原因在于WHERE子句在GROUP BY 子句之前执行,所以当WHERE子句执行的时候,尚未进行分组,也就无法在WHERE子句中使用分组函数。
在SQL中提供了HAVING子句,用来解决此问题,解决方式如下:
SELECT deptno,count(empno)
FROM emp
GROUP BY deptno
HAVING count(empno) >3;
例:查询每个部门最高工资大于2900的部门编号,最高工资
SELECT deptno, max(sal)
FROM emp
GROUP BY deptno
HAVING max(sal)>2900; 
例:查询职位以SALES开头,每种职位的工资和,并且要求工资和大于5000,按照工资和升序排列
SELECT job, SUM(sal)
FROM emp
WHERE job NOT LIKE 'SALES%'
GROUP BY job
HAVING SUM(sal)>5000
ORDER BY SUM(sal); 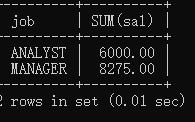
总结:
1、WHERE子句用来过滤分组之前的记录,不能使用组函数
2、HAVING子句用来过滤分组之后的记录,可以使用组函数
4、SELECT语句6个子句的执行顺序
到现在为止,SELECT语句的6个子句都已经学习完毕,分别是:
SELECT子句、FROM子句、WHERE子句、GROUP BY子句、 HAVING子句、ORDER BY子句,书写直接按照此顺序就可以。那么这一条完整的SELECT子句发送到数据库服务器,执行顺序是如何的,可以通过案例来了解一下。
如下SQL语句:
SELECT deptno,job,avg(sal)
FROM emp
WHERE job in ('SALESMAN','MANAGER','CLERK')
GROUP BY deptno,job
HAVING avg(sal)>1000
ORDER BY 3 DESC; 执行过程:
1、通过FROM子句中找到需要查询的表;
2、通过WHERE子句进行非分组函数筛选判断;
3、通过GROUP BY子句完成分组操作;
4、通过HAVING子句完成组函数筛选判断;
5、通过SELECT子句选择显示的列或表达式及组函数;
6、通过ORDER BY子句进行排序操作。