文章目录
- 一、前言
- 二、算法选型
- 2.1 Run-Length Encoding (RLE)
- 2.2 Differential Pulse-Code Modulation (DPCM)
- 三、采用RLE算法实现图像压缩
- 四、哈夫曼编码实现压缩和解压
- 4.1 哈夫曼编码压缩自定义数据与还原
- 4.2 哈夫曼编码压缩完成图像的压缩和还原
书接上回(上一篇文章已经讲解了如何封装BMP格式图片保存到本地SD卡)。
一、前言
在当今物联网(IoT)技术快速发展的背景下,嵌入式系统在各种应用场景中扮演着越来越重要的角色。随着物联网设备数量的不断增长,数据传输成为了关键的一环,尤其是在资源受限的环境中,如何高效地传输数据变得尤为重要。本文将介绍一个基于STM32F103ZET6微控制器的图像采集系统,该系统利用OV7725摄像头采集RGB565格式的图像,并通过MQTT协议将图像数据上传至阿里云物联网平台。 但是原始RGB565图像数据量巨大,直接传输会带来较高的网络负载,需要设计有效的压缩算法来减小数据体积。
考虑到单片机资源有限,无法使用第三方优秀的开源库,当前就基于Run-Length Encoding (RLE)无损压缩算法来减小图像数据的传输负担。RLE算法是一种简单有效的压缩方法,尤其适用于图像中存在大量连续重复像素值的情况。通过对重复像素的值和重复次数进行记录,可以显著减小图像数据的大小,从而降低网络传输的负载。下面会详细介绍RLE算法的设计与实现过程,以及如何在STM32F103ZET6微控制器上实现图像数据的压缩与解压,最终实现在阿里云物联网平台上进行高效的数据传输,并通过APP上位机进行图像数据的拉取与显示。
当前文章最重要的知识点是介绍: 数据的压缩和解压。
下面这个图是用的chargptAI自动生成的,不是实物图。

二、算法选型
在单片机上进行图像数据压缩,需要选择是使用轻量级、简单但有效的压缩算法。
以下2个是可以用的压缩算法,适合在单片机上实现并能够有效减小数据量。
2.1 Run-Length Encoding (RLE)
RLE 是一种非常简单的无损压缩算法,特别适用于图像中有大量连续重复像素值的情况。通过记录重复像素的值和重复次数来实现压缩。
下面是算法的核心实现: 解压和压缩
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
// RLE 压缩函数
size_t RLE_compress(const uint16_t *input, size_t length, uint8_t *output) {
size_t out_index = 0;
for (size_t i = 0; i < length; ) {
uint16_t value = input[i];
size_t run_length = 1;
while (i + run_length < length && input[i + run_length] == value && run_length < 255) {
run_length++;
}
output[out_index++] = (uint8_t)(run_length);
output[out_index++] = (uint8_t)(value >> 8);
output[out_index++] = (uint8_t)(value & 0xFF);
i += run_length;
}
return out_index;
}
// RLE 解压函数
size_t RLE_decompress(const uint8_t *input, size_t length, uint16_t *output) {
size_t out_index = 0;
for (size_t i = 0; i < length; i += 3) {
uint8_t run_length = input[i];
uint16_t value = (input[i + 1] << 8) | input[i + 2];
for (size_t j = 0; j < run_length; j++) {
output[out_index++] = value;
}
}
return out_index;
}
2.2 Differential Pulse-Code Modulation (DPCM)
DPCM 适用于图像中连续像素值变化较小的情况。通过记录相邻像素值的差值来实现压缩。
下面是算法的核心实现: 解压和压缩
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
// DPCM 压缩函数
size_t DPCM_compress(const uint16_t *input, size_t length, int16_t *output) {
output[0] = input[0];
for (size_t i = 1; i < length; i++) {
output[i] = input[i] - input[i - 1];
}
return length;
}
// DPCM 解压函数
size_t DPCM_decompress(const int16_t *input, size_t length, uint16_t *output) {
output[0] = input[0];
for (size_t i = 1; i < length; i++) {
output[i] = output[i - 1] + input[i];
}
return length;
}
三、采用RLE算法实现图像压缩
下面这段代码采用Run-Length Encoding (RLE) 算法对 RGB565 格式图像数据进行压缩和解压。
代码里定义了一个常量数组 gImage_rgb565_100x100,存储 100x100 图像的 RGB565 像素数据(通过实际摄像头采集得到的)。
RLE 压缩函数 RLE_compress 遍历输入的 RGB565 数据数组,查找连续相同的像素值,并记录它们的长度和值,将这些信息存储到输出的压缩数组中。每次遇到一段连续的相同值时,它会记录该段的长度(最大为 255)和该像素值的高位和低位字节。压缩后的数据长度返回给调用者。解压函数 RLE_decompress 读取压缩后的数组,根据记录的长度和值还原原始数据,将这些值存储到输出的解压数组中。main 函数中,计算图像数据的长度,然后分配内存用于存储压缩和解压后的数据,分别调用压缩和解压函数进行处理。最后,打印出原始数据大小、压缩后的数据大小以及压缩率,以验证压缩效果。所有动态分配的内存最终被释放,以避免内存泄漏。通过这样的实现,可以在不使用第三方库的情况下,有效地减少图像数据的传输负荷,提高传输效率。
实现代码:
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
// RLE 压缩函数
size_t RLE_compress(const uint16_t* input, size_t length, uint8_t* output) {
size_t out_index = 0;
for (size_t i = 0; i < length; ) {
uint16_t value = input[i];
size_t run_length = 1;
while (i + run_length < length && input[i + run_length] == value && run_length < 255) {
run_length++;
}
output[out_index++] = (uint8_t)(run_length);
output[out_index++] = (uint8_t)(value >> 8);
output[out_index++] = (uint8_t)(value & 0xFF);
i += run_length;
}
return out_index;
}
// RLE 解压函数
size_t RLE_decompress(const uint8_t* input, size_t length, uint16_t* output) {
size_t out_index = 0;
for (size_t i = 0; i < length; i += 3) {
uint8_t run_length = input[i];
uint16_t value = (input[i + 1] << 8) | input[i + 2];
for (size_t j = 0; j < run_length; j++) {
output[out_index++] = value;
}
}
return out_index;
}
int main() {
size_t length = sizeof(gImage_rgb565_100x100) / 2;
uint16_t* rgb565_array = (uint16_t*)gImage_rgb565_100x100;
// 分配 RLE 压缩后的数组
uint8_t* rle_compressed = (uint8_t*)malloc(length * 3 * sizeof(uint8_t));
if (rle_compressed == NULL) {
perror("Unable to allocate memory for RLE compressed array");
return 1;
}
// RLE 压缩
size_t rle_compressed_length = RLE_compress(rgb565_array, length, rle_compressed);
// 分配 RLE 解压后的数组
uint16_t* rle_decompressed = (uint16_t*)malloc(length * sizeof(uint16_t));
if (rle_decompressed == NULL) {
perror("Unable to allocate memory for RLE decompressed array");
return 1;
}
// RLE 解压
size_t rle_decompressed_length = RLE_decompress(rle_compressed, rle_compressed_length, rle_decompressed);
// 打印 RLE 压缩率
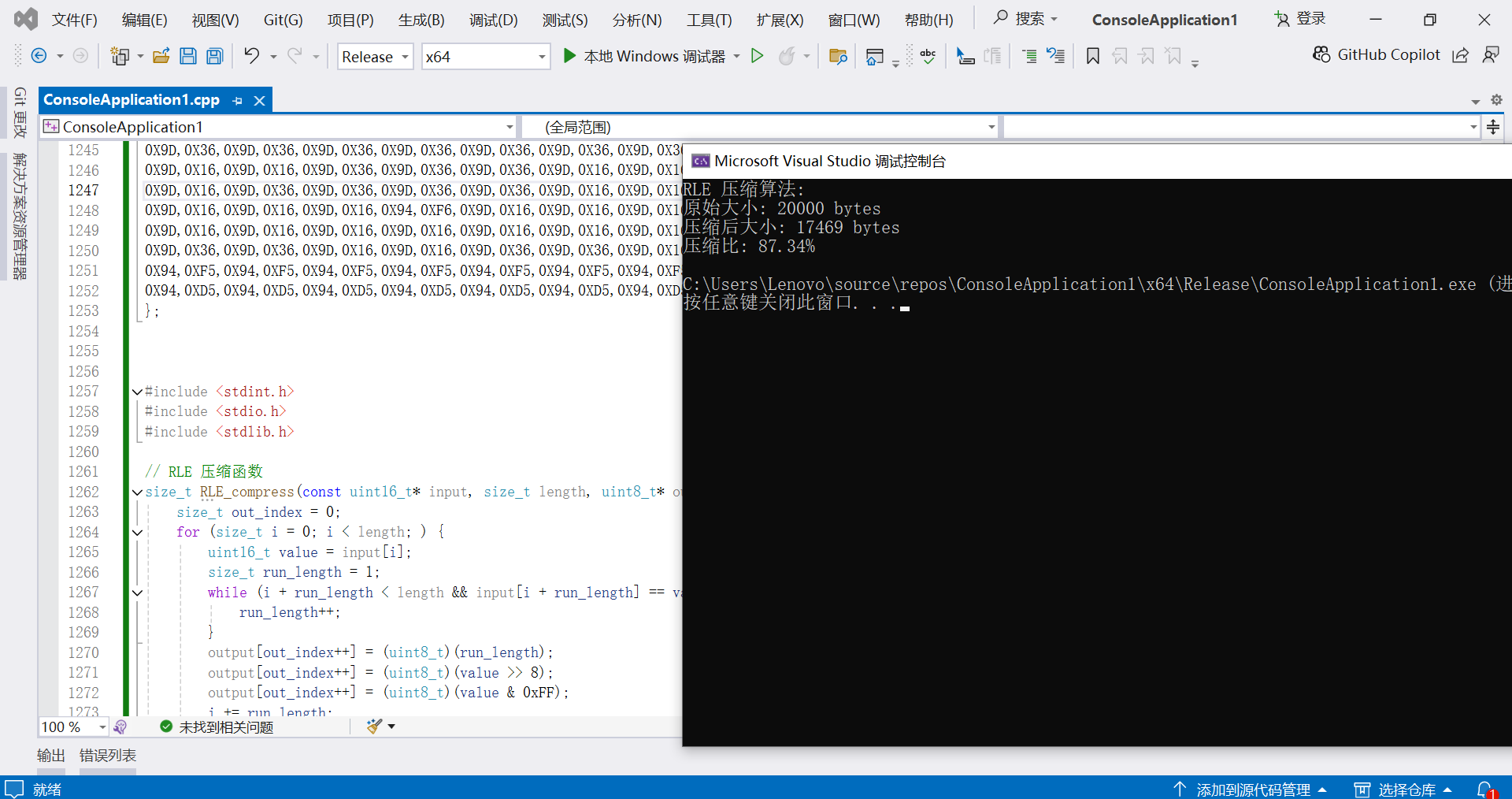
printf("RLE 压缩算法:\n");
printf("原始大小: %zu bytes\n", length * 2);
printf("压缩后大小: %zu bytes\n", rle_compressed_length);
printf("压缩比: %.2f%%\n", (double)rle_compressed_length / (length * 2) * 100);
// 释放内存
free(rle_compressed);
free(rle_decompressed);
return 0;
}
运行效果如下:
四、哈夫曼编码实现压缩和解压
哈夫曼编码是一种常用的无损压缩算法,通过构建哈夫曼树,根据字符频率生成最优编码,从而实现数据压缩。
4.1 哈夫曼编码压缩自定义数据与还原
下面代码使用哈夫曼编码对一段自定义数据进行压缩和解压,并打印压缩前后的大小和压缩率,验证压缩效果。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 定义树节点结构
typedef struct Node {
unsigned char ch;
unsigned int freq;
struct Node* left, * right;
} Node;
// 优先队列
typedef struct {
Node** nodes;
int size;
int capacity;
} PriorityQueue;
PriorityQueue* createPriorityQueue(int capacity) {
PriorityQueue* pq = (PriorityQueue*)malloc(sizeof(PriorityQueue));
pq->nodes = (Node**)malloc(capacity * sizeof(Node*));
pq->size = 0;
pq->capacity = capacity;
return pq;
}
void swapNodes(Node** a, Node** b) {
Node* t = *a;
*a = *b;
*b = t;
}
void heapify(PriorityQueue* pq, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < pq->size && pq->nodes[left]->freq < pq->nodes[smallest]->freq) {
smallest = left;
}
if (right < pq->size && pq->nodes[right]->freq < pq->nodes[smallest]->freq) {
smallest = right;
}
if (smallest != idx) {
swapNodes(&pq->nodes[smallest], &pq->nodes[idx]);
heapify(pq, smallest);
}
}
Node* extractMin(PriorityQueue* pq) {
Node* temp = pq->nodes[0];
pq->nodes[0] = pq->nodes[pq->size - 1];
pq->size--;
heapify(pq, 0);
return temp;
}
void insertPriorityQueue(PriorityQueue* pq, Node* node) {
pq->size++;
int i = pq->size - 1;
while (i && node->freq < pq->nodes[(i - 1) / 2]->freq) {
pq->nodes[i] = pq->nodes[(i - 1) / 2];
i = (i - 1) / 2;
}
pq->nodes[i] = node;
}
int isLeaf(Node* node) {
return !(node->left) && !(node->right);
}
PriorityQueue* buildPriorityQueue(unsigned char data[], int freq[], int size) {
PriorityQueue* pq = createPriorityQueue(size);
for (int i = 0; i < size; ++i) {
if (freq[data[i]] > 0) {
Node* node = (Node*)malloc(sizeof(Node));
node->ch = data[i];
node->freq = freq[data[i]];
node->left = node->right = NULL;
pq->nodes[pq->size++] = node;
}
}
for (int i = (pq->size - 1) / 2; i >= 0; --i) {
heapify(pq, i);
}
return pq;
}
Node* buildHuffmanTree(unsigned char data[], int freq[], int size) {
Node* left, * right, * top;
PriorityQueue* pq = buildPriorityQueue(data, freq, size);
while (pq->size != 1) {
left = extractMin(pq);
right = extractMin(pq);
top = (Node*)malloc(sizeof(Node));
top->ch = '\0';
top->freq = left->freq + right->freq;
top->left = left;
top->right = right;
insertPriorityQueue(pq, top);
}
return extractMin(pq);
}
void printCodes(Node* root, int arr[], int top, char** huffmanCodes) {
if (root->left) {
arr[top] = 0;
printCodes(root->left, arr, top + 1, huffmanCodes);
}
if (root->right) {
arr[top] = 1;
printCodes(root->right, arr, top + 1, huffmanCodes);
}
if (isLeaf(root)) {
huffmanCodes[root->ch] = (char*)malloc(top + 1);
for (int i = 0; i < top; ++i) {
huffmanCodes[root->ch][i] = '0' + arr[i];
}
huffmanCodes[root->ch][top] = '\0';
}
}
char** buildHuffmanCodes(unsigned char data[], int freq[], int size) {
Node* root = buildHuffmanTree(data, freq, size);
int arr[100], top = 0;
char** huffmanCodes = (char**)malloc(256 * sizeof(char*));
for (int i = 0; i < 256; ++i) {
huffmanCodes[i] = NULL;
}
printCodes(root, arr, top, huffmanCodes);
return huffmanCodes;
}
void compress(unsigned char data[], int dataSize, char** huffmanCodes, unsigned char** compressedData, int* compressedSize) {
int bitCount = 0;
for (int i = 0; i < dataSize; ++i) {
bitCount += strlen(huffmanCodes[data[i]]);
}
*compressedSize = (bitCount + 7) / 8;
*compressedData = (unsigned char*)malloc(*compressedSize);
memset(*compressedData, 0, *compressedSize);
int byteIndex = 0, bitIndex = 0;
for (int i = 0; i < dataSize; ++i) {
char* code = huffmanCodes[data[i]];
for (int j = 0; code[j] != '\0'; ++j) {
if (code[j] == '1') {
(*compressedData)[byteIndex] |= (1 << (7 - bitIndex));
}
bitIndex++;
if (bitIndex == 8) {
bitIndex = 0;
byteIndex++;
}
}
}
}
void decompress(unsigned char* compressedData, int compressedSize, Node* root, unsigned char** decompressedData, int dataSize) {
*decompressedData = (unsigned char*)malloc(dataSize + 1);
Node* current = root;
int byteIndex = 0, bitIndex = 0;
for (int i = 0; i < dataSize; ++i) {
while (!isLeaf(current)) {
if (compressedData[byteIndex] & (1 << (7 - bitIndex))) {
current = current->right;
}
else {
current = current->left;
}
bitIndex++;
if (bitIndex == 8) {
bitIndex = 0;
byteIndex++;
}
}
(*decompressedData)[i] = current->ch;
current = root;
}
(*decompressedData)[dataSize] = '\0';
}
int main() {
// 自定义数据
unsigned char data[] = "我是DS小龙哥 我正在测试这一段数据,看看能不能压缩成功";
int dataSize = strlen((char*)data);
// 计算频率
int freq[256] = { 0 };
for (int i = 0; i < dataSize; ++i) {
freq[data[i]]++;
}
// 构建哈夫曼编码
char** huffmanCodes = buildHuffmanCodes(data, freq, 256);
// 压缩
unsigned char* compressedData;
int compressedSize;
compress(data, dataSize, huffmanCodes, &compressedData, &compressedSize);
// 解压
unsigned char* decompressedData;
Node* root = buildHuffmanTree(data, freq, 256);
decompress(compressedData, compressedSize, root, &decompressedData, dataSize);
// 打印压缩前后的大小和压缩率
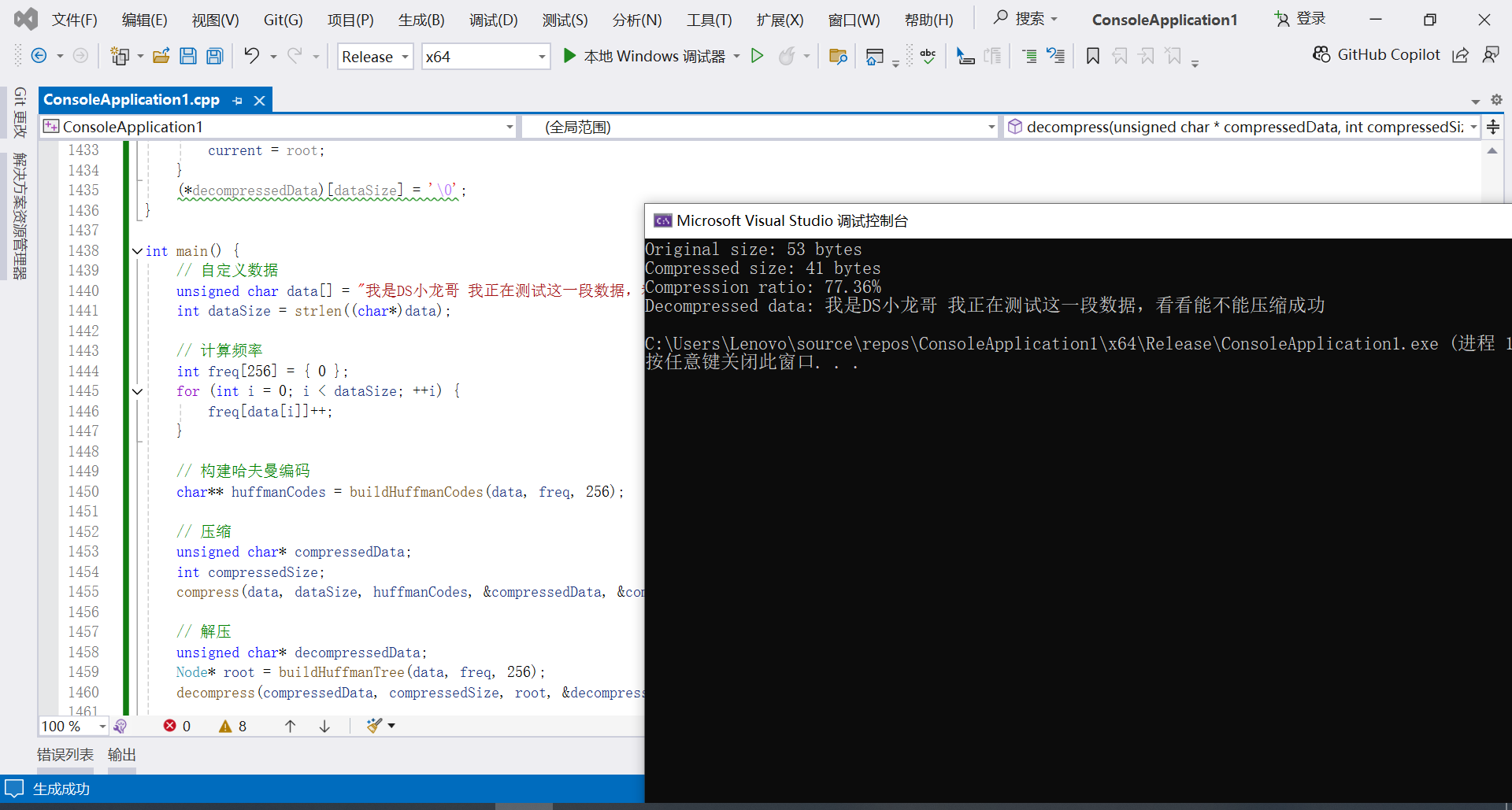
printf("Original size: %d bytes\n", dataSize);
printf("Compressed size: %d bytes\n", compressedSize);
printf("Compression ratio: %.2f%%\n", (double)compressedSize / dataSize * 100);
// 验证解压结果
printf("Decompressed data: %s\n", decompressedData);
// 释放内存
free(compressedData);
free(decompressedData);
for (int i = 0; i < 256; ++i) {
if (huffmanCodes[i]) {
free(huffmanCodes[i]);
}
}
free(huffmanCodes);
return 0;
}
测试效果:
4.2 哈夫曼编码压缩完成图像的压缩和还原
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 定义树节点结构
typedef struct Node {
unsigned short ch; // 使用 unsigned short 表示 RGB565 数据
unsigned int freq;
struct Node* left, * right;
} Node;
// 优先队列
typedef struct {
Node** nodes;
int size;
int capacity;
} PriorityQueue;
PriorityQueue* createPriorityQueue(int capacity) {
PriorityQueue* pq = (PriorityQueue*)malloc(sizeof(PriorityQueue));
pq->nodes = (Node**)malloc(capacity * sizeof(Node*));
pq->size = 0;
pq->capacity = capacity;
return pq;
}
void swapNodes(Node** a, Node** b) {
Node* t = *a;
*a = *b;
*b = t;
}
void heapify(PriorityQueue* pq, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < pq->size && pq->nodes[left]->freq < pq->nodes[smallest]->freq) {
smallest = left;
}
if (right < pq->size && pq->nodes[right]->freq < pq->nodes[smallest]->freq) {
smallest = right;
}
if (smallest != idx) {
swapNodes(&pq->nodes[smallest], &pq->nodes[idx]);
heapify(pq, smallest);
}
}
Node* extractMin(PriorityQueue* pq) {
Node* temp = pq->nodes[0];
pq->nodes[0] = pq->nodes[pq->size - 1];
pq->size--;
heapify(pq, 0);
return temp;
}
void insertPriorityQueue(PriorityQueue* pq, Node* node) {
pq->size++;
int i = pq->size - 1;
while (i && node->freq < pq->nodes[(i - 1) / 2]->freq) {
pq->nodes[i] = pq->nodes[(i - 1) / 2];
i = (i - 1) / 2;
}
pq->nodes[i] = node;
}
int isLeaf(Node* node) {
return !(node->left) && !(node->right);
}
PriorityQueue* buildPriorityQueue(unsigned short data[], int freq[], int size) {
PriorityQueue* pq = createPriorityQueue(size);
for (int i = 0; i < size; ++i) {
if (freq[data[i]] > 0) {
Node* node = (Node*)malloc(sizeof(Node));
node->ch = data[i];
node->freq = freq[data[i]];
node->left = node->right = NULL;
pq->nodes[pq->size++] = node;
}
}
for (int i = (pq->size - 1) / 2; i >= 0; --i) {
heapify(pq, i);
}
return pq;
}
Node* buildHuffmanTree(unsigned short data[], int freq[], int size) {
Node* left, * right, * top;
PriorityQueue* pq = buildPriorityQueue(data, freq, size);
while (pq->size != 1) {
left = extractMin(pq);
right = extractMin(pq);
top = (Node*)malloc(sizeof(Node));
top->ch = 0;
top->freq = left->freq + right->freq;
top->left = left;
top->right = right;
insertPriorityQueue(pq, top);
}
return extractMin(pq);
}
void printCodes(Node* root, int arr[], int top, char** huffmanCodes) {
if (root->left) {
arr[top] = 0;
printCodes(root->left, arr, top + 1, huffmanCodes);
}
if (root->right) {
arr[top] = 1;
printCodes(root->right, arr, top + 1, huffmanCodes);
}
if (isLeaf(root)) {
huffmanCodes[root->ch] = (char*)malloc(top + 1);
for (int i = 0; i < top; ++i) {
huffmanCodes[root->ch][i] = '0' + arr[i];
}
huffmanCodes[root->ch][top] = '\0';
}
}
char** buildHuffmanCodes(unsigned short data[], int freq[], int size) {
Node* root = buildHuffmanTree(data, freq, size);
int arr[100], top = 0;
char** huffmanCodes = (char**)malloc(65536 * sizeof(char*)); // 65536 表示所有可能的 RGB565 值
for (int i = 0; i < 65536; ++i) {
huffmanCodes[i] = NULL;
}
printCodes(root, arr, top, huffmanCodes);
return huffmanCodes;
}
void compress(unsigned short data[], int dataSize, char** huffmanCodes, unsigned char** compressedData, int* compressedSize) {
int bitCount = 0;
for (int i = 0; i < dataSize; ++i) {
bitCount += strlen(huffmanCodes[data[i]]);
}
*compressedSize = (bitCount + 7) / 8;
*compressedData = (unsigned char*)malloc(*compressedSize);
memset(*compressedData, 0, *compressedSize);
int byteIndex = 0, bitIndex = 0;
for (int i = 0; i < dataSize; ++i) {
char* code = huffmanCodes[data[i]];
for (int j = 0; code[j] != '\0'; ++j) {
if (code[j] == '1') {
(*compressedData)[byteIndex] |= (1 << (7 - bitIndex));
}
bitIndex++;
if (bitIndex == 8) {
bitIndex = 0;
byteIndex++;
}
}
}
}
void decompress(unsigned char* compressedData, int compressedSize, Node* root, unsigned short** decompressedData, int dataSize) {
*decompressedData = (unsigned short*)malloc(dataSize * sizeof(unsigned short));
Node* current = root;
int byteIndex = 0, bitIndex = 0;
for (int i = 0; i < dataSize; ++i) {
while (!isLeaf(current)) {
if (compressedData[byteIndex] & (1 << (7 - bitIndex))) {
current = current->right;
}
else {
current = current->left;
}
bitIndex++;
if (bitIndex == 8) {
bitIndex = 0;
byteIndex++;
}
}
(*decompressedData)[i] = current->ch;
current = root;
}
}
int main() {
int dataSize = sizeof(gImage_rgb565_100x100) / 2;
unsigned short* data = (unsigned short*)gImage_rgb565_100x100;
// 计算频率
int freq[65536] = { 0 };
for (int i = 0; i < dataSize; ++i) {
freq[data[i]]++;
}
// 构建哈夫曼编码
char** huffmanCodes = buildHuffmanCodes(data, freq, 65536);
// 压缩
unsigned char* compressedData;
int compressedSize;
compress(data, dataSize, huffmanCodes, &compressedData, &compressedSize);
// 解压
unsigned short* decompressedData;
Node* root = buildHuffmanTree(data, freq, 65536);
decompress(compressedData, compressedSize, root, &decompressedData, dataSize);
// 打印压缩前后的大小和压缩率
printf("Original size: %d bytes\n", dataSize * 2);
printf("Compressed size: %d bytes\n", compressedSize);
printf("Compression ratio: %.2f%%\n", ((double)compressedSize / (dataSize * 2)) * 100);
// 验证解压结果(仅在开发时使用)
for (int i = 0; i < dataSize; ++i) {
if (data[i] != decompressedData[i]) {
printf("Error: Decompressed data does not match original data at index %d.\n", i);
break;
}
}
// 释放内存
free(compressedData);
free(decompressedData);
for (int i = 0; i < 65536; ++i) {
if (huffmanCodes[i]) {
free(huffmanCodes[i]);
}
}
free(huffmanCodes);
return 0;
}



















