关于java应用的监控本系列有文章如下:
【运维监控】influxdb 2.0+telegraf 监控tomcat 8.5运行情况
【运维监控】influxdb 2.0+grafana 监控java 虚拟机以及方法耗时情况
【运维监控】Prometheus+grafana监控tomcat运行情况
【运维监控】Prometheus+grafana监控spring boot 3运行情况
- 本示例是通过java的代理运行java应用,同时将java虚拟机运行的数据以及应用对应的方法耗时信息数据存储到influxdb中。
- 本示例使用到的Java应用需要读者自行创建,通过influxdb的客户端收集java应用的虚拟机、方法耗时则由github上提供的开源jar完成。
- 本示例使用的grafana模板同样由grafana对应的开源模板提供。
- 本示例分为四个部分,即部署influxdb、创建java应用及配置、部署grafana和集成。
- 本示例的influxdb和grafana都部署在server2上,实际上你的环境可能不是这样部署的,同时java应用的部署服务器则可随意指定的,故没有说明。
该文章太长,故分成2个部分
【运维监控】influxdb 2.0+grafana 监控java 虚拟机以及方法耗时情况(1)
【运维监控】influxdb 2.0+grafana 监控java 虚拟机以及方法耗时情况(2)
【运维监控】influxdb 2.0+grafana 监控java 虚拟机以及方法耗时情况(完整版)
一、部署influxdb
1、下载
下载地址:https://docs.influxdata.com/influxdb/v2/install/?t=Linux#manually-download-and-install-the-influxd-binary
下载版本:influxdb2-2.7.10_linux_amd64.tar.gz
2、解压
[alanchan@server2 influxdb2-2.7.10]$ tar -zxvf ./influxdb2-2.7.10_linux_amd64.tar.gz
[alanchan@server2 influxdb2-2.7.10]$ cd /usr/local/bigdata/influxdb2-2.7.10
[alanchan@server2 influxdb2-2.7.10]$ ll
total 8
drwxr-xr-x 3 alanchan root 4096 Aug 16 20:25 etc
drwxr-xr-x 5 alanchan root 4096 Aug 16 20:25 usr
[alanchan@server2 local]$ cd /usr/local/bigdata/influxdb2-2.7.10/usr/bin
[alanchan@server2 bin]$ ll
total 117040
-rwxr-xr-x 1 alanchan root 119847176 Aug 16 20:26 influxd
3、启动
[alanchan@server2 bin]$ nohup ./influxd
4、验证
验证方式可以查看进程也可以通过浏览器进行,本示例介绍的是浏览器,也即通过web UI的方式。
在浏览器输入地址:http://server2:8086/
展示出如下图,则说明部署及启动成功。

5、配置influxdb
在上面启动成功后,则接下来需要进行influxdb的初始化配置,包含用户名、密码、org name、bucket。根据自己的需要填写相应的内容即可,该处的内容后在后面集成grafana的时候有用。

作者填写后的内容如下图所示。

填写完成后点击continue按钮,则进入下图所示页面。
- 特别提醒,下图中所示的token非常有用,在与grafana集成的时候要用到。当然,后面也可以进行二次生成,但意义已经不同,建议此处将其保存下来。
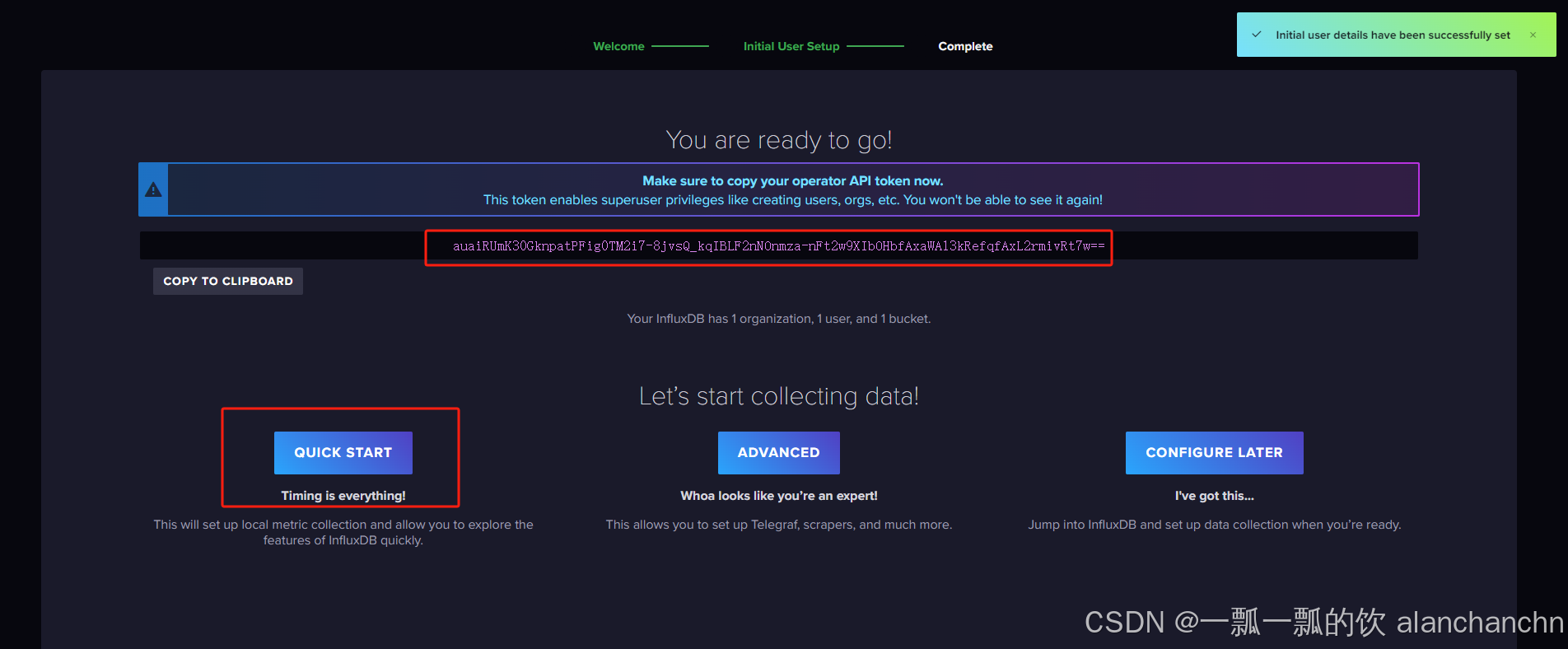
auaiRUmK30GknpatPFig0TM2i7-8jvsQ_kqIBLF2nNOnmza-nFt2w9XIbOHbfAxaWA13kRefqfAxL2rmivRt7w==
然后点击快速开始,进入下面页面,可以看到数据探索,已经可以看到我们初始化的bucket了。

6、简单试用
选择init_bucket,选择相应的字段,然后提交查看数据即可。

选择Dashboard,查看influxdb默认的dashboard,图示如下。

至此,已经完成了influxdb的部署及简单验证。
二、创建java应用及配置
本处使用的是一个简单java应用(为了验证其监控情况,建议使用较为复杂一点的应用以便观察效果,作者使用的是一个网络爬虫应用),然后通过github上的一个开源监控程序进行收集java虚拟机以及方法耗时信息。
1、创建java应用
此处使用的是非spring boot,一般普通的java应用即可。此处略。
通过maven打包成jar包,本示例的名称是spider-baidu.jar 。
2、下载MyPerf4J
下载地址:https://github.com/LinShunKang/MyPerf4J
下载版本:MyPerf4J-ASM-3.4.0-SNAPSHOT.jar
3、修改监控配置
修改配置前,需要先在influxdb中创建名称为MyPerf4J的bucket。由于本示例展示的是将收集的信息直接存储influxdb,所以日志相关的内容可以不配置。
# MyPerf4J 所有配置请参考:https://github.com/LinShunKang/MyPerf4J/wiki/%E9%85%8D%E7%BD%AE
# 配置监控应用的名称
app_name = spider-baidu-jar-with-dependencies
debug = false
###############################################################################
# Metrics Configuration #
###############################################################################
# 配置 MetricsExporter 类型,任选其一
# log.stdout: 以标准格式化结构输出到 stdout.log
# log.standard: 以标准格式化结构输出到磁盘
# log.influxdb: 以 InfluxDB LineProtocol 格式输出到磁盘
# http.influxdb: 以 InfluxDB LineProtocol 格式发送至 InfluxDB server,需要另行增加 influxdb 的配置
metrics.exporter = http.influxdb
###############################################################################
# InfluxDB Configuration #
###############################################################################
# 需要提前在influxdb 2.0中创建好database(bucket),该应用程序会直接将metrics的数据写入influxdb2.0中,不需要额外的telegraf
# 启动应用,具体启动参考readme中的说明
influxdb.version = 2.7.10
influxdb.host = server2
influxdb.port = 8086
influxdb.orgName = alanchan_win
influxdb.database = MyPerf4J
influxdb.username = alanchanchn
influxdb.password = xxxxx
# 1、如果需要在grafana中展示dashboard,需要提前在grafana中创建好influx的数据源。可以验证是否将数据写入了influxdb中
# 2、先在grafana中导入dashboard,其中对应的id分别是15672(method)和15671(jvm)
#
# 配置各项监控指标日志的文件路径
# 如果 metrics.exporter 配置为 log.influxdb,建议把所有的 metrics.log.* 路径配置成一样以方便 Telegraf 收集
metrics.log.method = D:/app//logs/metrics.log
metrics.log.class_loading = D:/app//logs/metrics.log
metrics.log.gc = D:/app//logs/metrics.log
metrics.log.memory = D:/app//logs/metrics.log
metrics.log.buff_pool = D:/app//logs/metrics.log
metrics.log.thread = D:/app//logs/metrics.log
metrics.log.file_desc = D:/app//logs/metrics.log
metrics.log.compilation = D:/app//logs/metrics.log
###############################################################################
# Filter Configuration #
###############################################################################
# 配置需要监控的package,可配置多个,用英文';'分隔
# com.demo.p1 代表包含以 com.demo.p1 为前缀的所有包和类
# [] 表示集合的概念:例如,com.demo.[p1,p2,p3] 代表包含以 com.demo.p1、com.demo.p2 和 com.demo.p3 为前缀的所有包和类,等价于 com.demo.p1;com.demo.p2;com.demo.p3
# * 表示通配符:可以指代零个或多个字符,例如,com.*.demo.*
filter.packages.include = org.spider;
# 配置不需要监控的package,可配置多个,用英文';'分隔
filter.packages.exclude = com;bsh;dev;io;javax;junit;junit3.8.1;net;netscape;
4、运行应用
运行环境不管是windows还是linux都可以,本示例的运行环境JDK是17,所以需要增加–add-opens java.base/java.lang=ALL-UNNAMED,完整的运行命令如下。
java -javaagent:MyPerf4J-ASM-3.4.0-SNAPSHOT.jar -DMyPerf4JPropFile=MyPerf4J.properties --add-opens java.base/java.lang=ALL-UNNAMED -jar spider-baidu.jar
5、验证
验证方式有2个方面,一个是验证应用的功能 是否正确;一个是验证是否将java虚拟机和方法耗时是否写入了influxdb中。此处仅仅验证是否将数据写入了influxdb中。

通过上图可以看到,influxdb已经可以正常的收集到应用的运行数据了。
三、部署grafana
1、部署
1)、下载
下载地址:https://grafana.com/grafana/dashboards/?search=influx&page=6
下载版本:https://dl.grafana.com/oss/release/grafana-11.1.4.linux-amd64.tar.gz
2)、解压
tar -zxvf grafana-11.1.4.linux-amd64.tar.gz
cd /usr/local/bigdata/grafana-v11.1.4/bin
3)、启动
启动命令可以是下面2种。
grafana-server start
或,推荐如下
grafana server start
[alanchan@server2 bin]$ grafana-server status
Deprecation warning: The standalone 'grafana-server' program is deprecated and will be removed in the future. Please update all uses of 'grafana-server' to 'grafana server'
INFO [08-28|00:55:36] Starting Grafana logger=settings version=11.1.4 commit=2355de00c61fdd6609a67f35ab506fae87f09a84 branch=HEAD compiled=2024-08-28T00:55:36Z
INFO [08-28|00:55:36] Config loaded from logger=settings file=/usr/local/bigdata/grafana-v11.1.4/conf/defaults.ini
INFO [08-28|00:55:36] Target logger=settings target=[all]
INFO [08-28|00:55:36] Path Home logger=settings path=/usr/local/bigdata/grafana-v11.1.4
INFO [08-28|00:55:36] Path Data logger=settings path=/usr/local/bigdata/grafana-v11.1.4/data
INFO [08-28|00:55:36] Path Logs logger=settings path=/usr/local/bigdata/grafana-v11.1.4/data/log
INFO [08-28|00:55:36] Path Plugins logger=settings path=/usr/local/bigdata/grafana-v11.1.4/data/plugins
INFO [08-28|00:55:36] Path Provisioning logger=settings path=/usr/local/bigdata/grafana-v11.1.4/conf/provisioning
INFO [08-28|00:55:36] App mode production logger=settings
2、验证
验证方式可以查看进程也可以通过浏览器进行,本示例介绍的是浏览器,也即通过web UI的方式。
在浏览器输入地址:http://server2:3000/login
展示出如下图,则说明部署及启动成功。
默认密码admin/admin,修改后admin/xxxxxx

登录进去后,如下图所示。

以上,则完成了grafana的部署。
四、grafana集成influxdb监控java 虚拟机以及方法耗时情况
1、添加grafana数据源
选择influxdb数据源,如下图所示。

在下图所示的页面,点击添加数据源按钮。

点击后进入下面页面中,针对红框内填写必要的信息

其中查询语言本示例选择的Flux(其中的区别参考官网,不同的类别下面需要填写的信息不同)
填写完成后,示例如下。

完成上图所示的信息后,继续往下填写,进行授权,如下图所示。

保存成功的图示如下。

至此,grafana集成influxdb的工作完成,集成后,Organization名称为alanchan_win的所有bucket都可以在grafana的数据探索中查到数据。示例如下图。

2、添加grafana的dashboard
1)、选择新建dashboard方式
在grafana的web ui页面中选择dashborad的菜单栏,如下图所示。

上图按钮提供三个功能,即创建目录、新建dashboard和导入dashboard。新建目录就是将不同的dashboard归类,新建dashboard页面如下图所示。下图中的import dashboard与该按钮下的import是一个功能。

提供三种功能,即自己创建可视化dashboard、导入panel和导入dashboard。本示例介绍的是导入dashboard。
2)、导入dashboard
导入dashboard需要以下几步:
- 1、在链接中选择需要的模板
- 2、选择导入模板的方式,本示例选择复制模板ID方式
- 3、加载模板ID后进行相应的配置
- 4、配置完成后,进行模板最后的Load
下面就按照上述的步骤进行操作示例。
点击import a dashboard按钮,进入下面页面。

在上图中第一个红色框内的链接(https://grafana.com/grafana/dashboards/)提供开源模板,供使用者自行选择需要的内容,本示例选择的是“MyPerf4J-InfluxDBv2.x-JVM”和“MyPerf4J-InfluxDBv2.x-Method”,ID分别是15671和15672。可以选择复制ID或自己下载json,在上图中上传json。本示例是复制ID操作方式。

点击Load按钮后,则进入下面页面,然后选择上述创建的influxdb-demo数据源,最后导入即可。

按照上述步骤,将两个模板导入后即完成了集成。
3、验证
说明:读者新建的应用可能不会像作者有这么多数据,可能需要将应用运行一段时间后再观察。
在grafana的dashboard中查看添加的dashboard,选择刚刚添加的2个dashboard即可。

分别查看对应的dashboard,点击MyPerf4J-InfluxDBv2.x-JVM对应的dashboard,则展示如下页面(便于查看,被作者折叠了)。

不折叠的情况如下页面。

点击MyPerf4J-InfluxDBv2.x-Method对应的dashboard,则展示如下页面。

将鼠标焦点放在具体的图上,则会显示应用对应的方法耗时,如下图所示。

以上,则完成了集成。