文章目录
- 1、 Kafka 基础API
- 1_Topic基本操作 DML管理
- 2_生产者
- 3_消费者 sub/assign
- 4_自定义分区策略
- 5_序列化
- 6_拦截器
- 2、Kafka API高级特性
- 1_Offset自动控制
- 2_Acks & Retries
- 3_幂等性
- 4_事务控制
- 1、生产者事务Only
- 2、消费者&生产者事务
- 3、测试需要的三个消费者案例属性
- 3、Spring Boot集成Kafka
- 4、总结
1、 Kafka 基础API
了解基础API的使用,通过代码使用Kafka。
创建maven测试项目,引入如下依赖——最主要的是Kafka的客户端依赖:
<dependencies>
<!-- 与使用的kafka版本一致 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
</dependencies>
在resource目录下创建日志配置文件log4j.properties:
log4j.rootLogger = info,console
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = %p %d{yyyy-MM-dd HH:mm:ss} %c - %m%n
1_Topic基本操作 DML管理
bootstrap.servers:Kafka的服务器地址。
package org.example.dml;
import org.apache.kafka.clients.admin.*;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.ExecutionException;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA 3.7.0有bug
*/
public class KafkaTopicDML {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建KafkaAdminClient
Properties props = new Properties();//配置连接设置
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,
"SHENYANG:9092");//运行时注意必须配置当前主机的`hosts`文件IP映射。
KafkaAdminClient adminClient = (KafkaAdminClient) KafkaAdminClient.create(props);
//删除Topic
// removeTopic(adminClient);
//创建Topic信息
createTopicSync(adminClient);
//查看topic列表
findListTopic(adminClient);
//查看topic的详细信息
findTopicInfo(adminClient);
//关闭
adminClient.close();
}
private static void removeTopic(KafkaAdminClient adminClient) throws InterruptedException, ExecutionException {
DeleteTopicsResult result = adminClient.deleteTopics(Arrays.asList("topic01"));
result.all().get();
}
private static void findTopicInfo(KafkaAdminClient adminClient) throws InterruptedException, ExecutionException {
System.out.println("=========================");
DescribeTopicsResult dtr = adminClient.describeTopics(Arrays.asList("topic01"));
Map<String, TopicDescription> topicDescriptionMap = dtr.all().get();
for (Map.Entry<String, TopicDescription> entry : topicDescriptionMap.entrySet()) {
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
System.out.println("===================");
System.out.println(dtr.allTopicNames() + "\t" + dtr.topicIdValues());
}
private static void findListTopic(KafkaAdminClient adminClient) throws InterruptedException, ExecutionException {
ListTopicsResult listTopicsResult = adminClient.listTopics();
Set<String> names = listTopicsResult.names().get();
for (String name : names) {
System.out.println(name);
}
}
private static void createTopicSync(KafkaAdminClient adminClient) throws InterruptedException, ExecutionException {
CreateTopicsResult result = adminClient.createTopics(Arrays.asList(new NewTopic("topic01", 3, (short) 1)));
result.all().get();//同步
}
}
2_生产者
- 创建连接
- bootstrap.servers:Kafka的服务器地址
- acks:表示当生产者生产数据到Kafka中,Kafka中会以什么样的策略返回
- key.serializer:Kafka中的消息是以key、value键值对存储的,而且生产者生产的消息是需要在网络上传到的,这里指定的是StringSerializer方式,就是以字符串方式发送(将来还可以使用其他的一些序列化框架:Google ProtoBuf、Avro)
- value.serializer:同上
- 创建一个生产者对象KafkaProducer
- 调用send方法发送消息(ProducerRecor,封装是key-value键值对)
- 调用Future.get表示等带服务端的响应
- 关闭生产者
package org.example.quickstart;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
* @since 2024/9/2 21:33
*/
public class KafkaProducerQuickStart {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"SHENYANG:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record =
//指定key策略是hash 不指定就是轮询
// new ProducerRecord<>("topic01", "key" + i, "value" + i);
new ProducerRecord<>("topic01", "value" + i);
//发送消息给服务器
producer.send(record);
}
producer.close();
}
}
3_消费者 sub/assign
- group.id:消费者组的概念,可以在一个消费组中包含多个消费者。如果若干个消费者的group.id是一样的,表示它们就在一个组中,一个组中的消费者是共同消费Kafka中topic的数据。
- Kafka是一种拉消息模式的消息队列,在消费者中会有一个offset,表示从哪条消息开始拉取数据
- kafkaConsumer.poll:Kafka的消费者API是一批一批数据的拉取
将下列消费者开启多份实例,生产者不指定key时默认将采取轮询的方式发送数据——新版本可能不同,不再使用默认分区策略,或者说老版本默认的分区策略在较新的版本中被废弃。

查看在同一消费者组下的多份实例之间是如何分配分区的——以及将某个消费实例下线,看看是不是该实例的分区会交给其他实例负责。
package org.example.quickstart;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
import java.util.regex.Pattern;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerQuickStart {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");//此时必须指定消费组
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
// consumer.subscribe(Pattern.compile("^topic.*"));
consumer.subscribe(Arrays.asList("topic01"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
手动指定消费分区和偏移量(去掉消费者组):
package org.example.quickstart;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
import java.util.regex.Pattern;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerQuickStart_1 {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic 手动指定消费分区,失去组管理的特性
List<TopicPartition> partitions = Arrays.asList(new TopicPartition("topic01", 0));
consumer.assign(partitions);
//指定消费分区位置 从0开始消费
// consumer.seekToBeginning(partitions);
//指定偏移量消费位置
consumer.seek(new TopicPartition("topic01", 0),0);
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
if (false) {
break;
}
}
consumer.close();
}
}
4_自定义分区策略
Determines which partition to send a record to when records are produced. Available options are:
- If not set, the default partitioning logic is used. This strategy send records to a partition until at least BATCH_SIZE_CONFIG bytes is produced to the partition. It works with the strategy:
- If no partition is specified but a key is present, choose a partition based on a hash of the key.
- If no partition or key is present, choose the sticky partition that changes when at least BATCH_SIZE_CONFIG bytes are produced to the partition.
org.apache.kafka.clients.producer.RoundRobinPartitioner: A partitioning strategy where each record in a series of consecutive records is sent to a different partition, regardless of whether the ‘key’ is provided or not, until partitions run out and the process starts over again. Note: There’s a known issue that will cause uneven distribution when a new batch is created. See KAFKA-9965 for more detail.
Implementing the org.apache.kafka.clients.producer.Partitioner interface allows you to plug in a custom partitioner.
原文的意思就是,如果没有特别指定分区策略,Kafka 生产者将使用默认的分区逻辑。这一策略的工作方式如下:
- 按批量大小分区:生产者将记录发送到某个分区,直到该分区中产生至少 BATCH_SIZE_CONFIG 字节的数据。这样可以提高数据的写入效率,减少网络往返时间——达到了这个大小会主动 flush 数据。
- 按键进行分区:如果记录包含键(key),则生产者根据键的哈希值来选择分区。这确保了相同键的记录总是被发送到同一个分区,便于顺序消费。
- 粘性分区(Sticky Partitioning):如果没有指定分区且没有提供键,生产者会选择一个粘性分区,只有在分区中的数据达到 BATCH_SIZE_CONFIG 字节时才会更换分区。这种方式可以在一定程度上保证记录的顺序性。
RoundRobinPartitioner:这是一个Kafka实现的自定义的分区策略,其中每条记录依次被发送到不同的分区,不论记录是否有键(key)。
- 轮询分区:记录会依次发送到每个分区,直到所有分区都被使用一次,然后重新开始循环。这有助于在负载均衡时尽可能均匀地分配数据到各个分区。
- 已知问题:在某些情况下,当新的批次(batch)创建时,这种策略可能会导致数据分布不均。
Kafka 允许你实现 org.apache.kafka.clients.producer.Partitioner 接口来创建自己的分区策略。
我们将仿照 RoundRobinPartitioner实现 Partitioner 接口编写自己的分区策略,如下:
package org.example.partitioner;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.clients.producer.internals.DefaultPartitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import javax.rmi.CORBA.Util;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class UserDefinePartition implements Partitioner {
private AtomicInteger counter = null;
/**
* @return 分区号
*/
@Override
public int partition(String topic,
Object key,
byte[] keyBytes,//key的字节数组
Object value,
byte[] valueBytes,
Cluster cluster) {
//获取所有分区
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int numPartitions = partitionInfos.size();
//如果没有提供key 自行计数采用轮询的方式
if (keyBytes == null || keyBytes.length == 0) {
int andIncrement = counter.getAndIncrement();
//与int最大值进行与运算,直接转为正数
return (andIncrement & Integer.MAX_VALUE) % numPartitions;
} else {
//先murmur2对其hash 再进行toPositive转成正数对分区数取余
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
@Override
public void close() {
System.out.println("===close==");
}
@Override
public void configure(Map<String, ?> map) {
counter = new AtomicInteger(1);
}
}
使用时给生产者添加如下配置:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,UserDefinePartition.class.getName());
5_序列化
无论是哪种序列化方式,在网络中都是以字节的形式传输的。我们之前使用的一直是针对 String 类型的序列化和反序列化,接下来我们通过 Apache lang3 工具包对自定义对象进行序列化测试。
自定义对象,实现序列化接口:
package org.example.serializer;
import org.apache.kafka.common.serialization.Serializer;
import java.io.Serializable;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class User implements Serializable {
private Integer id;
private String name;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name=" + name +
'}';
}
public void setName(String name) {
this.name = name;
}
public User() {
}
public User(Integer id, String name) {
this.id = id;
this.name = name;
}
}
Serializer class for value | key that implements the org.apache.kafka.common.serialization.Serializer interface.
Deserializer class for value | key that implements the org.apache.kafka.common.serialization.Deserializer interface.
序列化需要实现Serializer接口,而反序列化需要实现Deserializer接口。
自定义序列化、反序列化器:
package org.example.serializer;
import org.apache.commons.lang3.SerializationUtils;
import org.apache.kafka.common.serialization.Serializer;
import java.io.Serializable;
import java.util.Map;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class ObjectDefineSerializer implements Serializer<Object> {
@Override
public byte[] serialize(String s, Object data) {
return SerializationUtils.serialize((Serializable) data);
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
System.out.println("configure");
}
@Override
public void close() {
System.out.println("close");
}
}
package org.example.serializer;
import org.apache.commons.lang3.SerializationUtils;
import org.apache.kafka.common.serialization.Deserializer;
import java.util.Map;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class ObjectDefineDeserializer implements Deserializer<Object> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
System.out.println("configure");
}
@Override
public Object deserialize(String topic, byte[] data) {
return SerializationUtils.deserialize(data);
}
@Override
public void close() {
System.out.println("close");
}
}
在生产者中指定序列化方式:
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//使用自定义的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ObjectDefineSerializer.class.getName());
在消费者中指定反序列化方式:
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//使用自定义的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ObjectDefineDeserializer.class.getName());
6_拦截器
A list of classes to use as interceptors Implementing the org.apache.kafka.clients.producer.ProducerInterceptor interface allows you to intercept (and possibly mutate) the records received by the producer before they are published to the Kafka cluster. By default, there are no interceptors.
自定义拦截器需要实现 ProducerInterceptor 接口。
拦截器主要是对生产者发出的数据拦截后进行修改操作,如下自定义拦截器对生产者发送的record value进行了添加额外后缀的操作:
package org.example.intercepters;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class UserDefineProducerInterceptor implements ProducerInterceptor {
@Override
public ProducerRecord onSend(ProducerRecord record) {
return new ProducerRecord(record.topic(),record.key(),record.value()+"----shenyang");
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("metadata:"+metadata+",exception"+exception);
}
@Override
public void close() {
System.out.println("close()");
}
@Override
public void configure(Map<String, ?> configs) {
System.out.println("configure");
}
}
在kafka生产者中添加如下属性进行配置:
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, UserDefineProducerInterceptor.class.getName());
2、Kafka API高级特性
了解高级API的使用,对kafka更一步的控制。
1_Offset自动控制
Kafka消费者默认对于未订阅的topic的offset的时候,也就是系统并没有存储该消费者的消费分区的记录信息,默认Kafka消费者的默认首次消费策略:latest。
auto.offset.reset=latest
- earliest - 自动将偏移量重置为最早的偏移量。
- latest - 自动将偏移量重置为最新的偏移量。
- none - 如果未找到消费者组的先前偏移量,则向消费者抛出异常。
Kafka消费者在消费数据的时候默认会定期的提交消费的偏移量,这样就可以保证所有的消息至少可以被消费者消费1次,用户可以通过以下两个参数配置:
enable.auto.commit = true # 默认
auto.commit.interval.ms = 5000 #默认
如果用户需要自己管理offset的自动提交,可以关闭offset的自动提交,手动管理offset提交的偏移量,注意用户提交的offset偏移量永远都要比本次消费的偏移量+1,因为提交的offset是kafka消费者下一次抓取数据的位置。
消费策略——可自行测试,无论哪种策略关闭消费者再启动后,生产者发送的数据消费者都会进行续读,AUTO_OFFSET_RESET_CONFIG仅仅是决定没有偏移量时的首次动作
与自动提交——可以在消费到数据后立马关闭消费者,再次启动看看下次消费位置,验证是否10s提交 offset:
package org.example.offset;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerOffset01 {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//latest 如果系统(消费者组)没有消费者得分偏移量,系统会读取最后的偏移量。如果有会续读
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// earliest 如果系统(消费者组)没有消费者得分偏移量,系统会读取该分区最早的偏移量。
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//配置offset自动提交 10s自动提交
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,10000);
//默认自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
//props.put(ConsumerConfig.GROUP_ID_CONFIG, "g4");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
// consumer.subscribe(Pattern.compile("^topic.*"));
consumer.subscribe(Arrays.asList("topic01"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
手动提交偏移量——关闭自动提交,并且在消费完数据后调用consumer.commitAsync方法提交偏移量:
package org.example.offset;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerOffset04 {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// earliest 如果系统(消费者组)没有消费者得分偏移量,系统会读取该分区最早的偏移量。
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//默认自动提交 配置手动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g4");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
consumer.subscribe(Arrays.asList("topic01"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
//记录分区的消费元数据信息
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
//记录消费分区偏移量的元素
offsets.put(new TopicPartition(topic,partition),new OffsetAndMetadata(offset));//offset+1
//提交消费者偏移量 因为提交的是本次读到的数据,每个分区会一直有一条数据读不完,应该提交下一次开始读取的偏移量
consumer.commitAsync(offsets, (offsets1, exception) -> System.out.println("offsets:"+ offsets1 +" exception:"+exception));
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
2_Acks & Retries
Kafka生产者在发送完一个的消息之后,要求Broker在规定的额时间Ack应答答,如果没有在规定时间内应答,Kafka生产者会尝试n次重新发送消息。
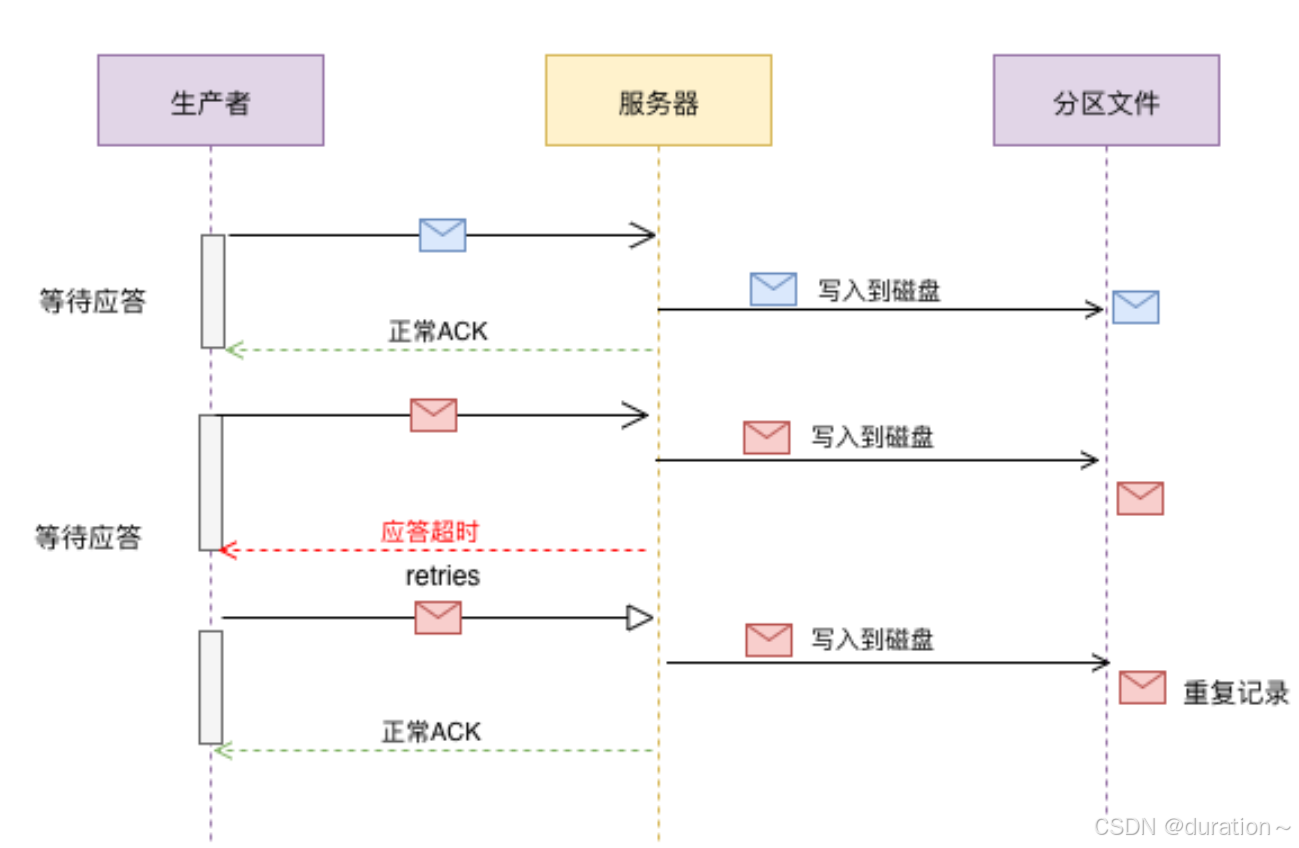
acks=1 默认
- acks=1: Leader会将Record写到其本地日志中,但会在不等待所有Follower的完全确认的情况下做出响应。在这种情况下,如果Leader在确认记录后立即失败,但在Follower复制记录之前失败,则记录将丢失。
- acks=0: 生产者根本不会等待服务器的任何确认。该记录将立即添加到套接字缓冲区中并视为已发送。在这种情况下,不能保证服务器已收到记录。
- acks=all: 这意味着Leader将等待全套同步副本确认记录。这保证了只要至少一个同步副本仍处于活动状态,记录就不会丢失。这是最有力的保证。这等效于acks = -1设置。
如果生产者在规定的时间内,并没有得到Kafka的Leader的Ack应答,Kafka可以开启reties机制。
request.timeout.ms = 30000 默认
retries = 2147483647 默认
发送一条记录,我们查看消费者将收到几条消息:
package org.example.acks;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaProducerAcks {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//关闭幂等 默认开启
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,false);
// 设置kafka ACK以及retries
props.put(ProducerConfig.ACKS_CONFIG,"all");
// 不包含第一次发送,如果尝试发送3次失败则系统放弃发送
props.put(ProducerConfig.RETRIES_CONFIG,4);
//将检测超时的时间设置为1毫秒(网络IO都不止1ms肯定会触发重试)
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,1);
//不要移动位置在配置put前,不然不生效
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record =
//指定key策略是hash 不指定就是轮询
// new ProducerRecord<>("topic01", "key" + i, "value" + i);
new ProducerRecord<>("topic02","ack", "value" + "ack");
//发送消息给服务器
producer.send(record);
producer.flush();
producer.close();
}
}
3_幂等性
当生产者发送的消息没有正确地被ack,使用重试机制发送消息时,必然会产生消息重复,为了防止数据被重复处理,消息的幂等性就需要得到保障。
HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
Kafka在0.11.0.0版本支持增加了对幂等的支持。幂等是针对生产者角度的特性。幂等可以保证上生产者发送的消息,不会丢失,而且不会重复。实现幂等的关键点就是服务端可以区分请求是否重复,过滤掉重复的请求。要区分请求是否重复的有两点:
唯一标识:要想区分请求是否重复,请求中就得有唯一标识。例如支付请求中,订单号就是唯一标识
记录下已处理过的请求标识:光有唯一标识还不够,还需要记录下那些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复记录,拒绝掉。
幂等又称为exactly once。要停止多次处理消息,必须仅将其持久化到Kafka Topic中仅仅一次。在初始化期间,kafka会给生产者生成一个唯一的ID称为Producer ID或PID。
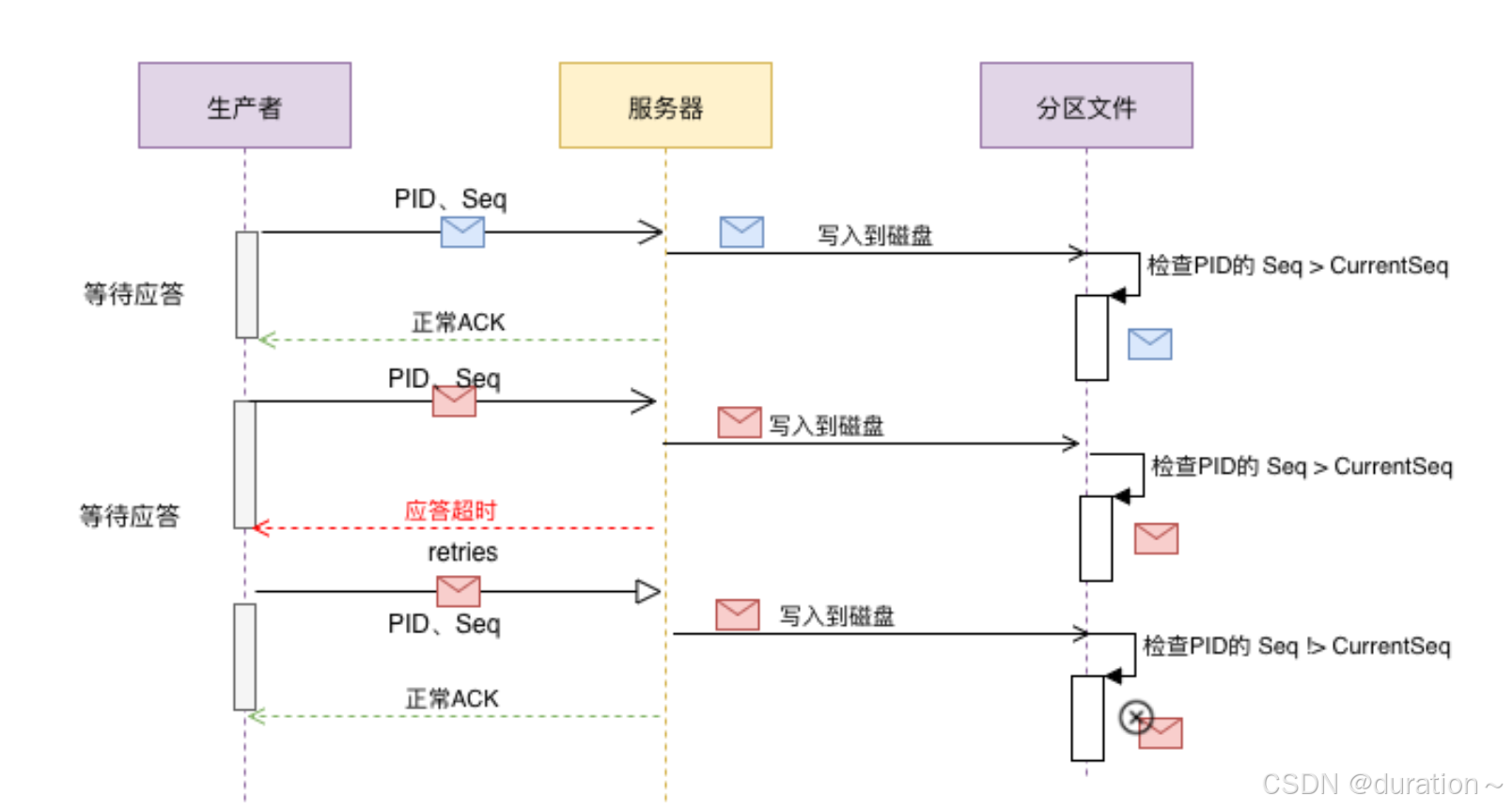
PID和sequence number(针对消息的一个递增序列)序列号与消息捆绑在一起,然后发送给Broker。由于序列号从零开始并且单调递增,因此,仅当消息的序列号比该PID / TopicPartition对中最后提交的消息正好大1时,Broker才会接受该消息。如果不是这种情况,则Broker认定是生产者重新发送该消息。
enable.idempotence= false #老版本默认
注意:在使用幂等性的时候,要求必须开启retries=true和acks=all
package org.example.idempotence;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaProducerIdempotence {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//幂等 默认开启
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);
//如果有多余1个记录没有应答阻塞客户端 默认5可能乱序
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,1);
// 设置kafka ACK以及retries
props.put(ProducerConfig.ACKS_CONFIG,"all");
// 不包含第一次发送,如果尝试发送3次失败则系统放弃发送
props.put(ProducerConfig.RETRIES_CONFIG,4);
//将检测超时的时间设置为1毫秒(网络IO都不止1ms肯定会触发重试)
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,1);
//不要移动位置在配置put前,不然不生效
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record =
//指定key策略是hash 不指定就是轮询
// new ProducerRecord<>("topic01", "key" + i, "value" + i);
new ProducerRecord<>("topic02","ack", "value" + "ack");
//发送消息给服务器
producer.send(record);
//kafka在发送数据之前会在本地做一次缓冲,flush防止缓冲
producer.flush();
producer.close();
}
}
4_事务控制
Kafka的幂等性,只能保证一条记录的在分区发送的原子性,但是如果要保证多条记录(多分区)之间的完整性,这个时候就需要开启kafk的事务操作。
在Kafka0.11.0.0除了引入的幂等性的概念,同时也引入了事务的概念。通常Kafka的事务分为 生产者事务Only、消费者&生产者事务。一般来说默认消费者消费的消息的级别是read_uncommited数据,这有可能读取到事务失败的数据,所有在开启生产者事务之后,需要用户设置消费者的事务隔离级别。
isolation.level = read_uncommitted 默认
该选项有两个值read_committed | read_uncommitted,如果开始事务控制,消费端必须将事务的隔离级别设置为read_committed。
开启的生产者事务的时候,只需要指定transactional.id属性即可,一旦开启了事务,默认生产者就已经开启了幂等性。但是要求"transactional.id"的取值必须是唯一的,同一时刻只能有一个"transactional.id"存在,其他的将会被关闭。
-
生产者
// 开启事务必须要配置事务的ID props.put("transactional.id", "dwd_user"); -
消费者
// 配置事务的隔离级别 props.put("isolation.level","read_committed"); // 关闭自动提交,一会我们需要手动来提交offset,通过事务来维护offset props.setProperty("enable.auto.commit", "false"); -
生产者
- 初始化事务
- 开启事务
- 需要使用producer来将消费者的offset提交到事务中
- 提交事务
- 如果出现异常回滚事务
如果使用了事务,不要使用异步发送
1、生产者事务Only
仅仅控制生产者的一些特性,假设有一个生产者同时发送了三条消息到三个分区,一条消息发送失败后 0,另外两个分区 1 2 也会进行回滚:
package org.example.transactions;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.UUID;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaProducerTransactionsProducerOnly {
public static void main(String[] args) {
KafkaProducer<String, String> producer = buildKafkaProducer();
//初始化事务
producer.initTransactions();
try {
//开启事务
producer.beginTransaction();
for (int i = 0; i < 10; i++) {
if(i == 8){
int j = 10/0;
}
ProducerRecord<String, String> record =
//指定key策略是hash 不指定就是轮询
// new ProducerRecord<>("topic01", "transaction" + i, "error data" + i);
new ProducerRecord<>("topic01", "right data" + i);
//发送消息给服务器
producer.send(record);
producer.flush();
}
//事务提交
producer.commitTransaction();
} catch (Exception e) {
System.err.println("出现错误~ " + e.getMessage());
//终止事务
producer.abortTransaction();
} finally {
producer.close();
}
}
public static KafkaProducer<String, String> buildKafkaProducer() {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//必须配置事务id
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction-id" + UUID.randomUUID().toString());
//配置kafka批处理大小 默认在缓存池中 大小,时间
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 1024);
//等待5ms如果batch数据不足1024
props.put(ProducerConfig.LINGER_MS_CONFIG, 5);
//配置Kafka的重试机制和幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 20000);
return new KafkaProducer<>(props);
}
}
2、消费者&生产者事务
既是消费者也是生产者,比如:消费topic01中的数据,业务处理完成后又将数据发送到topic02当中去。假设向topic02中发送数据失败了,不会成功消费掉topic01中的数据:
package org.example.transactions;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.CompletableFuture;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaProducerTransactionsProducerAndConsumer {
public static void main(String[] args) {
KafkaProducer<String, String> producer = buildKafkaProducer();
KafkaConsumer<String, String> consumer = buildKafkaConsumer("g1");
//初始化事务
producer.initTransactions();
//消费数据
consumer.subscribe(Arrays.asList("topic01"));
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
Iterator<ConsumerRecord<String, String>> consumerRecordIterator = consumerRecords.iterator();
//开启事务处理
producer.beginTransaction();
try {
//迭代数据业务处理
while(consumerRecordIterator.hasNext()){
ConsumerRecord<String, String> record = consumerRecordIterator.next();
//存储元数据
offsets.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset()+1));
ProducerRecord<String,String> pRecord = new ProducerRecord<String, String>("topic02",
record.key(),
record.value()+"shenyang online");
producer.send(pRecord);
}
//事务提交
producer.sendOffsetsToTransaction(offsets, "g1");//提交消费者得偏移量
producer.commitTransaction();
} catch (Exception e) {
System.out.println("出现错误~ " + e.getMessage());
//终止事务
producer.abortTransaction();
}
}
}
}
public static KafkaProducer<String, String> buildKafkaProducer() {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//必须配置事务id
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction-id" + UUID.randomUUID().toString());
//配置kafka批处理大小 默认在缓存池中 大小,时间
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 1024);
//等待5ms如果batch数据不足1024
props.put(ProducerConfig.LINGER_MS_CONFIG, 5);
//配置Kafka的重试机制和幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 20000);
return new KafkaProducer<>(props);
}
public static KafkaConsumer<String, String> buildKafkaConsumer(String groupId) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//设置消费者事务的隔离级别 read_un commit
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
//事务 必须关闭消费者端的自动提交(业务完成后提交)
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
return consumer;
}
}
3、测试需要的三个消费者案例属性
1:
package org.example.transactions;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerTransactionReadCommitted01 {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
//设置消费者事务的隔离级别 read_un commit
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
// consumer.subscribe(Pattern.compile("^topic.*"));
consumer.subscribe(Arrays.asList("topic01"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
2:
package org.example.transactions;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerTransactionReadCommitted02 {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
//设置消费者事务的隔离级别 read_un commit
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
// consumer.subscribe(Pattern.compile("^topic.*"));
consumer.subscribe(Arrays.asList("topic02"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
读取未提交数据的测试消费者:
package org.example.transactions;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
/**
* @author shenyang
* @version 1.0
* @info TestKAFKA
*/
public class KafkaConsumerTransactionReadUnCommitted {
public static void main(String[] args) {
//1.创建KafkaProducer
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "SHENYANG:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "g2");
//设置消费者事务的隔离级别 read_un commit
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_uncommitted");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅相关的Topic
// consumer.subscribe(Pattern.compile("^topic.*"));
consumer.subscribe(Arrays.asList("topic01"));
//遍历消息队列
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
//从队列中取出数据
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
while (recordIterator.hasNext()) {
//获取一个消费消息
ConsumerRecord<String, String> record = recordIterator.next();
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
long timestamp = record.timestamp();
System.out.println(
topic + "\t" +
partition + "\t" +
offset + "\t" +
key + "\t" +
value + "\t" +
timestamp);
}
}
}
}
}
3、Spring Boot集成Kafka
相关文档:https://docs.spring.io/spring-boot/reference/messaging/kafka.html#messaging.kafka,https://spring.io/projects/spring-kafka——kafka client对应版本。
引入kafka依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.2.0</version> <!-- 使用你需要的版本 -->
</dependency>
spring 的配置文件:
spring:
kafka:
bootstrap-servers: CentOSA:9092,CentOSB:9092,CentOSC:9092 #kafka服务节点
consumer:
auto-commit-interval: 100 # offset 自动提交间隔
auto-offset-reset: earliest # 首次加载record策略
enable-auto-commit: true # 启动offset自动提交
group-id: group1 #组id
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # key的序列化器
properties:
isolation:
level: read_committed #消费者读取数据的隔离级别
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # value的序列化器
producer:
acks: all # 生产者确认机制
batch-size: 16384 # 批处理大小
buffer-memory: 33554432 # 缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer # key的序列化器
properties:
enable:
idempotence: true #是否开启幂等
retries: 5 #重试次数
transaction-id-prefix: transaction-id- #事务id
value-serializer: org.apache.kafka.common.serialization.StringSerializer # key的序列化器
使用注解的形式监听并转发消息:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.*;
import org.apache.kafka.streams.state.KeyValueStore;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.KafkaListeners;
import org.springframework.messaging.handler.annotation.SendTo;
import java.io.IOException;
import java.util.Arrays;
import java.util.stream.Collectors;
@SpringBootApplication
@EnableKafkaStreams
@EnableKafka
public class KafkaSpringBootApplication {
public static void main(String[] args) throws IOException {
SpringApplication.run(KafkaSpringBootApplication.class,args);
System.in.read();
}
/**
* 从topic01中消费数据后加上后缀发送到topic02中去
* @param cr 消费记录
* @return record
*/
@KafkaListeners(value = {@KafkaListener(topics = {"topic01"})})
@SendTo(value = {"topic02"})
public String listener(ConsumerRecord<?, ?> cr) {
return cr.value()+" shenyang test";
}
@Bean
public KStream<String, String> kStream(StreamsBuilder kStreamBuilder) {
KStream<String, String> stream = kStreamBuilder.stream(
"topic02",
Consumed.with(Serdes.String(),
Serdes.String()));
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String s) {
return Arrays.stream(s.split(" ")).collect(Collectors.toList());
}
})
.selectKey((k,v)->v)
.groupByKey(Serialized.with(Serdes.String(),Serdes.String()))
.count(Materialized.<String,Long, KeyValueStore<Bytes, byte[]>>as("wordcount"))
.toStream()
.print(Printed.toSysOut());
return stream;
}
}
使用 KafkaTemplate 发送消息:
import com.example.KafkaSpringBootApplication;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaOperations;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest(classes = {KafkaSpringBootApplication.class})
@RunWith(SpringRunner.class)
public class KafkaTemplateTests {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test//非事务下执行
public void testOrderService(){
//开启事务后只能在事务环境中执行了,再使用send将会报错!
kafkaTemplate.send(new ProducerRecord("topic04","001","shenyang lin"));
}
@Test//事务下执行
public void testKafkaTemplate(){
kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback() {
@Override
public Object doInOperations(KafkaOperations kafkaOperations) {
return kafkaOperations.send(new ProducerRecord("topic01","002","this is a demo"));
}
});
}
}
在开启事务时,还可以通过spring的事务去执行send方法,可以调用MessageService的sendMessage方法去发送消息:
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Transactional
@Service
public class MessageService {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String id,Object message) {
kafkaTemplate.send(new ProducerRecord("topic04",id,message));
}
}
4、总结
了解API的使用帮助我们更好的在开发中使用kafka。