秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录 :《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有80+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
空间注意力虽提高卷积神经网络性能,但有局限。本文介绍了感受野注意力(RFA)新机制,解决大尺寸卷积核参数共享问题。RFA关注感受野空间特征,为大型卷积核提供有效权重。RFAConv操作几乎不增加计算成本,显著提升网络性能。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1.原理
2. 将C3_RFCAConv添加到yolov5网络中
2.1 C3_RFCAConv代码实现
2.2 C3_RFCAConv的神经网络模块代码解析
2.3 新增yaml文件
2.4 注册模块
2.5 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1.原理

论文地址:RFAConv: Innovating Spatial Attention and Standard Convolutional Operation——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
RFAConv(受体场注意卷积)是一种新颖的卷积运算,旨在解决标准卷积和现有空间注意机制的局限性,特别是在参数共享和大型卷积核方面。
RFAConv 背后的关键原则:
-
受体场空间特征:与专注于单个空间特征的传统空间注意不同,RFAConv 强调受体场空间特征,这些特征是根据卷积核的大小动态生成的。这种方法通过关注受体场内不同特征的重要性来增强特征提取。
-
解决参数共享问题:在标准卷积中,内核参数在整个输入中共享,限制了网络跨空间位置捕获不同信息的能力。RFAConv 通过将注意力机制与卷积相结合来解决此问题,为每个受体场创建非共享参数。
-
注意力机制集成:RFAConv 集成了一种注意力机制,该机制为接受场中的每个特征分配重要性,使网络能够专注于最重要的信息。此过程避免了 CBAM 和 CA 等传统注意力机制的局限性,这些机制在不同空间区域之间共享注意力权重。
-
高效轻量:尽管引入了注意力机制,但 RFAConv 仅增加了极少的计算开销和参数。它还使用组卷积等技术来高效提取接受场空间特征,使其适用于实时应用。
-
性能提升:通过解决空间注意力和卷积参数共享的局限性,RFAConv 增强了神经网络在分类、对象检测和分割等任务中的性能,在许多情况下优于 CBAM 和 CA 等其他基于注意力的方法。
综上所述,RFAConv 通过关注感受野空间特征进行创新,提供了一种更灵活、更强大的方法来替代标准卷积,同时保持效率并提高网络性能。
2. 将C3_RFCAConv添加到yolov5网络中
2.1 C3_RFCAConv代码实现
关键步骤一: 将下面的代码粘贴到\yolov5\models\common.py中
from einops import rearrange
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class RFAConv(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size,stride=1):
super().__init__()
self.kernel_size = kernel_size
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel,bias=False))
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size,padding=kernel_size//2,stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
# self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),
# nn.BatchNorm2d(out_channel),
# nn.ReLU())
self.conv = Conv(in_channel, out_channel, k=kernel_size, s=kernel_size, p=0)
def forward(self,x):
b,c = x.shape[0:2]
weight = self.get_weight(x)
h,w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) #b c*kernel**2,h,w -> b c k**2 h w
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, # b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)
class SE(nn.Module):
def __init__(self, in_channel, ratio=16):
super(SE, self).__init__()
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
b, c= x.shape[0:2]
y = self.gap(x).view(b, c)
y = self.fc(y).view(b, c,1, 1)
return y
class RFCBAMConv(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size=3,stride=1):
super().__init__()
if kernel_size % 2 == 0:
assert("the kernel_size must be odd.")
self.kernel_size = kernel_size
self.generate = nn.Sequential(nn.Conv2d(in_channel,in_channel * (kernel_size**2),kernel_size,padding=kernel_size//2,
stride=stride,groups=in_channel,bias =False),
nn.BatchNorm2d(in_channel * (kernel_size**2)),
nn.ReLU()
)
self.get_weight = nn.Sequential(nn.Conv2d(2,1,kernel_size=3,padding=1,bias=False),nn.Sigmoid())
self.se = SE(in_channel)
# self.conv = nn.Sequential(nn.Conv2d(in_channel,out_channel,kernel_size,stride=kernel_size),nn.BatchNorm2d(out_channel),nn.ReLu())
self.conv = Conv(in_channel, out_channel, k=kernel_size, s=kernel_size, p=0)
def forward(self,x):
b,c = x.shape[0:2]
channel_attention = self.se(x)
generate_feature = self.generate(x)
h,w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b,c,self.kernel_size**2,h,w)
generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
unfold_feature = generate_feature * channel_attention
max_feature,_ = torch.max(generate_feature,dim=1,keepdim=True)
mean_feature = torch.mean(generate_feature,dim=1,keepdim=True)
receptive_field_attention = self.get_weight(torch.cat((max_feature,mean_feature),dim=1))
conv_data = unfold_feature * receptive_field_attention
return self.conv(conv_data)
class RFCAConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride=1, reduction=32):
super(RFCAConv, self).__init__()
self.kernel_size = kernel_size
self.generate = nn.Sequential(nn.Conv2d(inp,inp * (kernel_size**2),kernel_size,padding=kernel_size//2,
stride=stride,groups=inp,
bias =False),
nn.BatchNorm2d(inp * (kernel_size**2)),
nn.ReLU()
)
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv = nn.Sequential(nn.Conv2d(inp,oup,kernel_size,stride=kernel_size))
def forward(self, x):
b,c = x.shape[0:2]
generate_feature = self.generate(x)
h,w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b,c,self.kernel_size**2,h,w)
generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
x_h = self.pool_h(generate_feature)
x_w = self.pool_w(generate_feature).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
h,w = generate_feature.shape[2:]
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
return self.conv(generate_feature * a_w * a_h)
class Bottleneck_RFAConv(Bottleneck):
"""Standard bottleneck with RFAConv."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFAConv(c_, c2, k[1])
class C3_RFAConv(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_RFAConv(c_, c_, shortcut, g, k=(1, 3), e=1.0) for _ in range(n)))
class Bottleneck_RFCBAMConv(Bottleneck):
"""Standard bottleneck with RFCBAMConv."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFCBAMConv(c_, c2, k[1])
class C3_RFCBAMConv(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_RFCBAMConv(c_, c_, shortcut, g, k=(1, 3), e=1.0) for _ in range(n)))
class Bottleneck_RFCAConv(Bottleneck):
"""Standard bottleneck with RFCBAMConv."""
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1)
self.cv2 = RFCAConv(c_, c2, 3)
class C3_RFCAConv(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_RFCAConv(c_, c_, shortcut, g, e=1.0) for _ in range(n)))2.2 C3_RFCAConv的神经网络模块代码解析
1. RFAConv 模块
RFAConv 是一种基于动态卷积的模块,它的核心思想是根据输入生成卷积核权重并应用于特征图上,具备空间自适应特性。
-
get_weight:-
先通过
AvgPool2d池化和Conv2d来生成与输入特征图相匹配的权重,这些权重控制卷积核在不同空间位置的响应。
-
-
generate_feature:-
通过深度可分离卷积生成多个特征图(数量为卷积核的大小平方倍),每个特征图捕获不同的局部信息。
-
-
weighted_data:-
权重和生成的特征图通过
softmax进行加权,并通过rearrange操作进行重构,最终输出的特征图经过卷积层得到输出。这一操作类似于对每个空间位置应用不同的卷积核(动态卷积)。
-
2. SE 模块
SE(Squeeze-and-Excitation)模块是一种经典的通道注意力机制。
-
gap(Global Average Pooling): 对特征图的每个通道进行全局平均池化,得到每个通道的全局信息。 -
fc(Fully Connected): 通过两个全连接层,对特征图通道进行缩放。它先将特征图的通道数缩小,再恢复为原始通道数,并通过 Sigmoid 激活生成注意力权重。 -
最终,SE模块会对输入的每个通道进行重新加权,增强重要通道,抑制无关通道。
3. RFCAConv 模块
RFCAConv 模块是 RFAConv 和 CA(Coordinate Attention)的结合体,结合了动态卷积与坐标注意力。
-
generate: 使用深度可分离卷积生成多个特征图。 -
pool_h和pool_w: 类似于CA注意力机制,分别在高度和宽度维度进行全局平均池化,捕捉每个方向上的全局信息。 -
conv1: 将池化后的特征通过1x1卷积和激活函数进行处理,然后将其分成高度和宽度两个部分。 -
conv_h和conv_w: 分别生成高度和宽度的注意力权重(通过 Sigmoid),这些权重会用来调整特征图的空间表示,类似于CA中的注意力机制。 -
输出: 将生成的特征图与高度和宽度的注意力权重相乘,提升空间上的特征表达能力,最终通过卷积层输出。
4. Bottleneck_RFAConv 模块
这是标准的瓶颈结构结合了 RFAConv。其中:
-
cv1: 用标准卷积进行初始特征提取。 -
cv2: 用RFAConv替换标准的第二层卷积,利用其动态卷积特性,增强空间信息的表达。
5. C3_RFCAConv 模块
这个模块基于 C3 结构,使用了 Bottleneck_RFCAConv,在其瓶颈结构中引入了 RFCAConv,从而结合了动态卷积和坐标注意力机制。
总结
-
RFAConv主要实现了动态卷积,能够根据输入自适应调整卷积核的权重。 -
RFCAConv则结合了RFAConv和Coordinate Attention,通过坐标注意力机制增强了特征的空间表达。 -
Bottleneck_RFAConv模块是将这些卷积整合到标准的神经网络结构中,增强了其特征提取能力。
这些模块的设计思想是为了提升模型的感受野和空间感知能力,同时通过注意力机制增强特征选择性。
2.3 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_C3_RFCAConv.yaml并将下面代码复制进去
- 目标检测yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_RFCAConv, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_RFCAConv, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_RFCAConv, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_RFCAConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 语义分割yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_RFCAConv, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_RFCAConv, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_RFCAConv, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_RFCAConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Segment (P3, P4, P5)
]
温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.4 注册模块
关键步骤三:在yolo.py的parse_model函数替换添加C3_RFCAConv

2.5 执行程序
在train.py中,将cfg的参数路径设置为yolov5_C3_RFCAConv.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments
0 -1 1 7040 models.common.Conv [3, 64, 6, 2, 2]
1 -1 1 73984 models.common.Conv [64, 128, 3, 2]
2 -1 3 180808 models.common.C3_RFCAConv [128, 128, 3]
3 -1 1 295424 models.common.Conv [128, 256, 3, 2]
4 -1 6 1213584 models.common.C3_RFCAConv [256, 256, 6]
5 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
6 -1 9 6719704 models.common.C3_RFCAConv [512, 512, 9]
7 -1 1 4720640 models.common.Conv [512, 1024, 3, 2]
8 -1 3 10199184 models.common.C3_RFCAConv [1024, 1024, 3]
9 -1 1 2624512 models.common.SPPF [1024, 1024, 5]
10 -1 1 525312 models.common.Conv [1024, 512, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 3 2757632 models.common.C3 [1024, 512, 3, False]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 3 690688 models.common.C3 [512, 256, 3, False]
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 2495488 models.common.C3 [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 9971712 models.common.C3 [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5_C3_RFCAConv summary: 641 layers, 47196349 parameters, 47196349 gradients, 114.3 GFLOPs3. 完整代码分享
https://pan.baidu.com/s/1aPhHxLJuM6zUp-it0KI78w?pwd=jncq提取码: jncq
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
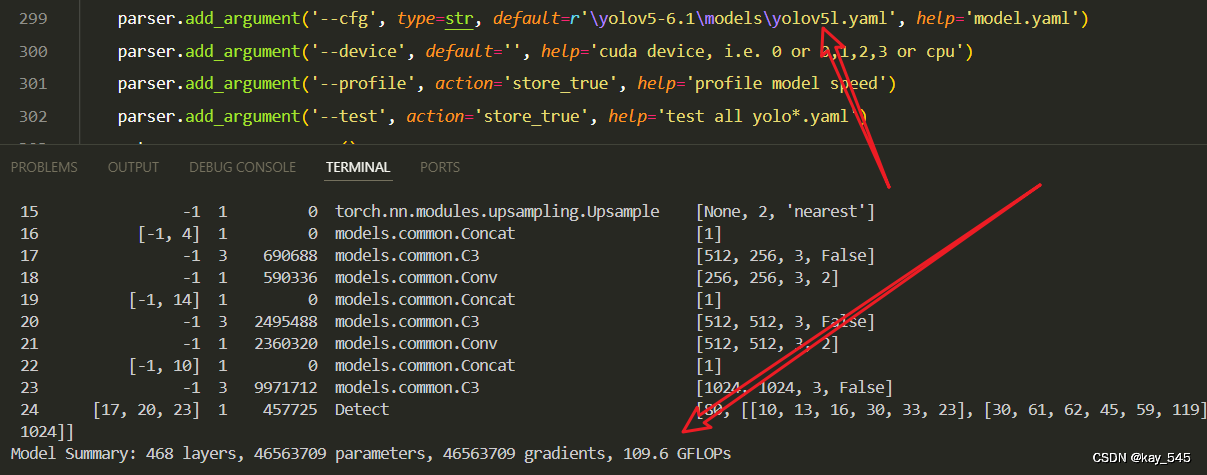
改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
C3_RFCAConv模块结合了 C2f 结构和 RFCAConv卷积层的设计,旨在增强模型的特征提取能力,特别是在空间和通道维度上的表达。C3通过多分支结构将输入特征分解并逐层融合,提升了特征多样性,而 RFCAConv 引入了动态卷积和坐标注意力机制。具体来说,RFCAConv通过自适应地生成卷积核权重,实现了对不同空间位置的卷积操作优化,并通过在高度和宽度维度上分别进行全局池化,生成相应的注意力权重,提升了特征的空间感知能力。在 C3_RFCAConv中,多个 Bottleneck_RFCAConv模块被堆叠使用,每个模块对特征进行动态卷积和注意力增强,逐步融合和强化不同层次的特征信息,从而提高了模型的感受野和对重要特征的选择性,使其在处理复杂视觉任务时更加高效。



















