小罗碎碎念
本期推文主题:树状图
本期推文主要介绍如何绘制树状图以及它的一些变体形式,看完本篇推文,你最终能够实现的效果如下。
一、组织结构图
Dendrogram是一种网络结构,由一个根节点开始,该节点通过边或分支连接多个节点。这个层次结构中的最后节点被称为叶节点。
在下面的例子中,CEO是根节点,他管理2个经理,每个经理管理8名员工(叶节点)。
1-1:创建一个数据框
# 加载所需的库
library(ggraph) # 用于绘制图形
library(igraph) # 用于处理图数据结构
library(tidyverse) # 用于数据处理和可视化
library(dplyr) # 用于数据处理
library(dendextend) # 用于树状图扩展
library(colormap) # 用于颜色映射
library(kableExtra) # 用于表格美化
options(knitr.table.format = "html") # 设置表格格式为HTML
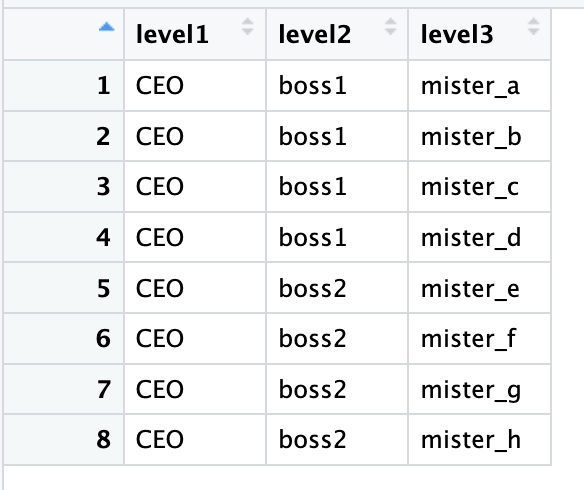
# 创建一个数据框
data=data.frame(
level1="CEO", # 第一层级的名称
level2=c( rep("boss1",4), rep("boss2",4)), # 第二层级的名称,每个名称重复4次
level3=paste0("mister_", letters[1:8]) # 第三层级的名称,由字母和前缀组成
)
创建的数据框如下:
1-2:将数据框转换为边列表
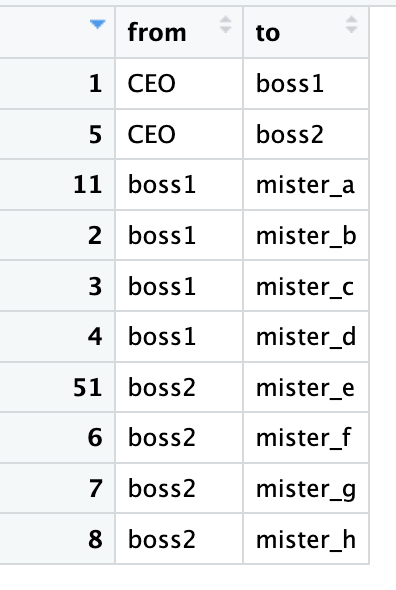
# 将数据框转换为边列表
edges_level1_2 = data %>% select(level1, level2) %>% unique %>% rename(from=level1, to=level2) # 第一层和第二层之间的边
edges_level2_3 = data %>% select(level2, level3) %>% unique %>% rename(from=level2, to=level3) # 第二层和第三层之间的边
edge_list=rbind(edges_level1_2, edges_level2_3) # 合并两个边列表
这段代码是使用R语言和dplyr包来处理数据框(data frame)并将其转换为边列表(edge list),通常用于表示网络或图结构。下面是对每一步的详细解释:
1. 导入dplyr包
首先,确保你已经安装并导入了dplyr包,因为这段代码使用了dplyr中的管道操作符%>%和其他函数。
library(dplyr)
2. 创建边列表
这段代码的目的是从数据框data中提取层次结构信息,并将其转换为边列表。data包含三列,分别是level1, level2, 和 level3,代表不同的层次。
提取第一层和第二层之间的边
edges_level1_2 = data %>%
select(level1, level2) %>% # 选择level1和level2两列
unique() %>% # 去除重复的行
rename(from=level1, to=level2) # 将列名重命名为from和to
select(level1, level2):从数据框中选择level1和level2两列。unique():去除这两列组合中的重复行,确保每条边只出现一次。rename(from=level1, to=level2):将level1列重命名为from,将level2列重命名为to,这样就形成了边的起点和终点。
提取第二层和第三层之间的边
edges_level2_3 = data %>%
select(level2, level3) %>% # 选择level2和level3两列
unique() %>% # 去除重复的行
rename(from=level2, to=level3) # 将列名重命名为from和to
这一步与上一步类似,只是选择的列不同。
3. 合并两个边列表
edge_list = rbind(edges_level1_2, edges_level2_3) # 合并两个边列表
rbind(edges_level1_2, edges_level2_3):使用rbind函数将edges_level1_2和edges_level2_3两个数据框按行合并,形成一个完整的边列表。
4.结果
最终,edge_list数据框包含了所有的边,其中每一行代表一条边,有两列分别表示边的起点(from)和终点(to)。
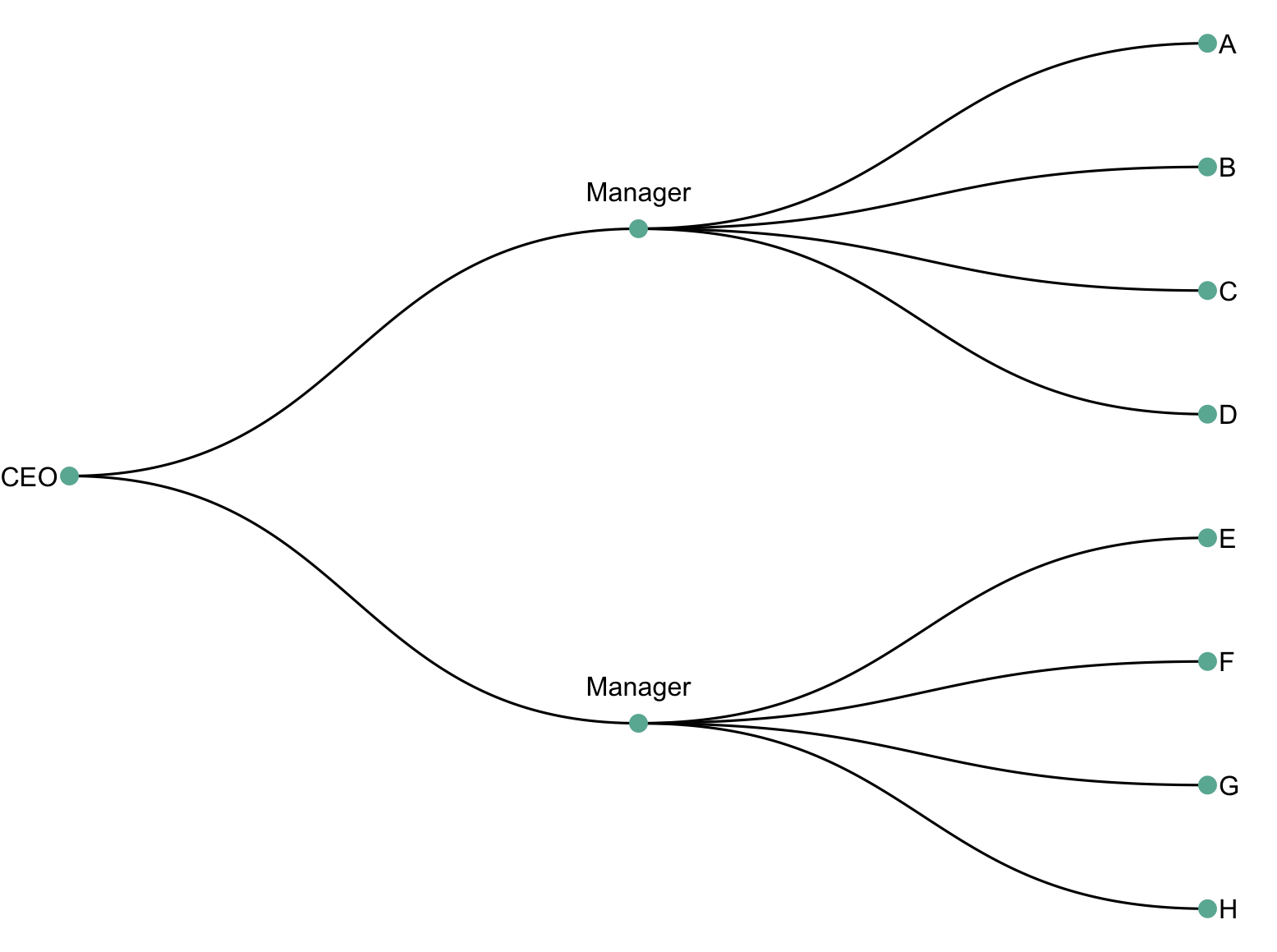
1-3:绘制组织结构图
这段代码是用R语言编写的,用于绘制一个组织结构图。它使用了igraph和ggraph包来创建和绘制图形。
# 现在我们可以绘制图形
mygraph <- graph_from_data_frame( edge_list ) # 从边列表创建图
ggraph(mygraph, layout = 'dendrogram', circular = FALSE) + # 使用树状图布局绘制图形
geom_edge_diagonal() + # 绘制对角线边
geom_node_point(color="#69b3a2", size=3) + # 绘制节点点,设置颜色和大小
geom_node_text(
aes( label=c("CEO", "Manager", "Manager", LETTERS[8:1]) ), # 设置节点标签
hjust=c(1,0.5, 0.5, rep(0,8)), # 设置标签水平对齐方式
nudge_y = c(-.02, 0, 0, rep(.02,8)), # 设置标签垂直偏移量
nudge_x = c(0, .3, .3, rep(0,8)) # 设置标签水平偏移量
) +
theme_void() + # 设置无主题
coord_flip() + # 水平翻转坐标轴
scale_y_reverse() # 反转y轴刻度
下面是代码的详细解释:
- 导入库:首先,你需要确保已经安装了
igraph和ggraph包。如果没有安装,可以使用以下命令安装:
install.packages("igraph")
install.packages("ggraph")
- 创建图:使用
graph_from_data_frame()函数从边列表(edge_list)创建一个图对象(mygraph)。
mygraph <- graph_from_data_frame(edge_list)
- 绘制图形:使用
ggraph()函数绘制图形。这里使用了树状图布局(layout = ‘dendrogram’),并设置circular = FALSE表示不使用圆形布局。
ggraph(mygraph, layout = 'dendagger', circular = FALSE) +
- 绘制对角线边:使用
geom_edge_diagonal()函数绘制对角线边。
geom_edge_diagonal() +
- 绘制节点点:使用
geom_node_point()函数绘制节点点,并设置颜色(color=“#69b3a2”)和大小(size=3)。
geom_node_point(color="#69b3a2", size=3) +
- 绘制节点文本:使用
geom_node_text()函数绘制节点标签。这里使用aes()函数设置标签内容,hjust、nudge_y和nudge_x参数分别设置标签的水平对齐方式、垂直偏移量和水平偏移量。
geom_node_text(
aes(label=c("CEO", "Manager", "Manager", LETTERS[8:1])),
hjust=c(1,0.5, 0.5, rep(0,8)),
nudge_y = c(-.02, 0, 0, rep(.02,8)),
nudge_x = c(0, .3, .3, rep(0,8))
) +
- 设置无主题:使用
theme_void()函数设置无主题,这样图形看起来更简洁。
theme_void() +
- 水平翻转坐标轴:使用
coord_flip()函数水平翻转坐标轴,使图形更符合组织结构图的阅读习惯。
coord_flip() +
- 反转y轴刻度:使用
scale_y_reverse()函数反转y轴刻度,使图形更符合组织结构图的阅读习惯。
scale_y_reverse()
这样,你就可以根据edge_list绘制出一个组织结构图。
1-4:优化
为了让绘制的图更精美,我们可以调整节点颜色、大小、边的样式以及添加一些视觉效果。下面的代码演示如何为图形添加背景色和框。
# 绘制图形
ggraph(mygraph, layout = 'dendrogram', circular = FALSE) + # 使用树状图布局绘制图形
geom_edge_diagonal() + # 绘制对角线边
geom_node_point(color="#69b3a2", size=3) + # 绘制节点点,设置颜色和大小
geom_node_text(
aes( label=c("CEO", "Manager", "Manager", LETTERS[8:1]) ), # 设置节点标签
hjust=c(1,0.5, 0.5, rep(0,8)), # 设置标签水平对齐方式
nudge_y = c(-.02, 0, 0, rep(.02,8)), # 设置标签垂直偏移量
nudge_x = c(0, .3, .3, rep(0,8)) # 设置标签水平偏移量
) +
theme_void() + # 设置无主题
coord_flip() + # 水平翻转坐标轴
scale_y_reverse() + # 反转y轴刻度
# 调整图形的视觉效果
theme(
plot.background = element_rect(fill = "#f0f0f0"),
panel.background = element_rect(fill = "#f0f0f0")
)
1-5:垂直组织结构图
# 现在我们可以绘制图形
mygraph <- graph_from_data_frame( edge_list ) # 从边列表创建图
ggraph(mygraph, layout = 'dendrogram', circular = FALSE) + # 使用树状图布局绘制图形
geom_edge_diagonal() + # 绘制对角线边
geom_node_point(color="#69b3a2", size=3) + # 绘制节点点,设置颜色和大小
geom_node_text(
aes( label=c("CEO", "Manager", "Manager", LETTERS[8:1]) ), # 设置节点标签
hjust=c(1,0.5, 0.5, rep(0,8)), # 设置标签水平对齐方式
nudge_y = c(-.02, 0, 0, rep(.02,8)), # 设置标签垂直偏移量
nudge_x = c(.5, .5, .5, rep(.5,8)) # 设置标签水平偏移量
) +
theme_void() # 设置无主题
二、聚类分析
从聚类中得到的树状图(Dendrogram from clustering)是聚类分析的一种可视化工具,它展示了数据点如何通过聚类过程逐渐聚集成更大的集群。在这个过程中,数据点之间的距离是关键因素,它决定了哪些数据点应该被组合在一起。
假设我们有一个包含28个主要城市的距离矩阵,该矩阵提供了所有成对城市之间的距离。这种矩阵可以通过计算多变量数据集中每对个体之间的相关性或欧几里得距离来得到。
在聚类分析中,数据点首先被按照它们之间的距离分组。随着聚类过程的进行,这些组会逐渐合并,直到所有数据点都被组合成一个大的集群。树状图展示了这个合并过程,其中数据点作为节点,节点之间的距离表示了数据点之间的相似度或距离。
树状图的顶部是单个数据点,底部是所有数据点的合并。树状图的分支长度和角度可以用来表示不同集群之间的相似度或距离。通过这种方式,树状图可以帮助研究者理解数据点的聚类结构,并确定最佳的聚类数。
2-1:加载数据
这段代码的功能是从一个CSV文件中读取数据,并进行一些预处理。
data <- read.table("/Users/luoxiaoluotongxue/Desktop/master_record/科研绘图/09-06.csv", header=T, sep=",") %>% as.matrix
colnames(data) <- gsub("\\.", " ", colnames(data)) # 将列名中的点替换为空格
下面是详细的解释:
1. 读取CSV文件
data <- read.table("/Users/luoxiaoluotongxue/Desktop/master_record/科研绘图/09-06.csv", header=T, sep=",")
read.table()函数用于从文本文件中读取数据。"/Users/luoxiaoluotongxue/Desktop/master_record/科研绘图/09-06.csv"是文件的路径。header=T表示文件的第一行是列名。sep=","表示文件中的列是用逗号分隔的。
2. 转换为矩阵
%>% as.matrix
%>%是管道操作符,用于将前一个函数的输出作为下一个函数的输入。as.matrix函数将数据框(data frame)转换为矩阵(matrix)。
3. 替换列名中的点
colnames(data) <- gsub("\\.", " ", colnames(data))
colnames(data)获取数据矩阵的列名。gsub("\\.", " ", colnames(data))使用正则表达式替换函数gsub将列名中的点(.)替换为空格(\\.表示匹配点字符(因为在正则表达式中文点表示任意字符,所以需要用反斜杠转义)。" "表示替换为空格。
2-2:预处理操作
这段代码的目的是对数据进行一系列的预处理操作,包括去除空格、转换数据类型和移除特定列。
data <- data %>%
as.data.frame() %>%
mutate_all(~ gsub(" ", "", .)) %>%
as.matrix() # 将数据框转换为矩阵,并去除列名中的空格
data <- apply(data, 2, as.numeric) # 将矩阵的每一列转换为数值型
data <- data[,-1] # 移除第一列(城市名称)
下面是详细的解释:
1. 转换为数据框并去除空格
data <- data %>%
as.data.frame() %>%
mutate_all(~ gsub(" ", "", .)) %>%
as.matrix()
%>%是管道操作符,用于将前一个函数的输出作为下一个函数的输入。as.data.frame()将数据转换为数据框(data frame)。mutate_all(~ gsub(" ", "", .))对数据框中的每一个元素应用gsub函数,去除其中的空格。gsub(" ", "", .)表示将所有的空格替换为空字符串。
as.matrix()将处理后的数据框转换为矩阵(matrix)。
2. 转换数据类型
data <- apply(data, 2, as.numeric)
apply(data, 2, as.numeric)对矩阵的每一列应用as.numeric函数,将其转换为数值型。2表示按列操作。
3. 移除第一列
data <- data[,-1]
data[,-1]表示移除矩阵的第一列。
示例数据
假设原始数据框 data 如下:
city value1 value2
1 New York 100 200
2 Chicago 150 250
3 Los Angeles 200 300
执行上述代码后,data 矩阵将会是:
value1 value2
[1,] 100 200
[2,] 150 250
[3,] 200 300
这样处理后的数据更适合用于后续的数据分析和图形绘制。
2-3:显示数据
这段代码的目的是从数据中选择特定的列和行,处理缺失值,并使用 kableExtra 库美化表格以便于展示。
library(kableExtra)
# 显示数据
tmp <- data %>% as.data.frame() %>% select(1,3,6) %>% .[c(1,3,6),] # 选择特定的列和行
tmp[is.na(tmp)] <- "-" # 将缺失值替换为短横线
tmp %>% kable() %>%
kable_styling(bootstrap_options = "striped", full_width = F) # 使用kableExtra库美化表格
下面是详细的解释:
1. 选择特定的列和行
tmp <- data %>% as.data.frame() %>% select(1,3,6) %>% .[c(1,3,6),]
%>%是管道操作符,用于将前一个函数的输出作为下一个函数的输入。as.data.frame()将数据转换为数据框(data frame)。select(1,3,6)选择数据框的第1、3和6列。.[c(1,3,6),]选择数据框的第1、3和6行。
2. 处理缺失值
tmp[is.na(tmp)] <- "-"
is.na(tmp)检查tmp中的缺失值。tmp[is.na(tmp)] <- "-"将缺失值替换为短横线-。
3. 美化表格
tmp %>% kable() %>%
kable_styling(bootstrap_options = "striped", full_width = F)
kable()函数将数据框转换为 HTML 表格。kable_styling(bootstrap_options = "striped", full_width = F)使用kableExtra库对表格进行美化。bootstrap_options = "striped"表示使用 Bootstrap 的条纹样式。full_width = F表示表格不占据整个页面宽度。
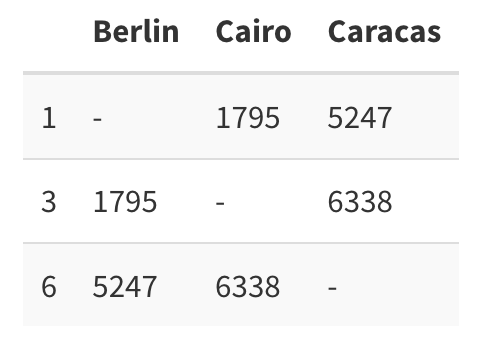
层次聚类分析的结果可以看作是一个树状图(dendrogram)。在这个树状图中,每个数据点作为一个节点,节点之间的边表示了数据点之间的距离。随着聚类过程的进行,这些节点会逐渐合并,形成更大的集群。
树状图的顶部是单个数据点,底部是所有数据点的合并。树状图的分支长度和角度可以用来表示不同集群之间的相似度或距离。
通过树状图,研究者可以直观地看到数据点的聚类结构,并确定最佳的聚类数。例如,他们可以选择在树状图中画一条垂直线,将树状图分割成两部分,每一部分代表一个聚类。这条线的位置可以用来确定聚类的最佳数量。
因此,树状图是层次聚类分析的重要工具,它可以帮助研究者理解和解释数据点的聚类结构。
2-4:绘制树状图
# 执行层次聚类分析
dend <- as.dist(data) %>% # 将数据转换为距离矩阵
hclust(method="ward.D") %>% # 使用Ward.D方法进行层次聚类
as.dendrogram() # 将聚类结果转换为树状图对象
# 根据簇的颜色绘制树状图
leafcolor <- colormap(colormap = colormaps$viridis, nshades = 5, format = "hex", alpha = 1, reverse = FALSE) # 生成颜色映射
par(mar=c(1,1,1,7)) # 设置图形边距
dend %>%
set("labels_col", value = leafcolor, k=5) %>% # 设置叶子节点的颜色
set("branches_k_color", value = leafcolor, k = 5) %>% # 设置分支的颜色
plot(horiz=TRUE, axes=FALSE) # 绘制水平树状图,不显示坐标轴
这段代码的目的是根据簇的颜色绘制一个水平的树状图。下面是详细的解释:
1. 生成颜色映射
leafcolor <- colormap(colormap = colormaps$viridis, nshades = 5, format = "hex", alpha = 1, reverse = FALSE)
colormap()函数生成一个颜色映射。colormaps$viridis表示使用 Viridis 颜色映射。nshades = 5表示生成5种颜色。format = "hex"表示颜色格式为十六进制。alpha = 1表示颜色的透明度为完全不透明。reverse = FALSE表示不反转颜色顺序。
2. 设置图形边距
par(mar=c(1,1,1,7))
par(mar=c(1,1,1,7))设置图形的边距。这里的参数分别表示下、左、上、右的边距。
3. 设置叶子节点和分支的颜色
dend %>%
set("labels_col", value = leafcolor, k=5) %>%
set("branches_k_color", value = leafcolor, k = 5) %>%
set("labels_col", value = leafcolor, k=5)设置叶子节点的颜色。k=5表示根据5个簇来分配颜色。set("branches_k_color", value = leafcolor, k = 5)设置分支的颜色。k = 5表示根据5个簇来分配颜色。
4. 绘制水平树状图
plot(horiz=TRUE, axes=FALSE)
plot(horiz=TRUE, axes=FALSE)绘制一个水平的树状图,并且不显示坐标轴。
这段代码首先执行了层次聚类分析,并将结果转换为树状图对象。然后,根据簇的数量生成了一个颜色映射,并设置了叶子节点和分支的颜色。最后,绘制了一个水平的树状图,不显示坐标轴。

正如预期的那样,地理位置相近的城市往往会聚类在一起。例如,黄色集群由数据集中的所有亚洲城市组成。需要注意的是,树状图提供了更多的信息。
一个常见的任务是将与预期结果比较聚类结果。例如,我们可以使用颜色条来检查国家是否确实按照大陆被分组。在树状图中,每个集群可以分配一个颜色,颜色条则显示了每个颜色的对应的大陆。通过这种方式,我们可以直观地看到聚类结果是否与我们的预期相符。
这种比较有助于验证聚类分析的有效性,并帮助我们了解数据集中的模式和结构。通过树状图和颜色条的结合,我们可以更好地理解和解释聚类分析的结果。
# 创建一个表示大洲的颜色向量
continent <- c("Europe", "South America", "Africa", "Asia", "Africa", "South America", "North America", "Asia", "North America",
"Europe", "Europe","Europe", "North America", "Asia", "South America", "North America", "Europe", "North America",
"Europe", "South America", "Europe", "North America", "Asia", "Europe", "Asia", "Asia", "Europe",
"North America"
)
# 生成颜色映射,并将其分配给大洲
barcolor <- colormap(colormap = colormaps$viridis, nshades = 5, format = "hex", alpha = 1, reverse = FALSE)
barcolor <- barcolor[as.numeric(as.factor(continent))]
# Make the dendrogram
par(mar=c(8,5,2,2))
dend %>%
set("labels_col", value = leafcolor, k=5) %>%
set("branches_k_color", value = leafcolor, k = 5) %>%
plot(axes=FALSE)
colored_bars(colors = barcolor, dend = dend, rowLabels = "continent")
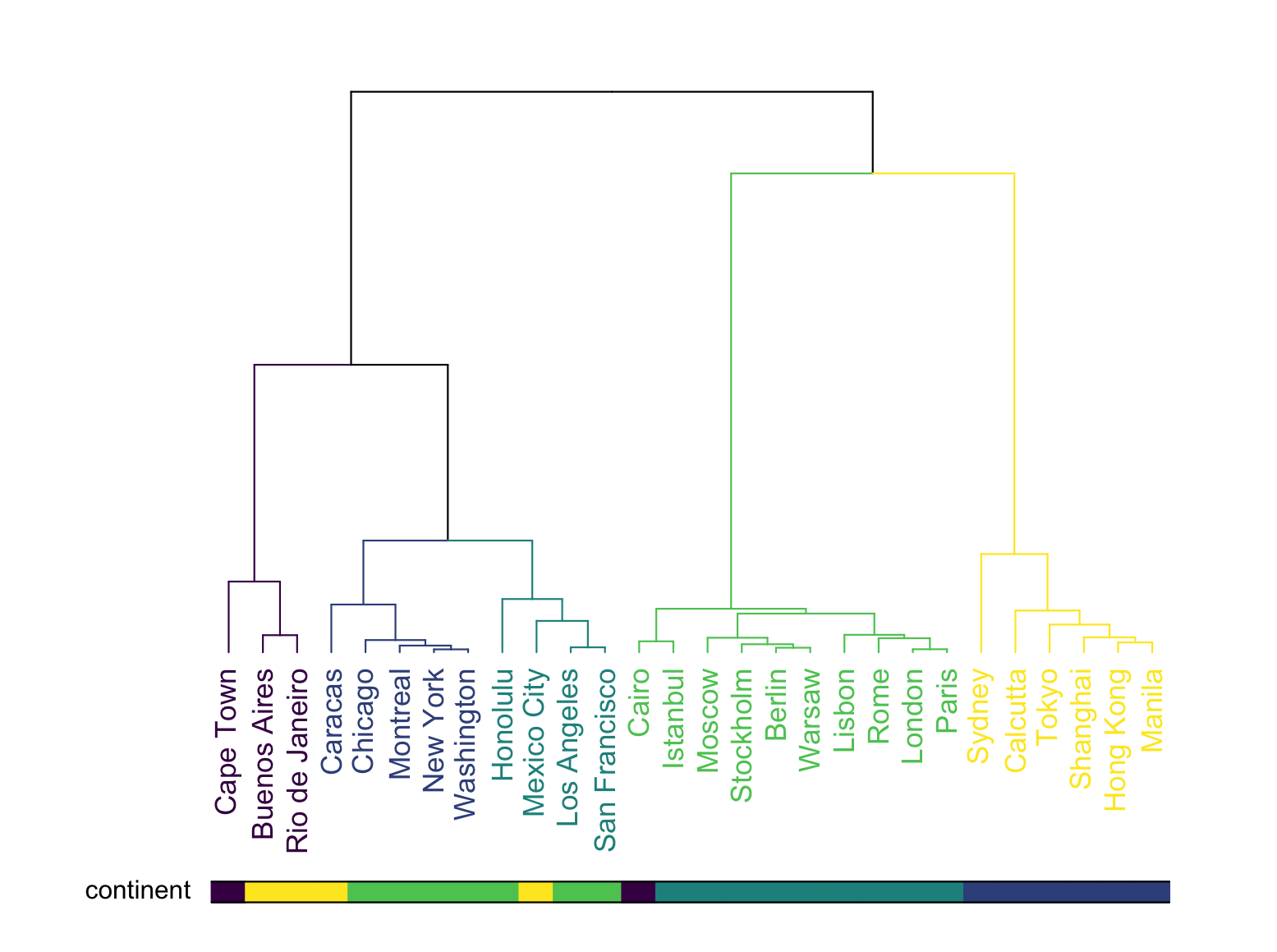
这种图形允许我们验证聚类确实将城市按大陆分组。这里有一些合理的差异。例如,墨西哥城在这里被认为是一个南美洲的城市,尽管它可能更接近北美洲,正如聚类所暗示的。
这些差异可能是由于距离计算的特定方式、聚类算法的选择、数据点的特征或其他因素。然而,它们并不一定意味着聚类分析是错误的。相反,它们可能反映了数据的真实复杂性或聚类方法的局限性。
例如,墨西哥城与北美洲的城市可能具有更高的基因相似性,而与南美洲的城市可能更接近地理上,这可能导致聚类分析将墨西哥城错误地分配给南美洲。这种现象可能是由于数据集中的其他城市在聚类过程中扮演了关键角色,或者是因为聚类算法在处理这种跨大陆的数据时存在局限性。
因此,通过图形和颜色条的验证,我们可以确认聚类分析的基本有效性,同时意识到可能存在的细微差异,这些差异需要进一步的分析和解释。这有助于我们更好地理解数据和聚类分析的结果。
三、变体
树状图存在许多变体。它可以水平或垂直显示,如之前所示。它也可以是线性的或圆形的。圆形版本的一个优点是它更有效地利用了图形空间:
- 水平树状图:这是最常见的树状图形式,节点沿着水平轴排列,分支从顶部向下延伸。
- 垂直树状图:在这种形式中,节点沿着垂直轴排列,分支从左侧向右侧延伸。
- 线性树状图:节点和分支沿着一条直线排列,这种形式通常用于展示大量的数据点。
- 圆形树状图:在这种形式中,节点围绕中心点排列,分支从中心点向外延伸。这种形式可以更有效地展示大量的数据点,并且可以更好地适应圆形或环形空间。
圆形树状图的一个优点是它能够更好地利用图形空间,特别是当数据点数量较多时。这种形式可以更紧凑地展示数据,减少空白空间,使得整个树状图更加紧凑和易于理解。
选择哪种树状图形式取决于数据点的数量、分析的目标以及可用空间的大小。每种形式都有其优势和局限性,研究者应根据具体情况选择最合适的形式。
3-1:创建一个数据框
# 加载所需的库
library(ggraph) # 用于绘制图形
library(igraph) # 用于处理图数据结构
library(tidyverse) # 用于数据处理和可视化
library(RColorBrewer) # 用于颜色映射
set.seed(1) # 设置随机数种子,以确保结果可重复
# 创建一个数据框,给出个体的层次结构
d1=data.frame(from="origin", to=paste("group", seq(1,10), sep=""))
d2=data.frame(from=rep(d1$to, each=10), to=paste("group", seq(1,100), sep="_"))
edges=rbind(d1, d2) # 合并两个数据框,形成边列表
3-2:创建一个顶点数据框
这段代码的主要目的是创建一个顶点数据框(vertices dataframe),用于表示层次结构中的对象。数据框中的每一行代表一个顶点,包含顶点的名称、随机生成的值以及所属的组。
# 创建一个顶点数据框。每行代表我们层次结构中的一个对象
vertices = data.frame(
name = unique(c(as.character(edges$from), as.character(edges$to))) , # 获取所有唯一的顶点名称
value = runif(111) # 为每个顶点生成一个随机值
)
# 添加一列,表示每个名称所属的组。稍后用于为点着色
vertices$group = edges$from[ match( vertices$name, edges$to ) ]
以下是代码的详细解释:
# 创建一个顶点数据框。每行代表我们层次结构中的一个对象
vertices = data.frame(
name = unique(c(as.character(edges$from), as.character(edges$to))) , # 获取所有唯一的顶点名称
value = runif(111) # 为每个顶点生成一个随机值
)
这段代码创建了一个名为vertices的数据框,包含两列:name和value。
name列:通过将edges数据框中的from和to列转换为字符类型,并使用unique()函数获取所有唯一的顶点名称。value列:使用runif(111)生成111个随机数,作为每个顶点的值。
# 添加一列,表示每个名称所属的组。稍后用于为点着色
vertices$group = edges$from[ match( vertices$name, edges$to ) ]
这段代码为vertices数据框添加了一个新列group,表示每个顶点所属的组。这是通过以下步骤实现的:
- 使用
match()函数查找vertices数据框中每个顶点名称(vertices$name)在edges数据框的to列中的位置。 - 使用这些位置从
edges数据框的from列中提取对应的组信息。 - 将提取的组信息添加到
vertices数据框的新列group中。
这样,vertices数据框中的每一行都包含了顶点的名称、随机值以及所属的组。这个数据框可以用于绘制层次结构图,其中顶点的颜色可以根据所属的组进行区分。
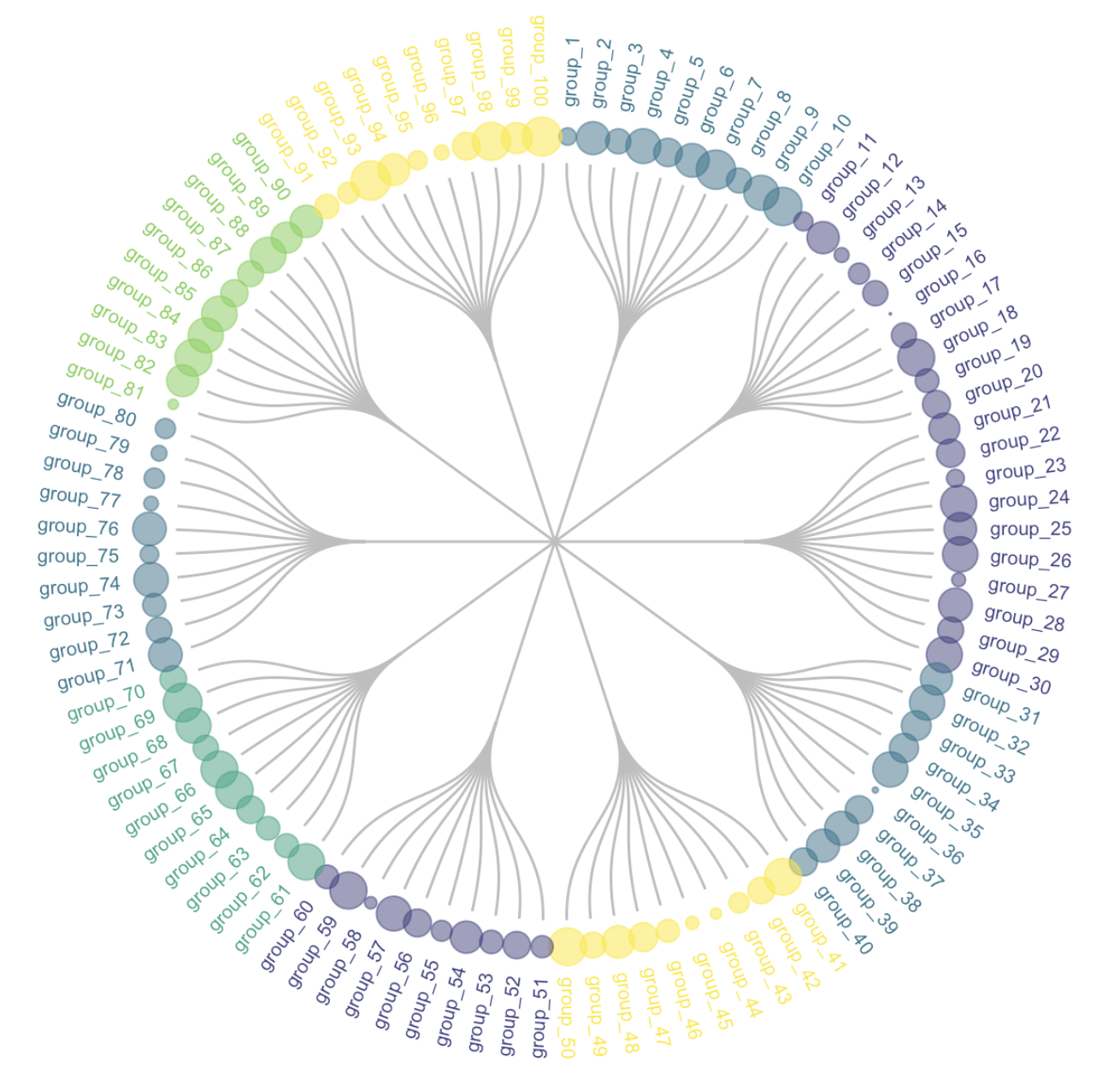
3-3:圆形树状图
# 添加关于我们将要添加的标签的信息:角度、水平调整和可能的翻转
# 计算标签的角度
vertices$id=NA
myleaves=which(is.na( match(vertices$name, edges$top) ))
nleaves=length(myleaves)
vertices$id[ myleaves ] = seq(1:nleaves)
vertices$angle= 90 - 360 * vertices$id / nleaves
# 计算标签的对齐方式:右对齐或左对齐
# 如果我在图的左侧部分,我的标签当前的角度 < -90
vertices$hjust<-ifelse( vertices$angle < -90, 1, 0)
# 翻转角度,使其可读
vertices$angle<-ifelse(vertices$angle < -90, vertices$angle+180, vertices$angle)
# 创建一个图对象
mygraph <- graph_from_data_frame( edges, vertices=vertices )
# 准备颜色
mycolor <- colormap(colormap = colormaps$viridis, nshades = 6, format = "hex", alpha = 1, reverse = FALSE)[sample(c(1:6), 10, replace=TRUE)]
# 绘制图形
ggraph(mygraph, layout = 'dendrogram', circular = TRUE) + # 使用树状图布局,设置为圆形
geom_edge_diagonal(colour="grey") + # 绘制对角线边,设置颜色为灰色
scale_edge_colour_distiller(palette = "RdPu") + # 设置边的颜色渐变
geom_node_text(aes(x = x*1.15, y=y*1.15, filter = leaf, label=name, angle = angle, hjust=hjust, colour=group), size=2.7, alpha=1) + # 绘制节点文本
geom_node_point(aes(filter = leaf, x = x*1.07, y=y*1.07, colour=group, size=value, alpha=0.2)) + # 绘制节点点
scale_colour_manual(values= mycolor) + # 设置点的颜色
scale_size_continuous( range = c(0.1,7) ) + # 设置点的大小范围
theme_void() + # 设置无主题
theme(
legend.position="none", # 不显示图例
plot.margin=unit(c(0,0,0,0),"cm"), # 设置图形边距
) +
expand_limits(x = c(-1.3, 1.3), y = c(-1.3, 1.3)) # 扩展坐标轴限制
这段代码首先加载了一些R库,然后创建了一个表示层次结构的数据框,并将其转换为边列表。接着,创建了一个顶点数据框,并计算了标签的角度和对齐方式。然后,创建了一个图对象,并准备了颜色。最后,使用ggraph库绘制了一个圆形树状图,展示了不同层级之间的关系。
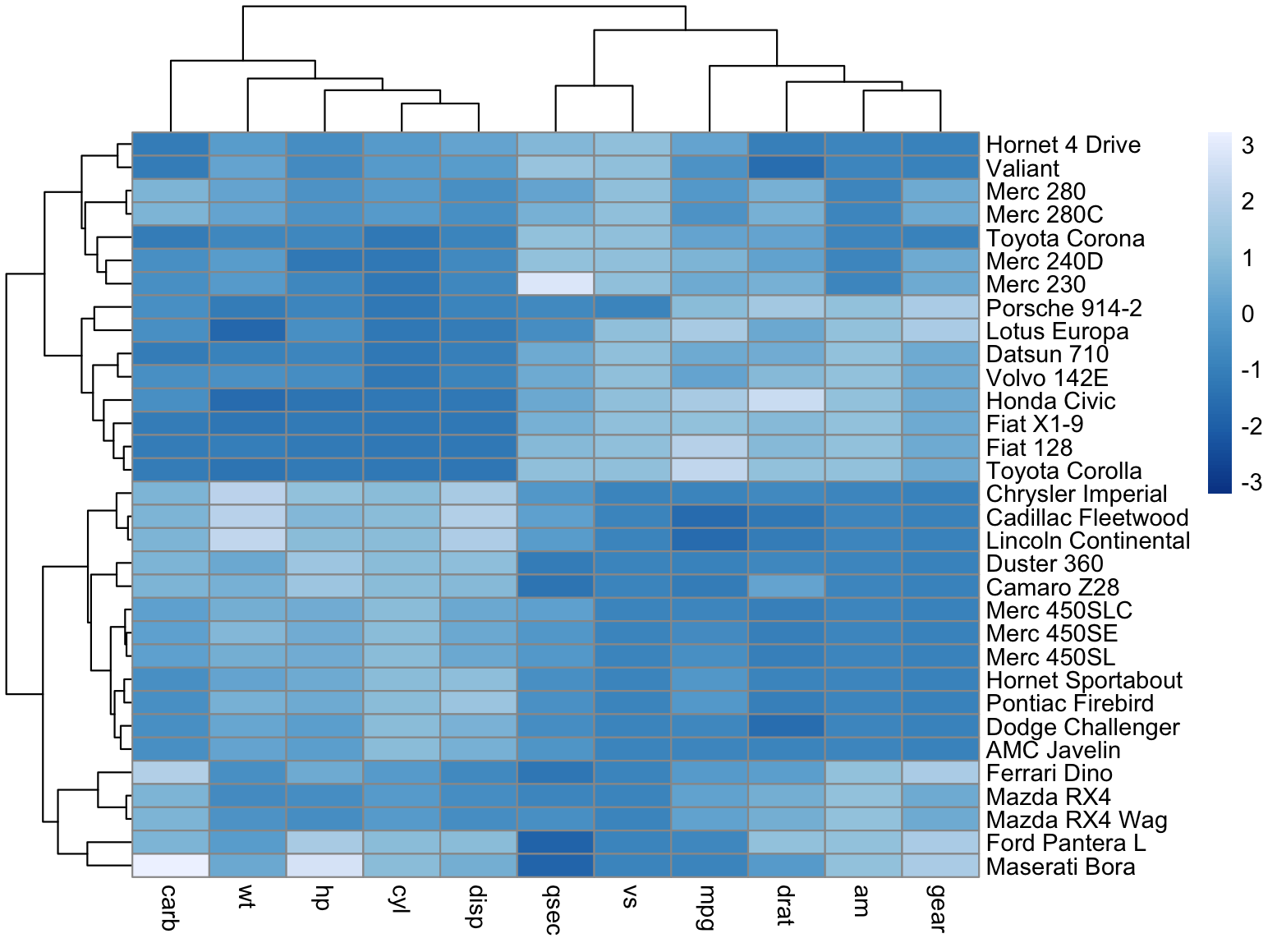
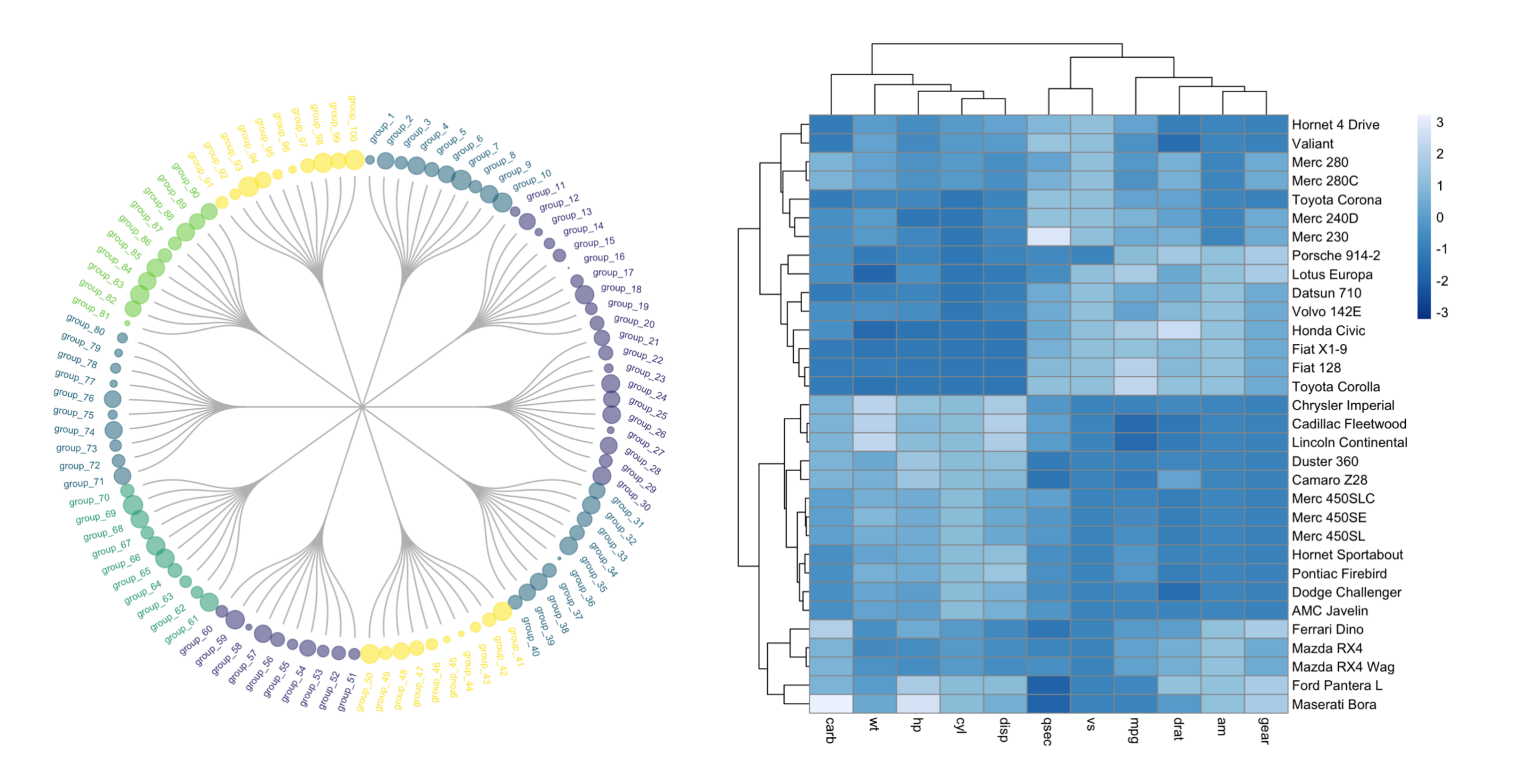
3-4:热图
另一种常见的树状图变体是在树状图底部显示热图。这种做法确实允许我们可视化每个样本之间的距离,从而理解为什么聚类算法将两个样本放在一起。
热图(heatmap)是一种使用颜色来表示数据分布的图表。在树状图底部添加热图,可以将数据点之间的距离与树状图中的聚类结果相结合,从而提供更深入的洞察。
具体来说,热图中的颜色可以代表样本之间的距离。颜色越暖(如红色)表示样本之间的距离越近,而颜色越冷(如蓝色)表示样本之间的距离越远。通过这种颜色编码,我们可以直观地看到样本是如何根据它们之间的相似性或距离被聚类在一起的。
例如,如果两个样本在树状图中相邻,我们可以通过查看它们在热图中的颜色来了解它们之间的距离非常近。相反,如果两个样本在树状图中相隔较远,我们可以通过查看它们在热图中的颜色来了解它们之间的距离较远。
这种将热图与树状图相结合的方法有助于我们更好地理解聚类结果,并识别聚类过程中可能存在的异常或异常值。通过这种方式,我们可以更全面地评估聚类算法的性能,并作出更准确的决策。
install.packages("pheatmap")
install.packages("RColorBrewer")
# 加载pheatmap库,用于创建热图
library(pheatmap)
library(RColorBrewer)
# 使用pheatmap函数创建一个热图
# 参数mtcars是一个内置的数据集,包含了32种不同汽车的信息
# scale = "column"表示按列对数据进行标准化
# color参数设置为颜色渐变方案
pheatmap(mtcars, scale = "column", color = colorRampPalette(rev(brewer.pal(n = 7, name = "Blues")))(100))