论文阅读:AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion
这是 ECCV 2024 的一篇文章,利用扩散模型实现图像恢复的任务。
Abstract
这篇文章提出了一个创新的 all-in-one 的图像恢复框架,融合了隐扩散技术,各种不同的图像退化都可以用这一个模型搞定,简称 AutoDIR。AutoDIR 模型可以自动的识别以及恢复一系列未知的图像退化。AutoDIR 提供了直观的开放式词汇图像编辑功能,使用户能够根据自己的喜好定制和增强图像。AutoDIR 由两个关键阶段组成:一个基于语义无关的视觉语言模型的盲图像质量评估(BIQA)阶段,它会自动检测输入图像中的未知图像退化类型;一个一体化图像恢复(AIR)阶段,利用结构校正的隐扩散来处理多种类型的图像退化。大量的实验评估表明,AutoDIR 在更广泛的图像恢复任务中优于当前最先进的方法。AutoDIR 的设计还能够实现灵活的用户控制(通过文本提示),并作为图像恢复的基础模型推广到新的任务中。

Introduction
文章作者探索了一种能够处理单个图像的多种未知退化的通用模型。为实现这一目标,相应的模型应具备以下能力:(1)分解和区分未知的退化类型,(2)一个与具体任务无关的框架,能够恢复各种退化,(3)理想情况下,允许用户根据自己的视觉偏好自由调整恢复结果。为解决类似问题已经有了很多相关的工作,但没有一个能够同时满足这三点。
为了能同时解决上述三个问题,文章作者提出了一个名为 AutoDIR 的流程,它满足上述所有三种能力,并且能够自动检测和恢复具有多种未知退化的图像。AutoDIR 由两个阶段组成:语义无关的盲图像质量评估(SA-BIQA)阶段和由 SA-BIQA 中生成的文本提示引导的一体化图像恢复(AIR)阶段。
在 SA-BIQA 阶段,我们能够以开放词汇的方式准确识别未知伪影情况下的每种退化。这是通过我们提出的语义无关的 CLIP(SA-CLIP)模型实现的,该模型采用了语义无关的正则化项,将原始的语义识别 CLIP 转换为语义无关的形式,重点关注图像的结构质量而非语义内容。此外,我们可以利用 SA-BIQA 阶段生成的文本嵌入作为指令来引导进一步的恢复模型。这种方法不仅能够实现有效的恢复,而且通过提供开放词汇的指令,还允许在运行时进行灵活的用户控制和编辑。
AIR 阶段是使用在广泛任务上联合训练的多任务图像恢复模型来处理退化。鉴于不同任务的多样性(例如,像超分辨率这样的一些任务需要生成纹理,但像低光增强这样的其他任务需要保留除亮度之外的一切),我们提出了一种混合方法,在通过引入额外的结构归纳偏差来保持图像结构一致性的同时,最大限度地发挥扩散模型的生成能力。
为了评估 AutoDIR 的有效性和泛化能力,我们进行了一组全面的实验,涵盖了七个图像恢复任务,包括去噪、运动去模糊、低光增强、去雾、去雨、去雨滴和超分辨率。实验结果表明,AutoDIR 始终优于当前最先进的方法。AutoDIR 还针对屏下摄像头和水下摄像头拍摄的图像恢复进行了评估,这些是具有多种未知退化的成像系统的例子。
Method

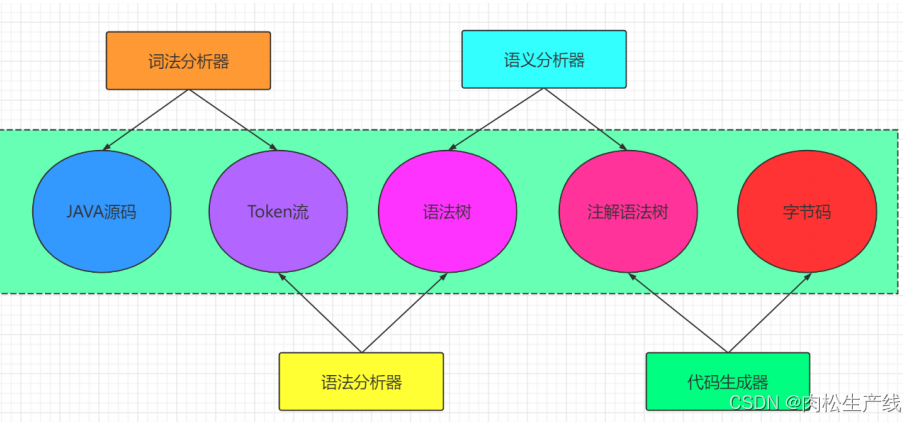
图 2 展示了所提出的 AutoDIR(具有潜在扩散的自动一体化图像恢复)的总体流程图,这是一个能够自动检测和处理图像中多种未知退化的统一模型。AutoDIR 包括两个主要阶段:
- 语义无关的盲图像质量评估(SA-BIQA):此阶段会自动识别输入图像中主要存在的退化,如噪声、模糊、雾霾,并生成相应的文本提示,记为 e a u t o e_{auto} eauto,随后在图像恢复过程中使用。
- 一体化图像恢复 (AIR):此阶段利用结构校正潜在扩散模型(SC-LDM),在来自 SA-BIQA 的文本嵌入 e a u t o e_{auto} eauto 或用户自定义的开放词汇指令 e u s e r e_{user} euser 的引导下,生成恢复后的图像 I r e s I_{res} Ires。
Semantic-Agnostic Blind Image Quality Assessment (SA-BIQA)
正如之前的工作所表明的,评估图像退化的一种常见方法是专门为此目的训练一个图像分类器。然而,这种简单的方法在处理包含广泛伪影的大型数据集时面临挑战。即使使用重型的 ViT 编码器,仅基于图像信息对图像退化进行分类的准确率也限制在 77.65%。
为了解决这一限制,我们提出利用人类语言知识来增强对图像退化的检测。我们引入了一个语义无关的 CLIP(SA-CLIP)模型作为我们盲图像质量评估(BIQA)的主干。SA-CLIP 基于 CLIP 模型构建,该模型在人类语言知识和图像质量之间建立了联系。然而,我们观察到,直接应用 CLIP 或为 BIQA 任务对其进行简单微调并不能产生可靠的结果。我们深入研究了这个问题,并找出了这个问题背后的原因。预训练的 CLIP 模型主要是为视觉识别任务而训练的,这些任务优先考虑语义信息而不是图像质量。因此,它在 BIQA 任务中的准确率较低。例如,该模型可能难以区分低光的狗图像和有噪点的狗图像,因为它更关注 “狗” 的方面,而不是噪声或光照的存在。
为了克服这个问题,我们分两步解决:(i)我们为微调 CLIP 构建了一个新的图像质量评估任务。(ii)我们提出了一个新的正则化项,用于语义无关和图像质量感知的训练,以导出 SA-CLIP 模型。
如图 2 所示,假设 C \mathcal{C} C 表示文章中考虑的图像退化类型的集合, C = { c 1 , c 2 , . . . , c K − 1 , c K } \mathcal{C}=\{c_1, c_2, ..., c_{K-1}, c_K \} C={c1,c2,...,cK−1,cK},其中 c i c_i ci 表示某种退化类型, K − 1 K-1 K−1 表示总的退化类型的数量,我们还添加了一种特殊类型 c K = " n o " c_K = "no" cK="no" 表示多步图像恢复的结束标识。文本提示描述集 T = { T ∣ T = "A photo needs ci artifact reduction , c ∈ C } \mathcal{T}=\{T|T = \text{"A photo needs ci artifact reduction}, c \in \mathcal{C} \} T={T∣T="A photo needs ci artifact reduction,c∈C}。给定一张包含了若干未知伪影的受损图像 I I I,我们的语义无关 CLIP 旨在识别 I I I 的主要退化并提取相应的文本嵌入。SA-CLIP 包含一个图像编码器 ε I \varepsilon_{I} εI 和一个文本编码器 ε T \varepsilon_{T} εT。首先获得图像嵌入 ε I ∈ R d \varepsilon_{I} \in \mathbb{R}^{d} εI∈Rd 和文本嵌入 ε T ∈ R K × d \varepsilon_{T} \in \mathbb{R}^{K \times d} εT∈RK×d,然后计算图像嵌入与每个文本嵌入的余弦相似度。
logit ( c i ∣ I ) = ε I ( I ) ⋅ ε T ( T i ) ∥ ε I ( I ) ∥ 2 ∥ ε T ( T ) ∥ 2 (1) \text{logit}(c_i | I) = \frac{ \varepsilon_{I}(I) \cdot \varepsilon_{T}(T_i) }{\left \| \varepsilon_{I}(I) \right \|_2 \left \| \varepsilon_{T}(T) \right \|_2 } \tag{1} logit(ci∣I)=∥εI(I)∥2∥εT(T)∥2εI(I)⋅εT(Ti)(1)
其中, T i T_i Ti 表示第 i i i 个文本嵌入,对计算得到的余弦相似度用 softmax 计算每个相似度量的概率 p ^ ( c i ∣ I ) \hat{p}(c_i | I) p^(ci∣I):
p ^ ( c i ∣ I ) = exp ( logit ( c i ∣ I ) ) ∑ i = 1 K exp ( logit ( c i ∣ I ) ) (2) \hat{p}(c_i|I) = \frac{\exp(\text{logit}(c_i | I))}{\sum_{i=1}^{K} \exp(\text{logit}(c_i | I))} \tag{2} p^(ci∣I)=∑i=1Kexp(logit(ci∣I))exp(logit(ci∣I))(2)
e a u t o = ∑ i = 1 K p ^ ( c i ∣ I ) ε T ( T i ) (3) e_{auto} = \sum_{i=1}^{K} \hat{p}(c_i | I) \varepsilon_{T}(T_i) \tag{3} eauto=i=1∑Kp^(ci∣I)εT(Ti)(3)
图像质量评估的简单微调,在 CLIP 模型的优化期间,我们冻结文本编码器 ε T \varepsilon_{T} εT 的参数,并使用多类别保真度损失微调图像编码器 ε I \varepsilon_{I} εI。保真度损失可以表示为:
L F I D = 1 − ∑ i = 1 K y ( c i ∣ I ) p ^ ( c i ∣ I ) (4) L_{FID} = 1 - \sum_{i=1}^{K} \sqrt{y(c_i | I) \hat{p}(c_i | I)} \tag{4} LFID=1−i=1∑Ky(ci∣I)p^(ci∣I)(4)
其中, y ( c i ∣ I ) y(c_i | I) y(ci∣I) 表示一个二分类的变量,如果某个退化类型占主导,那么该变量值为 1,否则为 0 。
图像质量评估的语义无关约束微调,由于原始的 CLIP 模型是在诸如图像分类等任务上进行预训练的,其相应的
ε
I
\varepsilon_{I}
εI 编码器倾向于根据图像的语义信息(例如,猫或狗)而不是图像质量(例如,有噪点或清晰)对图像进行编码。当我们根据图像质量微调 CLIP 模型以生成用于 BIQA 的文本时,这成为一个显著的限制。如图 3 a)和 b)所示,由原始 CLIP 和在有雾图像上微调的 CLIP 提取的图像嵌入,以及它们相应的真实干净图像,无法分开,这表明其重点在于语义信息而非图像质量差异。

为了解决这个问题,我们提出了一种称为语义无关约束损失 L S A L_{SA} LSA 的新方法来规范微调过程,并防止模型仅仅依赖语义信息而非图像质量。当 CLIP 模型表明在真实干净图像 I g t I_{gt} Igt(对应于退化图像 I I I)中存在伪影 c i c_i ci 时,语义无关损失 L S A L_{SA} LSA 会施加惩罚。这种惩罚迫使 CLIP 模型根据图像质量区分 I g t I_{gt} Igt 和 I I I,鼓励 CLIP 图像编码器 ε I \varepsilon_{I} εI 专注于提取图像质量信息而非语义信息。这种约束损失可以通过以下等式推导得出:
L S A = ∑ i = 1 K y ( c i ∣ I ) p ^ ( c i ∣ I g t ) (5) L_{SA} = \sum_{i=1}^{K} \sqrt{y(c_i | I)\hat{p}(c_i | I_{gt})} \tag{5} LSA=i=1∑Ky(ci∣I)p^(ci∣Igt)(5)
将 L S A L_{SA} LSA 与 L F I D L_{FID} LFID 结合,得到最终的微调 loss:
L B I Q A = L F I D + λ L S A (6) L_{BIQA} = L_{FID} + \lambda L_{SA} \tag{6} LBIQA=LFID+λLSA(6)
All-in-one Image Restoration (AIR)
一体化图像恢复(AIR)阶段旨在在一个共享的框架中处理多种退化。基于扩散的生成模型的最新进展已经展示了它们生成多样化图像的卓越能力,使其适用于多任务图像恢复。先前的研究已经表明,生成模型具有生成缺失或扭曲细节的卓越能力,特别是对于需要虚构的任务,例如超分辨率。基于这些见解,我们基于隐扩散模型(LDM)进行 AIR 阶段。LDM 结合了文本和图像嵌入条件,使用生成先验来恢复图像 I s d I_{sd} Isd。文本嵌入条件 e = { e a u t o , e u s e r } e = \{ e_{auto}, e_{user} \} e={eauto,euser} 旨在区分不同类型的图像退化,而来自 LDM 的图像编码器 ε l d m \varepsilon_{ldm} εldm 的潜在图像嵌入条件 z I = ε l d m ( I ) z_{I} = \varepsilon_{ldm}(I) zI=εldm(I) 提供了结构信息。
然而,尽管基于 LDM 的生成模型可以为多任务图像恢复提供基础,但由于具有变分自编码器(VAE)的压缩重建过程,它们在重建具有复杂和小结构的图像方面存在局限性,有工作试图通过在特定类别的图像(例如,人脸)上重新训练变分自编码器(VAE)网络以学习专门的概率分布来减少压缩重建过程引起的失真。然而,由于图像内容的多样性,这种方法不适用于图像恢复任务。为了解决这些限制,我们向 LDM 引入了一个轻量级的插件式结构校正模块,增强了其在图像恢复期间处理复杂和小结构的能力。
结构校正潜在扩散模型(SC-LDM), 虽然基于 LDM 的生成模型可以为多任务图像恢复提供基础,但人们普遍注意到它们可能无法保持原始图像结构,例如人脸和文本,如图 4 所示。为了解决结构失真问题,我们采用了一个有效的结构校正模块(SCM),记为 F \mathcal{F} F。SCM 的目的是以残差的方式从原始图像中提取上下文信息 R \mathcal{R} R,并将其与中间图像恢复结果 I s d I_{sd} Isd 相结合。这通过以下等式实现

I r e s = I s d + w ⋅ F ( [ I s d , I ] ) (7) I_{res} = I_{sd} + w \cdot \mathcal{F}([I_{sd}, I]) \tag{7} Ires=Isd+w⋅F([Isd,I])(7)
其中 [ ] 表示连接,并且 w 是一个可调节系数,其范围在 0 到 1 之间。w 的值决定了利用上下文信息来恢复最终结果的程度。w 的值较大时强调上下文信息的使用,这对于需要结构一致性的任务(例如低光增强)是有益的。相反,w 的值较小时通常用于保持潜在扩散模型对于像超分辨率这样的任务的生成能力。通过集成 SCM,AutoDIR 有效地恢复了原始图像的失真上下文,如 图 4 所示,无缝地整合了在编辑阶段所做的增强。
在训练阶段,我们为图像恢复任务对潜在扩散模型(LDM)的 UNet 的 backbone ϵ θ ( e , [ z t , z I ] , t ) \epsilon_{\theta}(e, [z_t, z_{I}], t) ϵθ(e,[zt,zI],t) 进行微调,其目标函数为:
L L D = E ε l d m ( x ) , c I , e , ϵ , t [ ∥ ϵ − ϵ θ ( e , [ z t , z I ] , t ) ∥ 2 2 ] (8) L_{LD} = \mathbb{E}_{\varepsilon_{ldm}(x), c_I, e, \epsilon, t} [ \left \| \epsilon - \epsilon_{\theta}(e, [z_t, z_{I}], t) \right \|_{2}^{2} ] \tag{8} LLD=Eεldm(x),cI,e,ϵ,t[∥ϵ−ϵθ(e,[zt,zI],t)∥22](8)
对于结构校正潜在扩散模型(SC-LDM),我们不使用耗时的完整逆向采样过程来生成编辑后的隐变量 z ^ t \hat{z}_t z^t,而是利用通过以下方式计算得到的估计编辑后的隐变量 z ~ \tilde{z} z~:
z ~ = z t α ˉ − 1 − α ˉ ( ϵ θ ( e , [ z t , z I ] , t ) ) α ˉ (9) \tilde{z} = \frac{z_t}{\sqrt{\bar{\alpha}}} - \frac{\sqrt{1 - \bar{\alpha}}( \epsilon_{\theta}(e, [z_t, z_{I}], t) )}{\sqrt{\bar{\alpha}}} \tag{9} z~=αˉzt−αˉ1−αˉ(ϵθ(e,[zt,zI],t))(9)
其中 α \alpha α 表示引入的噪声调度器。结构校正潜在扩散模型(SC-LDM)的损失函数进一步定义为:
L A I R = ∥ I g t − ( F ( D ( z ~ ) , I ) + D ( z ~ ) ) ∥ (10) L_{AIR} = \left \| I_{gt} - (\mathcal{F}(\mathcal{D}(\tilde{z}), I) + \mathcal{D}(\tilde{z}) ) \right \| \tag{10} LAIR=∥Igt−(F(D(z~),I)+D(z~))∥(10)
处理多任务图像恢复的机制,
图 5 展示了我们在逆向扩散过程中探索文本条件解开不同图像恢复任务机制的实验。我们发现不同的文本条件会产生不同的交叉注意力图。如图 5 所示,改变文本提示会导致交叉注意力图发生显著变化。该图与文本提示紧密对齐,对于 “去雾” 提示,注意力在整个图像上均匀分布;对于 “低分辨率” 提示,注意力集中在具有边缘或纹理的部分;对于 “去雨滴” 提示,注意力集中在诸如雨滴等特定区域。这表明 AutoDIR 可以将扩散注意力引导到更有可能存在图像伪影的区域。