图像渲染流水线(图像渲染流程)
图像渲染流程大致分为四个部分:

- Application 应用处理阶段:得到图元
- Geometry 几何处理阶段:处理图元
- Rasterization 光栅化阶段:图元转换为像素
- Pixel 像素处理阶段:处理像素,得到位图
除了Application阶段由 CPU 负责,后续都是由GPU负责
Application 应用处理阶段:得到图元
这个阶段具体指的就是图像在应用中被处理的阶段,此时还处于 CPU 负责的时期。在这个阶段应用可能会对图像进行一系列的操作或者改变,最终将新的图像信息传给下一阶段。这部分信息被叫做图元(primitives)
图元就是描述几何形状的基本元素,通常是三角形、线段、顶点等。
Geometry 几何处理阶段:处理图元
进入这个阶段之后,以及之后的阶段,就都主要由 GPU 负责了。此时 GPU 可以拿到上一个阶段传递下来的图元信息,GPU 会对这部分图元通过顶点着色器、形状装配、几何着色器进行处理,之后输出新的图元。这一系列阶段包括:
- 顶点着色器(Vertex Shader):这个阶段中会将图元中的顶点信息进行视角转换、添加光照信息、增加纹理等操作。
- 形状装配(Shape Assembly):图元中的三角形、线段、点分别对应三个 Vertex、两个 Vertex、一个 Vertex。这个阶段会将 Vertex 连接成相对应的形状。
- 几何着色器(Geometry Shader):额外添加额外的Vertex,将原始图元转换成新图元,以构建一个不一样的模型。简单来说就是基于通过三角形、线段和点构建更复杂的几何图形。
Rasterization 光栅化阶段:图元转换为像素
光栅化的主要目的是将几何渲染之后的图元信息,转换为一系列的像素,以便后续显示在屏幕上。
工作原理就是会根据图元信息,计算出每个图元所覆盖的像素信息等,从而将像素划分成不同的部分

一种简单的划分就是根据中心点,如果像素的中心点在图元内部,那么这个像素就属于这个图元。
Pixel 像素处理阶段:处理像素,得到位图
经过上述光栅化阶段,我们得到了图元所对应的像素,之后我们需要通过片段着色器(给每一个像素 Pixel 赋予正确的颜色)和测试与混合(处理片段的前后位置以及透明度)给这些像素填充正确的颜色和效果得到位图(bitmap)以便最终显示到屏幕上。
这些经过处理、蕴含大量信息的像素点集合,被称作位图
- 片段着色器(Fragment Shader):也叫做 Pixel Shader,这个阶段的目的是给每一个像素 Pixel 赋予正确的颜色。颜色的来源就是之前得到的顶点、纹理、光照等信息。由于需要处理纹理、光照等复杂信息,所以这通常是整个系统的性能瓶颈。
- 测试与混合(Tests and Blending):也叫做 Merging 阶段,这个阶段主要处理片段的前后位置以及透明度。这个阶段会检测各个着色片段的深度值 z 坐标,从而判断片段的前后位置,以及是否应该被舍弃。同时也会计算相应的透明度 alpha 值,从而进行片段的混合,得到最终的颜色。
屏幕成像原理
屏幕成像就是将先前图像渲染结束后得到的像素信息也就是位图显示在屏幕上。
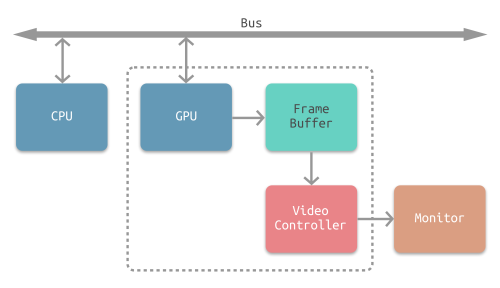
- 首先GPU将渲染结束后得到的位图存到帧缓存区(Framebuffer)中
- 之后视频控制器(Video Controller)会读取帧缓冲器中的信息,经过数模转换传递给显示器(Monitor)
- 显示器的电子束会从屏幕的左上角开始逐行扫描,屏幕上的每个点的图像信息都从帧缓冲器中的位图进行读取,在屏幕上对应地显示。
- 电子束扫描的过程中,屏幕就能呈现出对应的结果,每次整个屏幕被扫描完一次后,就相当于呈现了一帧完整的图像。屏幕不断地刷新,不停呈现新的帧,就能呈现出连续的影像。(而这个屏幕刷新的频率,就是帧率)
由于人眼的视觉暂留效应,当屏幕刷新频率足够高时(FPS 通常是 50 到 60 左右),就能让画面看起来是连续而流畅的。对于 iOS 而言,app 应该尽量保证 60 FPS 才是最好的体验。
画面撕裂与卡顿
画面撕裂
如果在电子束开始扫描新的一帧时,位图还没有渲染好,而是在扫描到屏幕中间时才渲染完成,被放入帧缓冲器中,那么已扫描的部分就是上一帧的画面,而未扫描的部分则会显示新的一帧图像,这就造成画面撕裂。
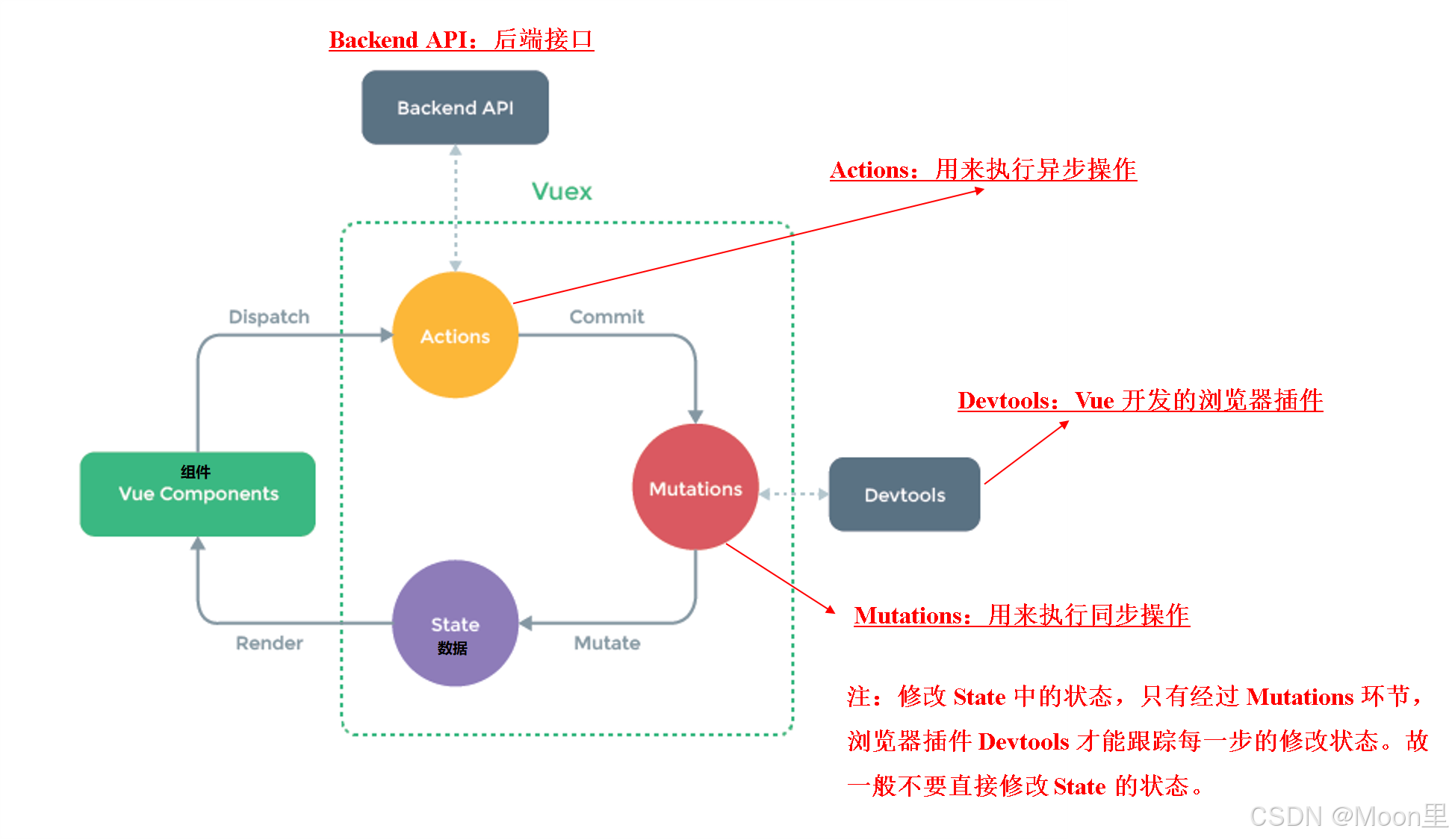
垂直同步 Vsync + 双缓冲机制 Double Buffering
iOS中使用垂直同步+双缓存机制解决画面撕裂问题。
垂直同步信号相当于给帧缓冲器加锁:当电子束完成一帧的扫描,将要从头开始扫描时,就会发出一个垂直同步信号。只有当视频控制器接收到垂直同步信号之后,才会将帧缓冲器中的位图更新为下一帧,这样就能保证每次显示的都是同一帧的画面,因而避免了屏幕撕裂。但是这种情况下,视频控制器在接受到 垂直同步信号 之后,就要将下一帧的位图传入,这意味着整个 CPU+GPU 的渲染流程都要在一瞬间完成,这是明显不现实的。于是提出双缓存机制
双缓冲机制会增加一个新的备用缓冲器(back buffer)。位图会预先保存在 back buffer 中,在接收到垂直同步信号的时候,视频控制器会将 back buffer 中的内容置换到 frame buffer 中,此时就能保证置换操作几乎在一瞬间完成(实际上是交换了内存地址)。
掉帧
启用 垂直同步信号以及双缓冲机制会导致掉帧。
如果在接收到垂直同步信号时 CPU 和 GPU 还没有渲染好新的位图存到back buffer中,视频控制器就不会去替换 frame buffer 中的位图。这时屏幕就会重新扫描呈现出上一帧一模一样的画面。相当于两个周期显示了同样的画面,这就是所谓掉帧的情况。
三缓冲 Triple Buffering
在发生掉帧的时候,CPU 和 GPU 有一段时间处于闲置状态(比如当 A 的内容正在被扫描显示在屏幕上,而 B 的内容已经被渲染好,此时 CPU 和 GPU 就处于闲置状态)。那么如果我们增加一个帧缓冲器,就可以利用这段时间进行下一步的渲染,并将渲染结果暂存于新增的帧缓冲器中。由于增加了新的帧缓冲器,可以一定程度上地利用掉帧的空档期,合理利用 CPU 和 GPU 性能,从而减少掉帧的次数。
iOS 中的渲染框架

iOS 的渲染框架依然符合渲染流水线的基本架构,iOS 中有 Core Graphics、Core Animation、Core Image、OpenGL 等多种软件框架来绘制内容,在 CPU 与 GPU 之间进行了更高层地封装。
-
GPU Driver:直接和CPU交流的代码块,直接与CPU连接。所有框架最终都会通过OpenGL连接到GPU Driver
-
OpenGL:是一个提供了 2D 和 3D 图形渲染的 API,它能和 GPU 密切的配合,最高效地利用 GPU 的能力,实现硬件加速渲染。
-
Metal:Metal 类似于 OpenGL ES,也是一套第三方标准,具体实现由苹果实现。Core Animation、Core Image、SceneKit、SpriteKit 等等渲染框架都是构建于 Metal 之上的。
-
Core Graphics:Core Graphics 是一个强大的二维图像绘制引擎,是 iOS 的核心图形库,常用的比如 CGRect 就定义在这个框架下。
-
Core Animation:可以理解为一个复合引擎,是 app 界面渲染和构建的最基础架构。主要职责包含:渲染、构建和实现动画。在 iOS 上,几乎所有的东西都是通过 Core Animation 绘制出来,它的自由度更高,使用范围也更广。
Core Animation 的职责就是尽可能快地组合屏幕上不同的可视内容,这个内容是被分解成独立的 layer(iOS 中具体而言就是 CALayer),并且被存储为树状层级结构。这个树也形成了 UIKit 以及在 iOS 应用程序当中你所能在屏幕上看见的一切的基础。
- Core Image:Core Image 是一个高性能的图像处理分析的框架,它拥有一系列现成的图像滤镜,能对已存在的图像进行高效的处理。
内容显示——CALayer
iOS中UIView时app的基本组成结构,UIView本身不具备显示内容的作用,只负责响应用户事件,每创建一个UIView都会自动创建一个CALayer,,并将自身固定设置为 CALayer 的代理。
用户能看到的屏幕上的内容都由 CALayer 进行管理,CALayer中有contents属性保存了由设备渲染流水线渲染好的位图 bitmap(通常也被称为 backing store),而当设备屏幕进行刷新时,会从 CALayer 中读取生成好的 bitmap,进而呈现到屏幕上。
也正因为每次要被渲染的内容是被静态的存储起来的,所以每次渲染时,Core Animation 会触发调用 drawRect: 方法,使用存储好的 bitmap 进行新一轮的展示。
Core Animation 渲染全内容
Core Animation Pipeline 渲染流水线

整个流水线一共有下面几个步骤:
- Handle Events:这个过程中会先处理点击事件,这个过程中有可能会需要改变页面的布局和界面层次。
- Commit Transaction:此时 app 会通过 CPU 处理显示内容的前置计算,比如布局计算、图片解码等任务。之后将计算好的图层进行打包发给
Render Server。 - Decode:打包好的图层被传输到
Render Server之后,首先会进行解码。注意完成解码之后需要等待下一个 RunLoop 才会执行下一步Draw Calls。 - Draw Calls:解码完成后,Core Animation 会调用下层渲染框架(比如 OpenGL 或者 Metal)的方法进行绘制,进而调用到 GPU。
- Render:这一阶段主要由 GPU 进行渲染。
- Display:显示阶段,需要等
render结束的下一个 RunLoop 触发显示。
Commit Transaction 发生了什么
一般开发当中能影响到的就是 Handle Events 和 Commit Transaction 这两个阶段。Commit Transaction 这部分中主要进行的是:Layout(处理视图的构建和布局,由CPU负责)、Display( Core Graphics 进行视图的绘制得到图元数据)、Prepare(图片的解码和转换)、Commit(图层打包发送到Rander Server) 等四个具体的操作。
Layout:构建视图
这个阶段主要处理视图的构建和布局,具体步骤包括:
- 调用重载的
layoutSubviews方法 - 创建视图,并通过
addSubview方法添加子视图 - 计算视图布局,即所有的 Layout Constraint
Display:绘制视图
这个阶段主要是交给 Core Graphics 进行视图的绘制(注意不是真正的显示)得到图元数据:
- 根据上一阶段 Layout 的结果创建得到图元信息。
- 如果重写了
drawRect:方法,那么会调用重载的drawRect:方法,在drawRect:方法中手动绘制得到 bitmap 数据,从而自定义视图的绘制。
正常情况下 Display 阶段只会得到图元信息,但是如果重写了 drawRect: 方法,这个方法会直接调用 Core Graphics 绘制方法得到 bitmap 数据,同时系统会额外申请一块内存,用于暂存绘制好的 bitmap。
由于重写了 drawRect: 方法,导致绘制过程从 GPU 转移到了 CPU,这就导致了一定的效率损失。与此同时,这个过程会额外使用 CPU 和内存,因此需要高效绘制,否则容易造成 CPU 卡顿或者内存爆炸。
Prepare:Core Animation 额外的工作
主要进行图片解码和转换
Commit:打包并发送
这一步主要是:图层打包并发送到 Render Server。
注意 commit 操作是依赖图层树递归执行的,所以如果图层树过于复杂,commit 的开销就会很大。这也是我们希望减少视图层级,从而降低图层树复杂度的原因。
Rendering Pass:Render Server 的具体操作
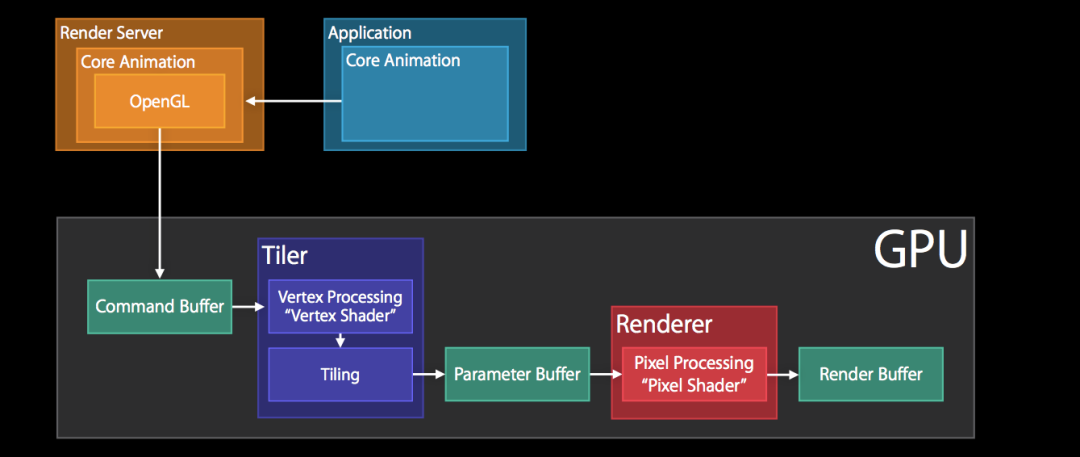
Render Server 通常是 OpenGL 或者是 Metal。
如果是OpenGL的话,么上图主要是 GPU 中执行的操作,具体主要包括:
- GPU收到包含图元信息的Command Buffer
- Tiler 开始工作:先通过顶点着色器 Vertex Shader 对顶点进行处理,更新图元信息
- 平铺过程:平铺生成 tile bucket 的几何图形,这一步会将图元信息转化为像素,之后将结果写入 Parameter Buffer 中
- Tiler 更新完所有的图元信息,或者 Parameter Buffer 已满,则会开始下一步
- Renderer 工作:将像素信息进行处理得到 bitmap,之后存入 Render Buffer
- Render Buffer 中存储有渲染好的 bitmap,供之后的 Display 操作使用
离屏渲染
通常的渲染流程是:CPU和GPU负责内容渲染流程,接着将得到的位图放入帧缓存区(frame buffer)中,而显示屏幕不断地从 Framebuffer 中获取内容,显示实时的内容

离屏渲染的流程是:先额外创建离屏渲染缓冲区 Offscreen Buffer,将提前渲染好的内容放入其中,等到合适的时机再将 Offscreen Buffer 中的内容进一步叠加、渲染,完成后将结果切换到 Framebuffer 中

离屏渲染的效率问题
离屏渲染的耗时操作主要体现在需要提前对部分内容进行额外的渲染并保存到 Offscreen Buffer,以及需要在必要时刻对 Offscreen Buffer 和 Framebuffer 进行内容切换
并且 Offscreen Buffer 本身就需要额外的空间,大量的离屏渲染可能早能内存的过大压力。与此同时,Offscreen Buffer 的总大小也有限,不能超过屏幕总像素的 2.5 倍。
一旦需要离屏渲染的内容过多,很容易造成掉帧的问题
离屏渲染的优点
- 一些特殊效果比如阴影和圆角等,需要使用额外的 Offscreen Buffer 来保存渲染的中间状态,所以不得不使用离屏渲染。
- 可以将内容提前渲染保存在 Offscreen Buffer 中,达到复用的目的。
对于第一种情况,一般都是系统自动触发的。比如使用了mask蒙版利用额外的内存空间保存中间的渲染结果来实现将两层渲染结果叠加。
而第二种情况,为了复用提高效率而使用离屏渲染一般是主动的行为,是通过 CALayer 的 shouldRasterize 光栅化操作实现的。
shouldRasterize 光栅化
开启光栅化后,会触发离屏渲染,Render Server 会强制将 CALayer 的渲染位图结果 bitmap 保存下来,这样下次再需要渲染时就可以直接复用,从而提高效率。
而保存的 bitmap 包含 layer 的 subLayer、圆角、阴影、组透明度 group opacity 等,所以如果 layer 的构成包含上述几种元素,结构复杂且需要反复利用,那么就可以考虑打开光栅化。这样可以节约第二次以后的渲染时间。
不过使用光栅化的时候需要注意以下几点:
- 如果 layer 不能被复用,则没有必要打开光栅化
- 如果 layer 不是静态,需要被频繁修改,比如处于动画之中,那么开启离屏渲染反而影响效率
- 离屏渲染缓存内容有时间限制,缓存内容 100ms 内如果没有被使用,那么就会被丢弃,无法进行复用
- 离屏渲染缓存空间有限,超过 2.5 倍屏幕像素大小的话也会失效,无法复用
圆角的离屏渲染
如果只是设置了 layer的cornerRadius 而没有设置 masksToBounds,由于不需要叠加裁剪,此时是并不会触发离屏渲染的。而当设置了裁剪属性的时候,由于 masksToBounds 会对 layer 以及所有 subLayer 的 content 都进行裁剪,所以不得不触发离屏渲染。
离屏渲染的具体逻辑
图层的叠加绘制大概遵循“画家算法”,在这种算法下会按层绘制,首先绘制距离较远的场景,然后用绘制距离较近的场景覆盖较远的部分。

在普通的layer绘制中,上层的 sublayer 会覆盖下层的 sublayer,下层 sublayer 绘制完之后就可以抛弃了。所有 sublayer 依次绘制完毕之后,整个绘制过程完成,就可以进行后续的呈现了。

如设置了 cornerRadius 以及 masksToBounds 进行圆角 + 裁剪时,masksToBounds 裁剪属性会应用到所有的 sublayer 上,也就是说所有的sublayer在第一次被绘制之后不能被立刻丢弃还需要被保存在 Offscreen buffer 中等待下一轮圆角+裁剪,这也就诱发了离屏渲染。

实际上不只是圆角+裁剪,如果设置了透明度+组透明(layer.allowsGroupOpacity+layer.opacity),阴影属性(shadowOffset 等)都会产生类似的效果,因为组透明度、阴影都是和裁剪类似的,会作用与 layer 以及其所有 sublayer 上,这就导致必然会引起离屏渲染。
离屏渲染的本质原因就是裁剪的叠加导致了对layer和所有的sublayer进行了二次处理。
下面这些情况都会触发离屏渲染:
- 使用了 mask 的 layer (
layer.mask) - 需要进行裁剪的 layer (
layer.masksToBounds/view.clipsToBounds) - 设置了组透明度为 YES,并且透明度不为 1 的 layer (
layer.allowsGroupOpacity/layer.opacity) - 添加了投影的 layer (
layer.shadow*) - 采用了光栅化的 layer (
layer.shouldRasterize) - 绘制了文字的 layer (
UILabel,CATextLayer,Core Text等)
不过,需要注意的是,重写
drawRect:方法并不会触发离屏渲染。前文中我们提到过,重写drawRect:会将 GPU 中的渲染操作转移到 CPU 中完成,并且需要额外开辟内存空间。这和标准意义上的离屏渲染并不一样
避免圆角离屏渲染
只要避免使用 masksToBounds 进行二次处理,而是对所有的 sublayer 进行预处理,就可以只进行“画家算法”,用一次叠加就完成绘制。
那么可行的实现方法大概有下面几种:
- 用带圆角的图片或者替换背景色为带圆角的纯色背景图。
- 用贝塞尔曲线绘制闭合带圆角的矩形,在上下文中设置只有内部可见,再将不带圆角的 layer 渲染成图片,添加到贝塞尔矩形中
- 重写
drawRect:,用 CoreGraphics 相关方法,在需要应用圆角时进行手动绘制