目录
一、前期准备
1.Scikit-learn
2.matplotlib
二、机器学习过程
三、代码框架
四、完整代码
1.导入所需库
2.准备训练数据
3.喂入训练数据
4.结果预测
5.输出模型中的w与b值
6.可视化
7.传入不规则数据
一、前期准备
在机器学习中我们使用Python居多,这里就不写Python的安装步骤了。这里主要讲跑机器学习需要用到的库。
1.Scikit-learn
这是一个机器学习库之一,是基于 Python 语言实现的机器学习算法库,它包含了常用的机器学习算法,比如回归、分类、聚类、支持向量机、随机森林等等。同时,它使用 NumPy 库进行高效的科学计算,比如线性代数、矩阵等等。
在Windows搜索栏搜索“cmd”进入命令指示栏窗口,在其中输入如下代码:
pip install scikit-learn
敲击回车就可以看到cmd在自动下载内容。
2.matplotlib
matplotlib是可视化绘图工具包,与上述一致,在cmd中输入
pip install matplotlib
并敲击回车,等待下载完成。
二、机器学习过程
“回归模型”其实就是指通过一个给定的数据集来预测值的模型,比较类似于初中时的给几对(x,y)数据求函数表达式,并依据表达式预测出剩余x所对应的y。
例如:这里有(1,3)、(2,5)两个点,要求(3,?)的问号值。这个题给初中生甚至小学生都会做,但我们还是需要捋清楚我们的解题步骤:
第一步,设定函数。在做此题时我们会先设一个函数y=kx+b。这个过程在机器学习中被称为假设函数。
第二步,解出k、b的值。在设好函数后,我们会将已知的两个数据(1,3)、(2,5)代入方程中,通过消元法解出k、b的值。在机器学习中,(1,3)、(2,5)这两个点称为数据集,将处理好的数据集喂给模型,模型就能自动解出k、b。解决线性回归问题的关键就在于求出这些值。
第三步,将(3,?)代入解出的函数中,求出?的值。
没错,实际上机器学习的回归模型就是一个不停解出系数的过程。只不过在实际应用中,我们需要的自变量不只x一个,而是有很多个,所以真正的假设函数长这个样子:
这里,我们的自变量将不只一个,而是有很多个,自变量前面的字母也不是k,而是,它的含义是权值,权值系数越大,那么这一项属性值对最终结果的影响就越大。
而且,问号的值也不会是确定的,而是需要根据结果不断调整参数,达到预测的目的。
三、代码框架
使用Scikit-learn(以下简称sklearn)实现线性回归算法主要分为三步:
1.从库中导入线性回归算法:
from sklearn import linear_model
2.使用fit()喂入数据,训练模型:
model = linear_model.LinearRegression()
model.fit(x, y)
3.对训练好的模型进行预测,调用predict()输出预测结果,“x_”为预测数据:
model.predict(x_)
没错,它就像看起来那样简单。
四、完整代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
x = np.linspace(3,6.4)
y = 3 * x + 2
x=[[i] for i in x]
y=[[i] for i in y]
model=linear_model.LinearRegression()
model.fit(x,y)
x_=[[4],[5],[6]]
y_=model.predict(x_)
print(y_)
print("w值为:",model.coef_)
print("b截距值为:",model.intercept_)
plt.scatter(x,y)
plt.plot(x_,y_,color="red",linewidth=3.0,linestyle="-")
plt.legend(["func","Data"],loc=0)
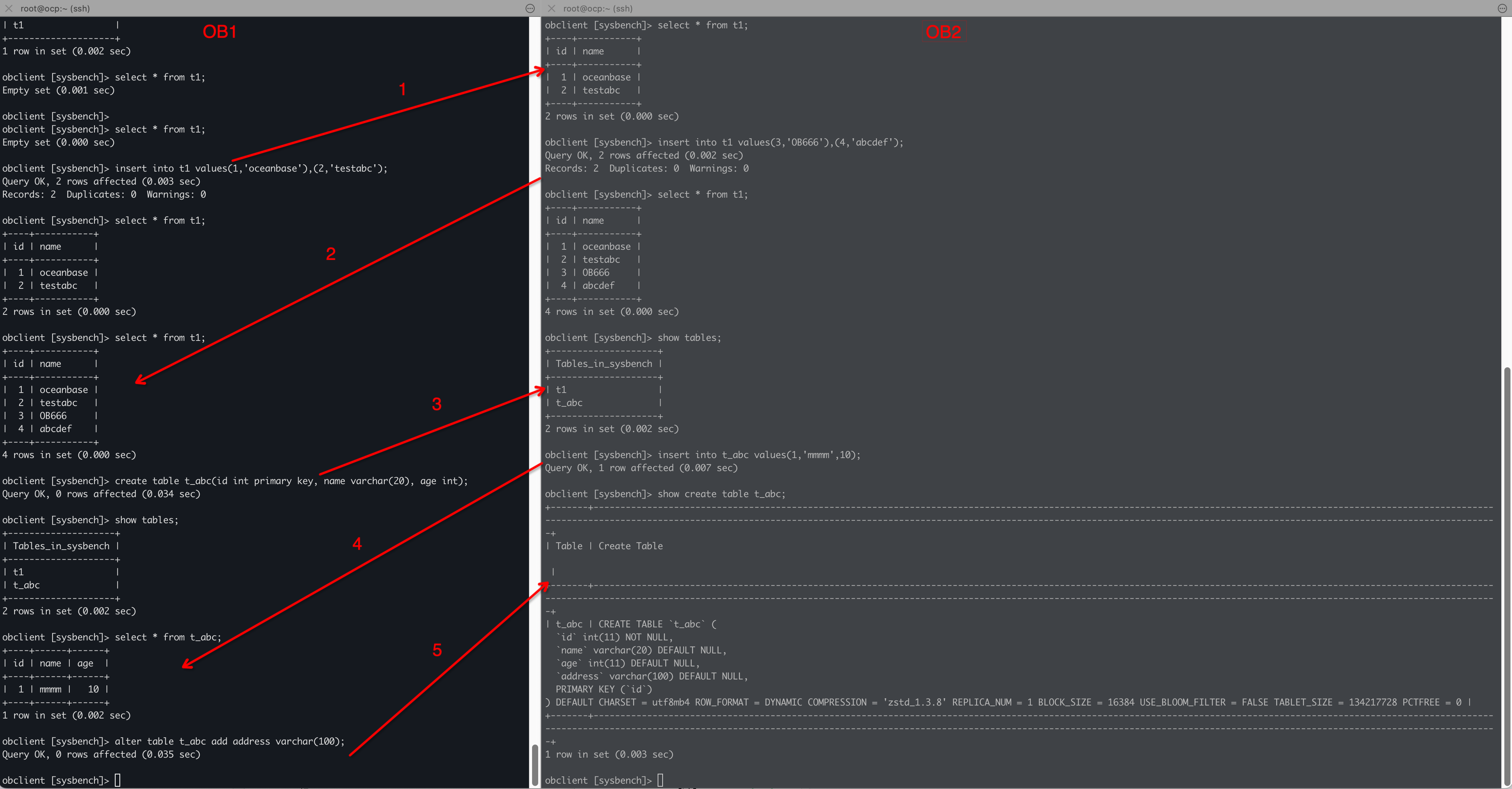
plt.show()运行结果:

输出:

详细讲解如下:
1.导入所需库
这个没什么好讲的,就是把库导入进来:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model2.准备训练数据
x = np.linspace(3,6.4)
y = 3 * x + 2这里,linspace()函数是numpy库里的生成等间隔数字序列的函数,函数原型如下:
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
这个函数最少需要传入两个函数,“start”是序列的起始值,“stop”是序列结束值,如果后面的“endpoint”参数为True,则将结束值包含在序列中,否则不包含。“num”是生成的样本数,默认是50。“endpoint”就是是否包含序列结束值的意思。“retstep”为是否返回样本之间的步长,默认是False。“dtype”是输出数组的数据类型,如果没有就从其他输入参数判断。
之后,我们使用了一个一次函数来计算y列表的值。这样,我们的x和y都有了。
3.喂入训练数据
x=[[i] for i in x]
y=[[i] for i in y]
model=linear_model.LinearRegression()
model.fit(x,y)由于fit需要传入二维矩阵数据,因此需要处理x,y的数据格式,将每个样本信息单独作为矩阵的一行。前两行代码相当于把[1,2,3]的数据转化为:[[1],[2],[3]]。之后我们调用线性回归模型,使用fit()函数喂入训练数据。fit函数原型长这样:
model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
其中,“x_train”代表训练数据的输入特征,“y_train”代表输入数据的目标值,与前一个“x_train”对应。“batch_size”代表每次训练所使用的样本量。“epochs”代表训练的轮数,每一轮表示模型在整个训练数据集上进行一次完整的遍历。“validation_data”代表在训练过程中提供验证数据,模型在每个 epoch 结束后会在验证数据上进行评估,以监控模型的性能。
这里,我们只传入了训练数据,其他全部默认。
4.结果预测
x_=[[4],[5],[6]]
y_=model.predict(x_)
print(y_)这里,我们又定义了一个“x_”的待预测数据,让“y_”等于经过模型预测的目标值,并将其打印。
5.输出模型中的w与b值
要判断机器做对题没有,需要将它计算出的w与b值打印才能判断:
print("w值为:",model.coef_)
print("b截距值为:",model.intercept_)6.可视化
plt.scatter(x,y)
plt.plot(x_,y_,color="red",linewidth=3.0,linestyle="-")
plt.legend(["func","Data"],loc=0)
plt.show()这里,我们使用matplotlib包,将训练数据与预测出的函数都显示出来。
这样,我们就完成了一次机器学习,并且预测结果和我们想象中的接近。
但需要注意的是,很多时候传入的训练数据并不会像这样规矩,所以接下来我们需要让训练数据稍微变动一下。
7.传入不规则数据
只需要在准备训练数据时多加一行,让x的值有一个上下浮动的范围即可:
x = np.linspace(3,6.4)
y = 3 * x + 2
x = x + np.random.rand(50) 

可以看到,我们的模型依然很好的完成了任务。
那么,具体模型是怎么做到的,我们下回分解(其实我也不会)。