本文是学习4K4D的笔记记录
Project Page:https://zju3dv.github.io/4k4d/
文章目录
- 1 Pipeline
- 1.1 特征向量的计算
- 1.2 几何建模
- 1.3 外观建模⭐
- 1) 球谐函数SH模型
- 2) 图像融合技术
- 1.4 可微分深度剥离渲染
- 2 Train(loss)
- 2.1 具体的 Mask Loss
- 1) mIoU Loss
- 2) MSE Loss
- 3) 总损失计算
- 3 Inference
- 3.1 预计算和预计存储
- 3.2 数据类型
- 3.3 减少渲染传递次数
- 4 实施细节
- 1)超参
- 2)点云初始化
1 Pipeline
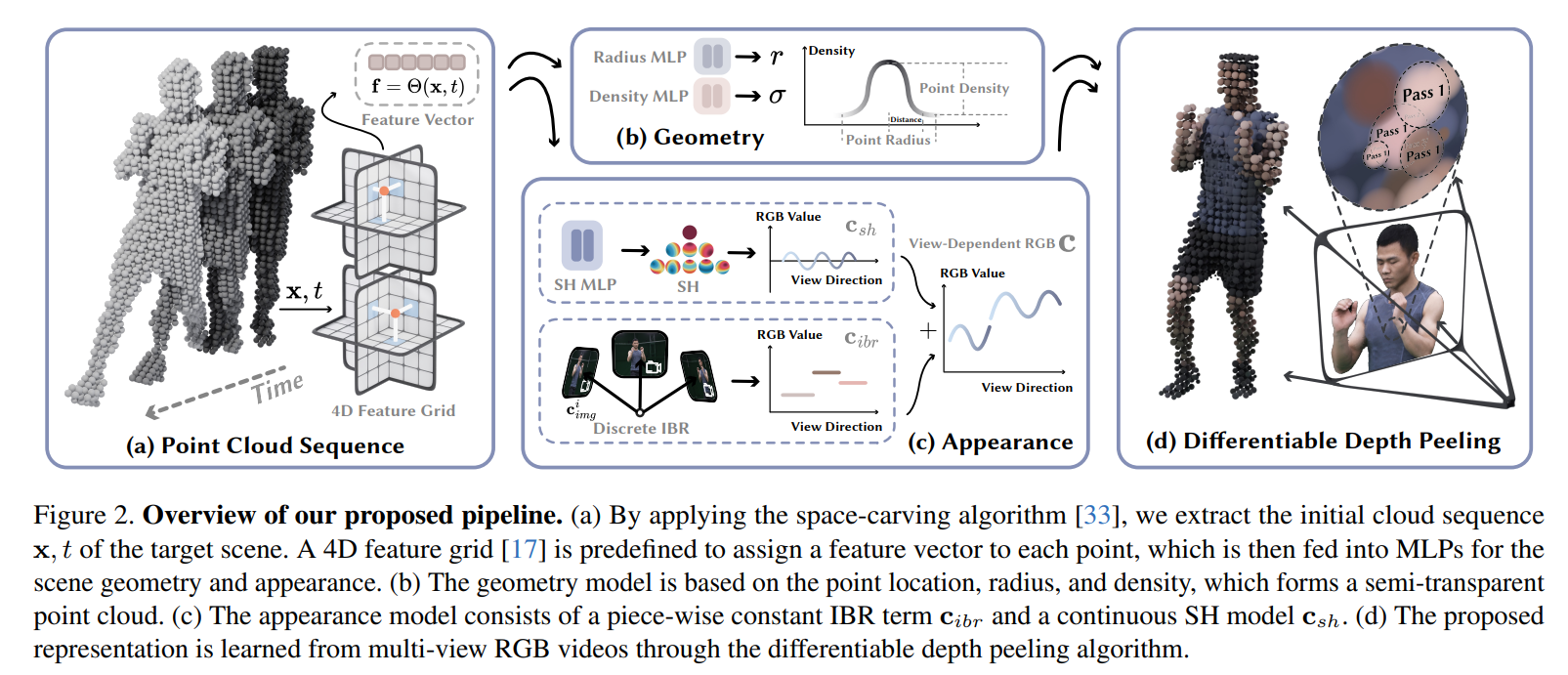
1.1 特征向量的计算
使用空间雕刻算法从多视图视频中得到粗糙点云,利用 K-Planes 使用的方法,定义六个特征平面 θ x y 、 θ x z 、 θ y z 、 θ t x 、 θ t y 、 θ t z θxy、 θxz、θyz、θtx、θty、θtz θxy、θxz、θyz、θtx、θty、θtz ,来模拟一个4D特征场 Θ ( x , t ) Θ(x, t) Θ(x,t) ,为每个点分配一个特征向量 f f f
对于4D空间中的任意点 ( x , t ) (x, t) (x,t) ,将6个平面的特征向量拼接起来形成一个完整的特征向量 f f f
- 空间位置信息:通过θxy, θxz, θyz特征平面,可以获得点在3D空间中的位置相关信息
- 时间信息:通过θtx, θty, θtz特征平面,可以获得点随时间变化的信息
1.2 几何建模
-
点位置的建模
点的位置是通过一个可优化的向量 p ∈ R 3 p \in \mathbb{R}^3 p∈R3 来表示
-
点半径和密度的预测
点的半径 r r r 和密度 σ σ σ 是使用 MLP 根据特征向量 f f f 来预测
1.3 外观建模⭐
同样使用特征向量 f f f ,进一步预测外观属性,即颜色和光照
外观模型由两部分组成:
- 离散视角依赖的外观 c i b r c_{ibr} cibr(通过图像融合技术获得)
- 连续视角依赖的外观 c s h c_{sh} csh(使用球谐函数SH模型表示)
1) 球谐函数SH模型
球谐函数用于表示颜色:球谐函数用于颜色的基本思路是将环境光照分解为球谐基函数的系数。这些系数随后可以用来重建光照,从而计算物体表面在特定方向上的颜色。
c sh ( s , d ) c_{\text{sh}}(s, d) csh(s,d)
c s h c_{sh} csh 是使用球谐函数表示的颜色,其中 s s s 是点 x x x 在时间 t t t 的SH系数, d d d 是观察方向。
SH模型用于表示动态场景中点的颜色随着观察方向的变化而变化。每个点的颜色 c s h c_{sh} csh 由一组SH系数 s s s 来描述,这些系数通过MLP网络从特征向量 f f f 中回归得到。
2) 图像融合技术
- 投影到输入图像中:对于动态场景中的每个点 x x x ,首先使用相机的内参将其投影回输入图像中,提取RGB颜色值 c i , i m g c_{i, img} ci,img 。
- 计算融合权重:然后,根据点的坐标和所在的输入图像,计算对应的融合权重 w i w_i wi 。这个融合权重会考虑点与输入图像中像素的距离等因素,以确定对最终颜色的贡献程度。注意:这里的融合权重与观察方向无关。
- 选择最近的输入视角:为了实现视角相关的效果,根据观察方向通过最近邻检索获得选择最近的 N ′ N' N′ 个输入视角。
- 颜色融合:最后,根据选定的 N ′ N' N′ 个输入视角和对应的融合权重,对输入的RGB颜色进行加权融合,得到最终的颜色 c i b r c_{ibr} cibr。这样,每个点在特定视角下的颜色就被融合出来了。
c i b r ( x , t , d ) = ∑ i = 1 N ′ w i c i , i m g c_{ibr}(x, t, d) = \sum_{i=1}^{N'} w_i c_{i, img} cibr(x,t,d)=i=1∑N′wici,img
其中, c i b r c_{ibr} cibr 是点 x x x 在时间 t t t 和观察方向 d d d 下的颜色, N ′ N' N′ 是根据观察方向选择的最近输入视图的数量, w i w_i wi 是基于点坐标和输入图像计算的混合权重, c i , i m g c_{i, img} ci,img 是输入图像中的RGB颜色。
其是由有限数量的颜色加权组合而成,导致在视角方向上存在离散性。结合球谐函数(SH)模型来精细地调整颜色,使其在不同视角之间平滑过渡。
c ( x , t , d ) = c i b r ( x , t , d ) + c s h ( s , d ) c(x, t, d) = c_{ibr}(x, t, d) + c_{sh}(s, d) c(x,t,d)=cibr(x,t,d)+csh(s,d)
1.4 可微分深度剥离渲染
深度剥离:一种顺序无关半透明渲染算法,这一方案的基本思想是先进行半透明片元绘制(这里是通道而不是实际绘制),并以深度顺序排入一个多层深度缓冲结构中;渲染时在基于这个多层深度缓冲进行从远到近的渲染,就能逐层正确混合了。
由于点云表示的优势,可以利用硬件光栅化器显著加快深度剥离过程(即一开始的半透明片元绘制)。此外,这个渲染过程易于变为可微分的,使得可以从输入的RGB视频中进行模型学习。
自定义着色器渲染:
-
深度剥离(对于特定的图像像素 u u u )
- 首先使用硬件光栅化器将点云渲染到图像上,将最靠近相机的一个点 x 0 x_0 x0 分配给像素 u u u 。然后,记录下该点的深度 t 0 t_0 t0 。
- 在第 k k k 次渲染通道中,将所有深度值 t k t_k tk 小于前一通道记录的深度 t k − 1 t_{k-1} tk−1 的点云的点都丢弃,从而得到每个像素的第 k k k 个最靠近相机的点 x k x_k xk 。在K次渲染后,像素 u u u 就有了一组以深度排序的点 { x k ∣ k = 1 , … , K } \{x_k|k = 1, …, K\} {xk∣k=1,…,K} 。
-
密度权重:基于每个像素上的点集 { x k ∣ k = 1 , … , K } \{x_k|k = 1, …, K\} {xk∣k=1,…,K} ,使用体渲染技术来合成像素的颜色。
对于每个点 x k x_k xk ,其对像素 u u u 的密度权重为 α k \alpha_k αk :
α k ( u , x ) = σ ⋅ max ( 1 − ∥ π ( x ) − u ∥ 2 r 2 , 0 ) \alpha_k(u, x) = \sigma \cdot \max(1 - \frac{\lVert \pi(x) - u \rVert^2}{r^2}, 0) αk(u,x)=σ⋅max(1−r2∥π(x)−u∥2,0)
这里, π \pi π 是点 x x x 到像素 u u u 的投影函数, σ \sigma σ 和 r r r 分别是点的密度和半径。
-
颜色合成:最终像素的颜色是根据渲染通道中每个点的颜色和密度进行加权融合得到的:
C ( u ) = ∑ k = 1 K T k α k c k C(u) = \sum_{k=1}^{K} T_k \alpha_k c_k C(u)=k=1∑KTkαkck其中, T k T_k Tk 表示从相机到像素 u u u 的路径上,由前 k-1 个点累积起来的透明度:
T k = ∏ j = 1 k − 1 ( 1 − α j ) T_k = \prod_{j=1}^{k-1} (1 - \alpha_j) Tk=j=1∏k−1(1−αj)
整个密度加权过程是可微分的,这意味着可以通过反向传播来更新点云的属性,以最小化渲染图像和真实图像之间的差异。
2 Train(loss)
-
图像重建损失:首先,使用均方误差(MSE)损失来比较生成的图像像素颜色 C ( u ) C(u) C(u) 与真实图像像素颜色 C g t ( u ) C_{gt}(u) Cgt(u) 之间的差异。
L img = ∑ u ∈ U ∣ ∣ C ( u ) − C gt ( u ) ∣ ∣ 2 2 L_{\text{img}} = \sum_{u \in U} ||C(u) - C_{\text{gt}}(u)||_2^2 Limg=u∈U∑∣∣C(u)−Cgt(u)∣∣22 -
感知损失:应用来提高生成图像的质量。感知损失通过比较生成图像和真实图像在VGG16网络中提取的图像特征之间的差异来度量图像之间的感知差异。
L lpips = ∣ ∣ Φ ( I ) − Φ ( I gt ) ∣ ∣ 1 L_{\text{lpips}} = ||\Phi(I) - \Phi(I_{\text{gt}})||_1 Llpips=∣∣Φ(I)−Φ(Igt)∣∣1其中, Φ Φ Φ 是一个VGG16网络, I I I 和 I g t I_{gt} Igt 分别是生成图像和真实图像。
感知损失是一种基于神经网络特征的损失函数,它通过比较目标图像和生成图像在高层特征图上的差异来度量图像的相似性。这种损失函数能够更好地捕捉图像的语义信息,从而使得生成图像更符合人类的视觉感知。 在PyTorch中,我们可以使用预训练的神经网络(如VGG或ResNet)提取特征,然后计算特征图之间的差异。
-
掩模损失:应用了掩模损失。
仅渲染动态区域的点云以获取它们的掩码(即透明度):
M ( u ) = ∑ k = 1 K T k α k M(u) = \sum_{k=1}^{K} T_k \alpha_k M(u)=k=1∑KTkαk
将生成的掩模与真实的掩模进行比较,以限制动态区域的几何形状,确保其与真实场景中的可视外壳一致。
L msk = ∑ u ∈ U ′ M ( u ) M gt ( u ) L_{\text{msk}} = \sum_{u \in U'} M(u)M_{\text{gt}}(u) Lmsk=u∈U′∑M(u)Mgt(u)其中, U ′ U' U′ 表示渲染掩模的像素集, M g t M_{gt} Mgt 是2D动态区域的真实掩模。通过引入掩模损失,模型可以受到动态区域几何形状的有效约束。(正则化)
最终的损失函数由图像重建损失、感知损失和掩模损失的加权和组成:
L = L img + λ lpips L lpips + λ msk L msk L = L_{\text{img}} + \lambda_{\text{lpips}} L_{\text{lpips}} + \lambda_{\text{msk}} L_{\text{msk}} L=Limg+λlpipsLlpips+λmskLmsk
其中, λ l p i p s λ_{lpips} λlpips和 λ m s k λ_{msk} λmsk 是控制相应损失权重的超参数。
2.1 具体的 Mask Loss
Mask Loss 在 MaskSupervisor 类中被计算。
1) mIoU Loss
mIoU_loss函数计算的是交并比(Intersection over Union, IoU)损失。表示预测和真实分割区域的交集与并集的比值。交并比越大,预测掩码和真实掩码的重叠程度越高,所以损失应该越小。
计算步骤:
- 计算交集 ( I ):预测值和真实值逐元素相乘,再求和: I = ∑ ( x ⋅ y ) I = \sum (x \cdot y) I=∑(x⋅y)
- 计算并集 ( U ):预测值和真实值逐元素相加,再减去交集的值: U = ∑ ( x + y ) − I U = \sum (x + y) - I U=∑(x+y)−I
- 计算mIoU:交集除以并集,然后取反得到损失: mIoU_loss = 1 − mIoU = 1 − I U \text{mIoU\_loss} = 1- \text{mIoU} = 1 - \frac{I}{U} mIoU_loss=1−mIoU=1−UI
2) MSE Loss
mse函数计算的是均方误差损失:
mse
=
1
N
∑
(
x
i
−
y
i
)
2
\text{mse} = \frac{1}{N} \sum (x_i - y_i)^2
mse=N1∑(xi−yi)2
3) 总损失计算
在compute_loss函数中,loss计算涉及到两个部分,总损失 loss 是在已有损失基础上增加了上述两种损失的加权和。:
mIoU_loss部分,具体权重为self.msk_loss_weight。mse部分,具体权重为self.msk_mse_weight。
总损失公式如下:
L m a s k = w m I o U ⋅ L m I o U + w m s e ⋅ L m s e L_{mask} = w_{mIoU} \cdot L_{mIoU} + w_{mse} \cdot L_{mse} Lmask=wmIoU⋅LmIoU+wmse⋅Lmse
其中:
L m I o U = 1 − ∑ ( x ⋅ y ) ∑ ( x + y ) − ∑ ( x ⋅ y ) L_{mIoU} = 1 - \frac{\sum (x \cdot y)}{\sum (x + y) - \sum (x \cdot y)} LmIoU=1−∑(x+y)−∑(x⋅y)∑(x⋅y)
L m s e = 1 N ∑ ( x i − y i ) 2 L_{mse} = \frac{1}{N} \sum (x_i - y_i)^2 Lmse=N1∑(xi−yi)2
3 Inference
3.1 预计算和预计存储
- 点位置 p p p 、半径 r r r 、密度 σ \sigma σ 、球谐系数 s s s 以及颜色混合权重 w i w_i wi 在训练完成后,对于场景中的每个点,预先计算其在渲染过程中这些需要的属性。
- 这些属性在渲染期间会异步传输到图形卡上,内存传输操作与GPU上的光栅化过程重叠,这样可以进一步提高渲染速度。
运行时的计算量减少到只需进行深度剥离和 c ( x , t , d ) = c i b r ( x , t , d ) + c s h ( s , d ) c(x, t, d) = c_{ibr}(x, t, d) + c_{sh}(s, d) c(x,t,d)=cibr(x,t,d)+csh(s,d)
3.2 数据类型
将模型的数据类型从32位浮点数转换为16位浮点数,以提高内存访问效率。这种转换可以提高每秒帧数(FPS)约20帧,并且不会导致可见的性能损失。
3.3 减少渲染传递次数
将可微深度剥离算法的渲染传递次数 K K K 从15减少到12。这也能提高FPS约20帧,同时不改变视觉质量。
4 实施细节
1)超参
- 使用Adam优化器,学习率为 5 × 1 0 − 3 5 \times 10^{-3} 5×10−3,通常在单个RTX 4090 GPU上训练200帧的序列,需要大约24小时。
- 点位置的学习率设置为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,正则化损失权重 λ lpips \lambda_{\text{lpips}} λlpips 和 λ msk \lambda_{\text{msk}} λmsk 设置为 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3。
- 在训练期间,可微深度剥离的传递次数 K K K 设置为15,最近输入视图的数量 N ′ N' N′ 设置为4。
2)点云初始化
-
对于动态区域,使用分割方法获得输入图像中的掩码,并使用空间雕刻算法提取粗点云。
-
对于静态背景区域,利用前景掩码计算所有帧中背景像素的掩码加权平均值,从而得到不包含前景内容的背景图像。
然后,在这些图像上训练 Instant-NGP,从中获得初始点云。





![[数据结构] 哈希结构的哈希冲突解决哈希冲突](https://i-blog.csdnimg.cn/direct/b5e222d58577426588b1442d6c7cb63e.png)













