D4内容介绍
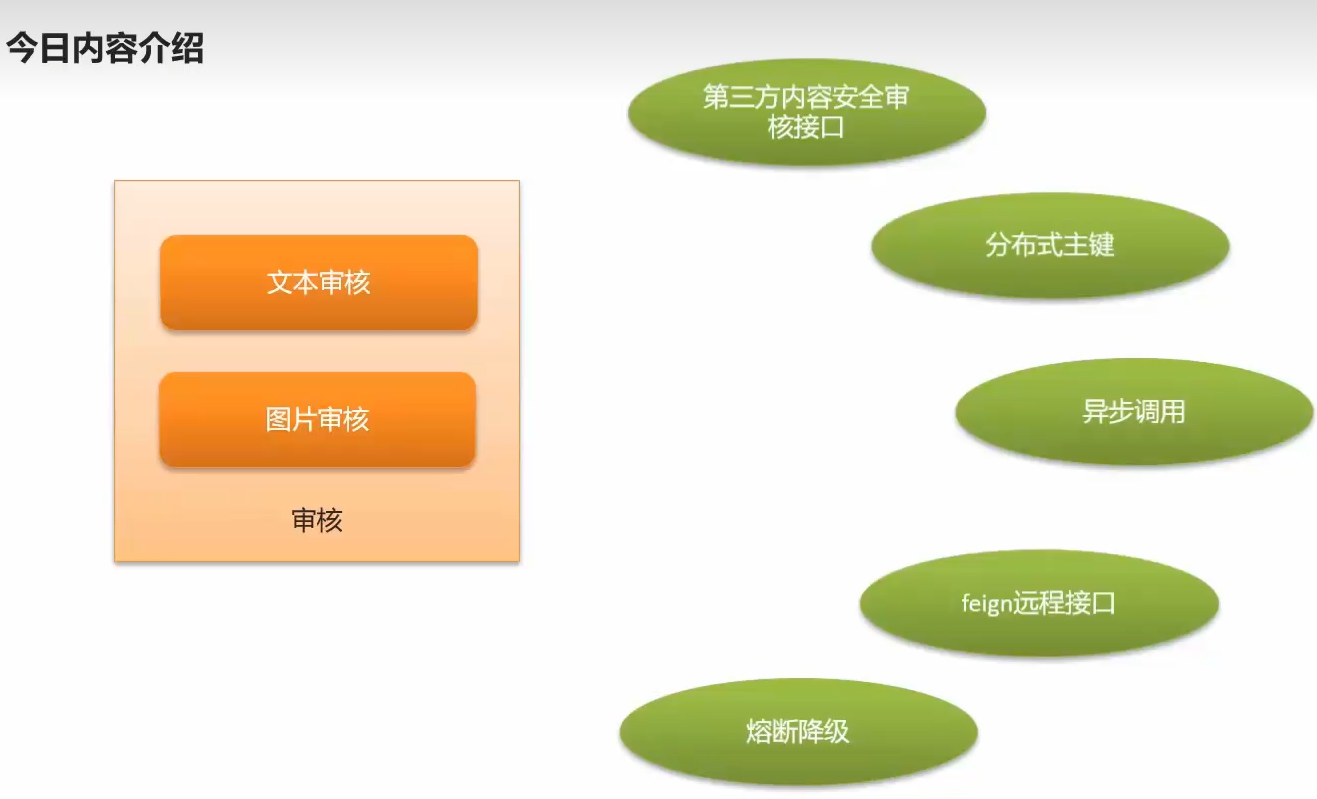
阿里三方安全审核
分布式主键
异步调用
feign
熔断降级
1.自媒体文章自动审核
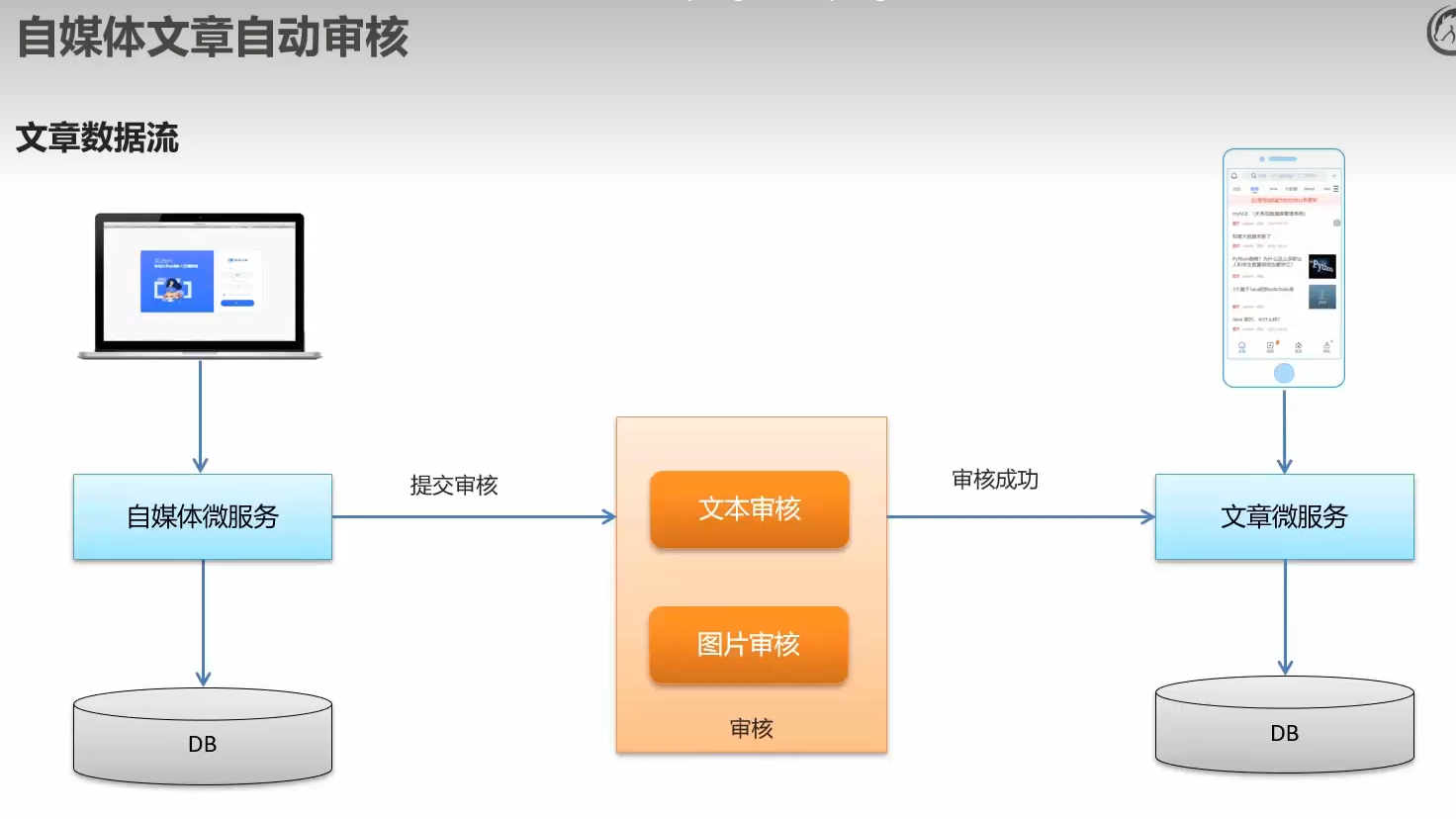
1.1审核流程

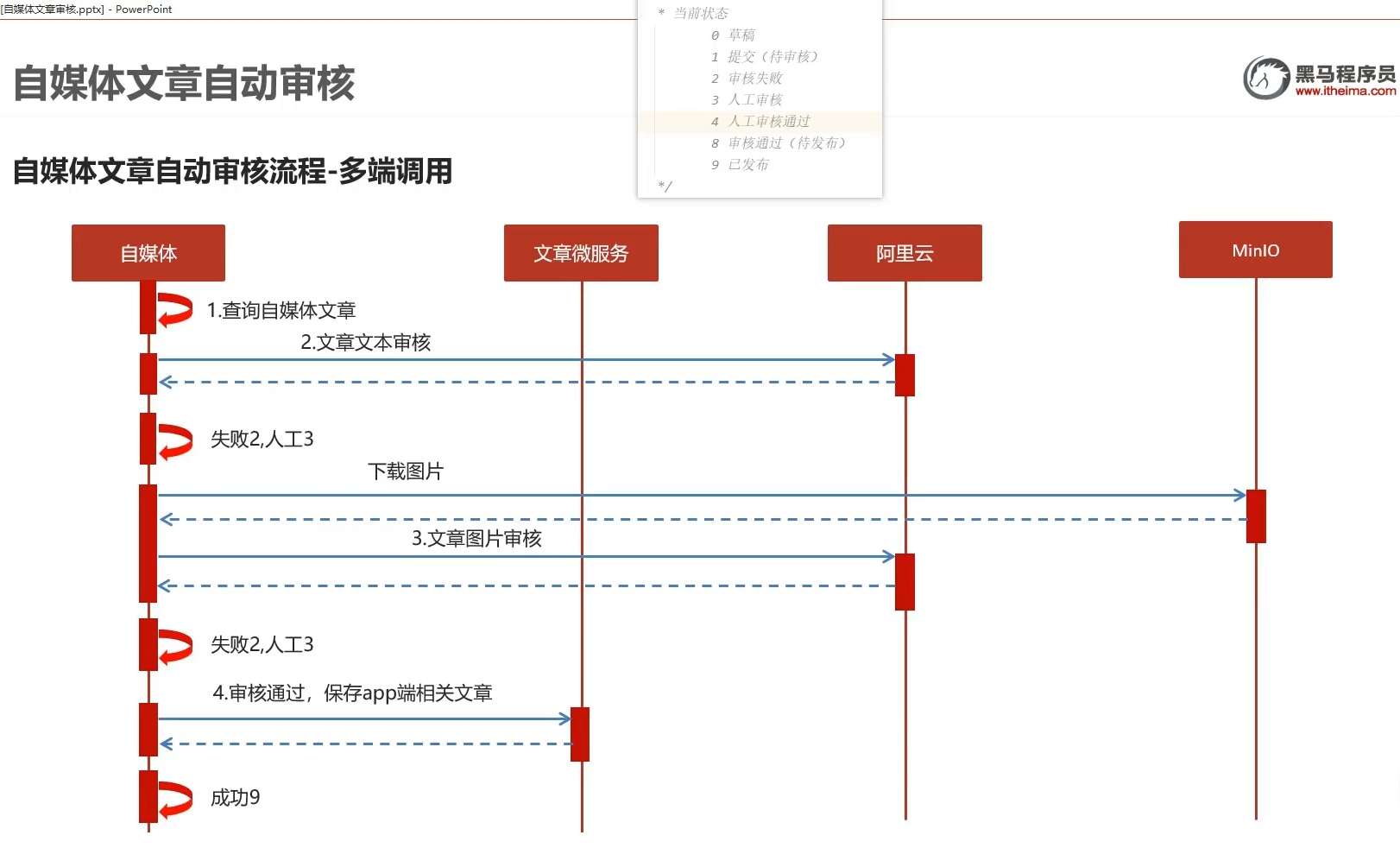
查文章——调接口文本审核——minio下载图片图片审核——审核通过保存文章——发布
草稿1,失败2,人工3,发布9
1.2接口获取
注册阿里云,开通内容安全
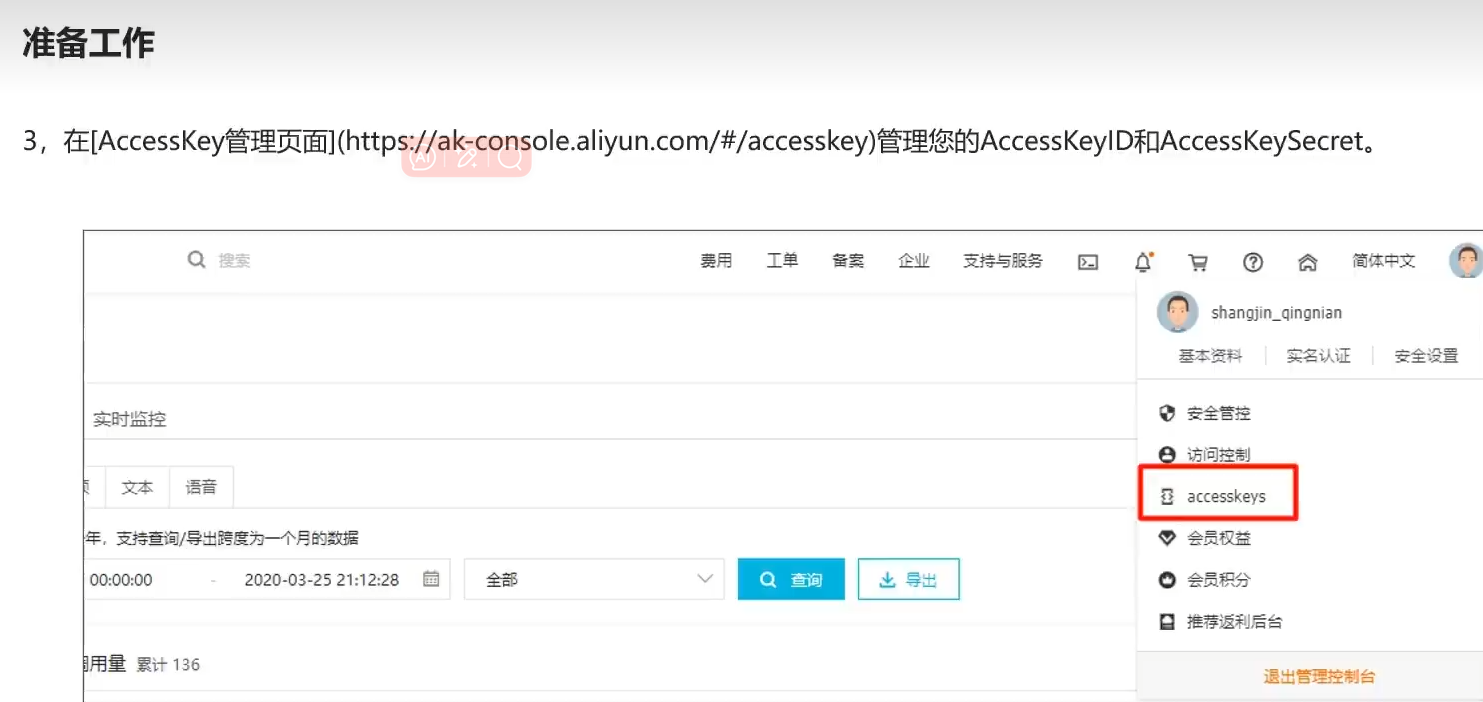
获取akey和skey
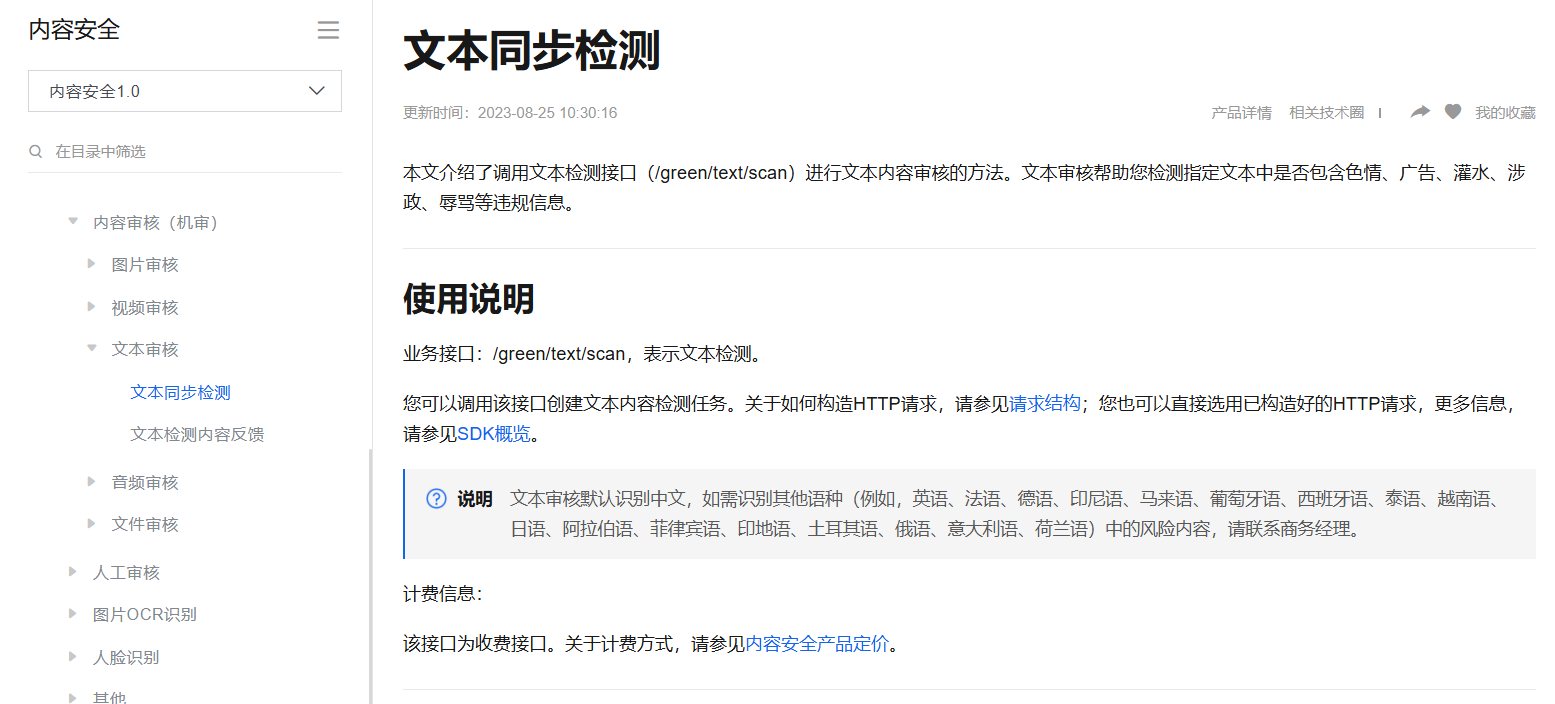
1.3文本内容审核接口
文本垃圾内容检测:https://help.aliyun.com/document_detail/70439.html?spm=a2c4g.11186623.6.659.35ac3db3l0wV5k
图片垃圾内容检测:https://help.aliyun.com/document_detail/70292.html?spm=a2c4g.11186623.6.616.5d7d1e7f9vDRz4
图片垃圾内容Java SDK: https://help.aliyun.com/document_detail/53424.html?spm=a2c4g.11186623.6.715.c8f69b12ey35j4

参数1,scene场景
参数2,task (图片地址)
设置两种鉴别场景 收费两次
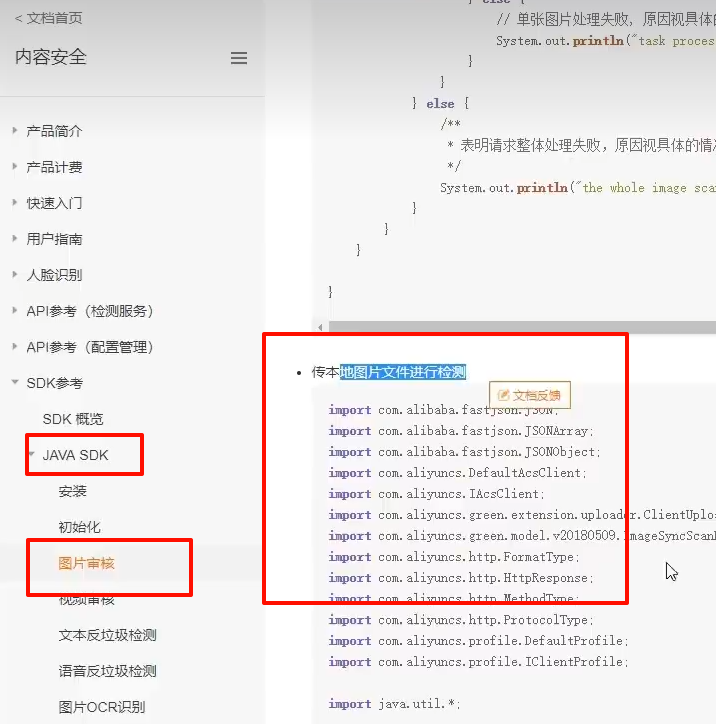
提供了相应的java sdk
1.4项目集成

1.4.1依赖导入
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-core</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-green</artifactId>
<version>3.6.6</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>2.8.3</version>
</dependency>
1.4.2实体类拷贝
拷贝阿里云审核工具类到common模块的common包下
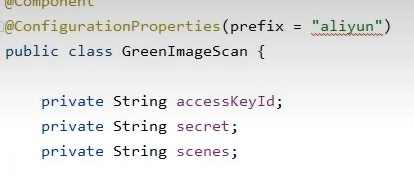
配置文件里读取并设置
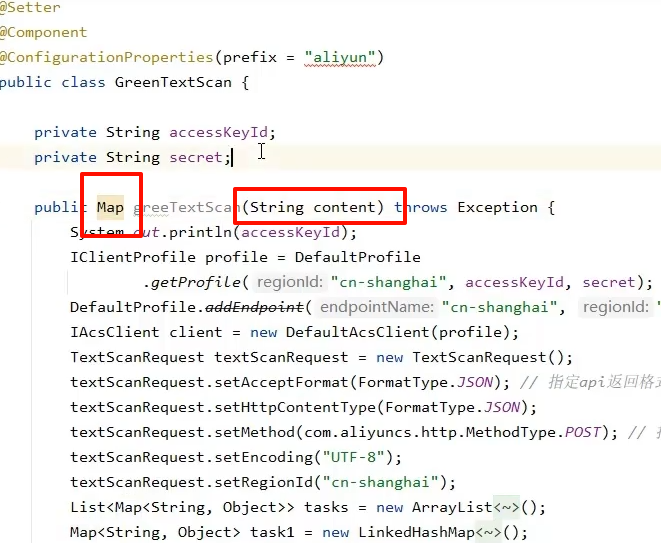
传入content 返回map,信息包含是否通过,人工审核等其他建议
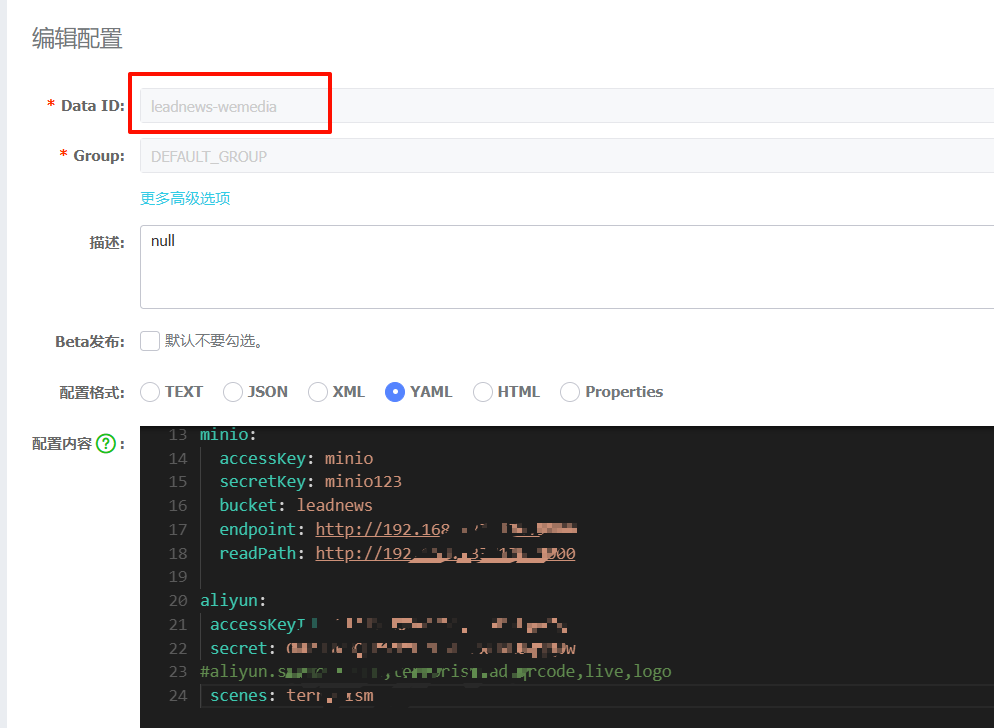
1.4.3配置中心里wemedia添加配置
不会自己百度查如何申请阿里云的accesskey
aliyun:
accessKeyId: 自填
secret: 自填
#aliyun.scenes=porn,terrorism,ad,qrcode,live,logo
scenes: terrorism
1.4.4测试
现在common模块注入那俩util工具类,wemedia微服务test测试类才能使用到
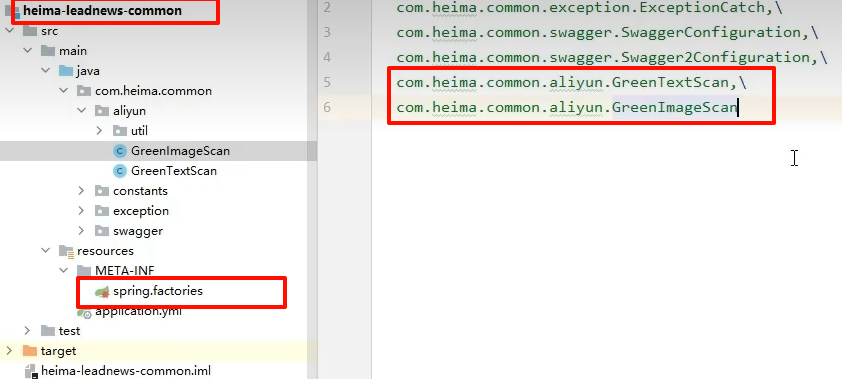
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.heima.common.exception.ExceptionCatch,\
com.heima.common.swagger.SwaggerConfiguration,\
com.heima.common.swagger.Swagger2Configuration,\
com.heima.common.aliyun.GreenImageScan,\
com.heima.common.aliyun.GreenTextScan
测试类

package com.heima.wemedia;
import com.heima.common.aliyun.GreenImageScan;
import com.heima.common.aliyun.GreenTextScan;
import com.heima.file.service.FileStorageService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Arrays;
import java.util.Map;
@SpringBootTest(classes = WemediaApplication.class)
@RunWith(SpringRunner.class)
public class AliyunTest {
@Autowired
private GreenTextScan greenTextScan;
@Autowired
private GreenImageScan greenImageScan;
@Autowired
private FileStorageService fileStorageService;
@Test
public void testScanText() throws Exception {
Map map = greenTextScan.greeTextScan("我是一个好人,冰毒");
System.out.println(map);
}
@Test
public void testScanImage() throws Exception {
byte[] bytes = fileStorageService.downLoadFile("http://192.168.200.130:9000/leadnews/2021/04/26/ef3cbe458db249f7bd6fb4339e593e55.jpg");
Map map = greenImageScan.imageScan(Arrays.asList(bytes));
System.out.println(map);
}
}
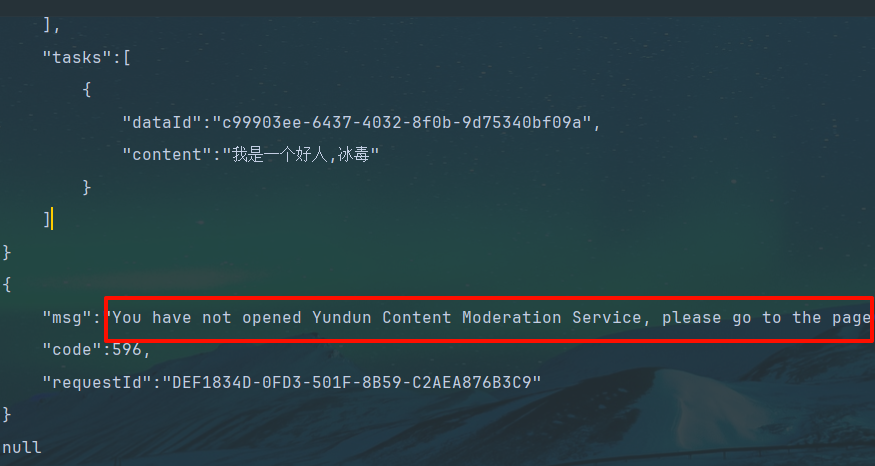

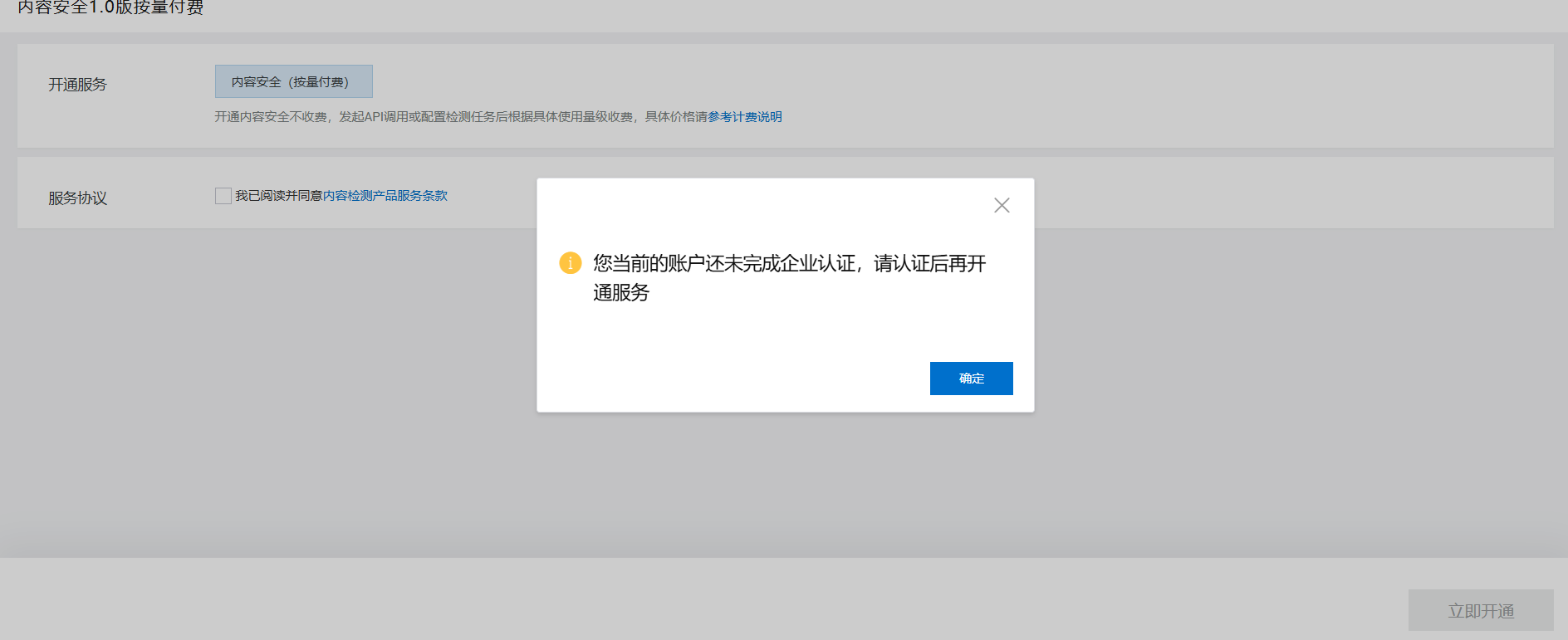
不过听说增强版相较于1.0不需企业认证?但是由于教程没有且不想耗费时间钻研这段直接跳过

当然图片审核也跳过了
1.5分布式主键策略——雪花算法
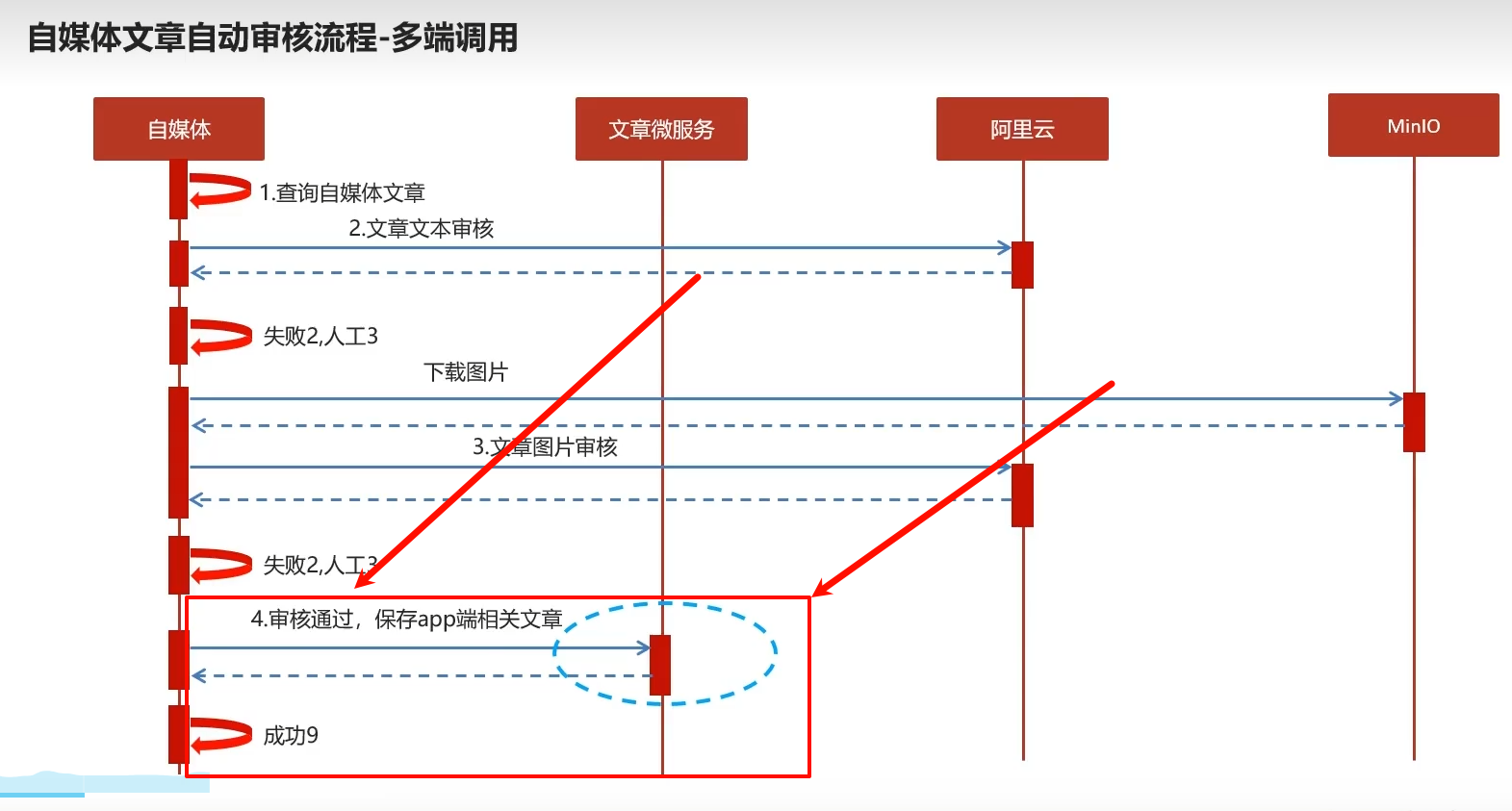
审核通过时进行文章保存
1.5.1表结构-article库
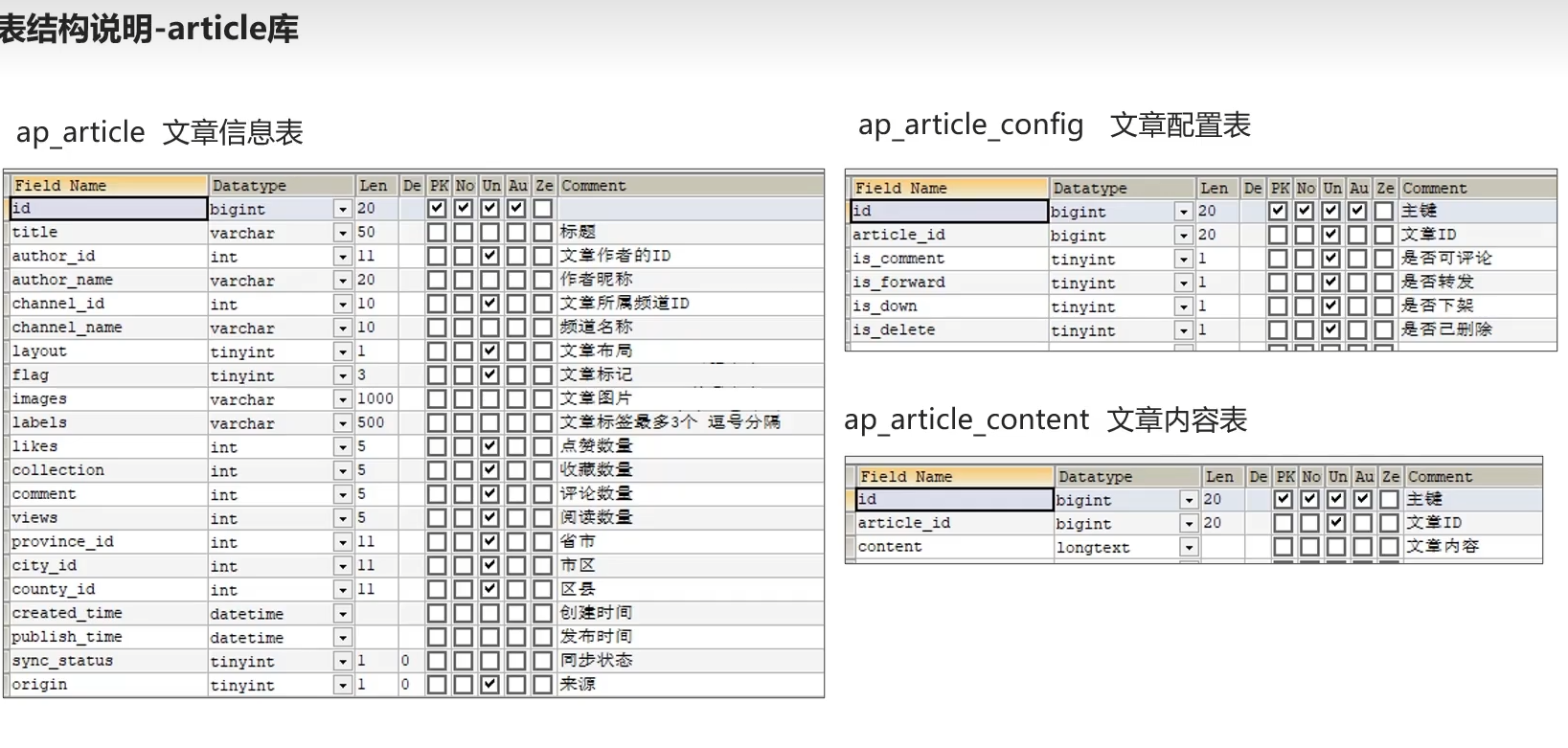
1对1表关系
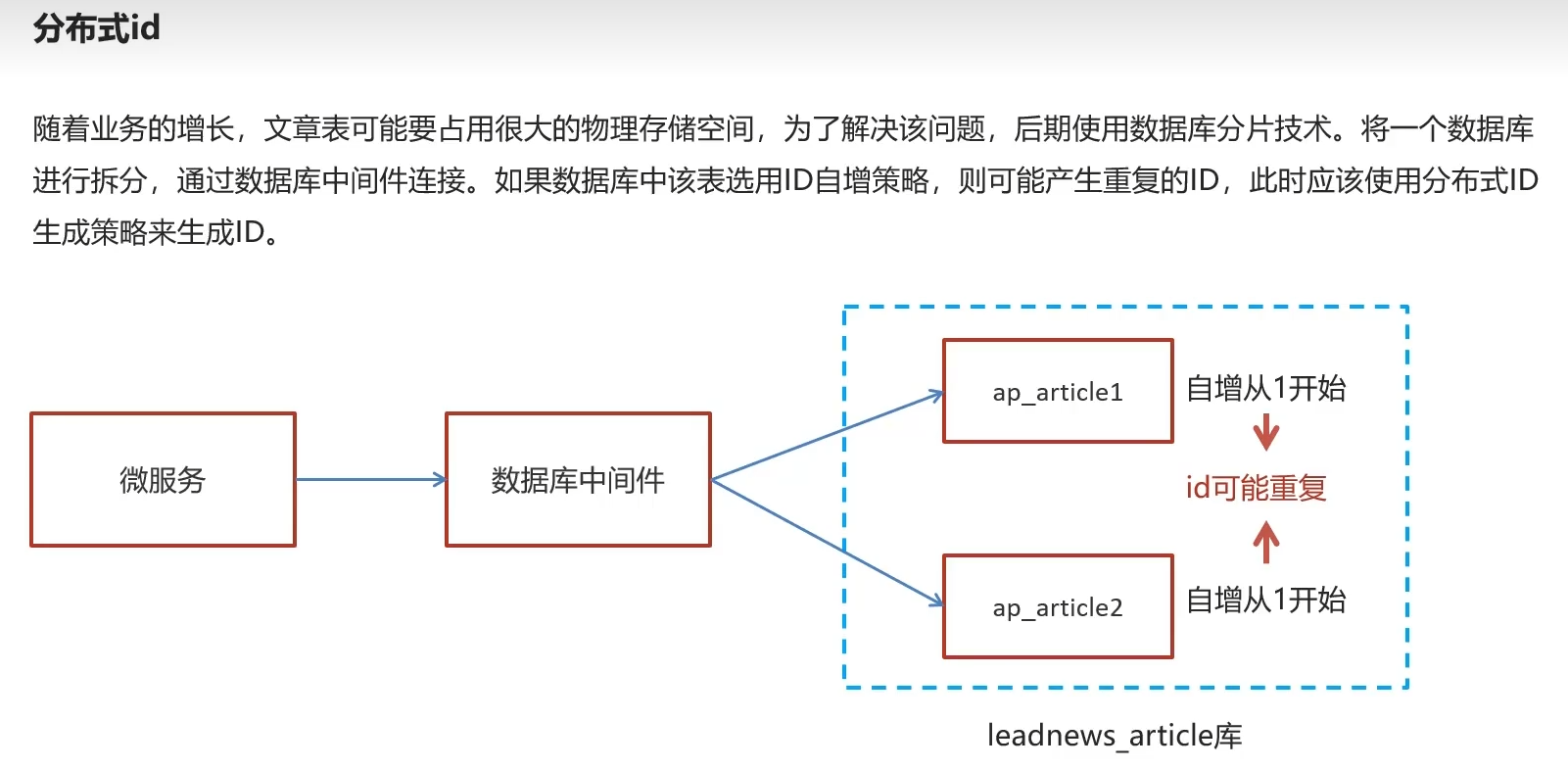
表数据满到快溢出来了,进行分表,不过自增id会重复
1.5.2分布式ID技术选型


- 第一位为0不用,为1负数,所以不用
- 第二部分为时间戳
- 前五位机房id 25=32,后五位为每个机房有多少个工作id 也32台,
32个机房每个机房32台工作id,一共1024台机器 - 序列号12位,4096个id不重复
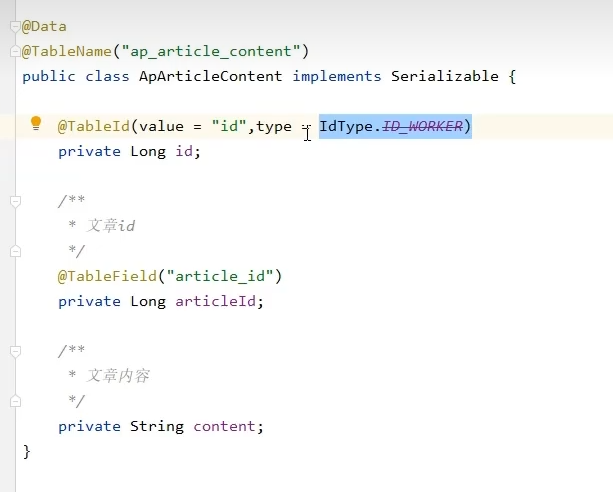
ID_WORKER为雪花算法
指定机房id和机器id
在nacos注册中心的article微服务里替换原先的mp配置
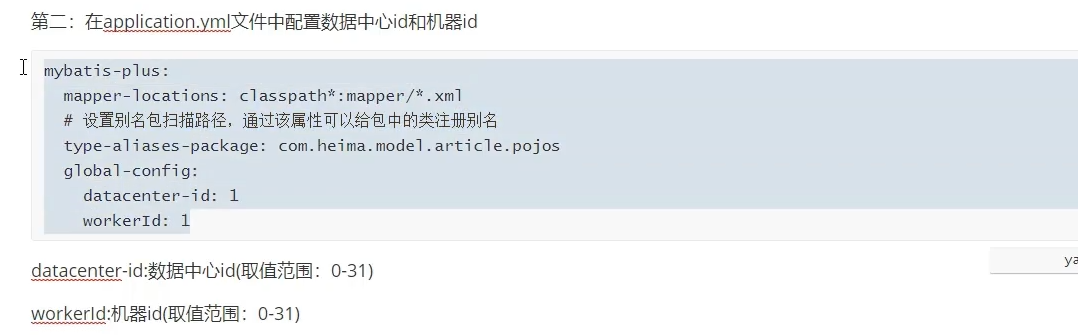
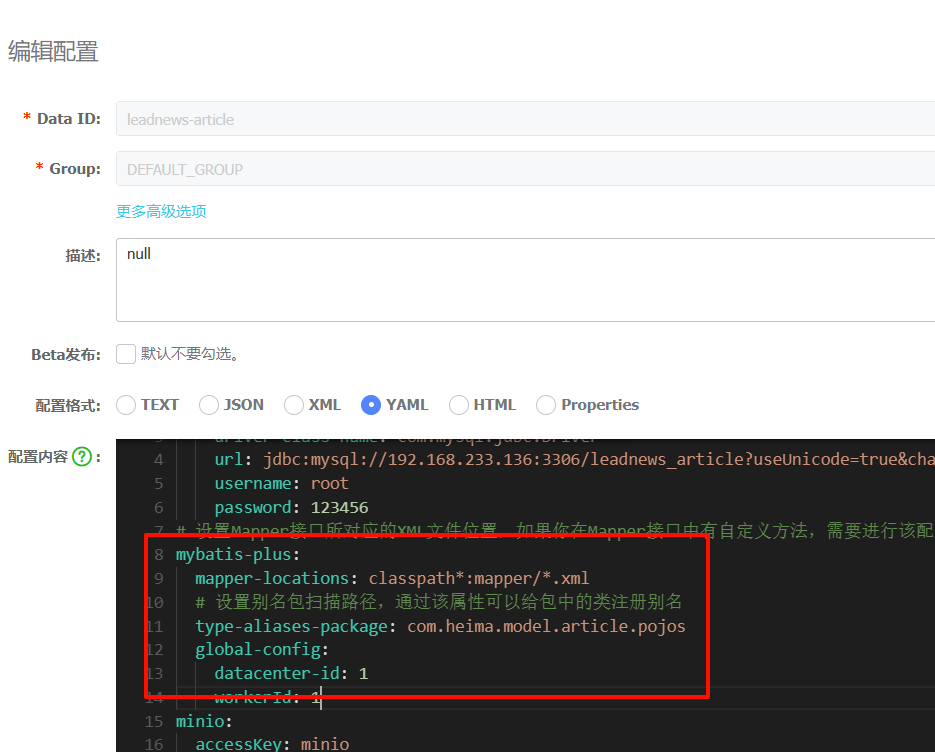
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1
workerId: 1
2.app端文章保存接口

为什么自媒体库也有文章id?。当修改审核通过后根据文章id修改前台的文章 aparticle
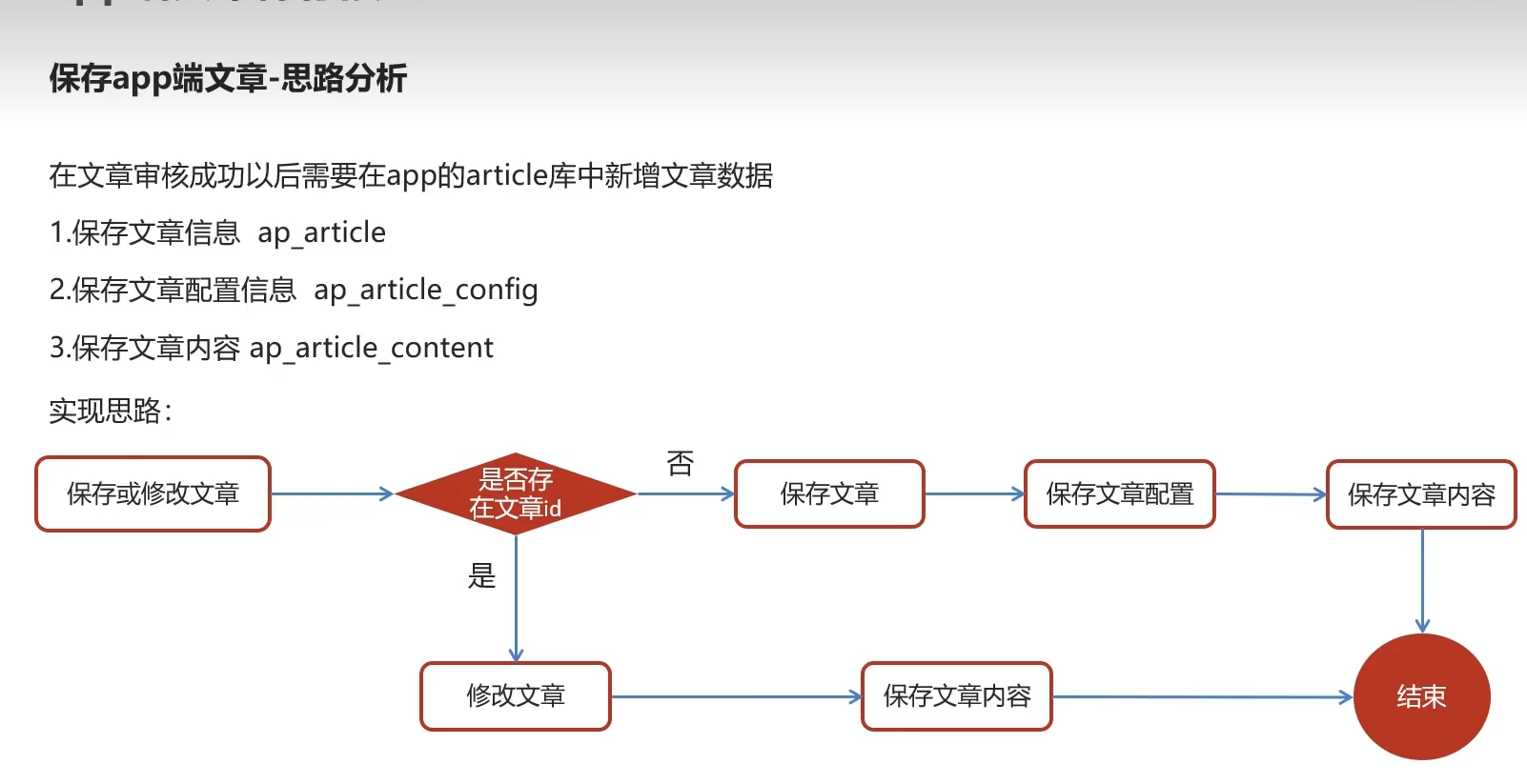
怎么没有修改文章配置?因为默认前端会设置好配置,保存时初始化添加即可
feign接口
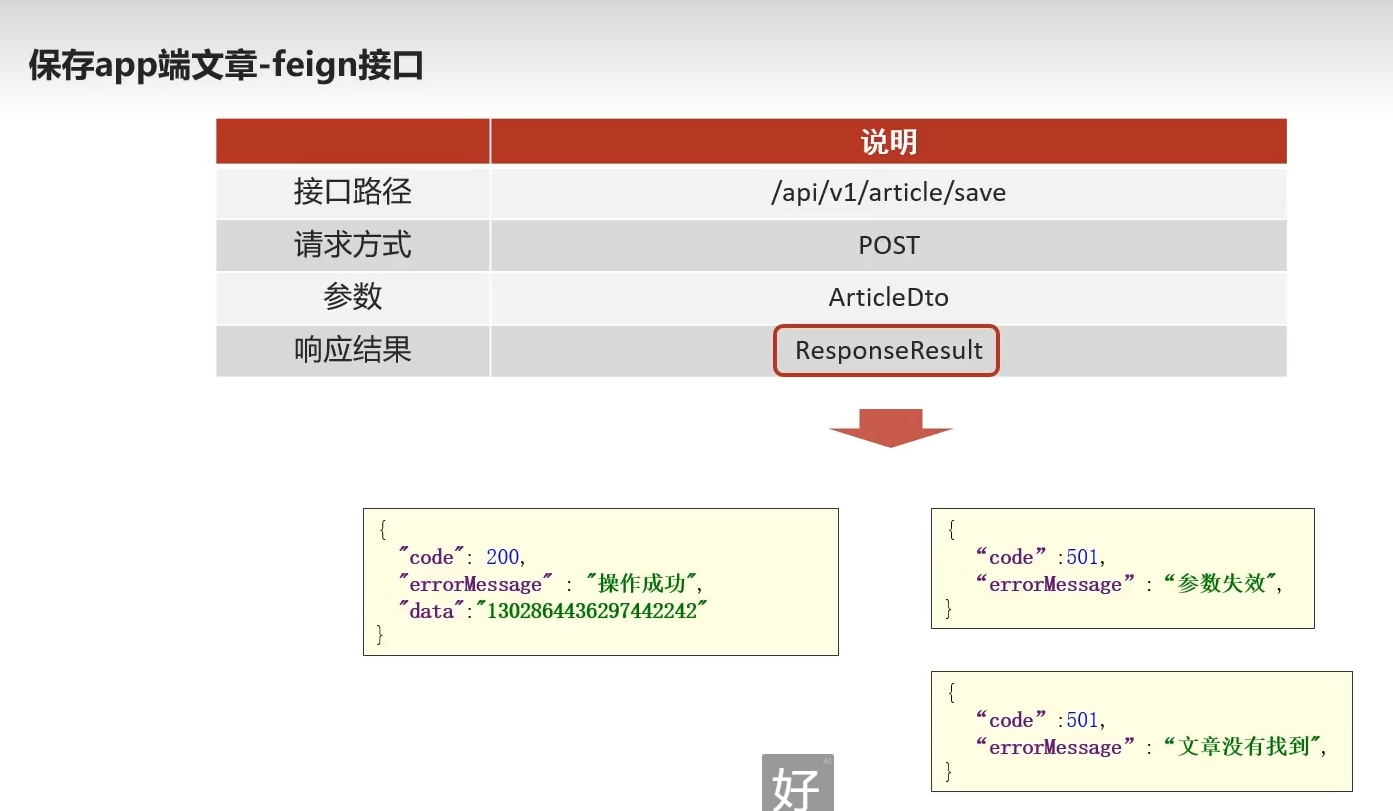
微服务间的调用使用远程客户端,操作成功且审核成功后返回文章id后续修改通过该id再次远程app端修改文章
如果没审核通过则没有aid

实现步骤

2.1在feign-api微服务定义接口
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
定义文章端的接口
接收wm文章的实体dto
package com.heima.model.article.dtos;
import com.heima.model.article.pojos.ApArticle;
import lombok.Data;
@Data
public class ArticleDto extends ApArticle {
/**
* 文章内容
*/
private String content;
}
在service下的article服务实现接口
package com.heima.article.feign;
import com.heima.apis.article.IArticleClient;
import com.heima.article.service.ApArticleService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.io.IOException;
@RestController
public class ArticleClient implements IArticleClient {
@Autowired
private ApArticleService apArticleService;
@Override
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto) {
return apArticleService.saveArticle(dto);
}
}
mapper
package com.heima.article.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.model.article.pojos.ApArticleConfig;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface ApArticleConfigMapper extends BaseMapper<ApArticleConfig> {
}
修改ApArticleConfig
添加如下构造函数,当保存文章时初始化实体类,id对应其他四个默认值,不下架不删除
public ApArticleConfig(Long articleId){
this.articleId = articleId;
this.isComment = true;
this.isForward = true;
this.isDelete = false;
this.isDown = false;
}
service添加保存方法
思路
- 没id,保存, 文章 文章配置 文章内容
- 有id,传来的文章id对应章内容表里的文章id 进行修改。先根据articleId查出来content实体,然后setContent在insert回去
package com.heima.article.service.impl;
import com.alibaba.cloud.commons.lang.StringUtils;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.heima.article.mapper.ApArticleConfigMapper;
import com.heima.article.mapper.ApArticleContentMapper;
import com.heima.article.mapper.ApArticleMapper;
import com.heima.article.service.ApArticleService;
import com.heima.common.constants.ArticleConstants;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.article.dtos.ArticleHomeDto;
import com.heima.model.article.pojos.ApArticle;
import com.heima.model.article.pojos.ApArticleConfig;
import com.heima.model.article.pojos.ApArticleContent;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Date;
import java.util.List;
@Service
public class ApArticleServiceImpl extends ServiceImpl<ApArticleMapper, ApArticle> implements ApArticleService {
@Autowired
ApArticleMapper apArticleMapper;
/**
* 加载文章列表
*
* @param dto
* @param type 1为加载更多,2为加载最新
* @return
*/
@Override
public ResponseResult load(ArticleHomeDto dto, Short loadtype) {
// 参数校验
// 判断大小是否正确
Integer size = dto.getSize();
if (size == null || size == 0) {
size = Math.min(size, 50);
}
// 类型参数检验,既不为1,加载更多也不为2加载最新,那么就默认1加载更多
if (!loadtype.equals(ArticleConstants.LOADTYPE_LOAD_MORE) && !loadtype.equals(ArticleConstants.LOADTYPE_LOAD_NEW)) {
loadtype = ArticleConstants.LOADTYPE_LOAD_MORE;
}
// 文章频道校验,如果不指定频道,那就是首页,直接加载最新10条
if (StringUtils.isEmpty(dto.getTag())) {
dto.setTag(ArticleConstants.DEFAULT_TAG);
}
// 时间校验。如果没有最大和最小时间,那么说明时间范围为无限,此时降序展示10条最新数据,与前面的Tag频道搭配
if (dto.getMaxBehotTime() == null) dto.setMaxBehotTime(new Date());
if (dto.getMinBehotTime() == null) dto.setMinBehotTime(new Date());
// 2.查询数据
List<ApArticle> apArticles = apArticleMapper.loadArticleList(dto, loadtype);
return ResponseResult.okResult(apArticles);
}
@Autowired
private ApArticleConfigMapper articleConfigMapper;
@Autowired
private ApArticleContentMapper apArticleContentMapper;
@Autowired
private ApArticleMapper articleMapper;
/**
* 保存app端相关文章
*
* @param dto
* @return
*/
@Override
public ResponseResult saveArticle(ArticleDto dto) {
// 0. 校验参数
if (dto == null) {
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
// 保存文章,先拷贝
ApArticle apArticle = new ApArticle();
BeanUtils.copyProperties(dto, apArticle);
// 1. 没由id的情况下
if (dto.getId() == null) {
// 保存文章
save(apArticle);
// 初始化文章配置实体,保存文章实体
ApArticleConfig apArticleConfig = new ApArticleConfig(apArticle.getId());
articleConfigMapper.insert(apArticleConfig);
// 保存文章内容到文章内容表
ApArticleContent apArticleContent = new ApArticleContent();
// id+content id相当于开后门,后续修改update可以根据他找到家~
apArticleContent.setArticleId(apArticle.getId());
apArticleContent.setContent(dto.getContent());
apArticleContentMapper.insert(apArticleContent);
}
// 2.存在id,那就是修改了
else {
// 直接修改文章,可能是封面?还是标题?
articleMapper.updateById(apArticle);
// 修改分出去的另一张文章内容表 ,根据文章id找,使用lambda
ApArticleContent apArticleContent = apArticleContentMapper.selectOne(Wrappers.<ApArticleContent>lambdaQuery().eq(ApArticleContent::getArticleId, dto.getId()));
apArticleContent.setContent(dto.getContent());
apArticleContentMapper.updateById(apArticleContent);
}
//3结果返回id
return ResponseResult.okResult(apArticle.getId());
}
}
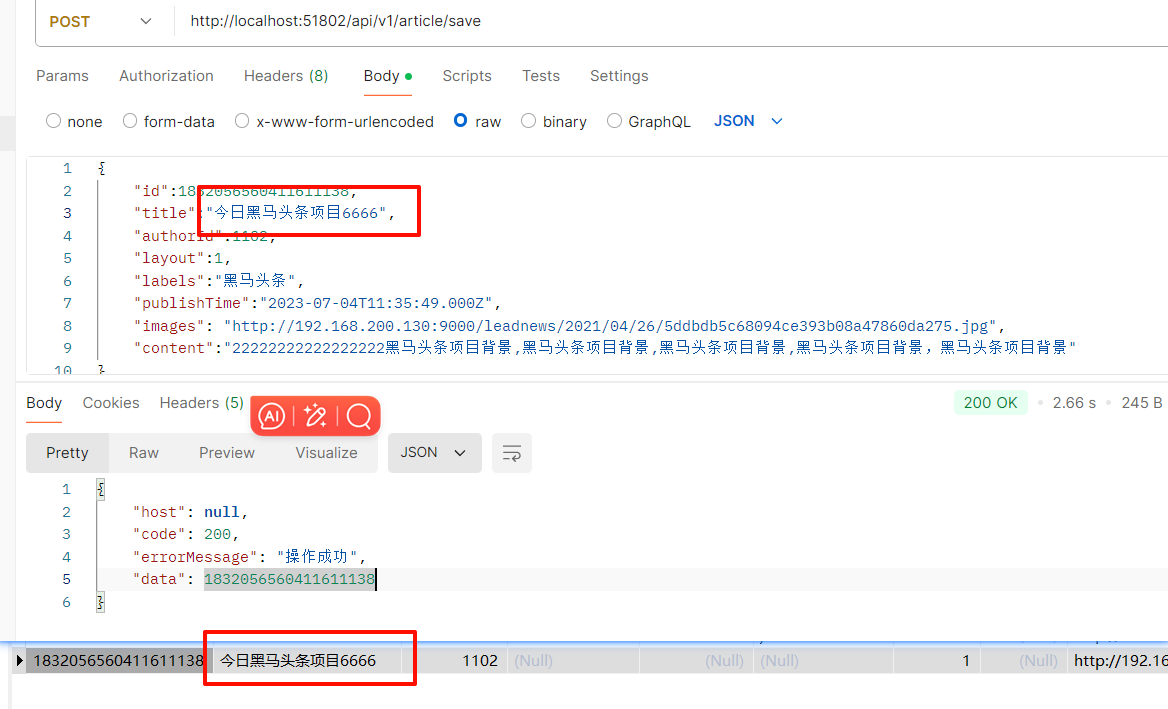
启动postman发保存请求测试
http://localhost:51802/api/v1/article/save
{
"title":"黑马头条项目背景22222222222222",
"authoId":1102,
"layout":1,
"labels":"黑马头条",
"publishTime":"2028-03-14T11:35:49.000Z",
"images": "http://192.168.200.130:9000/leadnews/2021/04/26/5ddbdb5c68094ce393b08a47860da275.jpg",
"content":"22222222222222222黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景"
}
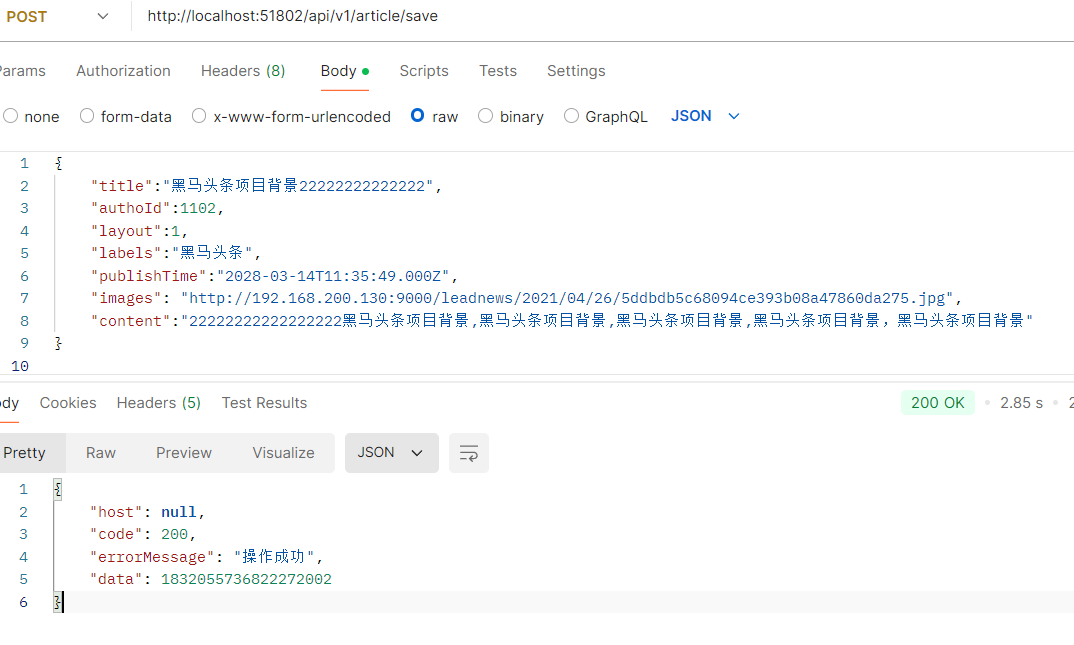

好家伙2028年
好家伙讲义authoId,少个r
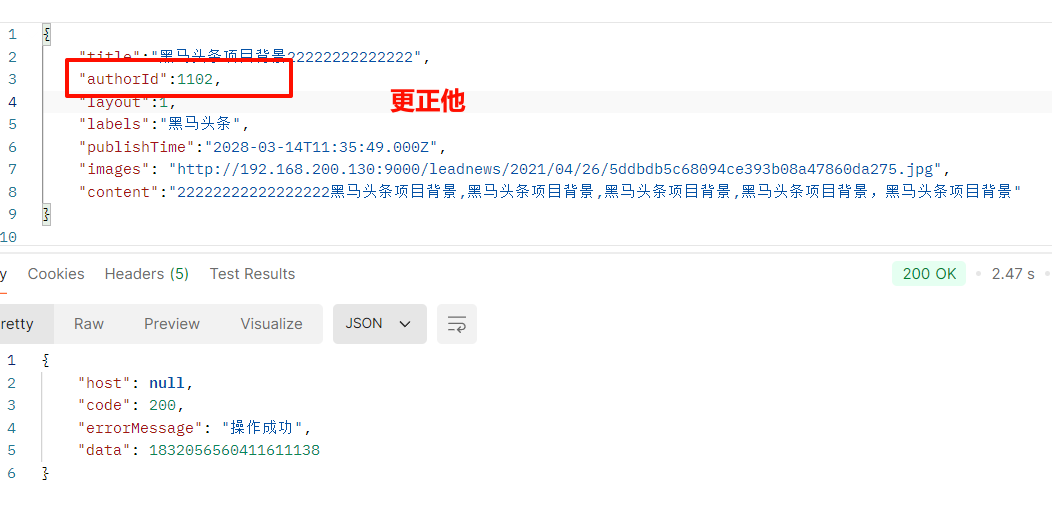
修改测试
{
"title":"黑马头条项目背景66666",
"authoId":1102,
"layout":1,
"labels":"黑马头条",
"publishTime":"2028-03-14T11:35:49.000Z",
"images": "http://192.168.200.130:9000/leadnews/2021/04/26/5ddbdb5c68094ce393b08a47860da275.jpg",
"content":"22222222222222222黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景"
}
先捋一下前面的服务
model,common,utl模块静态引用
feign-api内部服务互相访问
gateway外部请求重定向具体服务(具体的某个网关添加拦截器id加工处理操作对象标识)
service多个业务服务
basic自定义starter(minio)后续文章保存微服务引入并调用生成静态url路径并保存内容到数据库
test测试模块包含对freemarker的使用,和minio的使用
-
当有很多标识时使用枚举或常量
-
共同条件放最后,独有条件前判断,过五关斩六将
-
大文本大空间分表,减少数据库压力
-
minio存静态url,减少查询大表数据
-
提交文章时根据类型进行 设置type并且设置从内容抽取封面图,文章and素材绑定写表,删素材必须先删文章
-
自媒体保存文章,调用前台文章的保存,或修改,且配置表不变,只在新增时变化
-
存素材,拦截器存id,接口拿id,以id存对应素材,和收藏关系
-
feign要调用谁,谁实现接口,到时候审核完毕则调用该保存接口
-
微服务实现流程
springboot
-
配置bootstrap yml,填入远程注册中心端口
-
写服务名(后续拿着这个去注册中心匹配),
服务发现注册:discovery配置云端nacos的服务地址+端口配置注册:config,配置云端nacos IP+PORT ,指定文件后缀yml
nacos中心
-
datasource,mp配置
-
路由则填写每个服务的路由名
-
id 唯一标识
-
lb://leadnews-user 标识转发到后端服务的地址
-
predicates翻译过来是谓词?转发路由所需满足的条件?
-Path=/user/** 必须以/user打头的请求路径 -
stripPrefix,翻译为条带前缀 等于1意为去掉路径的第一标识
/user/** => /** 这样就能成功定位到后端的某个接口
-
-
3.自媒体文章审核
3.1表结构
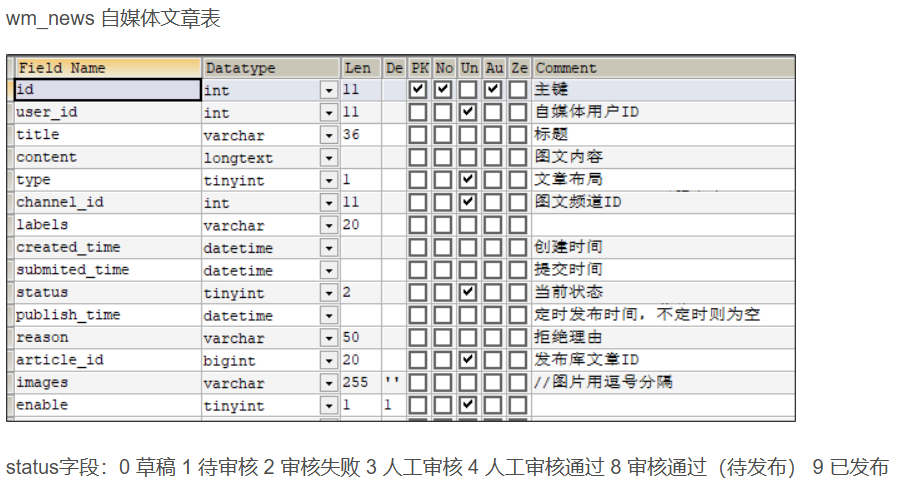
3.2实现
3.2.1思路
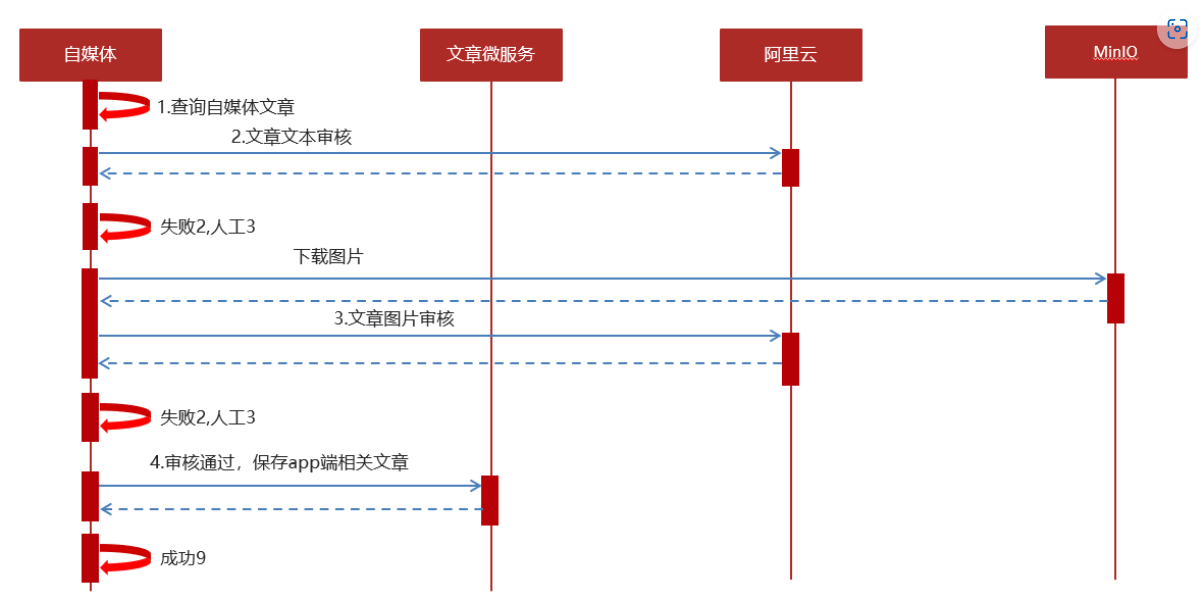
自媒体审核在自媒体微服务下
3.2.2service
传自媒体文章id
package com.heima.wemedia.service;
public interface WmNewsAutoScanService {
/**
* 自媒体文章审核
* @param id 自媒体文章id
*/
public void autoScanWmNews(Integer id);
}
3.2.3实现

content的结构是由多个对象组成,用map的key-value结构收集
package com.heima.wemedia.service.impl;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.heima.apis.article.IArticleClient;
import com.heima.common.aliyun.GreenImageScan;
import com.heima.common.aliyun.GreenTextScan;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.wemedia.pojos.WmChannel;
import com.heima.model.wemedia.pojos.WmNews;
import com.heima.model.wemedia.pojos.WmUser;
import com.heima.wemedia.mapper.WmChannelMapper;
import com.heima.wemedia.mapper.WmNewsMapper;
import com.heima.wemedia.mapper.WmUserMapper;
import com.heima.wemedia.service.WmNewsAutoScanService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.InputStream;
import java.util.*;
import java.util.stream.Collectors;
@Service
@Slf4j
@Transactional
public class WmNewsAutoScanServiceImpl implements WmNewsAutoScanService {
@Autowired
private WmNewsMapper wmNewsMapper;
/**
* 自媒体文章审核
*
* @param id 自媒体文章id
*/
@Override
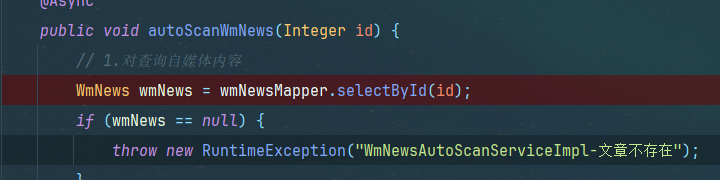
public void autoScanWmNews(Integer id) {
// 1.对查询自媒体内容
WmNews wmNews = wmNewsMapper.selectById(id);
if (wmNews == null) {
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章不存在");
}
// 判断该文章是否是已提交状态
if (!wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())) {
// 对其内容抽取取出所有的Text和Image,这里我们封装一个方法
Map<String, Object> stringObjectMap = extractTextAndImage(wmNews);
// 2.文本审核方法.传文本和文章,后续根据审核结果修改文章数据库的状态为人工审核还是审核成功的状态
if (scanText(stringObjectMap.get("text"), wmNews)) return;
// 3.图片审核
if (scanImages(wmNews, (List<String>) stringObjectMap.get("images"))) return;
// 4.审核通过,修改状态为已发布
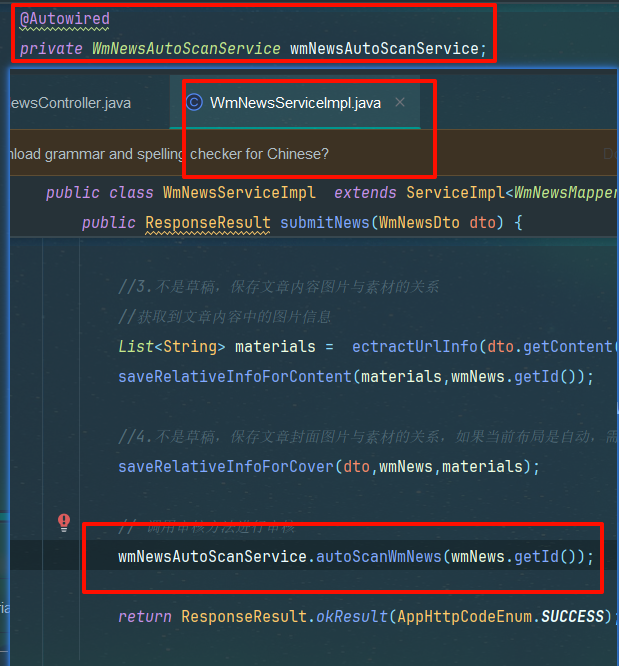
ResponseResult result = saveApArticle(wmNews);
if (result.getCode() != 200) {
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章审核,保存app端相关文章数据失败");
}
//回填article_id,下次进行修改会使用到
wmNews.setArticleId((Long) result.getData());
updateWmNews(wmNews, (short) 9, "审核成功");
}
}
@Autowired
private WmChannelMapper wmChannelMapper;
@Autowired
private WmUserMapper wmUserMapper;
@Autowired
private IArticleClient articleClient;
private ResponseResult saveApArticle(WmNews wmNews) {
wmNews.setStatus(WmNews.Status.PUBLISHED.getCode());
ArticleDto articleDto = new ArticleDto();
BeanUtils.copyProperties(wmNews, articleDto);
// 文章布局,自媒体里叫做type,而ap端叫layout,也就是封面那玩意了其实
articleDto.setLayout(wmNews.getType());
// 拷贝频道名 因为分表了
WmChannel wmChannel = wmChannelMapper.selectById(wmNews.getChannelId());
if (wmChannel != null) {
articleDto.setChannelName(wmChannel.getName());
}
// 作者名
Integer userId = wmNews.getUserId();
WmUser wmUser = wmUserMapper.selectById(userId);
articleDto.setAuthorId(Long.valueOf(userId));
if (wmUser != null) {
articleDto.setAuthorName(wmUser.getName());
}
// 文章id设置同步自媒体和app端id
if (wmNews.getArticleId() != null) {
articleDto.setId(wmNews.getArticleId());
}
// 创建时间
articleDto.setCreatedTime(new Date());
//远程调用传递数据
ResponseResult responseResult = articleClient.saveArticle(articleDto);
return responseResult;
}
@Autowired
private GreenImageScan greenImageScan;
@Autowired
private FileStorageService fileStorageService;
private boolean scanImages(WmNews wmNews, List<String> images) {
boolean flag = true;
// 判断有无图片,无图片无需审核
if (images.size() == 0 || images == null) {
return flag;
}
// 依次下载图片到list里,用bytes数组存储每一张图片
// 由于封面可能来自于内容,所以要去重
images = images.stream().distinct().collect(Collectors.toList());
List<byte[]> bytes = new ArrayList<>();
for (String image : images) {
byte[] imageBytes = fileStorageService.downLoadFile(image);
bytes.add(imageBytes);
}
// 将该集合传给接口审核
try {
Map map = greenImageScan.imageScan(bytes);
if (map != null) {
if (map.get("suggestion").equals("block")) {
flag = false;
updateWmNews(wmNews, (short) 2, "当前文章存在违规内容");
}
// 不确定信息 需要人工审核
if (map.get("suggestion").equals("review")) {
flag = false;
updateWmNews(wmNews, (short) 3, "当前文章存在不确定内容,需要人工审核");
}
}
} catch (Exception e) {
flag = false;
e.printStackTrace();
}
return flag;
}
@Autowired
private GreenTextScan greenTextScan;
private boolean scanText(Object text, WmNews wmNews) {
boolean flag = true;
if (StringUtils.isBlank(wmNews.getTitle()) || StringUtils.isBlank(text.toString())) {
return flag;
}
try {
Map map = greenTextScan.greeTextScan(wmNews.getTitle() + "-" + text.toString());
if (map != null) {
if (map.get("suggestion").equals("block")) {
flag = false;
updateWmNews(wmNews, (short) 2, "当前文章存在违规内容");
} else if (map.get("suggestion").equals("review")) {
flag = false;
updateWmNews(wmNews, (short) 3, "当前文章存在不确定内容,需要人工审核");
}
}
} catch (Exception e) {
flag = false;
e.printStackTrace();
}
return flag;
}
private void updateWmNews(WmNews wmNews, short status, String reason) {
wmNews.setStatus((short) status);
wmNews.setReason(reason);
wmNewsMapper.updateById(wmNews);
}
private Map<String, Object> extractTextAndImage(WmNews vmNews) {
// 抽取出来content然后加工
String content = vmNews.getContent();
// 初始化String容器和List<String>容器来存储Text和Images
StringBuilder stringBuilder = new StringBuilder();
List<String> images = new ArrayList<>();
// 对content进行拆分,拆分出Text和Images
// 1,从内容提取出图片和文本
if (StringUtils.isNotBlank(content)) {
// 由于存放的数据是json字符串,这里我们把它转为对象,且属性为多个Map,KV结构
List<Map> maps = JSON.parseArray(content, Map.class);
// 遍历map,如果是文本就放到字符串构造器,图片放list里
for (Map map : maps)
if (map.get("type").equals("text")) {
stringBuilder.append(map.get("value"));
} else if (map.get("type").equals("image")) {
images.add(map.get("value").toString());
}
}
// 2.提取文章封面图
String covers = vmNews.getImages();
if (StringUtils.isNotBlank(covers)) {
// 转为字符串数组
String[] split = covers.split(",");
// 转为List并且addAll该list的所有内容到图片集合
images.addAll(Arrays.asList(split));
}
// 3.将文本和图片存入map里后续审核
Map<String, Object> stringObjectMap = new HashMap<>();
stringObjectMap.put("content", stringBuilder.toString());
stringObjectMap.put("images", images);
return stringObjectMap;
}
}
添加feign注解,扫描feign apis包否则iarticleClient注入,远程调用失效
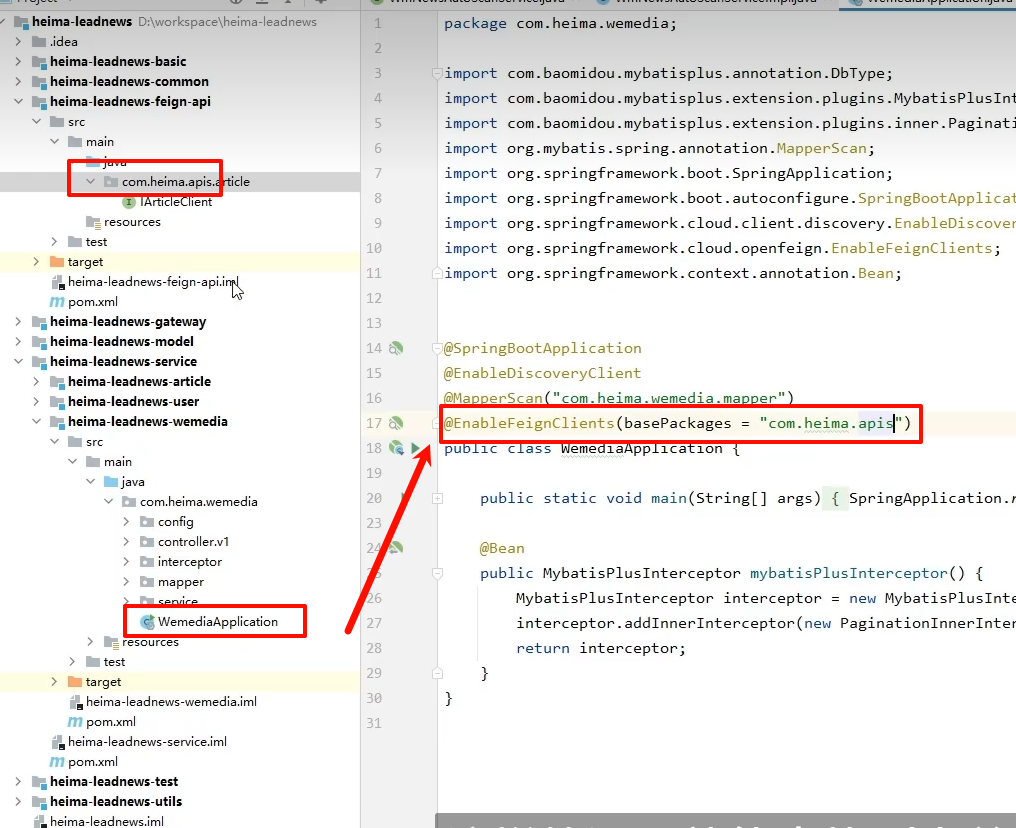
@EnableFeignClients(basePackages = "com.heima.apis")
不报红了了
3.2.4单元测试
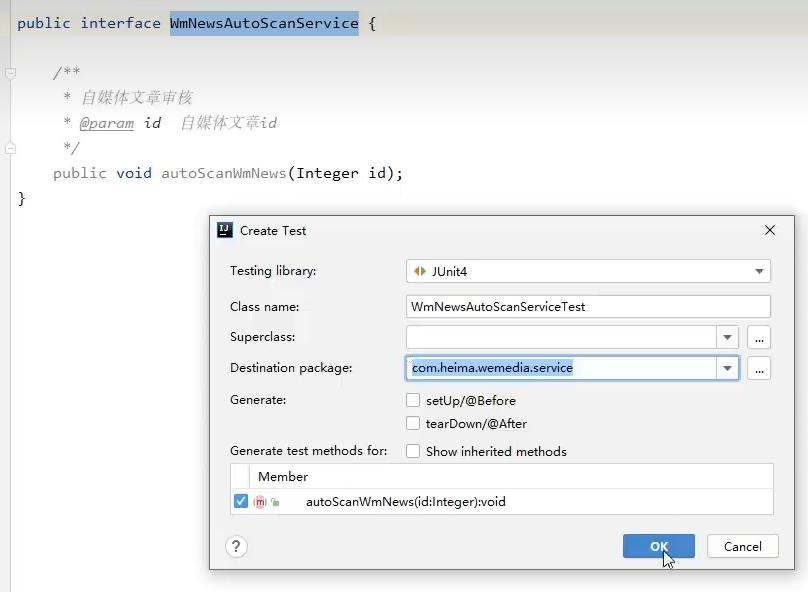
选中类名ctrl + shift + T创建
指定上下文和运行类(运行测试类之前先启动aparticle服务,因为feign要调他)
id填写之前创建的数据
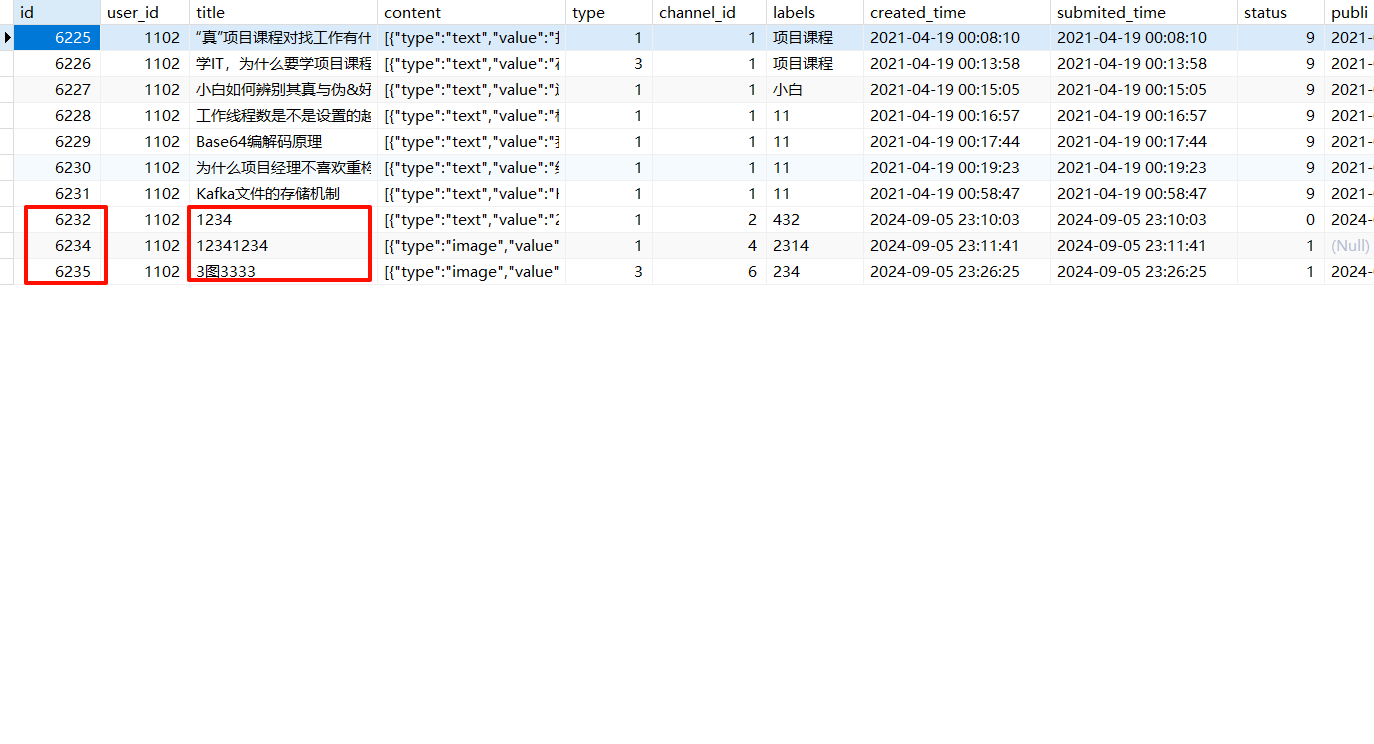
package com.heima.wemedia.service;
import com.heima.wemedia.WemediaApplication;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import static org.junit.Assert.*;
@SpringBootTest(classes = WemediaApplication.class)
@RunWith(SpringRunner.class)
public class WmNewsAutoScanServiceTest {
@Autowired
private WmNewsAutoScanService wmNewsAutoScanService;
@Test
public void autoScanWmNews() {
wmNewsAutoScanService.autoScanWmNews(6238);
}
}
如果出现timeout的在feign模块下新建配置文件application.yml 超时时间拉满,因为你电脑太fw了加载半天
#hystrix的超时时间
hystrix:
command:
default:
execution:
timeout:
enabled: true
isolation:
thread:
timeoutInMilliseconds: 3000000
#ribbon的超时时间
ribbon:
ReadTimeout: 30000000
ConnectTimeout: 300000000
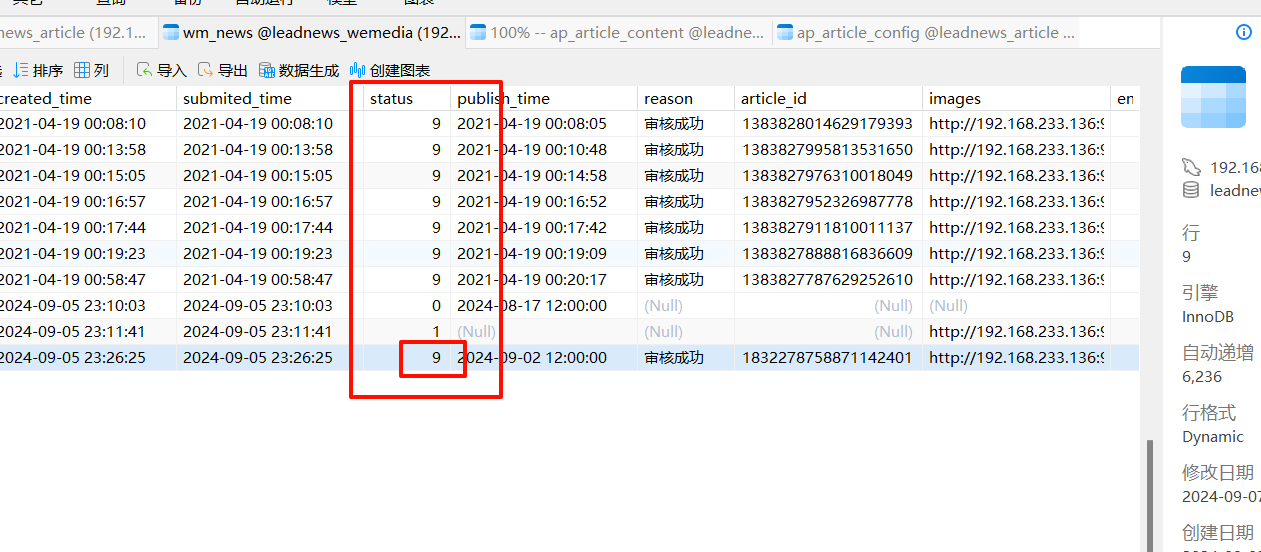
wmNews测试通过,状态为已发布,审核成功
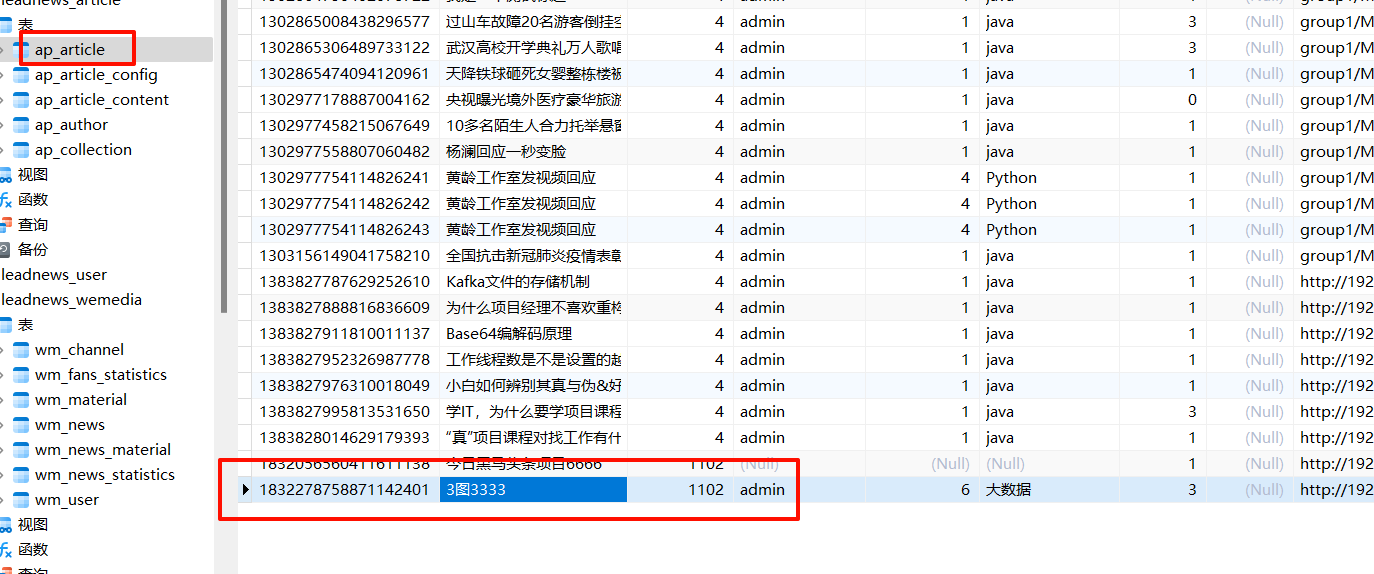
用户浏览端数据库增加成功
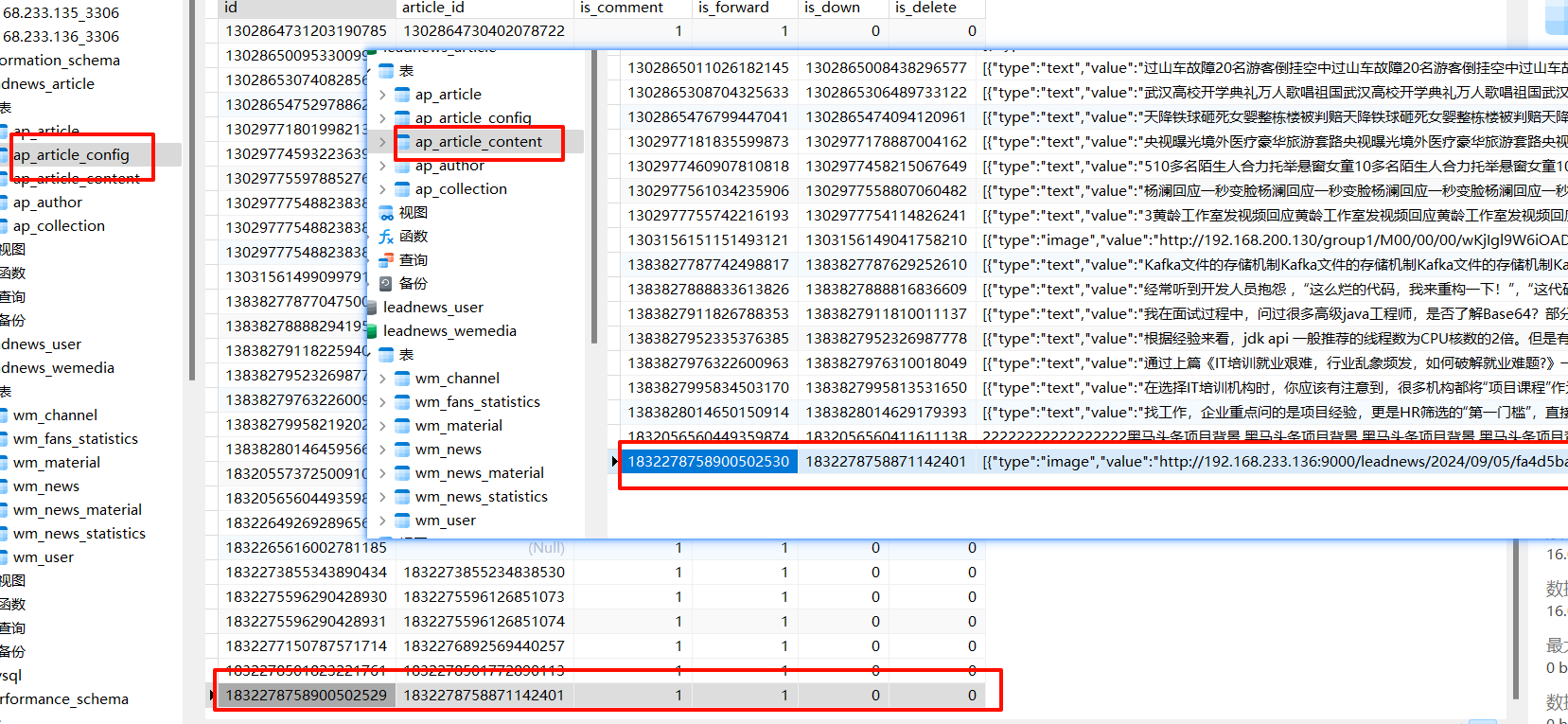
内容配置表新增成功…
3.2.5fegin接口调用方式
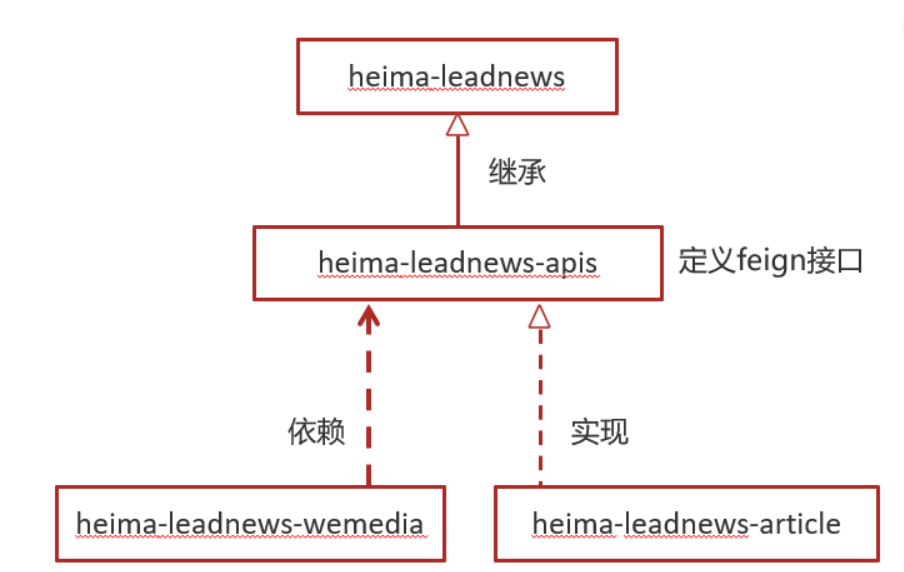
wemediea服务(发请求的人)引入apis依赖,调用article客户端发请求
引导类增加注释,开启feign指定客户端端包
4.feign调用服务降级
4.1场景
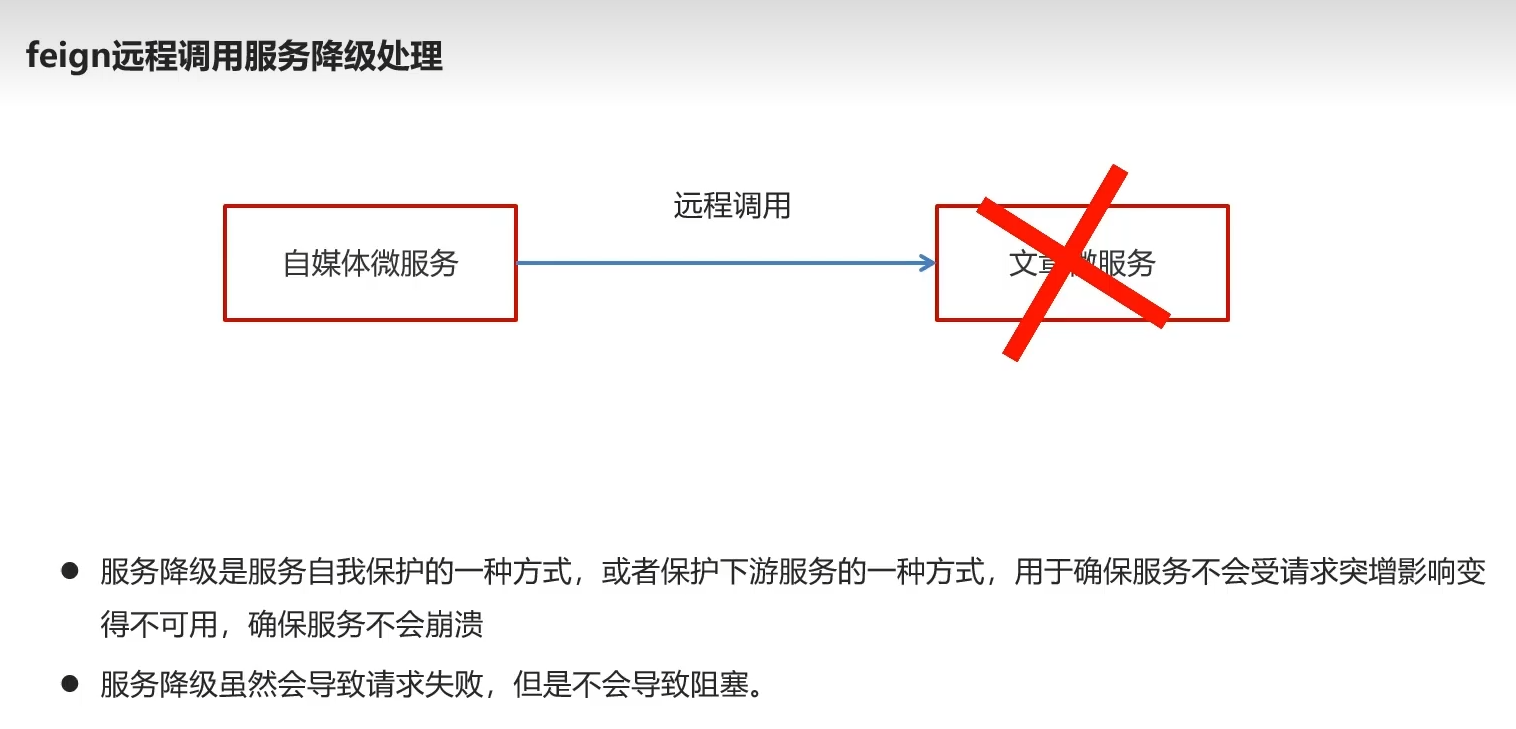
服务自我保护,保护服务不崩溃
会导致请求失败,但是不会阻塞请求也就是说不会卡住,会闪退的意思
当服务接收不了太多请求时降级,
4.2步骤
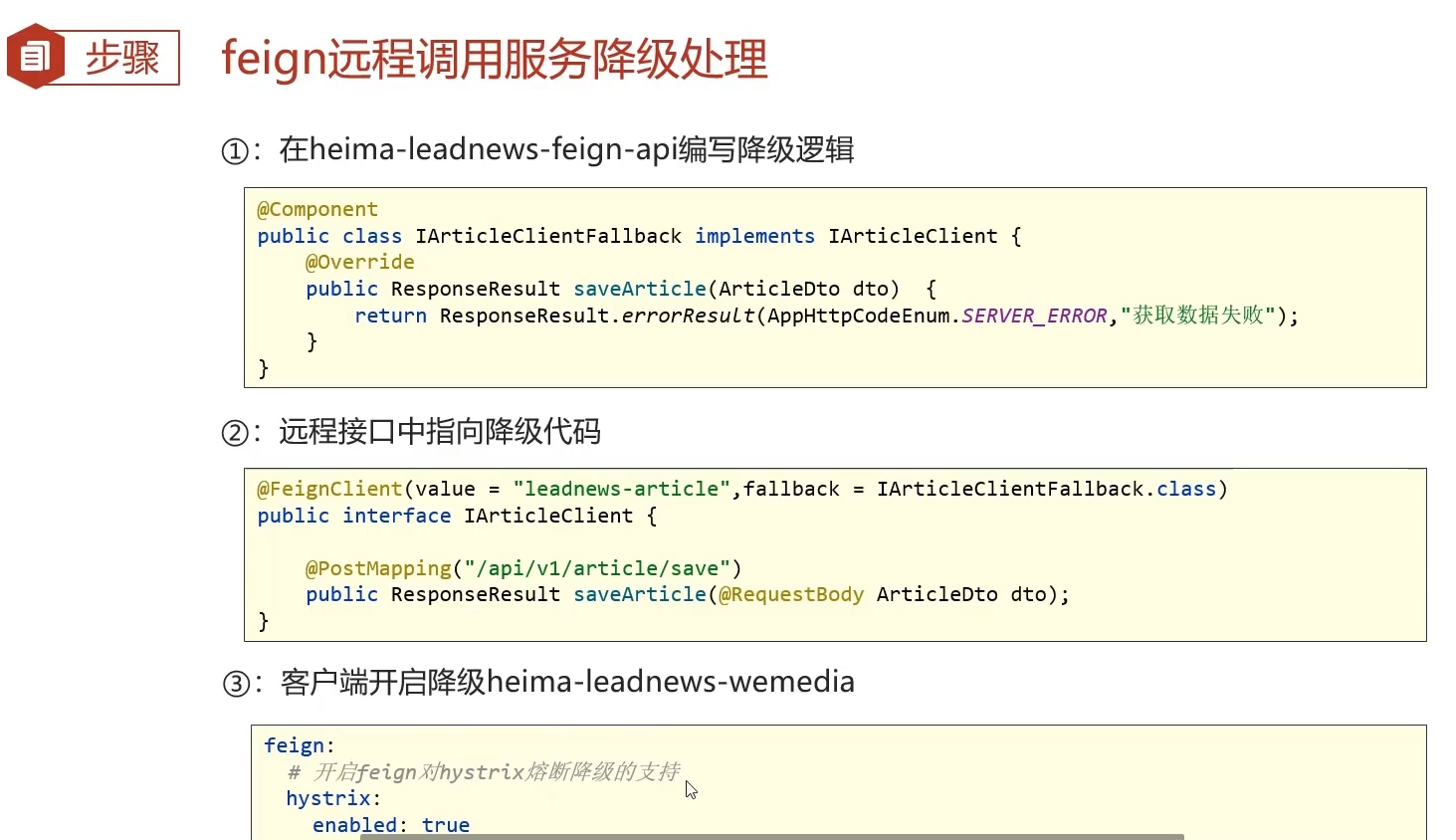
①实现接口,设置响应
②远程接口注解里增加属性fallback,指向降级类
③客户端配置文件开启熔断降级支持
降级类
package com.heima.apis.article.fallback;
import com.heima.apis.article.IArticleClient;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import org.springframework.stereotype.Component;
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}
远程接口指向降级代码类
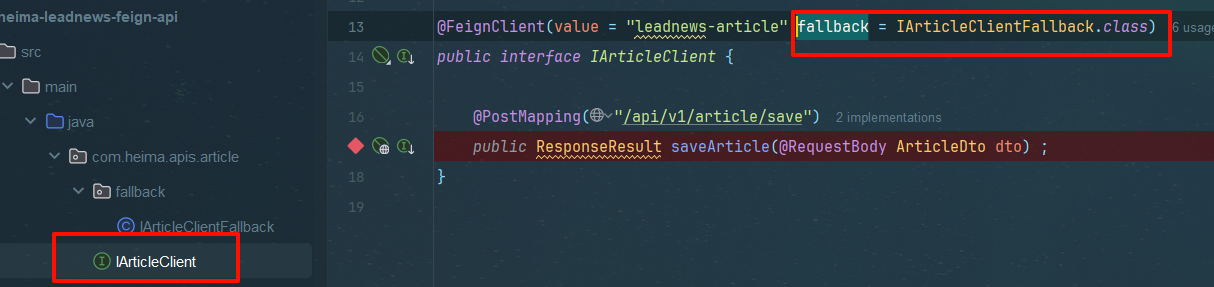
@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
由于该降级类存在在feign模块,不在wemedia下,不能被其加载component注解失效,因此要在wemedia服务下创建初始配置类扫描apis/fallback包,
因为该降级处理类作用在客户端wemedia上也就是发请求的那一方,所以客户端要将该类加载到自身的容器里
扫描类代码
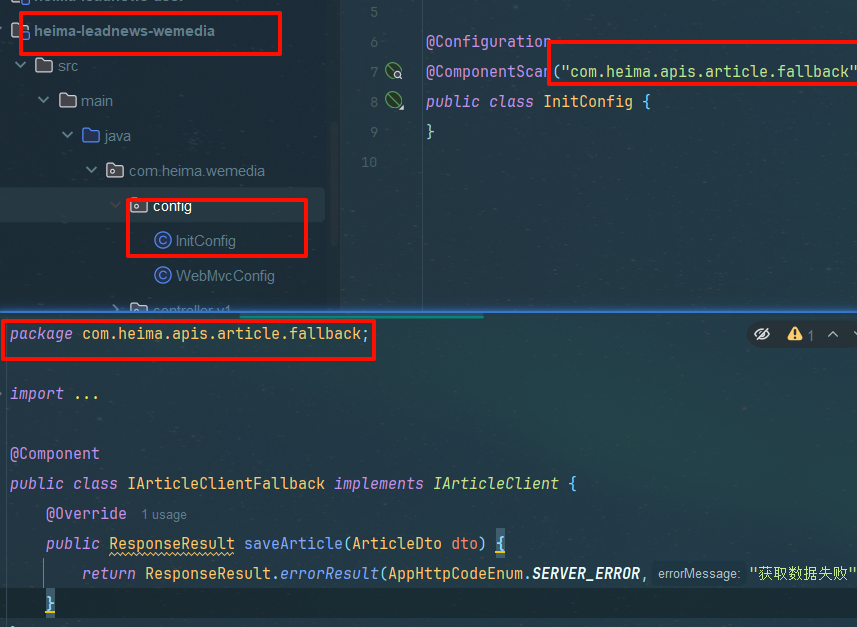
package com.heima.wemedia.config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.heima.apis.article.fallback")
public class InitConfig {
}
配置文件开启服务降级
一般不在编码的配置文件里设置 而在nacos配置中心
为什么基本配置都写在nacos呢?
- 统一管理
- 动态更新,不用重新编译打包部署重启,直接改配置中心
- 版本历史回滚
- 权限控制,不同角色配置内容不一样
- 健康检查,配置文件坏了及时通知管理员
- 格式灵活,yml xml。。。等等 还有许多由于不光说不练假把式就不列举了,反正用到再来
这里我们前面在feign模块下也有设置了。此时我们可以把原先的删除重新在这指定超时时间即可
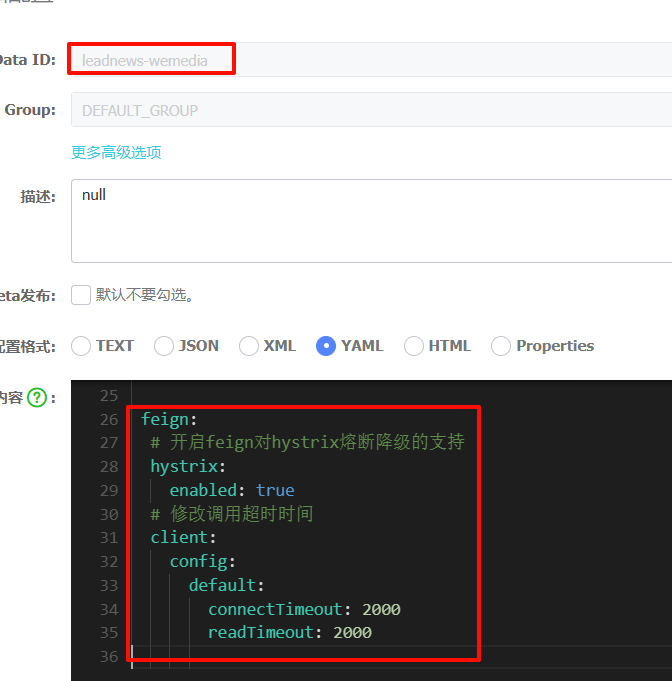
feign:
# 开启feign对hystrix熔断降级的支持
hystrix:
enabled: true
# 修改调用超时时间
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
注意这里缩进不要复制错了,刚才报了1次错浪费了我几分钟,泪目
4.3测试
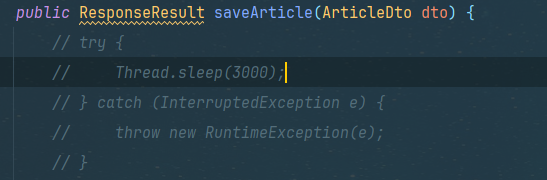
在文章保存实现类设置定时器,3000超过时间则失败,尝尝咸淡
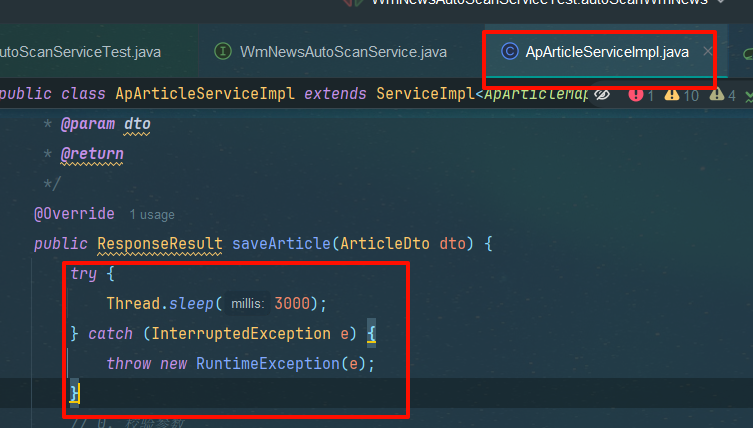
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
审核测试,由于之前创建了多条,这回还另一篇待审核的试试,你也可以修改刚才审核成功的9为1然后试试看

运行查看

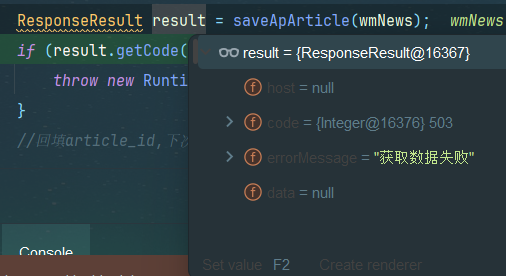
成功到达降级类

记得删掉 “优化加钱代码”
5.发布文章后异步审核

哪种好?异步的,发出审核调用后直接下一条代码接着干,同步还得搁那傻傻的等待,阻塞请求,体验感极差
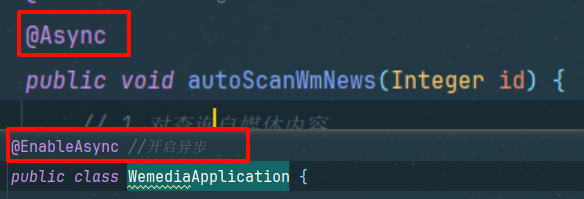
5.1步骤

①方法上加注解
②成功发布后调用审核方法
③引导类加注解开启异步调用
6.综合测试
服务启动列表


测试发布&&自动审核


自动审核成功
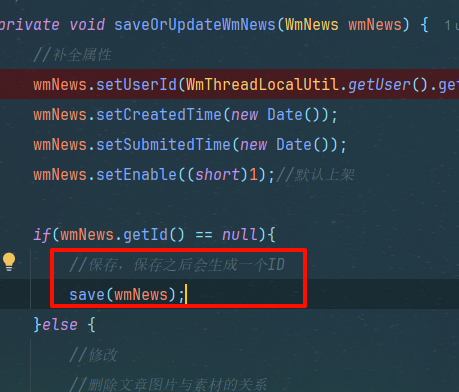
如果你的内容很多,那么数据库保存 素材~文章 关系表会很慢,因此下文拿不到
就是说前面保存的vmNews的动作还没执行完,id也没生成好,由于数据库操作是异步的
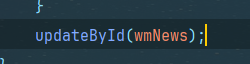
这俩其中之一涉及数据库的操作 没执行完此时
这一步还没搞完因此select不到,
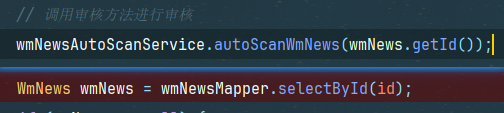

我们可以给他加一个定时器1秒让他执行完前面数据库操作再来select,不过一旦涉及到了定时器,业务就开始变得臃肿了感觉
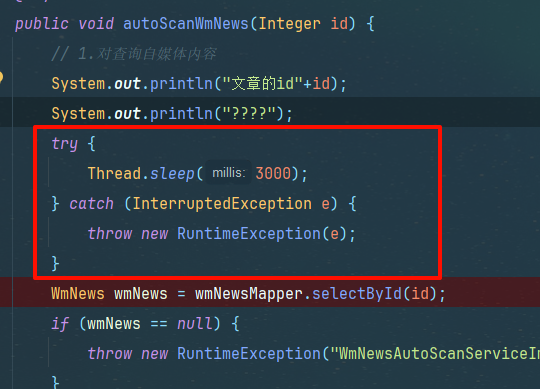
刷新再次添加大内容的文章,等待三秒刷新 审核成功,
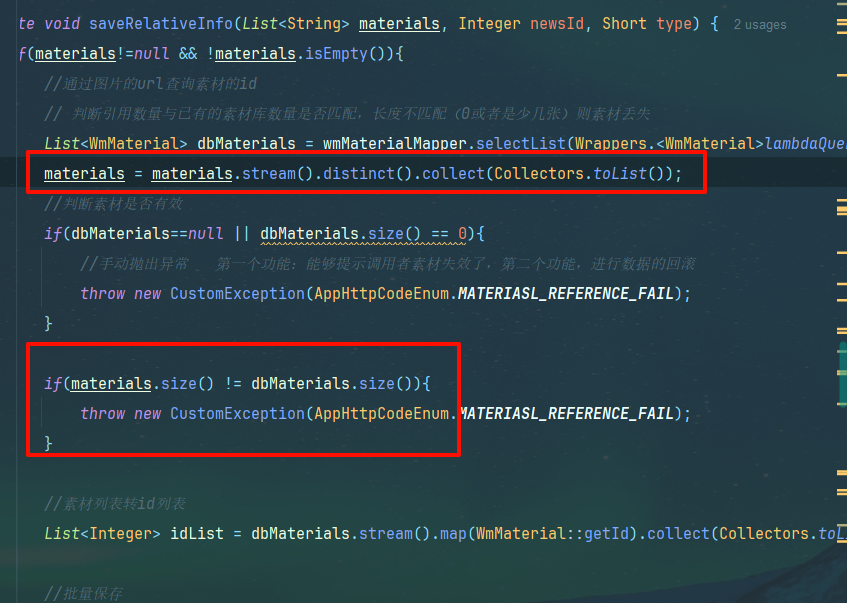
太捞了b样的,我一张素材库还只能添加一次。因为他是素材库和imgurl一一对应的,也就是前面比较url.size=dbUrl.size也就是说我一张图片给多次引用就产生了 dbUrl=1 urlSize=5次引用,
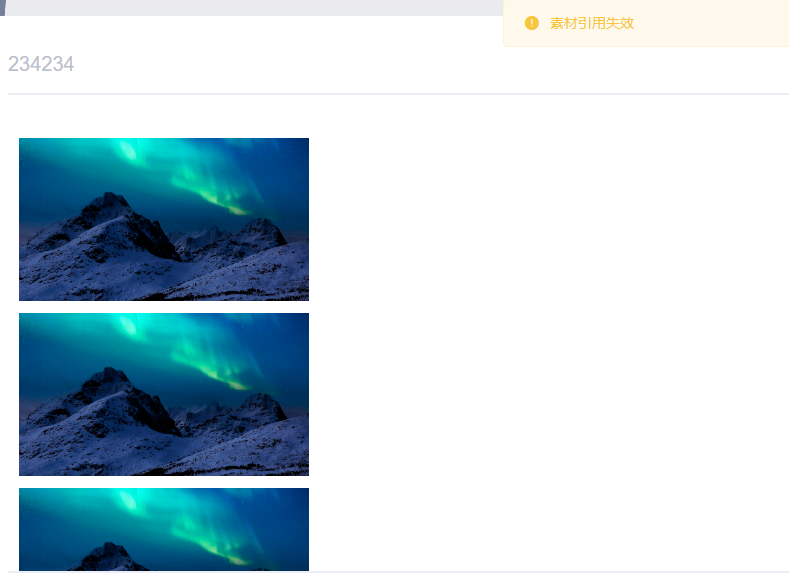
不过可以给前端content内的url去重,测试保存成功
还有个槽点,这个图片添加的按钮太tm小了吧,而且一次一张,猴年马月
如果你有内容安全的接口如果输入敏感词会得到以下效果

敏感ak47,csdn不会检测到吧 (笑)
如果审核过程中炸了不影响发布,不过审核状态一直为待审核
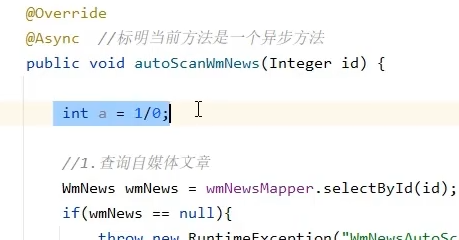

上页面了,不过一直待审核
7.自管理的敏感词

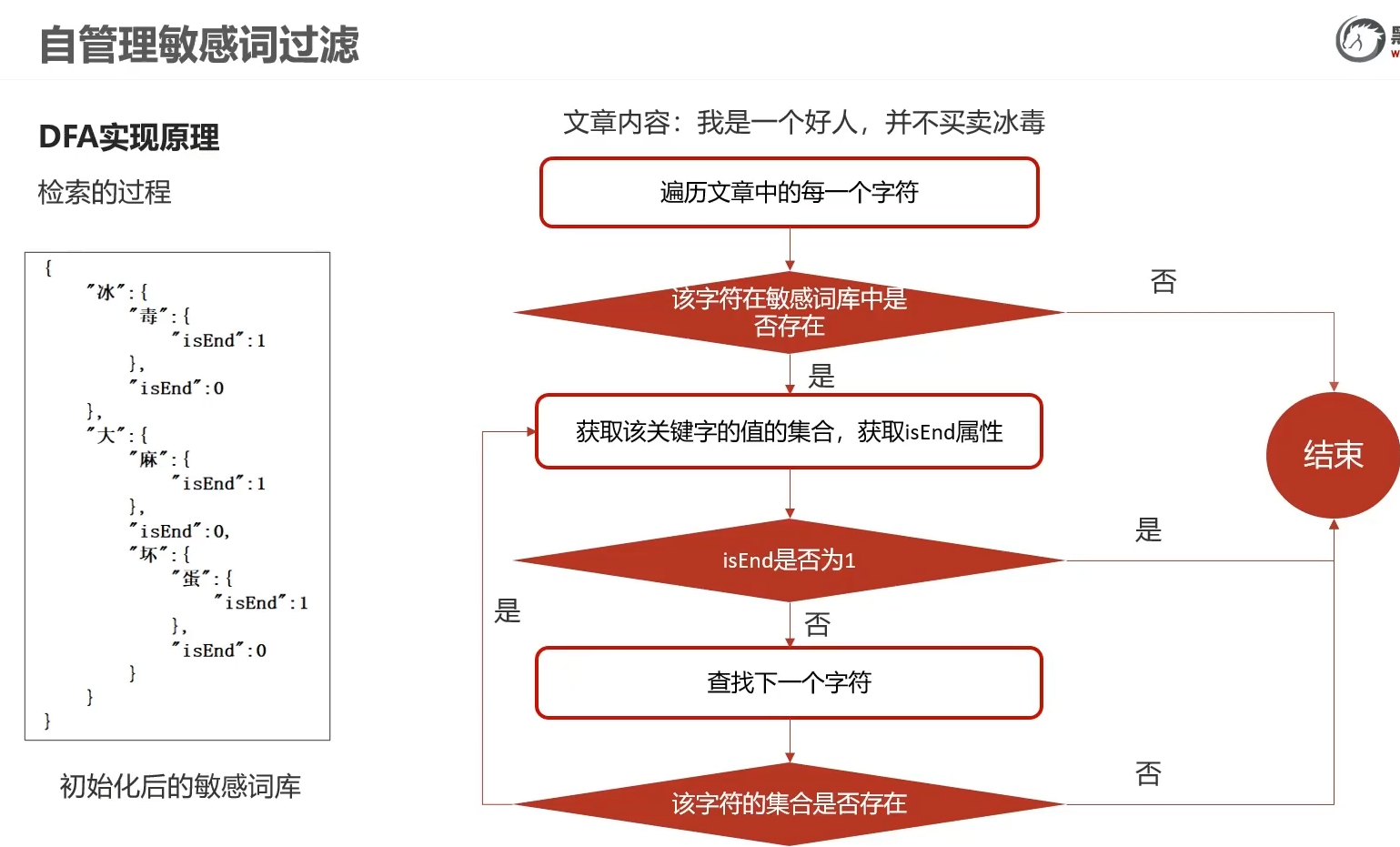
意思是以什么开头,且以什么为end,说明该词为敏感词 通俗点举例,end为1,说明这个词完蛋了,end结束了
例如
- 冰,不是end为1
- 冰,不是end为1,
- 下一个字符不存在,只有单个冰,则结束
- 下一个字符毒存在,get索引,查下一个如果下一个字符存在,则获取是否为最后一个,isEnd,如果是,则该tree成立,判断为敏感词
- 下一个字符块存在,get索引,不在该树里,且跳出结束 ,但是冰X毒怎么算?
直至检测到最后一个值不在该树里则通过
7.1dfv算法工具类
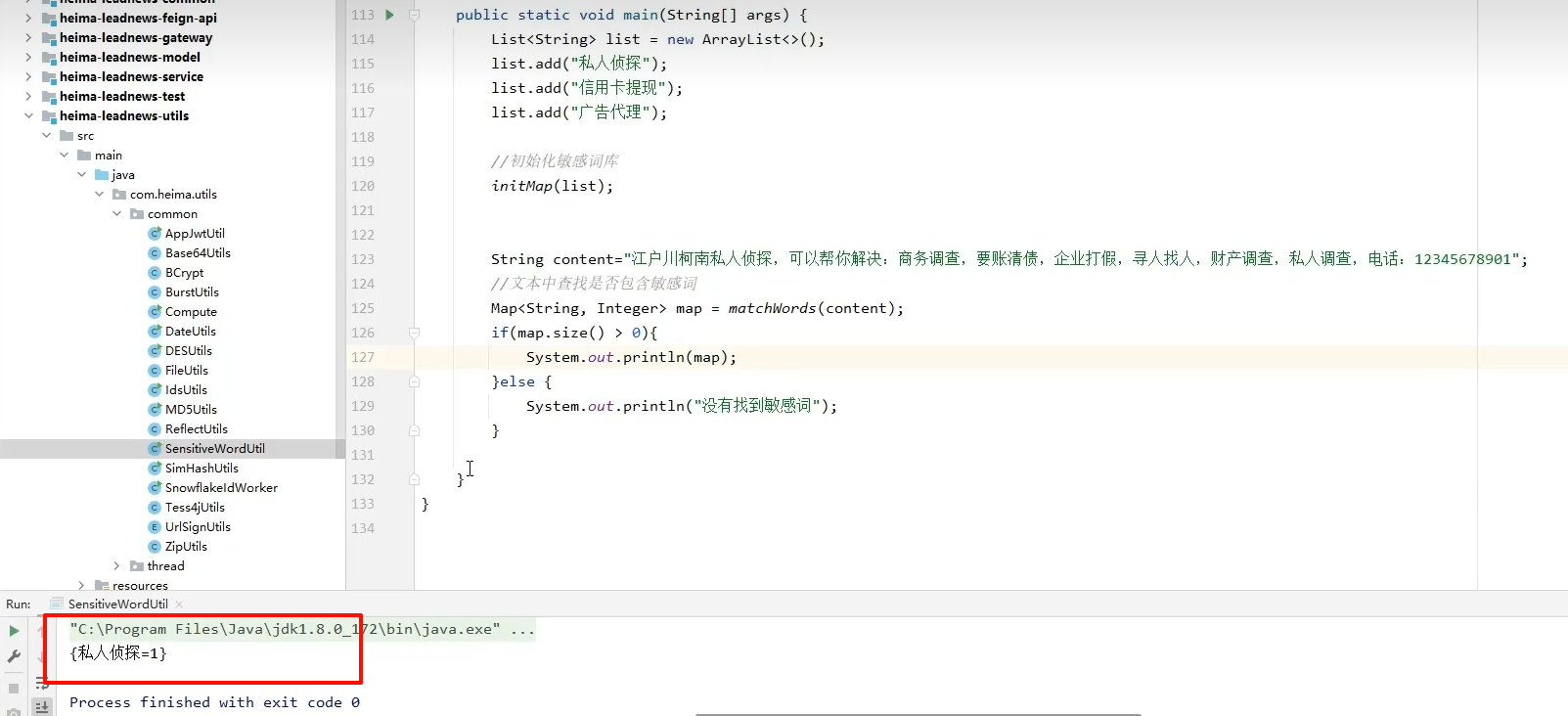
检测到则提示出现次数
7.2文章审核集成自管理敏感词
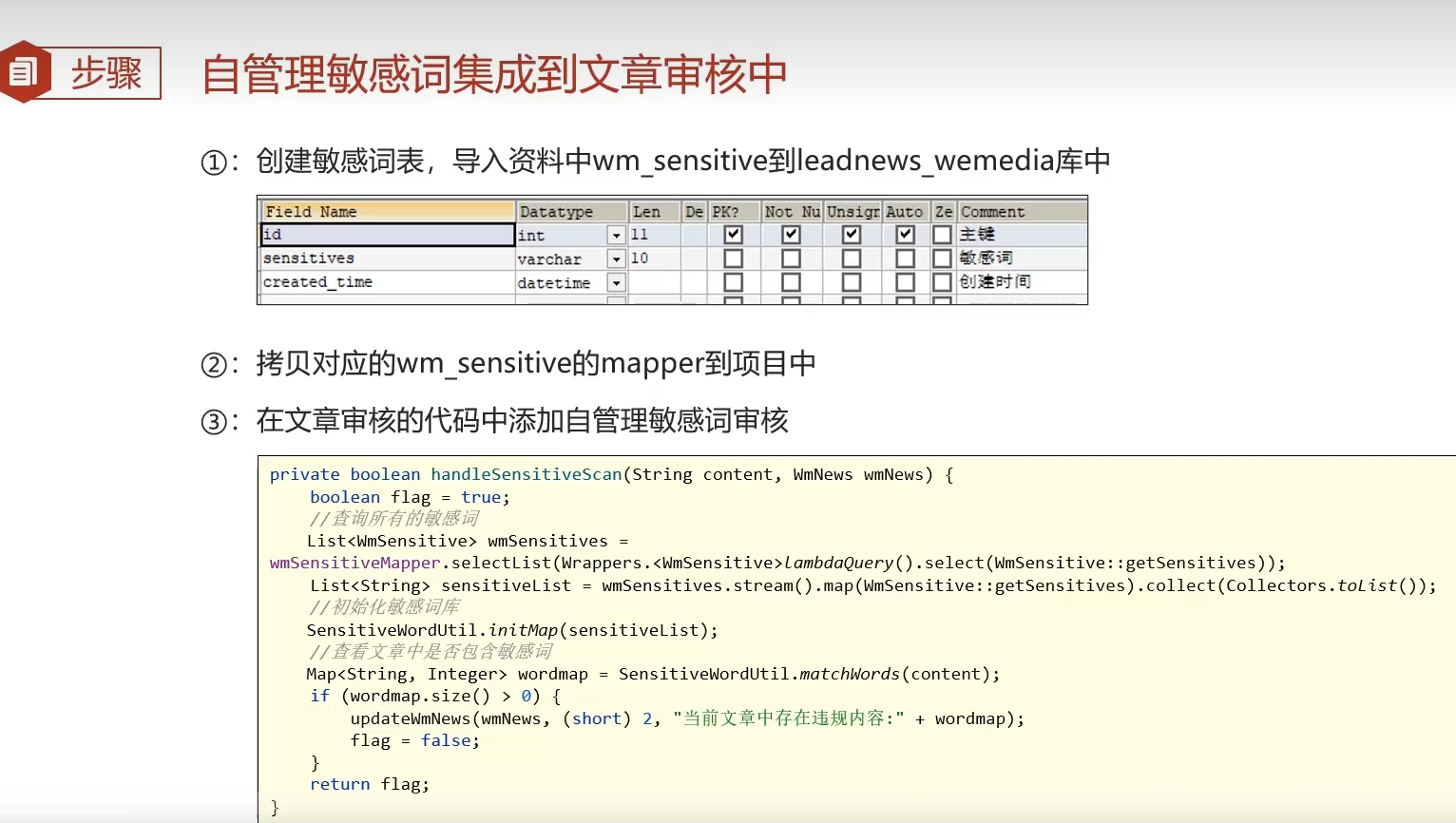
实体
package com.heima.model.wemedia.pojos;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* <p>
* 敏感词信息表
* </p>
*
* @author itheima
*/
@Data
@TableName("wm_sensitive")
public class WmSensitive implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 敏感词
*/
@TableField("sensitives")
private String sensitives;
/**
* 创建时间
*/
@TableField("created_time")
private Date createdTime;
}
mapper
package com.heima.wemedia.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.model.wemedia.pojos.WmSensitive;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface WmSensitiveMapper extends BaseMapper<WmSensitive> {
}
业务实现
- 查所有敏感词
- 初始化
- 调用方法,判断敏感次数
方法
@Autowired
private WmSensitiveMapper wmSensitiveMapper;
private boolean handleSensitiveScan(String content, WmNews wmNews) {
boolean flag = true;
// 查询所有的敏感词.仅需一个字段,用map加lambda
List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));
// 转为字符串类型的集合,后续进行工具类调用
List<String> sensitiveList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());
// 初始化敏感词库
SensitiveWordUtil.initMap(sensitiveList);
// 开始检测返回值为敏感的词名
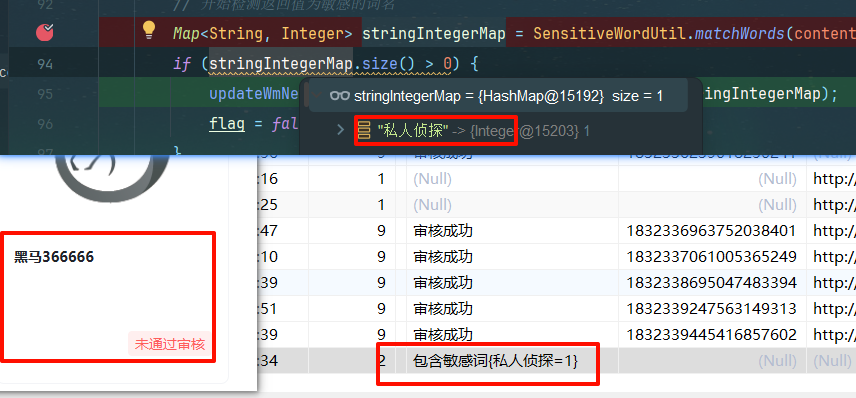
Map<String, Integer> stringIntegerMap = SensitiveWordUtil.matchWords(content);
if (stringIntegerMap.size() > 0) {
updateWmNews(wmNews, (short) 2, "包含敏感词" + stringIntegerMap);
flag = false;
}
return flag;
}
调用地方
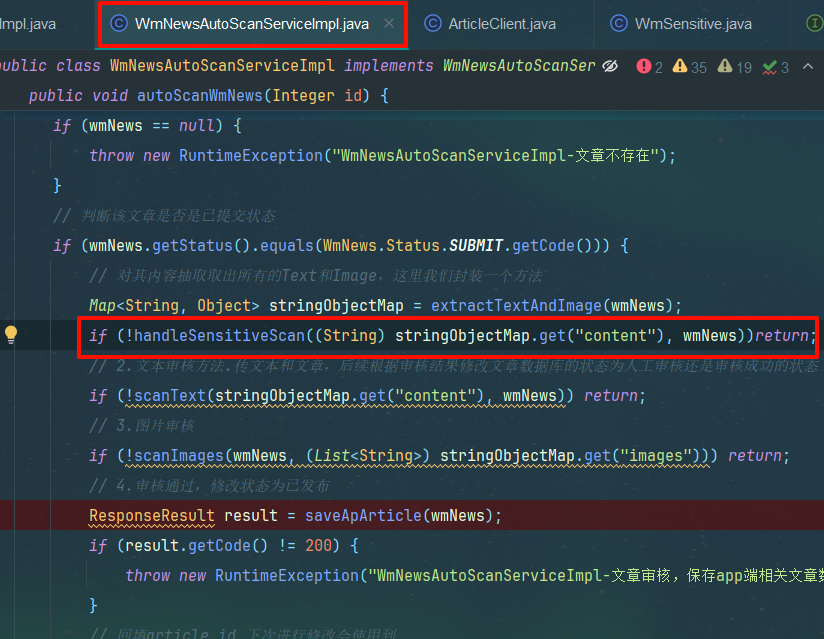
if (!handleSensitiveScan((String) stringObjectMap.get("content"), wmNews))return;
测试
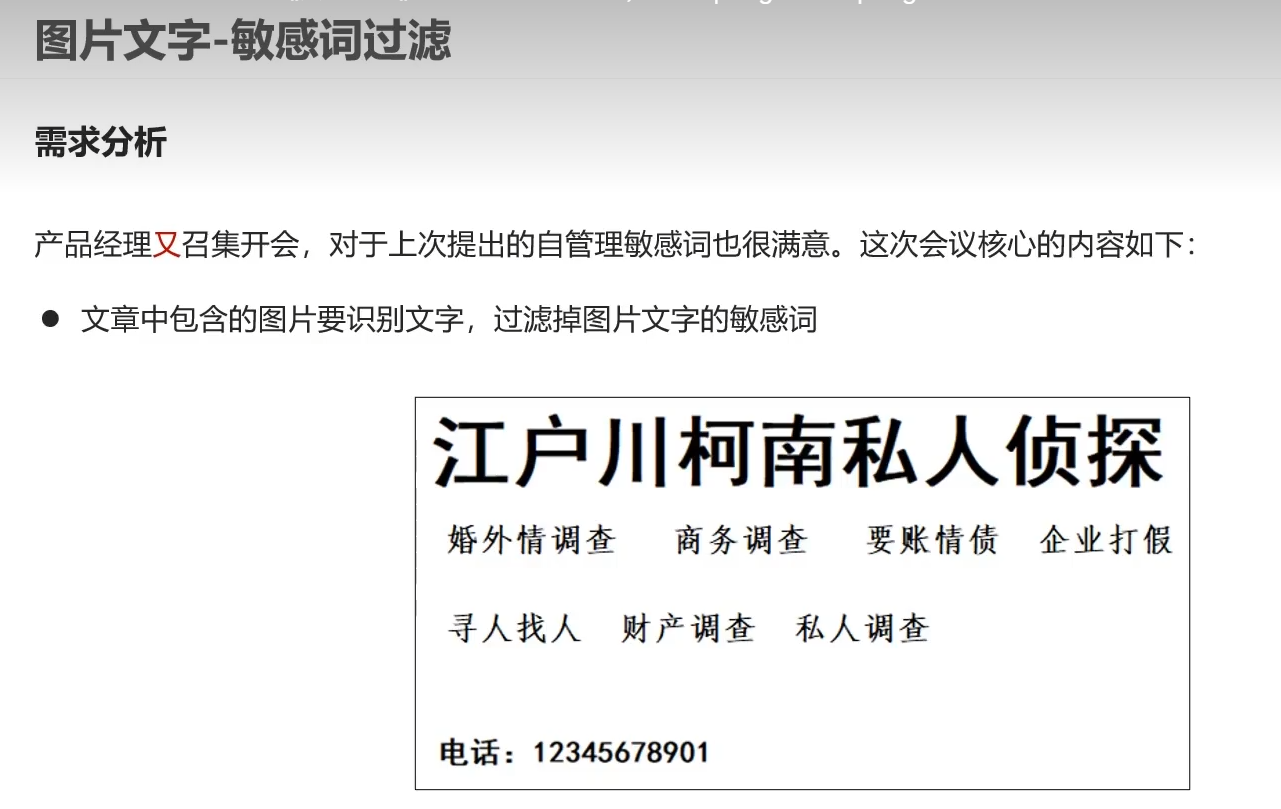
8.图片文字识别
8.1需求
识别图片文字。过滤敏感词并返回错误信息
8.2技术点

OCR,optical character recognition 光学字符识别,电子设备通过字符的亮暗确定形状,字符识别将形状翻译成文字的 过程
8.3Tesseract-OCR

- 支持UTF8编码,100多种语言识别
- 多种输出格式,文本,html,pdf
- 图片要清晰好分辨
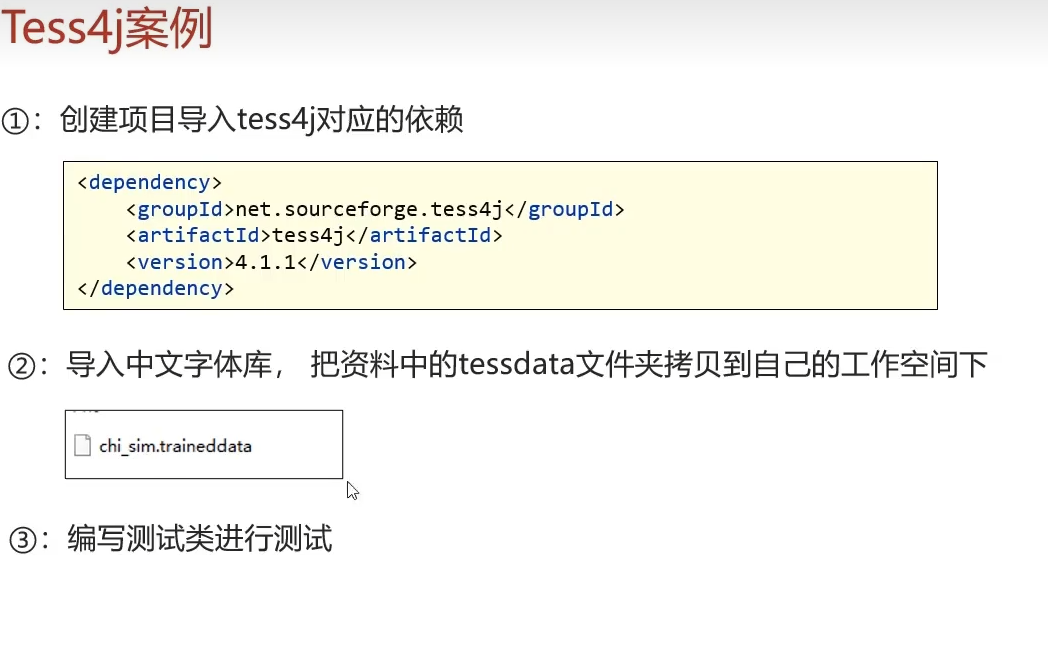
8.4步骤
依赖
<dependencies>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.1.1</version>
</dependency>
</dependencies>
测试类
package com.heima;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class Main {
public static void main(String[] args) throws TesseractException {
// 创建实例
Tesseract tesseract = new Tesseract();
//设置库路径
tesseract.setDatapath("E:\\javaOCR\\tessdata");
//设置语言 -->简体中文
tesseract.setLanguage("chi_sim");
File file = new File("E:\\javaOCR\\testImg\\1.png");
String result = tesseract.doOCR(file);
// System.out.println("识别的结果为"+result);
// 替换换行和回车,同时替换掉的用-连接
System.out.println("识别的结果为"+result.replaceAll("\\r|\\n", "-"));
}
}
测试结果
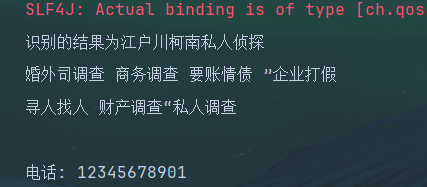

哎哟我去,一丝不差
8.5集成
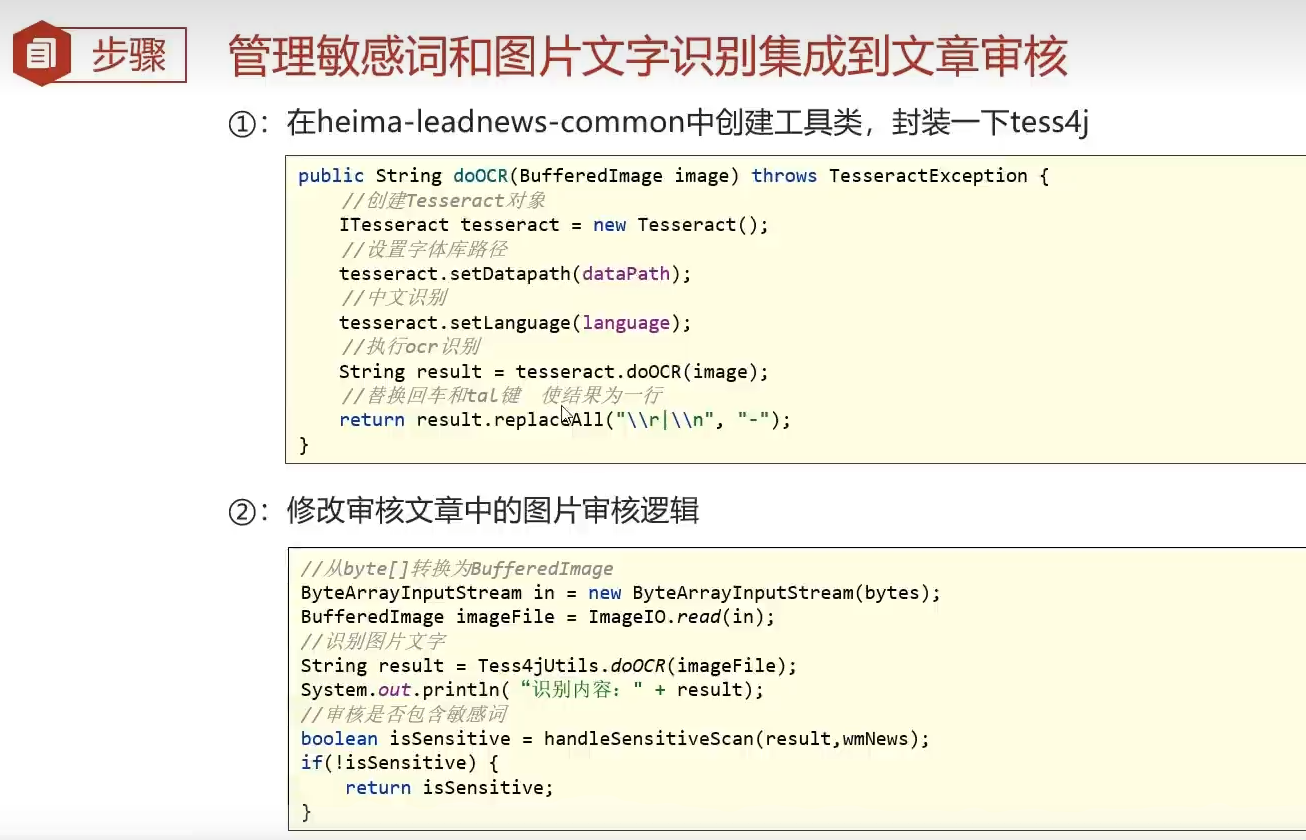
common模块创建工具类,封装tess4j方法
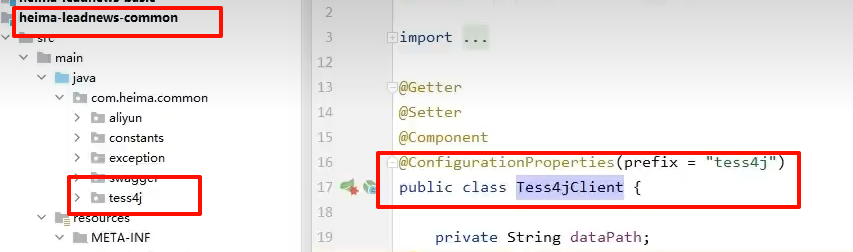
package com.heima.common.tess4j;
import lombok.Getter;
import lombok.Setter;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.awt.image.BufferedImage;
@Getter
@Setter
@Component
@ConfigurationProperties(prefix = "tess4j")
public class Tess4jClient {
private String dataPath;
private String language;
public String doOCR(BufferedImage image) throws TesseractException {
//创建Tesseract对象
ITesseract tesseract = new Tesseract();
//设置字体库路径
tesseract.setDatapath(dataPath);
//中文识别
tesseract.setLanguage(language);
//执行ocr识别
String result = tesseract.doOCR(image);
//替换回车和tal键 使结果为一行
result = result.replaceAll("\\r|\\n", "-").replaceAll(" ", "");
return result;
}
}
注册到工厂
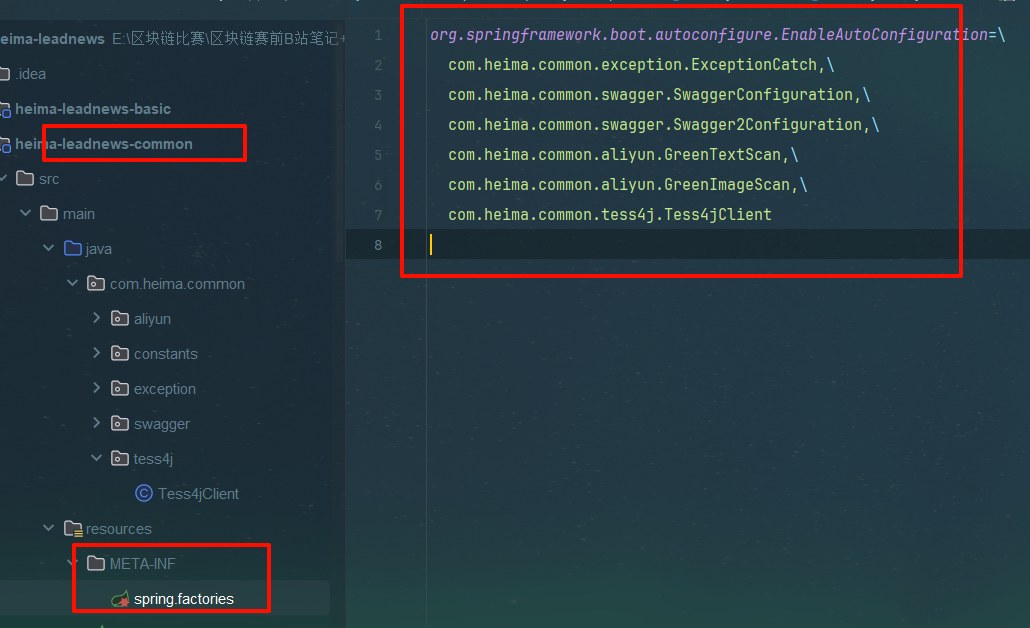
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.heima.common.exception.ExceptionCatch,\
com.heima.common.swagger.SwaggerConfiguration,\
com.heima.common.swagger.Swagger2Configuration,\
com.heima.common.aliyun.GreenTextScan,\
com.heima.common.aliyun.GreenImageScan,\
com.heima.common.tess4j.Tess4jClient
配置文件
在wemedia下yml配置补充
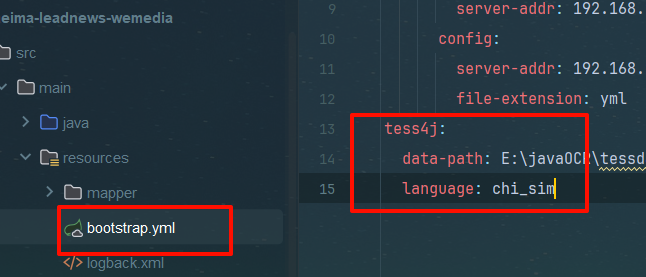
tess4j:
data-path: E:\javaOCR\tessdata
language: chi_sim
使用
在图片审核方法中,下载图片后的步骤加入,注入使用即可(先转字节数组输入流,在通过ImageIO读取到bufferedImg)
新的检测类
private boolean scanImages(WmNews wmNews, List<String> images) {
boolean flag = true;
// 判断有无图片,无图片无需审核
if (images.size() == 0 || images == null) {
return flag;
}
images = images.stream().distinct().collect(Collectors.toList());
List<byte[]> bytes = new ArrayList<>();
try {
// 依次下载图片到list里,用bytes数组存储每一张图片
// 由于封面可能来自于内容,所以要去重
for (String image : images) {
byte[] imageBytes = fileStorageService.downLoadFile(image);
ByteArrayInputStream stream = new ByteArrayInputStream(imageBytes);
BufferedImage bufferedImage = ImageIO.read(stream);
String ocrContent = tess4jClient.doOCR(bufferedImage);
boolean scanResult = handleSensitiveScan(ocrContent, wmNews);
if (!scanResult) {
return scanResult;
}
bytes.add(imageBytes);
}
} catch (Exception e) {
e.printStackTrace();
}
// // 将该集合传给接口审核
// try {
// Map map = greenImageScan.imageScan(bytes);
// if (map != null) {
// if (map.get("suggestion").equals("block")) {
// flag = false;
// updateWmNews(wmNews, (short) 2, "当前文章存在违规内容");
// }
//
// // 不确定信息 需要人工审核
// if (map.get("suggestion").equals("review")) {
// flag = false;
// updateWmNews(wmNews, (short) 3, "当前文章存在不确定内容,需要人工审核");
// }
// }
// } catch (Exception e) {
// flag = false;
// e.printStackTrace();
// }
return true;
}
发图片测试
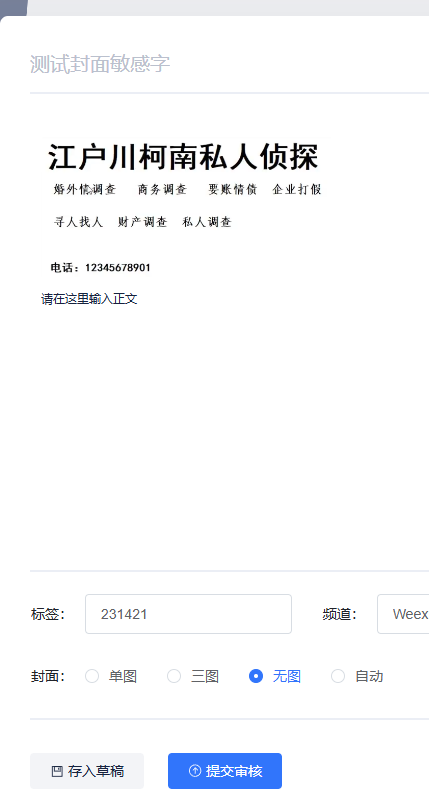

识别成功

返回

数据库

前台
9.文章详情静态文件生成
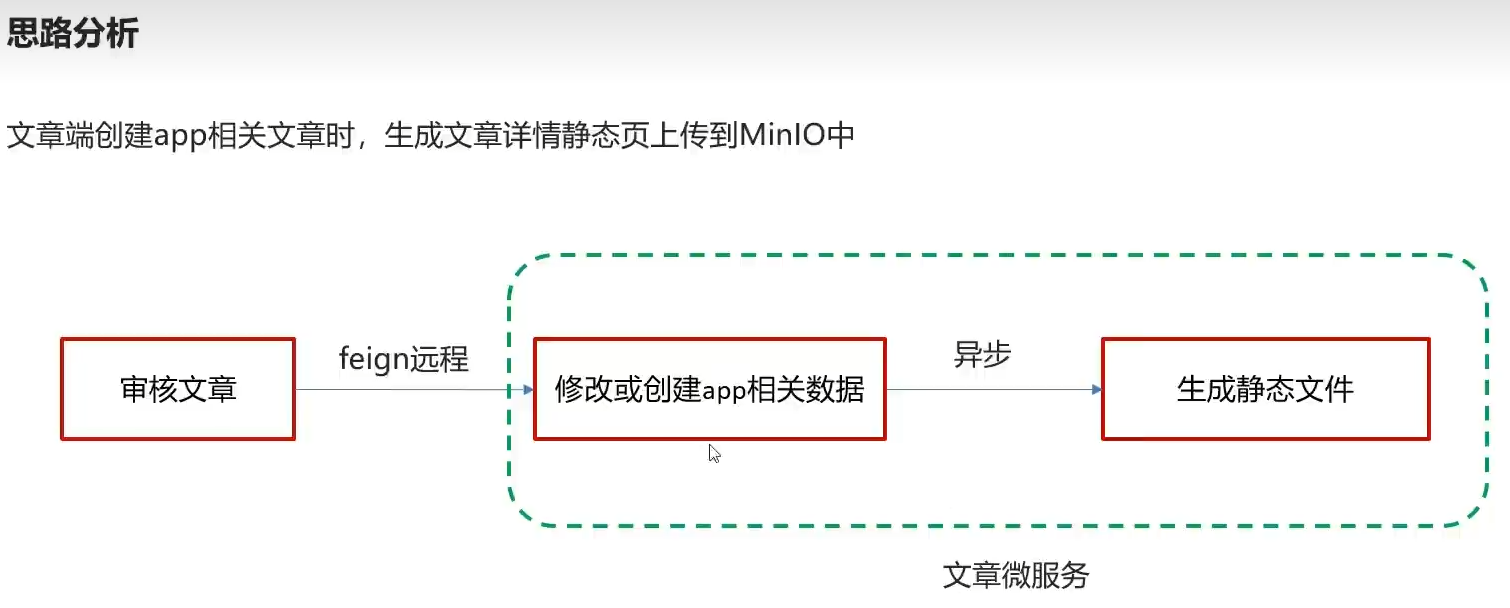
代码思路
根据内容上传文件返回url的接口和实现
在保存文章业务后面增加上传静态页面
方法增加异步注解
引导类开启异步注解 和
实现类事务注解(操作了数据库)
由原先直接指定id查内容到现在 现成apdto 含有content调用
接口
package com.heima.article.service;
import com.heima.model.article.pojos.ApArticle;
public interface ArticleFreemarkerService {
/**
* 生成静态文件上传到minIO中
* @param apArticle
* @param content
*/
public void buildArticleToMinIO(ApArticle apArticle,String content);
}
实现
package com.heima.article.service.impl;
import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.article.mapper.ApArticleContentMapper;
import com.heima.article.mapper.ApArticleMapper;
import com.heima.article.service.ArticleFreemarkerService;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.pojos.ApArticle;
import com.heima.model.article.pojos.ApArticleContent;
import freemarker.template.Configuration;
import freemarker.template.Template;
import org.apache.commons.lang3.StringUtils;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;
public class ArticleFreemarkerServiceImpl implements ArticleFreemarkerService {
// 注入template模板类
@Autowired
private Configuration configuration;
// 文件上传类
@Autowired
private FileStorageService fileStorageService;
@Autowired
private ApArticleMapper apArticleMapper;
public void buildArticleToMinIO(ApArticle apArticle,String content) {
// 1.获取文章内容
if (StringUtils.isNotBlank(content)) {
// 2.文章内容通过freemarker生成html文件
StringWriter out = new StringWriter();
Template template = null;
try {
template = configuration.getTemplate("article.ftl");
Map<String, Object> params = new HashMap<>();
params.put("content", JSONArray.parseArray(content));
template.process(params, out);
} catch (Exception e) {
throw new RuntimeException(e);
}
InputStream is = new ByteArrayInputStream(out.toString().getBytes());
// 3.把html文件上传到minio中
String path = fileStorageService.uploadHtmlFile("", apArticle.getId()+ ".html", is);
// 4.修改ap_article表,保存static_url字段
ApArticle article = new ApArticle();
article.setId(apArticle.getId());
article.setStaticUrl(path);
apArticleMapper.updateById(article);
}
}
}
在article服务的saveArticle方法调用

测试
重启文章服务,生成静态文件出加断点调试
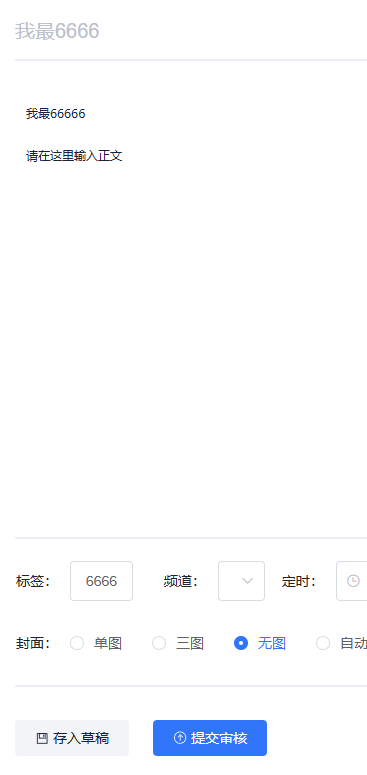
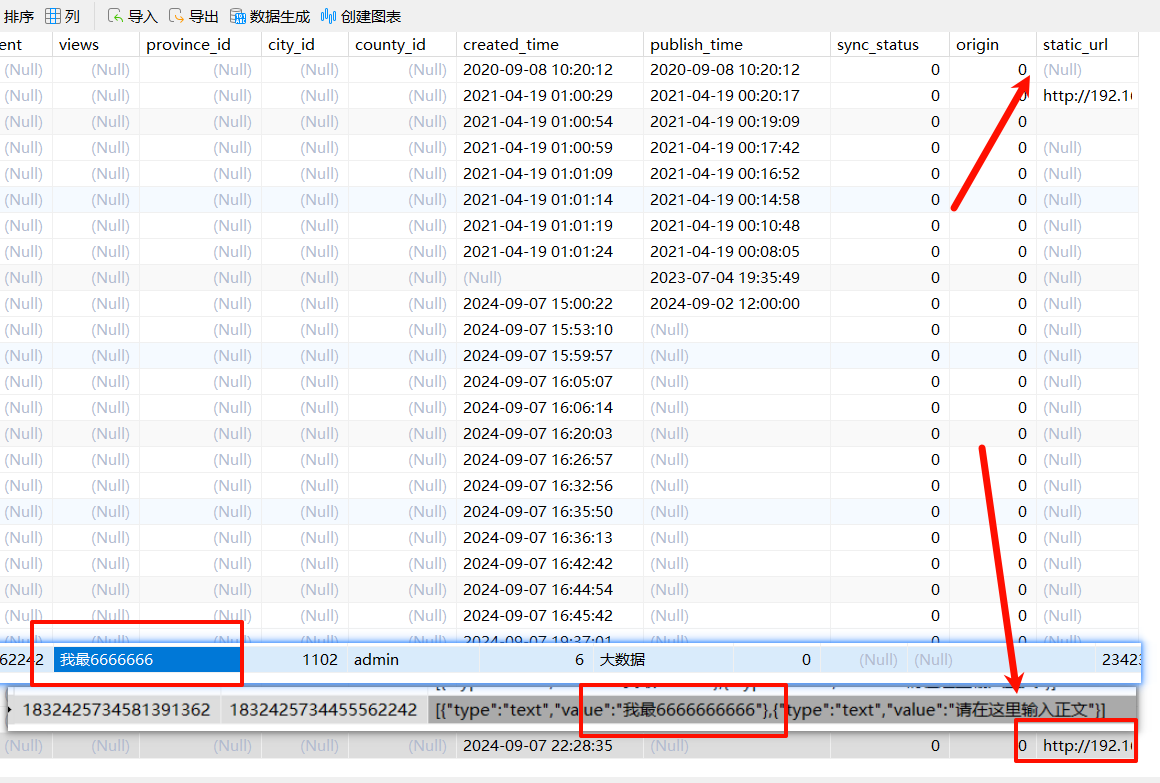

访问成功
10.今日作业
任务1
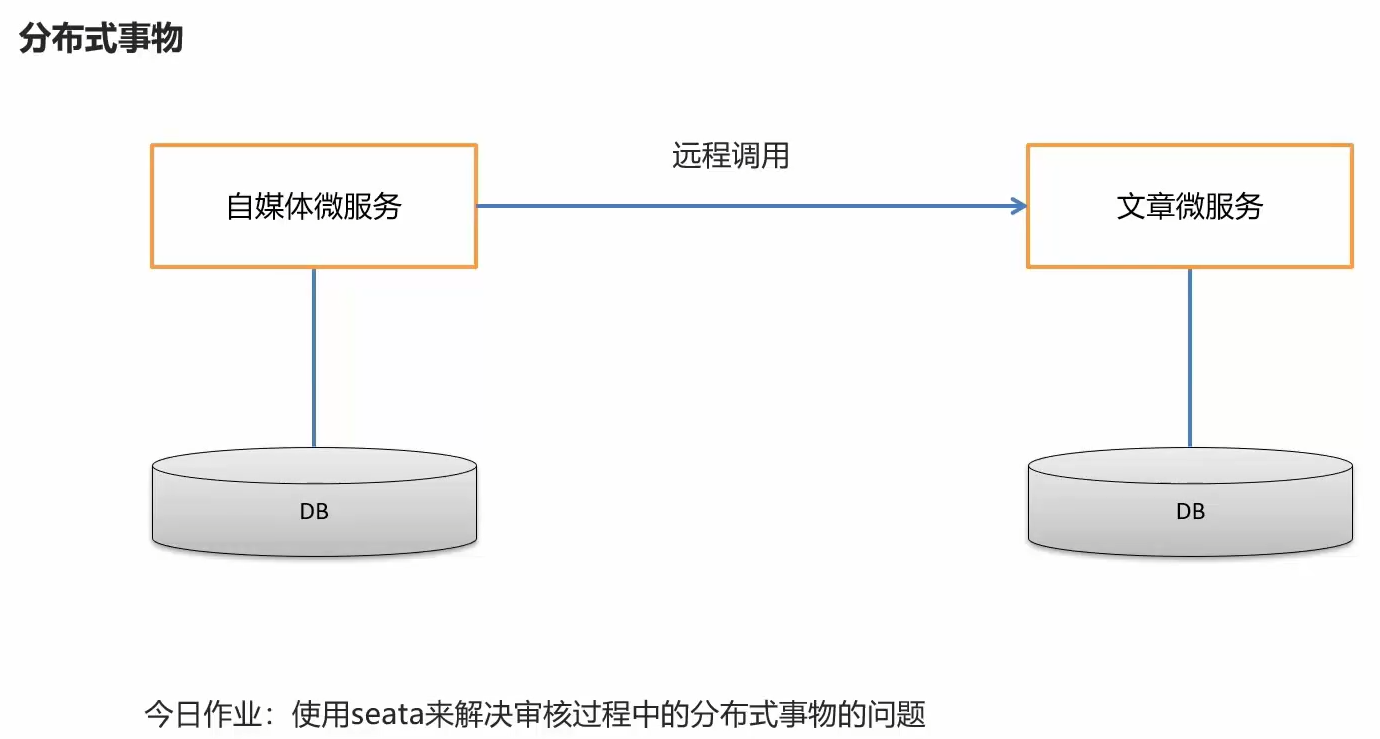
微服务之间崩了没互相之间通知一下,使用seata 完成微服务一致性
任务2

定时发布的文章审核时间




![[数据结构] 哈希结构的哈希冲突解决哈希冲突](https://i-blog.csdnimg.cn/direct/b5e222d58577426588b1442d6c7cb63e.png)














