随着大模型的发展,如何进行分布式训练也成了每位开发者必备的技能。
单机训练
- CPU Offloading
- Gradient Checkpointing
- 正向传播时,不存储当前节点的中间结果,在反向传播时重新计算,从而起到降低显存占用的作用
- Low Precision Data Types
- Memory Efficient Optimizers
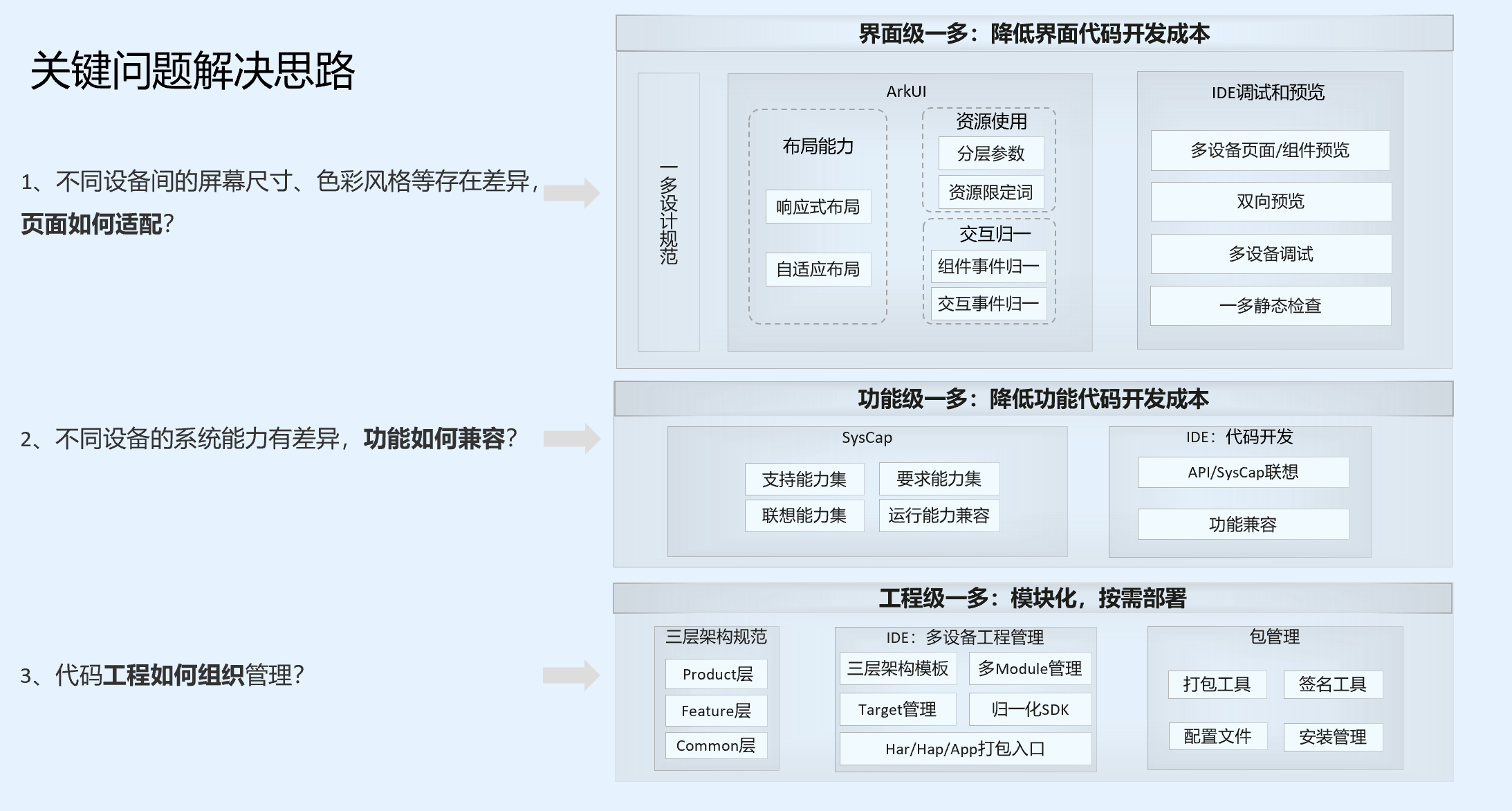
分布式
数据并行(DP)和模型并行(MP)
分布式通信基础:
- Broadcast: 把一个节点自身的数据广播到其他节点上
- Scatter:数据进行切片再分发给集群内所有的节点
- Gather: 把多个节点的数据收集到一个节点上
- AllGather:多个节点的数据收集到一个主节点上(Gather),再把收集到的数据分发到其他节点上(broadcast)
- Reduce:把多个节点的数据规约运算到一个主节点上
- ReduceScatter:所有节点上都按维度执行相同的Reduce规约运算,再将结果发散到集群所有节点上
- AllReduce: 多个节点的数据规约运算(Reducer),再把结果分发到其他节点上(broadcast)
类型基础:


FullyShardedDataParallel (FSDP)
- https://huggingface.co/docs/transformers/main/en/fsdp
ZeRO
zero的一些分布式设置
Deepspeed

a. Stage 1 : Shards optimizer states across data parallel workers/GPUs. 优化器状态切分 (ZeRO stage 1)
b. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs. +梯度切分 (ZeRO stage 2)
c. Stage 3: Shards optimizer states + gradients + model parameters across data parallel workers/GPUs. + 参数切分 (ZeRO stage 3)
d. Optimizer Offload: Offloads the gradients + optimizer states to CPU/Disk building on top of ZERO Stage 2
e. Param Offload: Offloads the model parameters to CPU/Disk building on top of ZERO Stage 3

其中多数情况下,
速度对比:ZeRO-0> ZeRO-1> ZeRO-2> ZeRO-2+offload> ZeRO-3> ZeRO-3+offloads
显存对比:ZeRO-0 <ZeRO-1< ZeRO-2< ZeRO-2+offload< ZeRO-3< ZeRO-3+offloads
因此,选择时,从FSDP开始,如果显存不足,则依次尝试ZeRO-2,ZeRO-2+offload,ZeRO-3,ZeRO-3+offload_optimizer, ZeRO-3+offload_optimizer+offload_param. 其中offload_optimizer: 是为减少GPU显存,将优化器状态加载到CPU。ZeRO-2仅用于训练,推理时不需要优化器和梯度。ZeRO-3也可用于推断,模型分布加载到多个GPU。
- ZeRO-0:禁用所有分片,此时将DeepSpeed视为DDP使用 (stage默认值:0)
"zero_optimization": {
"stage": 0
}
- ZeRO-1:ZeRO第一阶段的优化,将优化器状态进行切分。
"zero_optimization": {
"stage": 1
}
- ZeRO2
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 3e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 3e8,
"contiguous_gradients": true
}
- ZeRO3
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 4e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
Megatron
- https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many
- 下图来自bloom

Megatron-deepspeed
- https://github.com/bigscience-workshop/Megatron-DeepSpeed
Reference
- https://pytorch.org/docs/stable/distributed.html
- accelerate
- https://www.deepspeed.ai/getting-started/
- https://wandb.ai/byyoung3/ml-news/reports/A-Guide-to-DeepSpeed-Zero-With-the-HuggingFace-Trainer–Vmlldzo2ODkwMDc4
- https://github.com/huggingface/blog/blob/main/accelerate-deepspeed.md
- DeepSpeed之ZeRO系列:将显存优化进行到底 - basicv8vc的文章 - 知乎
- 从啥也不会到DeepSpeed————一篇大模型分布式训练的学习过程总结 - elihe的文章 - 知乎
- DDP系列第二篇:实现原理与源代码解析 - 996黄金一代的文章 - 知乎
- 关于Deepspeed的一些总结与心得 - 白板笔的文章 - 知乎
- deepspeed入门教程 - JOYWIN的文章 - 知乎
- deepspeed多机多卡训练踏过的坑 - 100110的文章 - 知乎
- https://www.zhangzhenhu.com/deepspeed/index.html
- https://github.com/hpcaitech/ColossalAI
- 模型并行训练:为什么要用Megatron,DeepSpeed不够用吗? - 流逝的文章 - 知乎
- 如何判断候选人有没有千卡GPU集群的训练经验? - 你的真实姓名的回答 - 知乎