Transformer从零详细解读
一、从全局角度概况Transformer
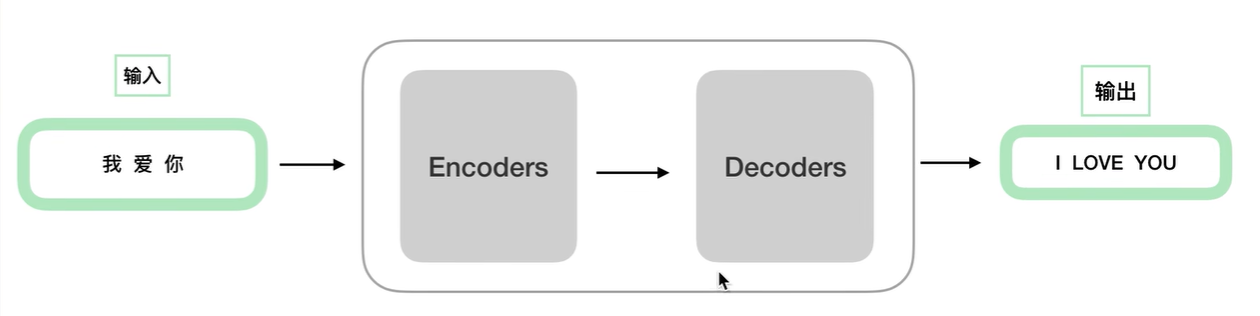
我们把TRM想象为一个黑盒,我们的任务是一个翻译任务,那么我们的输入是中文的“我爱你”,输入经过TRM得到的结果为英文的“I LOVE YOU”

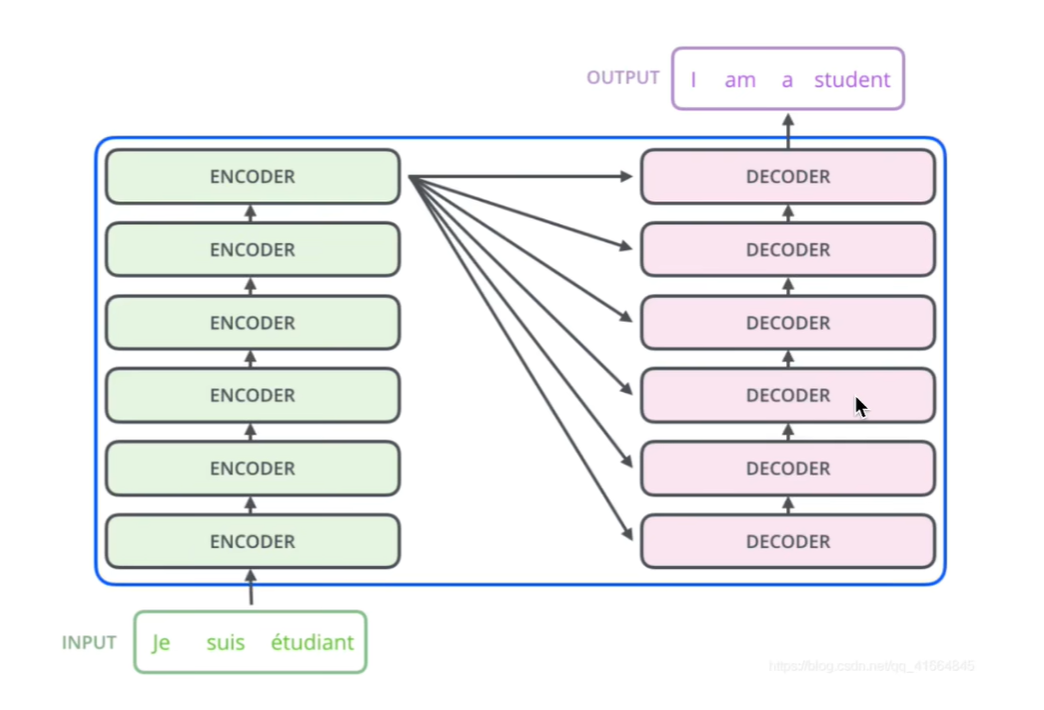
接下来我们对TRM进行细化,我们将TRM分为两个部分,分别为Encoders(编码器)和Decoders(解码器)
在此基础上我们再进一步细化TRM的结构:
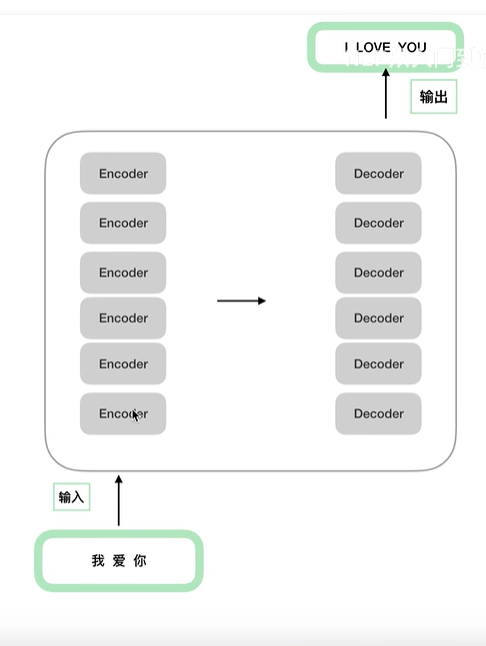
这里不一定是6个encoder和6个decoder,但是每个encoder之间的结构都是相同的,但是参数上并不相同,在训练的时候并不是只训练一个encoders,而是每个encoders都在训练。
我们再看一下TRM原论文中的结构图:
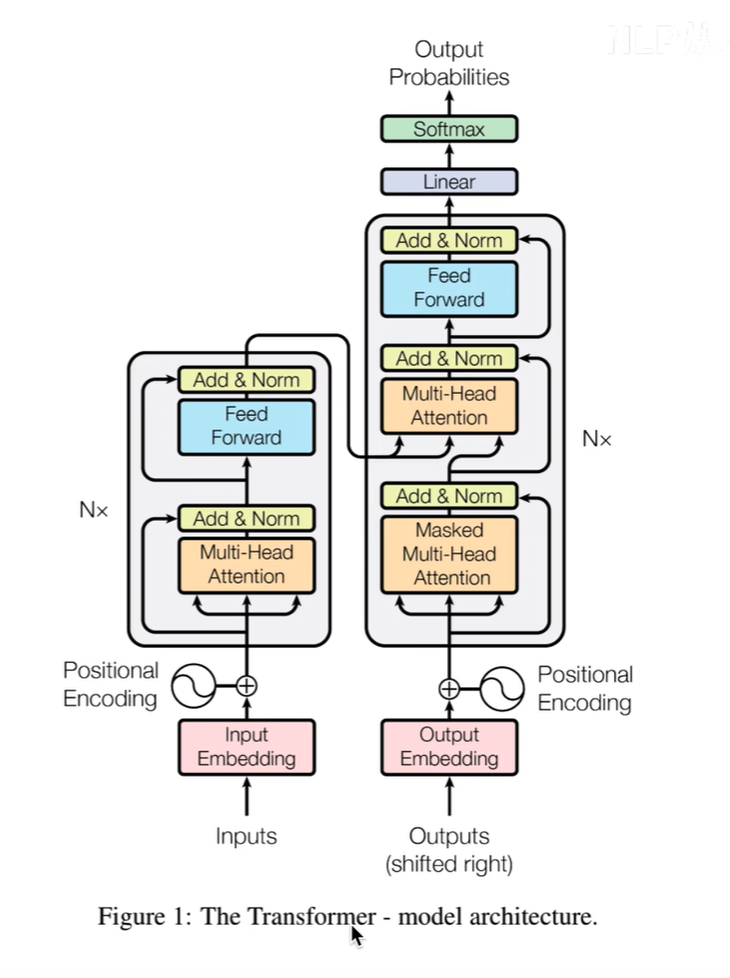
N是自己确定的数字,encoders和decoders之间的结构很不相同。
二、位置编码详细解读
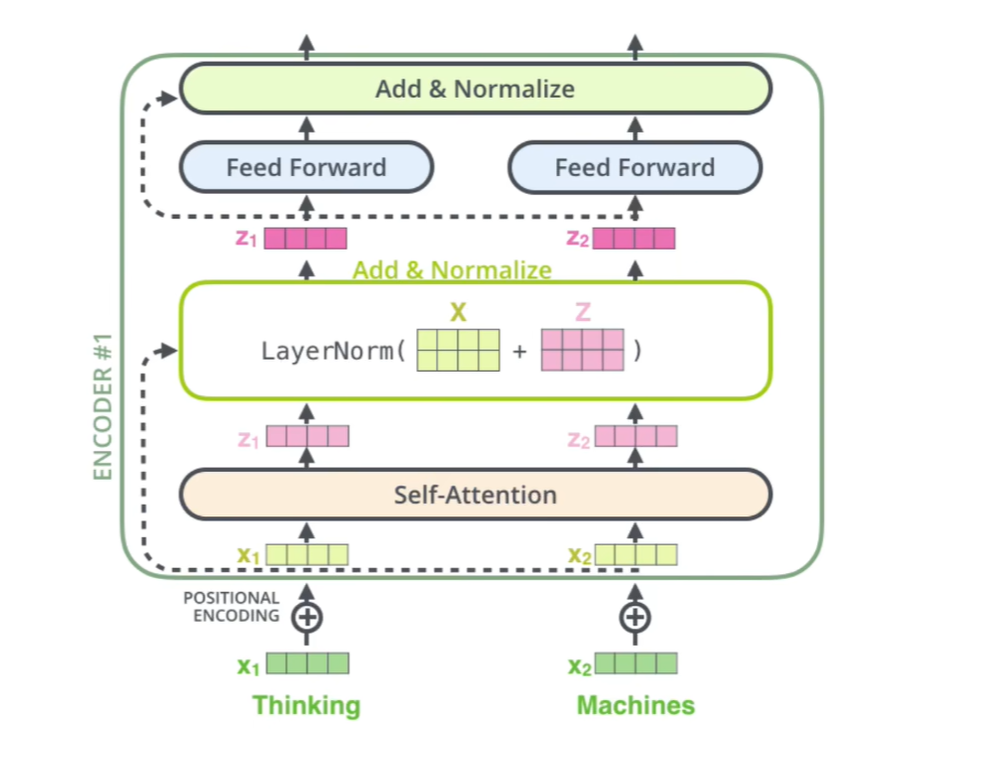
我们将encoder部分提取出来看,我们将encoder分为以下三个部分:
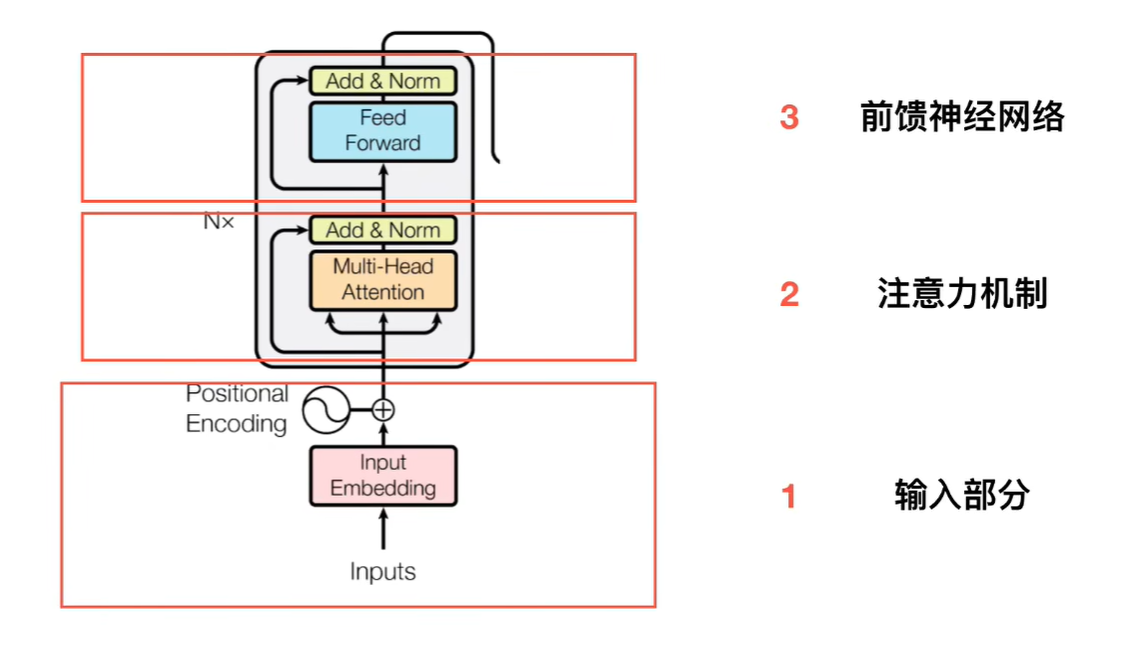
我们先看输入部分,输入部分分为:
-
Embedding
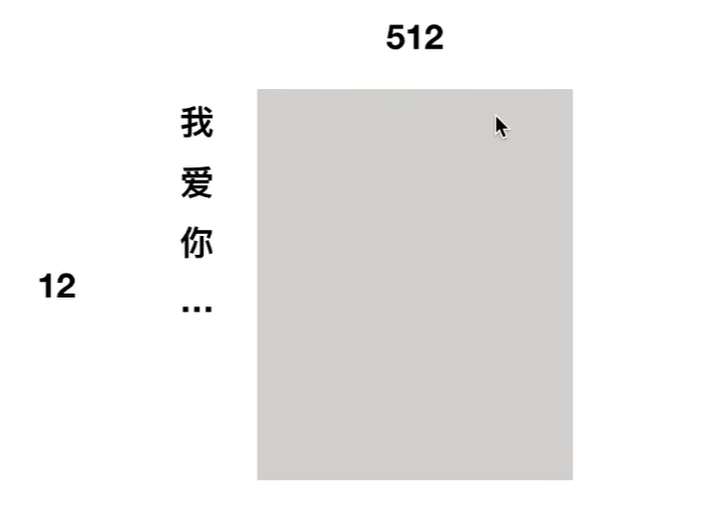
embedding的操作方法就是:假如现在输入12个字,每个字用一个512维度的向量表示,那么这12个字展开后就是一个12*512的二维矩阵。矩阵的每个位置有两种初始化方式,一种是随机初始化,另一种是wordtovector方式。
-
位置编码
我们从RNN结构来引入位置编码:
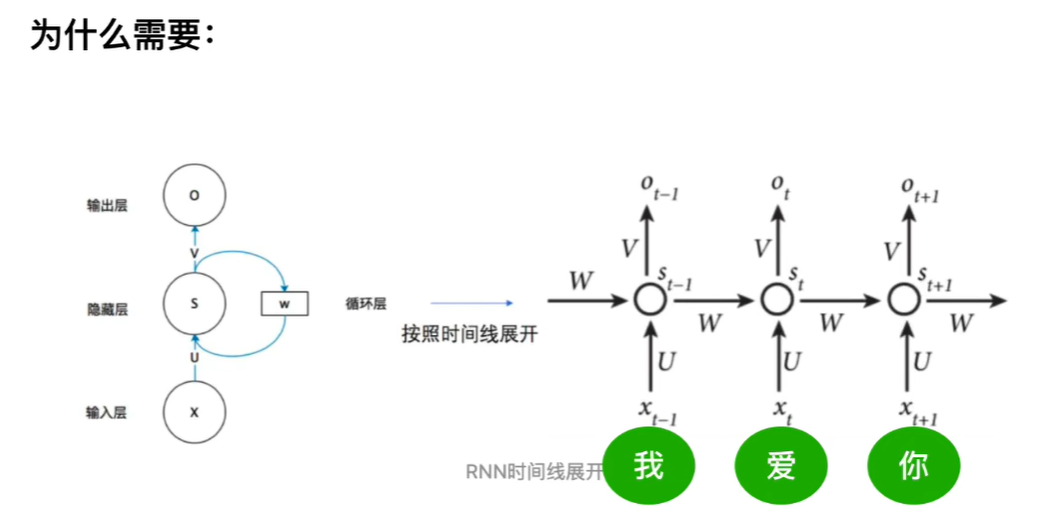
对于RNN的所有的timesteps都共享同一套参数(U,W,V),例如右图上的“我”,“爱”,“你”在展开以后,使用的都是同一套参数(U,W,V)。
面试题:RNN的梯度消失和普通网络的梯度消失有什么区别?
RNN的梯度是一个总的梯度和,它的梯度消失并不是变为0,而是总的梯度被近距离梯度主导,被远距离梯度忽略不计。
1.位置编码公式:
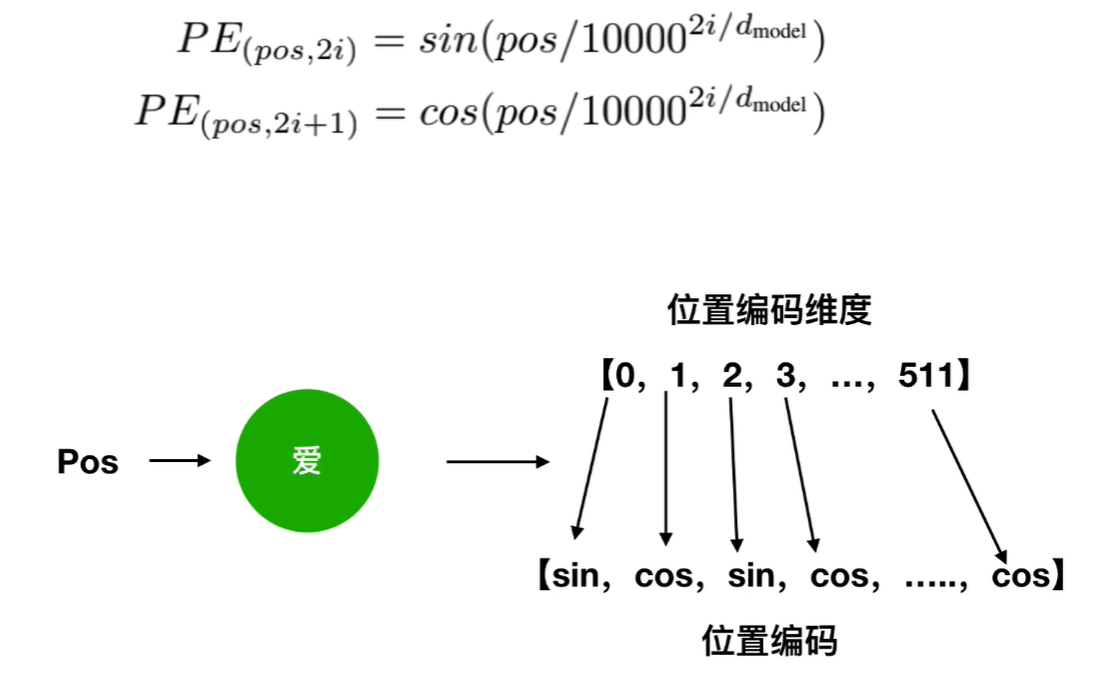
2i代表偶数,在偶数位置使用sin,在2i+1奇数的位置使用cos,就比如我爱你中的爱这个字,进行展开,其中的偶数位置使用sin表达式,奇数位置使用cos表达式。得到展开式以后:
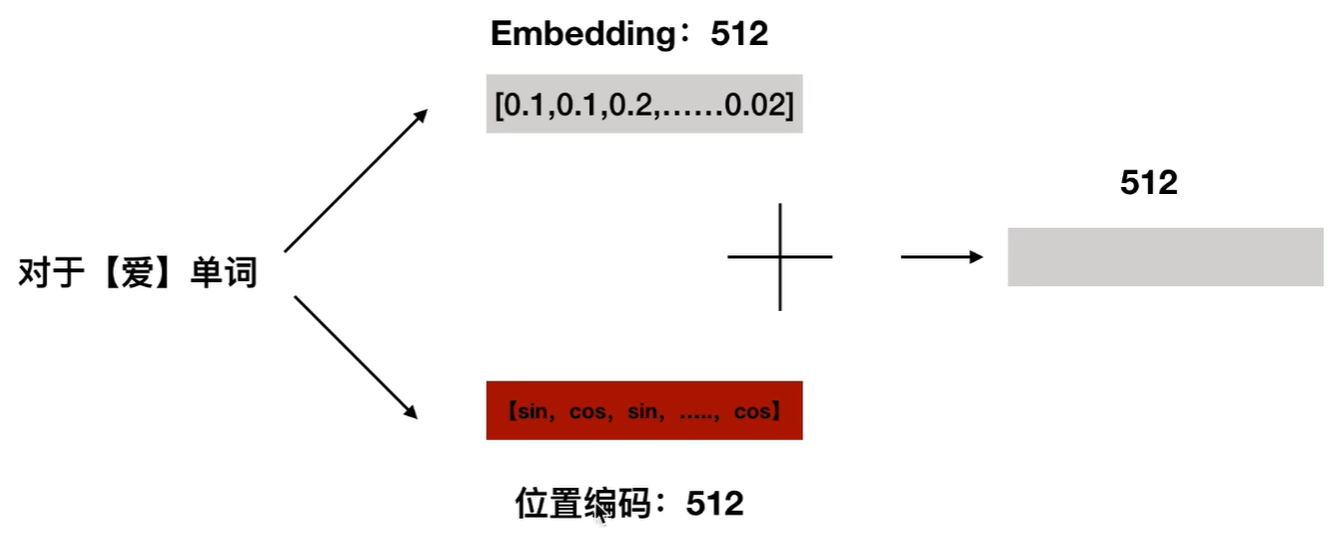
我们把字向量他们原本位置上的值与他们的位置编码相加,得到一个最终的512的维度的向量,作为TRM的输入。
2.为什么位置编码是有用的
我们看下图中的推导,正余弦位置函数,这个体现出的是一种绝对位置信息。

以“我 爱 你”为例,pos+k 代表“你”,pos代表“我”,k代表“爱”,也就是说,“我爱你”中的“你”,可以被“我”和“爱” 线性组合起来,这样的线性组合就意味着绝对的位置向量中蕴含了相对位置信息。但是这种相对位置信息会在注意力机制那里消失。
三、多头注意力机制
1.基本的注意力机制
我们看下图:

我们在看一张图的时候,一张图像总有一些部分是我们特别关注的地方。我们想通过一种方式得到“婴儿在干嘛”这句话 与图像中的哪部分区域更加关注/相似,这就是注意力机制的一种形式。
计算公式:
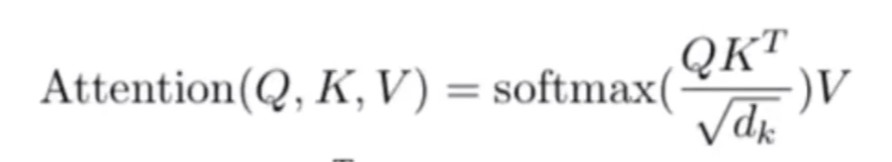
我们举一个例子,就拿上面的例子为例,我们通过计算来判断下“婴儿在干嘛”这句话与图片中的哪部分区域更加相似,看下图:
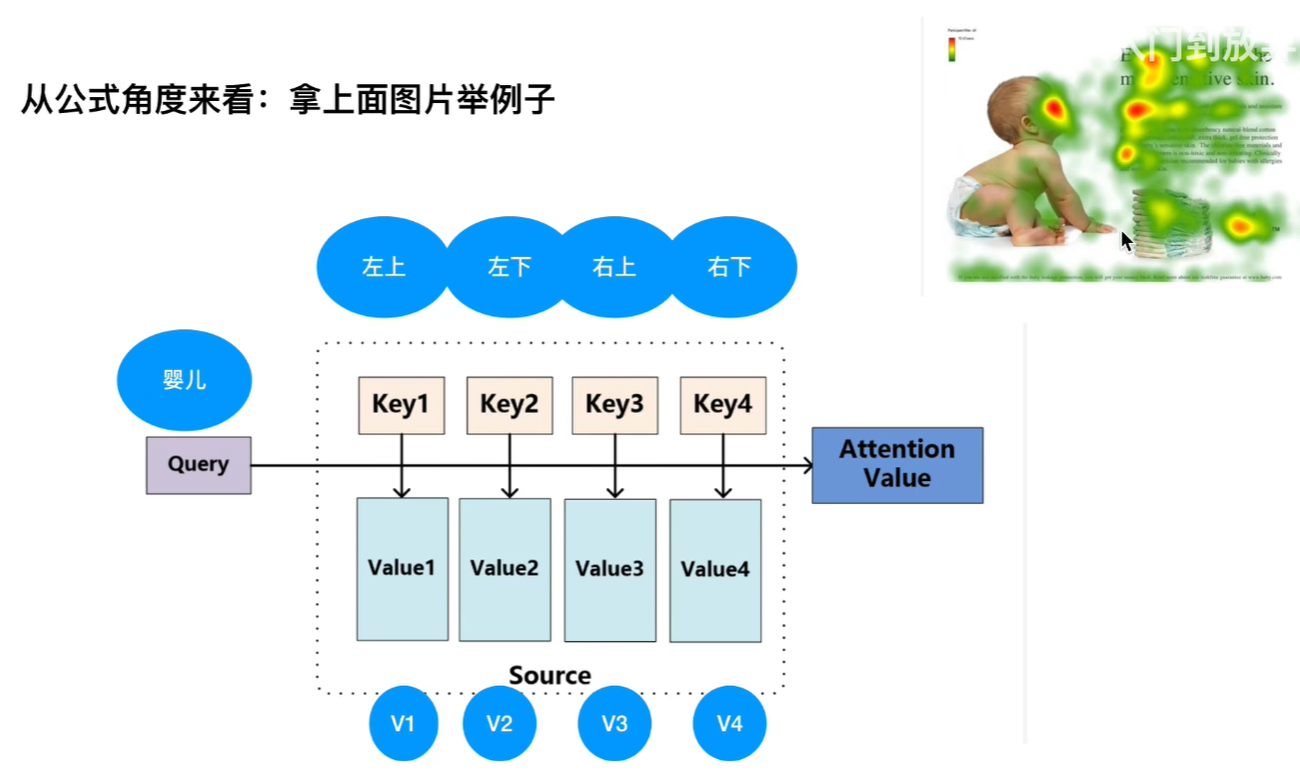 我单抽出婴儿这个单词,我们将区域分为四个部分,我们将“婴儿”作为q向量,四个区域分别对应K向量,和他们各自的V向量。我们判断“婴儿”与四个区域点乘的结果哪个是最大的,最大就代表了最相似。
我单抽出婴儿这个单词,我们将区域分为四个部分,我们将“婴儿”作为q向量,四个区域分别对应K向量,和他们各自的V向量。我们判断“婴儿”与四个区域点乘的结果哪个是最大的,最大就代表了最相似。
我们再举一个词与词的例子:
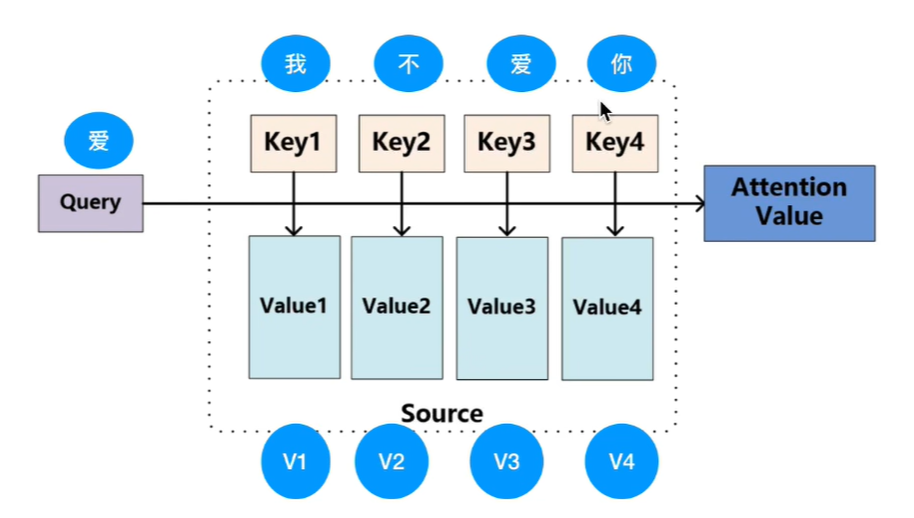
我们的计算步骤如下图:
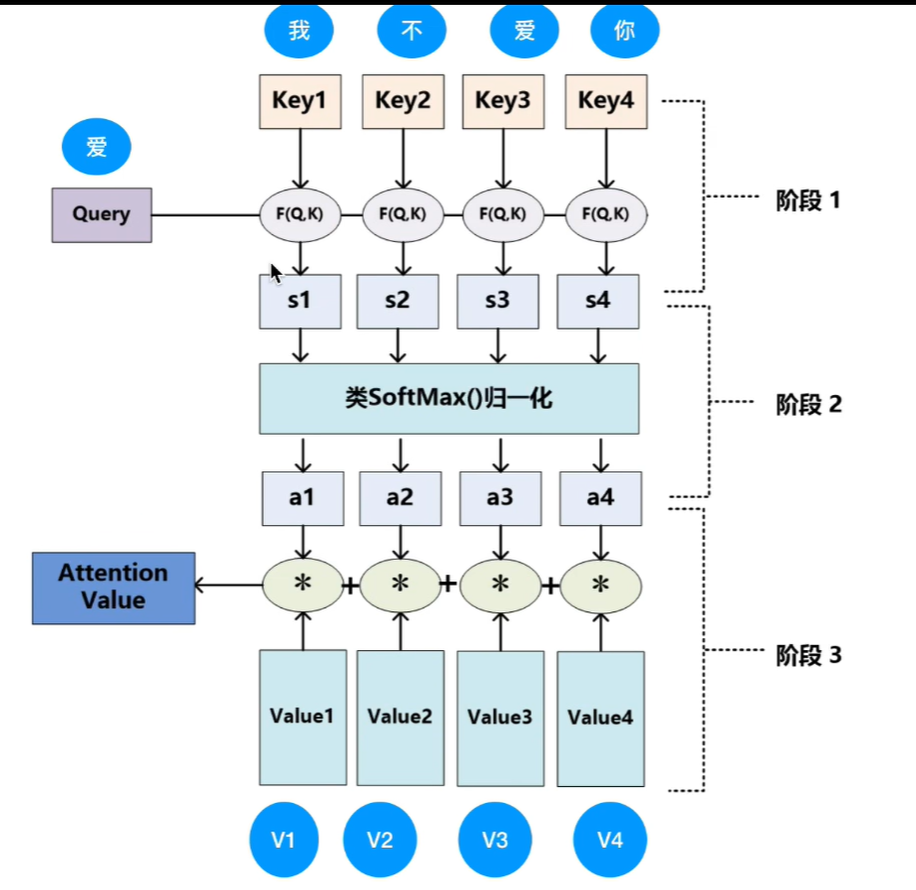
在只有单词向量的情况下,如何获取QKV
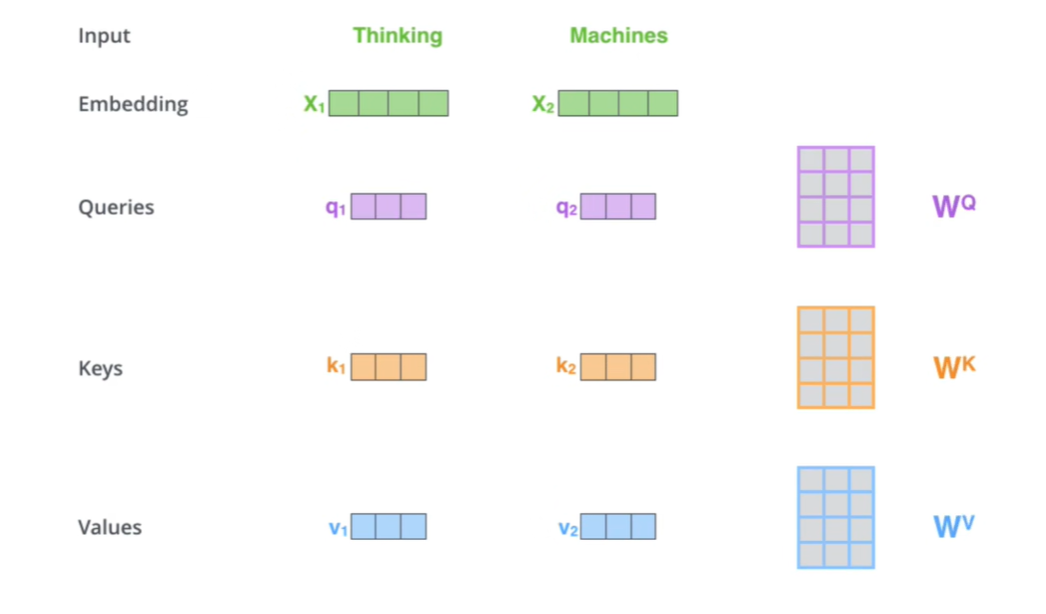
简单来说就是x1与WQ得到q1,,,行列分别相乘。
2.计算QK相似度,得到attention值
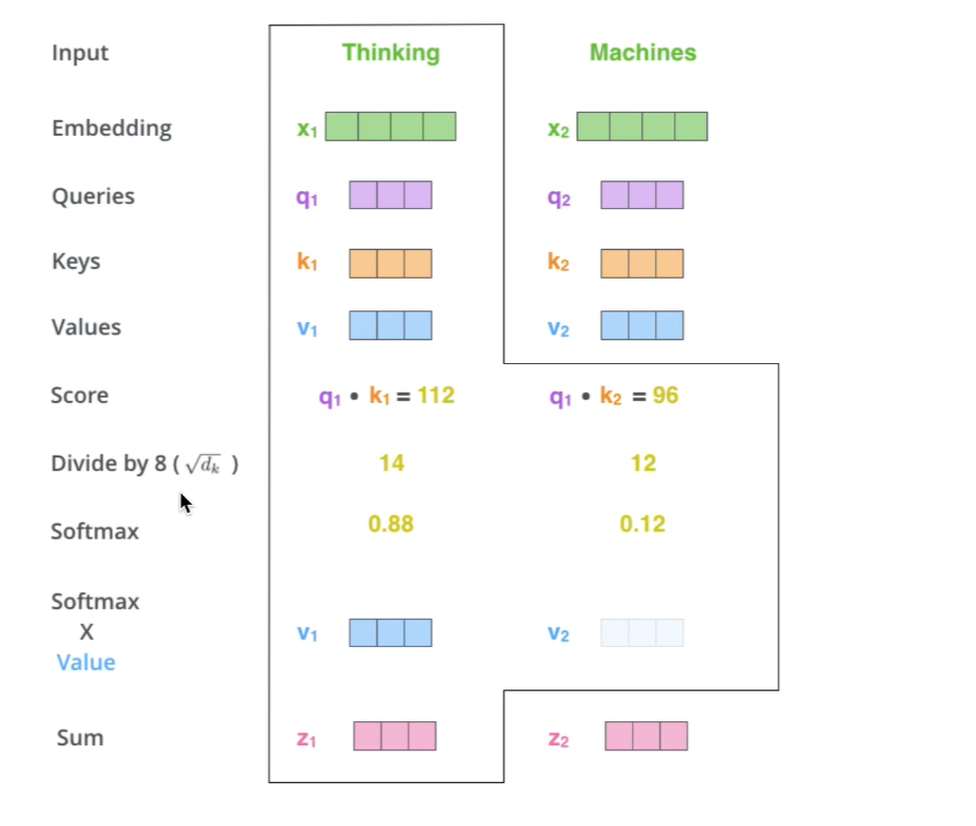
为什么要除以根号dk,q与k相乘值很大,softmax在反向传播的时候值很小,梯度会消失。在实际代码使用矩阵,方便并行。
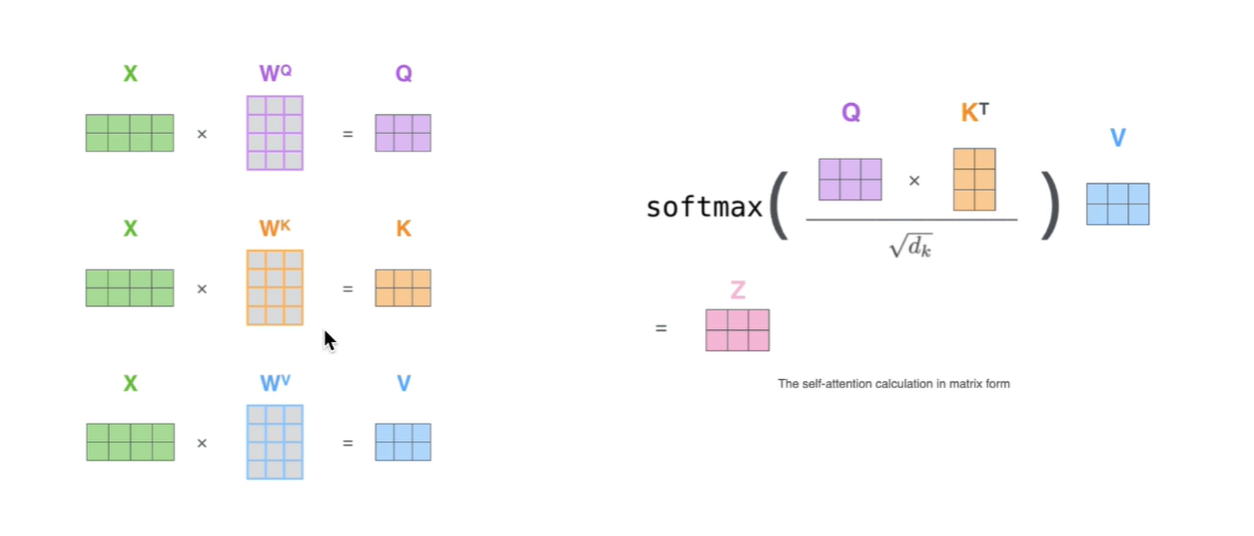
3.多头注意力机制
多头,相当于把原始数据打到了多个不同的空间,保证TRM捕获到不同空间中的多种信息。
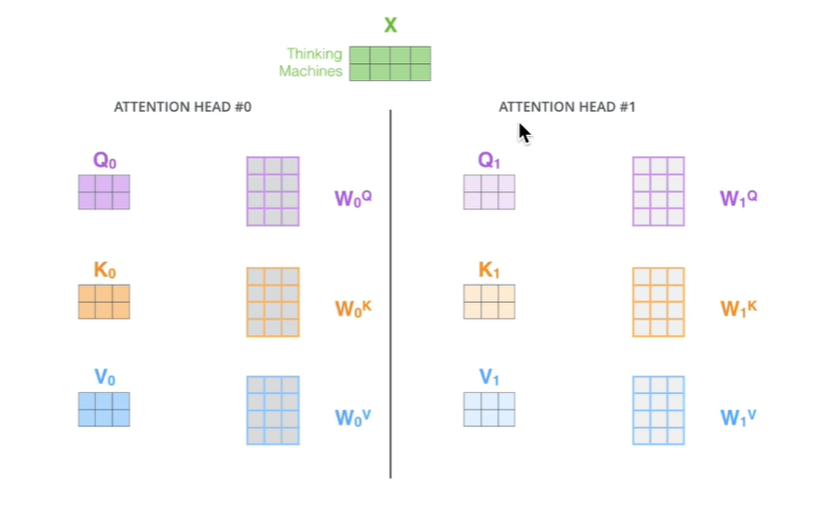
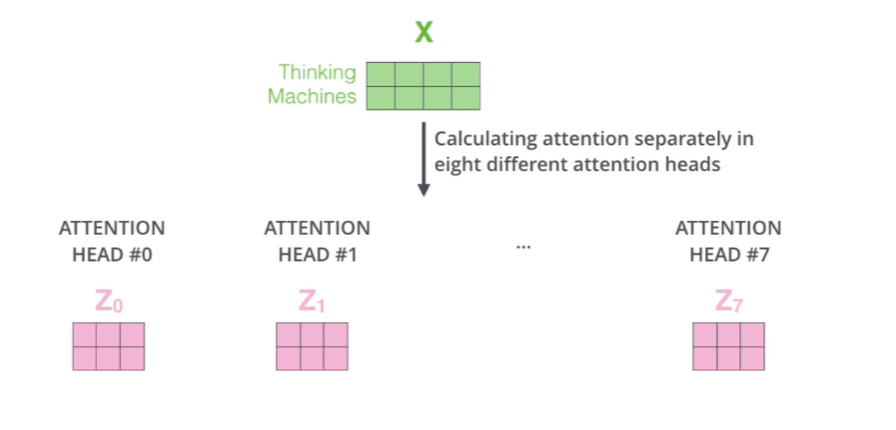
最后,我们将多套QKV计算得到的 结果通过一次矩阵计算进行合并,这样就可以得到我们多头注意力的输出。
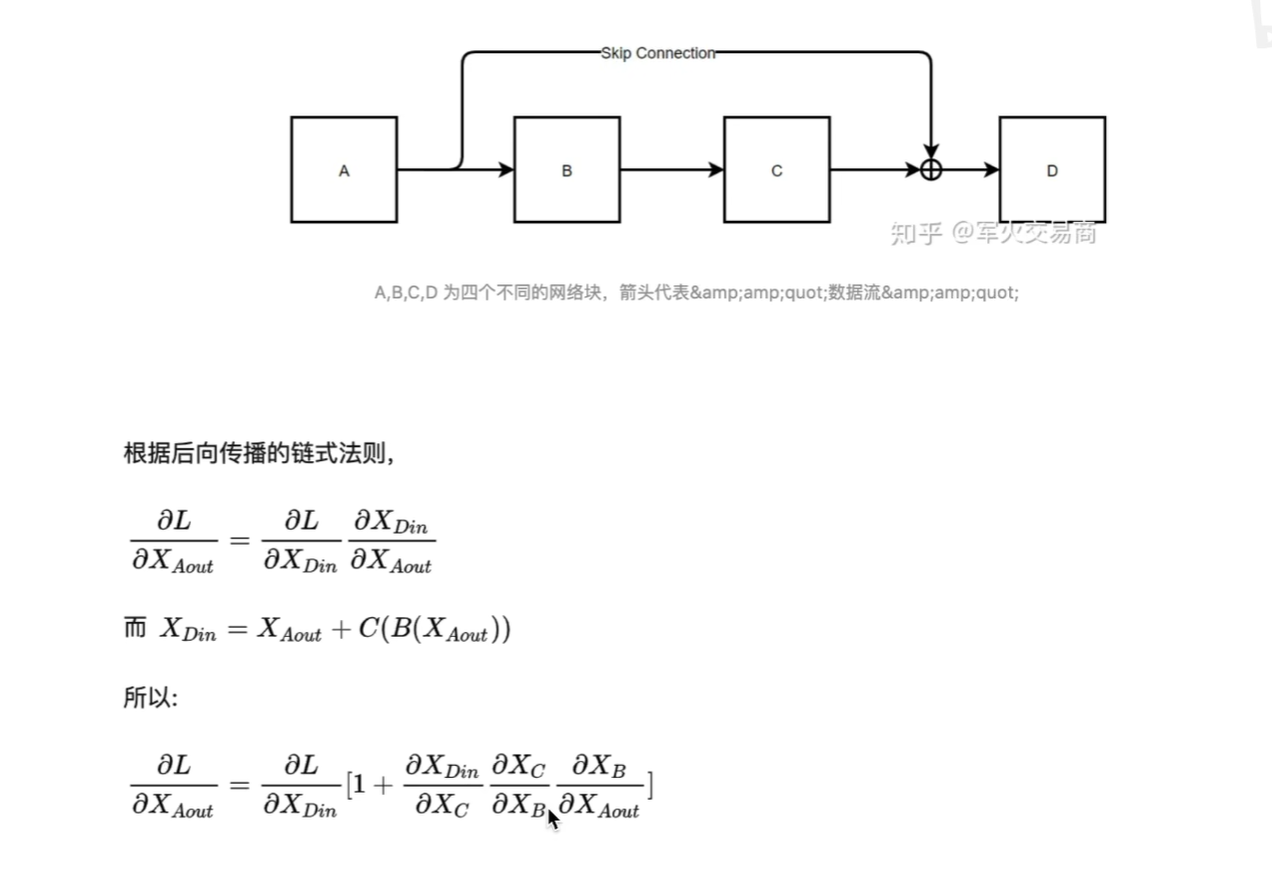
四、残差详解
1.什么是残差网络
残差的原则就是输出至少不比输入差!多进行一个加法操作。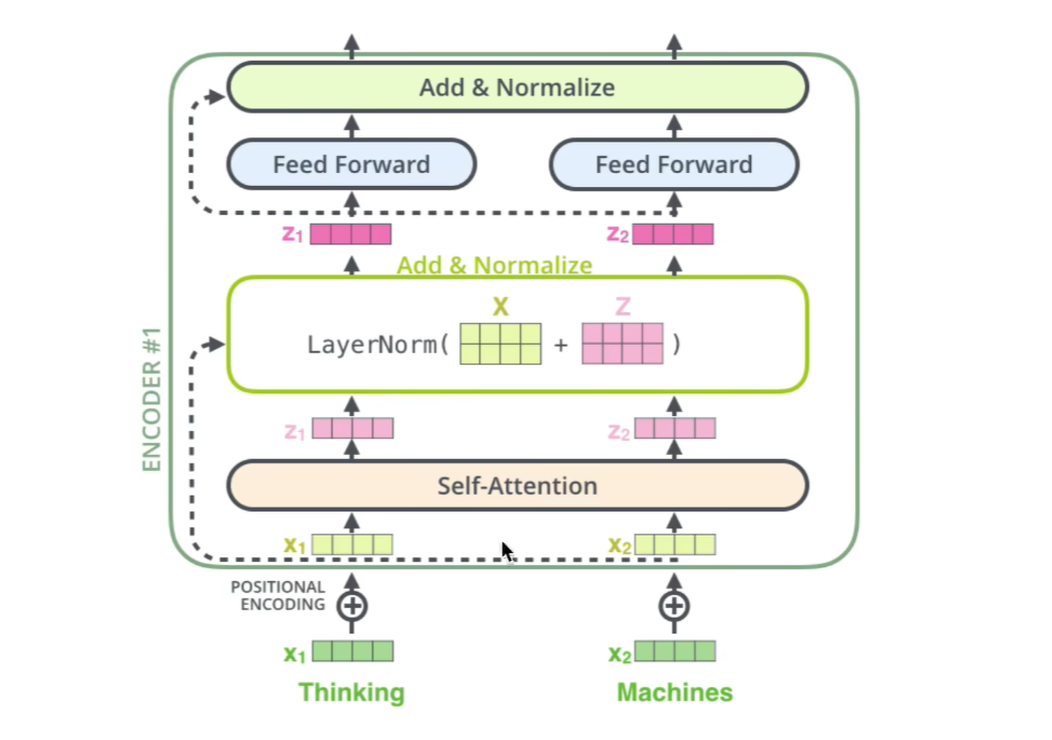
我们可以再看一个很经典的图:
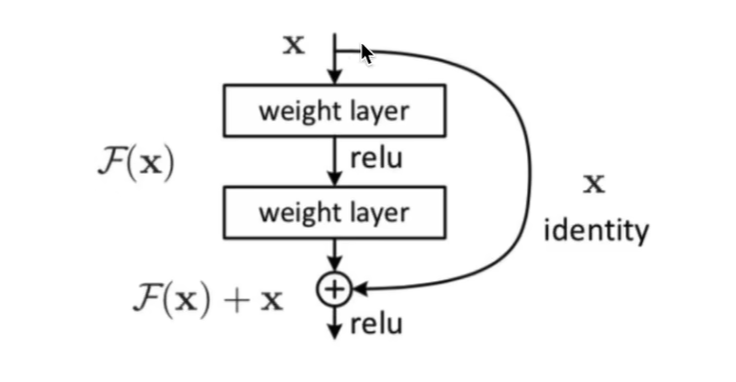
2.残差网络的数学推导
五、Batch Normal详解
BN的效果差,所以不用。再nlp中,很少使用BN,大多使用LN。
1.什么是BN,以及使用场景
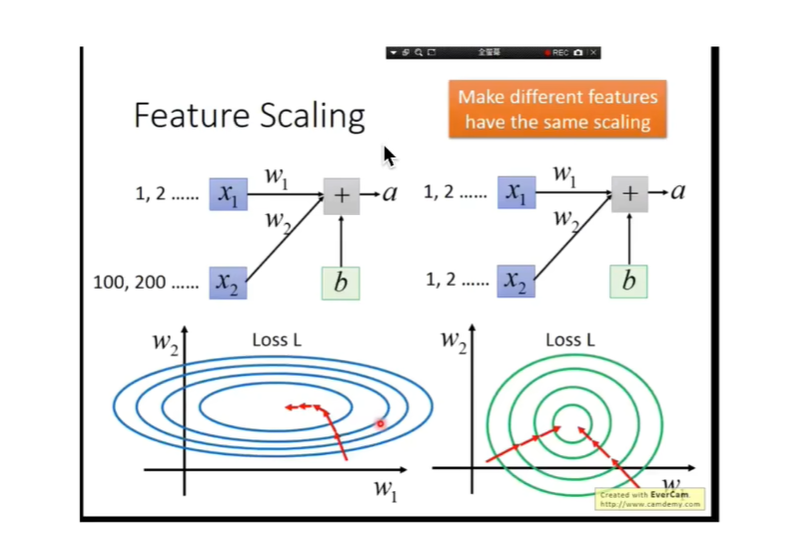
我们看下面一张图:
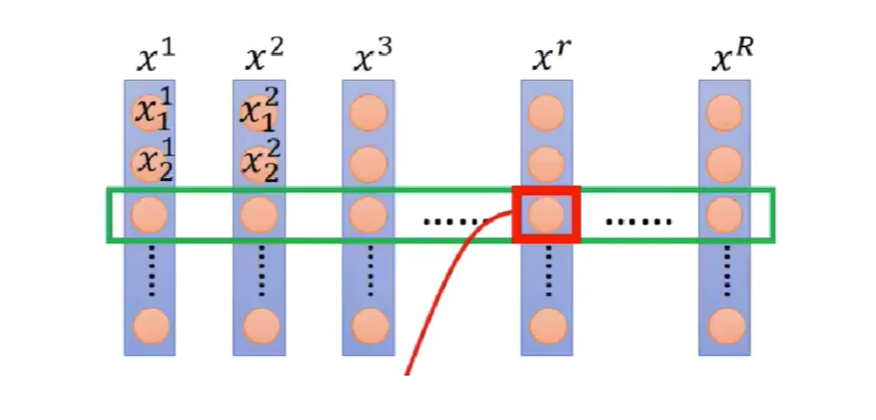
每一行代表一个特征,每个人的“体重,身高”等指标,每个人的第一个特征都是“体重”。x1,x2分别代表不同的人。
2.BN的优点
- 可以解决内部协变量偏移
- 缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛
3.BN的缺点
- batch_size较小的时候,效果差,局部的方差并不能代表全局
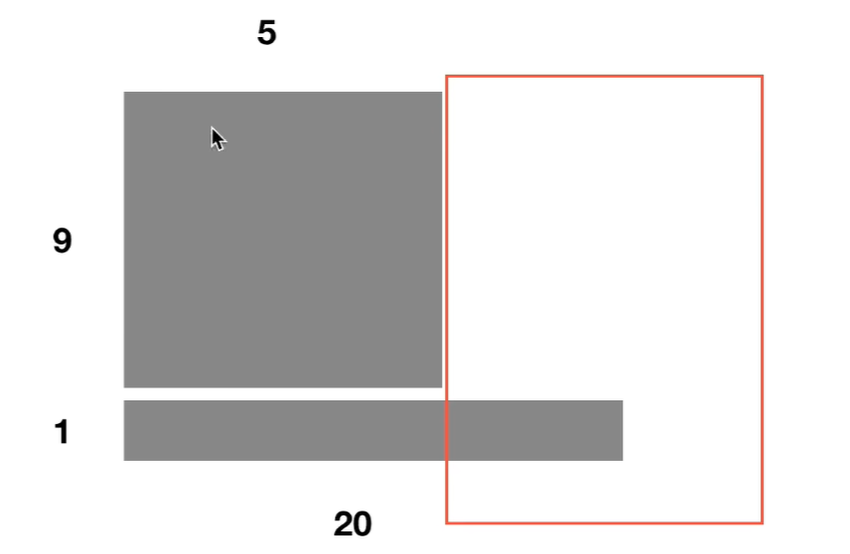
- BN再RNN中效果差,我们看下面的例子:前9个句子只有5个向量,但是第10个句子的长度达到20个向量的,这样导致第6到20维无法做BN,从而导致BN在RNN的处理中效果差
六、Layer Normal详解
1.如何理解LN
理解:为什么LayerNorm单独对一个样本的所有单词做缩放可以起到效果。
我们如果把BN引申到RNN,下面这张图则表示“我”和“今”是同一层的语义信息,,,“爱“和”天“是一层语义信息里面。

而在LN中,我们认为这两段话每段话都是分别的一个语义信息。
2.前馈神经网络
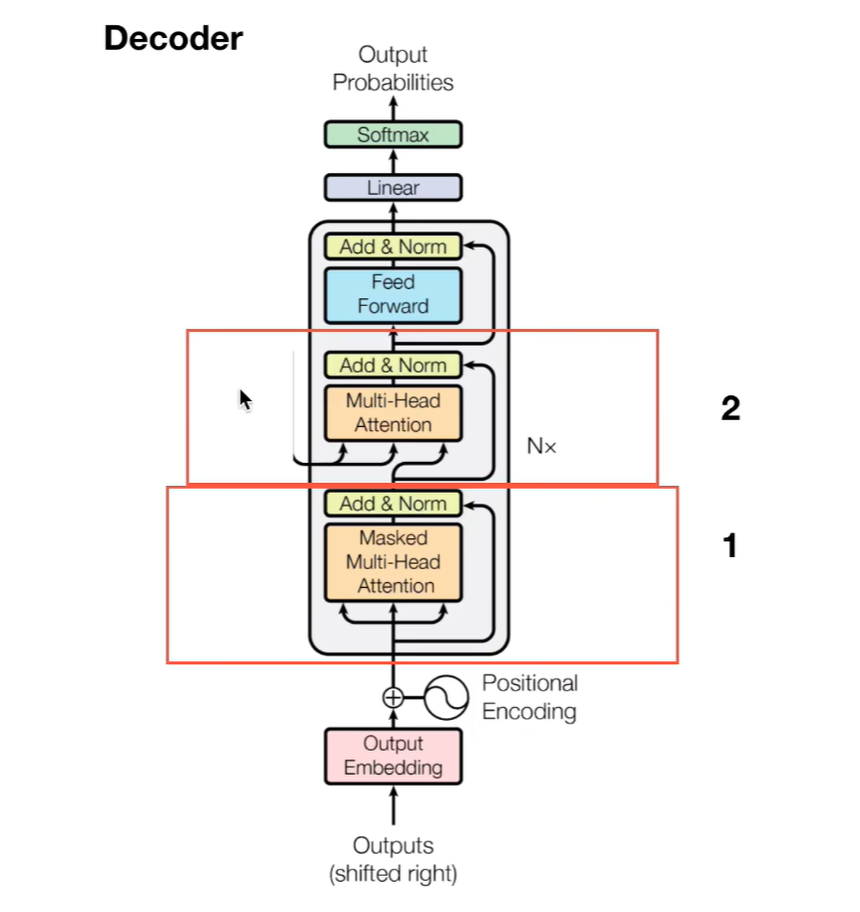
七、Decoder详解
1.多头注意力机制
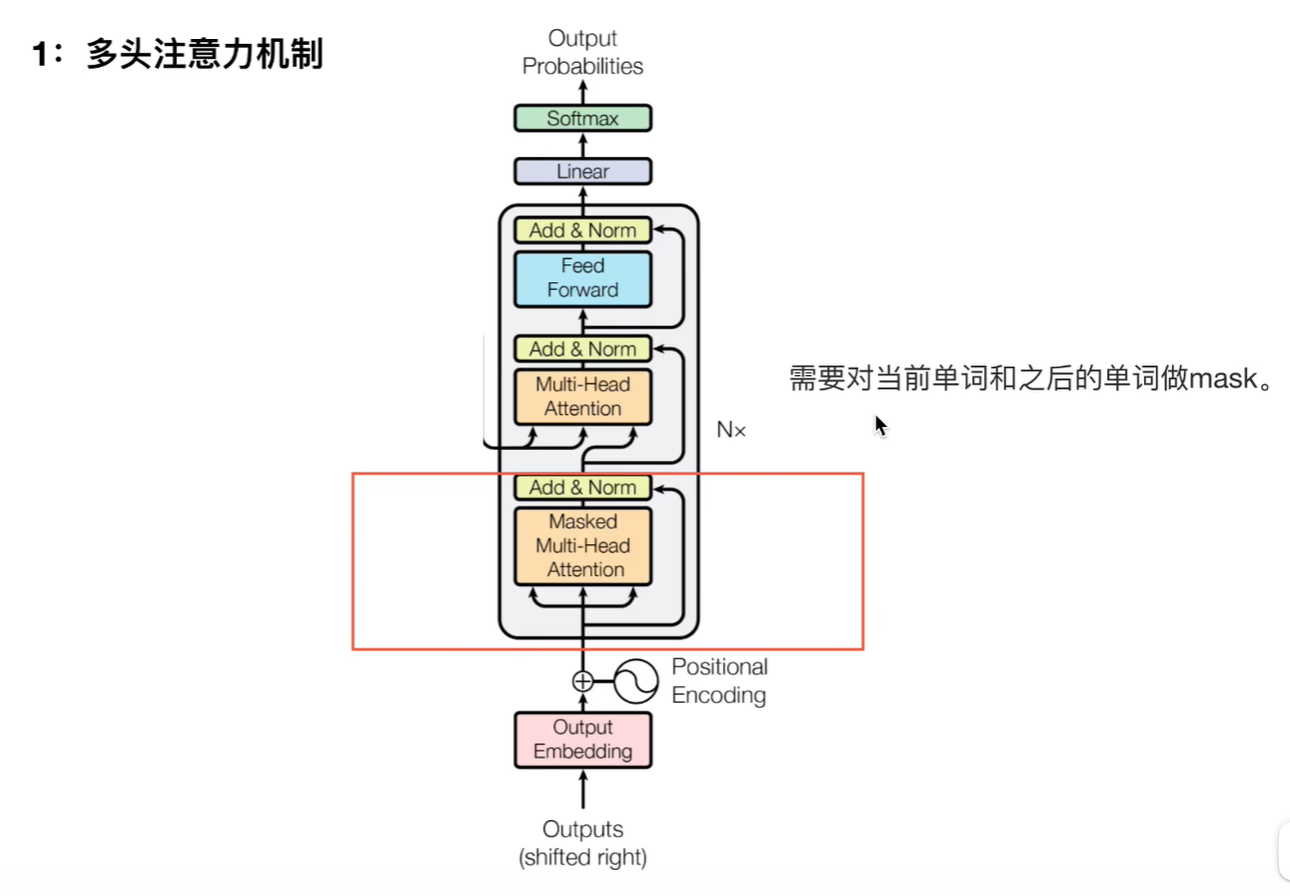
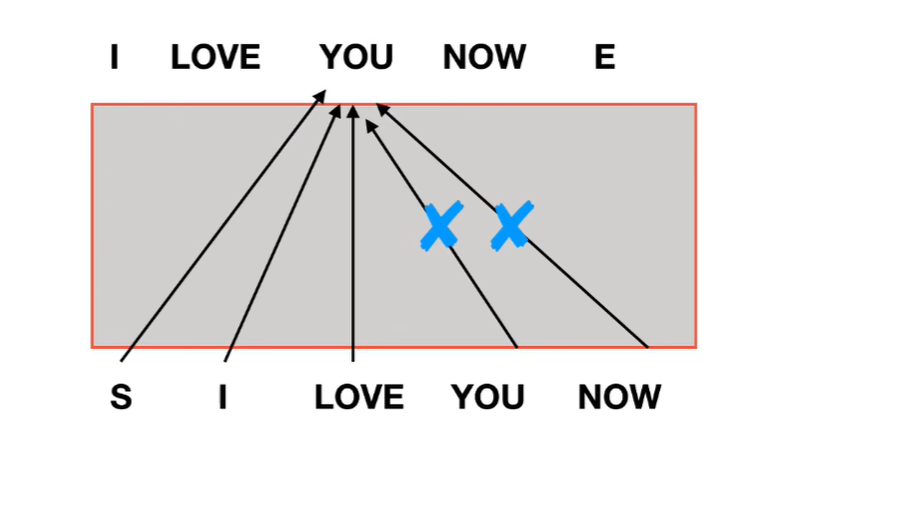
2.为什么需要mask
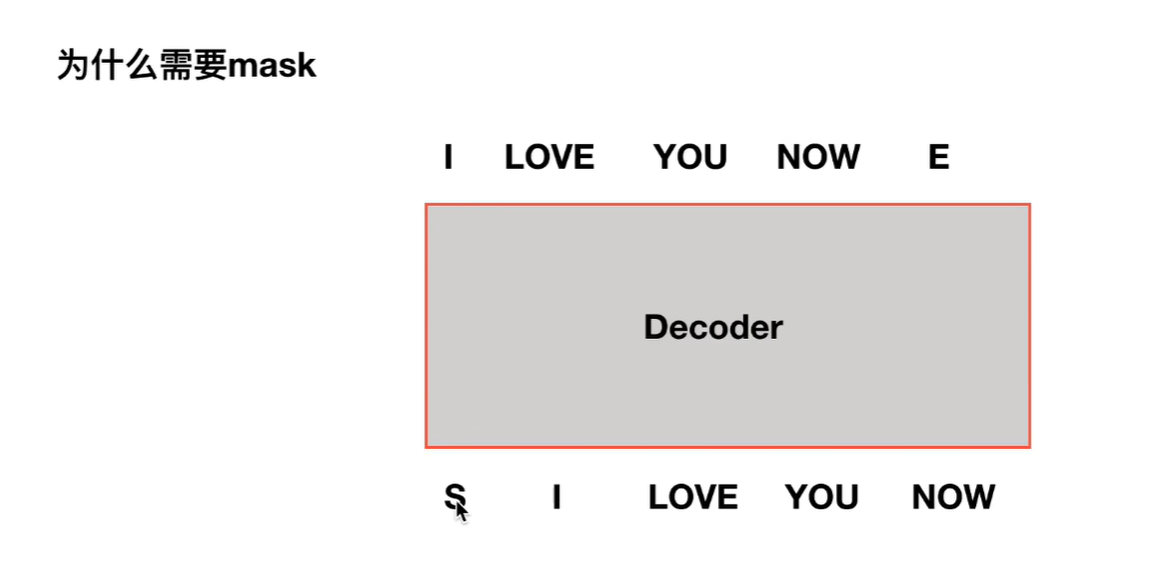
如果我们没有mask去训练的时候,我们在训练you的时候,所有的单词都对you做出了贡献。这样会导致训练和预测是不对等的。
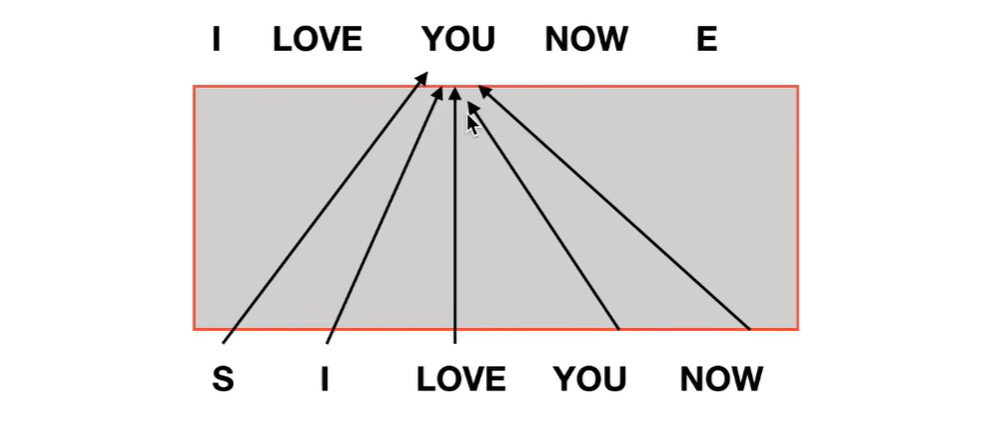
正确的做法是:
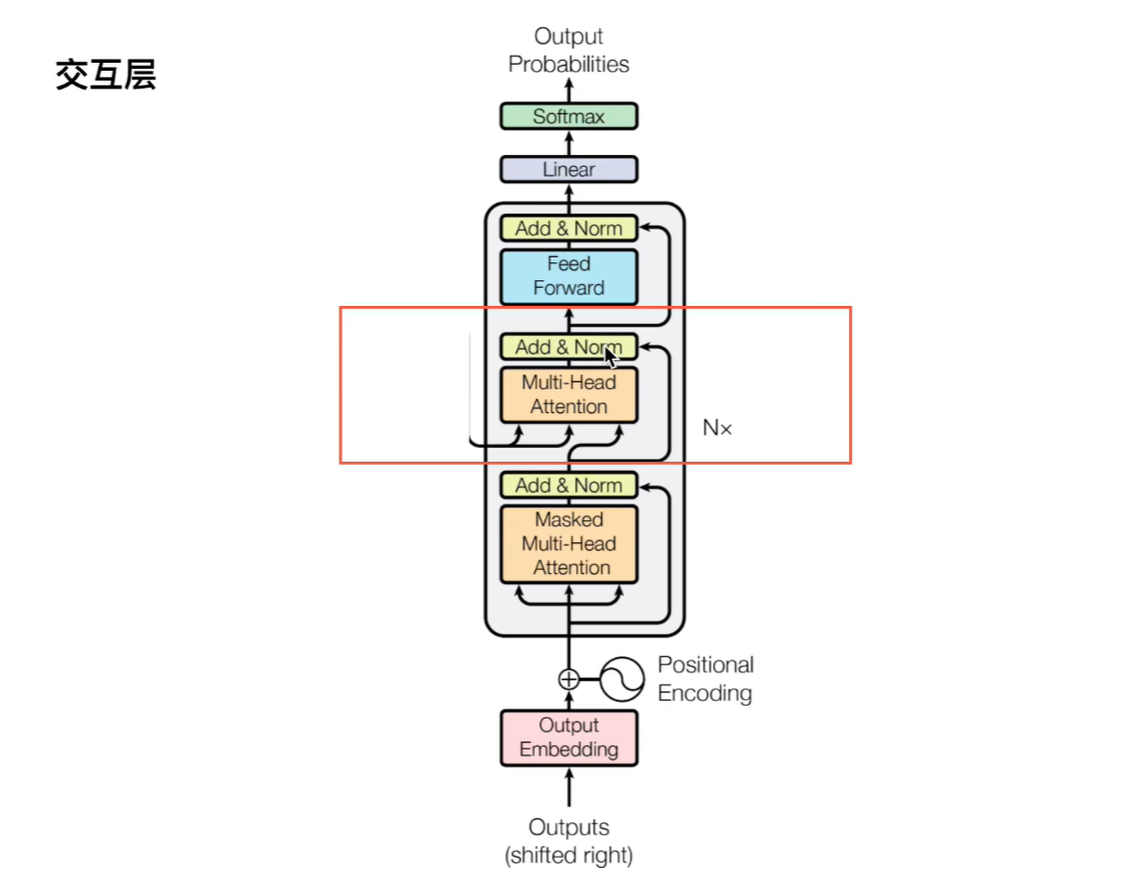
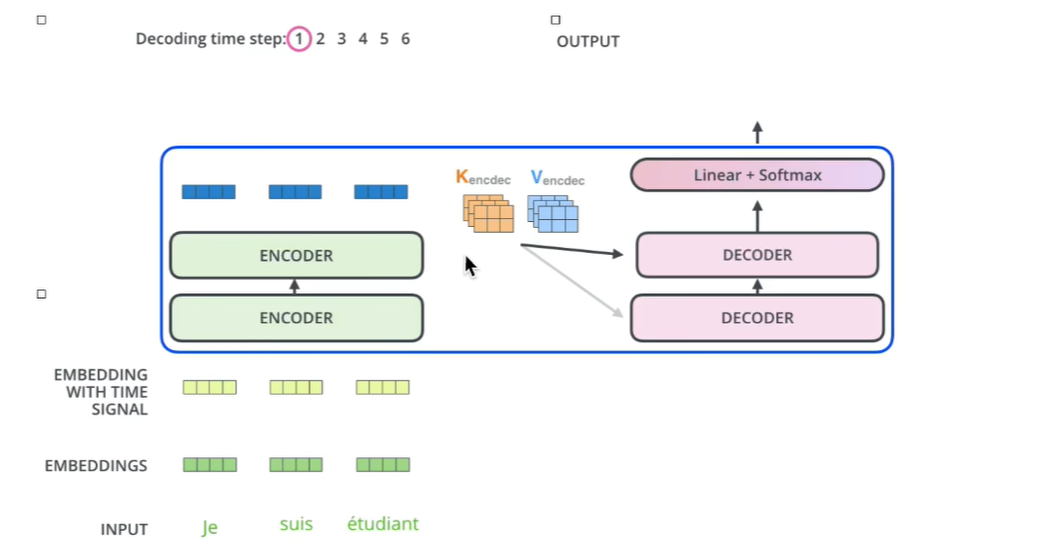
3.交互层
我们再来看一下交互层,在交互层我们需要注意的是encoder的输出需要和每一个decoder做交互。





![[Linux]:环境变量与进程地址空间](https://img-blog.csdnimg.cn/img_convert/1a5c9abd46ac7af93e5dbe7e0180b970.jpeg)






![[Git使用] 实战技巧](https://i-blog.csdnimg.cn/direct/19d8c77f77554a709f8ba383b96aa1e0.png)