前两天,搞了个微信 AI 小助理-小爱(AI),爸妈玩的不亦乐乎。
- 零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(上)
- 零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)
有朋友问:平时不喜欢打字,发语音多方便,小助理能听懂语音么?
必须能!
这背后的用到的其实就是语音识别,之前的教程中猴哥也多次分享过。
不过在语音识别之前,我们还需要能正确接收语音并解码。
本次分享,将继续基于wechatbot-wehook框架,带大家实操:如何接收微信语音,并通过语音识别,让小爱听懂你的心声!
1. 接收微信语音
参考:https://github.com/foyoux/pilk
1.1 语音数据简介
我们先来简单认识一下语音数据:
通常,保存和传输的语音数据分为多个独立的 frame,每个 frame 开头两字节存储剩余 frame 数据的大小,每个 frame 默认存储 20ms 的音频数据。
我们正常使用的音频格式为 mp3/wav 等,而微信传输的音频均为Silk v3格式,这种格式占用空间非常小。
为此,处理过程中需要对二者进行转换:
- SILK->PCM->MP3,这个过程叫做Silk v3的解码;
- MP3->PCM->SILK,这个过程叫做silk v3的编码
你会发现:这两的转换需要一个中间格式 PCM。
1.2 微信音频转换
当你给小爱发送一段语音,后台接收到的文件就是 Silk 格式,文件名类似:message-666-audio.sil,content-type为audio/silk。
标准 SILK 文件,以 b’#!SILK_V3’ 开始,以 b’\xFF\xFF’ 结束,中间为语音数据。
微信语音在标准 SILK 文件的基础上,开头插入了 b’\x02’,去除了结尾的 b’\xFF\xFF’,中间不变。
为此,我们可以通过以下两步,对.sil文件进行解码。
step1: SILK->PCM
import av
import pilk
def convert_to_pcm(in_path='output/test.sil'):
out_path = os.path.splitext(in_path)[0] + '.pcm'
with av.open(in_path) as in_container:
in_stream = in_container.streams.audio[0]
sample_rate = in_stream.codec_context.sample_rate
channels = in_stream.codec_context.channels
with av.open(out_path, 'w', 's16le') as out_container:
out_stream = out_container.add_stream('pcm_s16le', rate=sample_rate, layout='mono')
for frame in in_container.decode(in_stream):
frame.pts = None
for packet in out_stream.encode(frame):
out_container.mux(packet)
return out_path, sample_rate, channels
step2: PCM->MP3
def pcm_to_mp3(pcm_file, sample_rate=44100, channels=2):
mp3_file = os.path.splitext(pcm_file)[0] + '.mp3'
ffmpeg.input(pcm_file, format='s16le', ar=sample_rate, ac=channels)\
.output(mp3_file)\
.run(overwrite_output=True, quiet=True)
注意:上述步骤,需要依赖ffmpeg,一键安装指令如下:
sudo apt install ffmpeg
pip install ffmpeg-python
最后,我们来看下三种格式的文件大小:
du -h output/test.*
12K output/test.mp3
96K output/test.pcm
12K output/test.sil
一段 3 秒左右的语音.sil大概有 12K!微信语音默认采样率为 16000,单通道。
2. 语音识别-ASR
语音识别简称 ASR,之前和大家过两款 ASR 项目,并部署实战过,这不就派上用场了?
- FunASR
- SenseVoice
实测效果SenseVoice更佳,这次我们就用它!
不过你无需本地部署,siliconflow 提供了免费调用的接口。
给大家贴下调用代码:
def asr_sensevoice(file_path="output/test.mp3"):
url = "https://api.siliconflow.cn/v1/audio/transcriptions"
headers = {
"accept": "application/json",
"Authorization": "Bearer xxx"
}
files = {
"file": open(file_path, "rb"), # The key "file" should match the expected parameter name on the server
"model": (None, "iic/SenseVoiceSmall") # "None" is used because model is just a string, not a file
}
response = requests.post(url, files=files, headers=headers)
data = response.json()
return data["text"]
3. 语音合成-TTS
如果你还期待能够合成语音返回,就得用到语音合成技术。之前和大家过几款最近爆火的 TTS 项目:
- EdgeTTS
- ChatTTS
- CosyVoice
因为EdgeTTS底层是微软在线语音合成服务,无需本地部署,所以优先考虑。使用也非常简单,只需几行代码:
def tts_edge(text='', filename='output/tts.wav'):
communicate = edge_tts.Communicate(text=text,
voice="zh-CN-XiaoxiaoNeural", # zh-HK-HiuGaaiNeural
rate='+0%',
volume= '+0%',
pitch= '+0Hz')
communicate.save_sync(filename)
不过,wechatbot-wehook框架只支持发送音频文件,不支持发送语音到微信端侧直接显示。
先暂且搁置,等后续有空再进行二次开发。
4. 效果展示
给大家展示两个对话案例:
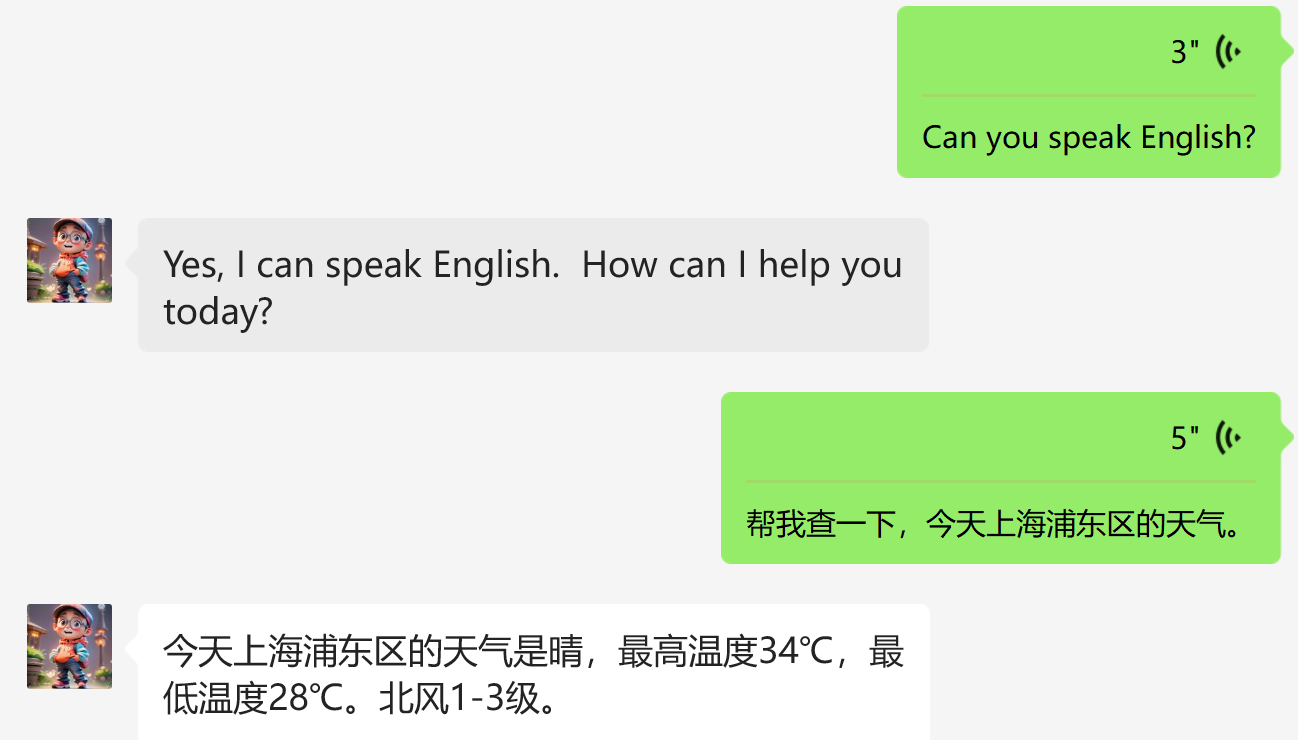
怎么样?
当作你口袋中的口语陪练,没问题吧?

写在最后
终于,又给小爱装上了耳朵,不想打字,只想发语音的必备神器。
当然,小爱还有无限想象空间,下一篇打算把文件处理也接入进来。
大家有更好的想法,欢迎评论区交流。
如果本文对你有帮助,不妨点个免费的赞和收藏备用。
为了方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
小爱也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。


![[Redis] 分布式系统与Redis介绍](https://i-blog.csdnimg.cn/direct/d2ad2344168843e595d2c2b86ebc4ede.png)












![[SDK]-组合框 和 列表框控件](https://i-blog.csdnimg.cn/direct/52ae953251da42e7975f7a6eae3afcac.gif)