详解TensorRT的C++高性能部署
- 一. ONNX
- 1. ONNX的定位
- 2. ONNX模型格式
- 3. ONNX代码使用实例
- 二、TensorRT
- 1 引言
- 三、C++部署Yolo模型实例
一. ONNX
1. ONNX的定位
ONNX是一种中间文件格式,用于解决部署的硬件与不同的训练框架特定的模型格式的兼容性问题。

ONNX本身其实是一种模型格式,属于文本,不是程序,因而无法直接在硬件设备上运行。因此,就需要ONNX Runtime、TensorRT等软件栈(推理框架(引擎))来加载ONNX模型,从而使得它在硬件设备上能够高效地推理。

许多芯片厂商依托自研的推理框架,NVIDIA的TensorRT、Intel的OpneVINO等可以充分发挥自家芯片的能力,但是普适性较差,你没有办法应用到其它的芯片上。
而,ONNX Runtime等通用性强,可以运行在不同的软硬件平台。
所以,PyTorch模型的部署通用流程一般如下:
首先,训练PyTorch等深度学习框架的网络模型;接着,将模型转换为ONNX模型格式;最后,使用推理框架把ONNX模型高效地运行在特定的软硬件平台上。

2. ONNX模型格式
ONNX (Open Neural Network Exchange)
一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。不同的训练框架可采用相同格式存储模型并交互。由微软,亚马逊,Facebook和BM等公司共同发起。

下图,是经典的LeNet-5由PyTorch框架转换ONNX中间格式后,netron.app可视化的结构图。ONNX模型是一个有向无环图,图中的每个结点代表每个用于计算的算子,所有算子的集合称之为算子集,图中的边表示结点的计算顺序和数据的流向。

模型属性,可以看到ONNX规范的第6个版本,PyTorch的版本,ONNX算子集的版本。

也可以点击结点,查看每个结点的信息。属性attributes记录的就记录超参数信息。1个输入,1个输出(名称为11)等等。

ONNX中定义的所有算子构成了算子集,访问网页,可以查看所有算子的定义。
算子在不同的版本,可能会有差异,比如这里的全局平均池化AveragePool,ONNX中AveragePool的属性中pads是个list,而PyTorch中是1个int,所以PyTorch导出ONNX时,会在AveragePool前面加上1个Pad结点。

3. ONNX代码使用实例
这里以图像分类模型转ONNX为例,进行PyTorch模型转ONNX。
import torch
import torchvision
# 选择模型推理的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 从pytorch官方实例化预训练模型,并转验证模型
model = torchvision.models.resnet18(pretrained=False)
model = model.eval().to(device)
# 构造一个输入图像的Tensor
# 该Tensor不需要任何的意义,只要在维度上匹配模型的输入即可
# 相当于构建一个输入,走一遍模型的推理过程
x = torch.randn(1, 3, 256, 256).to(device)
# 将x输入进模型推理
output = model(x)
print(output.shape) # 1x1000
# PyTorch模型转ONNX
with torch.no_grad():
torch.onnx.export(model, # 要转换的模型
x, # 模型的任意一个匹配的输入
"resnet18.onnx", # 导出的文件名
input_names=['input'], # 输入结点的名称列表(自定义名称)
output_names=['output'], # 输出结点的名称列表(自定义名称)
opset_version=11, # ONNX的算子集版本
)
加载导出的ONNX模型,并验证。
import onnx
# 验证是否导出成功
# 读取onnx模型
onnx_model = onnx.load('resnet18.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
# 以可读的形式打印计算图
print(onnx.helper.printable_graph(onnx_model.graph))
推理引擎ONNX Runtime的使用。
import onnxruntime
import torch
# 载入onnx模型,获取ONNX Runtime推理器
ort_session = onnxruntime.InferenceSession('resnet18.onnx')
# 构造随机输入
x = torch.randn(1, 3, 256, 256).numpy()
# ONNX Runtime的输入
# 这里构建的输入和输出的名称要和上面模型导出时自定义的名称一致。
ort_inputs = {'input': x}
# ONNX Runtime的输出,是1个list,对应模型的forward输出多少个,这里就是1个
ort_output = ort_session.run(['output'], ort_inputs)[0]
pass
注意事项:
1.在转ONNX时,将模型转成.eval()验证模式,因为模型在训练时,BN层、dropout都会起作用,而推理是不需要的。
2.这里导出onnx的api中第2个参数args,必须和我们使用PyTorch定义的模型model中forward函数中传入的参数一致,因为模型是torch.nn.Module,只有再执行一遍前向推理过程,也就是forward,才知道模型中有哪些算子。这也就是torch.jit.trace过程,trace得到的torch.jit.ScriptModule才是真正的计算图结构。

3.我们在上述导出ONNX时,x = torch.randn(1, 3, 256, 256).numpy()
,代表着batch为1,每次模型的推理只能接受1张图,这么做的效率就低了。可以在导出的时候设置dynamic_axes参数,使得动态接受数据的数量。

二、TensorRT
TensorRT是由NVIDIA 提供的一个高性能深度学习推理(inference)引擎。用于提高深度学习模型在NVIDIA GPU上运行的的推理速度和效率。
1 引言
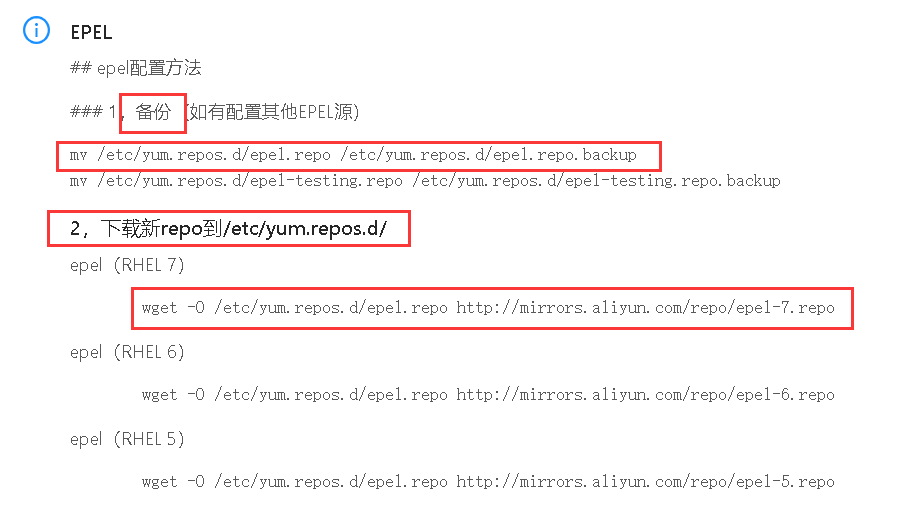
要进行NVIDIA显卡的高性能推理,首推的还是自研发的推理引起TensorRT。使用TensorRT部署ONNX模型时,分为两个阶段:
1.构建阶段。对ONNX模型转换和优化,输出优化后模型。

TensorRT会解析ONNX模型,并进行多项优化:
(1)模型量化。分为:训练后量化、训练时量化,均支持。下图为将FP32量化为INT8。

(2)层融合
(3)自动选择最合适计算的kernel。
build阶段,支持C++和Python的API,也可以使用可执行程序trtexec。

2.运行阶段。加载优化后模型,执行推理。

注意事项:
1.如果导出ONNX时设置了动态batch,使用trtexec转换TensorRT时,就需要加上最小shape、最优shape和最大shape的参数设置。这样得到的TensorRT模型就可以支持批处理了。

2.FP16、INT8、INT4等低精度可以提升推理效率,
三、C++部署Yolo模型实例
深度学习模型,以Yolo为例,通常在以Python和PyTorch框架训练模型后,整个推理过程分为:预处理、推理和后处理部分。而要进行模型的部署,需要把后处理的部分从模型里面摘出来。
OpenCV中的深度学习模块(DNN)只提供了推理功能,不涉及模型的训练,支持多种深度学习框架:Torch、TensorFlow、Caffe、Darknet。