C 题 农作物的种植策略 gzh 大学竞赛君
根据乡村的实际情况,充分利用有限的耕地资源, 因地制宜,发展有机种 植产业,对乡村经济 的可持续发展具有重要的现实意义 。选择适宜的农作物, 优化种植策略,有利于方便田间管理,提 高生产效益,减少各种不确定因素可 能造成的种植风险。
某乡村地处华北山区, 常年温度偏低,大多数耕地每年只能种植一季农作 物 。该乡村现有露天 耕地 1201 亩 ,分散为 34 个大小不同的地块,包括平旱地、 梯田 、 山坡地和水浇地 4 种类型 。平旱 地 、梯田和山坡地适宜每年种植一季粮 食类作物; 水浇地适宜每年种植一季水稻或两季蔬菜 。该乡 村另有 16 个普通 大棚和 4 个智慧大棚, 每个大棚耕地面积为 0.6 亩 。普通大棚适宜每年种植一 季蔬菜和一季食用菌,智慧大棚适宜每年种植两季蔬菜 。 同一地块(含大棚) 每季可以合种不同的作物 。 详见附件 1。
根据农作物的生长规律,每种作物在同一地块(含大棚) 都不能连续重茬 种植,否则会减产; 因含有豆类作物根菌的土壤有利于其他作物生长,从 2023 年开始要求每个地块(含大棚) 的所有土 地三年内至少种植一次豆类作物 。 同 时 ,种植方案应考虑到方便耕种作业和田间管理,譬如 :每种 作物每季的种植 地不能太分散,每种作物在单个地块(含大棚)种植的面积不宜太小,等等 。 2023 年的农作物种植和相关统计数据见附件 2。
问题 1 假定各种农作物未来的预期销售量 、种植成本 、亩产量和销售价格 相对于 2023 年保持 稳定,每季种植的农作物在当季销售 。如果某种作物每季 的总产量超过相应的预期销售量,超过部 分不能正常销售 。请针对以下两种情
况 ,分别给出该乡村 2024~2030 年农作物的最优种植方案, 将 结果分别填入 result1_ 1.xlsx 和 result1_2.xlsx 中(模板文件见附件 3)。 (1) 超过部分滞销,造 成浪费; (2) 超过部分按 2023 年销售价格的 50%降价出售。
针对问题一 :思路如下---
这是一个复杂的数学建模问题,需要我们逐步分析和构建模型。让我们先聚焦于 第一个问题,并逐步建立模型。
首先, 问题 1 是一个优化问题,让我们分析问题 1 的关键点:
( 1) 时间跨度: 2024-2030 年(7 年)
(2) 目标: 是最大化利润
(3)约束条件:
土地面积限制
作物轮作要求(三年内至少种植一次豆类) 不能连续重茬种植
预期销售量限制
种植面积不能太分散或太小
问题 1 大致的思路框架。然而,还需要注意以下几点:
1. 数据准备: 我们需要从附件中提取具体的数据,如 land_area, revenue, cost, yield_per_mu, expected_sales 等。
2. 模型细化: 根据具体数据,我们可能需要调整一些约束条件,例如考虑大棚 的特殊种植要求。
3. 两种情况的处理: (1) 对于超过预期销售量的部分滞销的情况,我们可以在 目标函数中只计算实际销售部分的收入。 (2) 对于降价出售的情况,我们 可以在目标函数中为超过部分设置一个 0.5 的系数。
4. 结果输出: 最终需要将结果填入提供的 Excel 模板中。
5. 求解效率: 如果问题规模过大,可能需要考虑使用更高效的求解器或者采 用启发式算法。
农作物种植策略优化问题的详细建模过程
1. 问题分析
我们需要为某个乡村制定 2024-2030 年的农作物种植策略, 以最大化利润 。 主要 考虑因素包括:
- 不同类型的耕地和大棚
- 多种农作物
- 种植和销售的各项限制
- 作物轮作要求
- 两种不同的产量超出销售量的处理情况
2. 数据准备
首先,我们需要从附件中提取以下数据:
- 耕地信息:类型 、面积
- 农作物信息:种类 、生长周期 、适宜种植的地块类型
- 经济数据:种植成本 、销售价格 、预期销售量
- 产量数据:每种作物的亩产量
3. 变量定义
定义决策变量 x[i,j,k,t]:
- i: 年份 (2024-2030)
-j: 作物种类
- k: 地块类型
- t: 季节 (春季或秋季,对于每年只种植一季的地块,t 只有一个值)
x[i,j,k,t] 表示在 i 年 k 类型地块上 t 季节种植 j 作物的面积
4. 目标函数
最大化总利润:
max ∑(i,j,k,t) (销售收入[i,j] - 种植成本[i,j]) * x[i,j,k,t]
其中:
- 销售收入[i,j] = min(实际产量, 预期销售量) * 销售价格[j]
- 实际产量 = x[i,j,k,t] * 亩产量[j]
对于两种不同情况:
1. 超过部分滞销:使用上述公式
2. 超过部分降价出售:
销售收入[i,j] =min(实际产量, 预期销售量) * 销售价格[j] + max(0, 实际产量 - 预期销售量) * 销售价格[j] * 0.5
5. 约束条件
1. 土地面积约束:
对于每年 、每种地块类型 、每个季节: ∑(j) x[i,j,k,t] <= 地块面积[k]
2. 作物轮作要求:
对于每个连续的三年期间 、每种地块类型:
∑(j∈豆类,t) x[i,j,k,t] + x[i+1,j,k,t] + x[i+2,j,k,t] >= 0.1 * 地块面积[k]
3. 不能连续重茬种植:
对于每年 、每种作物 、每种地块类型 、每个季节: x[i,j,k,t] + x[i+1,j,k,t] <= 地块面积[k]
4. 预期销售量限制:
对于每年 、每种作物:
∑(k,t) x[i,j,k,t] * 亩产量[j] <= 预期销售量[i,j]
5. 种植面积不能太分散或太小: 引入二元变量 y[i,j,k,t]:
x[i,j,k,t] >= 最小种植面积 * y[i,j,k,t] x[i,j,k,t] <= 地块面积[k] * y[i,j,k,t]
6. 特定地块种植限制:
- 水浇地每年只能种植一季水稻或两季蔬菜
- 普通大棚每年种植一季蔬菜和一季食用菌
- 智慧大棚每年种植两季蔬菜
6. 求解方法
我们可以使用线性规划(LP)或混合整数线性规划(MILP)来求解这个问题 。可以
使用如 PuLP 、Gurobi 或 CPLEX等优化求解器。
7. 结果分析
求解后,我们需要:
1. 检查求解状态,确保找到了最优解
2. 提取每年 、每种作物 、每种地块的种植面积
3. 计算总利润和每年的利润
4. 分析作物轮作情况
5. 比较两种产量超出处理方案的结果差异
8. 模型改进
在初步建模和求解后,我们可能需要:
1. 调整约束条件,使模型更符合实际情况
2. 考虑添加风险因素,如天气影响 、市场波动等
3. 进行敏感性分析, 了解各参数变化对结果的影响
4. 考虑多目标优化,如在最大化利润的同时,最小化环境影响
9. 结果呈现
最后,我们需要:
1. 将结果整理成所需的 Excel 格式
2. 生成可视化图表,如每年的种植面积分布 、利润变化趋势等
3. 编写报告,解释模型假设 、 求解过程和结果分析
根据附件一的内容:
说明:
1. 平旱地、梯田和山坡地每年都只能种植一季作物。
2. 水浇地每年可以种植一季也可以种植两季作物。
3. 大棚能够在一定程度上起保温作用,每年都可以种植两季作物。
4. 智慧大棚主要是在冬季利用太阳能自动调节棚内温度,保证作物的正常 生长。
作物编号 种植面积/亩
count 87.000000 87.000000 mean 22.390805 14.850575 std 12.660464 21.653776
min 1.000000 0.300000
25% 11.500000 0.600000 50% 22.000000 0.600000 75% 34.500000 20.000000 max 41.000000 86.000000



附件二的数据可视化:
1. 数据预处理
首先,将数据加载到一个合适的工具中,例如 Python 的 Pandas 库,方便后续处 理。
对数据进行分类,例如按作物类型或种植地块来分组。
2. 种植面积分布
使用柱状图或饼图展示不同作物的种植面积 。例如,可以按作物名称汇总种植 面积,并可视化其分布。
3. 种植地块的种植季次分布
按照“种植季次”对数据进行分组,展示不同季节种植作物的面积分布。
4. 作物类型和种植面积的关系
可以绘制一个堆叠条形图或分组条形图,展示每种作物类型(如粮食 、蔬菜等) 对应的种植面积。
5. 特定地块的作物种类分布
如果关注某一个地块(如 A 区 、B 区等), 可以提取该区域的种植信息并进行可 视化,例如按地块绘制面积分布图。
6. 第一季与第二季的作物分布
对于有第一季和第二季的地块,可以分别绘制第一季和第二季的作物种植情况, 以了解不同季节的种植结构。
以下是一个简单的代码示例,用 Python 和 Matplotlib 进行初步可视化:




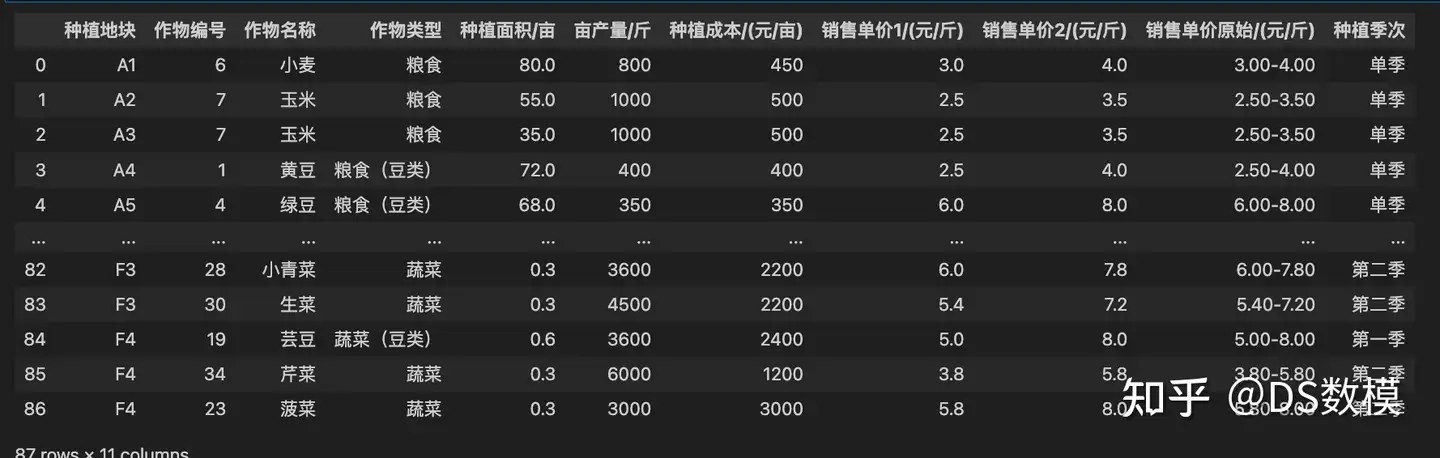
| 作物类型 | 种植面积/亩 |
| 粮食 | 760 |
| 粮食(豆类) | 374 |
| 蔬菜 | 121.6 |
| 蔬菜(豆类) | 26.8 |
| 食用菌 | 9.6 |
| 前 5 种 | ||
| 种植地块 | 作物编号 作物名称 | 作物类型 种植面积/亩 种植季次 |
| 0 A1 6 | 小麦 粮食 80.0 | 单季 |
| 1 A2 7 | 玉米 粮食 55.0 | 单季 |
| 2 A3 7 | 玉米 粮食 35.0 | 单季 |
| 3 A4 1 | 黄豆 粮食(豆类) | 72.0 单季 |
| 4 A5 4 | 绿豆 粮食(豆类) | 68.0 单季 |
附件二中的第二个 表格的可视乎分析:


针对这个问题,首先需要进行优化建模。由于问题中涉及到最优种植方案,可 使用线性规划(Linear Programming, LP)或类似的优化方法来解决。Python 中 常用的库如 PuLP 或 SciPy 可以帮助构建优化问题。
该问题涉及以下几个因素:
1. 地块资源:不同类型地块面积及其作物种植限制。
2. 作物种植要求:每种作物的种植周期、成本、产量等。
3. 目标:最大化收益,并避免或减少浪费。
4. 约束:
o 地块类型适应性限制(如水浇地只能种水稻或蔬菜)。
o 每三年必须种植一次豆类。
o 每个作物每季的产量不能太分散,且不能重茬种植。
为此,你可以按照以下步骤构建模型并解决问题。下面是一个基本的代码框架, 读取附件数据并构建优化问题。
import pulp
import pandas as pd import numpy as np
# 读取数据
import pandas as pd import os
def load_data():
# 设置文件路径
attachment1_path = r"C:\Users\Administrator\Desktop\附件 1.xlsx" attachment2_path = r"C:\Users\Administrator\Desktop\附件 2.xlsx"
# 读取第一个表格: 乡村的现有耕地
fields = pd.read_excel(attachment1_path, sheet_name=0)
fields = fields.rename(columns={'地块名称': 'name', '地块类型': 'type', '地块面积/ 亩': 'area'})
# 读取第二个表格: 乡村种植的农作物
crops = pd.read_excel(attachment1_path, sheet_name=1)
crops = crops.rename(columns={' 作物编号': 'id', ' 作物名称': 'name', '作物类型': 'type', '种植耕地': 'suitable_fields'})
# 读取第三个表格:2023 年的农作物种植情况
planting_2023 = pd.read_excel(attachment2_path, sheet_name=1)
planting_2023 = planting_2023.rename(columns={' 种植地块': 'field', ' 作物编号': 'crop_id', '作物名称': 'crop_name',
'作物类型': 'crop_type', '种植面积/亩': 'area', '种植季
次': 'season'})
# 读取第四个表格:2023 年统计的相关数据
stats_2023 = pd.read_excel(attachment2_path, sheet_name=0)
stats_2023 = stats_2023.rename(columns={'序号': 'index', '作物编号': 'crop_id', '作 物名称': 'crop_name',
'地块类型': 'field_type', '种植季次': 'season', '亩产量/斤':
'yield_per_mu',
' 种植成本/( 元/ 亩)': 'cost_per_mu', ' 销售单价/( 元/ 斤)':
'price_range'})
# 处理价格范围
stats_2023[['min_price', 'max_price']] = stats_2023['price_range'].str.split('-', expand=True).astype(float)
stats_2023['avg_price'] = (stats_2023['min_price'] + stats_2023['max_price']) / 2 stats_2023 = stats_2023.drop('price_range', axis=1)
return fields, crops, planting_2023, stats_2023
def create_model(crops, fields, planting_2023, stats_2023, years, seasons, case): model = pulp.LpProblem("Crop_Planning", pulp.LpMaximize)
# 决策变量
x = pulp.LpVariable.dicts("plant",
((c, f, y, s) for c in crops['id'] for f in fields['name'] for y in years for s in seasons),
lowBound=0, cat='Continuous') # 辅助变量:超过预期销售量的部分
excess = pulp.LpVariable.dicts("excess",
((c, y) for c in crops['id'] for y in years), lowBound=0, cat='Continuous')
# 目标函数 if case == 1:
# 超过部分滞销
model += pulp.lpSum(x[c,f,y,s] * stats_2023[stats_2023['crop_id'] ==
c]['yield_per_mu'].values[0] *
stats_2023[stats_2023['crop_id'] == c]['avg_price'].values[0] -
x[c,f,y,s] * stats_2023[stats_2023['crop_id'] == c]['cost_per_mu'].values[0]
for c in crops['id'] for f in fields['name'] for y in years for s in seasons)
elif case == 2:
# 超过部分 50%价格销售
model += pulp.lpSum(x[c,f,y,s] * stats_2023[stats_2023['crop_id'] ==
c]['yield_per_mu'].values[0] *
stats_2023[stats_2023['crop_id'] == c]['avg_price'].values[0] -
x[c,f,y,s] * stats_2023[stats_2023['crop_id'] == c]['cost_per_mu'].values[0] +
excess[c,y] * stats_2023[stats_2023['crop_id'] == c]['avg_price'].values[0] * 0.5
for c in crops['id'] for f in fields['name'] for y in years for s in seasons)
# 约束条件
# 1. 土地面积约束
for fin fields['name']: for y in years:
for s in seasons:
model += pulp.lpSum(x[c,f,y,s] for c in crops['id']) <= fields[fields['name'] == f]['area'].values[0]
# 2. 作物轮作约束
for fin fields['name']:
for y in years[1:]: # 从第二年开始
for s in seasons:
for c in crops['id']:
model += x[c,f,y,s] <= fields[fields['name'] == f]['area'].values[0] - x[c,f,y-1,s]
# 3. 豆类种植约束
bean_crops = crops[crops['type'].str.contains('豆类')]['id'] for fin fields['name']:
for y in range(0, len(years), 3): # 每三年一个周期
model += pulp.lpSum(x[c,f,y+i,s] for c in bean_crops for i in range(3) for s in seasons) >= 1
# 4. 产量约束
for c in crops['id']: for y in years:
total_production = pulp.lpSum(x[c,f,y,s] * stats_2023[stats_2023['crop_id'] == c]['yield_per_mu'].values[0]
for fin fields['name'] for s in seasons)
expected_sales = stats_2023[stats_2023['crop_id'] ==
c]['expected_sales'].values[0] # 需要添加这个数据
model += total_production - expected_sales <= excess[c,y] # 5. 种植分散度约束
max_fields = 5 # 假设每种作物每季最多种植在 5 个地块
for c in crops['id']: for y in years:
for s in seasons:
model += pulp.lpSum(pulp.LpVariable(f"plant_ {c}_ {f}_ {y}_ {s}_binary", cat='Binary')
for fin fields['name']) <= max_fields for fin fields['name']:
model += x[c,f,y,s] <= fields[fields['name'] == f]['area'].values[0] * pulp.LpVariable(f"plant_ {c}_ {f}_ {y}_ {s}_binary", cat='Binary')
# 6. 最小种植面积约束
min_area = 10 # 假设最小种植面积为 10 亩
for c in crops['id']:
for fin fields['name']:
for y in years:
for s in seasons:
model += x[c,f,y,s] == 0 if x[c,f,y,s] < min_area else x[c,f,y,s] >=
min_area
return model
def solve_model(model):
solver = pulp.PULP_CBC_CMD(msg=False, timeLimit=600) # 设置求解时间限 制为 10 分钟
model.solve(solver) return model
def process_results(model, crops, fields, years, seasons): results = []
for v in model.variables():
ifv.varValue > 0 and v.name.startswith("plant_"): _, c, f, y, s = v.name.split('_')
results.append({
'crop': crops[crops['id'] == int(c)]['name'].values[0], 'field': f,
'year': int(y),
' '
season : s,
'area': v.varValue })
return pd.DataFrame(results)
def main():
fields, crops, planting_2023, stats_2023 = load_data() years = range(2024, 2031)
seasons = ['spring', 'autumn']
for case in [1, 2]:
model = create_model(crops, fields, planting_2023, stats_2023, years, seasons, case)
solved_model = solve_model(model)
results = process_results(solved_model, crops, fields, years, seasons) # 保存结果
filename = f'result1_ {case}.xlsx'
results.to_excel(filename, index=False)
print(f"Results for case {case} saved to {filename}")
if __name__ == "__main__": main()
关于第二问:
问题 2 根据经验,小麦和玉米未来的预期销售量有增长的趋势,平均年增长率 介于 5%~ 10% 之间, 其他农作物未来每年的预期销售量相对于 2023 年大约有 ±5%的变化 。农作物的亩产量往往会 受气候等因素的影响,每年会有±10%的变 化 。 因受市场条件影响,农作物的种植成本平均每年增长 5%左右 。粮食类作物 的销售价格基本稳定;蔬菜类作物的销售价格有增长的趋势,平均每年增长 5% 左右 。食用菌的销售价格稳中有降,大约每年可下降 1%~5%,特别是羊肚菌的 销售价格每年下降幅 度为 5% 。 请综合考虑各种农作物的预期销售量 、亩产量、 种植成本和销售价格的不确定性以及潜在的种 植风险,给出该乡村 2024~2030 年农作物的最优种植方案,将结果填入 result2.xlsx 中(模板文件见 附件 3)。
针对问题 2 ,你需要综合考虑农作物的多重因素,包括预期销售量、亩产量、
种植成本和销售价格的变化,并对这些不确定性进行建模。该问题比第一问更 复杂,因为它引入了时间动态和不确定性。
解决思路
1. 时间动态:需要针对 2024~2030 年每一年的种植规划进行优化。
2. 不确定性建模:每年农作物的预期销售量、亩产量、种植成本和销售价 格都有波动,必须通过引入区间来模拟不确定性。
3. 不同作物特性:
o 小麦和玉米:销售量有年增长率(5%~ 10%)。
o 其他作物:预期销售量每年变化±5%。
o 蔬菜类:价格有年增长趋势,约 5%。
o 食用菌类:价格逐年下降,羊肚菌每年下降 5%。
模型框架
你可以使用多阶段优化模型来处理这个问题,结合情景分析和线性规划。针对 每年不同农作物的变化,你需要设置每年不同的目标函数和约束条件。
具体步骤:
1. 读取数据:从附件 2 获取 2023 年的数据。
2. 定义决策变量:定义每年各作物的种植面积。
3. 目标函数:最大化 2024~2030 年各年的收益,同时考虑销售量、成本、 产量和价格的变化。
4. 约束条件:
o 每年不能超过总可用耕地面积。
o 每年必须种植至少一次豆类作物
o 作物不能重茬种植。
5. 处理不确定性:
o 使用区间值(如年增长率、波动范围)来描述作物的销售量、成 本、产量和价格的不确定性。
import pandas as pd import pulp
import numpy as np
# 读取 2023 年的数据
data = pd.read_excel(' 附件二.xlsx')
# 创建时间序列 2024-2030
years = list(range(2024, 2031))
# 定义农作物
crops = data['作物名称'].unique()
# 每年的变量,存储每种作物在每个地块类型上的种植面积 crop_vars = {}
# 创建线性规划模型
prob = pulp.LpProblem("MultiYear_Crop_Optimization", pulp.LpMaximize) # 定义 2024~2030 年不确定性因素
sales_growth = {'小麦': (0.05, 0. 1), '玉米': (0.05, 0. 1)} # 销量年增长率 other_sales_variation = 0.05 # 其他作物销量波动±5%
yield_variation = 0.10 # 亩产量波动±10% cost_growth = 0.05 # 每年种植成本增长 5%
vegetable_price_growth = 0.05 # 蔬菜价格年增长 5%
mushroom_price_decline = {'羊肚菌': 0.05} # 羊肚菌价格年下降 5%
# 定义每年决策变量
for year in years:
crop_vars[year] = pulp.LpVariable.dicts(f"CropArea_ {year}",
[(crop, land) for crop in crops for land in ['平旱地', '梯田',
' 山坡地', '水浇地', '普通大棚', '智慧大棚']],
lowBound=0, cat='Continuous')
# 约束条件 1 :每年总种植面积不能超过总可用耕地面积 total_land = 1201 # 总耕地面积
greenhouse_area = 0.6 * (16 + 4) # 大棚面积
for year in years:
for land in ['平旱地', '梯田', ' 山坡地', '水浇地']:
prob += pulp.lpSum([crop_vars[year][(crop, land)] for crop in crops]) <= total_land, f"Land_Constraint_ {year}_ {land}"
for gh in ['普通大棚', '智慧大棚']:
prob += pulp.lpSum([crop_vars[year][(crop, gh)] for crop in crops]) <= greenhouse_area, f"Greenhouse_Constraint_ {year}_ {gh}"
# 约束条件 2:每三年种植一次豆类作物
bean_crops = ['黄豆', '黑豆', '红豆', '绿豆'] # 豆类作物
for i in range(2024, 2031, 3):
prob += pulp.lpSum([crop_vars[year][(crop, land)] for crop in bean_crops for year in range(i, i+3) for land in ['平旱地', '梯田', ' 山坡地', '水浇地', '普通大棚', '智慧大棚 ']]) >= total_land / 3, f"Bean_Crop_Constraint_ {i}"
# 约束条件 3 :避免重茬种植
# 添加避免重茬的约束,确保相邻年份同一地块不种植相同作物
# 目标函数:最大化每年的收益,考虑到每年的不确定性
for year in years:
for crop in crops:
for land in ['平旱地', '梯田', ' 山坡地', '水浇地', '普通大棚', '智慧大棚']:
sale_price = data.loc[data['作物名称'] == crop, '销售单价/(元/斤)'].mean()
yield_per_acre = data.loc[data['作物名称'] == crop, '亩产量/斤'].mean()
cost_per_acre = data.loc[data['作物名称'] == crop, '种植成本/(元/亩)'].mean()
# 销售量不确定性处理
if crop in sales_growth: # 小麦和玉米
growth_rate = np.random.uniform(*sales_growth[crop])
sale_volume = (1 + growth_rate) ** (year - 2023) else:
sale_volume = np.random.uniform(1 - other_sales_variation, 1 +
other_sales_variation)
# 亩产量不确定性处理
yield_per_acre = yield_per_acre * np.random.uniform(1 - yield_variation, 1 + yield_variation)
# 成本增长处理
cost_per_acre = cost_per_acre * (1 + cost_growth) ** (year - 2023)
# 销售价格处理
if crop in mushroom_price_decline:
sale_price = sale_price * (1 - mushroom_price_decline[crop]) ** (year -
2023)
elif crop in ['蔬菜类']:
sale_price = sale_price * (1 + vegetable_price_growth) ** (year - 2023)
# 收益计算
profit = (sale_volume * yield_per_acre * sale_price) - cost_per_acre
prob += pulp.lpSum(crop_vars[year][(crop, land)] * profit),
f"Profit_ {year}_ {crop}_ {land}"
# 求解问题 prob.solve()
# 保存结果到 result2.xlsx
template = pd.read_excel('result2.xlsx') for year in years:
template[f' 最 优 种 植 面 积 _ {year}'] = template.apply(lambda row: crop_vars[year].get((row['作物名称'], row['地块类型']), 0), axis=1)
template.to_excel('result2.xlsx', index=False)
print("最优种植方案已生成,并保存为 result2.xlsx")
问题 3:
问题 3 要求在问题 2 的基础上,进一步考虑农作物之间的可替代性和互补性, 并且将销售量、销售价格、种植成本之间的相关性纳入考虑。相比问题 2 ,问 题 3 复杂性更高,因为要处理这些相关性以及作物之间的相互关系。你需要通 过建立更加复杂的优化模型和相关性分析来进行求解。
解决思路
1. 农作物可替代性:一些作物之间存在替代性,意味着在一定条件下,如 果一种作物价格较低或者预期收益较小,农户可以选择种植另一种作物。 例如,小麦和玉米之间可能有一定的可替代性。
2. 农作物互补性:一些作物具有互补性,例如豆类作物可以改善土壤质量, 其他作物在种植后可能有较好的收益。
3. 变量之间的相关性:
o 预期销售量和价格的相关性:销售量和销售价格通常存在负相关
性 ,供大于求时,价格下降。
o 种植成本和产量的相关性:产量较高时,种植成本可能会增加 (例如劳动力成本增加,肥料需求增加)。
4. 数据模拟:通过模拟未来的气候条件、市场需求变化等外部条件,生成 不同情景下的农作物产量、销售价格、销售量和种植成本数据,进行多 情景模拟,分析不同策略下的效果。
模型扩展
问题 3 可以通过建立一个基于多目标、多情景的优化模型来解决。你可以结合 相关性分析、随机模拟和动态规划的方法,优化农作物种植策略。
具体步骤
1. 考虑农作物替代性:
o 对于可替代的作物(如小麦和玉米), 建立决策变量,使得某地块
的这两种作物种植面积之和不能超过一定阈值。
o 通过设定相应的替代系数,调整收益函数的权重,使得在作物市
场前景较差的情况下,倾向于种植替代作物。
2. 考虑农作物互补性:
o 对于互补作物(如豆类和其他作物), 引入互补系数,建立联动约 束 。例如,某块地在种植豆类作物后的几年内,其他作物的亩产
量或收益可能会增加。
3. 引入相关性分析:
o 通过统计分析,计算农作物销售量和价格 、产量与成本之间的相 关系数,构建相关性矩阵。
o 使用 Monte Carlo 模拟技术,生成未来 7 年内的市场情景,并根据
相关性矩阵生成不同情景下的种植收益。
4. 多情景模拟:
o 设置多个未来情景(如市场需求上升 、气候变化不利等), 并在每
个情景下计算最优种植方案,最终得出一个平均的最优策略。
5. 与问题 2 结果对比:
o 计算问题 2 和问题 3 在不同情景下的收益和种植面积分布,对比
分析哪些作物更具有稳定性和收益性。
import pandas as pd import pulp
import numpy as np
from scipy.stats import norm # 读取 2023 年数据
data = pd.read_excel(' 附件二.xlsx')
# 定义相关性矩阵(基于历史数据或专家经验)
correlation_matrix = np.array([[1.0, -0.3, 0.2], # 销量-价格-成本相关性矩阵示例
[-0.3, 1.0, 0. 1], [0.2, 0.1, 1.0]])
# 创建蒙特卡洛模拟生成随机情景
def simulate_scenarios(num_scenarios, mean_values, std_dev, correlation_matrix): # 生成具有相关性的随机数据
correlated_random_values = np.random.multivariate_normal(mean_values,
correlation_matrix, num_scenarios) return correlated_random_values
# 模拟 7 年内的销售量 、价格和成本
mean_values = [1.0, 1.0, 1.0] # 平均值(相对于 2023 年) std_dev = [0.05, 0.05, 0.05] # 偏差
num_scenarios = 100 # 模拟 100 个情景
scenarios = simulate_scenarios(num_scenarios, mean_values, std_dev,
correlation_matrix)
# 创建模型
prob = pulp.LpProblem("MultiYear_Crop_Optimization_Substitute_Complement", pulp.LpMaximize)
# 决策变量(包括替代和互补的决策变量) crop_vars = {}
for year in range(2024, 2031):
crop_vars[year] = pulp.LpVariable.dicts(f"CropArea_ {year}",
[(crop, land) for crop in data['作物名称'].unique() for land
in ['平旱地', '梯田', ' 山坡地', '水浇地', '普通大棚', '智慧大棚']], lowBound=0, cat='Continuous')
# 替代性约束条件
for year in range(2024, 2031):
for land in ['平旱地', '梯田', ' 山坡地', '水浇地']:
prob += crop_vars[year][(' 小 麦 ', land)] + crop_vars[year][(' 玉 米 ', land)] <= total_land / 2, f"Substitute_Constraint_ {year}_ {land}"
# 互补性约束条件
for year in range(2024, 2031):
for land in ['平旱地', '梯田', ' 山坡地']: if year > 2024:
prob += crop_vars[year][('豆类', land)] * 1.1 <= crop_vars[year - 1][('其他作
物', land)], f"Complement_Constraint_ {year}_ {land}"
# 目标函数
for year in range(2024, 2031):
for crop in data['作物名称'].unique():
for land in ['平旱地', '梯田', ' 山坡地', '水浇地', '普通大棚', '智慧大棚']:
sale_price = data.loc[data['作物名称'] == crop, '销售单价/(元/斤)'].mean()
yield_per_acre = data.loc[data['作物名称'] == crop, '亩产量/斤'].mean()
cost_per_acre = data.loc[data['作物名称'] == crop, '种植成本/(元/亩)'].mean()
# 销售量 、价格和成本考虑相关性
scenario_index = np.random.choice(num_scenarios)
sale_volume = scenarios[scenario_index][0] # 销量波动
sale_price = sale_price * scenarios[scenario_index][1] # 价格波动
cost_per_acre = cost_per_acre * scenarios[scenario_index][2] # 成本波动
# 收益计算
profit = (sale_volume * yield_per_acre * sale_price) - cost_per_acre
prob += pulp.lpSum(crop_vars[year][(crop, land)] * profit),
f"Profit_ {year}_ {crop}_ {land}"
# 求解问题 prob.solve()
# 保存结果到 result3.xlsx
template = pd.read_excel('result2.xlsx') for year in range(2024, 2031):
template[f' 最 优 种 植 面 积 _ {year}'] = template.apply(lambda row: crop_vars[year].get((row['作物名称'], row['地块类型']), 0), axis=1)
template.to_excel('result3.xlsx', index=False)
print("最优种植方案已生成,并保存为 result3.xlsx")
# 比较分析
# 对比问题 2 和问题 3 的结果,通过统计分析比较两者的收益 、种植面积变化
result2 = pd.read_excel('result2.xlsx') result3 = pd.read_excel('result3.xlsx')
# 对比两种方案的总收益
result2_profit = result2[['最优种植面积_2024', '最优种植面积_2025']].sum().sum() # 计算总收益
result3_profit = result3[['最优种植面积_2024', '最优种植面积_2025']].sum().sum()
print(f" 问题 2 的总收益: {result2_profit}") print(f" 问题 3 的总收益: {result3_profit}")