公众号:尤而小屋
编辑:Peter
作者:Peter
大家好,我是Peter~
今天给大家分享一个时间序列预测神器Prophet的简易入门教程。
什么是Prophet
Prophet是一种基于加法模型的时间序列预测工具,由Facebook的数据科学团队开发。它可以处理时间序列数据中的多种复杂性,包括趋势变化、季节性变化以及节假日效应等。
官网地址:https://facebook.github.io/prophet/docs/quick_start.html#python-api

在Prophet中,时间序列被分解为多个组成部分,包括趋势、季节性、节假日效应和误差项。这些组成部分可以分别进行建模和预测,然后将它们组合起来得到最终的预测结果。
Prophet的主要优点是易于使用和可解释性强。它提供了一种简单的接口,可以通过几行代码来训练和预测时间序列模型。同时,它还提供了丰富的可视化工具,可以帮助用户理解模型的行为和性能。
Prophet安装
Github官方地址:https://github.com/facebook/prophet
先安装prophet包:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple prophet
Windows系统中一次性安装成功。如果有安装失败,需要自行百度下。
导入库
import numpy as np
import pandas as pd
import os
import datetime
import time
import re
np.random.seed(42)
import plotly_express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import matplotlib.pyplot as plt
%matplotlib inline
# 设置支持中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置图像标题字体
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set_theme(style="darkgrid")
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.tsa.stattools import adfuller
from sklearn.metrics import r2_score,mean_squared_error,mean_squared_log_error
from prophet import Prophet
import warnings
warnings.filterwarnings('ignore')
读取数据
df = pd.read_csv("https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv")
# df.to_csv("data.csv",index=False) # 保存到本地
df.head()

该数据是佩顿.曼宁(美式橄榄球运动员)的维基百科的每日访问量的时间序列数据。
Prophet的输入数据一般都是两列:ds和y。其中,ds表示时间数据,y是我们希望预测的数值变量。
数据基本信息
df["ds"].min(),df["ds"].max()
(‘2007-12-10’, ‘2016-01-20’)
df["y"].min(),df["y"].max()
(5.26269018890489, 12.846746888829)
原数据可视化
fig = px.scatter(df,x="ds",y="y")
fig.show()
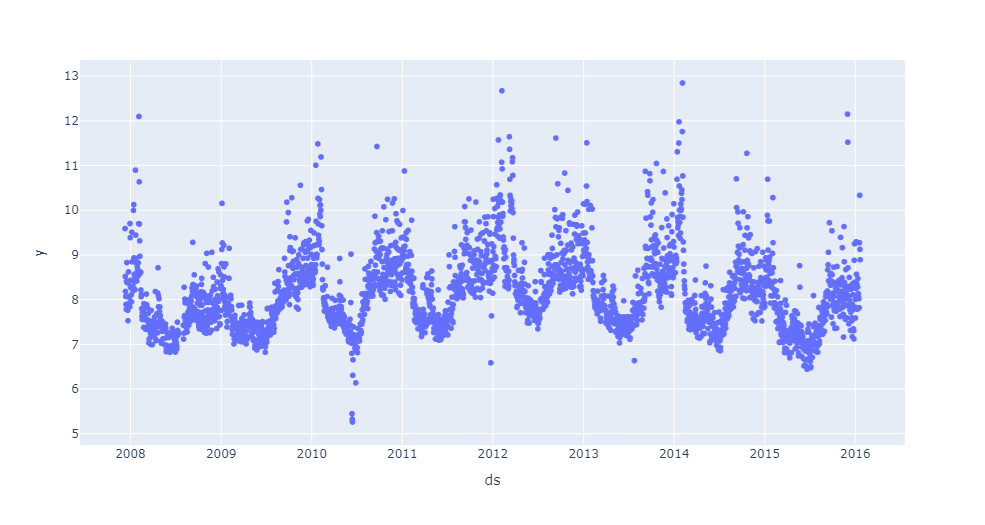
从图像中能够观察到,该数据有良好的周期性(季节性),y值在不断地变化。
数据对数转换
对数据进行对数转换:np.log
df["y"] = np.log(df["y"])
Prophet简易预测
Prophet遵循了sklearn的接口方式,在实例化Prophet对象的基础上可以使用fit方法进行训练,predict进行预测。
fit过程
p = Prophet()
p.fit(df)
<prophet.forecaster.Prophet at 0x78c63111acb0>
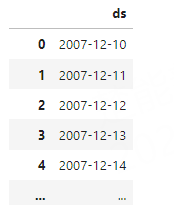
构建预测数据
使用辅助的方法 Prophet.make_future_dataframe构建待预测的数据:
future = p.make_future_dataframe(periods=365) # 指定预测一年的数据
future
predict过程
forecast = p.predict(future)
forecast.head()


forecast.columns # 生成预测数据的全部字段信息
Index(['ds', 'trend', 'yhat_lower', 'yhat_upper', 'trend_lower', 'trend_upper',
'additive_terms', 'additive_terms_lower', 'additive_terms_upper',
'weekly', 'weekly_lower', 'weekly_upper', 'yearly', 'yearly_lower',
'yearly_upper', 'multiplicative_terms', 'multiplicative_terms_lower',
'multiplicative_terms_upper', 'yhat'],
dtype='object')
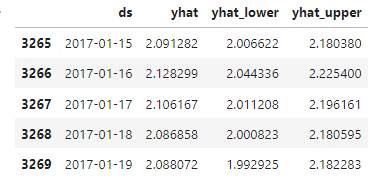
选取部分我们关注的字段:原始ds、预测值yhat、预测最低值yhat_lower、预测最高值yhat_upper
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
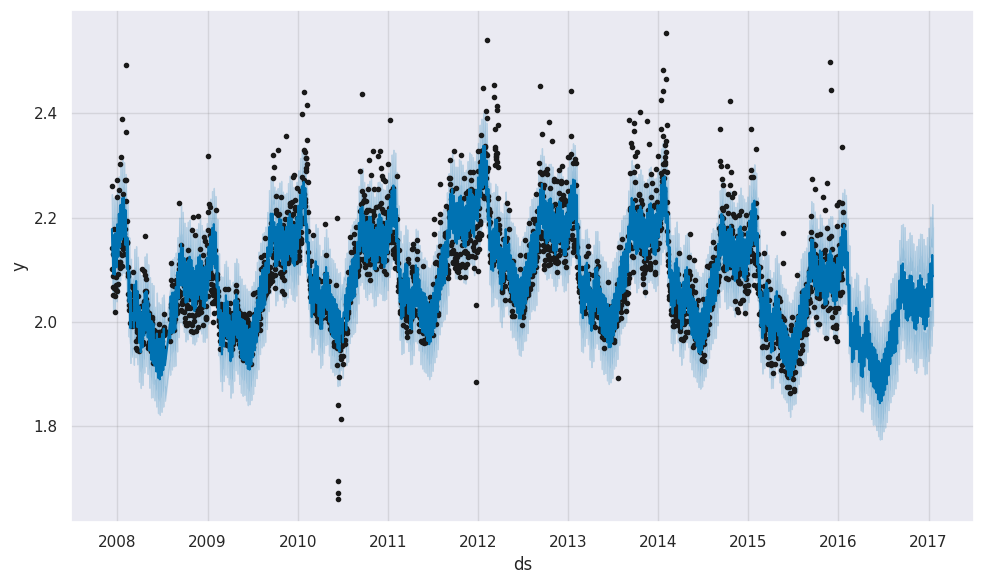
预测可视化
调用plot方法进行预测结果的可视化:
p.plot(forecast)
plt.show()
预测成分分析
调用plot_components方法
forecast.columns
Index(['ds', 'trend', 'yhat_lower', 'yhat_upper', 'trend_lower', 'trend_upper',
'additive_terms', 'additive_terms_lower', 'additive_terms_upper',
'weekly', 'weekly_lower', 'weekly_upper', 'yearly', 'yearly_lower',
'yearly_upper', 'multiplicative_terms', 'multiplicative_terms_lower',
'multiplicative_terms_upper', 'yhat'],
dtype='object')
p.plot_components(forecast)
plt.show()

可以看到每个成分的变化趋势。图1是根据trend画出来的,图2是根据weekly画出来的,图3是根据yearly画出来的。
在加法模型中,有如下关系式:
forecast['additive_terms'] = forecast['weekly'] + forecast['yearly']
forecast['yhat'] = forecast['trend'] + forecast['additive_terms']
forecast['yhat'] = forecast['trend'] +forecast['weekly'] + forecast['yearly']
如果存在假期因素holidays,则有:
forecast['yhat'] = forecast['trend'] +forecast['weekly'] + forecast['yearly'] + forecast['holidays']