目录
前言
超分数据如何构造呢?
Real-ESRGAN
1. 高质量细节重建
2. 真实感和自然度
3. 处理真实世界数据
4. 多尺度和多种类型的输入
5. 视觉效果的提升
超分如何退化
1. 模糊处理
2. 噪声处理
3. 压缩失真
4. 训练数据的退化模拟
2.经典退化模型◆退化过程全览
Real esrgan 实践开始
代码环境安装
数据构造
训练Real esrgan网络
第一步是训练real esrnet网络
训练Real esrGan
finetune和生成退化数据
前言
大家好,我是cv君,今天给大家重点介绍一下高质量超分方案Real esrgan,他的方案非常有效,我们可以使用他的方案,自己用高效的生成器来做很多高速、高效的超分。为啥呢?因为他的退化方案不错,他是盲超分算法,盲超分是啥意思呢,就是不知道低分辨率LR和高分辨率图像HR关系的。
超分数据如何构造呢?
我们在实际生活中,比如你手机是2k的图,你想训练个4倍超分,变成8K分辨率的图,你该怎么构造数据呢?你只有相机拍的2K图,相当于你没有GT咋训练呢,一般情况下,学术界很简单的通过下采样方式,将图像变小成一半或1/4等,这样就得到了小图当LR训练,原图当HR监督,这样就得到了一般的训练数据:DIV2K和Filcker数据等,大量的超分数据,都是这样退化的,那么他们的退化方式是:(双三次)下采样模糊退化,那么网络在学什么呢?学反过来的过程,双三次上采样变清晰进化。这样很明显有个问题:咱实际使用时,输入的图,并不是这么糊(双三次退化后的图像,比较糊,信息丢失严重,尤其是低频都没了),那实际用怎么会好呢?
所以,数据进化方式出现了:还是举例,你只有相机拍的2K图,如果你想变成8K超分模型,那么是不是我自己用方法构造出一张8K的图即可。咋构造呢,世界上还没有这样的方法吧。——1、用大模型超分,用好一些的超分模型,不就可以变大又清晰了吗,来做GT,这样的好处是,可以得到像素对齐的HR,不会移动图像位置,但是,有个缺点,就是你再用网络学,不就是相当于你的网络在学刚刚这个大超分网络的效果了吗,效果永远无法超越他。所以在这个进化方式完成后,需要对你认为不好的大模型生成的8K图,进行调整,比如你觉得噪声多了,用ps等减小一点,或者是锐度不够,就用ps加锐,注意,加锐可能噪声又会增加。

比如你可以用real-esrgan等模型进行超分你自己的数据集,然后得到高清的大图,这样就得到了LR(你的原图)和HR(其他大模型超分+调整后的图)然后和你的数据进行训练。
这样获得数据对,还是不够真实,怎样更真实呢,相当于你用两个镜头(一般手机镜头1倍是一个镜头,然后3或者5倍后会切另一个长焦镜头),这样,长焦镜头是光学的力量,是比所有方法都要清晰的。咋做超分数据呢?拿俩相机,(最好焦距是2 、4倍左右)对着同一个地方拍摄,就得到了如下俩图,然后只需要对齐一下数据,即可得到超分的LR和HR:接着对齐数据方式出现了:

如图所示,用105mm焦距的相机和28mm的广角相机,采集同样花圃区域的图像,然后用脚本对齐,或者用手动对齐图像,就得到了HR(105mm长焦的超清晰图像)和用28mm同区域采集到图像(他俩大约差4倍大小,然后稍微缩放成整数,即可训练),光学的力量就是最真实的,那么为啥现在没啥人用呢,数据制造比较麻烦,需要几个真实打算落地的相机,还要不同焦距,有这样的人不多,另外采集完数据,还要对齐,可能焦距不同,还会压缩图像,导致难以对齐,两图像的像素间有偏移,可能难以训练,所以RealSR提供的数据都有像素误差,还专门加了减少像素干扰超分的损失,算一个补丁损失。
除了这些方法外,还有个方法:模糊核估计,在线退化方法,像Real esrgan,就是在线退化:
Real-ESRGAN
Real-ESRGAN(Real Enhanced Super-Resolution Generative Adversarial Network)在图像超分辨率任务中展现了显著的效果和优势。以下是其主要效果的详细介绍:
1. 高质量细节重建
Real-ESRGAN能够在将低分辨率图像提升至高分辨率时,恢复丰富的细节和纹理。它不仅简单地放大图像,而是利用生成对抗网络的能力来生成具有高真实感的细节。这种方法能够在增强图像的分辨率时保持图像的自然外观,减少由于放大而产生的模糊或伪影。
2. 真实感和自然度
与传统的超分辨率方法相比,Real-ESRGAN特别关注生成图像的真实感。通过对抗训练,生成器不断改进其生成的图像,使其更接近于高分辨率原始图像,从而减少了通常见于超分辨率图像的伪影和不自然的细节。这使得Real-ESRGAN在处理真实世界图像时,能够提供更自然、更细腻的结果。
3. 处理真实世界数据
Real-ESRGAN在处理实际应用中的图像时表现优异,包括模糊、噪声和压缩损失等问题。它比许多传统方法更能够应对这些挑战,提供更加清晰和可用的图像。对于历史照片、低分辨率视频帧和其他高噪声图像,Real-ESRGAN能够有效地恢复图像质量。
4. 多尺度和多种类型的输入
Real-ESRGAN具备处理不同尺度和多种类型输入图像的能力。无论是低分辨率的图像、图像压缩损失、还是具有复杂纹理的图像,它都能提供一致且高质量的超分辨率输出。这使得它在各种应用场景中都能够表现良好,包括图像放大、视频增强和细节恢复等。
5. 视觉效果的提升
通过使用Real-ESRGAN,图像的视觉效果得到了显著提升。生成的高分辨率图像在细节、清晰度和色彩再现方面较传统方法有明显优势。这种提升使得Real-ESRGAN在艺术创作、视觉效果增强和图像质量改进等领域具有广泛的应用潜力。
总的来说,Real-ESRGAN通过深度学习和生成对抗网络的创新,提升了超分辨率图像生成的质量和效果,特别在处理实际图像和复杂情况时表现出色。
超分如何退化
Real-ESRGAN在超分辨率过程中处理图像退化的方式主要包括以下几个方面:
1. 模糊处理
在图像退化中,模糊是常见的问题,通常由拍摄条件、镜头质量等因素造成。Real-ESRGAN通过深度学习模型学习到如何从模糊的低分辨率图像中恢复出清晰的细节。这是通过训练生成器对抗判别器,逐步改进图像细节,减少模糊和恢复清晰度来实现的。
2. 噪声处理
图像在采集和传输过程中可能会受到噪声的干扰。Real-ESRGAN能够通过生成对抗网络的训练,识别并去除噪声,同时保留图像中的重要细节。这种处理使得生成的高分辨率图像不仅更清晰,还具有更好的视觉质量。
3. 压缩失真
低分辨率图像常常经历过压缩,导致细节丢失和伪影。Real-ESRGAN利用对抗训练来学习如何修复这些压缩失真,生成的高分辨率图像能够有效去除压缩带来的伪影,恢复图像的自然细节和纹理。
4. 训练数据的退化模拟
为了使Real-ESRGAN在处理实际退化图像时表现更好,训练过程中会使用模拟退化的低分辨率图像进行训练。这些模拟的退化包括不同类型的模糊、噪声和压缩,从而使模型在面对真实图像时能够表现出更好的恢复能力。
通过这些方法,Real-ESRGAN能够有效处理各种退化情况,使得从低分辨率图像生成的高分辨率图像更接近真实、自然的效果。

上图分别为 双三次上采样、ESRGAN、RealSR 和 Real-ESRGAN 的效果。
2.经典退化模型◆退化过程全览
盲 SR 旨在从具有未知和复杂退化的低分辨率图像中恢复高分辨率图像。通常采用经典退化模型来合成低分辨率输入。通常,首先将真实图像 y 与模糊核 k 进行卷积。然后,执行具有比例因子的下采样操作。低分辨率 x 是通过添加噪声 n 获得的。最后,JPEG压缩也被采用,因为它在真实世界的图像中被广泛使用。
其中 D 表示退化过程,退化实现了将清晰图像 y 模糊为 x 的过程。

Real-ESRGAN 中采用的纯合成数据生成。它利用二阶退化过程来模拟更实际的退化,其中每个退化过程采用经典的退化模型。其中列出了模糊、调整大小、噪声和 JPEG 压缩的详细选择。除此之外模型还使用 sinc 滤波器来合成常见的振铃和超调伪影。
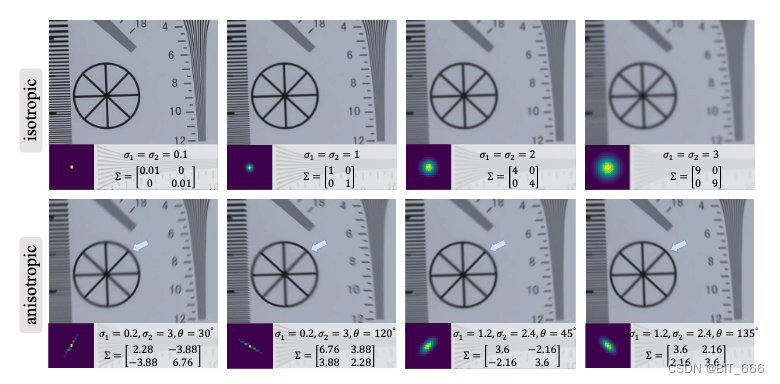
◆K - 高斯滤波
通常将模糊退化建模为具有线性模糊滤波器(内核)的卷积。各向同性和各向异性高斯滤波器是常见的选择。对于内核大小为 2t + 1 的高斯模糊核 k,其 (i, j) ∈ [−t, t] 元素从高斯分布中采样,形式如下:
其中 Σ 是协方差矩阵;C 是空间坐标;N 是归一化常数。协方差矩阵可以进一步表示如下:
其中 σ1 和 σ2 是沿两个主轴的标准差(即协方差矩阵的特征值); θ 是旋转度。当σ1 = σ2时,k 为各向同性高斯模糊核; 否则 k 为各向异性核。
这一步相当于对图像进行了高斯滤波模糊。下图为不同参数下图像的模糊效果:
◆N - 噪声
N 即 Noisy,我们考虑两种常用的噪声类型:1) 加性高斯噪声和 2)泊松噪声。加性高斯噪声的概率密度函数等于高斯分布的概率密度函数。噪声强度由高斯分布的标准差 σ控制。当 RGB 图像的每个通道都有独立的采样噪声时,合成噪声是颜色噪声。我们还通过将相同的采样噪声应用于所有三个通道来合成灰色噪声。泊松噪声遵循泊松分布。它通常用于近似模拟统计量子波动引起的传感器噪声,即在给定曝光水平下感知到的光子数的变化。泊松噪声的强度与图像强度成正比,不同像素的噪声是独立的。
这一步在高斯滤波的基础上为图像增加噪声。下图为不同噪声添加后的效果:
◆ ↓r - Resize
这一步其实代表 Downsampling 即下采样。下采样是合成 SR 中低分辨率图像的基本操作。更一般地说,我们考虑下采样和上采样,即调整大小操作。有几种调整算法——最近邻插值、区域大小调整、双线性插值和双三次插值。不同的调整大小操作会带来不同的效果——有些会产生模糊的结果,而有些可能会产生过锐化的图像,带有超调伪影。为了包含更多样化和复杂的调整大小效果,我们考虑了上述选择的随机调整大小操作。由于最近邻插值引入了错位问题,我们排除了它,只考虑区域、双线性和双三次运算。
↓r
这一步是在高斯滤波后对图像进行下采样。下图为下采样算法和上采样算法的不同组合的影响。图像首先被四倍的比例因子下采样,然后上采样到其原始大小:

◆jpeg - 压缩
JPEG 压缩是一种常用的数字图像有损压缩技术。它首先将图像转换为 YCbCr 颜色空间,并对色度通道进行下采样。然后将图像分成 8 × 8 个块,每个块用二维离散余弦变换 DCT 进行变换,然后对 DCT 系数进行量化。JPEG 压缩通常会引入不愉快的块伪影。压缩图像的质量由质量因子 q ∈ [0, 100] 决定,其中较低的 q 表示更高的压缩比和更差的质量。
上述操作代表对下采样且添加噪声的图像进行 jpeg 压缩。下图为 jpeg 压缩对图像画质的影响:

高阶退化模型
在采用上述经典退化模型来合成训练对时,训练后的模型确实可以处理一些真实样本。然而,它仍然不能解决现实世界中的一些复杂的退化,特别是未知的噪声和复杂的伪影。左侧的真实世界图片在经典退化模型的合成数据训练修正后可以解决,然后右侧更为复杂的真实世界图像的噪声却被放大了:
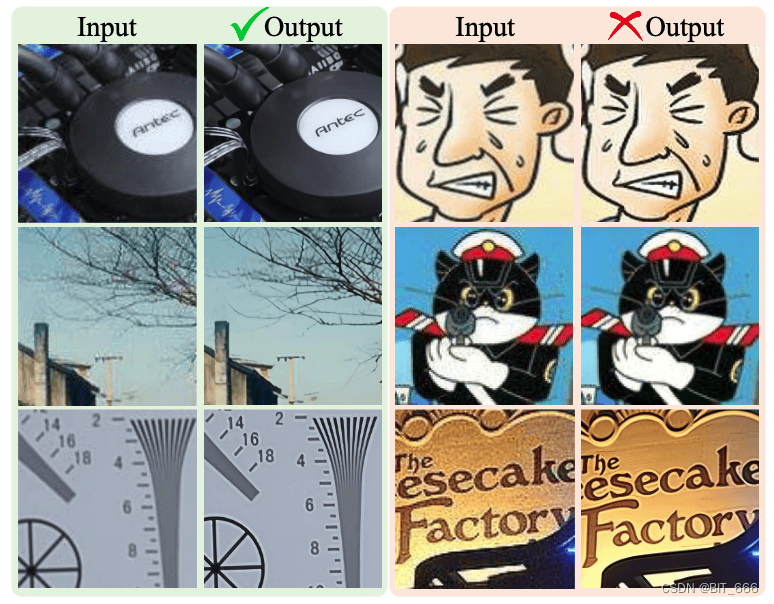
这是因为合成的低分辨率图像仍然与真实退化图像有很大的差距。因此,我们将经典的退化模型扩展到高阶退化过程,以模拟更实际的退化。经典的退化模型只包含一个固定的基本退化的数量,可以看作是一阶建模。然而,现实生活中的退化过程是相当多样化的,通常包括一系列程序,包括相机的成像系统、图像编辑、互联网传输等。
例如,当我们想要从互联网上恢复低质量的图像下载时,其潜在的退化涉及不同退化过程的复杂组合。具体来说,原始图像可能多年前用手机拍摄,这不可避免地包含相机模糊、传感器噪声、低分辨率和 JPEG 压缩等退化。然后使用锐化和调整大小操作对图像进行编辑,带来超调和模糊伪影。之后,它被上传到一些社交媒体应用程序,这引入了进一步的压缩和不可预测的噪音。随着数字传输也将带来伪影,当图像在互联网上传播多次时,这个过程变得更加复杂。
这种复杂的恶化过程不能用经典的一阶模型建模。因此,我们提出了一个高阶退化模型。n 阶模型涉及 n 个重复退化过程,其中每个退化过程采用具有相同过程但超参数不同的经典退化模型。请注意,这里的“高阶”与数学函数中使用的“高阶”不同。它主要是指同一操作的实现时间。但是我们强调高阶退化过程是关键,这表明并非所有打乱的退化都是必要的。为了使图像分辨率保持在合理的范围内,将式(1)中的下采样操作替换为随机调整大小操作。
根据经验,我们采用了二阶退化过程,因为它可以在保持简单性的同时解决大多数实际情况。下图描述了我们的纯合成数据生成管道的整体管道:
这一系列的 D 就模拟了生活中一张颠沛流体的图片的传递过程。值得注意的是,改进的高阶退化过程并不完美,不能覆盖现实世界中的整个退化空间。相反,它仅通过修改数据合成过程来扩展先前盲 SR 方法的可解退化边界。
环形和超调伪影
环形伪影经常出现在图像中急剧过渡附近的虚假边缘。他们在视觉上看起来像边缘附近的波段或"幽灵"。超调伪影通常与振铃伪影相结合,表现为边缘过渡处的跳跃增加。这些伪影的主要原因是信号在没有高频的情况下是带限的。这些现象非常常见,通常由锐化算法、JPEG压缩等产生。下图显示了一些遭受振铃和超调伪影的真实样本:
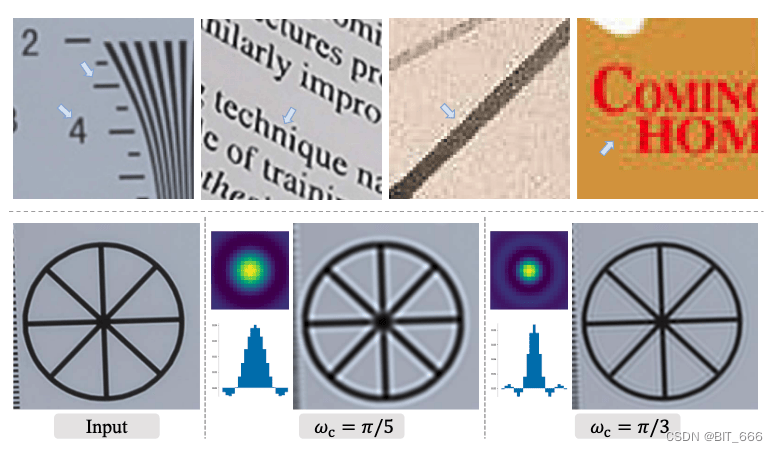
上图为存在振铃和超调伪影的真实样本。下图为 sinc 内核的示例 [kernel= 21] 和相应的过滤图像,可以看到图像经过 sinc 内核滤波会出现真实世界类似的振铃和超调伪影的状态。sinc 滤波器,这是一种理想化的滤波器,可以切断高频,以合成训练对的振铃和超调伪影。sinc 滤波器内核可以表示为:
模型在两个地方采用了sinc滤波器:模糊过程和合成的最后一步。last sinc 滤波器和 JPEG 压缩的顺序被随机交换以覆盖更大的退化空间,因为一些图像可能首先被过度锐化(具有过冲伪影),然后具有JPEG压缩;而一些图像可以首先进行JPEG压缩,然后进行锐化操作。
Real esrgan 实践开始
我们可以通过real esrgan官方代码训练,也可以通过basicsr框架实现,为了后续经常使用,我们这里以basicsr框架为例子:
代码环境安装
1、下载basicsr代码
git clone https://github.com/XPixelGroup/BasicSR.git然后就按照readme 安装即可:
如果有符合版本的torch了,就注释掉

如果自己之前安装过basicsr,就卸载掉,或者重开一个conda环境执行:
在根目录下执行python setup.py develop
如果卡住某个库安装比较慢,就ctrl c,手动自己用清华源安装:-i https;//pypi.tuna.tsinghua.edu.cn/simple
然后再继续setup
直到成功后,能在pip list里看到basicsr版本号
数据构造
然后就可以了,接下来就是数据构造,我上传了数据和代码,大家可以直接使用,数据可以用div2k也可以多用几个:
Real-ESRGAN/docs/Training_CN.md at master · xinntao/Real-ESRGAN · GitHub
这里面用了3个数据,我们简单些,只用div2k,效果要好,就多用一些。
然后按照readme切割数据成小图,(我们数据切过了,不用再切)

这图就是把原始的div HR和双三次降采样的LR图,同时切割成小图的代码,一块块变小。方便训练,我们的图 就是切割好了的。
训练Real esrgan网络
第一步是训练real esrnet网络
这个就是在先让网络学习超分的过程,是一个正常的网络,学完后,超分分数会高一些,但是还是有些模糊的,因为还没经过Gan网络。这个过程中,学习率稍微高一些。
大家可以调整一下options/train/esrnet X4 的yml,也可以用我的:
要生成个txt,非常简单:

然后呢,就在下面通过这俩来索引图像:txt里写的是文件名,然后前面的话,结合咱dataroot_gt,能拼接成你的图像路径即可。我们只需要HR,不用LR,因为他会在线退化LR。模拟放小、加噪声、加模糊等。
dataroot_gt: /home/zxx/AF/expandAi/SESR/data/DIV2K/DIV2K_train_HR_Sub
meta_info: /home/zxx/AF/expandAi/SESR/data/DIV2K/meta_info_DIV2K800sub_GT.txt# general settings
name: train_RealESRNetx4plus_1000k_B12G4
model_type: RealESRNetModel
scale: 4
num_gpu: auto # auto: can infer from your visible devices automatically. official: 4 GPUs
manual_seed: 0
# ----------------- options for synthesizing training data in RealESRNetModel ----------------- #
gt_usm: True # USM the ground-truth
# the first degradation process
resize_prob: [0.2, 0.7, 0.1] # up, down, keep
resize_range: [0.15, 1.5]
gaussian_noise_prob: 0.5
noise_range: [1, 30]
poisson_scale_range: [0.05, 3]
gray_noise_prob: 0.4
jpeg_range: [30, 95]
# the second degradation process
second_blur_prob: 0.8
resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
resize_range2: [0.3, 1.2]
gaussian_noise_prob2: 0.5
noise_range2: [1, 25]
poisson_scale_range2: [0.05, 2.5]
gray_noise_prob2: 0.4
jpeg_range2: [30, 95]
gt_size: 256
queue_size: 180
# dataset and data loader settings
datasets:
train:
name: DF2K+OST
type: RealESRGANDataset
dataroot_gt: /home/zxx/AF/expandAi/SESR/data/DIV2K/DIV2K_train_HR_Sub
meta_info: /home/zxx/AF/expandAi/SESR/data/DIV2K/meta_info_DIV2K800sub_GT.txt
io_backend:
type: disk
blur_kernel_size: 21
kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
sinc_prob: 0.1
blur_sigma: [0.2, 3]
betag_range: [0.5, 4]
betap_range: [1, 2]
blur_kernel_size2: 21
kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
sinc_prob2: 0.1
blur_sigma2: [0.2, 1.5]
betag_range2: [0.5, 4]
betap_range2: [1, 2]
final_sinc_prob: 0.8
gt_size: 256
use_hflip: True
use_rot: False
# data loader
num_worker_per_gpu: 5
batch_size_per_gpu: 12
dataset_enlarge_ratio: 1
prefetch_mode: ~
# Uncomment these for validation
# val:
# name: validation
# type: PairedImageDataset
# dataroot_gt: path_to_gt
# dataroot_lq: path_to_lq
# io_backend:
# type: disk
# network structures
network_g:
type: RRDBNet
num_in_ch: 3
num_out_ch: 3
num_feat: 64
num_block: 23
num_grow_ch: 32
# path
path:
# pretrain_network_g: ~
pretrain_network_g: /home/zxx/AF/expandAi/BasicSR/experiments/experiments/pretrained_models/ESRGAN_SRx4_DF2KOST_official-ff704c30.pth
param_key_g: params_ema
strict_load_g: true
resume_state: ~
# training settings
train:
ema_decay: 0.999
optim_g:
type: Adam
lr: !!float 2e-4
weight_decay: 0
betas: [0.9, 0.99]
scheduler:
type: MultiStepLR
milestones: [1000000]
gamma: 0.5
total_iter: 1000000
warmup_iter: -1 # no warm up
# losses
pixel_opt:
type: L1Loss
loss_weight: 1.0
reduction: mean
# Uncomment these for validation
# validation settings
# val:
# val_freq: !!float 5e3
# save_img: True
# metrics:
# psnr: # metric name
# type: calculate_psnr
# crop_border: 4
# test_y_channel: false
# logging settings
logger:
print_freq: 100
save_checkpoint_freq: !!float 5e3
use_tb_logger: true
wandb:
project: ~
resume_id: ~
# dist training settings
dist_params:
backend: nccl
port: 29500
如果需要验证看得分,就把valid取消注释。
然后下载和使用pre train模型:Real-ESRGAN/docs/Training_CN.md at master · xinntao/Real-ESRGAN · GitHub
这里面有,直接下载一下即可,当然不用也可以,就是拟合慢一些。pretrain_network_g改成自己的路径。打开上面的链接,教程训练。

然后训练完后,生成网络训练好了,就会在保存的路径里得到训好的pth,然后把这个pth路径复制一下,待会要训练gan了
第二步训练Real esrgan 对抗网络
pretrain_network_g: /home/zxx/AF/expandAi/BasicSR/experiments/experiments/pretrained_models/ESRGAN_SRx4_DF2KOST_official-ff704c30.pth
咱把刚刚训练好的net模型路径改掉我这个

然后可以不验证,验证就把div2k的lr hr都传进来。
完整的gan yml,大家改下路径即可:
# general settings
name: train_RealESRGANx4plus_400k_B12G4
model_type: RealESRGANModel
scale: 4
num_gpu: auto # auto: can infer from your visible devices automatically. official: 4 GPUs
manual_seed: 0
# ----------------- options for synthesizing training data in RealESRGANModel ----------------- #
# USM the ground-truth
l1_gt_usm: True
percep_gt_usm: True
gan_gt_usm: False
# the first degradation process
resize_prob: [0.2, 0.7, 0.1] # up, down, keep
resize_range: [0.15, 1.5]
gaussian_noise_prob: 0.5
noise_range: [1, 30]
poisson_scale_range: [0.05, 3]
gray_noise_prob: 0.4
jpeg_range: [30, 95]
# the second degradation process
second_blur_prob: 0.8
resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
resize_range2: [0.3, 1.2]
gaussian_noise_prob2: 0.5
noise_range2: [1, 25]
poisson_scale_range2: [0.05, 2.5]
gray_noise_prob2: 0.4
jpeg_range2: [30, 95]
gt_size: 256
queue_size: 180
# dataset and data loader settings
datasets:
train:
name: DF2K+OST
type: RealESRGANDataset
dataroot_gt: /home/zxx/AF/expandAi/SESR/data/DIV2K/DIV2K_train_HR_Sub
meta_info: /home/zxx/AF/expandAi/SESR/data/DIV2K/meta_info_DIV2K800sub_GT.txt
io_backend:
type: disk
blur_kernel_size: 21
kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
sinc_prob: 0.1
blur_sigma: [0.2, 3]
betag_range: [0.5, 4]
betap_range: [1, 2]
blur_kernel_size2: 21
kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
sinc_prob2: 0.1
blur_sigma2: [0.2, 1.5]
betag_range2: [0.5, 4]
betap_range2: [1, 2]
final_sinc_prob: 0.8
gt_size: 256
use_hflip: True
use_rot: False
# data loader
num_worker_per_gpu: 5
batch_size_per_gpu: 12
dataset_enlarge_ratio: 1
prefetch_mode: ~
# Uncomment these for validation
val:
name: validation
type: PairedImageDataset
dataroot_gt: /home/zxx/AF/expandAi/SESR/data/DIV2K/DIV2K_valid_HR_Sub
dataroot_lq: /home/zxx/AF/expandAi/SESR/data/DIV2K/DF2K_valid_LR_bicubic_X4_Sub
io_backend:
type: disk
# network structures
network_g:
type: RRDBNet
num_in_ch: 3
num_out_ch: 3
num_feat: 64
num_block: 23
num_grow_ch: 32
network_d:
type: UNetDiscriminatorSN
num_in_ch: 3
num_feat: 64
skip_connection: True
# path
path:
# use the pre-trained Real-ESRNet model
pretrain_network_g: /home/zxx/AF/expandAi/BasicSR/experiments/experiments/pretrained_models/ESRGAN_SRx4_DF2KOST_official-ff704c30.pth
param_key_g: params_ema
strict_load_g: true
resume_state: ~
# training settings
train:
ema_decay: 0.999
optim_g:
type: Adam
lr: !!float 1e-4
weight_decay: 0
betas: [0.9, 0.99]
optim_d:
type: Adam
lr: !!float 1e-4
weight_decay: 0
betas: [0.9, 0.99]
scheduler:
type: MultiStepLR
milestones: [400000]
gamma: 0.5
total_iter: 400000
warmup_iter: -1 # no warm up
# losses
pixel_opt:
type: L1Loss
loss_weight: 1.0
reduction: mean
# perceptual loss (content and style losses)
perceptual_opt:
type: PerceptualLoss
layer_weights:
# before relu
'conv1_2': 0.1
'conv2_2': 0.1
'conv3_4': 1
'conv4_4': 1
'conv5_4': 1
vgg_type: vgg19
use_input_norm: true
perceptual_weight: !!float 1.0
style_weight: 0
range_norm: false
criterion: l1
# gan loss
gan_opt:
type: GANLoss
gan_type: vanilla
real_label_val: 1.0
fake_label_val: 0.0
loss_weight: !!float 1e-1
net_d_iters: 1
net_d_init_iters: 0
# Uncomment these for validation
# validation settings
val:
val_freq: !!float 3e3
save_img: True
metrics:
psnr: # metric name
type: calculate_psnr
crop_border: 4
test_y_channel: false
# logging settings
logger:
print_freq: 100
save_checkpoint_freq: !!float 5e3
use_tb_logger: true
wandb:
project: ~
resume_id: ~
# dist training settings
dist_params:
backend: nccl
port: 29500
然后开始训练,训练就去改下路径即可

然后就可以开始训练了(训练net要一天,训练gan也是),训练gan的学习率很小,相当于简单finetune。
network_d:
type: UNetDiscriminatorSN
num_in_ch: 3
num_feat: 64
skip_connection: True
# path
path:
# use the pre-trained Real-ESRNet model
pretrain_network_g: /home/zxx/AF/expandAi/BasicSR/experiments/experiments/pretrained_models/ESRGAN_SRx4_DF2KOST_official-ff704c30.pth
param_key_g: params_ema
strict_load_g: true
resume_state: ~
这里就是D模型,鉴别器:discrimination模型,不断的用鉴别器模型来判断生成的图像是不是真的,不是的话,就增加鉴别损失,最后把损失backward,激励生成模型继续优化。
然后默认是把pretrain_network_g的pth(刚刚训练好的net模型)放过来。
然后训练gan模型就是,用了lr比较小的,慢慢对抗训练
训练完后会得到gan的模型。也要一两天。大家感受下过程即可
finetune和生成退化数据
然后呢,前面提到,咱们real esrgan,你输入一张图,他可以给你输出一张LR图,你就可以得到训练数据了:HR是你原图,LR是gan退化出来的,这样搞个几百张即可训练。
那他是怎么生成退化数据的呢,因为他训练时,会不需要LR的,只需要你给他HR就能训练,咱们上面说过了对吧。
好,那么众所周知,训练超分必定是需要LR 和HR的,就算是real esrgan在线生成,也会生成,把这个结果保存出来即可。他放小、加噪声加模糊的图,就是退化图。
文档里有说怎么弄,应该是用更小学习率训练你的HR,然后保存中间结果做LR吧,也可能是直接网络推理,把中间的退化图保存。

然后我再basicsr里好像没找到怎么把退化的LR图像保存下来的接口?
那很简单,找源码:

如图,我们可以看到他是如何构造LR的,就是把HR拿下来,做一下resize、做一下随机加噪声、做一下随机模糊,然后就得到了小图,self.lq :
# clamp and round
self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
# random crop
gt_size = self.opt['gt_size']
(self.gt, self.gt_usm), self.lq = paired_random_crop([self.gt, self.gt_usm], self.lq, gt_size,
self.opt['scale'])
# training pair pool
self._dequeue_and_enqueue()
# sharpen self.gt again, as we have changed the self.gt with self._dequeue_and_enqueue
self.gt_usm = self.usm_sharpener(self.gt)
self.lq = self.lq.contiguous() # for the warning: grad anself.lq 是从out变量转来的,那我们看看退化过程,可以看到怎么加的噪声、模糊:
@torch.no_grad()
def feed_data(self, data):
"""Accept data from dataloader, and then add two-order degradations to obtain LQ images.
"""
if self.is_train and self.opt.get('high_order_degradation', True):
# training data synthesis
self.gt = data['gt'].to(self.device)
self.gt_usm = self.usm_sharpener(self.gt)
self.kernel1 = data['kernel1'].to(self.device)
self.kernel2 = data['kernel2'].to(self.device)
self.sinc_kernel = data['sinc_kernel'].to(self.device)
ori_h, ori_w = self.gt.size()[2:4]
# ----------------------- The first degradation process ----------------------- #
# blur
out = filter2D(self.gt_usm, self.kernel1)
# random resize
updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
if updown_type == 'up':
scale = np.random.uniform(1, self.opt['resize_range'][1])
elif updown_type == 'down':
scale = np.random.uniform(self.opt['resize_range'][0], 1)
else:
scale = 1
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, scale_factor=scale, mode=mode)
# add noise
gray_noise_prob = self.opt['gray_noise_prob']
if np.random.uniform() < self.opt['gaussian_noise_prob']:
out = random_add_gaussian_noise_pt(
out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
else:
out = random_add_poisson_noise_pt(
out,
scale_range=self.opt['poisson_scale_range'],
gray_prob=gray_noise_prob,
clip=True,
rounds=False)
# JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
out = self.jpeger(out, quality=jpeg_p)
# ----------------------- The second degradation process ----------------------- #
# blur
if np.random.uniform() < self.opt['second_blur_prob']:
out = filter2D(out, self.kernel2)
# random resize
updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
if updown_type == 'up':
scale = np.random.uniform(1, self.opt['resize_range2'][1])
elif updown_type == 'down':
scale = np.random.uniform(self.opt['resize_range2'][0], 1)
else:
scale = 1
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(
out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
# add noise
gray_noise_prob = self.opt['gray_noise_prob2']
if np.random.uniform() < self.opt['gaussian_noise_prob2']:
out = random_add_gaussian_noise_pt(
out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
else:
out = random_add_poisson_noise_pt(
out,
scale_range=self.opt['poisson_scale_range2'],
gray_prob=gray_noise_prob,
clip=True,
rounds=False)
# JPEG compression + the final sinc filter
# We also need to resize images to desired sizes. We group [resize back + sinc filter] together
# as one operation.
# We consider two orders:
# 1. [resize back + sinc filter] + JPEG compression
# 2. JPEG compression + [resize back + sinc filter]
# Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
if np.random.uniform() < 0.5:
# resize back + the final sinc filter
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
out = filter2D(out, self.sinc_kernel)
# JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
out = torch.clamp(out, 0, 1)
out = self.jpeger(out, quality=jpeg_p)
else:
# JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
out = torch.clamp(out, 0, 1)
out = self.jpeger(out, quality=jpeg_p)
# resize back + the final sinc filter
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
out = filter2D(out, self.sinc_kernel)
推理
推理就很简单了,直接运行inference即可:

总结
Real eargan就这样,大家后续联系我给百度网盘给数据代码啥的。比较大,还没上传完。
联系cv君,zxx15277368495z