0 前言
本文将以**分布式系统的基本组成为出发点,详细探讨分布式系统的发展历程;逐步展开到分布式系统构成的核心要素,分析这些核心要素会对系统造成怎样的影响、以及影响的不同表现形式;最后探讨如何构建基本可用的分布式系统**,合理利用分布式领域已有的思想、算法、工具及中间件,设计出符合可用性/一致性要求的分布式系统。
1 什么是分布式系统
**「分布式系统 Distributed System」**通常指代一种通过网络连接多个计算机节点、并以协同工作和共享资源的计算系统;它们能够共同完成任务,就像个单一的系统一样对外提供服务。
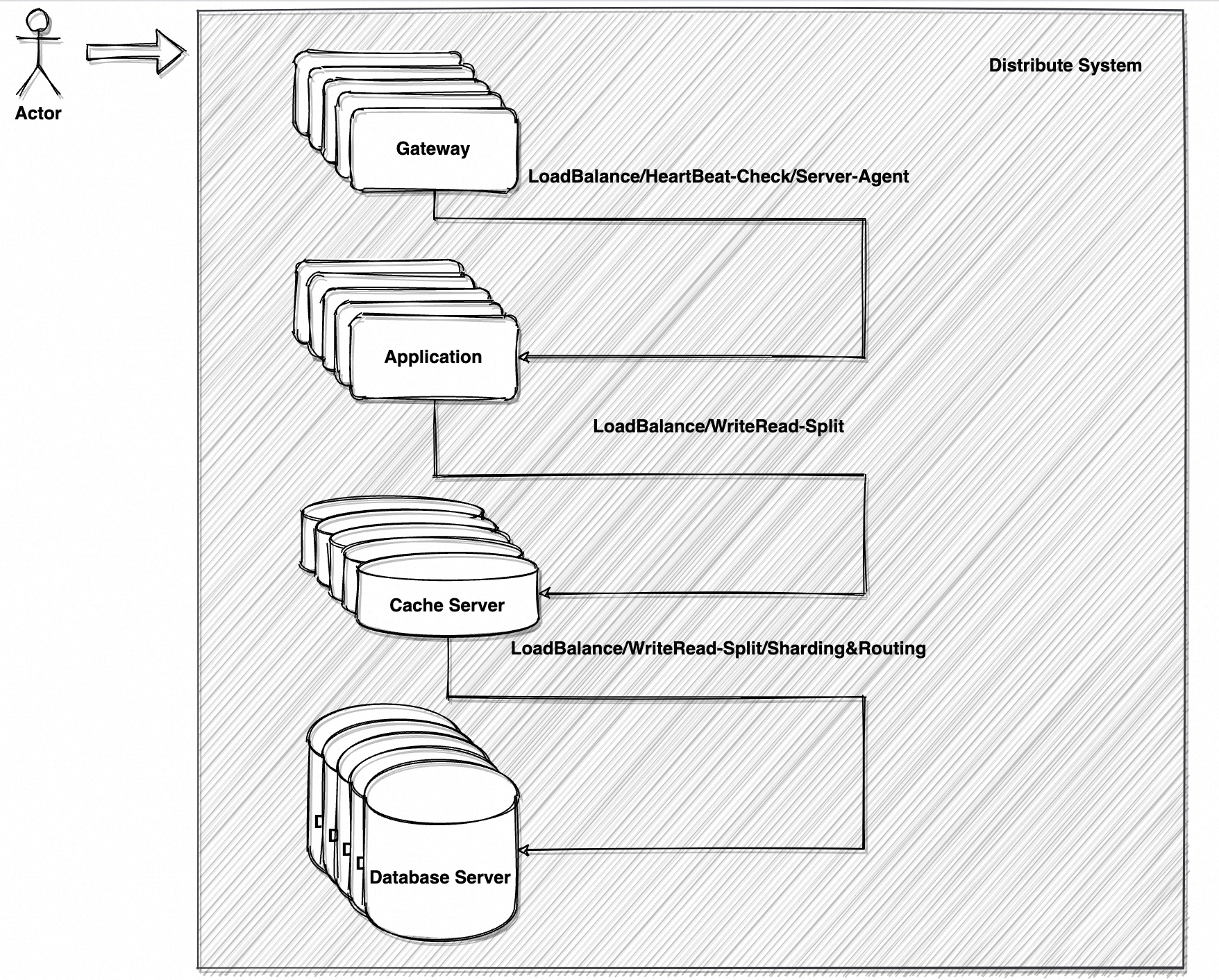
如图 1 是经典的分布式系统架构,系统通常如此构成:
- 通用网关 Gateway:将请求路由到对应的应用服务器上。出于性能、可用性、扩展性的考量,也可能负责基本的参数/安全检查(Check/Filter)、负载均衡(Load Balance)、服务心跳检查(Heartbeat Check)、**正向/反向代理(Agent)**等。
- 应用服务 Application:真正提供服务的应用服务器。应用通常会以水平扩展和垂直扩展两种基本路线,分别进行分布式集群构建(Cluster)/扩容(Scale up),和微服务拆分(Split)、升级机器配置。
- 缓存服务 Cache:提供高性能的内存读写服务。由于内存读写的极低延迟(微秒级,不超过毫秒级)以及磁盘读写相对差的性能表现(毫秒级,可能会达到秒级),缓存成了高并发系统最佳的提升性能手段。通常前置于数据库读写操作。
- 数据库服务 Database:提供可靠的事务性磁盘读写服务。以关系型数据库 RDBMS(Relational Database Management System)为代表所提供的事务、表连接、索引、约束等高级特性,使得数据库服务成了可靠且全面的代名词,也成了持久化存储的基石。
整个分布式系统以整体向用户提供服务,如单一的系统一般。
分布式系统的所有组成部分也可以是分布式系统,例如图 1 中的 Gateway,可能有 N 个 Gateway 实例提供相同的网关服务,俗称「集群 Cluster」;Application 也可以由 M 个提供不同类型服务(如垂直拆分为用户服务、交易服务、商品服务等)的集群组成,俗称「微服务集群 Micro-Service Cluster」;Database 可以以主从集群、分库分表等方式,拆分成 N 个数据库实例构成的分布式数据库服务。
它们无一例外都履行了一致的承诺——以网络通讯的方式联结多个服务器,以一个整体向外界提供服务,且外界基本无感知。
2 分布式系统演进
分布式系统的诞生符合事物发展的客观规律。随着对于系统性能、可用、扩展等指标的需求日益提高,系统架构的演进历程开始运转。
最初整个系统仅由一台机器组成,即「单体架构 Standalone」。
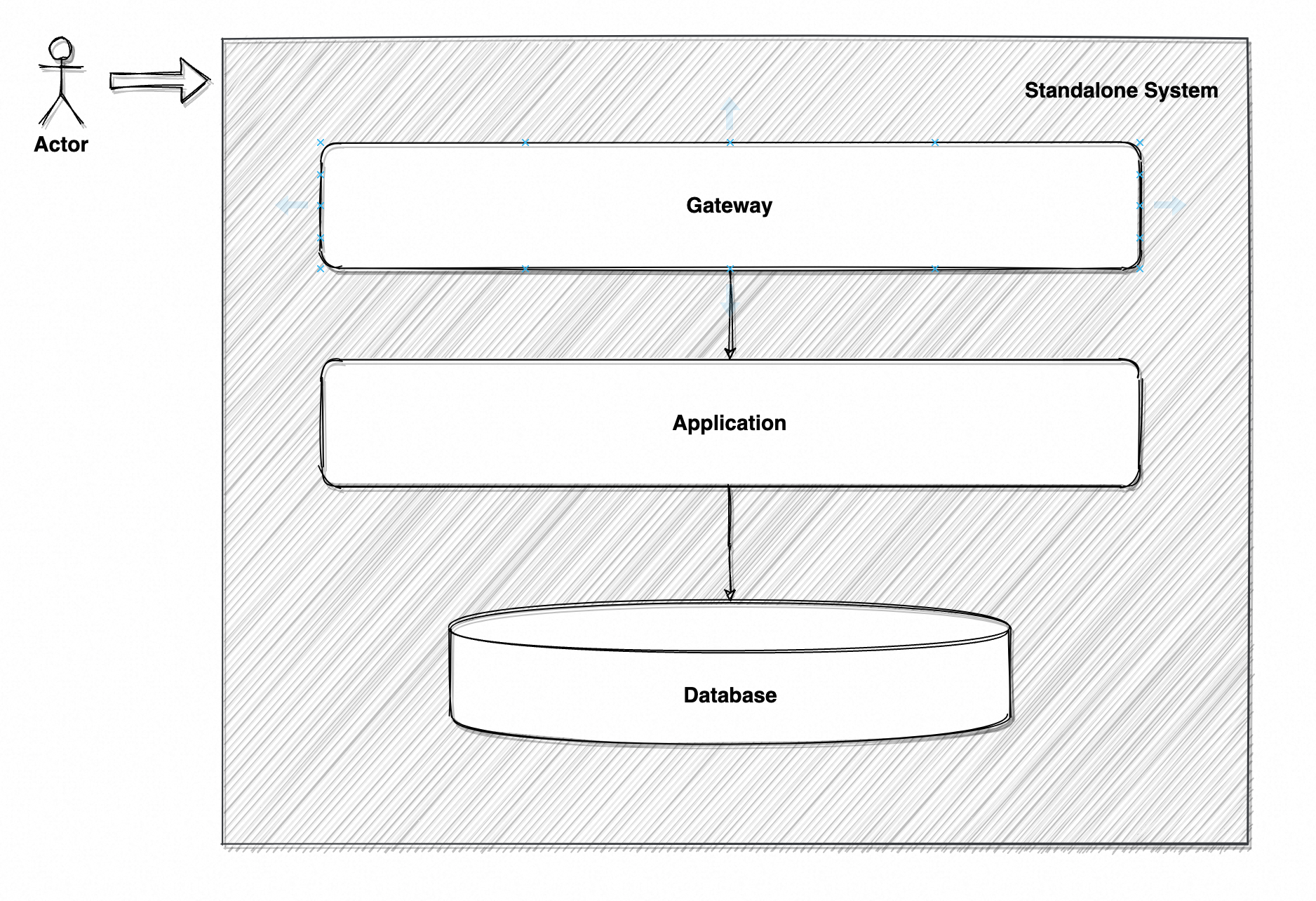
如图 2 所示,网关服务(也可能没有)、应用服务、数据库服务部署在同一台机器上,每个部分通过本地进程间通讯交互。初期肯定是够用的,但很快就出现了明显矛盾:
- 任一部分异常,整个服务不可用,出现单点故障;
- 单机负载极高,高峰期消费速度 < 生产速度,请求成功率大幅下跌;
- 所有服务组成共用机器的 CPU、内存、IO 资源,出现显著的资源争抢;
- ······
最简单的措施是升配置,但治标不治本,总有升不上去的时候。第二简单的就是加机器,一台不够用就来一北台,同时将数据库服务独立部署,因为数据库本身就是通用的组件。于是如图 3 的「服务集群 Cluster」诞生了,由前置网关通过负载均衡策略、决定将请求路由到服务集群中具体哪台机器上。
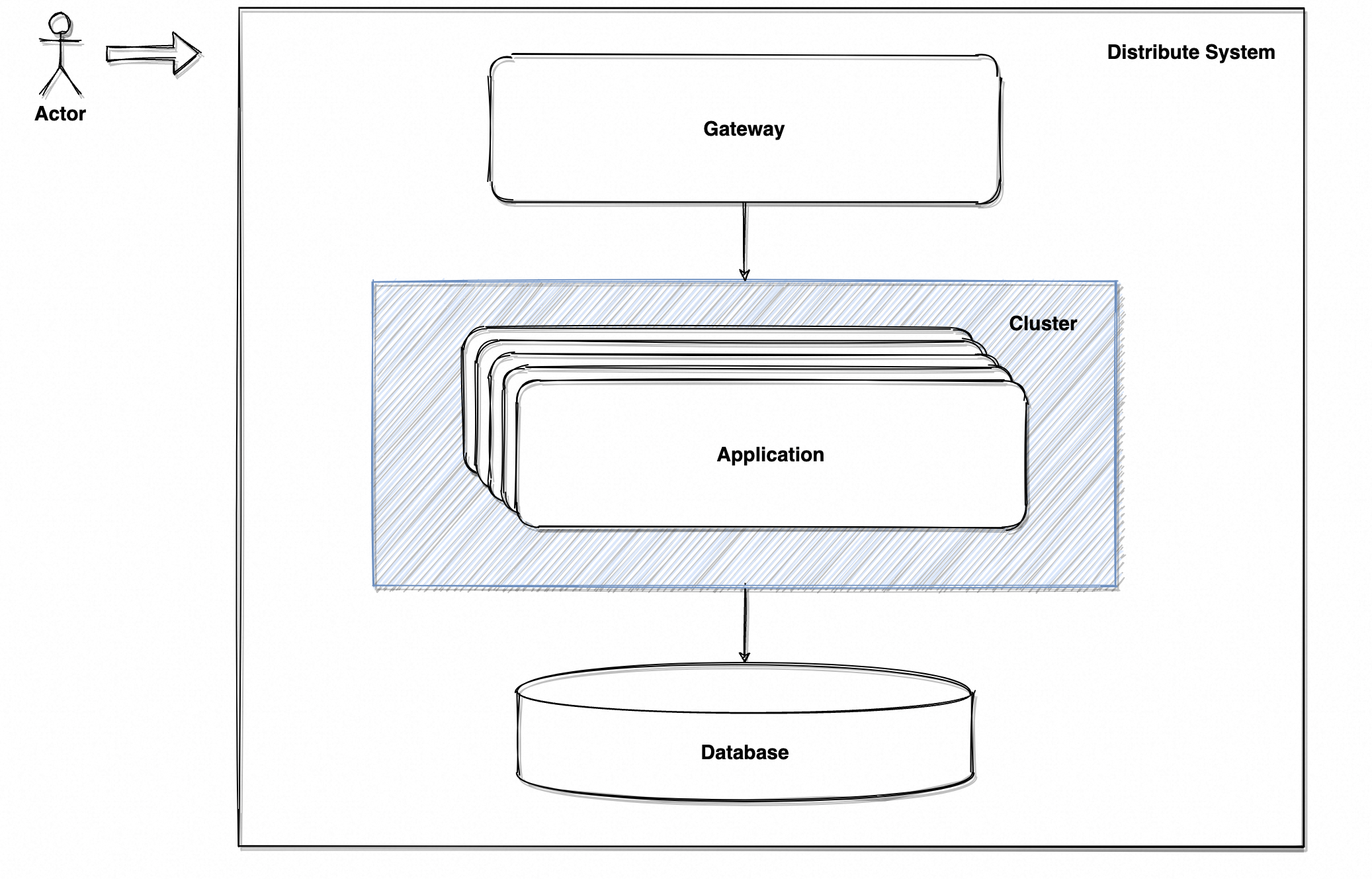
此时已初具分布式架构的雏形,由单机服务变成了通过网络通讯联结成的整体服务。服务层的单点故障消失了、性能吞吐也翻了几番。
之后人们发现系统中的每个部分都可以继续拆分扩展 :
- 大应用可以垂直拆分为小应用,并将小应用也扩展成集群;
- 数据库可以水平拆分为主从实例、并配合读写分离策略,还能通过叠加分库分表中间件,垂直拆分为多个表、多个库实例;
- 还可以在不同服务中间引入合理的分布式中间件,例如分布式缓存系统、分布式计算引擎、分布式消息队列等;
- ······
最开始一切都那么美好,我拆我拆我拆,最终真的拆成了图 1 中的样子。而随着系统复杂度越来越高,分布式环境下特有的缺陷与问题逐渐暴露,简直不胜枚举:
- 由于不同服务间通过网络通讯,而网络通讯并不可靠,请求可能处于成功或失败的叠加态——超时。此时应该将请求视为成功还是失败?状态未知的请求是丢弃还是重试?重试是否需要考虑幂等问题?
- 某台机器的响应结果总是超时或失败,应该如何判定该机器此时的状态?又该对异常状态作怎样的处理?例如是否应该主动将不可用机器剔除?剔除后又该如何恢复?
- 当用户请求发送到集群中不同机器时,是否可能返回不同的结果(如访问服务器 A 校验成功、访问服务器 B 校验失败)?如果可能,是否意为着集群状态不一致?集群的状态一致性如何管理?
请再次仔细察看图 1 的示例,**分布式系统不是一堆服务器的叠加,而是无数分布式环境问题解决方案的集合。**负载均衡、心跳检查、服务代理、读写分离、中心化管理等等等等,维持分布式系统正常运行的代价日益夸张,人们开始怀念当时使用单体架构无忧无虑的日子……
分布式系统不是一颗银弹,而是**系统达到瓶颈的客观事实下,一种有理论和实践基础的架构方案。**它是一柄极其锋利且残忍的双刃剑,用得不对或不好只会对系统造成毁灭性打击。不过,分布式架构在经历漫长时间的发展后,积累了大量理论基础及成熟的解决方案,基本可以做到开箱即用。例如分布式消息队列 Kafka、RocketMQ,分布式缓存 Redis,分布式计算引擎 Flink 等等等等。
作为使用者,显然需要理解分布式架构存在的问题,进一步能够快速定位和解决问题,最后做到通过合理的选型、架构设计、编码规避问题。
作为一名合格的开发人员,也必须掌握如何构建分布式系统,避免系统存在分布式环境的常见问题。
3 分布式系统核心要素
章节「2 分布式系统演进」提及了大量分布式环境问题解决方案,也枚举了部分分布式环境下的致命问题。事实上存在的问题以及对应的解决方案比想象中多得多,没有人敢打包票了解所有问题。但这并不影响开发者构建完整的分布式系统,因为前人早已总结出分布式系统开发的指导方针——即一个**分布式系统可用的最基本要素**。
分布式环境下的所有问题,都是基本要素不具备、或不完善而出现的变体。这也是本文以及本系列讨论的重点,了解构建分布式环境的基本要素,并在可实施的范围内最大化满足要素。
分布式系统最著名的理论则是 Eric Brewer 教授提出的「CAP 理论」,其认为分布式系统由 3 个基本要素构成:
- Consistency 一致性:所有节点上的数据在同一时间的视图保持一致,即数据写入操作完成后、所有节点都能读取到最新且一致的数据。
- Availability 可用性:系统保证每个请求都能正常得到响应,即使部分节点出现故障;但可能返回旧的数据,或无法保证所有节点返回一致的结果。
- Partition Tolerance 分区容错性:系统能够在出现网络分区的情况下继续工作。
并且,CAP 理论认为:在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三个特性不可能同时实现;在发生网络分区时,如果需要继续提供读写服务,则只能在一致性和可用性中选择一个满足。
相信于开发人员而言 CAP 理论并不陌生,但理论内容偏抽象、自解释性不强、并且有较多前提条件没有提及,因此还是先大致介绍一下。
首先 CAP 理论将「分区容错性」作为必要条件,是因为这样的前提:
- 系统运行依赖所有节点达成共识/数据一致
- 存在节点间的网络通讯
- 存在网络异常
- 存在分区间不可达
如果分区现象不会出现,也就不必讨论是保 C 还是保 A 了,通讯没问题理所应当保证服务既可用又数据一致。但网络不是 100% 可靠,分区现象一定会出现,而分区现象出现时系统仍需正常提供服务;此时系统只能在「一致性」与「可用性」间权衡,无法两者完美兼顾。这就是 CAP 理论想要表达的观点。
以一个提供增删改查服务的分布式数据库为例,如图 4 的数据库具有 N 个节点(Node),数据节点分布在 4 个区域(Region),区域内通过局域网进行通讯、区域间通过互联网进行通讯。
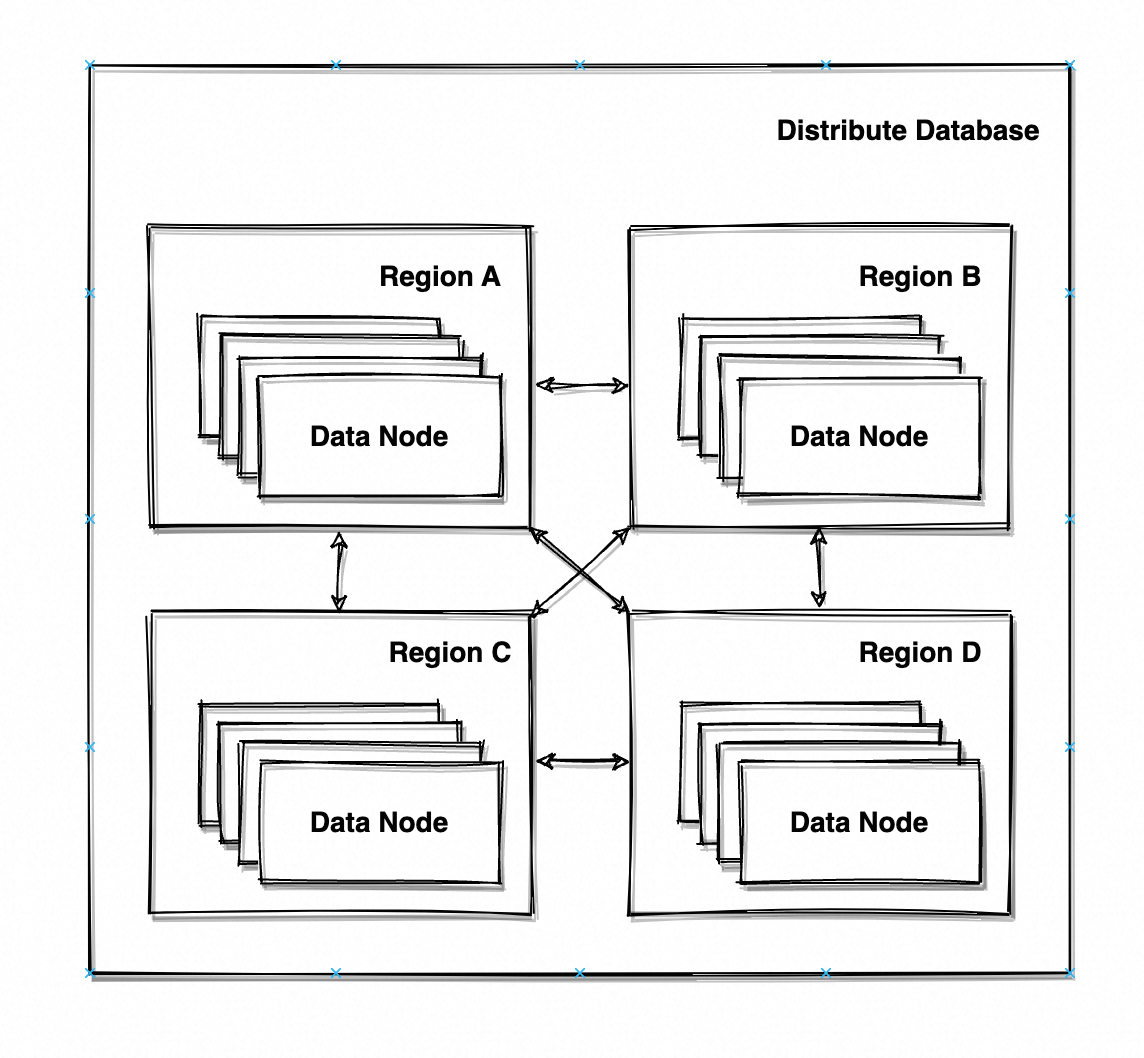
每个 Region 都具有一份完整的数据副本,数据根据分片规则(Sharding Strategy)均匀分布在 Region 内的 M 个节点上(M = N/4);每个节点都可以响应读写请求,根据分片规则计算读/写数据所应分布的节点,如非自身则将请求路由到对应节点。****由于任意节点都可以响应读写请求,因此写请求需要在写入自身节点的同时、向其他节点发起数据同步,以满足系统对相同请求永远响应一致结果(否则会出现前脚写入后脚查不到、或者一会能查到一会查不到的现象)。
诚然笔者设计不出这么牛逼的架构,基本完全照搬 ElasticSearch(一个牛逼的分布式搜索引擎),只不过增加了 Region 的概念。ElasticSearch 中的索引有主分片与副本分片(Primary/Replica)之分,且每个分片会位于不同节点上,以此实现高吞吐和高可用。
扯远了,在系统及分区间网络正常时,系统提供着可用且一致的服务。假设此时 Region A 网络出现异常、分区现象出现,系统的架构变成了这样。
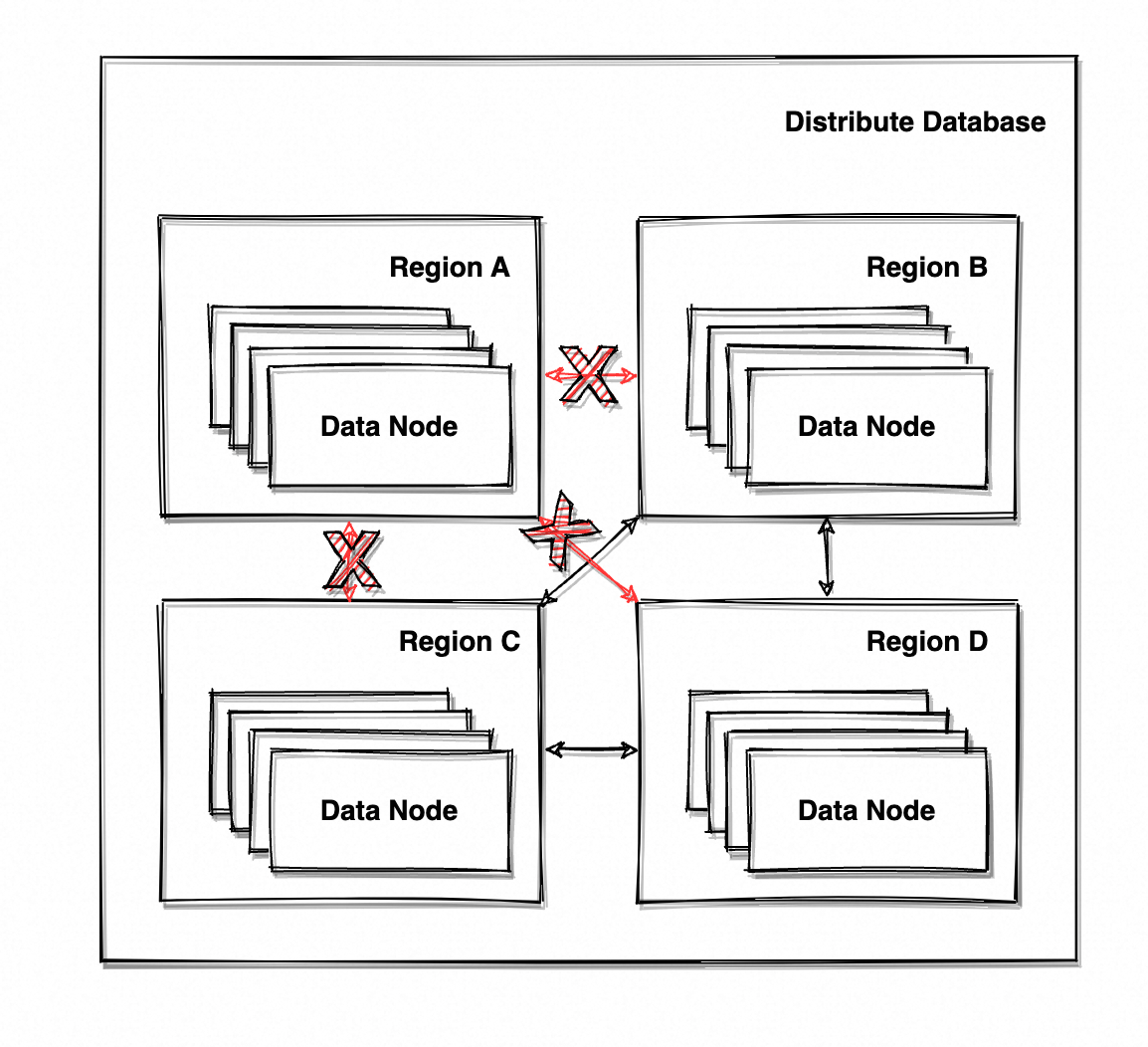
如图 5 所示,所有区域与 Region A 的通讯均出现异常,分布式系统被分为了两个分区:Region A 与 Region B+C+D。系统仍能响应外部请求,但 Region A 所有节点都无法通讯,即无法正常同步数据。
问题来了,此时系统有两种选择:
- 停止提供服务,优先保证数据一致性,直至分区异常恢复、节点间数据同步恢复。
- 继续提供服务,优先保证服务可用性,但 Region A 无法进行数据同步,可能导致数据不一致。
两种选择完全互斥,保证数据一致就要停止数据写入、否则 Region A 的数据就会与整体不一致;继续提供服务就会出现数据不一致,写入 Region A 的数据无法同步到其他 Region、写入其他 Region 的数据无法同步到 Region A。
这就是 CAP 理论的基本论点,构建分布式系统就是在「一致性」与「可用性」之间权衡,永远无法达到两全其美。CAP 是非常经典的理论,但本身不具备太强的实践指导意义。因为这个命题过于庞大,对于一个分布式系统而言,该如何定义系统的「一致性」与「可用性」?又是怎样的权衡过程?权衡到什么程度系统才算可用?
这些问题远比想象中复杂,本文也由此进入正题。
4 一致性
本章仍会以章节「3 分布式系统核心要素」提到的分布式数据库为例,分析一致性/可用性在系统中的体现,实现对应一致性/可用性的方案以及所需付出的代价,系统最终如何在两者间进行权衡。
4.1 强一致性/线性一致性
前文提到该分布式数据库满足“系统对相同请求永远响应一致结果”,其中的隐藏含义为:
- 一旦有客户端读取到最新的值,所有客户端都不能读取更旧的值(任何一次读都能读到某个数据最近一次写入的数据,如果 Client A 认为写入成功并且能读取到,那么其他所有 Client 都应该能读取到)
- 数据一旦写入就全局可见(操作序列符合预期,写入成功但读取不到意味着不符合预期)
这是极为强力、令人安心的一致性保证,整个系统如同只有一份数据,无论何时读取、读取任一节点都表现一致。这也是 CAP 中对于一致性的定义,俗称「强一致性」、也称「线性一致性/可线性化 Linearizability」,是分布式系统最美丽而苛刻的一致性。
这里不深入探讨线性一致性的定义(感兴趣的同学可以自行了解并发操作的「全序 Total Order」与「偏序 Partial Order」),仅从实际简要分析。

如图 6 的操作序列图, P 1 / P 2 P_1/P_2 P1/P2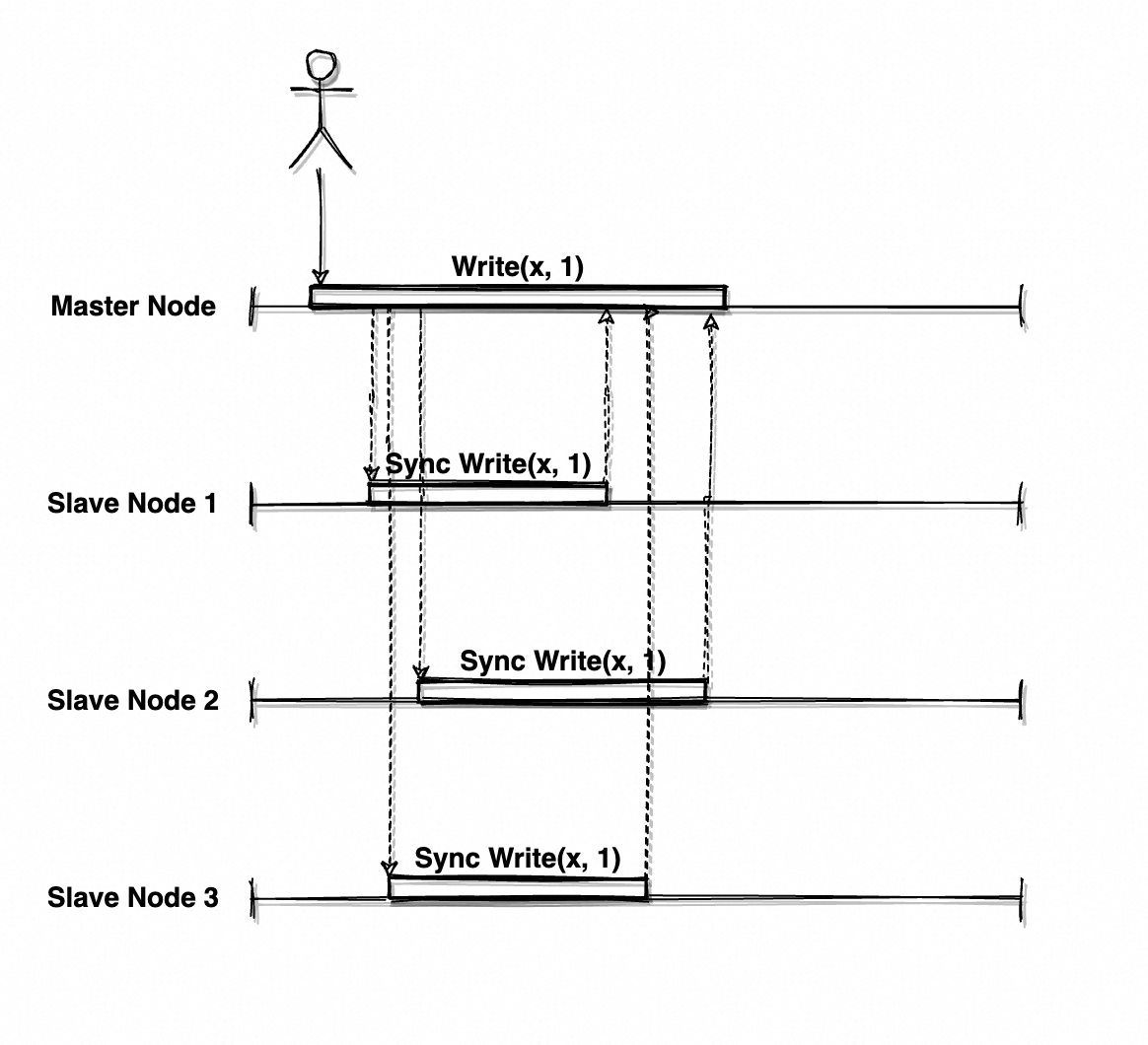
为啥说是基本?系统响应时所有节点都完成了本次写入数据的复制啊?举个例子就清楚了。

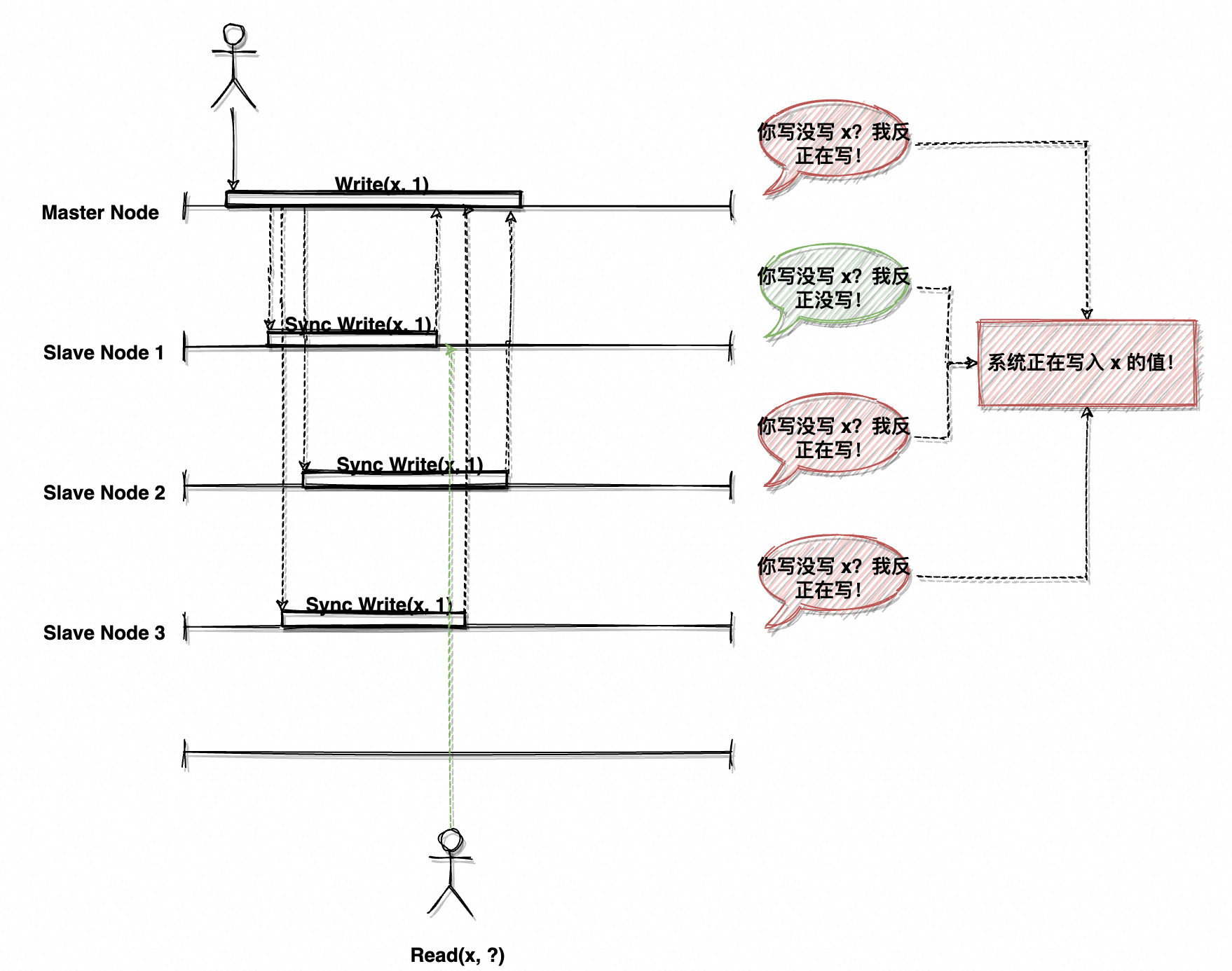
如图 8 的读写操作序列,在 Write(x, 1)执行期间会有 Client 读取 x 的值:
- 第一次读取请求被路由到了 Node3,此时该节点仍在处理复制任务,因此读到任何值都有可能;假设读取到了 x = null。
- 第二次读取请求被路由到了 Node1,此时该节点已经完成了复制,因此只会读到 x = 1。
- 第三次读取请求被路由到了 Node2,情况同 Node3;假设读取到了 x = null。
在全局时钟顺序下,用户先后读取到了 null、1、null,并难以置信地揉了揉眼睛。数据如同海市蜃楼,时有时无,难以捉摸。系统显然不满足线性一致性,只是实时性较强的最终一致性(这个「最终」会来得早一些)。
十分令人沮丧,明明已经如此努力了,还是做不到吗?事实上想达成线性一致性确实非常非常困难,并且伴随着极低的性能与可用性——同步数据复制意味着请求要等到最后一个节点完成复制才能响应,并且这一切都建立在“网络分区一定不会出现”的美好前提之上,节点间通讯一定保持正常是不可能的。只要一个节点抖动或不可用,整个服务都会崩溃。
4.1.2 Step2:读请求约束
系统已经采用最严格的同步复制,在一致性层面基本没有优化余地了。但线性一致性的海口已经夸下去了,只能在现有架构下作进一步约束。
图 8 的读写序列之所以不满足线性一致性,是节点间数据复制存在时间差,时间差内不同节点自然会返回不同读取结果。可以发现矛盾出现在时间差窗口内,如果针对窗口期对读取请求作一定约束,或许就能够解决不一致现象。
首先需要感知系统是否处于数据复制窗口期,如图 8 的三次读取请求,第 1/3 次知道自身处于窗口期,因为 Node2/Node3 正在处理数据复制;而第 2 次读取时 Node1 已经完成了数据复制,可本质上整个系统的数据复制并未结束,因此其并不知道自己处于窗口期。显然系统内出现了认知不一致,在解决一致性问题的路上,又遇到另一个不一致性问题。
但别无他法,保证系统所有节点达成共识,是分布式系统一致性的基本条件。
如何达成共识?在当前场景下即为:如何得知系统内是否正在处理写入请求/数据复制?简单啊,每个人都问一遍呗。
如图 9 所示,Client 在读取 x 的值时,首先确认当前节点是否在写入对应数据;如果不是,则询问其他节点是否在写入,有任一节点返回正在写入,则说明系统正处于写入窗口期。成功获取到了具有共识的状态后,读取节点可以选择返回读取失败、要求用户稍后再重试;也可以阻塞读取请求、不断向其他节点轮询写入状态、直至系统返回写入完毕,再返回给用户准确的值。
看起来还真是那么回事,用串行数据复制保证了写入实时性,又用写入状态全局检测保证了数据写期间不可读。只要所有节点写入完成就全局可读,好像确实是能保证线性一致性。但代价是什么?
试想一下这样的场景,变量 x 是热点数据。然而系统的每次读取请求都会走一遍全量节点的状态询问,这就注定了读取的效率不会高到哪去——甚至这还是在没有数据写入时,一旦有写入、所有的读取请求都会被挂起或失败。更极端的场景,x 会被高频写入,在持续写入期间、没有任何人能读取到 x 的值,最长就是一辈子。最令人恐惧的是,这一切又建立在了“网络分区一定不会出现”的前提之上,只要有一个节点不可用,系统状态就无法达成一致,系统又全面宕机了。
4.1.3 Step3:写冲突
好像没什么硬伤了,但系统还有个致命问题未解决。
由于系统为「多主同步复制」,所有节点都可以响应写入请求;假设写请求存在并发,如果两个节点在同一时间分别写入 x = 1/x = 2,最终的值到底是 1 还是 2?「写冲突」出现了,如同合并代码时发现同一个类被修改为了两个不同版本,此时需要程序员抉择到底是选取版本 A、还是选取版本 B、还是糅合 A 与 B。
事实上笔者也不知道,并且业界还没有非常成熟的写冲突解决方案(感兴趣的同学可以了解一下这个话题:收敛至一致的状态及自定义冲突解决逻辑)。但为了避免写冲突,只能在屎上再雕一朵花。
和上一章读请求的状态检测逻辑一致,在写入数据时也问问,当前数据有没有节点在写入。并且还可以优化一把,状态检测本质上就是一个互斥锁嘛,发起写入的节点尝试加锁,加锁成功说明没有节点在写;读取同理,轮询锁是否存在,存在则不可读。
但矛盾出现了,多主架构就是为了提高写并发,但写入又要进行分布式锁抢占,同一时间只有单节点可写。那多主的意义是什么?直接用一主多从节点不就完了吗?
没错,你能叫上名字的分布式中间件**基本都采用一主多从架构,仅主节点可写,大大降低了系统复杂性,拓扑结构也更清晰。**
经过上面三步,一个非严格意义上的「线性一致性」分布式数据库似乎诞生了,但看看这些努力为使用者带来了什么:
- 无法容忍网络分区,只要任一节点网络异常,读写服务全盘不可用。
- 读取效率低,因为要轮询所有节点状态。
- 写入效率低,因为写入前要先进行写冲突检测,写入时所有节点写入完毕才响应。
- 总结:除了具备线性一致性以外,基本不具备可用性。
通常会将数据库服务特性分为“读多写少”和“写多读少”,而这个数据库显然只能支持“读少写少”……
虽然架构采用了非常简陋的实现方案,但仍然能一窥「线性一致性」实现的难度之高,因此绝大部分分布式中间件并不提供线性一致性,即使提供也明确告知了性能会急剧下降。通常是在可用性与一致性之间平衡,最终提供弱化的一致性版本。
并且大家应该也能够深刻理解,为何 CAP 理论将「分区容错性」作为不可选的必要条件,因为对网络异常的容忍能力,实在是一个分布式系统最基本的要求。对于上述架构,任何节点网络异常都会导致系统不可用。
那么接下来应该去寻找更科学可靠、分区容错性更强的方案。
4.1.4 etcd 的串行化读与线性读
在寻找之前再卖个关子,相信大家仍有不甘(反正笔者有)。可恶,难道这个世界就不存在线性一致性的中间件了吗?
答案是有的,CNCF 的开源高可用分布式 KV 数据库 etcd(Distributed ETC Directory),著名的容器编排引擎 K8S(Kubernetes)就将 etcd 作为服务发现模块使用。etcd 提供「串行化读」与「线性读」两种数据读取方式,其中「线性读」就能够保证线性一致性。
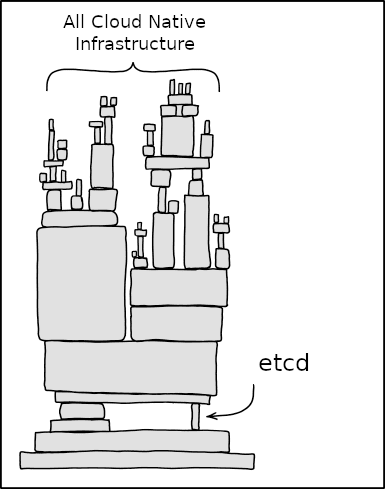
由于 etcd 采取了「一主多从」,仅主节点可写,这样既不存在写冲突问题,又能够保证主节点的数据一定是线性化的,因此线性读的实现方式也很简单——只读主节点。没错,就是如此大巧不工,既然读取从节点不可避免出现复制延迟,那就只读主嘛。这与主从 MySQL 避免“读多写多”的数据不一致的方案一致,**写主读主**就一定一致了,“读多写少”或延迟容忍度高的数据读从节点。
但实际方案肯定不是只读主节点这么简单,其中涉及**复制状态机(Replication State Machine)**相关知识(如状态机日志的 Commit 与 Apply),这里不作赘述。至于「多主复制」如何实现线性一致性,得靠同学们自己探索了。
4.2 共识算法
回到上一章遗留的重要问题,如何设计出分区容错性更强的方案?如何在网络异常、节点故障的情况下保证系统可用?
在前文实现线性一致性分布式数据库的历程中,采用了 2PC 进行写入请求状态判断、全局写入状态检测进行写冲突控制和读请求管理,这本质上是「对同一事物达成一致看法的过程」。某个节点询问其他所有节点是否在写入 x,最终得到未写入/写入中,这个结果就是系统对这件事达成的一致看法。
整个过程被称为「达成共识」,实现这个目的的方式被称为「共识算法 Consensus Algorithm」。「共识算法」主要用于在分布式系统中的多个节点之间就某个事情(可以是数值或状态)达成一致。其解决的问题是,即使在存在故障(如节点宕机或网络分区)的情况下,系统中的多个节点也能就某个值或操作顺序达成一致。
其在结果上似乎与 2PC/3PC/TCC 这类一致性算法类似 ,都是在保证某些行为或值一致。但一致性算法更注重“结果”,即某个行为最终要不都成功、要不都失败;而共识算法更注重“过程”,即某个状态在系统中达成共识,基于这个共识再进行数据的一致性控制那是后话。并且,共识算法的应用场景是分布式环境,其深知分区容错性的重要性;因此考虑了 Failover、节点故障、网络分区、甚至恶意行为(拜占庭错误 Byzantine Fault),具有强大的容错能力,少量节点宕机或通讯异常完全不是问题,显然是 2PC 等一众一致性算法所不具备的。
但需要明白的是,达成「共识」并不意味着「一致」,共识算法需要在网络异常/节点宕机场景下仍然可用,因此无法强保证所有节点实时保持一致状态,而是**使分布式系统中绝大部分节点(Quorum 法定人数/Majority 大多数派)达成共识**,但最终一定会趋于一致。
4.2.1 Paxos
分布式系统共识算法的代名词「Paxos」登场了,由分布式理论领域传奇人物莱斯利·兰伯特(Leslie Lamport)教授于 1998 年提出,用于帮助分布式系统中所有节点就某个值达成一致。通常用于分布式系统领导选举(Leader Election)、日志复制(Log Replication)等领域。
Paxos 做的事其实很简单:提议者发起提案,接受者为提案投票(接受/拒绝),提案在大部分节点间达成共识后(投票成功)告诉所有人,最终达成一致。算法在可能出现节点宕机、网络异常、消息丢失的分布式系统中,仍然能坚挺地正确运作。理论乍一看挺简单,实现却极其复杂。
Paxos 算法包含 3 种角色,且一个节点可以同时担任多个角色:
- 提议者 Proposer:提出值的建议(也称提案 Proposal),并试图说服多数接受者(Acceptor)接受其建议。
- 接受者 Acceptor:响应提议者的建议,并记录已接受的建议。
- 学习者 Learner:一旦某个值被多数接受者接受,学习者会学习到这个值。

Paxos 的运行流程如图 11:
- Proposer 选择一个新提案编号 n,提案编号必须不重复且单调递增,这一步是为了区分不同提案以及提案的先后顺序。
- Proposer 发起提案准备(Prepare Phase)请求,即广播“编号为 n 的提案被提出了”到大多数(Quorum)Acceptor。一般要求系统有 2X + 1 个节点,因此大多数 = X + 1;奇数个节点可以保证投票时不会平票,也可以保证 Write + Read = X + 1,具体推导过程请自行搜索。
- Acceptor 接收到提案准备请求后,检查自身之前响应过的 Prepare 请求提案编号。如果 n > 已响应最大提案编号 n’,则记录 n 为已响应最大提案编号、并承诺不再接受小于 n 的任何提案(原本是不再接受小于 n’ 的提案,被更大的 n 刷新了),最后返回(当前响应提案编号 n, 已接受/投票提案编号 N, 已接受/投票提案值 V)。反之则不投票。
- Proposer 接收到大多数 Acceptor 响应后,说明本次提案准备通过了,发起提案接受(Accept Phase)请求。 比较 Acceptors 响应中的已接受提案编号 N,选取最大 Acceptor 所具有的提案值 V,将(本次提案编号 n,已接受提案值 V)广播到 Acceptor。
特殊情况是,如果所有 Acceptor 都未曾接受过提案(即 N = V = null),则不存在已接受最大提案,此时可由 Proposer 自行赋值。 - 见 4。
- Acceptor 比较提案编号 n 与已响应最大提案编号 n’,如 n >= n’ 则接受提案,将已接受提案编号 N 改为 n、已接受提案值 V 改为当前提案值 Value,并返回 n’(此时 n’ = n)。反之则不接受该提案,直接返回 n’。
注意,提案存在并发发起,Acceptor 只承诺不再接受小于 n 的提案,大于 n 的提案仍会响应;因此在这个过程中 n’ 是可能被改变的。 - Proposer 接收到大多数 Acceptor 响应后,检查是否有 Acceptor 已响应最大提案编号 n’ > 当前提案编号 n,如有则返回步骤 1;反之则达成共识。
更具体的 Paxos 运行流程、数学推导过程、算法安全性/活性保证,以及衍生版的 Multi-Paxos 请自行寻找资料或者找笔者当面探讨。这里顺带记录笔者在理解 Paxos 过程中遇到的最大疑问,希望对你有帮助。
自问:
有个疑问,在我看来 Proposer 所提出的提案由 [tid, value] 构成,即本次提案所具有的全局唯一递增 id 和提案值;但以文章中的描述来看,Proposer 在「表决」完毕后、真正发往所有 Acceptor 进行「决策」的提案内容,反而是所有 Acceptor 在表决阶段返回的已通过决策提案的最大值。这不就导致 Proposer 本身所具有的提案值丢失了吗?
举个例子,Proposer 本来想提出 [100, “Sunday”],在表决完毕后、发现 Acceptor 返回的最大值为 [99, “Monday”],不得不将提案值修改为 “Monday”,其本身想提出的提案不就丢失了吗?
还是说 Proposer 在提出提案的时刻,是不具备本身想提出的提案内容的、只有一个 tid 来帮助全局达成共识?
希望您能帮助解惑。
自答:
又琢磨了很久,发现了一个关键的概念。Paxos 算法最大的目的是让系统保持共识,Proposal 被提出的根本目的也是如此。因此 Proposal 在系统已经达成共识时,放弃并覆盖自己提出的提案值(即算法中描述的,如果 Acceptor 已经具有通过且最大的提案,则 Proposer 会将该提案提交给所有 Acceptor)。
提出提案及提案对应的值于 Paxos 而言,并非「一定要被接受」,而是「一定要保持共识」。
传统数据库提供的写服务,通常代表「写入请求一定要成功」;这在 Paxos 算法场景并不适用,需要结合 Paxos 及实际业务逻辑,设计能够保障新提案一定被接受的干预措施。
4.2.2 Raft
Paxos 啥都好,就是太太太 tm 复杂了,笔者看都看了好几宿。并且基础的 Paxos(Basic Paxos)可用性并不高,如果有两个 Proposer 交替发起提案,Prepare 成功、Accept 失败(已接受最大提案号交替攀升,永无止境),提案就永远无法达成共识,从而形成活锁。
天才工友们开始琢磨如何简化了,Paxos 复杂就复杂在所有节点都能发起提案、还会出现并发提案,想在这种场景下维持准确实在太难。是不是很眼熟?章节「4.1.3 Step3:写冲突」讨论了多主架构带来的复杂度飙升,其实与 Paxos 如出一辙;多主意味着每个节点写入时都要问问自己是否可写、写入后是否全局成功写,但如果只有唯一的主节点可写,即采取主从架构,问题就大大简化了。
Raft 将分布式共识简化成了:选举(Leader Election)、日志复制(Log Replication)、**安全性(Safety)**这三个主要问题,解决了它们就解决了共识问题。

Raft 中也包含 3 种角色:
- 跟随者 Follower:相当于 Slave,正常情况下节点处于跟随者状态,接收领导者的日志复制和心跳消息。
- 候选者 Candidate:如果跟随者在一定时间内没有收到领导者的心跳消息,会变为候选者状态,并发起选举。
- 领导者 Leader:候选者在选举中获得多数节点的投票后,成为领导者,开始处理客户端请求和日志复制。
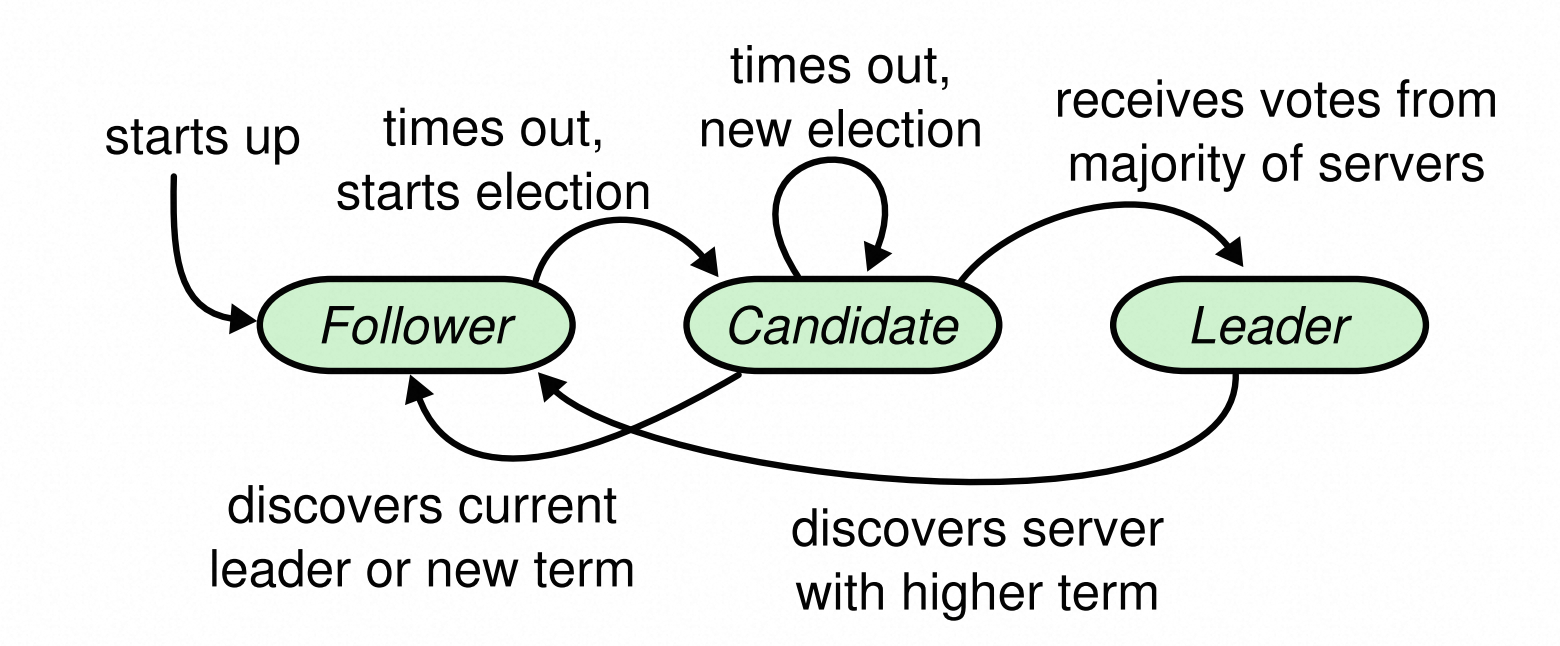
选举的逻辑并不复杂,如图 13 所示:
- 初始状态时所有节点都是 Follower,此时系统内不存在 Leader 节点。每个节点会有一个随机的心跳超时时间(Heartbeat-Timeout,大概在几百毫秒,每个节点值都不同),在超时时间内如果未收到来自 Leader 的心跳,则认为系统内已经没有 Leader 节点,将发起并参与选举,此时节点变为 Candidate。
- Candidate 会投自己一票,并向其他节点请求投票,如果获取到了绝大部分选票(Quorum),则成为当前任期(Term)内唯一的 Leader,通知其他节点 Leader 已产生。
- 如果 Candidate 在选举超时时间(Election-Timeout)内未能获取到绝大部分选票,则将 Term + 1 并发起新一轮选举,直至 Leader 出现,或者发现 Term 比自身大的 Candidate、此时会将自己转为 Follower 并投出宝贵的一票。
「任期 Term」是极为重要的概念,每次选举 Term 都会递增,低 Term 必须将票投给高 Term,以此保证选举的优先级。
选举完成后,会由 Leader 处理 Client 的写请求:
- Leader 将写请求记录进 Append-Only 的日志,写入后向 Follower 节点发送 AppendEntries RPC(相当于一次带数据的心跳)。
- Follower 会对日志进行一致性检查,如有效则将日志写入本地日志并响应 Leader,无效则会进行一致性处理、试图跟 Leader 保持一致(正常情况下都会与 Leader 一致,但发起重新选举后可能存在状态滞后,此时需要额外操作抹平差异,具体可以了解 Raft 日志一致性检查)。
- 当大多数 Follower 响应成功后,Leader 认为本次写入成功、将日志状态修改为 Commited(此时日志真正被提交了)、并** Apply 到本地的复制状态机(此时 Leader 节点写已可见)**,通知 Follower 也将状态改为 Commited。
- Leader 此时便可以响应 Client 写入成功(为了提高写性能),Follower 后续会自行将日志 Apply 到复制状态机(此时 Follower 节点写不一定可见)。
日志的状态由 野日志 -> Commited -> Applied,对应 未写入 -> 已写入 -> 已可见,整个过程推进和状态流转十分清晰,且做了很多细节上的性能优化,优雅且可靠。
Raft 又追加了两条规则用于保证 Safety:
- 拥有更大的 Term 或 Log Index 的 Follower 才能成为 Leader。
- 先前任期的日志,只能由当前任期的提交而间接被提交(在 Commit 当前日志时会带上之前已写入本地的日志)。
这样就彻底保证了 Leader 节点的数据完整性(日志一定连续),也避免了已 Commit 的数据被覆盖。更具体的流程细节以及 Safety 对应的「Follower 崩溃」与「Leader 崩溃」,这里不作赘述。
4.2.3 ZAB
Raft 已经很 nb 了,这 ZAB 又是啥?用来干嘛的?
ZAB 全称「Zookeeper Atomic Broadcast」,中文名 Zookeeper 原子广播,主要用于 Apache ZooKeeper 分布式协调服务。ZAB 是一种原子广播协议,旨在确保分布式系统中的数据一致性和高可用性。它结合了 Paxos 和 Viewstamped Replication 的特点,特别适用于需要强一致性和高可用性的分布式环境中。
其中有 3 种角色:
- 领导者 Leader:处理客户端请求,生成事务并广播给跟随者。
- 跟随者 Follower:接收并应用领导者的事务,响应客户端读请求。
- 观察者 Observer:类似 Paxos 的 Learner,不参与投票,仅用于扩展读取能力。
主要提供 3 种能力:
- 领导者选举(Leader Election):选举出一个唯一的领导者节点。
- 同步(Synchronization):确保所有节点的数据一致,特别是在领导者变更时。
- 广播(Broadcast):领导者将客户端请求转换为事务并广播到所有跟随者。
和 Raft 基本一毛一样,只不过实现细节更符合 Zookeeper 的定制化需求,就不多介绍了。
4.2.4 总结
共识算法的设计理念为:在分布式环境中,确保大多数节点在可能出现网络分区、节点故障和数据丢失等异常现象的情况下,仍能够就某个值或状态达成一致。
共识算法中通常采用这样的方案:
- 法定人数 Quorum/多数派 Majority:确保节点内大多数节点达成一致,以此实现 2X + 1 个节点中 X 个节点异常仍可用,提高性能与分区容错的同时确保了数据准确性(Paxos 提出提案时使用 Quorum,推导过程见抽屉原理)。
- 领导选举:用「主从复制」代替「多主复制」,简化写操作一致性和故障恢复。
- 日志复制:利用 Append-Only 日志 + 复制状态机实现一致性。
最后总结一下, 2PC/3PC 采取 WARO(Write All Read one),所有副本复制完成才算完成,任一节点不可用则不可写、任一节点网络阻塞则全局阻塞。而共识算法采取 Quorum(法定人数)/Majority(多数派),能够容忍 2X + 1 中 X 个节点异常,且兼顾 Failover 的准确性,提供极强的容错性。
4.3 再探线性一致
再来回看章节「4.1 强一致性/线性一致性」中示例数据库留下的问题:
- 不具备任何分区容错能力,单节点宕机/网络异常直接不可写;
- 读取效率低,只有所有节点都完成复制才可读;
- 写入效率低,要先进行写冲突检测、还要等所有节点写完才算完。
有了共识算法这个好宝贝,又该如何改造这个支持“读少写少”、多主复制、线性一致的分布式数据库?
4.3.1 基于共识算法的数据复制

假设图 14 的分区再次出现,基于原有的 2PC 算法,Region A 不恢复通信写入永远无法成功,因为系统无法达成 WARO 的共识。采用 Paxos 算法就好办了,共 4 个节点(这是个不恰当的例子,一般推荐使用奇数个节点),只要有 4/2+1 = 3 个节点写入成功,即认为达成共识,本次写入成功。
系统具备了 1 节点宕机/网络分区的分区容错,历史性的飞跃!甚至可以采用 Raft 的日志复制机制,不需要等写入成功,日志状态改为 Commited 直接响应 Client,性能也有了进一步提升。
但是问题来了,共识算法实现的数据复制满足线性一致吗?
答案是 NO,这也是非常常见的误解,认为采用了共识算法的系统就一定满足线性一致。再看一遍线性一致性的定义:
系统所有操作满足全局时钟下的操作序列(或者说:所有操作按照全局顺序执行,且顺序满足全局时钟顺序),则认为该系统满足「线性一致性」。
而共识算法只要求系统内绝大部分节点达成共识(即写入成功),在全局时钟下显然会出现少部分节点仍未就该操作达成共识(写入成功的消息还未传播到),此时如果正好读取到该部分节点,就会读取到旧值。
因此,使用共识算法并不意味着满足线性一致,只保证了系统异常时的数据准确性。
4.3.2 基于共识算法的读写
采用共识算法后分区容错是有了,线性一致性又没了,仍然不满足需求。这引发了笔者的思考,多主复制架构真的能满足线性一致吗?
基于 Paxos 算法的数据写入会呈现如下流程:
- Region A 发起 Write(X, 1),此时其具有最大的提案编号 1,因此 Region B/C 响应准备写入;此时 Region D 提交写入,Region B/C 返回成功,满足法定人数,本次写入成功。
- Region B 发起 Write(Y, 10),此时其具有最大的提案编号 2,因此 Region C/D 响应准备写入;此时 Region B 提交写入,Region C/D 返回成功,满足法定人数,本次写入成功。
- Region C 发起 Write(Z, 100),此时其具有最大的提案编号 3,因此 Region A/D 响应准备写入;此时 Region C 提交写入,Region A/D 返回成功,满足法定人数,本次写入成功。
此时每个节点具有的数据如下:
- Region A:(X, 1) (Z, 100)
- Region B:(X, 1) (Y, 100)
- Region C:(X, 1) (Y, 100) (Z, 100)
- Region D: ** (Y, 100) (Z, 100)**
不难发现,只有 Region C 具有完整数据副本,此时无论读哪个节点都可能出现数据不一致,也就不满足线性一致了。但这并没有破坏 Paxos 的原则,每次写入操作都有大部分节点达成共识。这也是 Basic Paxos 存在的问题之一——无法就多个值达成共识,没有多值共识就无法保证节点具有完整数据副本,甚至可能所有节点都没有完整数据。
这大大提升了线性一致性的实现难度,假设存在这样一个达成多值共识的节点,只读该节点就能天然保持线性一致(这里的说法并不准确,Basic Paxos 无法很好地解决并发表决,仍存在写冲突问题;但一起错和一起对都是线性一致)。因此只能在读操作进行前再发起一次提案表决,过程与写操作提案一致,重点是保证本节点的读操作与大多数节点返回结果一致——即系统需要在读取结果上保持共识。
沿用刚才的例子,此时 Region 的数据副本呈上文状态。读取操作变成了这样:
- Client 发起 Read(X, ?),此时 Region D 响应该请求;
- Region D 发现本地不存在 X,但该结果是不置信的,因为结果未形成共识;
- 发起读取提案,Region B/C 响应准备读取,均返回 Read(X, 1);
- Region D 采信该结果,系统对该结果形成共识,响应 Client Read(X, 1)。
系统似乎又实现了线性一致,但是每次写要两个来回的网络 IO,读也要两个来回,忙了半天数据库还是只支持“读少写少”。而且系统复杂度可谓是飙升,不仅要考虑写操作的共识,连读操作也要设计合理的共识过程。可用性也一步降低了,读操作也需要大部分节点支持。原本多主架构是为了提高读写并发,现在写并发低就不说了,读并发也下去了,实在令人汗颜。
4.3.3 基于一主多从的复制与读写
正如章节「4.1.3 Step3:写冲突」中提到的,这一切都是「多主架构」的错(更准确的说法应该是:互为主从的多主架构,如果能够根据分片规则确保数据仅在某一主节点存在,也不会出现读写冲突),无法保证具有完整的数据副本导致存在读操作共识问题、写冲突问题。不如进一步简化架构,直接采取「主从架构」。
事实上绝大部分分布式中间件都采取主从架构,包括上文提到的分布式 KV 数据库 etcd。仅主节点可写,既不存在写冲突、又保证了主节点数据一定完整,在此基础上实现线性一致性就简单多了。
假设 Region A 为 Leader 节点,在经过几次写入后每个节点具有的数据如下:
- Region A:**(X, 1) (Y, 100) **(Z, 100)
- Region B:(X, 1) (Y, 100)
- Region C:**(X, 1) (Y, 100) **(Z, 100)
- Region D:**(X, 1) **
其中 X 与 Y 已经达成共识并被 ABC 3 个 Region Apply、Region D 发生了复制延迟所以还未具有 Y;Leader 正在写入 Z,由于只有 Region C 响应、未达成共识因此 Z 也不可读。
无论发生什么,Leader 节点的数据都是完整且有序的,只读主便一定满足线性一致(这个说法并不准确,实际还有复制状态机的 Commit 与 Apply 问题,感兴趣的同学自行了解 etcd 线性读)。
4.4 弱一致性
至此,该分布式数据库满足了 CAP 中的 CP,系统操作一定符合线性一致。
但在网络分区出现时,为避免节点数据不一致,写入操作会被无限挂起直至网络恢复或重新选举出 Leader。其次由于仅 Leader 节点可读,其他节点仅作为 Failover 的副本存在,Leader 节点承担了读写的双重压力,两个操作互相影响,使得读并发也达到瓶颈。
显然,系统的可用性降低了,但没办法,C 与 A 不可能同时满足,这已经是权衡后的最好结果。在对准确性、实时性要求极高,且读写并发不会太高的场景下,这种保证是必须的——因为没有用户希望自己刚收到转账、钱又消失、又出现、又消失,报警的手举起又放下;也没有哪个元数据中心能接受节点已下线却无法感知。
但也许使用场景并不需要这么严格的一致性约束呢?换句话说,一致性可以/必须为可用性与性能让步,此时又该如何设计?这又是一个精细的权衡过程了。
4.4.1 最终一致性
如果需要设计一个支持海量并发的内存 KV 数据库(没错就是 Redis),由于单节点并发存在理论上限,该数据库理所应当设计成了一个分布式数据库。
最初采用了如图 15 的「一主多从复制」架构,读并发确实具备很强扩展能力,但由于写操作仅 Leader 可以响应且需要达成共识(需要起码 3 个从节点写入成功),很快就达到了瓶颈,再加多少节点也没什么改善(甚至是负收益,系统节点越多需要达成共识的条件就越苛刻)。
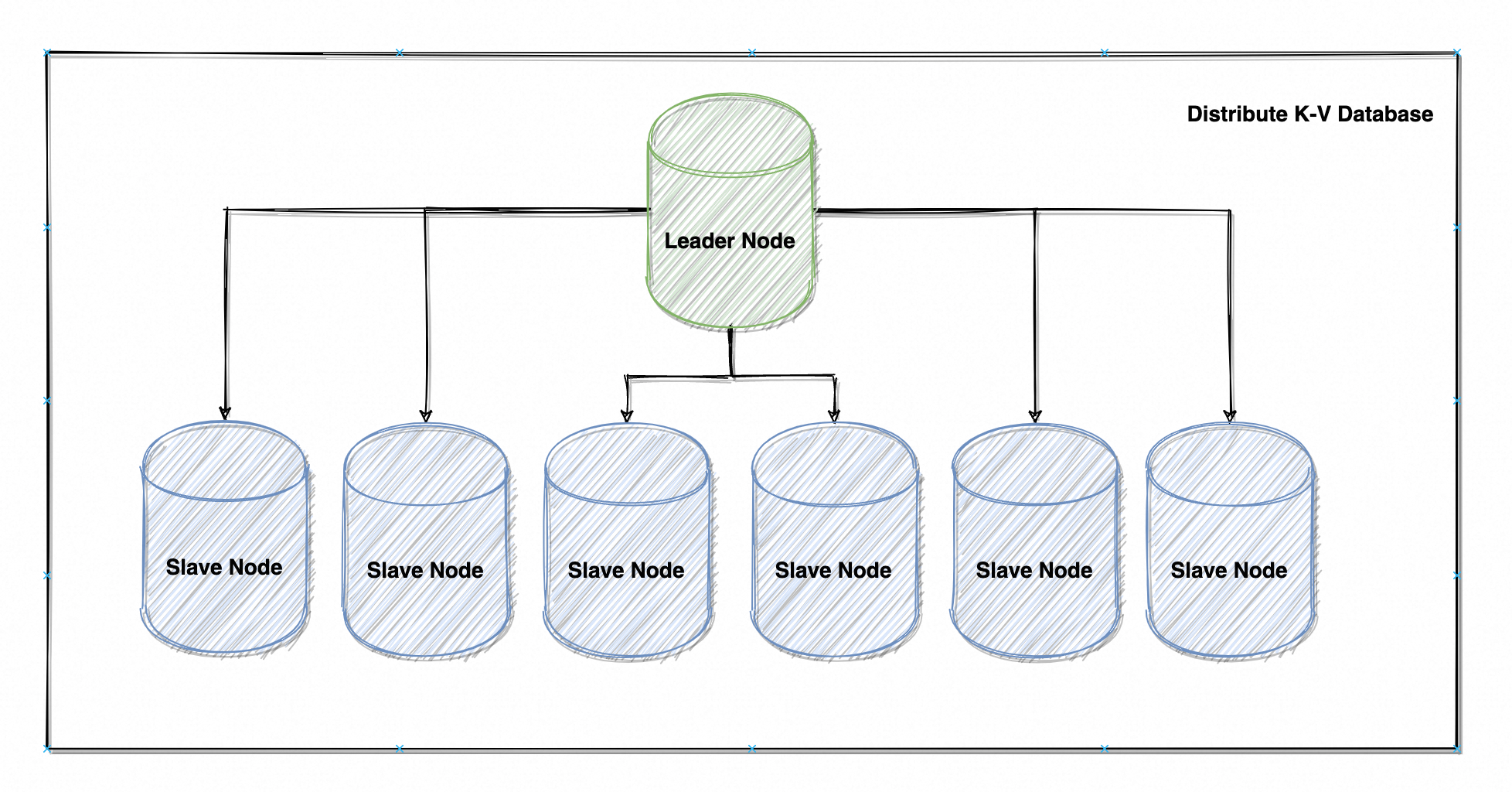
研发同学一琢磨:“俺们使用场景就是个 BBS,这讯息和帖子发出去就发出去了呗,大伙晚点读到好像也没啥吧?”确实如此,当前场景更倾向于为海量用户提供稳定可用的服务,不应该为了一致性牺牲用户体验,让用户晚点看到总比都看不到好些。
因此研发团队大手一挥,注释掉写操作的共识过程,改用**异步订阅变更事件(Binlog)保持一致** + 定时 Dump 增量/全量数据保持数据完整性及 Failover 准确性(AOF/RDB)。数据库的写入性能一下子翻了几番,异步复制虽然导致了一致性降低,但大部分时间延迟还是在毫秒级的,对用户体验影响很小,研发们又过上了幸福的日子。
好景不长,由于架构中仅主节点可写,始终存在无法扩展的单点上限,阴影又笼罩在研发团队上空。要扩展写并发,只能使得多节点可写,将架构变为「多主多从」。得,多主又来了,老生常谈的写冲突也来了,要同步处理写冲突吧就又降低了写并发、不处理或异步处理吧又有可能丢数据(你合代码应该也合错过吧。。。),有没有可能避免写入操作的冲突?
答案是有!用数据 key 的 hashcode 进行数据分片(感谢 Redis 赞助的大量思路),天然将不同数据的存储隔离开;每个分片负责一部分数据的写入和读取,你写你的我写我的,完全不存在冲突。
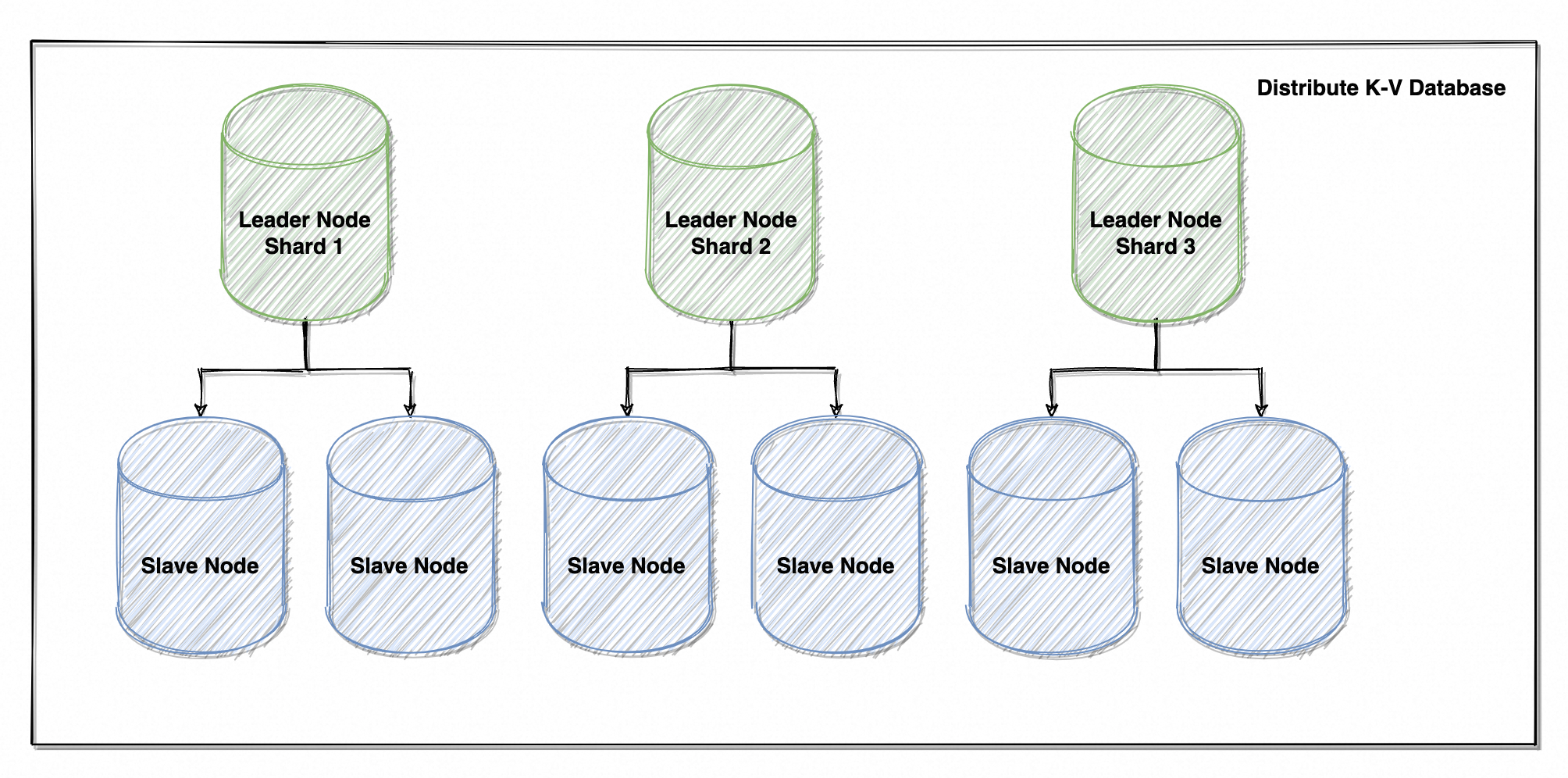
此时分片越多,数据打散得越彻底,写并发也就越高。并且主节点的数据复制压力也更小,因为单分片的数据量更少、从节点也更少。
4.4.2 单调一致性
性能上的瓶颈消失了,系统又正常运行了好一阵子。但用户体验的工单也越来越多,经常有用户反映:“帖子怎么老是时有时无,而且绝对不是被删了,一刷新就没了、再刷新又有了,还能不能用?退钱!”
研发团队开会一讨论得出结论:这就是「最终一致性」的弊端,异步复制导致每个节点的复制进度不可控,这时读取到不同节点就会呈现不同的结果。
老板一拍大腿:“读取相同数据时,将同一个用户的读取请求路由到同一个节点,就能保证数据不会乱跳了。在应用层保证同一用户只读同一节点(当然前提是节点未发生故障,故障转移场景另行讨论),用 UserId 先做个 hashcode 再取个余,用这个值来路由同一个从节点;确保同一个人读取同一个数据时、只会读到一个从实例。”
会议室一时又充满了轻松的笑声,此时架构变成了这样:
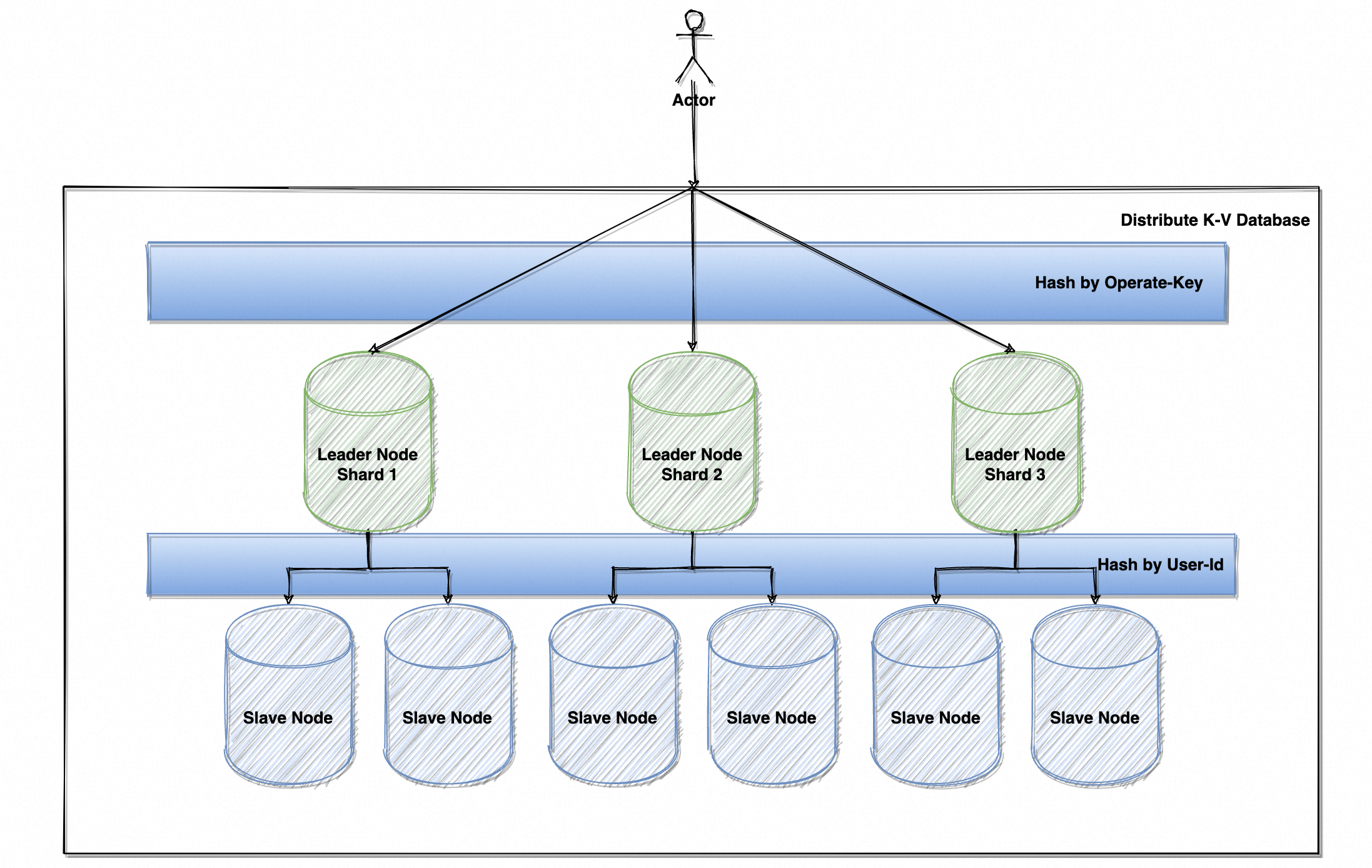
- 第一层 Hash 运算,根据读写 Key 确定数据分片;
- 第二层 Hash 运算,根据 UserId 确定读取哪个从节点。
此时,系统保证了「单调一致性」,即读操作不会读到更旧的数据。
4.4.3 读写一致性
直到有一天又接到了一个工单,用户反馈:“我刚发的帖子,下一秒就看不到了,所以我到底发了没发?大家到底能不能看到?”
问题也很明显,由于用户写主读从,读取的从节点还未完成数据复制时,就会出现写了但看不到的情况。这个延迟其实一直存在,只不过用户不知道别人写没写过,所以一直没发现别人写入的数据也存在延迟;但用户明确知道自己写过,自己的延迟就显得很刺眼。
解决方案就是让系统感知最近存在写入用户的读请求并作特殊处理,例如该用户 1 分钟内曾有过写入(这里假设主从复制的延迟最多 1 分钟,实际值可能更长或更短),就将其读取请求全部路由到主库;或者在读取前获取所有从库的同步进度,仅读取同步进度大于用户写入时间的从库。
此时,系统保证了「读写一致性」,即用户一定能立即读到自己所写的数据,但别人写的不作保证。
4.4.4 顺序一致性
最近倒是没工单了,但研发团队最近用到了 **Zookeeper **作为注册中心,听说 Zookeeper 利用 ZAB 实现强一致性,但又不是广义的强一致性而是「顺序一致性」(Raft 也满足顺序一致),于是展开了讨论。
Zookeeper 对一致性作出了如下保证:
- 全局顺序一致性:所有客户端对于写操作的观察顺序是一致的,即所有写操作按照单调递增的事务 ID(Zxid)顺序被应用。
- 内部顺序一致性:对于单个客户端,ZooKeeper 确保其操作按照发出的顺序执行。例如,如果一个客户端发起两个连续的写操作,第二个操作在第一个操作成功后才会生效。
ZAB 协议保证只有一个 Leader 节点,Follower 会将写请求按其内部顺序路由到 Leader,Leader 会以写请求到达的顺序串行处理,写请求会分配到一个单调递增的 zxid。
因此在 Zookeeper 场景下,全局顺序一致性的含义为:Zookeeper 会以 zxid 从小到大的顺序,依次处理写请求,保证所有节点看到写入的顺序一致。
内部顺序一致性的含义为:单个 Zookeeper Client 会以内部发起写入的顺序,将写请求依次有序发送到 Zookeeper Server,Zookeeper 会依次处理这些请求。
这两点结合起来就严格保证了「顺序一致性」,即系统所有操作按照相同的全局顺序执行,保证每个节点看到的操作顺序一致,并且符合单客户端的操作顺序。「顺序一致性」仅比「线性一致性」稍弱一点,后者存在全局时钟下的约束,进一步保证了相同时间下的操作顺序一致。线性一致性本身就是在顺序一致性的基础上提出的,而这也是两者间最大的差异。
4.4.5 因果一致性
需要自行捕捉读与写、写与写、读与读之间的因果关系,并合理处理这种因果关系。例如上面讲到的「读写一致性」就存在“读依赖于写”的因果关系,带有“写”因素的“读”则需要额外处理逻辑。
太复杂,并且每个场景下的因果关系与处理方式无法枚举,很难用孤例讲清楚,自己设计一个带因果的场景再尝试给出解决方案吧。
4.4.6 总结
文中提到的非线性一致性本质上都是弱一致性,只是除了「最终一致性」以外的一致性都增加了符合文中场景的**偏序约束**:
- 「单调一致性」保证了同一 UserId 下读操作序列的单调性,该偏序仅在 UserId 可比场景生效;
- 「读写一致性」保证了 UserId + Last Write Timestamp 下读写序列的单调性,该偏序仅在 UserId + Last Write Timestamp 可比场景生效;
- 「顺序一致性」保证了全局操作顺序下的读写序列单调性,该偏序仅在全局操作顺序可比场景生效。
而「线性一致性」则是在全局时钟 + 全局操作顺序等等所有场景下生效,而不是限定部分可比场景、再宣布在该场景下生效。这是一种完备的**全序约束**,但实现起来十分困难。
简言之,「最终一致性」不对“系统最终一定会达到一致”以外的任何一致性作保证,其他「弱一致性」会**对部分场景作一致性保证,「强一致性/线性一致性」对所有场景作一致性保证**。
一致性的逐级有序,也意味着系统复杂度的不断提高、其必定伴随着性能的降低,但这都是系统对于不得不满足的使用场景的权衡(Trade-Off)。于一个分布式系统而言,一致性与可用性的设计并不是单纯的 1 和 0,两者也不是零和博弈关系,你可以在任何粒度划定不同的一致性等级,而该等级或多或少会影响系统的可用性。
这便是一致性&可用性权衡的艺术。
5 可用性
前文花了大量篇幅讲述一致性的概念及特性,似乎可用性没有被放在相同的高度。但请你千万不要产生误会,两者在分布式系统设计中相辅相成,抛开可用性去谈一致性毫无意义。只是由于示例的出发点不同,假设了系统先对一致性有要求,可用性自然会成为为其让步的配角。
那么到底有多可用才算是可用?
5.1 可用性定义
对大型互联网企业而言,通常不希望应用存在不可用时段,因为给出了 99.9999999 的山盟海誓。毕竟系统能用但是会出错还有弥补的空间,直接不可用那就真透心凉了(支付系统除外,出错了怎么弥补简直不敢想)。
「可用性」的定义就比较单纯了,确保每个请求正常响应即可(注意超时和返回异常不算正常响应,指能够正常执行业务逻辑)。并且有量化的计算公式(其中 MTBF 为「平均故障间隔时间」,MTTR 为「平均修复时间」):
A
=
M
T
B
F
M
T
B
F
+
M
T
T
R
A = \frac{MTBF}{MTBF + MTTR}
A=MTBF+MTTRMTBF
在笔者看来,可用性其实是一个不太好单独定义的概念。近现代的服务架构基本都是集群,通常可以认为做到了节点冗余、限流、降级、熔断此类特性,就具备了事实上的可用性。但如果只要能响应请求就算可用,那相当于没有给使用者任何承诺;因此还是需要结合一致性和网络分区,综合讨论系统在怎样的场景下、需要舍弃什么、最终来保持可用。
5.2 可用性设计
事实上,通常不由研发人员在系统中进行一致性与可用性的设计,而是直接引入中间件解决——将系统的问题转嫁到中间件头上,俗称「故障转移」。首先是因为确实没必要重复造轮子(更何况你有人家造得好吗),从底层做起效率太低;其次是想要达到生产可用,章节「4.4 弱一致性」中的设计过程连打地基都算不上,实际系统中的每个问题如负载均衡、Failover、扩缩容、网络异常等,都是一个巨大的命题。
CAP 理论一再强调,不存在完美一致性与可用性的系统,只能在两者间进行权衡。了解不同中间件对可用性与一致性作出的承诺、选择合适的中间件、设计合理的应用层补偿,在笔者看来是比较科学的设计方案。
5.3 分布式中间件解析
优秀的现代中间件应当明确告知使用者,系统所支持的一致性/可用性等级,甚至给使用者选择不同等级的权利。本章便抛砖引玉,就几个常用的分布式中间件,深度讨论其一致性/可用性等级,以及该等级所适配的使用场景。
5.3.1 Zookeeper
- Consistency:写线性一致性、读顺序一致性/线性一致性;
- Availability:仅主从选举(Fast Election)期间不可用;
- Partition Tolerance:允许 2N + 1 中的 N 个节点不可用;
- 支持 CP;
章节「4.2.3 ZAB」对 Zookeeper 的核心内容「Zookeeper 原子广播」作了基本介绍,Zookeeper 保证系统中只会有一个 Leader 节点,所有写操作都由 Leader 处理,因此天然保证写操作线性一致。章节「4.4.4 顺序一致性」介绍顺序一致性的定义时提到,Zookeeper 确保所有节点看到一致且正确的读写序列,保证了全局/内部顺序一致。
本章着重介绍 Zookeeper 如何保证全局/内部顺序一致性。
5.3.1.1 全局顺序一致性
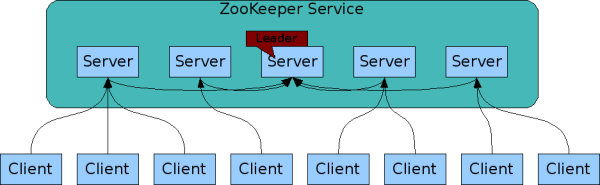
Client 发起的写操作会被路由到 Leader 节点(如图 18),Leader 节点会以写操作到达的顺序赋予单调递增的 zxid,并依次发起提案。提案的发起流程天然保证有序(基于 TCP 请求队列),但提案的处理需要等待多数节点 ACK,不可能等前一个提案全部 ACK + Commit 以后再处理下一个,严格的串行效率太低,因此提案处理过程中还是有并发操作存在的。
Zookeeper 以 zxid 顺序发起提案,此时提案处于 Prepare 状态,提案会记录在一个 ConcurrentHashMap 中,名为 outstandingProposals,意为「未完成提案」;这个 map 会存放所有还未 Commit 的提案,key 为 zxid、value 为提案本身,此时这些提案会处于“等待大多数 Follower ACK”的状态。
每当 Follower 就一个提案返回 ACK 时,Leader 会在 outstandingProposals 中找到该提案对 ACK++ 并尝试提交,提交会进行如下判断
- 判断该提案之前是否还有未提交提案,即当前提案 zxid 是否为 outstandingProposals 中最小的 zxid;
- 判断该提案是否被大多数节点 ACK;
- 如两条件都满足,则从 outstandingProposals 中清除、应用到自身(写入内存,名为 dataTree 的 ConcurrentHashMap)、广播到所有 Follower 节点。
重点在第 1 点判断,zxid 从小到大依次被提出,保证相同顺序 Commit 就保证了事务有序。如果 outstandingProposals 的 keys 中仍存在更小的 zxid,说明还有更早提出的 Proposal 未被提交;此时哪怕当前 Proposal 已具备 Commit 条件,也应当阻塞等待直至其成为最小 zxid。
Leader 会为每个 Follower 维护一个 FIFO 的阻塞队列,Proposal Commit 请求会放入该队列,Leader 不断从该队列中取出 Proposal 并广播给 Follower。
这样就一定能够保证每个节点看到相同的写入顺序,即实现了「全局顺序一致性」。
5.3.1.2 内部顺序一致性
保证了全局顺序一致性还不够,如果同一个 Client 先后发起 Write(x, 1)、Write(x, 2),而 Zookeeper 无法保证按顺序处理,就可能出现最终 Read(x, 1)。即使所有节点都先看到 2 再看到 1,全局顺序保持一致,但对这个 Client 来说显然是不合理的。
直接上代码,看看 Zookeeper Client 如何创建一个 ZNode。
/**
* same as {@link #create(String, byte[], List, CreateMode, Stat)} but
* allows for specifying a TTL when mode is {@link CreateMode#PERSISTENT_WITH_TTL}
* or {@link CreateMode#PERSISTENT_SEQUENTIAL_WITH_TTL}. If the znode has not been modified
* within the given TTL, it will be deleted once it has no children. The TTL unit is
* milliseconds and must be greater than 0 and less than or equal to
* {@link EphemeralType#maxValue()} for {@link EphemeralType#TTL}.
*/
public String create(
final String path,
byte[] data,
List<ACL> acl,
CreateMode createMode,
Stat stat,
long ttl) throws KeeperException, InterruptedException {
final String clientPath = path;
PathUtils.validatePath(clientPath, createMode.isSequential());
EphemeralType.validateTTL(createMode, ttl);
validateACL(acl);
final String serverPath = prependChroot(clientPath);
RequestHeader h = new RequestHeader();
setCreateHeader(createMode, h);
Create2Response response = new Create2Response();
Record record = makeCreateRecord(createMode, serverPath, data, acl, ttl);
ReplyHeader r = cnxn.submitRequest(h, record, response, null);
if (r.getErr() != 0) {
throw KeeperException.create(KeeperException.Code.get(r.getErr()), clientPath);
}
if (stat != null) {
DataTree.copyStat(response.getStat(), stat);
}
if (cnxn.chrootPath == null) {
return response.getPath();
} else {
return response.getPath().substring(cnxn.chrootPath.length());
}
}
如上代码块主要做了一些参数拼装和校验,构建请求头 RequestHeader、一个空的响应对象 Create2Response、以及包含请求参数的 Record 对象,这几个类都实现了 Record 接口;该接口用于序列化与反序列化,Zookeeper 基本都是靠它进行通讯传输的。之后调用 submitRequest 方法提交请求。
/**
* These are the packets that need to be sent.
*/
private final LinkedBlockingDeque<Packet> outgoingQueue = new LinkedBlockingDeque<Packet>();
public ReplyHeader submitRequest(
RequestHeader h,
Record request,
Record response,
WatchRegistration watchRegistration,
WatchDeregistration watchDeregistration) throws InterruptedException {
ReplyHeader r = new ReplyHeader();
Packet packet = queuePacket(
h,
r,
request,
response,
null,
null,
null,
null,
watchRegistration,
watchDeregistration);
synchronized (packet) {
if (requestTimeout > 0) {
// Wait for request completion with timeout
waitForPacketFinish(r, packet);
} else {
// Wait for request completion infinitely
while (!packet.finished) {
packet.wait();
}
}
}
if (r.getErr() == Code.REQUESTTIMEOUT.intValue()) {
sendThread.cleanAndNotifyState();
}
return r;
}
//org.apache.zookeeper.ClientCnxn#queuePacket(org.apache.zookeeper.proto.RequestHeader, org.apache.zookeeper.proto.ReplyHeader, org.apache.jute.Record, org.apache.jute.Record, org.apache.zookeeper.AsyncCallback, java.lang.String, java.lang.String, java.lang.Object, org.apache.zookeeper.ZooKeeper.WatchRegistration, org.apache.zookeeper.WatchDeregistration)
public Packet queuePacket(
RequestHeader h,
ReplyHeader r,
Record request,
Record response,
AsyncCallback cb,
String clientPath,
String serverPath,
Object ctx,
WatchRegistration watchRegistration,
WatchDeregistration watchDeregistration) {
Packet packet = null;
// Note that we do not generate the Xid for the packet yet. It is
// generated later at send-time, by an implementation of ClientCnxnSocket::doIO(),
// where the packet is actually sent.
packet = new Packet(h, r, request, response, watchRegistration);
packet.cb = cb;
packet.ctx = ctx;
packet.clientPath = clientPath;
packet.serverPath = serverPath;
packet.watchDeregistration = watchDeregistration;
// The synchronized block here is for two purpose:
// 1. synchronize with the final cleanup() in SendThread.run() to avoid race
// 2. synchronized against each packet. So if a closeSession packet is added,
// later packet will be notified.
synchronized (state) {
if (!state.isAlive() || closing) {
conLossPacket(packet);
} else {
// If the client is asking to close the session then
// mark as closing
if (h.getType() == OpCode.closeSession) {
closing = true;
}
outgoingQueue.add(packet);
}
}
sendThread.getClientCnxnSocket().packetAdded();
return packet;
}
调用 queuePacket 方法将所有信息包装成一个 Packet,并放入 outgoingQueue 阻塞队列(LinkedBlockingDeque);Zookeeper 的 SendThread 不断从队列中取出 Packet 并发往 Server,保证取出顺序与消费顺序相同,且先提交的一定先完成。再由提交 Packet 的线程不断轮询 Packet 的执行状态(finished 属性),阻塞至该 Packet(也就是该请求)完成。
可以发现 Zookeeper 大量使用 FIFO 阻塞队列以及异步事件机制,提高性能的同时将各个阶段解耦,并且非常自然的支持了内部与全局的顺序。Zookeeper 所支持的 InBackground/InForeground(即异步与同步)模式,便是基于这套天然的异步事件机制实现的。
5.3.1.3 强制同步 sync
Zookeeper 支持顺序一致性读,因为 Proposal 只需要被大部分节点 ACK 就认为写入完成,此时读取到未完成 ACK 的节点自然读取不到,这种场景下的读对一致性没有什么实质性的保障。
Zookeeper 也深谙其道,提供了强保障一致性的 API:sync()。
sync 方法本质上就是一个写请求,与上文介绍的线性一致性写流程基本一致。不同的是,Server 在接收 sync 请求后会阻塞读请求、直至 sync 请求返回成功;而 sync 请求本质是写请求,它响应意味着前面所有写请求已成功 Commit,如此一来保证了所有读请求、一定建立在 sync 完成后的副本。
因此,如果你需要强一致性的读取,可以先调用 sync() 再进行读操作。但显然 sync 是一个相当重的操作,它需要与 Leader 产生交互,还会阻塞读操作,非强一致场景不建议使用。
5.3.1.4 使用场景
- 分布式锁:写操作线性一致 + 有序节点。
- 分布式队列/同步器:写操作线性一致 + Watcher 机制。
- 元数据/配置中心:支持顺序/线性一致性读。
- 注册中心:写操作线性一致 + 临时节点。
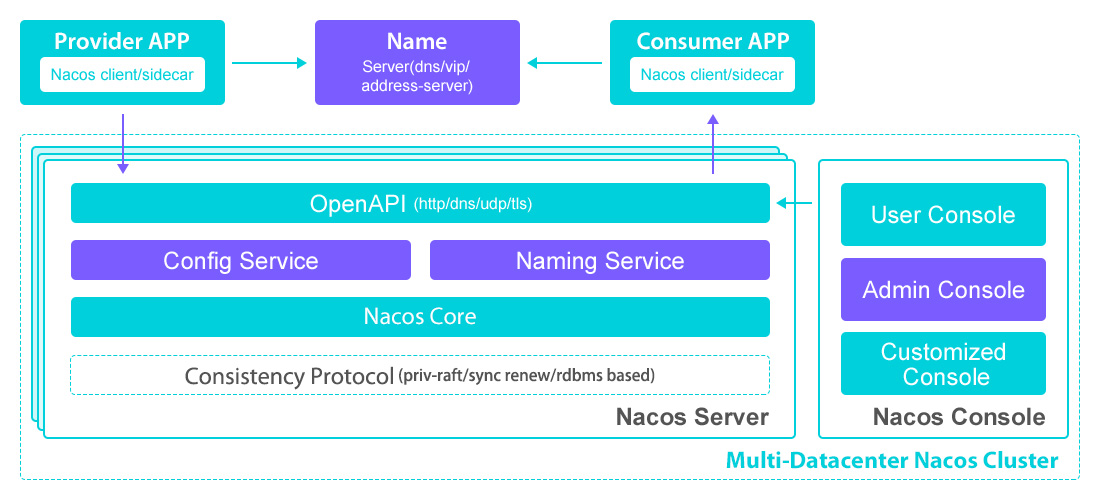
5.3.2 Nacos
- Consistency:AP 模式最终一致性, CP 模式线性一致性;
- Availability:AP 模式保证高可用,CP 模式选举期间不可用;
- Partition Tolerance:AP 模式支持全死,CP 模式允许 2N + 1 中的 N 个节点不可用;
- 支持 AP/CP;
作为同样优秀的现代注册/配置中心,Nacos 给了使用者充分的想象空间,可以在 AP 与 CP 之间自由选择。
5.3.2.1 AP & Distro 算法
注册中心无疑是分布式环境核心组件之一,哪怕再短暂的不可用时间也会变得十分致命。
想象一下,注册中心内部出现了网络分区,Client 拿不到服务元数据(例如服务名、对应的 IP 地址、以及健康状态),这直接导致了你的系统在这段时间内无法发起任何 RPC 请求。而分布式环境仰仗的便是服务间的网络通讯,这意味着你的系统直接宕机了。
笔者听着都冒冷汗,因此注册中心使用场景不太能接受不可用时间,一致性反而显得没那么重要。假设系统强依赖 Zookeeper 作为注册中心,在网络分区时常出现的前提下,一不留神 Zookeeper 就会发起重新选举,选举期间是无法响应任何请求的。
而 Nacos 的 AP 模式采用自研的「Distro 算法」,实现了高可用性的最终一致,并采用了各种补偿手段提高数据一致性。Distro 算法下的 Nacos 本质上是「多主复制」模型,跟本文示例分布式数据库的第一版类似,所有节点均可响应写请求,并且会将请求路由到真正处理写的节点(类似分片的概念)。不同之处在于 Distro 算法采用异步复制,因此只保证最终一致性;还增加了节点定时自检,与其他节点的数据进行对比,如不一致则发起全量数据拉取,进一步保证了数据一致性。
AP 模式下的 Nacos 所有节点可响应写(写请求路由到具体节点),所有节点可响应读(所有节点具有全量数据,但仅满足最终一致性)。在网络分区出现时仍然可以响应读写请求,满足高可用性;甚至 Client 还有一份兜底缓存,即使 Nacos 整个宕掉也可以先使用本地的缓存,是非常优秀的注册中心。
5.3.2.2 CP & Raft 算法
CP 模式下采用仅 Leader 节点可写 + 主从复制,使用了基于 Raft 魔改的「JRaft 算法」,上文已介绍过就不作赘述了。
值得一提的是,得益于底层的一致性模块解耦(如图 19 最底层的 Consistency Protocol 模块),Nacos 支持“不同命名空间(Namespace)使用不同一致性等级”的灵活玩法;例如 Configuration 命名空间使用 CP、Registry 命名空间使用 AP,灵活性不可谓不高。
5.3.2.3 使用场景
- 元数据/配置中心:CP 模式支持线性一致性。
- 注册中心:AP 模式支持高可用 + Client 本地缓存。
5.3.3 Kafka
- Consistency:可配置最终一致性、线性一致性;
- Availability:高可用;
- Partition Tolerance:理论上支持单节点也可用;
为什么这里要探讨 Kafka 的一致性与可用性?
因为对于分布式流式处理引擎/消息队列而言,元素的顺序消费是极为关键的特性——例如两个元素的消费存在因果关系(如上文讨论的因果一致性),元素 A 代表订单生成事件、元素 B 代表订单支付事件,此时元素 B 则具有了“元素 A 先被消费完成”的因果关系。如果 Kafka 不能保证这样的顺序与因果关系,显然会大幅增加使用者的心智负担。
并且消息队列通常作为「持久化存储介质」存乎于服务中间层,其可靠性与安全性的重要程度不言而喻。俗话说就是它需要保证消息不丢失、不重复,以及尽可能高的可用性,即使在节点宕机或网络分区的情况下。

5.3.3.1 可用性 & 一致性
Kafka 是一个典型的分布式系统(如图 20),用多节点横向扩展确保高吞吐,系统由多个「Broker 代理者」组成,每个 Broker 就是一个节点,可以独立处理 Producer 的消息写入与 Consumer 的消息拉取。Broker 越多,Topic 的 Partition 便可以越发散地分布于各节点上,读写并发量也就越高。
每个 Topic(主题)以 Key Hash(或其他算法,由 Partitioner 模块负责)划分为物理意义上的多个 Partition(分区),Partition 会均匀分布在 Broker(代理者/节点)上。为了安全性考虑,Partition 会拥有多个数据副本(默认为 1 即无副本,支持配置副本数),副本会冗余在其他 Broker 上;读写由 Leader 副本响应,Replica 副本会定时拉取数据,确保数据与主副本保持一致。
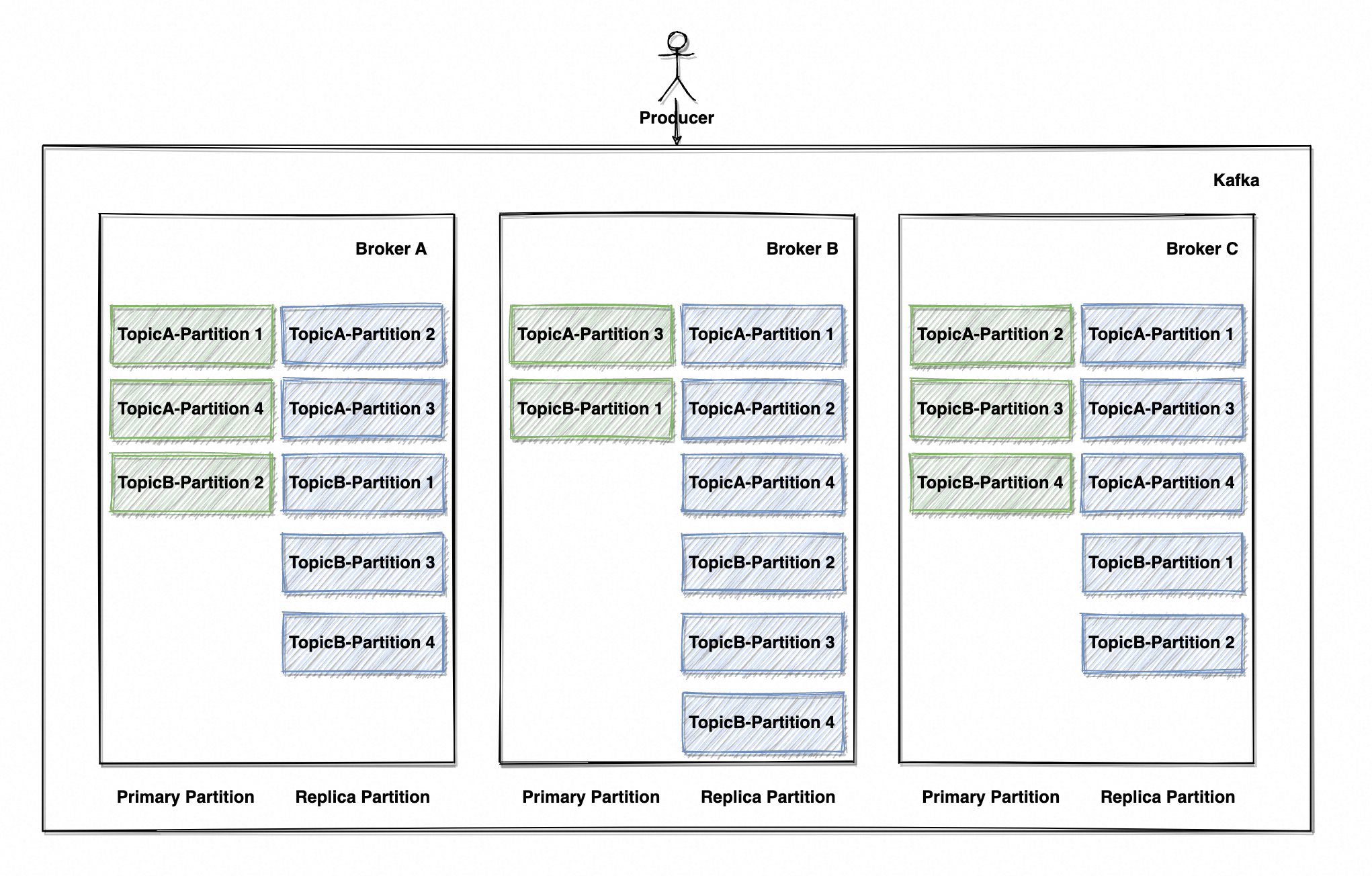
但网络是不可靠的,节点异常与网络分区时常出现,要确保消息不丢失不重复,在消息发送阶段便要作出一些保证。因此 Kafka 提供 3 种 ACK 模式:
- ACKS = 0:不等待 Broker 返回成功,Producer 直接认为发送成功;高吞吐但安全性不佳。
- ACKS = 1:Broker 写入 Leader 副本成功,即返回 Producer 写入成功;吞吐与安全性较为平衡,为缺省配置。
- ACKS = -1:Broker 写入 Leader 副本、并同步到所有 Follower 副本后,返回写入成功;最强一致性保障,但吞吐较差。
确保消息发出去、并且确保副本数据复制的进度越快,也就确保了可靠性。又是经典的一致性与可用性的取舍问题,显然更严格的一致性保证就意味着更低的性能。
ACKS = 0/1 时本质上对数据一致性是没有什么保证的,0 就不必多说了,1 在刚写入 Leader 副本、Replica 还未来得及同步时 Broker 挂掉,消息一定会丢失。因此如果对一致性有严格要求,是一定要配置 ACK = -1 的。
而在这之上,Kafka 提供了更加折中且灵活的方式来保障一致性:
- In-Sync Replicas 同步副本:简称 ISR,与 Leader 保持数据同步的副本信息。值得注意的是,并非完全一致才认为状态同步,这种要求相当于线性一致,太难实现且性能较差;有一个同步判断阈值,如 offset 相差多少以内、或延迟时间在多少 ms,均支持配置。
- Out-of-Sync Replicas 未同步副本:简称 OSR,与 ISR 概念相对应,同步进度较慢的副本信息。副本会随时被踢出 ISR、进入 OSR,赶上进度后又可能加入 ISR。
- Log End Offset 日志最大偏移量:简称 LEO,节点已写入消息日志偏移量,简言之写入多少条日志偏移量就是多少。
- High Watermark 高水位:简称 HW,所有 ISR 节点中 LEO 的最小值,即短板原理,该值代表了所有副本数据同步的进度;Consumer 只能读到 Leader 副本的 HW Offset,因为写入成功不代表同步成功,同步成功才可读取。HW ≤ LEO。
在 ACKS = -1 的情况下,写消息操作需要等 Leader 的 ISR 节点全部完成复制才算成功。ISR 节点的数量是动态变化的,如果没有任何节点与 Leader 保持同步(即 ISR 为空),写入 Leader 就返回照样会丢数据。此时就需要配置 ISR 最小数量 ≥ 2,最起码要有 2 个 ISR(包含 Leader 副本本身)节点、即除了 Leader 还要有一个副本完成同步,才能保证数据可靠性。

Failover 期间会从 ISR 节点中选取一个升格为 Leader 副本,ISR 节点具有最新进度的数据副本,最大程度减少了服务不可用时间的同时、保障了服务可用性。甚至 Leader 选举模式也支持配置,默认情况下使用 Max LEO + Raft 算法的大多数共识,可以配置成上述的选举方式。
这也是为何 Kafka 的可用性与一致性一定得放在一起看,因为它真的太他妈 nb 了,基本所有能权衡的点都交由使用者选择。
5.3.3.2 顺序性
Kafka 的**每个分区本质是一个 Append-Only 的日志,其设计天然保证了顺序写入;Consumer 只需要按顺序读取分区,便可以保证消息的有序性。Kafka 强制每个 Partition 只能由一个 Consumer(也就是一个线程)消费**,也就保障了消息有序消费。
但 Kafka 只保证单分区内有序,分区间是无序的,因此需要根据业务场景设计合理的分区 key,例如时间戳、订单 id、商品 id等。
5.3.3.3 使用场景
- 流式数据通道
- 消息队列
6 结语
分布式系统设计需要在一致性、可用性和分区容错性之间不断权衡,随着技术不断进步和应用场景扩展发起一轮又一轮新的重构与升级,这也正是分布式系统的挑战和魅力所在。先驱们所留下的无数宝物,会成为解决问题的利刃,但同时也希望这柄利刃不会伤到你,也不会伤到你的绩效。
希望这篇文章能为你提供新的见地,或多或少为你排除几个错误答案,能在工作和学习中应对分布式系统问题就最好不过了。
最后,感谢你认真的看到这里,笔者相信这只是你踏入分布式领域的第一步,祝愿你不断发现和创造新的可能。
共勉。
7 参考文献
- 《Designing Data-Intensive Application》:DDIA,强烈推荐,神书
- In Search of an Understandable Consensus Algorithm:https://raft.github.io/raft.pdf
- Wait-Free Synchronization:https://cs.brown.edu/~mph/Herlihy91/p124-herlihy.pdf,讲多核处理器无锁数据同步的,老实说没看懂
- 图解 Raft:http://thesecretlivesofdata.com/raft/?spm=ata.21736010.0.0.2c557536TZaILs#election
- MIT 6.824 - 8.1 Linearizability:8.1 线性一致(Linearizability)(1) | MIT6.824 (gitbook.io)
- Replication:事务,一致性与共识:https://zhuanlan.zhihu.com/p/560246401?utm_id=0
- etcd 线性一致性读:https://www.cnblogs.com/ricklz/p/15204381.html#:~:text=%E7%BA%BF%E6%80%A7%E4%B8%80%E8%87%B4%E6%80%A7%E8%AF%BB.%201%E3%80%81
- Zookeeper:https://zookeeper.apache.org/doc/current/zookeeperOver.html
- Nacos:https://nacos.io/zh-cn/docs/v2/architecture.html
- Apache Kafka:https://kafka.apache.org/documentation/#brokerconfigs_min.insync.replicas
- 全序关系和偏序关系的区别是什么? - Jiaheng Zhuang的回答 - 知乎https://www.zhihu.com/question/36758436/answer/2296723661


![P3631 [APIO2011] 方格染色](https://i-blog.csdnimg.cn/direct/79efe704570d425ab663d6a3fc4393c0.png#pic_center)