震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集
Abstract
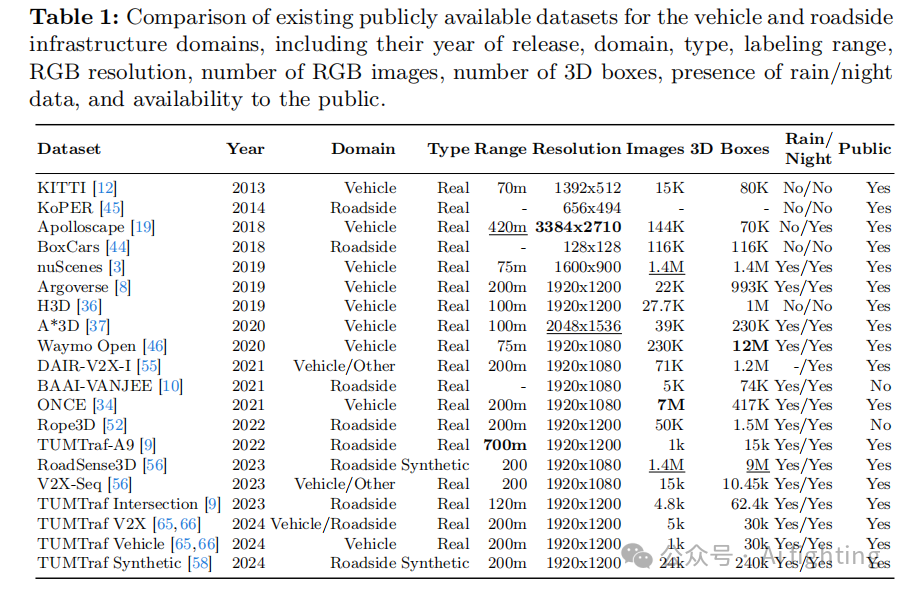
由于摄像机视角多变和场景条件不可预测,在动态路边场景中从单目图像中准确检测三维物体仍然是一个具有挑战性的问题。本文介绍了一种两阶段的训练策略来应对这些挑战。我们的方法首先在大规模合成数据集RoadSense3D上训练模型,该数据集提供了多样化的场景以实现稳健的特征学习。随后,我们在真实世界数据集的组合上微调模型,以增强其对实际条件的适应能力。Cube R-CNN模型在具有挑战性的公共基准数据集上的实验结果显示,检测性能显著提高,在TUM Traffic A9 Highway数据集上的平均精度从0.26提高到12.76,在DAIR-V2X-I数据集上的平均精度从2.09提高到6.60。
代码及数据获取:https://roadsense3d.github.io
Introduction
深度学习的最新进展激发了人们对2D/3D物体检测方法的浓厚兴趣。传统的一步和两步2D物体检测方法主要分析像素级信息。然而,仅提供2D检测的方法在提供物体与自车之间的精确实际距离测量方面存在局限性。这一局限性突显了对场景更全面理解的必要性以及发展先进的3D物体检测能力的需求。为了提高模型的泛化能力,研究者们尝试将模型在多个数据集上进行训练,以增强其在不同城市环境中的表现。例如,MonoUNI模型通过集成车辆和基础设施数据,提高了远程感知能力。
虽然这些模型在典型的(驾驶)条件下表现出高精度,但当遇到诸如车辆倾斜或因事故而翻覆等路边场景时,其性能显著下降,这主要是由于数据标注过程的局限性。具体来说,大多数自动驾驶模型主要依赖于偏航角,通常忽略横滚和俯仰角度,因为它们为零。然而,这些角度在准确检测略有提升的物体(如路边场景中的物体)时至关重要。为了解决这些局限性,本文中我们使用Cube R-CNN模型进行了综合迁移学习实验,从合成数据集RoadSense3D过渡到真实世界数据集TUM Traffic A9 Highway(TUMTraf-A9和DAIR-V2X-I。在这些实验中,我们在训练和测试阶段都引入了俯仰和横滚角度。真实世界数据集来自多个城市,每个城市的基础设施配置各不相同,确保模型暴露于广泛的城市环境中以改善泛化性能。通过对这三个真实世界数据集的广泛评估,我们证明了从模拟场景到真实场景的迁移学习将TUMTraf-A9数据集上的3D mAP结果从0.26提高到12.76,将DAIR-V2X-I数据集的结果从2.09提高到6.60。
3.Method
本节首先从数学上对基于单目相机的 3D 物体检测任务进行公式化描述。接下来,我们根据路边场景介绍模型选择过程。然后,我们描述了使用合成数据的初始训练过程,其中包括详细介绍数据集和从头开始训练模型的方法。接着,我们详细介绍了微调阶段,讨论了所选的真实世界数据集以及微调过程中的技术细节。
3.1 问题定义
基于图像的 3D 物体检测涉及根据相机捕捉的二维图像确定物体在三维空间中的位置和形状。为了解决这个问题,我们旨在学习一个函数,该函数由参数θ表示,将二维 RGB 图像映射到一组 3D 物体属性,其中
![]()
代表具有高度 H、宽度 W 和相应相机参数的图像集。具体来说,对于每个图像 i,模型输出每个检测到的物体 j 的属性:类别、3D 位置坐标
![]()
、尺寸
![]()
以及偏航-俯仰-滚动角度
![]()
这个过程可以公式化为:
![]()
其中表示图像 i 中检测到的物体数量。为了学习一个生成这些 3D 物体属性的函数,我们使用了包含带注释 3D 边界框图像的数据集 D (M = |D|)。训练数据集中的每个条目包括一个图像 i 及其对应的真实属性
![]()
,其中,星号表示真实值。训练目标是优化函数的参数𝜃,以准确预测这些属性。换句话说,我们的目标是最小化给定真实标注时预测的损失。形式化地表示为:
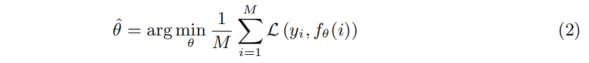
损失函数L是类别损失
![]()
、位置损失
![]()
、尺寸损失
![]()
和方向损失
![]()
的加权组合。训练过程的目标是找到最小化数据集 D 上这个复合损失的函数参数 θ。通过这样做,该函数可以从二维图像中生成准确的类别、位置、尺寸和方向,从而解决目标任务。
3.2 模型选择
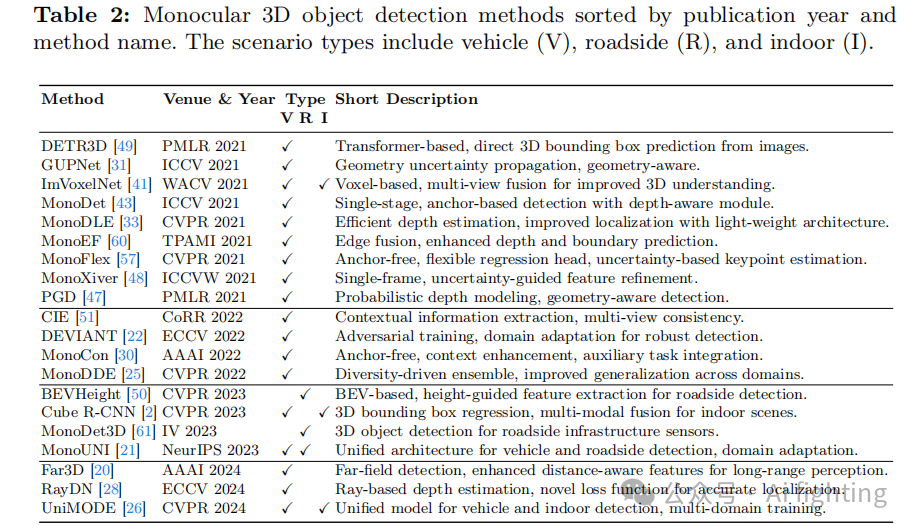
为了选择基于图像的3D物体检测方法,本文对自 2021 年以来的顶级计算机视觉会议(例如 ECCV、CVPR、ICCV)和期刊(例如 IEEE 模式分析与机器智能汇刊,T-PAMI)进行了广泛的审查。本文的审查特别关注那些利用端到端架构的模型,避免依赖辅助网络进行深度提取的模型。我们还优先考虑了在多个数据集上表现出强大性能的模型。我们的选择标准包括模型在不同任务中的领域适应能力和适用性(见表 2)。经过严格的评估,我们确定了四个值得进一步考虑的模型:MonoUNI 、ImVoxelNet、Cube R-CNN 和 UniMODE。其中,由于 Cube R-CNN 的显著可重现性和统一的训练流程,我们选择了它进行实验。与 UniMODE 由于训练流程的局限性被排除相比,Cube R-CNN 集成了多个相机坐标系,并在处理物体六自由度方向时表现出鲁棒性。与依赖于数据集特定训练策略的 ImVoxelNet 和 MonoUNI 不同,Cube R-CNN 在各个数据集上都能有效地工作而不妥协性能。从架构角度来看,Cube R-CNN 基于 Faster R-CNN 框架 ,这是一种端到端的基于区域的目标检测方法。Faster R-CNN 使用一个主干网络,通常是卷积神经网络 (CNN),将输入图像转换为高维特征表示。区域建议网络 (RPN) 随后生成感兴趣区域 (ROIs),标识图像中潜在的目标候选区域。这些 ROIs 由一个二维边框头处理,利用主干网络的特征图对目标进行分类并优化二维边界框预测。然后,每个检测到的物体应用一个立方体头来计算 3D 参数,包括中心点投影、深度、缩放尺寸和以物体为中心的方向。
3.3 初始模型创建
合成数据集选择。在我们的实验中,我们使用了 RoadSense3D合成数据集,该数据集包含超过 900 万个标注的 3D 物体和 140 万个帧用于模型训练。如表 1 所示,该数据集提供了从 CARLA 模拟器中的七个不同城镇的 35 个路边摄像头生成的各种场景的多样化数据。关键参数包括 1920x1080 图像分辨率、每个位置 40,448 帧、摄像头俯仰角度从 -25° 到 -45°、150 米的检测范围和 120° 的视场角。为了模拟现实条件,数据集包含了天气(晴天、多云、雾天)和一天中的不同时间(白天/夜晚)的变化。我们选择了 RoadSense3D 数据集,因为缺乏提供足够路边环境数据的大型真实数据集。实际上,尽管像 Rope3D 这样的数据集包含数百万张真实世界图像,但它们并未公开可用。从头开始训练模型需要大量数据,而在这个领域,现实世界中标注数据的获取并不容易,因为标注成本高,且往往需要手动标注工作 。考虑到这一点,在人工数据集中,RoadSense3D 是当前最大的合成数据集,提供了各种因素的全面覆盖。从头开始训练。我们在 RoadSense3D 合成数据集上训练了 Cube R-CNN,以应对物体姿势变化问题。该数据集是序列化的,多张图像包含了不同位置的相同物体。这种策略允许模型遇到各种物体、位置和遮挡场景。根据原始论文的描述,我们将数据集划分为训练集、验证集和测试集。模型在单个 GPU 上训练了 250,000 次迭代,使用批量大小为 4 和学习率为 0.0025 的设置。我们使用随机梯度下降 (SGD) 优化器,并每 10,000 次迭代进行一次模型评估。这些超参数的选择是为了应对原始 Cube R-CNN 模型训练中观察到的不一致性。图 1 展示了定性结果。

3.4 预训练模型迁移
实际数据集选择。为了使Cube R-CNN模型能够泛化到现实场景中,我们对其进行了微调,选择了多个具有不同摄像机设置和环境条件的多样化数据集。由于其公开可用性和规模,我们选择了TUMTraf-A9和DAIR-V2X-I数据集。TUMTraf-A9数据集是TUMTraf数据集家族的一个子集,捕捉了德国慕尼黑高速公路场景中复杂的天气和光照条件。它包括1,000个标注帧,含有15,000个3D边界框和跟踪ID,数据来自LiDAR和多视图摄像头,使用了16mm和50mm焦距来监控11条车道的交通。DAIR-V2X-I数据集收集于中国,代表了一个大规模的车路协同自动驾驶数据集,提供了超过71,000个来自基础设施和车辆视角的LiDAR和摄像头帧。
对于DAIR-V2X-I数据集,需要进行预处理,因为其提供的目标注释是在LiDAR坐标系中。由于Cube R-CNN在摄像头坐标系中操作,我们首先将注释从LiDAR坐标系转换到摄像头坐标系。在LiDAR系统中,注释指定了目标在七个自由度上的位置、尺寸和偏航旋转。当将这些注释投影到摄像机的视图中时,必须考虑目标相对于摄像机的旋转。这包括围绕三个轴投影注释。转换过程遵循方程:
![]()
,其中内参矩阵𝐾和外参矩阵𝑇被用于将世界坐标系中的3D点 (X, Y, Z) 投影到摄像头坐标系中的2D点 (x, y) 上。变量𝑤在此转换中作为一个缩放因子,确保点正确地投影到摄像头视图中。然后,我们使用60/40的比例进行训练和测试。对于测试,我们使用了来自V2X-Seq的顺序感知数据。对于TUMTraf-A9数据集,我们也采用了相同的60/40比例进行训练和测试,使用了来自北部和南部摄像头的数据,并结合了小焦距和大焦距的数据。
Experiment
在本节中,我们展示了从合成数据到真实数据迁移学习实验的结果。首先,我们考察了从RoadSense3D到TUMTraf-A9和DAIR-V2X-I的单步数据集迁移的影响。接下来,我们探索了从合成数据集到现实数据集的逐步过渡,依次从RoadSense3D到DAIR-V2X-I,再到TUMTraf-A9。我们使用3D平均精度(mAP3D)在一定的交并比(IoU)阈值下评估了模型在每个真实数据集测试集上的性能,衡量了检测和定位精度。
1.单步数据集迁移
在初步分析中,我们通过在RoadSense3D数据集上预训练Cube R-CNN模型,并在DAIR-V2X-I和TUMTraf-A9数据集上进行微调,发现迁移学习能显著提升模型在现实世界数据集上的性能。在TUMTraf-A9数据集上,迁移学习模型的mAP3D从0.26提升至12.76,增长了4808%。在DAIR-V2X-I数据集上,迁移学习模型在不同难度级别上的mAP3D也分别提升了215.8%至231.4%。这些结果表明,迁移学习对于提高模型在复杂或数据量有限的现实场景中的性能非常有效。表3和表4分别收集了这两个模型实例在相应现实数据集测试集上的mAP3D。定量观察到的提升在图2中的定性例子中可以更好地体现。



2.多步数据集迁移
在第二次分析中,我们探索了逐步迁移学习的效果。我们首先在RoadSense3D数据集上预训练Cube R-CNN模型,然后在DAIR-V2X-I数据集上微调,最后在TUMTraf-A9数据集上进行微调。与直接在TUMTraf-A9上训练的模型相比,这种逐步迁移学习方法在TUMTraf-A9测试集上的mAP3D从0.26提升至6.26,增长了2308%。尽管如此,直接在TUMTraf-A9上微调的模型表现更佳,mAP3D达到12.76。这表明虽然逐步迁移学习能提升性能,但直接微调在特定数据集上更有效。我们认为,中间的DAIR-V2X-I阶段可能引入了与TUMTraf-A9不匹配的特征,影响了模型的最终性能。表5收集了这两个模型实例在各个难度级别上的mAP3D。

结论
本文贡献如下:
1.迁移学习实验:本研究使用Cube R-CNN模型,从合成数据集RoadSense3D迁移到现实世界数据集TUMTraf-A9和DAIR-V2X-I,通过引入俯仰和横滚角度,显著提升了检测精度。
2.性能提升:直接迁移学习显著提高了TUMTraf-A9和DAIR-V2X-I数据集的3D mAP,分别从0.26提升到12.76和从2.09提升到6.60。
3.直接微调的优势:研究结果表明,尽管多步迁移学习有益,但在目标数据集上直接微调可以获得更优异的效果。
4.应用领域:这些研究结果为智能交通系统、自动驾驶和智慧城市基础设施中构建更稳健、适应性更强的模型提供了基础,这些领域中准确的3D感知对于提高安全性和效率至关重要。
引用文章:
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术,加入知识星球,一起学习自动驾驶感知技术。
当前属于预售阶段398,预售期到9月30号,到时可能涨价(50或者100)。
398让你跟着自动驾驶一线大佬学习一年。
正式发布倒计时27天!!!
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。