基于飞桨paddle2.6.1+cuda11.7+paddleRS开发版的目标提取-道路数据集训练和预测代码
预测结果:

预测影像:

(一)准备道路数据集
下载数据集地址:
https://aistudio.baidu.com/datasetdetail/56961
mass_road.zip
—原始地址Url:
https://ai-studio-online.bj.bcebos.com/v1/41357ea3cf184439b91fa53f3f7043fbe4098d72a6af445ebeaafe312dde6753?responseContentDisposition=attachment%3Bfilename%3Dmass_road.zip&authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2024-09-02T08%3A00%3A26Z%2F21600%2F%2Fb960ea800643817cef73410af3c78134882f697c4a16b7103ca1ec419d50c6b7
参考地址:https://aistudio.baidu.com/aistudio/projectdetail/3792610
(二) 数据预处理
import random
import os.path as osp
from os import listdir
import cv2
print(cv2.__version__)
# 随机数生成器种子
RNG_SEED = 56961
# 调节此参数控制训练集数据的占比
TRAIN_RATIO = 0.9
# 数据集路径
DATA_DIR = 'i://cwgis_ai/cup/mass_road'
# 分割类别
CLASSES = (
'background',
'road',
)
def write_rel_paths(phase, names, out_dir, prefix):
"""将文件相对路径存储在txt格式文件中"""
with open(osp.join(out_dir, phase+'.txt'), 'w') as f:
for name in names:
f.write(
' '.join([
osp.join(prefix, 'input', name),
osp.join(prefix, 'output', name)
])
)
f.write('\n')
random.seed(RNG_SEED)
train_prefix = osp.join('road_segmentation_ideal', 'training')
test_prefix = osp.join('road_segmentation_ideal', 'testing')
train_names = listdir(osp.join(DATA_DIR, train_prefix, 'output'))
train_names = list(filter(lambda n: n.endswith('.png'), train_names))
test_names = listdir(osp.join(DATA_DIR, test_prefix, 'output'))
test_names = list(filter(lambda n: n.endswith('.png'), test_names))
# 对文件名进行排序,以确保多次运行结果一致
train_names.sort()
test_names.sort()
random.shuffle(train_names)
len_train = int(len(train_names)*TRAIN_RATIO)
write_rel_paths('train', train_names[:len_train], DATA_DIR, train_prefix)
write_rel_paths('val', train_names[len_train:], DATA_DIR, train_prefix)
write_rel_paths('test', test_names, DATA_DIR, test_prefix)
# 写入类别信息
with open(osp.join(DATA_DIR, 'labels.txt'), 'w') as f:
for cls in CLASSES:
f.write(cls+'\n')
print("数据集划分已完成。")
(三)将GT中的255改写为1,便于训练
import os.path as osp
from glob import glob
import cv2
from tqdm import tqdm
# 数据集路径
DATA_DIR = 'i://cwgis_ai/cup/mass_road'
train_prefix = osp.join('road_segmentation_ideal', 'training')
test_prefix = osp.join('road_segmentation_ideal', 'testing')
train_paths = glob(osp.join(DATA_DIR, train_prefix, 'output', '*.png'))
test_paths = glob(osp.join(DATA_DIR, test_prefix, 'output', '*.png'))
for path in tqdm(train_paths+test_paths):
im = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
im[im>0] = 1
# 原地改写
cv2.imwrite(path, im)
(四)查看图片尺寸大小python代码
import cv2
import os
DATA_DIR = 'i:/cwgis_ai/cup/mass_road'
image_dir = "i:/cwgis_ai/cup/mass_road/road_segmentation_ideal/testing/input"
for image_name in os.listdir(image_dir):
image_path = os.path.join(image_dir,image_name)
img = cv2.imread(image_path)
height,width = img.shape[:2]
if width!=1500 or height!=1500:
print(image_name,"----------尺寸:",width,"x",height)
else:
print(image_name,"尺寸:",width,"x",height)
# 修改图像尺寸
# import cv2
#img = cv2.imread("data/INF_All_9.1/temp1/WIN_20230818_11_12_30_Pro_150.png")
#resize_img = cv2.resize(img,(640,512)) # 自定义为自己想要的图像尺寸
#cv2.imwrite("data/INF_All_9.1/temp/WIN_20230818_11_12_30_Pro_150.png",resize_img) # 保存修改尺寸后的图像到指定路径
#height,width = resize_img.shape[:2]
#print(resize_img,"尺寸:",width,"x",height)
# 更改img-14.png图片大小为1500 X 1500
img = cv2.imread("i:/cwgis_ai/cup/mass_road/road_segmentation_ideal/testing/input/img-14-old.png")
resize_img = cv2.resize(img,(1500,1500)) # 自定义为自己想要的图像尺寸
print(resize_img.shape) # (1500, 1500, 3)
cv2.imwrite("i:/cwgis_ai/cup/mass_road/road_segmentation_ideal/testing/input/img-14.png",resize_img) # 保存修改尺寸后的图像到指定路径
(五)训练代码
# 导入需要用到的库
import random
import os.path as osp
import cv2
import numpy as np
import paddle
import paddlers as pdrs
from paddlers import transforms as T
from matplotlib import pyplot as plt
from PIL import Image
# 定义全局变量
# 随机种子
SEED = 56961
# 数据集存放目录
DATA_DIR = 'i:/cwgis_ai/cup/mass_road'
# 训练集`file_list`文件路径
TRAIN_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/train.txt'
# 验证集`file_list`文件路径
VAL_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/val.txt'
# 测试集`file_list`文件路径
TEST_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/test.txt'
# 数据集类别信息文件路径
LABEL_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/labels.txt'
# 实验目录,保存输出的模型权重和结果
EXP_DIR = 'i:/cwgis_ai/cup/road_model/'
# 固定随机种子,尽可能使实验结果可复现
random.seed(SEED)
np.random.seed(SEED)
paddle.seed(SEED)
# 构建数据集
# 定义训练和验证时使用的数据变换(数据增强、预处理等)
train_transforms = T.Compose([
T.DecodeImg(),
# 随机裁剪
T.RandomCrop(crop_size=512),
# 以50%的概率实施随机水平翻转
T.RandomHorizontalFlip(prob=0.5),
# 以50%的概率实施随机垂直翻转
T.RandomVerticalFlip(prob=0.5),
# 将数据归一化到[-1,1]
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
T.ArrangeSegmenter('train')
])
eval_transforms = T.Compose([
T.DecodeImg(),
T.Resize(target_size=1500),
# 验证阶段与训练阶段的数据归一化方式必须相同 target_size=1488
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
T.ArrangeSegmenter('eval')
])
# 分别构建训练和验证所用的数据集
train_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=TRAIN_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=train_transforms,
num_workers=4,
shuffle=True
)
val_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=VAL_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=eval_transforms,
num_workers=0,
shuffle=False
)
# 构建DeepLab V3+模型,使用ResNet-50作为backbone= ResNet50_vd ResNet101_vd
model = pdrs.tasks.seg.DeepLabV3P(
in_channels=3,
num_classes=len(train_dataset.labels),
backbone='ResNet50_vd'
)
model.initialize_net(
pretrain_weights='CITYSCAPES',
save_dir=osp.join(EXP_DIR, 'pretrain'),
resume_checkpoint=None,
is_backbone_weights=False
)
# 构建优化器
optimizer = paddle.optimizer.Adam(
learning_rate=0.001,
parameters=model.net.parameters()
)
# 执行模型训练 原参数:num_epochs=100,train_batch_size=8
model.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=2,
eval_dataset=val_dataset,
optimizer=optimizer,
save_interval_epochs=2,
# 每多少次迭代记录一次日志
log_interval_steps=30,
save_dir=EXP_DIR,
# 是否使用early stopping策略,当精度不再改善时提前终止训练
early_stop=False,
# 是否启用VisualDL日志功能
use_vdl=True,
# 指定从某个检查点继续训练
resume_checkpoint=None
)
#-----the----end-------
'''
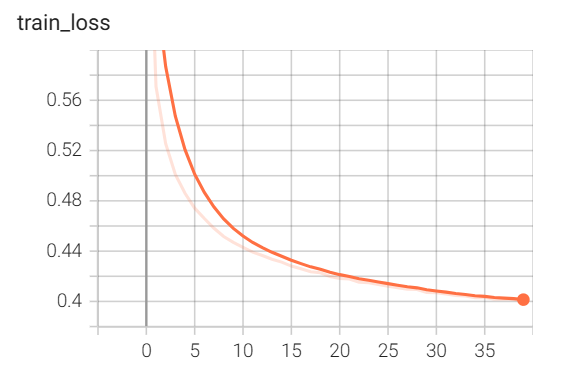
(六) 训练过程信息
'''
(rs) PS G:\app2024\MyProject深度学习AI项目\web> & C:/Users/Administrator/.conda/envs/rs/python.exe g:/app2024/MyProject深度学习AI项目/web/cup_trans.py
Can not use `conditional_random_field`. Please install pydensecrf first.
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
2024-09-03 14:18:45,486-WARNING: post-quant-hpo is not support in system other than linux
2024-09-03 14:18:45 [WARNING] Including an `Arrange` object in the transformation operator list is deprecated and will not take effect.
2024-09-03 14:18:45 [WARNING] Including an `Arrange` object in the transformation operator list is deprecated and will not take effect.
2024-09-03 14:18:45 [INFO] 723 samples in file i:/cwgis_ai/cup/mass_road/train.txt
2024-09-03 14:18:45 [INFO] 81 samples in file i:/cwgis_ai/cup/mass_road/val.txt
W0903 14:18:45.873943 4776 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.6, Runtime API Version: 11.7
W0903 14:18:45.881899 4776 gpu_resources.cc:164] device: 0, cuDNN Version: 8.4.
2024-09-03 14:18:46 [INFO] Loading pretrained model from i:/cwgis_ai/cup/road_model/pretrain\model.pdparams
2024-09-03 14:18:47 [WARNING] [SKIP] Shape of parameters head.decoder.conv.weight do not match. (pretrained: [19, 256, 1, 1] vs actual: [2, 256, 1, 1])
2024-09-03 14:18:47 [WARNING] [SKIP] Shape of parameters head.decoder.conv.bias do not match. (pretrained: [19] vs actual: [2])
2024-09-03 14:18:47 [INFO] There are 358/360 variables loaded into DeepLabV3P.
2024-09-03 14:18:47 [INFO] Loading pretrained model from i:/cwgis_ai/cup/road_model/pretrain\model.pdparams
2024-09-03 14:18:48 [WARNING] [SKIP] Shape of parameters head.decoder.conv.weight do not match. (pretrained: [19, 256, 1, 1] vs actual: [2, 256, 1, 1])
2024-09-03 14:18:48 [WARNING] [SKIP] Shape of parameters head.decoder.conv.bias do not match. (pretrained: [19] vs actual: [2])
2024-09-03 14:18:48 [INFO] There are 358/360 variables loaded into DeepLabV3P.
2024-09-03 14:19:36 [INFO] [TRAIN] Epoch=1/6, Step=30/361, loss=0.189093, lr=0.001000, time_each_step=1.57s, eta=0:57:4
2024-09-03 14:20:24 [INFO] [TRAIN] Epoch=1/6, Step=60/361, loss=0.093886, lr=0.001000, time_each_step=1.59s, eta=0:56:47
2024-09-03 14:21:11 [INFO] [TRAIN] Epoch=1/6, Step=90/361, loss=0.106614, lr=0.001000, time_each_step=1.59s, eta=0:56:1
2024-09-03 14:21:59 [INFO] [TRAIN] Epoch=1/6, Step=120/361, loss=0.170390, lr=0.001000, time_each_step=1.59s, eta=0:55:24
2024-09-03 14:22:47 [INFO] [TRAIN] Epoch=1/6, Step=150/361, loss=0.079456, lr=0.001000, time_each_step=1.59s, eta=0:54:31
2024-09-03 14:23:34 [INFO] [TRAIN] Epoch=1/6, Step=180/361, loss=0.161471, lr=0.001000, time_each_step=1.58s, eta=0:53:30
2024-09-03 14:24:22 [INFO] [TRAIN] Epoch=1/6, Step=210/361, loss=0.075722, lr=0.001000, time_each_step=1.59s, eta=0:53:2
2024-09-03 14:25:10 [INFO] [TRAIN] Epoch=1/6, Step=240/361, loss=0.117546, lr=0.001000, time_each_step=1.59s, eta=0:51:58
2024-09-03 14:25:57 [INFO] [TRAIN] Epoch=1/6, Step=270/361, loss=0.101394, lr=0.001000, time_each_step=1.59s, eta=0:51:11
2024-09-03 14:26:45 [INFO] [TRAIN] Epoch=1/6, Step=300/361, loss=0.057541, lr=0.001000, time_each_step=1.59s, eta=0:50:27
2024-09-03 14:27:33 [INFO] [TRAIN] Epoch=1/6, Step=330/361, loss=0.070874, lr=0.001000, time_each_step=1.59s, eta=0:49:38
2024-09-03 14:28:20 [INFO] [TRAIN] Epoch=1/6, Step=360/361, loss=0.132143, lr=0.001000, time_each_step=1.59s, eta=0:48:49
2024-09-03 14:28:22 [INFO] [TRAIN] Epoch 1 finished, loss=0.1463401052491982 .
2024-09-03 14:29:08 [INFO] [TRAIN] Epoch=2/6, Step=29/361, loss=0.049420, lr=0.001000, time_each_step=1.6s, eta=0:48:18
2024-09-03 14:29:56 [INFO] [TRAIN] Epoch=2/6, Step=59/361, loss=0.265671, lr=0.001000, time_each_step=1.59s, eta=0:47:24
2024-09-03 14:30:44 [INFO] [TRAIN] Epoch=2/6, Step=89/361, loss=0.110936, lr=0.001000, time_each_step=1.59s, eta=0:46:37
2024-09-03 14:31:31 [INFO] [TRAIN] Epoch=2/6, Step=119/361, loss=0.108888, lr=0.001000, time_each_step=1.59s, eta=0:45:49
2024-09-03 14:32:19 [INFO] [TRAIN] Epoch=2/6, Step=149/361, loss=0.065547, lr=0.001000, time_each_step=1.59s, eta=0:45:3
2024-09-03 14:33:07 [INFO] [TRAIN] Epoch=2/6, Step=179/361, loss=0.057928, lr=0.001000, time_each_step=1.59s, eta=0:44:15
2024-09-03 14:33:55 [INFO] [TRAIN] Epoch=2/6, Step=209/361, loss=0.055898, lr=0.001000, time_each_step=1.59s, eta=0:43:28
2024-09-03 14:34:43 [INFO] [TRAIN] Epoch=2/6, Step=239/361, loss=0.135333, lr=0.001000, time_each_step=1.61s, eta=0:43:0
2024-09-03 14:35:31 [INFO] [TRAIN] Epoch=2/6, Step=269/361, loss=0.048581, lr=0.001000, time_each_step=1.6s, eta=0:41:55
(七)预测代码
# 导入需要用到的库
import random
import os.path as osp
import cv2
import numpy as np
import paddle
import paddlers as pdrs
from paddlers import transforms as T
from matplotlib import pyplot as plt
from PIL import Image
# 定义全局变量
# 随机种子
SEED = 56961
# 数据集存放目录
DATA_DIR = 'i:/cwgis_ai/cup/mass_road'
# 训练集`file_list`文件路径
TRAIN_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/train.txt'
# 验证集`file_list`文件路径
VAL_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/val.txt'
# 测试集`file_list`文件路径
TEST_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/test.txt'
# 数据集类别信息文件路径
LABEL_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/labels.txt'
# 实验目录,保存输出的模型权重和结果
EXP_DIR = 'i:/cwgis_ai/cup/road_model/'
eval_transforms = T.Compose([
T.DecodeImg(),
T.Resize(target_size=1500),
# 验证阶段与训练阶段的数据归一化方式必须相同 target_size=1488
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
T.ArrangeSegmenter('eval')
])
# 固定随机种子,尽可能使实验结果可复现
random.seed(SEED)
np.random.seed(SEED)
paddle.seed(SEED)
# 构建测试集
test_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=TEST_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=eval_transforms,
num_workers=0,
shuffle=False
)
# 构建DeepLab V3+模型,使用ResNet-50作为backbone= ResNet50_vd ResNet101_vd
model = pdrs.tasks.seg.DeepLabV3P(
in_channels=3,
num_classes=2,
backbone='ResNet50_vd'
)
model.initialize_net(
pretrain_weights='CITYSCAPES',
save_dir=osp.join(EXP_DIR, 'pretrain'),
resume_checkpoint=None,
is_backbone_weights=False
)
# 构建优化器
optimizer = paddle.optimizer.Adam(
learning_rate=0.001,
parameters=model.net.parameters()
)
# 为模型加载历史最佳权重
state_dict = paddle.load(osp.join(EXP_DIR, 'best_model/model.pdparams'))
model.net.set_state_dict(state_dict)
# 执行测试
test_result = model.evaluate(test_dataset)
print(
"测试集上指标:IoU为{:.2f},Acc为{:.2f},Kappa系数为{:.2f}, F1为{:.2f}".format(
test_result['category_iou'][1],
test_result['category_acc'][1],
test_result['kappa'],
test_result['category_F1-score'][1]
)
)
(八)单张图片预测代码
# 导入需要用到的库
import random
import os.path as osp
import cv2
import numpy as np
import paddle
import paddlers as pdrs
from paddlers import transforms as T
from matplotlib import pyplot as plt
from matplotlib.image import imread
from PIL import Image
# 定义全局变量
# 随机种子
#SEED = 56961
SEED = 22961
# 数据集存放目录
DATA_DIR = 'i:/cwgis_ai/cup/mass_road'
# 训练集`file_list`文件路径
TRAIN_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/train.txt'
# 验证集`file_list`文件路径
VAL_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/val.txt'
# 测试集`file_list`文件路径
TEST_FILE_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/test.txt'
# 数据集类别信息文件路径
LABEL_LIST_PATH = 'i:/cwgis_ai/cup/mass_road/labels.txt'
# 实验目录,保存输出的模型权重和结果
EXP_DIR = 'i:/cwgis_ai/cup/road_model/'
eval_transforms = T.Compose([
T.DecodeImg(),
T.Resize(target_size=1500),
# 验证阶段与训练阶段的数据归一化方式必须相同 target_size=1488
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
T.ArrangeSegmenter('eval')
])
# 固定随机种子,尽可能使实验结果可复现
random.seed(SEED)
np.random.seed(SEED)
paddle.seed(SEED)
#====================================================================
# 构建测试集
test_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=TEST_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=eval_transforms,
num_workers=0,
shuffle=False
)
# 构建DeepLab V3+模型,使用ResNet-50作为backbone= ResNet50_vd ResNet101_vd
model = pdrs.tasks.seg.DeepLabV3P(
in_channels=3,
num_classes=2,
backbone='ResNet50_vd'
)
model.initialize_net(
pretrain_weights='CITYSCAPES',
save_dir=osp.join(EXP_DIR, 'pretrain'),
resume_checkpoint=None,
is_backbone_weights=False
)
# 构建优化器
optimizer = paddle.optimizer.Adam(
learning_rate=0.001,
parameters=model.net.parameters()
)
# 为模型加载历史最佳权重
state_dict = paddle.load(osp.join(EXP_DIR, 'best_model/model.pdparams'))
model.net.set_state_dict(state_dict)
# 预测结果可视化
# 重复运行本单元可以查看不同结果
def read_image(path):
im = cv2.imread(path)
return im[...,::-1]
def show_images_in_row(ims, fig, title='', quantize=False):
n = len(ims)
fig.suptitle(title)
axs = fig.subplots(nrows=1, ncols=n)
for idx, (im, ax) in enumerate(zip(ims, axs)):
# 去掉刻度线和边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.get_xaxis().set_ticks([])
ax.get_yaxis().set_ticks([])
if isinstance(im, str):
im = read_image(im)
if quantize:
im = (im*255).astype('uint8')
if im.ndim == 2:
im = np.tile(im[...,np.newaxis], [1,1,3])
ax.imshow(im)
# 需要展示的样本个数
num_imgs_to_show = 20
# 随机抽取样本
chosen_indices = random.choices(range(len(test_dataset)), k=num_imgs_to_show)
# 参考 https://stackoverflow.com/a/68209152
#fig = plt.figure(constrained_layout=True)
#fig.suptitle("Test Results")
#subfigs = fig.subfigures(nrows=3, ncols=1)
# 读取输入影像并显示
im_paths = [test_dataset.file_list[idx]['image'] for idx in chosen_indices]
#show_images_in_row(im_paths, subfigs[0], title='Image')
# print(im_paths[0])
#im = cv2.imread(im_paths[0], cv2.IMREAD_GRAYSCALE)
#print(im)
#plt.imshow(im)
#plt.show()
# 获取模型预测输出
with paddle.no_grad():
model.net.eval()
preds = []
for idx in chosen_indices:
input = test_dataset.file_list[idx]['image'] # i:/cwgis_ai/cup/mass_road\road_segmentation_ideal\testing\input\img-5.png
#mask = test_dataset.file_list[idx]['mask'] # i:/cwgis_ai/cup/mass_road\road_segmentation_ideal\testing\output\img-5.png
print(input)
filename=osp.basename(input)
if(filename=="img-10.png"):
input, mask = test_dataset[idx]
print("idx="+str(idx))
#print(input["image"])
#print('-------------------')
#print(mask)
input = paddle.to_tensor(input["image"]).unsqueeze(0)
logits, *_ = model.net(input)
pred = paddle.argmax(logits[0], axis=0)
preds.append(pred.numpy())
out_path="i:/cwgis_ai/cup/out10.png"
im=pred.numpy()
im[im>0] = 255
cv2.imwrite(out_path, im)
#show_images_in_row(preds, subfigs[1], title='Pred', quantize=True)
#plt.figure(figsize=(1500, 1500))
#print(preds[0])
#plt.imshow(preds[0])
#plt.show()
# 读取真值标签并显示
#m_paths = [test_dataset.file_list[idx]['mask'] for idx in chosen_indices]
#show_images_in_row(im_paths, subfigs[2], title='GT', quantize=True)
# 渲染结果
#fig.canvas.draw()
#Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())
本blog地址:https://blog.csdn.net/hsg77