就是非常不起眼的帐号去重计数,用 SQL 写就是 COUNT(DISTINCT …)。
帐号去重计数在商业分析中很常见也有重要的业务意义。这里的帐号可能是用户 ID、银行帐户、手机号、车牌号、…。计算逻辑基本一样,就是从某个时段的历史数据中统计出有多少个帐号满足某个条件。
比如,上个月有多少辆汽车去过北京?上周有多少手机在凌晨 2 点 -4 点之间有过通话?今年收到过海外汇款的银行帐户有多少?…
历史数据通常只会记录发生过的事件,比如某辆车在某时刻在某地出现,某个手机在某时刻和谁通话,某个银行帐户在某日期发生过汇入汇出,…。用指定条件直接筛选历史记录会得到很多帐号相同的记录(某辆车可能多次去过北京,…),但只能按 1 次计数,所以要做去重处理。
去重计数中的筛选条件经常并不会像上面那例子中那么简单。比如,今年发生过周消费总额超过 1000 元的信用卡帐户有多少?需要先统计帐户每周的消费额再来筛选;上月中发生过连续三天消费额超过 100 元的帐户有多少?需要对帐户的交易进行更复杂的存在性判断。不过,无论怎样的条件,最后都归结于计算 COUNT(DISTINCT)。
著名的电商漏斗统计就是这类复杂化的 COUNT(DISTINCT),只不过它会更复杂一些。漏斗统计涉及多步有次序的事件,每一步都对应有一个 COUNT(DISTINCT),以便和上一步的 COUNT(DISTINCT) 一起计算这一步的客户流失率;下一步的 COUNT(DISTINCT) 要在上一步的基础上筛选。并且要考虑事件发生的次序。整个过程比较复杂,但本质上仍然是在做 COUNT(DISTINCT)。
COUNT(DISTINCT) 却一直是数据库计算的难题,通常都会非常慢,如果数据量大(帐号数多,这也是常态),还有可能导致数据库崩掉。
这是为什么呢?
因为 COUNT(DISINCT) 计算量很大。COUNT(DISTINCT id) 需要把遍历过的不同的 id 都保存成一个列表,下一个 id 要和这个列表比对才知道是不是新的,以决定是否要增加计数值并将其添加进列表中。而普通的 COUNT(id) 并不需要保存遍历过的 id,当然也不需要比对,这显然要简单很多。COUNT(DISTINCT) 在 SQL 中的地位看起来和 COUNT,SUM 差不多,但计算速度却要慢得多。
而且,很多数据库在计算 COUNT(DISTINCT id) 时,会把上述的 id 列表放在内存中,这样才能高速的访问和比对,但如果帐号数很多时,内存很可能就装不下,于是跑崩不可避免。如果把这个 id 列表缓存到外存,虽然可以避免崩掉,但访问和比对都不方便,性能会进一步急剧下降。
好在,COUNT(DISTINCT id) 计算中的 id 通常只是一列数据,100G 内存在极限时可能装下几十亿个 id,超出大多数应用的帐号数量了,所以计算常规的 COUNT(DISTINCT) 虽然慢一点,还不致于会频繁跑崩。
但情况再复杂一些就不一定了。比如,漏斗统计会有多个搅和在一起的 COUNT(DISTINCT),写出 SQL 会有嵌套的 JOIN,这时候想跑得快,占用的内存就会大得多(JOIN 也会导致内存和性能之间的严重矛盾),跑崩的概率也就会陡增。
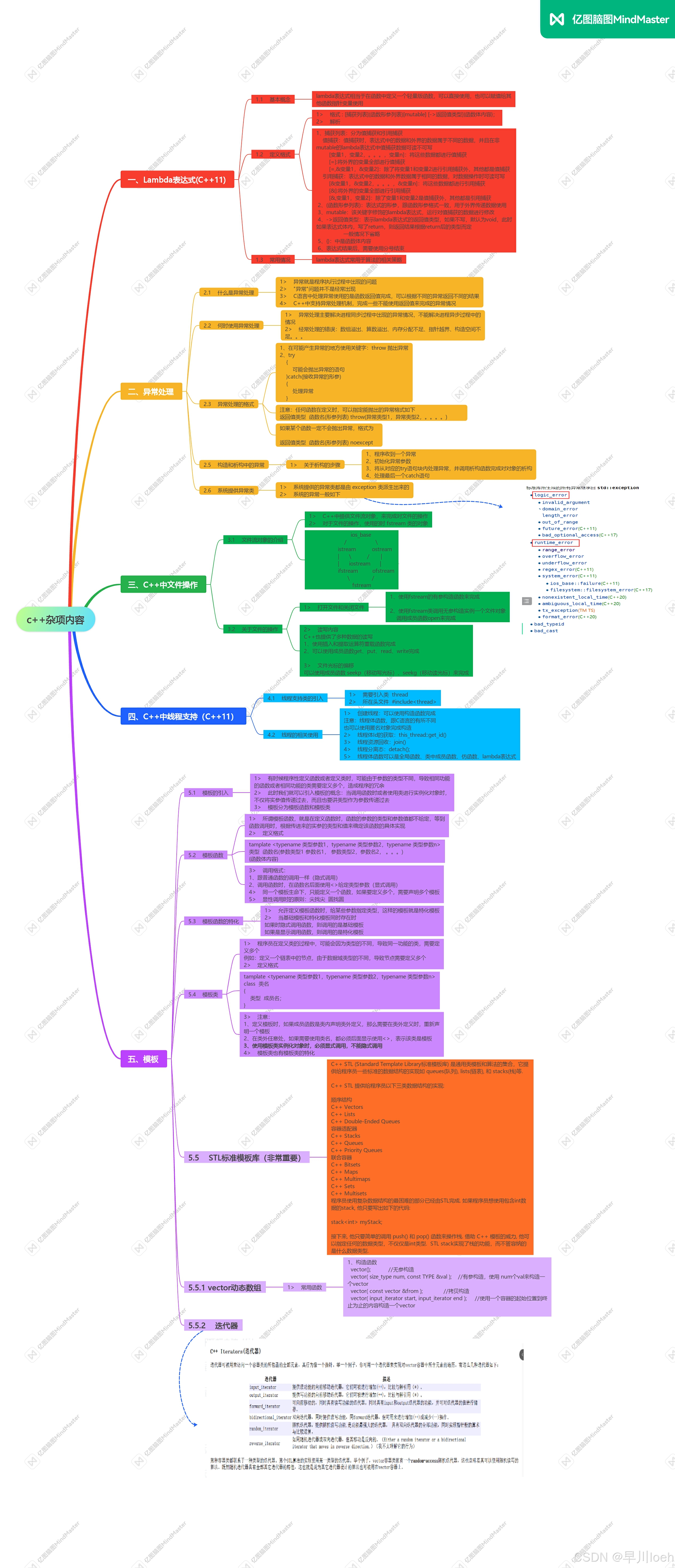
下面是用 SQL 实现的某实际场景的三步漏斗分析:
WITH e1 AS (
SELECT userid, visittime AS step1_time, MIN(sessionid) AS sessionid, 1 AS step1
FROM defined_events e1 JOIN eventgroup ON eventgroup.id = e1.eventgroup
WHERE visittime >= DATE_ADD(arg_date,INTERVAL -14 day) AND visittime < arg_date AND eventgroup.name='SiteVisit'
GROUP BY userid,visittime
), e2 AS (
SELECT e2.userid, MIN(e2.sessionid) AS sessionid, 1 AS step2, MIN(visittime) AS step2_time, MIN(e1.step1_time) AS step1_time
FROM defined_events e2 JOIN e1 ON e1.sessionid = e2.sessionid AND visittime > step1_time JOIN eventgroup ON eventgroup.id = e2.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND eventgroup.name = 'ProductDetailPage'
GROUP BY e2.userid
), e3 AS (
SELECT e3.userid, MIN(e3.sessionid) AS sessionid, 1 AS step3, MIN(visittime) AS step3_time, MIN(e2.step1_time) AS step1_time
FROM defined_events e3 JOIN e2 ON e2.sessionid = e3.sessionid AND visittime > step2_time
JOIN eventgroup ON eventgroup.id = e3.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND (eventgroup.name = 'OrderConfirmationType1')
GROUP BY e3.userid
)
SELECT s.devicetype AS devicetype,
COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step1_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step2 IS NOT NULL THEN funnel_conversions.step2_userid ELSE NULL END) AS step2_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END) AS step3_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END)
/ COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step3_rate
FROM (
SELECT e1.step1_time AS step1_time, e1.userid AS userid, e1.userid AS step1_userid, e2.userid AS step2_userid,e3.userid AS step3_userid,
e1.sessionid AS step1_sessionid, step1, step2, tep3
FROM e1 LEFT JOIN e2 ON e1.userid=e2.userid LEFT JOIN e3 ON e2.userid=e3.userid ) funnel_conversions
LEFT JOIN sessions s ON funnel_conversions.step1_sessionid = s.id
GROUP BY s.devicetype
可以看出,这里不仅有多个 COUNT(DISTINCT),还有多个自关联子查询以实现复杂的漏斗步骤判断。这个 SQL 语句在 Snowflake 的 Medium 级集群(4 节点)三分钟没跑出结果。
那么,该怎么解决这个讨厌的 COUNT(DISTINCT) 呢?
其实并不难,只要把数据按帐号排序后,COUNT(DISINCT) 就很容易算了。
数据对 id 有序时,再计算 COUNT(DISTINCT id) 时,只要保存上一个 id 这一个值就可以了。下一个 id 如果和上一个 id 相等,则增加当前保存 id 的计数,如果不同则替换这个保存的 id 并将计数清 0。不需要在一个大列表中查找比对,只保存一个 id 时占用的内存几乎可以忽略不计。跑得快也不可能崩掉。
对于漏斗这种复杂任务也没问题,数据对 id 有序时,可以每次读入一个 id 的数据进内存,然后可以方便地进行复杂的计算,过程中不会涉及其它 id 的数据,原则上内存只要能装下一个 id 的数据就可以了,同时保存多套 COUNT(DISTINCT) 的计数值也没问题。
可惜,关系数据库和 SQL 做不到这一点。
作为关系数据库理论基础的关系代数是基于无序集合的,SQL 中集合成员(表的记录)没有次序,数据库在存储数据在理论上也不支持有序。上述的优化逻辑在 SQL 中无法实现。
esProc SPL 可以!
esProc SPL 严格地说并不是一个数据库,而是个专业的计算引擎。它不再采用关系代数了,而是自创了以有序集合为基础的离散数据集理论并发明了新程序语言 SPL。esProc 在存储数据时会刻意支持有序,SPL 也提供了丰富的有序计算方法,这样就可以高性能低资源地实现帐号去重统计了。
SPL 的 icount 函数用去重计数,缺省情况会用前述方法实现,即保持一个遍历过的不同 id 的列表,下一个 id 要和列表对比。数据对 id 有序则使用 icount@o,这时候 SPL 就会采用有序去重计数的算法,即只保持上一个 id 值用于比对。
特别地,SPL 还支持有序游标,数据对 id 有序时,可以每次取出 id 相同的一批数据,然后进行复杂的计算以判断当前 id 是否满足筛选条件,之后的计数可以直接用 COUNT,连保持上一个 id 再比对的动作都不需要了(在游标取数时已经比对过了)。
漏斗分析就可以用这个机制实现:
|
| A |
| 1 | =now() |
| 2 | =eventgroup=file("eventgroup.btx").import@b() |
| 3 | =devicetype=file("devicetype.btx").import@b() |
| 4 | =long(elapse(arg_date,-14)) |
| 5 | =long(arg_date) |
| 6 | =long(arg_date+1) |
| 7 | =A2.(case(NAME,"SiteVisit":1,"ProductDetailPage":2,"OrderConfirmationType1":3;null)) |
| 8 | =file("defined_events.ctx").open() |
| 9 | =A8.cursor@m(USERID,SESSIONID,VISITTIME,EVENTGROUPNO;VISITTIME>=A4 && VISITTIME<A6,EVENTGROUPNO:A7:#) |
| 10 | =sessions=file("sessions.ctx").open().cursor@m(USERID,ID,DEVICETYPENO;;A9) |
| 11 | =A9.joinx@m(USERID:SESSIONID,A10:USERID:ID,DEVICETYPENO) |
| 12 | =A11.group(USERID) |
| 13 | =A12.new(~.align@a(3,EVENTGROUPNO):e,e(1).select(VISITTIME<A5).group@u1(VISITTIME):e1,e(2).group@o(SESSIONID):e2,e(3):e3) |
| 14 | =A13.run(e=join@m(e1:e1,SESSIONID;e2:e2,SESSIONID).select(e2=e2.select(VISITTIME>e1.VISITTIME && VISITTIME<e1.VISITTIME+86400000).min(VISITTIME) ) ) |
| 15 | =A14.run(e0=e1.id(DEVICETYPENO),e1=e.min(e1.VISITTIME),e2=e.min(e2),e=e.min(e1.SESSIONID),e3=e3.select(SESSIONID==e && VISITTIME>e2 && VISITTIME<e1+86400000).min(VISITTIME),e=e0) |
| 16 | =A15.news(e;~:DEVICETYPE,e2,e3) |
| 17 | =A16.groups(DEVICETYPE;count(1):STEP1_COUNT,count(e2):STEP2_COUNT,count(e3):STEP3_COUNT,null:STEP3_RATE) |
| 18 | =A17.run(DEVICETYPE=devicetype.m(DEVICETYPE).DEVICETYPE,STEP3_RATE=STEP3_COUNT/STEP1_COUNT) |
| 19 | =interval@s(A1,now()) |

(SPL 代码写在格子里,这和普通程序语言很不像,参考这里写在格子里的程序语言)
A12 每次读出一个 USERID 的数据进行后续判断,到 A17 再计算时就直接用 count 函数,不需要 icount 了。这个代码不仅更简洁通用(做更多步漏斗只要改 A7,而 SQL 代码要加很多子查询),跑得也更快,使用 Snowflake 同规格的 EC2,只用单台 10 秒即可完成。
其实,去重计数只是个表现,这个问题的实质在于以帐号为单位来切分数据再做处理。按帐号做分组汇总也是类似的运算,而有些汇总并不是简单的 SUM/MAX 这些,有时要很复杂的过程才能计算出来。比如计算每部手机通话时长小于 3 秒的次数;计算上月信用卡帐户的新增积分,规则是有连续三天消费超过 100 元时这几天的积分将加倍;…
信息系统中几乎所有事件性质的数据都会挂在某个帐号下,所以这类运算非常普遍,在各种查询跑批任务中都会碰到,可以说是最常见的业务逻辑模型之一了。有了 esProc SPL 这种基于有序存储上的有序运算,这一大类问题就都可以简洁且高性能的实现了,而对于 SQL 体系的关系数据库即非常困难。
这里举一个变种例子,一个时空碰撞问题,找出和某指定手机在同一时间段和同一地点出现过次数最多的前 20 个手机,数据规模约 250 亿行。SQL 写出来大概是这样:
WITH DT AS ( SELECT DISTINCT id, ROUND(tm/900)+1 as tn, loc FROM T WHERE tm<3*86400)
SELECT * FROM (
SELECT B.id id, COUNT( DISINCT B.tn ) cnt
FROM DT AS A JOIN DT AS B ON A.loc=B.loc AND A.tn=B.tn
WHERE A.id=a AND B.id<>a
GROUP BY id )
ORDER BY cnt DESC
LIMIT 20
这里又有嵌套的 DISTINCT 运算以及自关联 JOIN,单节点的 ClickHouse 直接崩掉,动用了 5 节点的集群用了 30 多分钟才跑出来。
SPL 代码利用了有序存储和前面提到的有序游标,可以有效避免这些困难,只用一个节点不到 6 分钟就跑完。
| A | |
| 1 | =now() |
| 2 | >NL=100000,NT=3*96 |
| 3 | =file("T.ctx").open() |
| 4 | =A3.cursor(tm,loc;id==a).fetch().align(NL*NT,(loc-1)*NT+tm\900+1) |
| 5 | =A3.cursor@mv(;id!=a && A4((loc-1)*NT+tm\900+1)) |
| 6 | =A5.group@s(id;icount@o(tm\900):cnt).total(top(-20;cnt)) |
| 7 | =interval@ms(A1,now()) |
细心的读者可能会发现,esProc SPL 的算法有效性依赖于数据对 id 有序,而数据产生次序通常不会是 id,而是时间。那么,这个算法是不是只能应用于事先排序过的历史数据上,对来不及一起排序的新数据就无效了呢?
esProc 已经考虑到这一点,SPL 的复组表可以在数据进入时实现增量排序,实时保证数据在读出时对 id 有序,可以让这套有序计算方案应用到最新的数据上。而且,这类运算通常都会涉及时间区间,SPL 的虚表支持双维有序机制,可以迅速将时间区间外的数据过滤掉,进一步提升运算性能。
esProc 是个纯 Java 软件,能在任何有 JVM 的环境下运算,可以无缝地嵌入到 Java 程序中,非常轻量地将数据仓库的运算能力赋予给各种场景下的应用中。
esProc 提供了可视的开发环境,支持单步执行、设置断点、所见即所得的结果预览,开发调试要比 SQL 和存储过程方便得多。
SPL 还有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用,拥有存储过程才有的过程化能力,可以全面取代 SQL 和存储过程。
…
最后,esProc SPL 是开源免费的。SPL开源地址





![[ComfyUI]Flux:不花钱免费白嫖最强反推JoyCaption,仅需几步无门槛轻松搞定](https://img-blog.csdnimg.cn/direct/4a2d3a791f754642af3f0383c95ee9c7.png#pic_center)