前言
这是我用时两天完成的第一个AI项目。
我的代码和运行结果放在kaggle上面,地址: Sentiment Analysis of IMDB Movie Reviews (90%)
我参考的原作者kaggle项目地址:Sentiment Analysis of IMDB Movie Reviews
我如何选择的这个项目见我上一篇博客:我如何选择自己的AI细分方向和第一个入门项目
这篇博客详细记录了我在这个项目中学到的很多知识和实践经验、碰到的一些困难和挑战、以及自己的一些思考、分析、优化和解决方案(有成功的经验也有失败的尝试)。
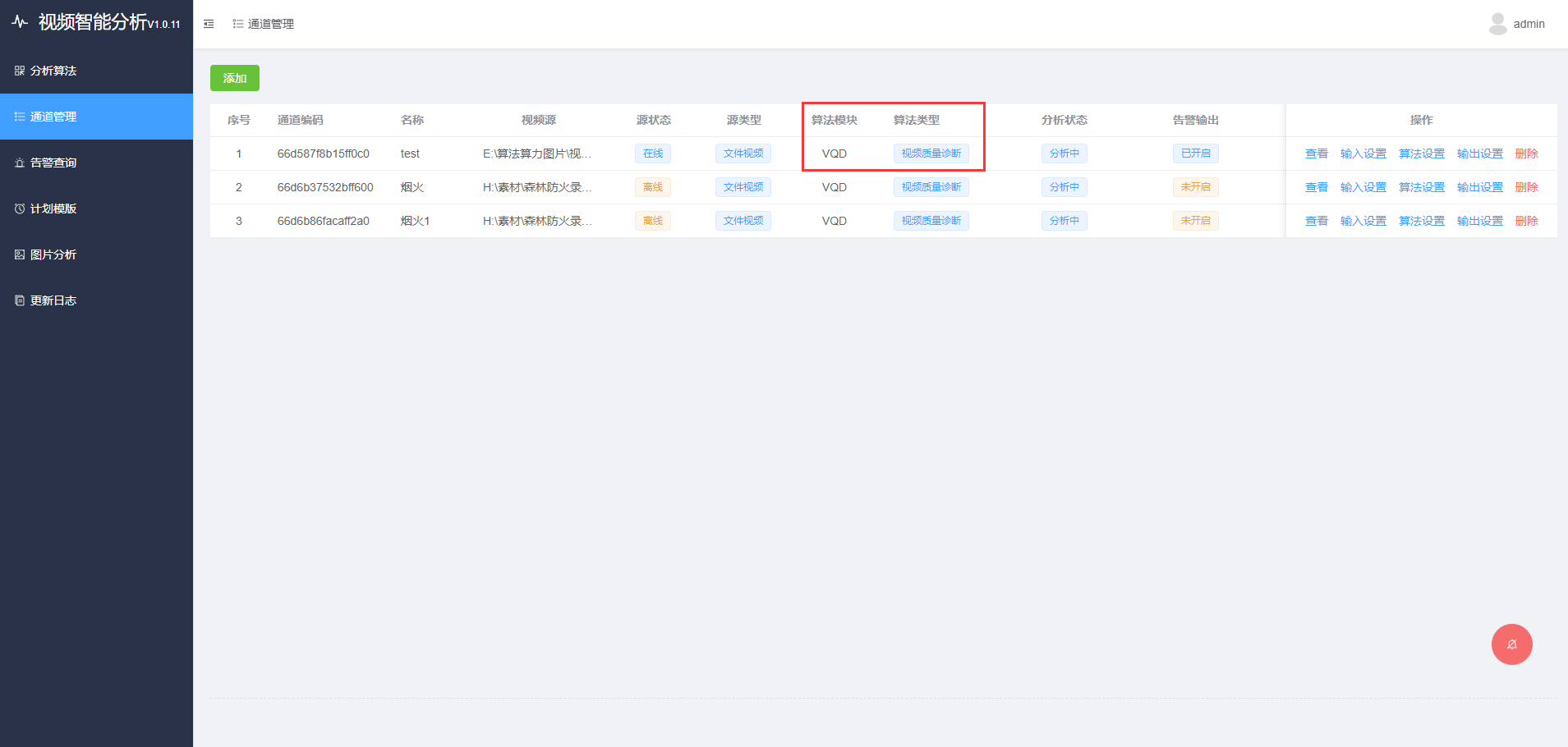
思维导图
下图是我完成项目的完整流程。
红黄蓝数字分别表示不同层级的步骤,由高到低
红黄蓝的旗帜表示我做的一些优化和思考,难度由难到易

目录
- 前言
- 思维导图
- 一、前期准备工作
- kaggle上的项目我应该如何学习和实践
- 1. **选择合适的项目**
- 2. **学习别人分享的解决方案**
- 3. **动手实践**
- 4. **参加Kaggle竞赛**
- 5. **总结和复盘**
- 6. **持续学习和提升**
- 如何学习别人分享的解决方案
- 1. **初步浏览项目**
- 2. **理解数据处理过程**
- 3. **分析特征工程**
- 4. **理解模型选择与训练**
- 5. **模型评估与优化**
- 6. **总结与反思**
- 7. **拓展与实践**
- 一个电影评论情感分析项目一般分为哪些步骤?
- 1. **数据收集**
- 2. **数据预处理**
- 3. **数据标注**
- 4. **特征提取**
- 5. **模型选择与训练**
- 6. **模型评估**
- 7. **模型调优**
- 8. **模型部署**
- 9. **结果分析与报告**
- 10. **持续优化与维护**
- 二、项目的主要流程
- 数据收集
- 数据加载
- 数据探索
- 1. **基本用法**
- 示例代码:
- 输出:
- 2. **非数值数据的处理**
- 示例代码:
- 输出:
- 3. **选择性描述**
- 只描述数值型数据:
- 只描述字符串类型的数据:
- 4. **多重描述**
- 划分数据集(Spliting dataset)
- 数据预处理 Data pre-processing
- 1. **文本清理**
- 2. **去除停用词**
- 3. **拼写校正(可选)**
- 4. **词干提取或词形还原**
- 5. **文本标记化**
- 6. **处理频繁或罕见词汇**
- 7. **文本表示转换**
- 8. **总结**
- 为什么在数据预处理之前需要先进行数据集的拆分?
- 关键点解释:
- 总结:
- 移除HTML标签
- 1. **安装 BeautifulSoup**
- 2. **使用 BeautifulSoup 移除HTML标签**
- **示例代码**
- **输出结果**
- 3. **代码解析**
- 4. **应用场景**
- 5. **处理复杂情况**
- **示例:移除特定标签**
- **输出结果**
- 6. **注意事项**
- 7. **替代方法**
- 总结
- 移除方括号及其内容
- 1. **使用正则表达式移除方括号及其内容**
- 2. **示例代码**
- 3. **输出结果**
- 4. **代码解析**
- 5. **应用场景**
- 6. **注意事项**
- 移除方括号及其内容-本项目代码解析
- 1. **`re.sub()` 函数**
- 2. **正则表达式 `'\[[^]]*\]'` 解析**
- 3. **整体代码解析**
- 4. **示例**
- 输出结果:
- 5. **总结**
- 去除多余的两个函数定义
- 移除特殊字符
- 1. **移除所有非字母字符**
- 示例代码:
- 输出:
- 2. **移除特定的特殊字符**
- 示例代码:
- 输出:
- 3. **移除非ASCII字符**
- 示例代码:
- 输出:
- 4. **移除所有特殊字符并保留数字**
- 示例代码:
- 输出:
- 5. **处理噪声的注意事项**
- 移除特殊字符-本项目代码
- 1. **代码概览**
- 2. **正则表达式 `r'[^a-zA-Z0-9\s]'` 解析**
- 3. **整体代码解析**
- 4. **示例**
- 输出结果:
- 5. **总结**
- Text stemming(文本词干提取)
- 1. **为什么使用词干提取?**
- 2. **常见的词干提取算法**
- 3. **使用示例**
- 输出结果:
- 4. **应用场景**
- 5. **注意事项**
- 6. **总结**
- Removing stopwords(移除停用词)
- 1. **安装和导入必要的库**
- 2. **加载停用词列表**
- 3. **移除停用词**
- 4. **代码解析**
- 5. **示例输出**
- 6. **总结**
- 拼写校正(Spelling Correction)(可选)
- 文本规范化中的拼写校正
- 1. **如何进行拼写校正**
- (1) **基于词典的拼写校正**
- 输出:
- (2) **基于编辑距离的拼写校正**
- 输出:
- (3) **基于上下文的拼写校正**
- 2. **什么时候需要进行拼写校正**
- 3. **什么时候不需要进行拼写校正**
- 4. **拼写校正中的问题和不足**
- 5. **总结**
- 电影评论的情感分析是否需要做拼写校正?
- 1. **什么时候需要做拼写校正**
- 2. **什么时候不需要做拼写校正**
- 3. **拼写校正可能带来的问题**
- 4. **权衡与建议**
- 总结
- 特征提取 Feature Extraction
- 词袋模型(Bag of Words, 简称BoW)
- 1. **词袋模型的基本概念**
- 举例说明
- 2. **词袋模型的优点**
- 3. **词袋模型的缺点**
- 4. **改进和扩展**
- 5. **实际应用**
- 6. **总结**
- 词袋模型-本项目代码
- 1. 导入和初始化 `CountVectorizer`
- 2. 拟合并转换训练数据
- 3. 转换测试数据
- 4. 输出维度信息
- 总结
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 示例代码
- 代码解析
- 1. 导入 `TfidfVectorizer`
- 2. 初始化 TF-IDF 向量化器
- 3. 拟合并转换训练数据
- 4. 转换测试数据
- 5. 输出维度信息
- 6. 获取特征名称
- 总结
- 词汇表如何生成以及大小由什么决定
- 1. 词袋模型(Bag of Words, BOW)如何生成词汇表
- 词汇表生成过程:
- 词汇表大小的决定因素:
- 2. TF-IDF 模型如何生成词汇表
- 词汇表生成过程:
- 词汇表大小的决定因素:
- 3. 词汇表的典型大小
- 4. 总结
- 是否需要缩减词汇表的大小?
- 标签二值化处理(Label Binarization)
- 1. **二值化处理的应用场景**
- 2. **二值化处理示例**
- (1) **使用`LabelBinarizer`进行二值化**
- 输出:
- (2) **使用`OneHotEncoder`进行One-Hot编码**
- 输出:
- (3) **简单的二分类问题**
- 输出:
- 3. **注意事项**
- 4. **总结**
- 多个模型的训练、评估、结果分析和报告
- 逻辑回归模型(Logistic Regression)
- 1. **逻辑回归的基本概念**
- (1) **Sigmoid函数**
- (2) **概率与分类**
- 2. **逻辑回归的损失函数**
- 3. **逻辑回归模型的训练**
- 4. **逻辑回归的优点**
- 5. **逻辑回归的缺点**
- 6. **Python实现逻辑回归**
- 7. **正则化**
- 8. **多类分类**
- 总结
- 逻辑回归模型训练-本项目代码
- 1. 初始化逻辑回归模型
- 2. 使用词袋模型(Bag of Words)特征训练模型
- 3. 使用 TF-IDF 特征训练模型
- 4. 总结
- 逻辑回归模型的初始化参数配置解析
- 模型评估:准确率
- 使用 `scikit-learn` 计算准确率
- 解释:
- 准确率的局限性:
- 模型评估:分类报告
- 1. 生成分类报告
- 2. 打印分类报告
- 3. 分类报告的输出内容
- 4. 总结
- 模型评估:混淆矩阵
- 1. 生成混淆矩阵
- 2. 打印混淆矩阵
- 3. 混淆矩阵的结构
- 4. 解释混淆矩阵
- 5. 总结
- 线性支持向量机(SVM)模型
- 1. **线性SVM的基本概念**
- (1) **超平面**
- (2) **间隔(Margin)**
- (3) **支持向量**
- (4) **线性可分与软间隔**
- 2. **SVM的损失函数**
- 3. **线性SVM的优点**
- 4. **线性SVM的缺点**
- 5. **Python实现线性SVM**
- 主要参数说明:
- 6. **SVM与其他模型的对比**
- 7. **总结**
- SVM模型训练-本项目代码
- 1. 初始化线性 SVM 模型
- 2. 使用词袋模型(Bag of Words)特征训练 SVM 模型
- 3. 总结
- SVM模型的初始化参数配置解析
- 随机梯度下降(SGD)
- 1. **梯度下降的基本概念**
- (1) **批量梯度下降(Batch Gradient Descent)**
- (2) **随机梯度下降(SGD)**
- 2. **SGD的优缺点**
- 优点:
- 缺点:
- 3. **SGD的改进与变种**
- (1) **小批量梯度下降(Mini-Batch Gradient Descent)**
- (2) **动量(Momentum)**
- (3) **自适应学习率方法(如AdaGrad、RMSProp、Adam)**
- 4. **Python实现随机梯度下降**
- 主要参数说明:
- 5. **总结**
- 多项式朴素贝叶斯模型
- 1. **朴素贝叶斯的基本原理**
- 2. **多项式朴素贝叶斯**
- (1) **模型公式**
- (2) **参数估计**
- 3. **Multinomial Naive Bayes 的优缺点**
- 优点:
- 缺点:
- 4. **Python实现Multinomial Naive Bayes**
- 主要参数说明:
- 5. **多项式朴素贝叶斯的应用场景**
- 6. **总结**
- 文本数据可视化工具:词云(Word Cloud)
- 1. 设置图像大小
- 2. 提取正面评论文本
- 3. 初始化词云对象
- 4. 生成词云
- 5. 显示词云图
- 6. 总结
- 三、我做的一些分析、优化和总结
- 使用并行计算缩短词干提取时间
- 可能的原因
- 优化方案
- 为什么在处理大规模数据集时,spaCy要优于nltk?
- 1. **spaCy 专为工业级处理优化**
- 2. **批量处理能力(Pipeline 和 nlp.pipe)**
- 3. **并行处理**
- 4. **内存管理和效率**
- 5. **词形还原 vs 词干提取**
- 6. **预训练的语言模型**
- 7. **简洁的 API 和现代设计**
- 8. **依赖关系和集成**
- 总结:
- 用spaCy替代nltk来加速词干提取的尝试
- 初步尝试效果不理想
- 使用spaCy的批处理功能来进一步优化
- 并行处理优化
- 总结
- spaCy词干提取的实际耗时比nltk更长的原因
- 1. **词干提取与词形还原的区别**
- 2. **`spaCy` 的处理管道更复杂**
- 3. **词形还原复杂度高**
- 4. **多进程的开销**
- 5. **模型加载和内存管理**
- 总结:
- 使用并行计算缩短移除停用词的时间
- 多个模型结果对比
- 训练时间
- 准确率(Accuracy)
- 分类报告
- 混淆矩阵(Confusion matrix)
- 为什么LR的训练时间远大于LSVM和MNB?
- 1. **逻辑回归(LR)**:
- 2. **线性支持向量机(LSVM)**:
- 3. **多项式朴素贝叶斯(MNB)**:
- 总结:
- 为什么LSVM在准确率上的表现不如LR和MNB?
- 原因:
- 总结:
- 为什么LSVM在分类报告上的结果较差?
- 1. **类不平衡问题**
- 2. **线性可分性问题**
- 3. **偏差问题**:
- 解决方案建议:
- 总结:
- 为什么LSVM在混淆矩阵上的结果较差?
- 优化TFIDF的参数大幅提升了准确率
- 说明
- 只修改了一行代码
- 对LR和MNB模型的影响
- 对LSVM模型的影响
- 优化TFIDF的参数大幅提升了准确率的原因分析
- 1. **`min_df` 参数的修改**:
- 2. **`max_df` 参数的修改**:
- 3. **`ngram_range` 参数的修改**:
- 总结三个参数的修改对模型的影响:
- 为什么 **LSVM** 的正类样本识别问题也修复了?
- 总结:
- 结尾:如何进一步提升准确率?
- 1. **进一步优化特征工程**
- 2. **调优超参数**
- 3. **使用预训练的词向量或深度学习模型**
- 4. **模型集成**:
- 5. **增强数据集(Data Augmentation)**
- 6. **处理类别不平衡问题**
- 7. **进一步错误分析**
- 总结:
一、前期准备工作
kaggle上的项目我应该如何学习和实践
在Kaggle上学习和实践是提升数据科学和NLP技能的好方法。以下是一些具体的建议,帮助你更好地利用Kaggle上的资源:
1. 选择合适的项目
- 从入门项目开始:如果你是Kaggle的新手,可以先选择一些初级项目,比如Titanic生存预测、房价预测等。这些项目通常有大量的解决方案和教程,可以帮助你快速上手。
- 关注NLP相关比赛和数据集:既然你对NLP感兴趣,可以选择一些与NLP相关的比赛或数据集,例如文本分类、情感分析、问答系统等。可以通过搜索关键词“text”、“NLP”来找到相关的项目。
2. 学习别人分享的解决方案
- 浏览排行榜前几名的解决方案:在比赛结束后,很多顶尖选手会分享他们的代码和解决方案。你可以学习他们的思路、模型选择和参数调优技巧。这些都是非常宝贵的学习资源。
- 阅读讨论区:Kaggle的讨论区是一个很好的资源,选手们会分享他们的实验结果、遇到的问题以及解决方案。通过参与讨论,你也可以提升自己的理解和技能。
3. 动手实践
- 独立完成项目:在学习了别人的解决方案之后,尝试自己从头到尾独立完成一个项目。从数据预处理、特征工程到模型训练和评估,每一步都尽量自己完成,这样能够加深理解。
- 进行反复迭代:尝试不同的模型、参数调整、特征工程方法,看看能否提升模型性能。通过这种反复迭代,你会逐渐掌握一些优化技巧。
4. 参加Kaggle竞赛
- 加入团队:对于一些难度较大的比赛,可以考虑加入一个团队。团队合作可以帮助你学习新的技能和方法,同时也能激发更多的创意和灵感。
- 设定目标:比赛中设定一个具体的目标,例如进入前50%或提升某一指标,这可以帮助你保持动力,并逐步提高自己的水平。
5. 总结和复盘
- 记录学习笔记:在完成每个项目或比赛后,写一篇总结,记录下你学到的知识、遇到的挑战以及解决方法。这个过程不仅有助于加深理解,还能帮助你在面试中更好地展示自己的能力。
- 开源自己的项目:将你完成的项目代码上传到GitHub,并在Kaggle上分享你的解决方案和思路。这不仅是对自己学习的一个总结,也是展示你技能的一个平台。
6. 持续学习和提升
- 学习新工具和技术:Kaggle上经常有新的库、模型和技术出现,比如Transformer、BERT、GPT等。保持学习的态度,不断尝试新工具,跟上行业的发展步伐。
- 参与社区活动:Kaggle上有很多社区活动,如Kernel竞赛、学习打卡等,参与这些活动可以帮助你保持学习的节奏,并结识更多志同道合的人。
通过以上步骤,你可以系统地提升自己在数据科学和NLP领域的技能,并为进入相关领域的工作打下坚实的基础。如果在学习过程中有具体的问题,随时可以向我提问。
如何学习别人分享的解决方案
请具体说明如何学习别人分享的解决方案,可以以这个网址的案例来分析:https://www.kaggle.com/code/lakshmi25npathi/sentiment-analysis-of-imdb-movie-reviews/notebook
要学习和分析Kaggle上别人分享的解决方案,你可以遵循以下步骤。我们以你提供的网址中的IMDB电影评论情感分析项目为例,来具体说明如何学习和实践。
1. 初步浏览项目
- 打开Notebook:首先,打开这个Notebook,快速浏览一下内容。了解作者在这个项目中使用了哪些步骤,包括数据加载、预处理、模型选择、训练和评估。
- 明确目标:理解该项目的目标——IMDB电影评论的情感分析任务。这是一个二分类问题,目的是预测每条评论的情感是“正面”还是“负面”。
2. 理解数据处理过程
-
数据加载和探索:
- 查看作者是如何加载数据的,使用了哪些Python库(如Pandas、Numpy)。
- 观察数据探索的步骤,理解数据集的结构、样本数量、类别分布等。如果有数据可视化的部分,理解图表所表达的信息。
-
数据预处理:
- 研究作者的数据清洗和预处理步骤,如文本的标点符号处理、大小写转换、停用词去除、词干化或词形还原等。理解为什么要进行这些处理,以及这些处理对模型的影响。
- 如果使用了特定的库(如NLTK、SpaCy、TfidfVectorizer),查看这些库的文档,理解其功能和用法。
3. 分析特征工程
- 特征提取:
- 注意作者如何将文本数据转换为模型可以理解的数值特征。这通常包括词袋模型(Bag of Words)、TF-IDF、Word Embeddings等方法。理解每种方法的优缺点。
- 如果使用了嵌入层(如Word2Vec或GloVe),理解这些嵌入如何帮助模型捕捉词语之间的语义关系。
4. 理解模型选择与训练
-
模型选择:
- 作者选择了哪些模型(如Logistic Regression、SVM、深度学习模型等)?了解这些模型的工作原理,以及为什么选择这些模型来解决情感分析问题。
- 如果作者对模型进行了超参数调优,研究调优的策略和结果。理解如何通过交叉验证选择最佳参数组合。
-
模型训练:
- 注意训练过程中的技巧,例如如何处理过拟合(Overfitting),是否使用了正则化,是否进行了数据增强等。
- 如果使用了深度学习模型,研究网络结构、激活函数、损失函数和优化器的选择。
5. 模型评估与优化
-
评估指标:
- 查看作者使用了哪些指标来评估模型的表现,如准确率、精确率、召回率、F1分数等。理解每个指标的含义,以及在情感分析任务中它们的适用性。
- 如果有混淆矩阵、ROC曲线或其他评估图表,理解这些图表如何帮助评估模型的性能。
-
模型优化:
- 注意作者是否进行了模型优化,如通过调参、特征选择或组合不同模型进行集成学习。理解这些优化如何提高了模型的性能。
6. 总结与反思
-
项目总结:
- 仔细阅读作者的总结部分,理解他们对项目的反思,包括模型的优缺点、未来改进的方向。
- 思考你在这个项目中学到了什么,是否有可以借鉴或改进的地方。
-
尝试复现:
- 在你本地或Kaggle的环境中复现这个Notebook,确保你理解每个步骤并能成功运行。
- 在复现的过程中,可以尝试做一些修改,比如使用不同的模型、调参、或改变预处理步骤,看看对结果有何影响。
7. 拓展与实践
- 应用到其他项目:
- 将你在这个项目中学到的知识和方法,应用到其他类似的NLP项目中。例如,可以尝试使用相同的方法处理不同的数据集,看看效果如何。
- 分享与交流:
- 如果你有新的想法或改进,可以在Kaggle上分享自己的Notebook,与社区交流。通过参与讨论,你可以获得更多反馈,并进一步提升自己的技能。
通过以上步骤,你可以深入理解一个Kaggle项目的解决方案,并通过实践巩固自己的知识。如果在分析或实践过程中遇到问题,随时可以向我寻求帮助。
一个电影评论情感分析项目一般分为哪些步骤?
一个电影评论情感分析项目通常包括以下主要步骤:
1. 数据收集
- 获取数据:从电影评论网站(如IMDb、Rotten Tomatoes、豆瓣等)获取评论数据。数据可以通过API、网页抓取(如使用
BeautifulSoup、Scrapy)或从公开数据集(如Kaggle)获取。 - 数据格式化:将收集到的评论数据存储在适当的格式中,通常是CSV或JSON格式,每条评论包括评论文本和标签(如果已存在标签)。
2. 数据预处理
- 文本清理:包括移除HTML标签、标点符号、特殊字符,转换为小写,去除多余的空格等。
- 去除停用词:使用停用词表(如
nltk提供的stopwords)移除对情感分析无关的常见词汇。 - 拼写校正(可选):对评论中的拼写错误进行纠正,特别是如果拼写错误可能影响情感分析结果。
- 词干提取或词形还原:将单词转换为其词干或词根形式,以减少词汇量。
- 文本标记化:将文本拆分为单词或词组(Tokenization)。
3. 数据标注
- 手动标注:如果评论没有情感标签,可能需要手动标注情感类别(正面、负面或中性)。
- 自动标注:可以使用情感词典或预训练模型进行初步标注,然后进行人工校正。
4. 特征提取
- 词袋模型(Bag of Words):将文本转换为词频向量,忽略词序。
- TF-IDF(Term Frequency-Inverse Document Frequency):在词频的基础上,考虑单词在整个语料库中的出现频率。
- 词嵌入(Word Embeddings):使用预训练的词向量(如Word2Vec、GloVe)或上下文感知的模型(如BERT)将文本转换为向量表示,捕捉语义信息。
5. 模型选择与训练
- 选择模型:根据任务需求选择适当的机器学习或深度学习模型,如逻辑回归、支持向量机(SVM)、随机森林、LSTM、BERT等。
- 训练模型:使用训练数据集对模型进行训练,调整超参数以优化模型性能。
- 交叉验证:使用交叉验证方法评估模型在不同数据子集上的表现,避免过拟合。
6. 模型评估
- 性能指标:使用准确率、精确率、召回率、F1分数等指标评估模型的表现。
- 混淆矩阵:分析混淆矩阵,查看模型在哪些类别上表现不佳,可能需要调整模型或进一步清理数据。
7. 模型调优
- 超参数调优:使用网格搜索(Grid Search)或随机搜索(Random Search)等方法调整模型的超参数。
- 特征选择:通过选择最有用的特征(如使用PCA降维)来简化模型,提高性能。
8. 模型部署
- 模型保存:将训练好的模型保存为文件(如
pickle格式),以便部署。 - API部署:将模型部署为Web服务或API,允许用户提交评论并获取情感分析结果。
- 用户界面(可选):创建一个简单的用户界面,允许用户输入电影评论并查看分析结果。
9. 结果分析与报告
- 结果可视化:使用图表(如柱状图、饼图)展示情感分类结果,分析评论的情感分布。
- 报告撰写:总结项目的主要发现、模型的表现、遇到的挑战及未来改进方向。
10. 持续优化与维护
- 模型监控:在实际应用中监控模型的表现,处理新的数据,并定期更新模型。
- 用户反馈:收集用户反馈,根据实际需求调整模型或改进算法。
通过以上步骤,你可以完成一个完整的电影评论情感分析项目,从数据收集到模型部署,再到结果分析,为电影评论提供有价值的情感洞察。
二、项目的主要流程
数据收集
kaggle上已经存在现成的CSV格式的数据集,每条评论包括评论文本和标签。省去了数据收集的过程。
数据加载
复制一份notebook,先把Import necessary libraries和Import the training dataset两部分跑一下,因为kaggle可以使用你复制的notebook的老环境,所以不会出现版本兼容问题。

数据探索
pandas的describe函数
理解数据集的结构、样本数量、类别分布等
pandas 的 describe 函数是一个非常有用的工具,用于快速生成数据帧中数值型数据的描述性统计信息。它可以帮助你快速了解数据的分布情况。
1. 基本用法
当你调用 describe 函数时,它会返回如下统计信息:
- count: 非空值的数量
- mean: 平均值
- std: 标准差
- min: 最小值
- 25%: 第一个四分位数(下四分位数)
- 50%: 中位数(第二个四分位数)
- 75%: 第三个四分位数(上四分位数)
- max: 最大值
示例代码:
import pandas as pd
# 创建一个简单的数据帧
data = {
'age': [23, 29, 31, 35, 40, 28, 50],
'salary': [70000, 80000, 120000, 110000, 150000, 95000, 130000]
}
df = pd.DataFrame(data)
# 使用 describe 函数
description = df.describe()
print(description)
输出:
age salary
count 7.000000 7.000000
mean 33.714286 108571.428571
std 8.948008 27076.642949
min 23.000000 70000.000000
25% 28.000000 95000.000000
50% 31.000000 110000.000000
75% 35.000000 130000.000000
max 50.000000 150000.000000
2. 非数值数据的处理
对于非数值类型的数据(如字符串类型),你可以通过将 include 参数设置为 'all' 来获得描述性统计信息。它会提供计数、唯一值数量、最频繁出现的值(top)以及该值的频率(freq)。
示例代码:
data = {
'name': ['Alice', 'Bob', 'Charlie', 'David', 'Edward', 'Alice', 'Bob'],
'age': [23, 29, 31, 35, 40, 28, 50]
}
df = pd.DataFrame(data)
# 对所有列使用 describe
description = df.describe(include='all')
print(description)
输出:
name age
count 7 7.000000
unique 5 NaN
top Alice NaN
freq 2 NaN
mean NaN 33.714286
std NaN 8.948008
min NaN 23.000000
25% NaN 28.000000
50% NaN 31.000000
75% NaN 35.000000
max NaN 50.000000
3. 选择性描述
你可以通过 include 和 exclude 参数来选择性地描述数据。例如,只描述数据帧中的某种类型的数据。
只描述数值型数据:
description = df.describe(include=[np.number])
只描述字符串类型的数据:
description = df.describe(include=[object])
4. 多重描述
你还可以描述多种类型的数据,通过 include 参数传递一个列表:
description = df.describe(include=[np.number, object])
describe 函数是快速理解数据集结构的好方法,尤其是在数据分析的初期阶段。通过它,你可以轻松获得数据的基本统计信息,从而为后续的分析提供依据。
划分数据集(Spliting dataset)
将数据集划分为训练数据集(40000个样本)和测试数据集(10000个样本)
数据预处理 Data pre-processing
在情感分析项目中,数据预处理主要做文本规范化(Text normalization)
在情感分析项目中,数据预处理是一个关键步骤,旨在将原始文本数据转换为适合模型输入的格式。以下是数据预处理的常见步骤:
1. 文本清理
文本清理的目标是去除原始文本中的噪声,以便更好地提取有用的信息。主要包括以下操作:
-
移除HTML标签:有些评论可能包含HTML标签,需要使用
BeautifulSoup或正则表达式将其移除。from bs4 import BeautifulSoup def remove_html_tags(text): soup = BeautifulSoup(text, "html.parser") return soup.get_text() -
移除特殊字符:删除标点符号、数字和其他非字母字符,保留字母和空格。
import re def remove_special_characters(text): return re.sub(r'[^a-zA-Z\s]', '', text) -
转换为小写:将所有文本转换为小写,确保同一单词不会因为大小写不同而被认为是不同的词。
def to_lowercase(text): return text.lower() -
去除多余的空白:删除多余的空格、换行符等,确保词汇之间只有一个空格。
def remove_extra_whitespace(text): return ' '.join(text.split())
2. 去除停用词
停用词(如 “the”, “is”, “in” 等)是高频且对情感分析贡献较小的词汇。去除这些词有助于简化文本表示,减少模型的复杂性。
from nltk.corpus import stopwords
# 下载并加载停用词列表
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
def remove_stopwords(text):
return ' '.join([word for word in text.split() if word not in stop_words])
3. 拼写校正(可选)
在处理用户生成内容时,文本中可能包含拼写错误,这些错误可能影响情感分析的准确性。可以使用拼写校正工具来纠正这些错误。
from textblob import TextBlob
def correct_spelling(text):
return str(TextBlob(text).correct())
4. 词干提取或词形还原
-
词干提取:将单词转换为其词干形式,去掉词缀。例如,将 “running” 转为 “run”。
from nltk.stem import PorterStemmer stemmer = PorterStemmer() def stem_words(text): return ' '.join([stemmer.stem(word) for word in text.split()]) -
词形还原:将单词还原为其基本形式(如 “running” 转为 “run”),通常比词干提取更精确。
from nltk.stem import WordNetLemmatizer from nltk.corpus import wordnet nltk.download('wordnet') lemmatizer = WordNetLemmatizer() def lemmatize_words(text): return ' '.join([lemmatizer.lemmatize(word, wordnet.VERB) for word in text.split()])
5. 文本标记化
标记化是将文本拆分为单词、短语或其他有意义的单元。通常使用空格分隔单词,但也可以使用更复杂的标记化工具来处理。
from nltk.tokenize import word_tokenize
nltk.download('punkt')
def tokenize_text(text):
return word_tokenize(text)
6. 处理频繁或罕见词汇
- 频繁词汇:有时,某些高频词可能无助于情感分析,可以考虑去除这些词。
- 罕见词汇:罕见词汇(只出现一次或极少出现)可能是拼写错误或无意义的词,也可以考虑去除。
from collections import Counter
def remove_rare_words(text, min_freq=2):
words = text.split()
freq = Counter(words)
return ' '.join([word for word in words if freq[word] >= min_freq])
7. 文本表示转换
- 词袋模型(Bag of Words):将文本转换为词频向量。
- TF-IDF:在词频的基础上,考虑单词在整个语料库中的出现频率。
- 词嵌入(Word Embeddings):使用Word2Vec、GloVe等方法,将单词表示为向量,捕捉语义信息。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 词袋模型
vectorizer = CountVectorizer()
X_bow = vectorizer.fit_transform(corpus)
# TF-IDF
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
8. 总结
数据预处理是情感分析项目中的关键步骤,直接影响模型的性能和效果。通过合理的预处理,可以有效地提取文本中的关键信息,减少噪声,从而提高情感分类的准确性。不同的项目可能需要不同的预处理步骤,因此需要根据具体情况灵活选择和组合这些技术。
为什么在数据预处理之前需要先进行数据集的拆分?
在数据预处理之前需要先进行数据集的拆分(通常是将数据分为训练集和测试集)。其核心概念是为了避免数据泄漏(Data Leakage),以及模拟真实世界中处理未知数据的情景。
关键点解释:
-
数据泄漏(Data Leakage):
- 数据泄漏 是指在模型训练过程中,模型获取到了测试集中的信息,导致模型的性能看起来很好,但实际上对新数据的泛化能力很差。如果你在拆分数据之前对整个数据集进行某些计算(例如归一化、特征缩放、特征选择等操作),这些计算会基于整个数据集,包括测试集。这会让模型在训练时“看到了”本不该看到的测试集信息,产生不公平的结果,导致数据泄漏。
-
计算数据值的操作:
- 一些预处理操作,例如特征缩放(归一化、标准化)、PCA 等,都会基于数据集的统计信息进行计算(如均值、标准差等)。如果这些操作在拆分数据之前进行,测试集中的信息就会“泄露”给训练过程,导致模型在评估阶段表现不真实。
-
模拟现实世界中的未知数据:
- 现实世界中,模型训练完成后,将会面对完全未知的数据。因此,在数据预处理之前拆分数据集(通常是将数据分为训练集、验证集和测试集)能够更好地模拟这种情形。测试集应当只用于最终的模型评估,不能参与任何模型的训练和调整,确保模型在测试集上做出的预测能够代表它在真实数据上的表现。
总结:
在数据预处理之前拆分数据集的原因是为了防止数据泄漏,并且能够更真实地模拟模型在未知数据上的表现。
移除HTML标签
Removing the html strips
文本规范化的顺序很重要,移除HTML标签这一步要先做。
要从文本中移除HTML标签(也称为“HTML strips”),可以使用Python的BeautifulSoup库。这在自然语言处理(NLP)和网页抓取中是一个常见的预处理步骤。以下是详细的中文解释,包括步骤、示例代码和应用场景。
1. 安装 BeautifulSoup
在开始之前,需要确保已经安装了BeautifulSoup库。可以使用pip进行安装:
pip install beautifulsoup4
2. 使用 BeautifulSoup 移除HTML标签
BeautifulSoup可以解析HTML内容,并提取纯文本,去除所有HTML标签。以下是具体的实现步骤和示例代码。
示例代码
from bs4 import BeautifulSoup
def remove_html_tags(text):
"""
移除文本中的HTML标签。
参数:
text (str): 包含HTML标签的字符串。
返回:
str: 移除HTML标签后的纯文本。
"""
# 使用 BeautifulSoup 解析HTML内容
soup = BeautifulSoup(text, "html.parser")
# 获取文本内容,去除所有HTML标签
return soup.get_text()
# 示例HTML文本
html_text = """
<div>
<h1>欢迎来到NLP世界!</h1>
<p>这是一个包含<a href="http://example.com">链接</a的示例段落。</p>
<p>让我们移除<b>HTML</b>标签吧!</p>
</div>
"""
# 移除HTML标签
clean_text = remove_html_tags(html_text)
print(clean_text)
输出结果
欢迎来到NLP世界!
这是一个包含链接的示例段落。
让我们移除HTML标签吧!
3. 代码解析
-
导入库:
from bs4 import BeautifulSoup导入
BeautifulSoup库,用于解析和处理HTML内容。 -
定义函数:
def remove_html_tags(text): soup = BeautifulSoup(text, "html.parser") return soup.get_text()定义一个函数
remove_html_tags,接受一个包含HTML标签的字符串,返回移除标签后的纯文本。 -
解析HTML内容:
soup = BeautifulSoup(text, "html.parser")使用
BeautifulSoup解析传入的HTML字符串,指定使用html.parser作为解析器。 -
提取纯文本:
return soup.get_text()使用
soup.get_text()方法提取纯文本,自动去除所有HTML标签。
4. 应用场景
-
网页抓取:
在从网页抓取数据时,通常会获取到包含大量HTML标签的内容。使用BeautifulSoup可以轻松提取纯文本,便于后续的数据分析和处理。 -
数据预处理:
在进行自然语言处理(如文本分类、情感分析等)之前,清理文本中的HTML标签可以提高模型的准确性和效率。 -
用户生成内容:
处理用户生成的内容(如评论、论坛帖子等)时,可能包含HTML标签。移除这些标签可以获得更干净的文本数据。
5. 处理复杂情况
有时候,你可能需要保留某些特定的HTML标签或内容。BeautifulSoup提供了灵活的方式来定制解析和提取规则。例如,可以只移除某些特定的标签,或者保留标签内的特定属性。
示例:移除特定标签
def remove_specific_tags(text, tags):
"""
移除文本中指定的HTML标签。
参数:
text (str): 包含HTML标签的字符串。
tags (list): 需要移除的HTML标签列表。
返回:
str: 移除指定标签后的纯文本。
"""
soup = BeautifulSoup(text, "html.parser")
for tag in tags:
for match in soup.find_all(tag):
match.decompose() # 完全移除标签及其内容
return soup.get_text()
# 示例HTML文本
html_text = """
<div>
<h1>欢迎来到NLP世界!</h1>
<p>这是一个包含<a href="http://example.com">链接</a的示例段落。</p>
<p>让我们移除<b>HTML</b>标签吧!</p>
</div>
"""
# 只移除<b>标签
clean_text = remove_specific_tags(html_text, ['b'])
print(clean_text)
输出结果
欢迎来到NLP世界!
这是一个包含链接的示例段落。
让我们移除HTML标签吧!
在这个示例中,只有<b>标签被移除,其他标签(如<a>)仍然保留并被转换为纯文本。
6. 注意事项
-
编码问题:
确保处理的文本编码正确,尤其是在处理多语言内容时。BeautifulSoup通常能够自动检测编码,但在某些情况下可能需要手动指定。 -
特殊字符:
有些HTML内容中包含实体字符(如&表示&)。BeautifulSoup会自动转换这些实体字符为相应的符号。 -
性能考虑:
对于非常大的HTML文档,解析和处理可能会消耗较多的内存和时间。在这种情况下,可以考虑逐步解析或使用更高效的解析器。
7. 替代方法
除了BeautifulSoup,还有其他方法和库可以用来移除HTML标签:
-
使用正则表达式:
虽然不推荐,但在简单情况下可以使用正则表达式移除HTML标签。import re def remove_html_tags_regex(text): clean = re.compile('<.*?>') return re.sub(clean, '', text) html_text = "<p>Hello <b>World</b>!</p>" clean_text = remove_html_tags_regex(html_text) print(clean_text) # 输出: Hello World!注意:正则表达式对于复杂的HTML结构可能不够可靠,容易出错,因此不推荐用于复杂的HTML解析。
-
使用
lxml库:
lxml是另一个强大的HTML和XML解析库,具有更高的性能。from lxml import etree from io import StringIO def remove_html_tags_lxml(text): parser = etree.HTMLParser() tree = etree.parse(StringIO(text), parser) return ''.join(tree.xpath('//text()')) html_text = "<p>Hello <b>World</b>!</p>" clean_text = remove_html_tags_lxml(html_text) print(clean_text) # 输出: Hello World!
总结
移除HTML标签是文本预处理中的关键步骤,BeautifulSoup提供了一种简便且高效的方法来实现这一目标。通过解析HTML内容并提取纯文本,可以为后续的自然语言处理任务打下坚实的基础。根据具体需求,还可以结合其他方法进行更细致的文本清理和处理。
移除方括号及其内容
Removing the square brackets
移除文本中的方括号(即[])及其内容是文本预处理中的一个常见任务。方括号通常用于包裹注释、参考文献编号或其他不需要的内容,在文本分析之前,我们可能需要将其去除。以下是实现这一任务的详细中文解释。
1. 使用正则表达式移除方括号及其内容
正则表达式(Regular Expression, 简称 regex)是一个强大的工具,可以用于匹配和替换字符串中的特定模式。要移除方括号及其中的内容,我们可以使用正则表达式来查找匹配的部分并将其替换为空字符串。
2. 示例代码
以下是一个使用Python和正则表达式来移除方括号及其内容的示例代码:
import re
def remove_square_brackets(text):
"""
移除文本中的方括号及其内容。
参数:
text (str): 输入的字符串。
返回:
str: 移除方括号及其内容后的字符串。
"""
# 使用正则表达式匹配方括号及其中的内容,并将其替换为空字符串
cleaned_text = re.sub(r'\[.*?\]', '', text)
# 去除多余的空白符
cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip()
return cleaned_text
# 示例文本
text = "这是一个包含方括号的示例文本 [参考1],它应该被清理。"
# 移除方括号及其内容
cleaned_text = remove_square_brackets(text)
print(cleaned_text)
3. 输出结果
这是一个包含方括号的示例文本,它应该被清理。
4. 代码解析
-
re.sub(r'\[.*?\]', '', text):
这行代码使用正则表达式r'\[.*?\]'来匹配方括号及其中的内容。具体来说:\[: 匹配左方括号[(需要加反斜杠来转义)。.*?: 非贪婪模式匹配任意字符,直到遇到第一个右方括号]。\]: 匹配右方括号](同样需要加反斜杠来转义)。'': 将匹配到的内容替换为空字符串。
-
re.sub(r'\s+', ' ', cleaned_text).strip():
这行代码用于去除多余的空白符,包括由于移除方括号及其内容后可能产生的多余空格。strip()用于去除字符串两端的空格。
5. 应用场景
-
文本清理:
在处理用户评论、论坛帖子或其他包含参考文献、注释等内容的文本时,方括号内的内容通常是分析时不需要的,可以通过这种方法清理掉。 -
自然语言处理:
在进行文本分类、情感分析等NLP任务时,移除方括号及其内容可以减少噪声,提高模型的准确性。 -
文档处理:
在处理包含文献引用(如学术论文)的文档时,可以使用这种方法去除引用标记,得到更干净的文本内容。
6. 注意事项
-
贪婪与非贪婪匹配:
在正则表达式中,.*?是非贪婪匹配,它会匹配尽可能少的字符直到遇到第一个右方括号。如果使用.*(贪婪匹配),它会匹配尽可能多的字符,可能会导致错误地移除不需要的内容。 -
嵌套方括号:
如果文本中包含嵌套的方括号(如[[内容]]),上述正则表达式可能无法正确处理,需要更复杂的正则表达式来匹配嵌套的结构。
通过上述方法,你可以有效地移除文本中的方括号及其内容,为后续的文本处理任务做好准备。如果有特定的需求,也可以根据需要调整正则表达式的匹配规则。
移除方括号及其内容-本项目代码解析
re.sub('\[[^]]*\]', '', text)
这段代码 re.sub('\[[^]]*\]', '', text) 使用正则表达式(regex)来移除字符串 text 中的方括号及其内容。以下是对代码的逐步解析:
1. re.sub() 函数
re.sub() 是 Python 中 re 模块的一个函数,用于替换字符串中符合某个正则表达式模式的部分。其基本语法为:
re.sub(pattern, replacement, string)
pattern: 用于匹配字符串的正则表达式模式。replacement: 用于替换匹配部分的字符串。在这个例子中是空字符串'',表示删除匹配部分。string: 要处理的原始字符串。
2. 正则表达式 '\[[^]]*\]' 解析
正则表达式 '\[[^]]*\]' 用于匹配方括号以及括号内的内容。我们逐步解析这一模式:
-
\[:- 这个模式用于匹配左方括号
[. 由于方括号在正则表达式中有特殊意义,表示字符集,因此需要用反斜杠\进行转义。\[表示精确匹配字符[.
- 这个模式用于匹配左方括号
-
[^]]*:[^]]: 方括号中的^是一个否定符号,表示“非”或“排除”。因此,[^]]表示匹配除右方括号]之外的任何字符。*: 量词,表示匹配前面的字符集零次或多次。即它匹配任意长度的、包含非]字符的序列。
因此,
[^]]*匹配的是从左方括号开始,到右方括号之前的所有字符,不包括右方括号本身。 -
\]:- 这个模式用于匹配右方括号
]. 同样,由于右方括号在正则表达式中有特殊意义,也需要用反斜杠\进行转义。
- 这个模式用于匹配右方括号
3. 整体代码解析
re.sub('\[[^]]*\]', '', text) 这行代码的作用是:
-
匹配模式: 查找
text中所有以[开头、以]结尾的字符串片段,其中包括左方括号、右方括号,以及它们之间的任何字符。 -
替换操作: 将所有匹配到的字符串片段替换为空字符串
'',即将这些方括号及其内容删除。
4. 示例
假设有如下字符串:
import re
text = "这是一个包含方括号的示例文本 [参考1],它应该被清理。"
cleaned_text = re.sub(r'\[[^]]*\]', '', text)
print(cleaned_text)
输出结果:
这是一个包含方括号的示例文本 ,它应该被清理。
5. 总结
- 作用: 这段代码用于从文本中移除所有带有方括号的内容,包括方括号本身以及其中的字符。
- 正则表达式:
'\[[^]]*\]'的作用是匹配以[开始、以]结束的所有内容,其中中间的部分可以是任意字符,但不包括]本身。 re.sub(): 使用这个正则表达式模式来查找并替换匹配到的内容,在本例中是替换为空字符串,相当于删除这些内容。
这种方式非常适合处理需要移除文本中特定标记或注释内容的情况,比如在清理数据中的参考文献、注释或无关内容时。
去除多余的两个函数定义
作者这里的代码很简单,没必要定义两个函数,所以我去除了函数strip_html和remove_between_square_brackets。这样更简洁
作者的代码:
#Removing the html strips
def strip_html(text):
soup = BeautifulSoup(text, "html.parser")
return soup.get_text()
#Removing the square brackets
def remove_between_square_brackets(text):
return re.sub('\[[^]]*\]', '', text)
#Removing the noisy text
def denoise_text(text):
text = strip_html(text)
text = remove_between_square_brackets(text)
return text
#Apply function on review column
imdb_data['review']=imdb_data['review'].apply(denoise_text)
我修改后的代码:
#Removing the noisy text
def denoise_text(text):
#Removing the html strips
text = BeautifulSoup(text, "html.parser").get_text()
#Removing the square brackets
text = re.sub('\[[^]]*\]', '', text)
return text
#Apply function on review column
imdb_data['review']=imdb_data['review'].apply(denoise_text)
移除特殊字符
Removing special characters
移除特殊字符是文本预处理中的常见步骤,通常用于清理文本数据,使其更容易被模型处理。特殊字符包括标点符号、数字、HTML标签、非ASCII字符等。以下是一些常见的方法和示例代码,展示如何移除这些特殊字符。
1. 移除所有非字母字符
这是最常见的情况之一,通常我们希望保留字母字符和空格,移除所有其他字符(如标点符号、数字、特殊符号等)。
示例代码:
import re
def remove_special_characters(text):
# 使用正则表达式移除所有非字母字符(保留空格)
cleaned_text = re.sub(r'[^A-Za-z\s]', '', text)
# 去除多余的空白符
cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip()
return cleaned_text
# 示例文本
text = "Hello!!! Welcome to the world of NLP 101. Let's clean this #data!"
# 移除特殊字符
cleaned_text = remove_special_characters(text)
print(cleaned_text)
输出:
Hello Welcome to the world of NLP Lets clean this data
2. 移除特定的特殊字符
如果你只想移除特定的特殊字符而保留其他内容,可以在正则表达式中指定需要移除的字符。
示例代码:
def remove_specific_characters(text, characters_to_remove):
# 创建正则表达式模式
pattern = f"[{re.escape(characters_to_remove)}]"
# 使用正则表达式移除特定字符
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
# 示例文本
text = "Hello!!! Welcome to the world of NLP 101. Let's clean this #data!"
# 只移除感叹号和数字
cleaned_text = remove_specific_characters(text, "!1234567890")
print(cleaned_text)
输出:
Hello Welcome to the world of NLP . Let's clean this #data!
3. 移除非ASCII字符
在某些情况下,你可能需要移除所有非ASCII字符(如特殊符号、外语字符等),以确保文本只包含标准的英文字母和标点符号。
示例代码:
def remove_non_ascii(text):
# 使用正则表达式移除所有非ASCII字符
cleaned_text = re.sub(r'[^\x00-\x7F]+', '', text)
return cleaned_text
# 示例文本
text = "Hello! Welcome to the world of NLP. Let's clean this data – 你好!"
# 移除非ASCII字符
cleaned_text = remove_non_ascii(text)
print(cleaned_text)
输出:
Hello! Welcome to the world of NLP. Let's clean this data !
4. 移除所有特殊字符并保留数字
有时你可能希望保留文本中的数字并只移除标点符号和特殊字符。
示例代码:
def remove_special_characters_but_keep_numbers(text):
# 移除所有非字母和非数字字符
cleaned_text = re.sub(r'[^A-Za-z0-9\s]', '', text)
# 去除多余的空白符
cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip()
return cleaned_text
# 示例文本
text = "Hello!!! Welcome to the world of NLP 101. Let's clean this #data!"
# 移除特殊字符但保留数字
cleaned_text = remove_special_characters_but_keep_numbers(text)
print(cleaned_text)
输出:
Hello Welcome to the world of NLP 101 Lets clean this data
5. 处理噪声的注意事项
- 语境重要:在清理特殊字符时,要考虑文本的语境。例如,在社交媒体数据处理中,#和@符号可能有重要意义(如标签和用户名),不应随意移除。
- 自定义规则:根据任务的需求,自定义处理规则。例如,在处理金融数据时,保留$符号可能很重要。
通过这些方法,你可以根据具体需求清理文本中的特殊字符,从而提高文本数据的质量,为后续的自然语言处理任务做好准备。如果有特定的清理需求,可以根据上述方法进行调整和扩展。
移除特殊字符-本项目代码
原作者代码:
pattern=r'[^a-zA-z0-9\s]'
text=re.sub(pattern,'',text)
有个小错误,应该将z改为Z:
pattern=r'[^a-zA-Z0-9\s]'
text=re.sub(pattern,'',text)
这段代码使用了正则表达式来清理文本中的特殊字符。以下是对代码的详细解析。
1. 代码概览
pattern = r'[^a-zA-Z0-9\s]'
text = re.sub(pattern, '', text)
pattern: 这是一个正则表达式,用于定义要匹配的字符模式。re.sub(pattern, '', text): 这是一个替换操作,使用正则表达式pattern匹配text中的内容,并将匹配到的内容替换为空字符串'',从而删除这些内容。
2. 正则表达式 r'[^a-zA-Z0-9\s]' 解析
-
r'':- 前缀
r表示这是一个原始字符串(raw string),在Python中,原始字符串中的反斜杠\不会被解释为转义符。因此,正则表达式的书写更加直接和清晰。
- 前缀
-
[]:- 方括号
[]表示字符集,字符集中列出了你希望匹配的一组字符。
- 方括号
-
a-zA-Z0-9\s:a-z: 匹配小写字母a到z。A-Z: 匹配大写字母A到Z。0-9: 匹配数字0到9。\s: 匹配任何空白字符(如空格、制表符、换行符等)。
-
^:- 在字符集的开头,
^是一个否定符号,表示“非”或“排除”。因此,[^...]表示匹配任何不在方括号内列出的字符。
- 在字符集的开头,
综合起来,r'[^a-zA-Z0-9\s]' 的含义是:
- 匹配任何非字母(无论大小写)、非数字、非空白字符的字符。
3. 整体代码解析
-
pattern = r'[^a-zA-Z0-9\s]':- 定义一个正则表达式模式,用于匹配所有不是字母(
a-z或A-Z)、数字(0-9)和空白字符(\s)的字符。
- 定义一个正则表达式模式,用于匹配所有不是字母(
-
text = re.sub(pattern, '', text):- 使用
re.sub()函数将text中匹配pattern的所有字符替换为空字符串'',相当于删除这些字符。
- 使用
4. 示例
假设你有以下字符串:
import re
text = "Hello, World! Welcome to NLP 101. Let's clean this #data!"
# 定义正则表达式模式
pattern = r'[^a-zA-Z0-9\s]'
# 删除非字母、数字和空白字符
cleaned_text = re.sub(pattern, '', text)
print(cleaned_text)
输出结果:
Hello World Welcome to NLP 101 Lets clean this data
5. 总结
- 目的: 这段代码的目的是移除字符串
text中的所有特殊字符,保留字母、数字和空白字符。 - 正则表达式
[^a-zA-Z0-9\s]: 匹配所有非字母、非数字和非空白字符的部分。 re.sub(): 替换匹配到的特殊字符为空字符串,从而删除它们。
这种处理方式在清理文本数据时非常常见,尤其是当你希望只保留字母和数字信息,而删除其他无关字符时。
Text stemming(文本词干提取)
Text stemming(文本词干提取)是一种常见的自然语言处理(NLP)技术,其目的是将单词还原为其词干或词根形式。词干是一个单词的基本形式,通常通过去掉后缀(如 “-ing”, “-ed”, “-ly”, “-es” 等)来实现。词干提取的结果不一定是一个合法的单词,但它能够将相关的词汇归为同一组,从而减少特征空间的维度,有助于文本分析和处理。
1. 为什么使用词干提取?
在文本处理中,同一单词的不同形式(如 “running”、“runner”、“ran”)可能会被看作不同的词汇,但在实际分析中,它们的根本意义是相同的。通过词干提取,可以将这些词统一为同一个词干(如 “run”),从而:
- 降低文本维度:减少模型需要处理的特征数量。
- 增强模型泛化能力:避免模型因为词形变化而无法识别相似词汇。
- 提高检索精度:在信息检索或搜索引擎中,能够更准确地匹配用户查询与文档内容。
2. 常见的词干提取算法
-
Porter Stemmer:由Martin Porter于1980年提出,是最常用的词干提取算法之一。它通过一系列规则来去除单词的后缀。
-
Snowball Stemmer(也叫Porter2 Stemmer):Porter算法的改进版本,支持多种语言,处理更复杂的规则。
-
Lancaster Stemmer:一种更为激进的词干提取算法,相较于Porter Stemmer更简洁但有时过于“暴力”,可能会过度削减词语。
3. 使用示例
以下是如何使用Python中的nltk库来进行词干提取的示例:
import nltk
from nltk.stem import PorterStemmer
# 创建一个PorterStemmer对象
porter = PorterStemmer()
# 示例单词列表
words = ["running", "runner", "ran", "easily", "fairly", "studies", "studying"]
# 对单词列表中的每个单词进行词干提取
stemmed_words = [porter.stem(word) for word in words]
print(stemmed_words)
输出结果:
['run', 'runner', 'ran', 'easili', 'fairli', 'studi', 'studi']
在这个例子中,我们使用了Porter Stemmer来提取词干:
- “running”, “runner” 和 “ran” 都被归一化为"run"或其变体。
- “easily” 被提取为 “easili”。
- “studies” 和 “studying” 被提取为 “studi”。
4. 应用场景
-
文本分类:在情感分析、主题建模等任务中,词干提取有助于统一不同形式的单词,提升分类器的准确性。
-
信息检索:在搜索引擎中,词干提取有助于提高查询的匹配度。
-
机器翻译:在预处理过程中,词干提取可以减少词汇表大小,提高翻译系统的效率。
5. 注意事项
-
词干化 vs. 词形还原(Lemmatization):词干提取只是去除词尾,不考虑词语的词性和词汇学含义,而词形还原会将单词还原为其在词典中的标准形式,因此更为精准。根据应用场景,可以选择词干提取或词形还原。
-
过度词干化:如Lancaster Stemmer,有时可能会过度简化单词,导致信息丢失。
6. 总结
词干提取是一种有效的文本预处理方法,可以减少文本中的特征数量,并增强模型的泛化能力。在实际应用中,选择合适的词干提取算法非常重要,通常需要根据具体的任务和数据集来决定是使用词干提取还是词形还原。
Removing stopwords(移除停用词)
在自然语言处理(NLP)中,移除停用词(stopwords)是文本预处理的一个重要步骤。停用词是指那些在文本中频繁出现但对分析意义不大的词汇,如“the”、“is”、“at”、“which”等。移除这些词可以减少噪声,提升模型的性能。
以下是移除停用词的步骤和示例代码,使用的是Python中的nltk库。
1. 安装和导入必要的库
首先,确保你已经安装了nltk库,并且已经下载了停用词列表。
pip install nltk
然后,在Python脚本中导入必要的模块:
import nltk
from nltk.corpus import stopwords
# 下载停用词列表
nltk.download('stopwords')
2. 加载停用词列表
你可以加载英语的停用词列表,nltk提供了多种语言的停用词列表。在这里我们使用英语的停用词列表。
stop_words = set(stopwords.words('english'))
3. 移除停用词
假设你有一段文本 text,可以通过以下代码移除其中的停用词:
text = "This is a simple example demonstrating the removal of stopwords from a sentence."
# 将文本拆分成单词列表
words = text.split()
# 移除停用词
filtered_words = [word for word in words if word.lower() not in stop_words]
# 将过滤后的单词列表重新组合成一个字符串
filtered_text = ' '.join(filtered_words)
print(filtered_text)
4. 代码解析
-
text.split():- 将文本字符串拆分成单词列表。
split()默认按空格分割字符串。
- 将文本字符串拆分成单词列表。
-
列表推导式:
filtered_words = [word for word in words if word.lower() not in stop_words]:- 遍历拆分后的单词列表,将每个单词转换为小写(
word.lower()),并检查它是否在停用词列表stop_words中。 - 如果该单词不在
stop_words中,就将其保留在新的列表filtered_words中。
- 遍历拆分后的单词列表,将每个单词转换为小写(
-
' '.join(filtered_words):- 将过滤后的单词列表重新组合成一个字符串,单词之间用空格分隔。
5. 示例输出
假设 text 为 "This is a simple example demonstrating the removal of stopwords from a sentence.",执行上述代码后,filtered_text 将是:
simple example demonstrating removal stopwords sentence
6. 总结
- 目的: 移除停用词可以减少文本中的无关信息,提升模型对重要特征的关注。
- 效果: 通过移除停用词,文本长度减少,内容更集中于有意义的词汇。
移除停用词是许多文本处理管道中的一个常见步骤,它有助于减少噪声,改善文本分析的效果。如果你处理的是非英语文本,nltk 还提供了其他语言的停用词列表,可以通过 stopwords.words('language') 来加载相应的停用词。
拼写校正(Spelling Correction)(可选)
文本规范化中的拼写校正
拼写校正(Spelling Correction)是文本规范化中的一个关键步骤,特别是在处理用户生成的内容(如社交媒体、论坛、评论等)时,这些内容常常包含拼写错误。拼写校正旨在将错误拼写的单词纠正为正确的形式,以提高文本分析的准确性。
1. 如何进行拼写校正
有多种方法可以实现拼写校正:
(1) 基于词典的拼写校正
这种方法依赖于预定义的词典(dictionary)。当遇到一个不在词典中的单词时,算法会尝试找到与之最接近的词典中的单词。
- Python实现(使用
TextBlob库):
from textblob import TextBlob
# 示例文本
text = "I havv a speling mistake in this sentnce."
# 使用 TextBlob 进行拼写校正
corrected_text = str(TextBlob(text).correct())
print(corrected_text)
输出:
I have a spelling mistake in this sentence.
(2) 基于编辑距离的拼写校正
编辑距离(Edit Distance)或Levenshtein距离是计算两个字符串之间最小编辑操作数(插入、删除、替换)的度量。拼写校正可以通过寻找与错误单词编辑距离最小的词典词来实现。
- Python实现(使用
pyspellchecker库):
from spellchecker import SpellChecker
spell = SpellChecker()
# 示例单词列表
words = ["speling", "mistke", "hapy", "recieve"]
# 校正拼写错误
corrected_words = [spell.correction(word) for word in words]
print(corrected_words)
输出:
['spelling', 'mistake', 'happy', 'receive']
(3) 基于上下文的拼写校正
这种方法利用语言模型(如BERT、GPT等)来考虑上下文,提供更加智能的拼写校正。上下文拼写校正不仅仅关注单词的拼写,还会考虑句子中的其他单词来预测正确的单词。
- Python实现(使用
transformers库):
from transformers import pipeline
# 使用Hugging Face的预训练模型进行拼写校正
corrector = pipeline('fill-mask', model='bert-base-uncased')
# 示例句子
text = "I havv a speling mistake in this sentnce."
# 使用上下文进行拼写校正(假设使用mask填充法)
corrected_text = corrector("I havv a speling mistake in this [MASK].")
print(corrected_text)
2. 什么时候需要进行拼写校正
- 用户生成内容:如社交媒体、论坛帖子、评论等,这类文本常包含拼写错误,校正这些错误有助于提升模型的理解和分析能力。
- 信息检索:搜索引擎或信息检索系统中,拼写错误可能导致不精确的搜索结果,进行拼写校正有助于改善用户体验。
- 文本分类和情感分析:在这些任务中,拼写错误可能影响特征提取的准确性,拼写校正能减少这种负面影响。
3. 什么时候不需要进行拼写校正
- 拼写错误传达特殊意义:有时候,拼写错误可能是有意的,如在某些社交媒体或网络文化中,错拼的单词可能传达特定的情感或幽默。此时,校正可能会改变文本的原意。
- 正式文本:在正式文档、新闻文章、书籍等高质量文本中,拼写错误较少,校正的必要性不大。
- 领域专有名词:在特定领域(如医学、技术、品牌名称)中,某些词汇虽然不在普通词典中,但校正可能会将这些正确的专有名词错误地更正为其他常见词汇。
4. 拼写校正中的问题和不足
- 过度校正:有时算法可能会将原本正确的单词错误地校正为另一个单词,尤其是在处理领域专有词汇或俚语时。
- 上下文依赖:简单的拼写校正方法不考虑上下文,可能会在上下文敏感的情况下做出错误的校正。
- 计算复杂度:基于编辑距离和上下文的校正方法计算复杂度较高,处理大量文本时可能会很慢。
- 词典局限性:基于词典的方法依赖于词典的完备性,如果词典中缺少某些词汇(如新词或技术术语),则可能无法正确校正。
5. 总结
拼写校正是文本规范化中的一个重要步骤,在处理非正式文本时特别有用。然而,拼写校正也有其局限性,需要根据具体的应用场景决定是否使用,并选择合适的方法。如果处理的文本包含大量专有名词、俚语或有意的拼写错误,可能需要谨慎使用拼写校正,或者结合上下文模型来进行更智能的处理。
电影评论的情感分析是否需要做拼写校正?
因为范例代码中将拼写校正的代码给注释了,说明不做拼写校正也是可以的,我有点疑惑,想要搞明白为什么。从下面的分析来看,这个项目确实可以不做。以后有时间的话,可以测试一下做与不做拼写校正的效果对比,我估计对最终结果影响不大,所以可以不做,至少在这个数据集上是这样。
电影评论的情感分析是否需要进行拼写校正,这取决于多个因素,包括数据的质量、任务的需求以及模型的类型。以下是详细分析。
1. 什么时候需要做拼写校正
-
用户生成内容的质量较差:如果电影评论是从社交媒体、论坛或其他用户生成内容中收集的,这类数据往往会包含拼写错误。拼写错误可能会影响情感分析的准确性,因为模型可能无法识别错误拼写的词汇。如果你的情感分析模型依赖于词袋模型(Bag of Words)、TF-IDF或者简单的词嵌入模型(如Word2Vec),那么拼写错误会导致词汇表膨胀,降低模型的性能。
-
目标是提高模型的准确性:在一些情况下,拼写校正可以提高情感分析的准确性。例如,如果评论中存在大量拼写错误,且这些错误影响了关键情感词汇的识别,那么拼写校正可以帮助模型更好地理解评论内容,从而做出更准确的情感预测。
2. 什么时候不需要做拼写校正
-
拼写错误传达了特殊的情感或语气:在非正式的文本中,用户有时会故意拼错单词以表达特定的情感或语气(如“goooood”表示非常好)。此时,拼写校正可能会误解用户的意图,削弱情感分析的效果。
-
数据质量较高:如果评论数据已经过筛选,且拼写错误很少,那么进行拼写校正的必要性不大,反而可能会增加不必要的计算复杂度。
-
使用上下文感知的模型:如果你使用的是基于上下文的深度学习模型(如BERT、GPT等),这些模型在一定程度上能够理解拼写错误的单词在上下文中的含义。因此,拼写错误对这些模型的影响较小,拼写校正可能不再是必需的步骤。
3. 拼写校正可能带来的问题
-
过度校正:拼写校正工具可能会将某些原本正确但不常见的单词或俚语误认为是拼写错误,从而错误地修改它们,导致情感分析的结果偏差。
-
计算开销:拼写校正尤其是基于上下文的拼写校正(如使用语言模型)可能增加额外的计算成本,尤其是在处理大量数据时。
4. 权衡与建议
-
数据分析:首先,进行一些初步的数据分析,看看电影评论中拼写错误的普遍程度。如果拼写错误很常见且可能影响关键情感词汇的识别,那么进行拼写校正可能是有益的。
-
模型测试:可以在预处理中引入拼写校正步骤,训练模型后与未做拼写校正的版本进行对比。通过比较两者的性能(如准确性、F1得分),来确定拼写校正是否有助于提高情感分析的效果。
-
结合上下文:如果有资源,可以尝试使用结合上下文的拼写校正方法,或者直接使用上下文感知的模型来处理拼写错误,从而在保证精度的同时避免误校正。
总结
在电影评论的情感分析中,是否需要做拼写校正应根据数据的具体情况和分析任务的需求来决定。如果评论中存在大量影响情感分析的拼写错误,拼写校正可以提高模型的准确性。但要注意拼写校正可能带来的误校正风险,并结合上下文和模型类型做出权衡。如果数据质量较高或使用的是上下文感知模型,则拼写校正的必要性会降低。
特征提取 Feature Extraction
1.词袋模型、 TF-IDF和词嵌入 是文本分类任务中的特征提取部分,它们负责将文本数据转换为可用于模型训练的数值特征。这是文本分类项目中非常关键的一步,因为特征的质量直接影响到最终模型的性能。
2.该项目只使用了词袋模型和TF-IDF模型。
词袋模型(Bag of Words, 简称BoW)
词袋模型(Bag of Words, 简称BoW)是一种常见且简单的文本表示方法,用于自然语言处理(NLP)和文本分类任务。它将文本转换为固定长度的向量,以便于机器学习模型处理。以下是词袋模型的详细解释。
1. 词袋模型的基本概念
在词袋模型中,每个文本被表示为一个词频向量(Term Frequency Vector)。这个向量的每个元素表示在该文本中出现的某个词的频率。关键点在于,词袋模型不考虑词语的顺序或语法结构,而只关注词汇的出现频率。
举例说明
假设有以下三个句子:
- “I love machine learning”
- “Machine learning is great”
- “I love programming”
首先,构建一个包含所有句子中出现的唯一单词的词汇表(不区分大小写):
['i', 'love', 'machine', 'learning', 'is', 'great', 'programming']
然后,对于每个句子,构建一个对应的词频向量:
- 对于句子 “I love machine learning”,词频向量为
[1, 1, 1, 1, 0, 0, 0] - 对于句子 “Machine learning is great”,词频向量为
[0, 0, 1, 1, 1, 1, 0] - 对于句子 “I love programming”,词频向量为
[1, 1, 0, 0, 0, 0, 1]
每个向量的长度等于词汇表的大小,向量中每个位置对应词汇表中的一个词,该位置的数值表示这个词在该句子中出现的次数。
2. 词袋模型的优点
- 简单易用:词袋模型直观且容易实现,是处理文本数据的基本方法。
- 有效性:对于许多简单的文本分类任务,如垃圾邮件分类、情感分析等,词袋模型往往表现得很好。
- 模型兼容性:词袋模型生成的词频向量可以直接用于传统的机器学习算法(如朴素贝叶斯、支持向量机等),并且易于扩展为TF-IDF模型。
3. 词袋模型的缺点
- 忽略词序:词袋模型完全忽略了单词的顺序,这意味着 “I love machine learning” 和 “Machine learning love I” 会被表示为相同的向量,尽管语义上不同。
- 数据稀疏性:对于大型词汇表来说,大多数文本的词频向量会非常稀疏(大部分元素为零),这会影响计算效率和内存消耗。
- 语义信息缺失:词袋模型仅考虑词频,无法捕捉单词之间的上下文关系和语义信息。例如,“good” 和 “not good” 在词袋模型中可能非常接近,但实际含义完全相反。
4. 改进和扩展
为了弥补词袋模型的缺陷,有一些常见的改进和扩展方法:
-
TF-IDF(Term Frequency-Inverse Document Frequency):在词频的基础上,引入逆文档频率(IDF)来降低常见词对模型的影响,从而提高模型对稀有但重要词汇的敏感度。
-
N-grams:词袋模型只考虑单个词的频率,而N-grams模型会考虑词语的组合(如双词组、三词组等),以捕捉局部的语序信息。
-
词嵌入(Word Embeddings):如Word2Vec、GloVe等模型可以将单词映射到低维连续向量空间,捕捉单词之间的语义关系,替代词袋模型中离散的词频向量。
5. 实际应用
词袋模型广泛应用于各种文本分类任务,如:
- 垃圾邮件分类:将电子邮件内容表示为词袋模型,使用分类器判断邮件是否为垃圾邮件。
- 情感分析:分析电影评论、社交媒体内容等的情感倾向,判断文本是正面、负面还是中性。
- 文档分类:将新闻文章或学术论文分类为不同主题,如体育、政治、科技等。
6. 总结
词袋模型是一种简单有效的文本表示方法,尤其适用于初步的文本分析任务。尽管它有一些缺点,如忽略词序和语义信息,但在很多情况下,配合合适的模型和特征工程手段,词袋模型依然可以提供令人满意的结果。对于更复杂的NLP任务,词袋模型可以作为基础,再结合更高级的模型进行改进和优化。
词袋模型-本项目代码
从输出结果来看,只有1万条评论的测试样本,就生成了
#Count vectorizer for bag of words
cv=CountVectorizer(min_df=0,max_df=1,binary=False,ngram_range=(1,3))
#transformed train reviews
cv_train_reviews=cv.fit_transform(norm_train_reviews)
#transformed test reviews
cv_test_reviews=cv.transform(norm_test_reviews)
print('BOW_cv_train:',cv_train_reviews.shape)
print('BOW_cv_test:',cv_test_reviews.shape)
这段代码使用了 CountVectorizer 来实现词袋模型(Bag of Words, BOW),将文本数据转换为特征向量。这种方法在自然语言处理(NLP)任务中常用于将文本转换为机器学习模型可以理解的格式。下面是对代码的详细解析:
1. 导入和初始化 CountVectorizer
cv = CountVectorizer(min_df=0, max_df=1, binary=False, ngram_range=(1,3))
-
CountVectorizer:CountVectorizer是scikit-learn中的一个工具,用于将文本转换为词频矩阵。每行表示一个文档,每列表示一个词或 n-gram,矩阵中的值表示词或 n-gram 在该文档中出现的频率。 -
参数解释:
min_df=0:忽略频率低于min_df的词语。在此设置为0,意味着不忽略任何词语。max_df=1:忽略频率高于max_df的词语。设置为1,意味着不忽略任何词语(即使在所有文档中都出现的词语也会被保留)。binary=False:如果为True,则将每个词语的计数转换为二进制值(即词语是否存在,而不是出现次数)。在此设置为False,表示保留词频。ngram_range=(1,3):生成 1-gram, 2-gram 和 3-gram 的词组特征。例如,对于句子 “I love NLP”,1-gram 是 “I”、“love”、“NLP”;2-gram 是 “I love”、“love NLP”;3-gram 是 “I love NLP”。
2. 拟合并转换训练数据
cv_train_reviews = cv.fit_transform(norm_train_reviews)
-
fit_transform:对norm_train_reviews(归一化的训练文本数据)进行拟合并转换,生成词频矩阵。此操作会构建词汇表,并将训练数据转换为特征向量。 -
cv_train_reviews:这是转换后的训练数据,表示为一个稀疏矩阵,每行表示一个文档,每列表示一个词或 n-gram,矩阵中的值表示词语在该文档中出现的频率。
3. 转换测试数据
cv_test_reviews = cv.transform(norm_test_reviews)
-
transform:使用在训练数据中拟合好的词汇表,将norm_test_reviews(归一化的测试文本数据)转换为词频矩阵。此操作不会重新拟合模型,而是直接使用训练时构建的词汇表。 -
cv_test_reviews:这是转换后的测试数据,形式同样是一个稀疏矩阵。
4. 输出维度信息
print('BOW_cv_train:', cv_train_reviews.shape)
print('BOW_cv_test:', cv_test_reviews.shape)
- 这里打印了训练集和测试集的词袋模型(BOW)的维度信息。
cv_train_reviews.shape表示训练集的词频矩阵的形状,输出(文档数量, 词汇表大小)。cv_test_reviews.shape表示测试集的词频矩阵的形状,输出(文档数量, 词汇表大小)。
总结
这段代码的目的是使用 CountVectorizer 对归一化后的训练和测试文本数据进行词袋模型转换,将文本转换为可以用于机器学习模型的特征向量。通过这一步,文本数据被表示为稀疏矩阵,其中每个元素表示词语在文本中的频率。
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘的统计方法,用来评估一个词语在文档集合中的重要性。它的核心思想是:一个词语在文档中出现得越频繁,它对文档的重要性越高;但如果一个词语在整个文档集合中都频繁出现,那么它的区分能力就越差。
在Python中,sklearn 提供了 TfidfVectorizer 类来方便地实现 TF-IDF 模型。下面是一个使用 TfidfVectorizer 的示例代码,以及对每个步骤的解释:
示例代码
from sklearn.feature_extraction.text import TfidfVectorizer
# 初始化 TF-IDF 向量化器
tfidf = TfidfVectorizer(min_df=0, max_df=1, ngram_range=(1,3))
# 转换训练数据
tfidf_train_reviews = tfidf.fit_transform(norm_train_reviews)
# 转换测试数据
tfidf_test_reviews = tfidf.transform(norm_test_reviews)
# 输出维度信息
print('TFIDF_train:', tfidf_train_reviews.shape)
print('TFIDF_test:', tfidf_test_reviews.shape)
# 获取特征名称
vocab = tfidf.get_feature_names_out()
代码解析
1. 导入 TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer是sklearn中的一个工具,用于将一组文档转换为 TF-IDF 特征矩阵。
2. 初始化 TF-IDF 向量化器
tfidf = TfidfVectorizer(min_df=0, max_df=1, ngram_range=(1,3))
- 参数解释:
min_df=0:忽略在低于min_df个文档中出现的词语。这里设置为0,表示不忽略任何词语。max_df=1:忽略在高于max_df个文档中出现的词语。这里设置为1,表示不忽略任何词语。ngram_range=(1,3):生成 1-gram, 2-gram 和 3-gram 的词组特征。
3. 拟合并转换训练数据
tfidf_train_reviews = tfidf.fit_transform(norm_train_reviews)
-
fit_transform:对norm_train_reviews(归一化的训练文本数据)进行拟合并转换,生成 TF-IDF 特征矩阵。这个操作会构建词汇表,并计算每个文档中每个词的 TF-IDF 值。 -
tfidf_train_reviews:这是转换后的训练数据,表示为一个稀疏矩阵,每行表示一个文档,每列表示一个词或 n-gram,矩阵中的值表示该词在该文档中的 TF-IDF 值。
4. 转换测试数据
tfidf_test_reviews = tfidf.transform(norm_test_reviews)
-
transform:使用在训练数据中拟合好的词汇表,将norm_test_reviews(归一化的测试文本数据)转换为 TF-IDF 特征矩阵。此操作不会重新拟合模型,而是直接使用训练时构建的词汇表和 IDF 值。 -
tfidf_test_reviews:这是转换后的测试数据,同样以稀疏矩阵形式表示。
5. 输出维度信息
print('TFIDF_train:', tfidf_train_reviews.shape)
print('TFIDF_test:', tfidf_test_reviews.shape)
- 这里打印了训练集和测试集的 TF-IDF 特征矩阵的维度信息。
tfidf_train_reviews.shape表示训练集的 TF-IDF 特征矩阵的形状,输出(文档数量, 词汇表大小)。tfidf_test_reviews.shape表示测试集的 TF-IDF 特征矩阵的形状,输出(文档数量, 词汇表大小)。
6. 获取特征名称
vocab = tfidf.get_feature_names_out()
get_feature_names_out():这个方法用于获取词汇表中的所有特征名称,即词或 n-gram。返回的是一个包含所有特征名称的数组。
总结
TF-IDF 模型通过综合考虑词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF),为每个词语在文档中的重要性赋予一个权重。使用 TfidfVectorizer 可以方便地将文本数据转换为 TF-IDF 特征矩阵,使得文本数据能够作为输入传递给机器学习模型进行训练和预测。
在实际应用中,TF-IDF 常用于文本分类、信息检索、推荐系统等领域。相比于简单的词袋模型,TF-IDF 通过降低那些在所有文档中都频繁出现的常见词的权重,能够更好地突出在特定文档中具有区分度的词语。
词汇表如何生成以及大小由什么决定
词袋模型和TF-IDF是如何生成词汇表的,词汇表的大小由什么决定,一般有多大。
词袋模型(Bag of Words, BOW)和 TF-IDF 模型在生成词汇表时有一些相似之处,但也存在一定的差异。以下是它们各自如何生成词汇表的过程,以及词汇表大小的决定因素。
1. 词袋模型(Bag of Words, BOW)如何生成词汇表
词汇表生成过程:
- 收集词汇:在词袋模型中,首先遍历所有文档,收集其中出现的所有单词或 n-gram(根据
ngram_range参数)。 - 词汇表构建:将所有出现过的单词或 n-gram 组成一个词汇表(Vocabulary)。每个词汇在词汇表中占据一个位置(即一列),并用于表示该词在文档中的出现频次。
- 过滤:在构建词汇表时,可以使用
min_df和max_df参数过滤掉一些词汇。min_df表示词汇必须在至少min_df个文档中出现,才会被包含在词汇表中。max_df则表示如果一个词汇在超过max_df个文档中出现,它会被忽略(因为这类词通常为无意义的常见词)。
词汇表大小的决定因素:
- 文档总数:文档越多,词汇表中可能的词汇数量越大。
- 文档内容的多样性:文档内容越多样化,出现的不同词汇就越多,词汇表也就越大。
ngram_range参数:ngram_range=(1,3)会产生 1-gram、2-gram 和 3-gram 的词汇,可能会显著增加词汇表的大小。min_df和max_df参数:通过设置这些参数,可以控制词汇表中保留的词汇数量。过滤掉低频词或高频词可以减小词汇表的大小。
2. TF-IDF 模型如何生成词汇表
词汇表生成过程:
- 与词袋模型类似:TF-IDF 模型在生成词汇表时的步骤与词袋模型几乎相同,首先通过遍历文档来收集所有单词或 n-gram。
- 构建词汇表:所有出现过的词汇会被加入词汇表,之后对每个词汇计算 TF-IDF 值,即该词汇在某个文档中的重要性分数。
- 过滤:同样可以通过
min_df和max_df参数来过滤掉不需要的词汇。
词汇表大小的决定因素:
- 与词袋模型类似:文档总数、文档内容的多样性、
ngram_range参数、min_df和max_df参数都会影响 TF-IDF 词汇表的大小。
3. 词汇表的典型大小
-
中小型语料库:对于数百到数千篇文档的语料库,词汇表的大小通常在几千到几万个词汇之间。例如,对于一个包含 1000 篇文档的新闻数据集,词汇表的大小可能在 5,000 到 20,000 之间。
-
大型语料库:如果处理的是包含数十万篇文档的语料库,词汇表的大小可能会达到数十万甚至上百万的词汇。
-
调整策略:
- 降维:如果词汇表过大,可以通过设置
max_features参数来限制最大特征数量。 - 过滤:设置
min_df和max_df来过滤掉低频或高频的无用词汇,从而减小词汇表的大小。 - 停用词:移除停用词(如 “the”, “is”, “and” 等)可以显著减小词汇表大小,并提高模型效果。
- 降维:如果词汇表过大,可以通过设置
4. 总结
词袋模型和 TF-IDF 模型都通过遍历文档来构建词汇表,词汇表的大小主要由文档的数量、内容的多样性、n-gram 范围以及过滤参数(如 min_df 和 max_df)决定。词汇表的大小直接影响模型的维度和复杂性,因此在实际应用中需要根据任务的具体需求进行调整和优化。
是否需要缩减词汇表的大小?
输出结果:
BOW_cv_train: (40000, 6209089)
BOW_cv_test: (10000, 6209089)
Tfidf_train: (40000, 6209089)
Tfidf_test: (10000, 6209089)
我的初步想法:从该项目的输出结果来看,两个模型的词汇表的大小都高达620万,相当于大型语料库的词汇量了。还好训练资料只有4万笔,不是很大,所以计算量不大,训练起来还是比较快,如果训练资料很大的话,可能需要考虑设置
min_df和max_df来过滤掉低频或高频的无用词汇,从而减小词汇表的大小。
后续更新想法:在下面的代码版本6中,通过Tfidf的参数优化,即设置 min_df 和 max_df 的值,把词汇表的大小从620万缩减到了30万。不仅加快了模型训练速度,也极大的改善了模型预测结果。详见段落:优化TFIDF的参数大幅提升了准确率,所以缩减词汇表的大小是必要的。
输出结果:
Tfidf_train: (40000, 297387)
Tfidf_test: (10000, 297387)
标签二值化处理(Label Binarization)
标签二值化处理(Label Binarization)是将多类别标签转换为二进制格式的过程,通常用于分类任务,尤其是在多标签分类或多类分类任务中。二值化处理可以使标签适应某些机器学习算法或损失函数,如逻辑回归、支持向量机等。常见的方法包括One-vs-Rest策略和使用LabelBinarizer或OneHotEncoder工具。
1. 二值化处理的应用场景
-
二分类问题:当你的数据有两个类别(如正面、负面)时,可以直接将其标签二值化,例如将“正面”映射为1,将“负面”映射为0。
-
多标签分类:当每个样本可以属于多个类别时,二值化处理将每个类别的标签独立处理,形成一个多维的二进制向量,每一维对应一个类别。
-
多类分类:对于多类问题(如三个以上的类别),二值化处理可以将每个类别表示为一个独立的二进制向量(通常称为One-Hot Encoding)。
2. 二值化处理示例
(1) 使用LabelBinarizer进行二值化
LabelBinarizer 是 sklearn 库中的工具,用于将多类别标签转换为二值标签。
from sklearn.preprocessing import LabelBinarizer
# 示例标签
labels = ['positive', 'negative', 'neutral']
# 初始化LabelBinarizer
lb = LabelBinarizer()
# 进行二值化处理
binary_labels = lb.fit_transform(labels)
print(binary_labels)
输出:
[[0 0 1]
[1 0 0]
[0 1 0]]
在这个例子中,LabelBinarizer 将标签 “positive”、“negative”、“neutral” 分别转换为 [0, 0, 1]、[1, 0, 0]、[0, 1, 0]。
(2) 使用OneHotEncoder进行One-Hot编码
OneHotEncoder 是另一种常用的二值化工具,它将类别变量转换为稀疏矩阵(适用于大数据集)。
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# 示例标签
labels = np.array(['positive', 'negative', 'neutral']).reshape(-1, 1)
# 初始化OneHotEncoder
onehot = OneHotEncoder(sparse=False)
# 进行One-Hot编码
onehot_labels = onehot.fit_transform(labels)
print(onehot_labels)
输出:
[[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]]
(3) 简单的二分类问题
如果只是一个简单的二分类问题,可以使用如下方法将标签转换为二值:
# 示例标签
labels = ['positive', 'negative', 'positive']
# 二值化处理
binary_labels = [1 if label == 'positive' else 0 for label in labels]
print(binary_labels)
输出:
[1, 0, 1]
3. 注意事项
-
类别顺序:在进行二值化处理时,尤其是使用
LabelBinarizer或OneHotEncoder时,默认类别的顺序由字母序或数值大小决定。如果需要特定的顺序,可能需要先对类别进行排序。 -
多标签分类:在多标签分类问题中,每个标签都是独立的,因此通常需要用
MultiLabelBinarizer来处理。 -
稀疏矩阵处理:
OneHotEncoder的输出通常是稀疏矩阵,尤其在类别很多的情况下。如果你的模型不能处理稀疏矩阵,可以设置sparse=False来获取密集矩阵。
4. 总结
标签二值化处理是文本分类、情感分析等任务中非常重要的一步。通过将标签转换为二进制格式,可以更好地适应机器学习模型的输入要求。根据任务的不同,可能需要使用 LabelBinarizer、OneHotEncoder 或者简单的列表推导式进行二值化处理。在实际应用中,选择合适的二值化方法可以有效提升模型的表现。
多个模型的训练、评估、结果分析和报告
逻辑回归模型(Logistic Regression)
逻辑回归模型(Logistic Regression)是一种经典的统计模型,常用于二分类问题。尽管名字中带有“回归”,但逻辑回归主要用于分类任务,而不是预测连续值。它的核心思想是利用线性回归的思想,通过逻辑函数(Sigmoid函数)将预测结果映射到0和1之间的概率值,并根据概率进行分类。
1. 逻辑回归的基本概念
(1) Sigmoid函数
逻辑回归模型使用的核心函数是Sigmoid函数,它将线性回归的输出转换为概率值。Sigmoid函数的数学表达式为:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
其中, z = w T x + b z = w^T x + b z=wTx+b, w w w 是权重向量, x x x 是输入特征向量, b b b 是偏置项。
Sigmoid函数的输出范围是0到1之间,可以解释为某一类的概率。
(2) 概率与分类
- 如果 σ ( z ) ≥ 0.5 \sigma(z) \geq 0.5 σ(z)≥0.5,则预测结果为1(即正类)。
- 如果 σ ( z ) < 0.5 \sigma(z) < 0.5 σ(z)<0.5,则预测结果为0(即负类)。
通过调整阈值(默认0.5),可以适应不同的分类需求。
2. 逻辑回归的损失函数
逻辑回归的目标是最大化模型预测结果与实际结果之间的匹配程度。为了实现这一点,通常使用二元交叉熵(Binary Cross-Entropy)作为损失函数,其形式为:
L ( w , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( y ^ ( i ) ) + ( 1 − y ( i ) ) log ( 1 − y ^ ( i ) ) ] L(w, b) = -\frac{1}{m} \sum_{i=1}^{m} [y^{(i)} \log(\hat{y}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)})] L(w,b)=−m1i=1∑m[y(i)log(y^(i))+(1−y(i))log(1−y^(i))]
其中, y ( i ) y^{(i)} y(i) 是第 i i i 个样本的实际标签, y ^ ( i ) \hat{y}^{(i)} y^(i) 是模型预测的概率, m m m 是样本总数。
通过最小化这个损失函数,可以找到最优的权重 w w w 和偏置 b b b。
3. 逻辑回归模型的训练
逻辑回归模型的训练通常通过梯度下降法来实现,通过反复调整模型参数(权重和偏置),以最小化损失函数。常见的优化方法包括:
- 梯度下降(Gradient Descent)
- 随机梯度下降(Stochastic Gradient Descent, SGD)
- 批量梯度下降(Mini-Batch Gradient Descent)
4. 逻辑回归的优点
- 简单易用:逻辑回归模型容易理解和实现,计算成本较低。
- 解释性强:权重系数 w w w 的大小和符号可以解释每个特征对分类结果的影响。
- 适合高维数据:在处理稀疏、高维的数据时,逻辑回归表现良好,尤其在文本分类任务中。
5. 逻辑回归的缺点
- 线性可分性:逻辑回归假设特征与目标之间存在线性关系,对线性不可分的数据表现较差。
- 容易过拟合:当特征数量远大于样本数量时,逻辑回归容易过拟合,需要使用正则化技术来缓解。
- 对异常值敏感:逻辑回归对异常值敏感,可能会被极端值影响模型性能。
6. Python实现逻辑回归
以下是使用sklearn库实现逻辑回归模型的示例:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 假设 X 是特征矩阵,y 是标签向量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
print(f"Classification Report:\n{report}")
7. 正则化
为了防止过拟合,逻辑回归常常加入正则化项,最常见的有L1正则化(Lasso)和L2正则化(Ridge)。
- L1正则化:鼓励稀疏性,使得一些特征的权重为零,从而起到特征选择的作用。
- L2正则化:鼓励权重的平方和较小,从而平滑模型,防止过拟合。
在sklearn中,可以通过设置penalty参数来选择正则化类型:
# L1正则化
model = LogisticRegression(penalty='l1', solver='liblinear')
# L2正则化(默认)
model = LogisticRegression(penalty='l2')
8. 多类分类
逻辑回归模型也可以扩展到多类分类问题(即类别数大于2),通过One-vs-Rest(OvR)或One-vs-One(OvO)的方式实现。sklearn中的逻辑回归模型默认使用OvR策略。
# 使用多类分类
model = LogisticRegression(multi_class='ovr')
总结
逻辑回归模型是一种简单而有效的分类模型,适用于二分类问题,尤其在处理高维稀疏数据(如文本分类)时表现良好。通过正则化技术,可以进一步提高模型的泛化能力。在实际应用中,逻辑回归常常作为基线模型,用于与其他更复杂的模型进行比较。
逻辑回归模型训练-本项目代码
#training the model
lr=LogisticRegression(penalty='l2',max_iter=500,C=1,random_state=42)
#Fitting the model for Bag of words
lr_bow=lr.fit(cv_train_reviews,train_sentiments)
print(lr_bow)
#Fitting the model for tfidf features
lr_tfidf=lr.fit(tv_train_reviews,train_sentiments)
print(lr_tfidf)
这段代码展示了如何使用逻辑回归(Logistic Regression)模型来进行文本分类任务。具体来说,代码展示了对词袋模型(Bag of Words)和 TF-IDF 特征分别进行模型训练的过程。下面是对代码的详细解析:
1. 初始化逻辑回归模型
lr = LogisticRegression(penalty='l2', max_iter=500, C=1, random_state=42)
LogisticRegression:这是scikit-learn中的逻辑回归模型,用于分类任务。- 参数解释:
penalty='l2':指定使用 L2 正则化,以防止过拟合。L2 正则化通过对模型参数的平方和加以约束,使得模型更简单、更通用。max_iter=500:最大迭代次数设为 500,允许更多的迭代次数来确保模型收敛。C=1:正则化强度的倒数,C值越小,正则化越强。这里C=1表示标准的正则化强度。random_state=42:设置随机种子,以确保结果的可重复性。
2. 使用词袋模型(Bag of Words)特征训练模型
lr_bow = lr.fit(cv_train_reviews, train_sentiments)
print(lr_bow)
-
lr.fit(cv_train_reviews, train_sentiments):使用词袋模型生成的特征矩阵cv_train_reviews和对应的情感标签train_sentiments进行模型训练。cv_train_reviews:这是由CountVectorizer转换后的训练数据特征矩阵(词袋模型)。train_sentiments:这是训练数据中的情感标签(通常是 0 或 1,表示负面或正面情感)。
-
lr_bow:存储了使用词袋模型特征训练好的逻辑回归模型。 -
print(lr_bow):打印训练好的模型对象。通常会输出模型的参数信息。
3. 使用 TF-IDF 特征训练模型
lr_tfidf = lr.fit(tv_train_reviews, train_sentiments)
print(lr_tfidf)
-
lr.fit(tv_train_reviews, train_sentiments):使用 TF-IDF 模型生成的特征矩阵tv_train_reviews和对应的情感标签train_sentiments进行模型训练。tv_train_reviews:这是由TfidfVectorizer转换后的训练数据特征矩阵(TF-IDF 模型)。train_sentiments:同样是训练数据中的情感标签。
-
lr_tfidf:存储了使用 TF-IDF 特征训练好的逻辑回归模型。 -
print(lr_tfidf):打印训练好的模型对象。通常会输出模型的参数信息。
4. 总结
这段代码的核心工作是对文本分类任务中的两种不同特征(词袋模型和 TF-IDF 模型)分别训练逻辑回归分类器。通过 fit 方法,模型学习到如何根据输入的特征矩阵预测情感标签。
- 词袋模型(Bag of Words):将文本转换为词频矩阵,然后使用这些特征训练模型。
- TF-IDF 模型:将文本转换为 TF-IDF 特征矩阵,然后使用这些特征训练模型。
训练好的模型对象 lr_bow 和 lr_tfidf 可以用于对新数据的情感分类预测。通常,接下来会使用测试集来评估这两个模型的性能,比较它们在分类任务中的准确性、精确率、召回率等指标。
逻辑回归模型的初始化参数配置解析
LogisticRegression(C=1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=500,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=42, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
这段代码展示了 LogisticRegression 类的初始化参数配置。LogisticRegression 是一种常用的线性分类模型,广泛应用于二分类和多分类问题中。以下是每个参数的详细解释及其影响:
-
C=1
- 解释:正则化强度的倒数。正则化是用来防止模型过拟合的,
C值越小,正则化越强。C=1表示标准的正则化强度。 - 影响:较小的
C值会增加正则化,防止过拟合;较大的C值则允许模型更好地拟合训练数据,但可能导致过拟合。
- 解释:正则化强度的倒数。正则化是用来防止模型过拟合的,
-
class_weight=None
- 解释:用于设置各类别的权重。如果设置为
None,表示不调整权重;如果设置为'balanced',会根据类别频率自动调整权重,以处理类别不平衡问题。 - 影响:在类别不平衡的数据集中,调整权重可以使模型更加关注少数类别,提升少数类的识别能力。
- 解释:用于设置各类别的权重。如果设置为
-
dual=False
- 解释:是否使用对偶形式(dual form)来优化问题。对偶形式通常用于特征数多于样本数的情况。
- 影响:对于特征数多于样本数的情况,
dual=True可能更有效;而样本数多于特征数时,dual=False更适合。
-
fit_intercept=True
- 解释:是否为模型计算截距(intercept)。如果设置为
False,模型将不计算截距,假设数据已经中心化。 - 影响:大多数情况下,
True是合理的选择,因为它允许模型拟合数据的偏移。
- 解释:是否为模型计算截距(intercept)。如果设置为
-
intercept_scaling=1
- 解释:仅在
solver设置为'liblinear'且fit_intercept=True时有用。该参数用于缩放截距项。 - 影响:通常不需要调整这个参数,除非在处理特殊数据时需要特定的缩放。
- 解释:仅在
-
l1_ratio=None
- 解释:在
penalty设置为'elasticnet'时,此参数控制 L1 正则化的比重。它只在solver='saga'时有效。 - 影响:通过调整
l1_ratio可以在 L1 和 L2 正则化之间找到一个平衡点。
- 解释:在
-
max_iter=500
- 解释:最大迭代次数。如果在给定的迭代次数内算法未收敛,算法会停止并发出警告。
- 影响:增加
max_iter可以确保模型在复杂数据集上有足够的时间收敛。
-
multi_class='warn’
- 解释:指定多分类策略。在较新的版本中,
multi_class参数的默认值为'auto',它会根据solver自动选择'ovr'(One-vs-Rest)或'multinomial'。 - 影响:选择
'ovr'时,模型会为每个类别训练一个二分类器;选择'multinomial'时,模型同时考虑所有类别之间的关系。
- 解释:指定多分类策略。在较新的版本中,
-
n_jobs=None
- 解释:指定并行计算时使用的 CPU 核心数。
None表示使用单个核心,-1表示使用所有可用核心。 - 影响:并行化计算可以加速训练过程,特别是在处理大数据集时。
- 解释:指定并行计算时使用的 CPU 核心数。
-
penalty='l2’
- 解释:指定正则化类型。
'l2'正则化是最常用的类型,用来防止模型过拟合。 - 影响:L2 正则化通过惩罚较大的权重参数,促使模型更简单、更具泛化能力。
- 解释:指定正则化类型。
-
random_state=42
- 解释:设置随机数生成器的种子,以确保结果的可重复性。任何整数值都可以作为随机种子。
- 影响:固定随机种子可以确保每次运行时结果一致,方便调试和模型验证。
-
solver='warn’
- 解释:指定用于优化问题的算法。
solver决定了如何寻找最优解,例如'liblinear','lbfgs','newton-cg','sag','saga'等。'warn'是旧版本中的警告提示,在较新版本中应该使用'lbfgs'或其他更合适的选项。 - 影响:不同的
solver对处理大规模数据集、多分类问题和不同的正则化方法有不同的效果。
- 解释:指定用于优化问题的算法。
-
tol=0.0001
- 解释:判断模型是否收敛的容忍度。当损失函数的改进小于
tol时,模型认为已收敛并停止迭代。 - 影响:较小的
tol值可以让模型更精确地收敛,但也可能增加计算时间。
- 解释:判断模型是否收敛的容忍度。当损失函数的改进小于
-
verbose=0
- 解释:控制训练过程中的输出信息量。
0表示不输出,1表示输出较少信息,2表示输出详细信息。 - 影响:在调试过程中,增加
verbose的值可以帮助跟踪训练过程和模型的优化状态。
- 解释:控制训练过程中的输出信息量。
-
warm_start=False
- 解释:是否在每次调用
fit方法时重用上一次训练的结果。如果设置为True,模型会在上一次训练的基础上继续训练,而不是从头开始。 - 影响:
warm_start适用于在多个阶段逐步训练模型的情况,尤其是在增量学习的场景中。
- 解释:是否在每次调用
总结:这些参数的配置决定了 LogisticRegression 模型的训练方式和性能表现。通过调整这些参数,可以更好地适应不同的数据集和任务需求,优化模型的表现。
模型评估:准确率
准确率结果:
lr_bow_score : 0.7512
lr_tfidf_score : 0.75
通过查看这两个准确性得分,你可以判断哪种特征提取方法(词袋模型或 TF-IDF)在你的分类任务中效果更好。通常,TF-IDF 在处理高频词和低频词时有更好的表现,但这也取决于具体的数据集和任务。
在该数据集和任务上准确率好像没有什么差别。
在模型评估中,准确率(Accuracy)是一个非常常用的指标,特别是在二分类或多分类问题中。准确率衡量的是模型预测正确的样本数量占总样本数量的比例。它的计算公式为:
准确率 = 正确预测的样本数 总样本数 \text{准确率} = \frac{\text{正确预测的样本数}}{\text{总样本数}} 准确率=总样本数正确预测的样本数
即:
Accuracy = T P + T N T P + T N + F P + F N \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
其中:
- TP(True Positives):模型正确预测为正例的样本数。
- TN(True Negatives):模型正确预测为负例的样本数。
- FP(False Positives):模型错误预测为正例的样本数(即假阳性)。
- FN(False Negatives):模型错误预测为负例的样本数(即假阴性)。
使用 scikit-learn 计算准确率
在 scikit-learn 中,计算模型准确率非常简单,可以使用 accuracy_score 函数。以下是如何使用准确率评估模型的示例:
from sklearn.metrics import accuracy_score
# 假设 test_sentiments 是测试集的真实标签,lr_bow_predict 是模型的预测标签
accuracy_bow = accuracy_score(test_sentiments, lr_bow_predict)
print(f"Bag of Words Model Accuracy: {accuracy_bow:.4f}")
# 假设 lr_tfidf_predict 是基于 TF-IDF 特征的模型预测标签
accuracy_tfidf = accuracy_score(test_sentiments, lr_tfidf_predict)
print(f"TF-IDF Model Accuracy: {accuracy_tfidf:.4f}")
解释:
-
accuracy_score(test_sentiments, lr_bow_predict):- 计算词袋模型(Bag of Words)在测试集上的准确率。
test_sentiments是测试集的真实标签,lr_bow_predict是模型的预测标签。
- 计算词袋模型(Bag of Words)在测试集上的准确率。
-
accuracy_score(test_sentiments, lr_tfidf_predict):- 计算基于 TF-IDF 特征的模型在测试集上的准确率。
-
打印结果:结果会显示模型在测试集上的准确率,通常以小数表示,例如
0.85表示 85% 的预测是正确的。
准确率的局限性:
虽然准确率是一个直观且常用的评估指标,但它在类别不平衡的数据集中可能会产生误导。例如,如果在一个极端不平衡的二分类问题中,99%的样本属于一个类别,那么一个总是预测为该类别的模型也会有99%的准确率,但这个模型显然是无效的。因此,在类别不平衡的情况下,还应结合其他指标(如精确率、召回率、F1 分数)来全面评估模型的性能。
模型评估:分类报告
词袋模型的结果:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| Positive | 0.75 | 0.75 | 0.75 | 4993 |
| Negative | 0.75 | 0.75 | 0.75 | 5007 |
| accuracy | 0.75 | 10000 | ||
| macro avg | 0.75 | 0.75 | 0.75 | 10000 |
| weighted avg | 0.75 | 0.75 | 0.75 | 10000 |
#Classification report for bag of words
lr_bow_report=classification_report(test_sentiments,lr_bow_predict,target_names=['Positive','Negative'])
print(lr_bow_report)
这段代码生成并打印了一个分类报告,该报告展示了使用词袋模型(Bag of Words)特征的逻辑回归模型在测试数据上的分类性能。以下是代码的详细解释:
1. 生成分类报告
lr_bow_report = classification_report(test_sentiments, lr_bow_predict, target_names=['Positive', 'Negative'])
-
classification_report:classification_report是scikit-learn中的一个函数,用于生成分类模型的详细性能报告。
-
参数说明:
test_sentiments:这是测试数据的真实情感标签,表示模型的实际分类目标。lr_bow_predict:这是使用词袋模型特征(Bag of Words)进行预测得到的情感标签。target_names=['Positive', 'Negative']:指定分类标签的名称。这里假设test_sentiments和lr_bow_predict中的标签是二分类的,并且标签顺序分别对应 “Positive” 和 “Negative”。
2. 打印分类报告
print(lr_bow_report)
- 这一行代码将生成的分类报告打印出来,以便查看模型在测试数据上的表现。
3. 分类报告的输出内容
生成的分类报告包含以下内容:
-
Precision(精确率):表示在模型预测为某个类别的样本中,实际为该类别的比例。例如,如果模型预测为“Positive”的样本中,有 80% 实际是“Positive”,那么精确率为 0.8。
-
Recall(召回率):表示实际为某个类别的样本中,模型正确预测为该类别的比例。例如,如果实际为“Positive”的样本中,模型正确识别了 75%,那么召回率为 0.75。
-
F1-Score:精确率和召回率的调和平均数,用于衡量模型在分类任务中的综合表现。F1 分数是精确率和召回率的权衡,分数越高表示模型性能越好。
-
Support(支持度):指的是每个类别在测试集中实际存在的样本数量。例如,测试集中有 200 个“Positive”的样本和 150 个“Negative”的样本,那么支持度为 200 和 150。
4. 总结
通过这段代码生成的分类报告,你可以详细了解模型在不同情感类别上的表现。查看精确率、召回率和 F1 分数,可以帮助你评估模型在分类任务中的可靠性和准确性。结合这些指标,可以更好地调整模型参数或选择不同的特征提取方法以提高分类性能。
模型评估:混淆矩阵
词袋模型的结果:
[[3766 1241]
[1248 3745]]
#confusion matrix for bag of words
cm_bow=confusion_matrix(test_sentiments,lr_bow_predict,labels=[1,0])
print(cm_bow)
这段代码生成并打印了词袋模型(Bag of Words)特征的逻辑回归模型在测试集上的混淆矩阵(Confusion Matrix)。混淆矩阵是一种用于描述分类模型性能的表格,它显示了模型在预测时的各种类型的正确和错误分类情况。下面是对代码的详细解析:
1. 生成混淆矩阵
cm_bow = confusion_matrix(test_sentiments, lr_bow_predict, labels=[1, 0])
confusion_matrix:confusion_matrix是scikit-learn中的一个函数,用于生成混淆矩阵。test_sentiments:这是测试数据的真实情感标签。lr_bow_predict:这是使用词袋模型特征进行预测得到的情感标签。labels=[1, 0]:指定标签的顺序。1通常代表正类(Positive),0通常代表负类(Negative)。通过指定labels=[1, 0],你可以确保混淆矩阵中的行和列按照指定顺序排列。
2. 打印混淆矩阵
print(cm_bow)
- 打印混淆矩阵:输出的混淆矩阵将展示模型的分类情况,包括正确和错误的预测。
3. 混淆矩阵的结构
混淆矩阵通常是一个 2x2 的矩阵,表示模型在二分类问题中的分类情况。假设 labels=[1, 0],输出矩阵的结构如下:
Predicted: 1 (Positive)
Predicted: 0 (Negative)
Actual: 1 (Positive)
TP
FN
Actual: 0 (Negative)
FP
TN
\begin{array}{cc|c} & \text{Predicted: 1 (Positive)} & \text{Predicted: 0 (Negative)} \\ \hline \text{Actual: 1 (Positive)} & \text{TP} & \text{FN} \\ \text{Actual: 0 (Negative)} & \text{FP} & \text{TN} \\ \end{array}
Actual: 1 (Positive)Actual: 0 (Negative)Predicted: 1 (Positive)TPFPPredicted: 0 (Negative)FNTN
- TP(True Positive):实际为正类,预测也为正类的数量。
- FN(False Negative):实际为正类,但预测为负类的数量。
- FP(False Positive):实际为负类,但预测为正类的数量。
- TN(True Negative):实际为负类,预测也为负类的数量。
4. 解释混淆矩阵
假设 cm_bow 的输出如下:
50
10
5
35
\begin{array}{cc} 50 & 10 \\ 5 & 35 \\ \end{array}
5051035
这意味着:
- TP = 50:模型正确地将 50 个正类样本分类为正类。
- FN = 10:模型错误地将 10 个正类样本分类为负类。
- FP = 5:模型错误地将 5 个负类样本分类为正类。
- TN = 35:模型正确地将 35 个负类样本分类为负类。
5. 总结
混淆矩阵为你提供了关于模型分类性能的详细信息,尤其是在处理不平衡数据集时非常有用。通过分析混淆矩阵中的 TP、FN、FP 和 TN,可以更好地理解模型在不同类别上的表现,并据此调整模型或优化数据处理步骤。
线性支持向量机(SVM)模型
线性支持向量机(SVM,Support Vector Machine)是一种常用的监督学习算法,广泛应用于分类任务中。线性SVM旨在找到一个最佳的超平面,将数据集中的样本分成不同类别,最大化类别间的间隔(margin)。与逻辑回归类似,线性SVM也适合处理高维稀疏数据(如文本分类)。
1. 线性SVM的基本概念
(1) 超平面
在二分类问题中,线性SVM试图找到一个超平面来将两类数据分开。在二维空间中,超平面就是一条直线;在三维空间中,超平面是一个平面;在更高维空间中,超平面是一个(n-1)维的子空间。
(2) 间隔(Margin)
SVM的目标是找到能够将两类数据分开的最大间隔(margin)。间隔是指从超平面到最近的正例和负例的距离之和。SVM会选择能够最大化这个间隔的超平面,从而提高分类器的泛化能力。
(3) 支持向量
支持向量是离超平面最近的样本点,这些点在模型的构建中起到了关键作用。实际分类任务中,只有这些支持向量会影响最终的分类决策,其他样本点则不会。
(4) 线性可分与软间隔
在实际应用中,数据通常不是线性可分的。为了解决这个问题,SVM引入了“软间隔”(Soft Margin)的概念。通过引入松弛变量,SVM允许一些数据点位于错误的一侧,但同时会尽量减少这种错误的数量。
2. SVM的损失函数
线性SVM的优化目标是最小化以下损失函数:
L ( w , b ) = 1 2 ∥ w ∥ 2 + C ∑ i = 1 m max ( 0 , 1 − y ( i ) ( w T x ( i ) + b ) ) L(w, b) = \frac{1}{2} \|w\|^2 + C \sum_{i=1}^{m} \text{max}(0, 1 - y^{(i)}(w^T x^{(i)} + b)) L(w,b)=21∥w∥2+Ci=1∑mmax(0,1−y(i)(wTx(i)+b))
其中:
- w w w 是权重向量。
- b b b 是偏置项。
- C C C 是正则化参数,用于控制间隔最大化与误分类容忍之间的权衡。
第一项 1 2 ∥ w ∥ 2 \frac{1}{2} \|w\|^2 21∥w∥2 是正则化项,用于最大化间隔;第二项是“铰链损失”项,用于最小化分类错误。
3. 线性SVM的优点
- 高维数据处理能力强:线性SVM在处理高维数据时表现出色,尤其适用于文本分类等任务。
- 有效避免过拟合:通过最大化间隔,SVM能够有效避免过拟合问题。
- 适用于线性可分和近似线性可分的数据:SVM通过软间隔能够处理大部分现实问题中的线性不可分数据。
4. 线性SVM的缺点
- 对大规模数据不够高效:当数据集非常大时,SVM的训练时间较长,计算资源消耗较大。
- 对噪声敏感:特别是当类别之间存在重叠或噪声时,SVM的性能可能会下降。
- 选择合适的正则化参数C较难:模型的表现高度依赖于参数C的选择,可能需要进行交叉验证来选择最佳参数。
5. Python实现线性SVM
在Python中,可以使用scikit-learn库中的SVM模块来实现线性SVM。以下是一个文本分类的简单示例:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 假设 X 是文本数据,y 是标签(0 或 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将文本数据转换为TF-IDF表示
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
# 初始化线性SVM模型
model = SVC(kernel='linear', C=1.0)
# 训练模型
model.fit(X_train_tfidf, y_train)
# 预测
y_pred = model.predict(X_test_tfidf)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
print(f"Classification Report:\n{report}")
主要参数说明:
kernel='linear': 指定使用线性核函数,适用于线性可分或近似线性可分的数据。C=1.0: 正则化参数,控制分类边界的严格程度。较小的C值会使模型更注重分类边界的宽度,容忍一定的误分类;较大的C值则更倾向于正确分类训练集样本。
6. SVM与其他模型的对比
- 与逻辑回归:SVM与逻辑回归都是线性模型,但SVM通过最大化分类间隔进行优化,而逻辑回归通过最小化对数损失函数进行优化。SVM通常在高维空间下表现较好,而逻辑回归更容易解释模型输出。
- 与决策树:决策树通过划分特征空间进行分类,容易处理非线性数据。SVM则通过超平面划分数据,更适合线性分类任务。
- 与神经网络:神经网络能够处理复杂的非线性关系,但通常需要更多的数据和计算资源。SVM在小数据集和高维数据中表现出色。
7. 总结
线性支持向量机是一种强大的分类算法,尤其适用于高维数据和文本分类任务。通过最大化间隔,线性SVM能够有效避免过拟合,并且在处理线性可分或近似线性可分的数据时表现优异。尽管在大规模数据集上训练较慢且对噪声敏感,但SVM依然是许多实际分类任务中的首选模型之一。
SVM模型训练-本项目代码
#training the linear svm
svm=SGDClassifier(loss='hinge',max_iter=500,random_state=42)
#fitting the svm for bag of words
svm_bow=svm.fit(cv_train_reviews,train_sentiments)
print(svm_bow)
这段代码使用 SGDClassifier 训练了一个线性支持向量机(SVM)模型,并使用词袋模型(Bag of Words)特征进行训练。以下是代码的详细解释:
1. 初始化线性 SVM 模型
svm = SGDClassifier(loss='hinge', max_iter=500, random_state=42)
SGDClassifier:这是scikit-learn中的一种分类器,使用随机梯度下降(SGD)方法来优化线性模型。- 参数解释:
loss='hinge':指定损失函数为hinge,这是标准的支持向量机损失函数,适用于线性 SVM。max_iter=500:最大迭代次数,设置为 500。随机梯度下降法需要多次迭代来调整模型参数,直到损失函数收敛或达到最大迭代次数。random_state=42:设置随机种子,保证结果的可重复性。42 是常用的种子值,但可以设置为任何整数。
2. 使用词袋模型(Bag of Words)特征训练 SVM 模型
svm_bow = svm.fit(cv_train_reviews, train_sentiments)
print(svm_bow)
-
svm.fit(cv_train_reviews, train_sentiments):- 这一步使用词袋模型特征(Bag of Words)的训练数据
cv_train_reviews和对应的情感标签train_sentiments来训练 SVM 模型。 cv_train_reviews是通过CountVectorizer提取的词袋模型特征矩阵,train_sentiments是与这些特征对应的真实情感标签(例如 0 表示负面,1 表示正面)。
- 这一步使用词袋模型特征(Bag of Words)的训练数据
-
svm_bow:- 存储了训练好的线性 SVM 模型。这个对象包含了模型的所有参数和状态,可以用来进行预测或评估模型的性能。
-
print(svm_bow):- 打印训练好的模型对象。通常,这会输出模型的参数信息和状态,但不会详细显示训练过程中的具体计算。
3. 总结
这段代码的核心工作是训练一个线性支持向量机(SVM)模型,用于文本分类任务。使用词袋模型特征,SGDClassifier 通过多次迭代优化模型的权重,使其能够根据输入的文本特征预测文本的情感(如正面或负面)。
接下来,你可以使用测试集来评估模型的性能,计算准确率、精确率、召回率、F1 分数等指标。你还可以将这个模型与其他模型(如使用 TF-IDF 特征的 SVM 或逻辑回归模型)进行比较,以确定哪种方法在你的特定任务中效果最好。
SVM模型的初始化参数配置解析
SGDClassifier(alpha=0.0001, average=False, class_weight=None,
early_stopping=False, epsilon=0.1, eta0=0.0, fit_intercept=True,
l1_ratio=0.15, learning_rate='optimal', loss='hinge',
max_iter=500, n_iter_no_change=5, n_jobs=None, penalty='l2',
power_t=0.5, random_state=42, shuffle=True, tol=0.001,
validation_fraction=0.1, verbose=0, warm_start=False)
这段代码展示了如何初始化 SGDClassifier(随机梯度下降分类器)的一个实例,并列出了其常见的参数配置。SGDClassifier 是一种用于大规模线性分类的工具,适用于处理大量样本和高维数据。以下是每个参数的详细解释及其影响:
-
alpha=0.0001
- 解释:
alpha是正则化项的系数,它控制正则化的强度。正则化有助于防止模型过拟合。 - 影响:较大的
alpha值会导致更强的正则化,抑制模型的复杂性;较小的alpha值则会允许模型更好地拟合训练数据,但可能增加过拟合的风险。
- 解释:
-
average=False
- 解释:当设置为
True时,模型在每次迭代时会计算参数的平均值,而不是只使用最后一轮的参数。这对处理噪声数据或收敛缓慢的数据集可能有帮助。 - 影响:开启
average可能在某些情况下提高模型的鲁棒性,但会增加计算成本。
- 解释:当设置为
-
class_weight=None
- 解释:用于设置各类别的权重。如果设置为
None,则表示不调整权重;如果设置为'balanced',则根据类别频率自动调整权重,以应对类别不平衡问题。 - 影响:在类别不平衡的数据集中,调整权重可以使模型更加关注少数类别,提高少数类的识别率。
- 解释:用于设置各类别的权重。如果设置为
-
early_stopping=False
- 解释:是否启用早停策略。如果设置为
True,模型在验证集上的表现不再提升时会提前停止训练。 - 影响:启用早停可以防止模型过拟合,特别是在训练集表现良好但验证集表现开始下降时。
- 解释:是否启用早停策略。如果设置为
-
epsilon=0.1
- 解释:该参数用于
epsilon-insensitive损失函数,主要用于回归任务。对分类任务的影响较小。 - 影响:在回归任务中,
epsilon值越大,模型对误差的容忍度越高。
- 解释:该参数用于
-
eta0=0.0
- 解释:初始学习率。仅在
learning_rate设置为'constant'或'invscaling'时有意义。 - 影响:初始学习率决定了参数更新的步长。过大的学习率可能导致模型无法收敛,过小的学习率则可能导致训练过慢。
- 解释:初始学习率。仅在
-
fit_intercept=True
- 解释:是否为模型计算截距(intercept)。如果设置为
False,模型不会计算截距,假设数据已经中心化。 - 影响:大多数情况下,
True是默认且合理的选择,因为截距项可以帮助模型更好地拟合数据。
- 解释:是否为模型计算截距(intercept)。如果设置为
-
l1_ratio=0.15
- 解释:在使用 ElasticNet(混合 L1 和 L2 正则化)时,该参数控制 L1 正则化的比重。仅在
penalty='elasticnet'时有用。 - 影响:
l1_ratio=0.15表示 15% 的正则化强度来自于 L1,剩下的 85% 来自于 L2。这种组合可以在稀疏性和模型复杂性之间取得平衡。
- 解释:在使用 ElasticNet(混合 L1 和 L2 正则化)时,该参数控制 L1 正则化的比重。仅在
-
learning_rate='optimal’
- 解释:学习率调度方式。
'optimal'表示使用一种自适应的学习率,根据初始学习率和数据特性来调整步长。 - 影响:自适应学习率可以加速训练过程,尤其是在复杂的高维数据集上。
- 解释:学习率调度方式。
-
loss='hinge’
- 解释:损失函数设置为
'hinge',这是标准的支持向量机(SVM)损失函数,用于最大化分类间隔。 - 影响:
hinge损失函数适用于线性分类问题,通过最大化分类间隔来提高模型的泛化能力。
- 解释:损失函数设置为
-
max_iter=500
- 解释:最大迭代次数。模型将在这个次数内不断更新参数,直到收敛或达到此次数。
- 影响:如果数据复杂且学习率较低,可能需要更高的迭代次数来确保模型收敛。
-
n_iter_no_change=5
- 解释:早停的相关参数。如果在
n_iter_no_change次迭代中,损失函数的改进小于tol,则停止训练。 - 影响:这一参数用于加速训练,防止不必要的迭代。
- 解释:早停的相关参数。如果在
-
n_jobs=None
- 解释:指定并行计算时使用的 CPU 核心数。
None表示使用单个核心,-1表示使用所有可用核心。 - 影响:并行计算可以加快训练过程,尤其是在大数据集上。
- 解释:指定并行计算时使用的 CPU 核心数。
-
penalty='l2’
- 解释:正则化类型,L2 正则化会惩罚较大的权重参数,从而防止模型过拟合。
- 影响:L2 正则化通常用于大多数线性模型,可以使模型更具泛化能力。
-
power_t=0.5
- 解释:控制学习率的调度速率。仅在
learning_rate='invscaling'时有意义。 - 影响:
power_t值越高,学习率下降得越快。这个参数需要与初始学习率eta0配合使用。
- 解释:控制学习率的调度速率。仅在
-
random_state=42
- 解释:设置随机数生成的种子,以确保结果的可重复性。任何整数值都可以作为随机种子。
- 影响:固定随机种子可以确保每次运行时结果一致,方便调试和验证模型。
-
shuffle=True
- 解释:在每次迭代前是否打乱数据顺序。打乱数据可以防止模型陷入局部最优解。
- 影响:打乱数据有助于提高模型的泛化能力,特别是在处理顺序敏感的数据集时。
-
tol=0.001
- 解释:判断模型是否收敛的容忍度。如果在迭代过程中损失的改进小于
tol,则认为模型已收敛。 - 影响:较小的
tol值会让模型收敛得更精确,但也可能增加训练时间。
- 解释:判断模型是否收敛的容忍度。如果在迭代过程中损失的改进小于
-
validation_fraction=0.1
- 解释:用于早停的验证集比例。当
early_stopping=True时,训练集的一部分将被分离出来作为验证集。 - 影响:验证集比例会影响早停判断的可靠性,设置过大或过小都可能影响模型性能。
- 解释:用于早停的验证集比例。当
-
verbose=0
- 解释:控制训练过程中的输出信息量。
0表示不输出,1表示输出少量信息,2表示输出详细信息。 - 影响:在调试过程中,增加
verbose值可以帮助跟踪训练过程。
- 解释:控制训练过程中的输出信息量。
-
warm_start=False
- 解释:是否在每次调用
fit方法时重用上一次训练的结果。如果设置为True,则模型会在上一次的基础上继续训练。 - 影响:适用于需要在多个阶段逐步训练模型的场景。
- 解释:是否在每次调用
这些参数的设置可以根据具体的任务需求和数据集特性进行调整,以获得最佳的模型性能。在实际应用中,通常需要通过实验和调参来找到最适合的配置。
随机梯度下降(SGD)
随机梯度下降(Stochastic Gradient Descent, SGD)是一种用于优化机器学习模型(尤其是神经网络和线性模型)的迭代方法。SGD通过逐步调整模型参数,最小化损失函数,进而找到模型的最优参数。与标准的梯度下降相比,SGD在每次迭代时仅使用一个或少量样本来更新模型参数,从而在处理大规模数据集时表现出色。
1. 梯度下降的基本概念
在机器学习中,模型的目标是最小化损失函数,即衡量预测结果与真实标签之间差异的函数。梯度下降是找到使损失函数最小化的参数(如权重)的常用方法。
(1) 批量梯度下降(Batch Gradient Descent)
批量梯度下降计算整个训练集的梯度,然后更新一次模型参数。这种方法计算精确,但对大数据集来说,计算开销大,效率低。
- 更新公式: θ : = θ − η ⋅ 1 m ∑ i = 1 m ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta := \theta - \eta \cdot \frac{1}{m} \sum_{i=1}^{m} \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)}) θ:=θ−η⋅m1∑i=1m∇θJ(θ;x(i),y(i))
其中:
- θ \theta θ 是模型参数
- η \eta η 是学习率(learning rate)
- m m m 是训练样本的总数
- ∇ θ J ( θ ; x ( i ) , y ( i ) ) \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)}) ∇θJ(θ;x(i),y(i)) 是第 i i i 个样本的梯度
(2) 随机梯度下降(SGD)
随机梯度下降在每次迭代时仅使用一个样本计算梯度并更新参数。由于每次更新只依赖一个样本,SGD的更新频繁,因此它能够更快地在大数据集上收敛。
- 更新公式: θ : = θ − η ⋅ ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta := \theta - \eta \cdot \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)}) θ:=θ−η⋅∇θJ(θ;x(i),y(i))
其中:
- θ \theta θ 是模型参数
- η \eta η 是学习率
- ∇ θ J ( θ ; x ( i ) , y ( i ) ) \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)}) ∇θJ(θ;x(i),y(i)) 是单个样本的梯度
2. SGD的优缺点
优点:
- 效率高:SGD适合大规模数据集,因为它在每次迭代中只使用一个样本更新参数,计算量较小。
- 在线学习:SGD可以在训练过程中逐渐引入新数据,适合在线学习场景。
- 更容易跳出局部最优:由于每次迭代仅使用一个样本,SGD的更新方向较为随机,这使得它有时能跳出局部最优点,找到更优解。
缺点:
- 更新不稳定:由于每次更新只依赖一个样本,SGD的收敛过程可能会比较不稳定,导致损失函数震荡或收敛较慢。
- 需要调节学习率:SGD对学习率敏感,过高的学习率可能导致不收敛,过低的学习率则可能导致收敛缓慢。
- 可能陷入局部最优:尽管SGD可以跳出局部最优点,但也可能在复杂损失面中陷入局部最优。
3. SGD的改进与变种
为了克服SGD的缺点,研究人员提出了多种改进方法:
(1) 小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降结合了批量梯度下降和SGD的优点。它在每次迭代时使用一个小批量样本(如32或64个样本)来更新参数。这样可以减少更新的波动,同时保持一定的计算效率。
(2) 动量(Momentum)
动量方法通过引入之前梯度的影响来加速收敛并减少振荡。动量项会积累之前梯度的加权平均值,更新时考虑这一累积值。
- 更新公式: v t = γ v t − 1 + η ⋅ ∇ θ J ( θ ) v_t = \gamma v_{t-1} + \eta \cdot \nabla_{\theta} J(\theta) vt=γvt−1+η⋅∇θJ(θ)
- 参数更新: θ : = θ − v t \theta := \theta - v_t θ:=θ−vt
其中, γ \gamma γ 是动量因子,通常在0.9左右。
(3) 自适应学习率方法(如AdaGrad、RMSProp、Adam)
这些方法通过调整学习率,使得在训练的早期具有较大的步长,而在训练的后期自动缩小步长,从而提高收敛速度和稳定性。Adam是目前使用最广泛的优化方法之一,结合了动量和RMSProp的优点。
4. Python实现随机梯度下降
在scikit-learn中,许多线性模型(如线性回归、逻辑回归、线性SVM)都可以使用SGD进行训练。以下是一个使用SGD训练逻辑回归模型的示例:
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化SGD分类器(逻辑回归)
sgd_clf = SGDClassifier(loss='log', max_iter=1000, tol=1e-3)
# 训练模型
sgd_clf.fit(X_train, y_train)
# 预测
y_pred = sgd_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
主要参数说明:
loss='log': 指定损失函数为逻辑回归的对数损失。max_iter=1000: 迭代次数上限。tol=1e-3: 容忍误差,当损失函数的变化小于该值时,提前停止迭代。
5. 总结
随机梯度下降(SGD)是一种高效的优化算法,尤其适用于大规模数据集和在线学习场景。尽管SGD在收敛过程中可能会有波动,但通过动量、小批量梯度下降和自适应学习率等技术,可以提高SGD的收敛速度和稳定性。在实际应用中,SGD通常是许多机器学习模型的默认优化算法,尤其是在深度学习中,SGD及其变种广泛用于神经网络的训练。
多项式朴素贝叶斯模型
Multinomial Naive Bayes(多项式朴素贝叶斯)是朴素贝叶斯算法的一种变体,特别适用于文本分类任务,如垃圾邮件检测、情感分析等。它基于贝叶斯定理,并假设特征(在文本分类中通常是词汇)之间的条件独立性。
1. 朴素贝叶斯的基本原理
朴素贝叶斯算法基于贝叶斯定理,贝叶斯定理描述了在已知某些证据的情况下,计算某个事件发生的概率:
P ( C k ∣ x ) = P ( C k ) ⋅ P ( x ∣ C k ) P ( x ) P(C_k | x) = \frac{P(C_k) \cdot P(x | C_k)}{P(x)} P(Ck∣x)=P(x)P(Ck)⋅P(x∣Ck)
其中:
- ( P(C_k | x) ) 是在给定特征 ( x ) 的情况下类别 ( C_k ) 的后验概率。
- ( P(C_k) ) 是类别 ( C_k ) 的先验概率。
- ( P(x | C_k) ) 是在给定类别 ( C_k ) 的情况下特征 ( x ) 的似然概率。
- ( P(x) ) 是特征 ( x ) 的边际概率。
朴素贝叶斯假设特征之间相互独立,这使得计算 ( P(x | C_k) ) 的难度大大降低:
P ( x ∣ C k ) = P ( x 1 ∣ C k ) ⋅ P ( x 2 ∣ C k ) ⋅ … ⋅ P ( x n ∣ C k ) P(x | C_k) = P(x_1 | C_k) \cdot P(x_2 | C_k) \cdot \ldots \cdot P(x_n | C_k) P(x∣Ck)=P(x1∣Ck)⋅P(x2∣Ck)⋅…⋅P(xn∣Ck)
2. 多项式朴素贝叶斯
多项式朴素贝叶斯特别适用于离散型特征的数据集,尤其是文本数据。它假设给定类别的情况下,每个特征(词汇)出现的次数服从多项分布。
(1) 模型公式
对于一个给定的类别 ( C_k ),给定特征 ( x = (x_1, x_2, \dots, x_n) ),特征向量中每个特征(词汇) ( x_i ) 的条件概率为:
P ( C k ∣ x ) ∝ P ( C k ) ∏ i = 1 n P ( x i ∣ C k ) x i P(C_k | x) \propto P(C_k) \prod_{i=1}^{n} P(x_i | C_k)^{x_i} P(Ck∣x)∝P(Ck)i=1∏nP(xi∣Ck)xi
其中:
- ( P(C_k) ) 是类别 ( C_k ) 的先验概率,可以通过类别在数据集中出现的频率来估计。
- ( P(x_i | C_k) ) 是特征(词汇) ( x_i ) 在类别 ( C_k ) 下的条件概率,通常使用词频估计。
(2) 参数估计
-
先验概率 ( P(C_k) ):可以通过类别在训练集中出现的频率进行估计。
-
条件概率 ( P(x_i | C_k) ):可以通过词频进行估计,使用拉普拉斯平滑(Laplace Smoothing)来避免出现概率为零的情况。
P ( x i ∣ C k ) = N i k + α N k + α n P(x_i | C_k) = \frac{N_{ik} + \alpha}{N_k + \alpha n} P(xi∣Ck)=Nk+αnNik+α
其中:
- ( N_{ik} ) 是类别 ( C_k ) 中特征 ( x_i ) 的出现次数。
- ( N_k ) 是类别 ( C_k ) 中所有特征的总次数。
- ( \alpha ) 是平滑参数(通常为1)。
- ( n ) 是特征(词汇)的总数。
3. Multinomial Naive Bayes 的优缺点
优点:
- 计算效率高:由于模型简单,多项式朴素贝叶斯的计算量较小,适合大规模数据集。
- 适用于文本分类:在文本分类中,多项式朴素贝叶斯是一个强有力的基线模型,表现往往优于其他复杂的模型。
- 对稀疏数据的处理:在高维稀疏数据(如TF-IDF向量)中,多项式朴素贝叶斯能够很好地处理这种特征空间。
缺点:
- 独立性假设过于简单:假设特征之间相互独立在实际情况中并不成立,可能导致模型的准确性下降。
- 对概率为零的敏感性:在计算条件概率时,如果某个词汇在训练集中没有出现在某个类别中,模型可能会赋予该类别的概率为零。尽管平滑技术可以缓解这个问题,但仍然是一个潜在的弱点。
4. Python实现Multinomial Naive Bayes
在scikit-learn中,MultinomialNB类用于实现多项式朴素贝叶斯。以下是一个简单的文本分类示例:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 假设 X 是文本数据,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将文本数据转换为TF-IDF表示
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
# 初始化多项式朴素贝叶斯模型
nb = MultinomialNB()
# 训练模型
nb.fit(X_train_tfidf, y_train)
# 预测
y_pred = nb.predict(X_test_tfidf)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
print(f"Classification Report:\n{report}")
主要参数说明:
alpha=1.0: 拉普拉斯平滑参数,默认为1。可以调整该参数以控制平滑的程度。fit_prior=True: 是否学习类别的先验概率。如果设置为False,则所有类别的先验概率被认为是相等的。
5. 多项式朴素贝叶斯的应用场景
多项式朴素贝叶斯模型广泛应用于文本分类任务,特别是以下场景:
- 垃圾邮件过滤:区分垃圾邮件和正常邮件。
- 情感分析:分析文本的情感倾向,如电影评论的正面或负面评价。
- 文档分类:根据内容将文档归类为不同的类别,如新闻分类、产品评论分类等。
6. 总结
多项式朴素贝叶斯是一种有效且高效的分类算法,尤其适用于文本分类任务。尽管独立性假设可能过于简单,但在许多实际应用中,多项式朴素贝叶斯依然表现出色。它作为一个强有力的基线模型,通常用于与更复杂的模型进行对比,以评估后者的性能提升。通过适当的平滑技术和特征工程,Multinomial Naive Bayes 可以在许多场景中提供稳健的分类性能。
文本数据可视化工具:词云(Word Cloud)
项目代码:
#word cloud for positive review words
plt.figure(figsize=(10,10))
positive_text=norm_train_reviews[1]
WC=WordCloud(width=1000,height=500,max_words=500,min_font_size=5)
positive_words=WC.generate(positive_text)
plt.imshow(positive_words,interpolation='bilinear')
plt.show
这段代码生成了一个词云(Word Cloud),用于可视化显示正面评论中的常见词语。词云是一种直观的文本数据可视化工具,词语的大小与其在文本中的频率相关。下面是对代码的详细解析:
1. 设置图像大小
plt.figure(figsize=(10,10))
- 解释:
plt.figure(figsize=(10, 10))用于设置图像的尺寸,figsize参数决定图像的宽度和高度(单位为英寸)。在这里,图像的尺寸设置为 10x10 英寸。 - 影响:较大的图像尺寸可以容纳更多内容,适合展示更复杂或更详细的词云。
2. 提取正面评论文本
positive_text = norm_train_reviews[1]
- 解释:
positive_text是从norm_train_reviews数据集中提取的文本。norm_train_reviews[1]指的是该数据集的第二条评论(假设索引从 0 开始)。 - 影响:此处只使用了一个评论文本来生成词云。如果你想要显示多个正面评论中的常见词,可以将多个评论文本拼接在一起。
3. 初始化词云对象
WC = WordCloud(width=1000, height=500, max_words=500, min_font_size=5)
- 解释:
WordCloud是wordcloud库中的一个类,用于生成词云图。width=1000和height=500设置词云图的宽度和高度(像素)。max_words=500限制词云中显示的最大单词数量,只有频率最高的 500 个词语会被显示。min_font_size=5设置词云图中最小字体的大小。
- 影响:这些参数决定了词云图的外观和复杂性。你可以根据具体需求调整这些参数。
4. 生成词云
positive_words = WC.generate(positive_text)
- 解释:
generate方法接受一个字符串(即positive_text)作为输入,并根据词频生成一个词云对象positive_words。 - 影响:词云的生成是基于文本中词语的出现频率,出现频率越高的词语在词云中显示得越大。
5. 显示词云图
plt.imshow(positive_words, interpolation='bilinear')
plt.show()
- 解释:
plt.imshow(positive_words, interpolation='bilinear')将生成的词云对象作为图像显示。interpolation='bilinear'设置图像插值方法,使图像在放大时更加平滑。 plt.show()用于显示图像。- 影响:词云图会显示在一个新窗口或笔记本单元格中,展示文本中词语的分布和频率。
6. 总结
这段代码的主要功能是生成并展示一个词云图,视觉化表示正面评论中的常用词语。通过查看词云图,你可以直观地了解哪些词在正面评论中出现频率最高,通常这些词与评论的情感倾向有密切关系。如果你需要分析负面评论,或者多个评论文本的词语频率,可以相应调整输入的文本内容。
三、我做的一些分析、优化和总结
使用并行计算缩短词干提取时间
通过 joblib 来并行计算后,从6min 37s 优化到了 2min 41s。
我kaggle的V4版本
#Stemming the text
def simple_stemmer(text):
ps=nltk.porter.PorterStemmer()
text= ' '.join([ps.stem(word) for word in text.split()])
return text
#Apply function on review column
imdb_data['review']=imdb_data['review'].apply(simple_stemmer)
在Kaggle上运行原作者这段代码时,跑了5分钟还没结束,所以我决定进行了一些优化提升运行速度。
可能的原因
-
数据量大:
如果imdb_data['review']列包含大量的文本数据,逐个词进行stemming(词干提取)会耗费大量时间。因为代码对每个单词都进行了一次处理,并且这是在每个文本段落中逐词处理的,处理大数据集时,这会导致非常高的计算开销。 -
逐词处理效率低:
在simple_stemmer函数中使用了逐词处理,ps.stem(word)对每个单词进行词干提取,这种方式在Python的解释器中逐词处理会非常耗时,尤其是在处理较大的数据集时。 -
未优化的代码结构:
由于simple_stemmer函数在每次调用时都会创建一个新的PorterStemmer对象,这增加了不必要的开销。创建PorterStemmer对象本身虽然不耗费太多时间,但在处理大量数据时,这些小的开销会累积起来。
优化方案
为了提高运行速度,我尝试了以下优化方法:
-
重用
PorterStemmer对象:
避免在每次调用simple_stemmer时创建新的PorterStemmer对象,可以将它移到函数外部:ps = nltk.porter.PorterStemmer() def simple_stemmer(text): return ' '.join([ps.stem(word) for word in text.split()]) -
并行处理:
如果数据量非常大,可以尝试使用多线程或多进程库(如multiprocessing或joblib)来并行处理不同的文本段落,从而加快处理速度。通过joblib来并行计算后,优化到了2min 41s。新版代码如下:
#Stemming the text
# 初始化 PorterStemmer
ps=nltk.porter.PorterStemmer()
# 定义优化后的词干提取函数
def simple_stemmer(text):
return ' '.join([ps.stem(word) for word in text.split()])
# 并行处理函数
def parallelize_dataframe(df, func, n_jobs=-1):
return Parallel(n_jobs=n_jobs)(delayed(func)(text) for text in df)
# 假设 imdb_data['review'] 是评论列
# 使用并行处理对每个评论应用词干提取函数
imdb_data['review'] = parallelize_dataframe(imdb_data['review'], simple_stemmer)
-
使用更高效的库:
尽量使用经过优化的库或者方法来处理文本。例如,spaCy库可以在某些文本处理任务上表现得更快,并且它支持更高效的并行化处理。 -
减少数据量:
如果你仅是在测试代码,可以先在一个较小的数据子集上进行测试,待代码确认无误后再应用于整个数据集。
通过这些优化方法,可以显著提高代码运行的效率,并减少执行时间。
为什么在处理大规模数据集时,spaCy要优于nltk?
在处理大规模数据集时,spaCy 通常优于 nltk,主要有以下几方面的原因:
1. spaCy 专为工业级处理优化
- spaCy 是一个为大规模数据处理设计的库,专注于效率和速度。它的底层使用了高度优化的 Cython 来实现,能够高效地处理大量数据。
- 相比之下,nltk 更加学术化,功能丰富且灵活,适合研究和教学,但其设计未针对高效处理大量文本进行优化。其实现主要是 Python,速度相对较慢。
2. 批量处理能力(Pipeline 和 nlp.pipe)
- spaCy 提供了高效的批量处理功能,例如
nlp.pipe(),允许同时处理多个文档。这种批处理机制通过减少函数调用的开销,显著提高了处理大规模数据的速度。 - nltk 则倾向于逐个文档或逐个词处理,这种处理方式在大规模数据集上效率较低,尤其是在处理高频操作(如
词形还原、词干提取)时。
3. 并行处理
- spaCy 内部支持并行处理,能够充分利用多核 CPU 来加速任务,尤其在处理数万个文档时性能提升显著。通过合理利用多核,可以大幅度缩短处理时间。
- nltk 没有内建的并行处理机制,需要用户自行实现并行化,这增加了开发复杂度,同时效率也不如
spaCy优化得好。
4. 内存管理和效率
- spaCy 的内存管理经过优化,能够处理更大的数据集而不会造成内存不足。它的内存分配与释放更加高效,特别是在处理长文本或大规模文本数据时,这一点尤为重要。
- nltk 在处理大数据时可能会消耗更多的内存,尤其是在重复操作中更容易导致内存溢出或处理速度缓慢。
5. 词形还原 vs 词干提取
- spaCy 提供了快速且准确的词形还原(lemmatization),它基于上下文来还原单词的词形,因此更准确。
- nltk 主要依赖于 PorterStemmer 或 SnowballStemmer 等算法进行词干提取(stemming),这些算法基于规则,处理较为机械,准确性较低,尤其在复杂文本中。相比词形还原,词干提取的效果不够精准。
6. 预训练的语言模型
- spaCy 提供了多个预训练的语言模型,如
en_core_web_sm,这些模型包含词性标注、依存分析、命名实体识别等功能,且这些功能是高度优化的,可以高效地应用于大规模文本处理任务。 - nltk 提供了更多的工具和算法,但缺乏直接的、优化过的预训练模型,尤其在高效处理上不如
spaCy友好和快速。
7. 简洁的 API 和现代设计
- spaCy 的 API 设计现代且简洁,许多复杂操作可以通过一两行代码实现,非常适合工业级别的数据处理和应用部署。
- nltk 的 API 丰富灵活,但相对更复杂,初学者和开发者在处理大规模数据时可能需要更多的代码,操作也可能不如
spaCy直观。
8. 依赖关系和集成
- spaCy 与许多现代深度学习框架(如 TensorFlow、PyTorch)集成得更好,适合搭建复杂的 NLP 管道,直接在文本预处理中衔接机器学习任务。
- nltk 虽然提供了广泛的工具,但在工业级应用中的集成性和现代框架的适配性不如
spaCy。
总结:
spaCy 在处理大规模数据集时,性能、效率和内存管理显著优于 nltk,主要原因是它专为工业应用设计,支持批处理、多线程优化、Cython 底层实现和现代 API。对于需要高效处理大规模文本数据的任务,如机器学习和深度学习的预处理阶段,spaCy 是更合适的选择。
用spaCy替代nltk来加速词干提取的尝试
初步尝试效果不理想
从下面运行结果可以看出,如果跑完要花费超过10min,可能和未做并行处理的nltk速度相当,明显慢于并行处理优化后的nltk(2min 41s)
11%|█ | 5595/50000 [01:20<10:39, 69.46it/s]
代码如下:
%%time
import spacy
from tqdm import tqdm
# 确保下载了所需的spaCy模型,例如en_core_web_sm
# 你可以在命令行中运行以下命令来下载:
# python -m spacy download en_core_web_sm
# 加载spaCy模型,禁用不必要的组件以加快处理速度
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
# 定义词形还原函数
def lemmatize_text(text):
doc = nlp(text)
return ' '.join([token.lemma_ for token in doc if not token.is_punct and not token.is_space])
# 使用tqdm显示进度条,处理数据集
tqdm.pandas()
# 假设 imdb_data 是你的DataFrame,'review' 是评论列
imdb_data['review'] = imdb_data['review'].progress_apply(lemmatize_text)
使用spaCy的批处理功能来进一步优化
效果还是不理想,如果跑完仍然要花费超过10min
10%|█ | 5/50 [01:15<11:25, 15.23s/it]
尝试把batch_size从1000修改为5000,还是没有什么效果,反而更慢了一点
10%|█ | 1/10 [01:25<12:52, 85.83s/it]
代码如下:
%%time
import spacy
from tqdm import tqdm
# 加载spaCy模型,禁用不必要的组件
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
# 定义批处理的大小
batch_size = 5000
# 定义批处理函数
def batch_lemmatize(texts):
docs = nlp.pipe(texts, batch_size=batch_size)
return [' '.join([token.lemma_ for token in doc if not token.is_punct and not token.is_space]) for doc in docs]
# 处理数据集并应用词形还原
reviews = imdb_data['review'].tolist()
lemmatized_reviews = []
for i in tqdm(range(0, len(reviews), batch_size)):
batch = reviews[i:i + batch_size]
lemmatized_batch = batch_lemmatize(batch)
lemmatized_reviews.extend(lemmatized_batch)
imdb_data['review'] = lemmatized_reviews
并行处理优化
我使用的是 spaCy 2.x 版本,升级到3.x 版本失败,所以手动实现并行处理,利用了4核CPU,时间从12min缩短为4min 35s,但还是比nltk的批处理优化慢(2min 41s)。
CPU times: user 9.82 s, sys: 3.39 s, total: 13.2 s
Wall time: 4min 35s
代码如下:
%%time
import spacy
from multiprocessing import Pool
# 仍然加载 spaCy 的语言模型,但不使用并行化参数
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner', 'textcat'])
def lemmatize_text(text):
doc = nlp(text)
return ' '.join([token.lemma_ for token in doc if not token.is_punct and not token.is_space])
def parallel_lemmatize(texts, num_processes):
with Pool(num_processes) as pool:
results = list(pool.imap(lemmatize_text, texts))
return results
reviews = imdb_data['review'].tolist()
# 设置使用的进程数
num_processes = 4 # 根据你的 CPU 核心数调整
# 并行处理
lemmatized_reviews = parallel_lemmatize(reviews, num_processes)
imdb_data['review'] = lemmatized_reviews
总结
用spaCy替代nltk来做词干提取,实际测试下来,速度还要慢一倍,所以打算放弃,仍然采用nltk来做词干提取。为什么spaCy会更慢的原因分析见下面。
spaCy词干提取的实际耗时比nltk更长的原因
在你使用 spaCy 进行词干提取时发现耗时比 nltk 更长的情况下,即便两者都使用了并行计算,可能有以下原因导致这种性能差异:
1. 词干提取与词形还原的区别
spaCy默认进行的是 词形还原(lemmatization),而nltk提供的是 词干提取(stemming)。- 词形还原(Lemmatization) 是根据单词的上下文和词法形态,返回其词典中的标准形式。这是一个更复杂的过程,涉及到词性标注和规则匹配,因此耗时较长。
- 词干提取(Stemming) 是一种简单的规则截断方法,仅通过切割词缀来减少单词的形态,这个过程简单直接,速度更快,但准确性较低。
如果你在 spaCy 中期望进行 词干提取(stemming) 而不是词形还原,spaCy 默认不提供词干提取功能。你可以使用 nltk 的 PorterStemmer 或其他 stemming 算法,而不是使用 spaCy 的词形还原器。
2. spaCy 的处理管道更复杂
spaCy的 NLP 管道包含多个步骤,如 词性标注、依存分析、命名实体识别 等,尽管在你的情况下已经禁用了某些组件,但即使只进行词形还原,spaCy仍然会进行一系列复杂的处理,比如句法解析和上下文分析,这使得其在处理单个文本时更耗时。- 相比之下,
nltk的词干提取器直接在字符串级别操作,跳过了大量复杂的 NLP 处理步骤,因此速度快。
3. 词形还原复杂度高
- 词形还原不仅依赖于单词,还依赖于上下文和词性等信息,因此需要更复杂的模型支持。这意味着即便是并行化计算,每次处理的文本依然需要更多的时间来解析单词的上下文、词法和词性。
nltk的PorterStemmer或SnowballStemmer算法则不关心上下文,只是单纯地按照规则截取词干,因此速度要快得多。
4. 多进程的开销
- 在并行计算时,进程间通信和内存共享的开销可能抵消了一部分
spaCy的并行化优势。特别是spaCy的内部管道相对复杂,数据在多个进程之间的传递和处理可能比nltk的简单操作耗费更多资源。 - 并行化并不总是能带来线性速度提升,在处理较短或较简单的任务时,启动多个进程所带来的开销可能会导致整体性能下降。
5. 模型加载和内存管理
spaCy加载模型(如en_core_web_sm)时会占用更多内存,并且会涉及更多的依赖和上下文处理。即便使用了批处理和并行处理,模型加载和保持内存的开销也可能比nltk更大。- 如果你需要处理的大部分任务只是简单的词干提取,那么
spaCy的这种复杂模型加载带来的性能优势可能无法显现,反而可能增加处理时间。
总结:
spaCy的词形还原 相比nltk的词干提取 更为复杂,因此速度较慢。这是因为spaCy是一个更为强大、复杂的 NLP 工具,适合于上下文敏感的任务,如依存解析和实体识别。- 如果任务是简单的词干提取,
nltk更适合。spaCy更适合需要复杂语法分析和上下文依赖的场景。 - 若不需要复杂的词形还原,可以直接使用
nltk的PorterStemmer或者SnowballStemmer,速度会快得多。
使用并行计算缩短移除停用词的时间
我kaggle的V5版本
时间从1min14s缩短为42s,减少了近一倍
原来的时间:
CPU times: user 1min 13s, sys: 26.2 ms, total: 1min 13s
Wall time: 1min 14s
现在的时间:
CPU times: user 5.18 s, sys: 162 ms, total: 5.34 s
Wall time: 42 s
原来的代码:
#set stopwords to english
stop=set(stopwords.words('english'))
print(stop)
#removing the stopwords
def remove_stopwords(text, is_lower_case=False):
tokens = tokenizer.tokenize(text)
tokens = [token.strip() for token in tokens]
if is_lower_case:
filtered_tokens = [token for token in tokens if token not in stopword_list]
else:
filtered_tokens = [token for token in tokens if token.lower() not in stopword_list]
filtered_text = ' '.join(filtered_tokens)
return filtered_text
#Apply function on review column
imdb_data['review']=imdb_data['review'].apply(remove_stopwords)
现在的代码:
%%time
import multiprocessing
# 设置停用词为英文
stop = set(stopwords.words('english'))
# 去除停用词的函数
def remove_stopwords(text, is_lower_case=False):
tokens = word_tokenize(text) # 使用 word_tokenize 分词
tokens = [token.strip() for token in tokens]
if is_lower_case:
filtered_tokens = [token for token in tokens if token not in stop]
else:
filtered_tokens = [token for token in tokens if token.lower() not in stop]
filtered_text = ' '.join(filtered_tokens)
return filtered_text
# 并行化处理每一条评论
def parallel_apply(data, func, n_jobs=-1):
return Parallel(n_jobs=n_jobs)(delayed(func)(text) for text in data)
# 将评论数据并行化处理
imdb_data['review'] = parallel_apply(imdb_data['review'], remove_stopwords, n_jobs=multiprocessing.cpu_count())
多个模型结果对比
我kaggle的V5版本
逻辑回归模型(Logistic Regression)下面简称:LR
线性支持向量机(SVM)模型下面简称:LSVM
多项式朴素贝叶斯(Multinomial Naive Bayes)模型下面简称:MNB
在特征提取方面,因为TF-IDF模型一般来说会优于BoW模型,所以下面的分析和后面的优化,为了简便起见,均采用TF-IDF模型的结果。
训练时间
LR:28s
LSVM:3s
MNB:2s
准确率(Accuracy)
LR:0.75
LSVM:0.51
MNB:0.75
分类报告
LR:各项指标均为0.75
LSVM:各项指标差别较大
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| Positive | 1.00 | 0.02 | 0.04 | 4993 |
| Negative | 0.51 | 1.00 | 0.67 | 5007 |
| accuracy | 0.51 | 10000 | ||
| macro avg | 0.75 | 0.51 | 0.36 | 10000 |
| weighted avg | 0.75 | 0.51 | 0.36 | 10000 |
MNB:各项指标均为0.75
混淆矩阵(Confusion matrix)
LR:
[[3662 1345]
[1156 3837]]
LSVM:
[[5007 0]
[4888 105]]
MNB:
[[3727 1280]
[1213 3780]]
为什么LR的训练时间远大于LSVM和MNB?
在这三种模型中,逻辑回归(LR) 训练时间最长,线性支持向量机(LSVM) 训练时间居中,而 多项式朴素贝叶斯(MNB) 训练时间最短。造成这些模型训练时间差异的原因可以从算法复杂性、优化方法和模型假设等方面进行解释:
1. 逻辑回归(LR):
-
训练时间:28秒
-
算法特性:
- 逻辑回归是基于最大似然估计的分类算法,它通过梯度下降或其他优化算法(如
liblinear,lbfgs等)来最小化损失函数。这个过程通常需要多次迭代来调整模型的权重,直到找到一个收敛的解。 - 当数据量大、特征维度高时,梯度下降的收敛可能需要较多的迭代次数,尤其是在模型收敛较慢时,因此训练时间较长。
- 正则化:如果你在逻辑回归中使用了正则化(如 L1 或 L2),这会进一步增加训练复杂度。
- 逻辑回归是基于最大似然估计的分类算法,它通过梯度下降或其他优化算法(如
-
时间较长的原因:
- 逻辑回归需要不断调整权重参数并最小化损失函数,可能需要较多次迭代才能收敛。
- 梯度下降的迭代次数可能较多,尤其在高维数据上,训练时间会进一步增加。
2. 线性支持向量机(LSVM):
-
训练时间:3秒
-
算法特性:
- 线性 SVM 通过寻找最大间隔的超平面来进行分类任务。LSVM 使用的优化方法(如
liblinear)能够快速处理线性问题。 - LSVM 的优化过程往往比逻辑回归更高效,尤其是在数据线性可分的情况下,训练速度会更快,因为不需要过多的迭代就能找到最优解。
- 稀疏性:SVM 由于其最大化分类间隔的特性,在许多情况下只依赖少量的支持向量,进一步加快了训练过程。
- 线性 SVM 通过寻找最大间隔的超平面来进行分类任务。LSVM 使用的优化方法(如
-
时间较短的原因:
- LSVM 在处理线性可分的数据时,通常收敛较快。
- 使用
liblinear优化器能够在高维稀疏特征空间中更高效地找到解。 - 对比逻辑回归,LSVM 的损失函数使得其参数调整更迅速。
3. 多项式朴素贝叶斯(MNB):
-
训练时间:2秒
-
算法特性:
- 朴素贝叶斯是一种基于简单概率假设的分类算法。多项式朴素贝叶斯特别适用于离散型数据(如词频表示的文本数据),它假设特征之间相互独立。
- MNB 的训练过程非常快速,因为它不需要复杂的迭代优化过程。模型训练只是基于统计推导,计算每个类别的条件概率分布。
- 无迭代优化:与逻辑回归和 SVM 不同,MNB 并不需要调整权重或寻找最优超平面。训练过程只是对特征出现频率进行简单统计。
-
时间最短的原因:
- MNB 不需要迭代优化,只需对数据进行一次扫描来计算条件概率。
- 由于假设了特征之间的独立性,MNB 训练时的计算复杂度远低于逻辑回归和 SVM。
总结:
- 逻辑回归(LR) 训练时间最长,因为它需要进行多次迭代的优化,尤其在高维特征下,收敛速度可能较慢。
- 线性 SVM(LSVM) 训练时间较短,虽然它也需要优化,但由于线性问题的特性和
liblinear优化器的效率,LSVM 能够更快速地找到解。 - 多项式朴素贝叶斯(MNB) 训练时间最短,因为它不需要进行迭代优化,直接通过计算条件概率完成训练。
主要差异点在于:
- 逻辑回归和线性 SVM 都需要通过迭代优化来调整模型参数,而多项式朴素贝叶斯只需进行一次简单的统计计算。
- LSVM 通常在高维稀疏特征空间中具有更高的优化效率,而逻辑回归的优化过程较慢,尤其在数据量较大时。
为什么LSVM在准确率上的表现不如LR和MNB?
原因:
-
数据线性不可分:线性 SVM 假设数据是线性可分的,如果数据本质上不是线性可分的(即类别之间没有一个清晰的线性超平面),SVM 的表现可能不佳。在这种情况下,逻辑回归通过概率模型,可能会比 SVM 更好地找到分类边界。
-
文本数据的特性:文本数据通常是高维稀疏的,这对于 SVM 来说并不总是最理想的。朴素贝叶斯和逻辑回归都能很好地处理这种稀疏特征。朴素贝叶斯通过条件概率计算能快速分类,而逻辑回归通过概率模型能适应更多样的数据分布。
-
噪声的影响:SVM 对噪声较为敏感,尤其是在边界模糊的情况下,噪声点会对 SVM 产生较大影响,导致模型性能下降。而逻辑回归和朴素贝叶斯在面对噪声数据时,鲁棒性更强。
总结:
- 逻辑回归(LR) 和 多项式朴素贝叶斯(MNB) 的准确率都为 0.75,这是因为这两种模型都能较好地处理文本数据的高维稀疏特征,并且具有较强的鲁棒性。
- 线性支持向量机(LSVM) 的准确率较低(0.51),可能是由于数据线性不可分或数据噪声较多,SVM 无法找到一个有效的线性分类边界,因此表现不佳。
为什么LSVM在分类报告上的结果较差?
LSVM 在 Positive 类别上的表现非常差,而在 Negative 类别上表现较好。各项指标之间的差异较大,特别是 precision 和 recall 之间的显著不平衡。以下是对这一现象的可能解释:
1. 类不平衡问题
- 尽管支持的样本数(
support)在正负类别上几乎是均衡的(4993 vs 5007),但 LSVM 的 recall(召回率)在 Positive 类别上非常低,只有 0.02,而在 Negative 类别上则达到 1.0。 - 这可能是因为模型在训练过程中未能正确识别出正类(Positive),大多数正类样本被错误分类为负类(Negative)。
2. 线性可分性问题
- SVM 是基于最大化分类间隔的分类器,它假设数据是线性可分的。在这种情况下,如果正负类别之间的分界线并不是简单的线性分界,线性 SVM 可能无法找到一个合适的决策边界来区分这两个类别。
- 如果数据的分布较复杂,或者类别之间的边界不清晰,SVM 的决策平面可能无法有效分割正类和负类,导致模型在正类上的召回率极低。
3. 偏差问题:
- 高精度低召回:在正类上,precision(精确率)为 1.00,说明当模型预测为正类时,几乎都是正确的(没有假阳性)。但 recall(召回率)仅为 0.02,这表明模型实际上几乎无法识别出正类样本,模型几乎将所有正类样本错误分类为负类。
解决方案建议:
-
使用非线性 SVM:考虑使用非线性核函数(如 RBF 核)进行分类,这可能比线性核更适合处理复杂的文本数据分布。
-
调整
class_weight:在 SVM 中使用class_weight='balanced',自动根据类别的频率调整分类权重,或手动指定权重来平衡正负类的预测能力。from sklearn.svm import LinearSVC model = LinearSVC(class_weight='balanced') model.fit(X_train, y_train) -
重新采样数据:如果类别分布严重不平衡,可以尝试通过过采样(如 SMOTE)或欠采样来平衡数据集中的类别。
-
调整正则化参数
C:SVM 中的正则化参数C控制决策边界的软硬度。适当调整该参数可以让模型在训练时更好地找到适合的分类边界。
总结:
- LSVM 模型的正负类表现差异大,主要是由于 线性不可分性 和 模型偏向负类 的问题。正类的召回率极低意味着模型几乎忽略了正类样本,而只关注负类样本,这可能是由于不合理的决策边界或没有平衡类别权重所导致的。
- 逻辑回归(LR)和多项式朴素贝叶斯(MNB)在处理这类文本分类任务时表现较好,因为它们在处理高维稀疏数据方面更加鲁棒,并且能够更好地适应复杂的数据分布。
为什么LSVM在混淆矩阵上的结果较差?
-
混淆矩阵:
[[5007 0] [4888 105]] -
解释:
- 5007:模型正确地将 5007 个负类样本分类为负类(True Negative),即模型几乎将所有负类样本都分类正确。
- 0:模型完全没有正确识别出任何正类样本(True Positive)。
- 4888:模型将 4888 个正类样本错误地分类为负类(False Negative)。
- 105:模型仅将 105 个负类样本错误分类为正类(False Positive)。
原因和解决方案和上面分类报告的分析相同。
优化TFIDF的参数大幅提升了准确率
我kaggle的V6版本,准确率大幅提升到0.9
说明
从初始版本来看,词袋模型和TFIDF模型的效果差不多,准确率都为0.75,但是从进一步优化的潜力来看,TFIDF明显优于词袋模型。所以从这个版本开始,也就是版本6开始,我删除了词袋模型,特征工程只用TFIDF,来继续优化模型。
只修改了一行代码
# 原来的代码
tv=TfidfVectorizer(min_df=0,max_df=1,use_idf=True,ngram_range=(1,3))
# 修改参数后的代码
tv=TfidfVectorizer(min_df=2, max_df=0.5, ngram_range=(1,2))
对LR和MNB模型的影响
准确率
LR从0.75提高到0.9
MNB从0.75提高到0.89
分类报告各项指标和混淆矩阵也都得到了相应的优化
对LSVM模型的影响
准确率也提高到了0.9,分类报告各项指标和混淆矩阵也都得到了彻底修复和相应的优化,和另外两个模型没有什么差别了,修复了上一个版本实际上几乎无法识别出正类样本的严重问题。
优化TFIDF的参数大幅提升了准确率的原因分析
修改了 TfidfVectorizer 的两个重要参数——min_df 和 max_df,这对特征选择和模型性能有很大的影响。通过这两个参数的调整,模型的特征向量表示发生了显著变化,从而提升了分类性能。以下是对每个修改的详细解释及其对模型性能的潜在影响:
1. min_df 参数的修改:
-
原代码:
min_df=0min_df=0表示包括所有在文档中至少出现过一次的单词,即使它只在一个文档中出现。这样做会引入很多非常稀有的单词(低频词),这些单词通常是噪音,因为它们对模型的泛化能力几乎没有贡献,反而会增加模型复杂性和过拟合风险。
-
修改后的代码:
min_df=2min_df=2表示单词至少要在 2 个文档中出现才会被纳入特征。这有效地过滤掉了极少出现的词语,从而减少了噪音。低频词往往对分类任务贡献较小,移除它们可以帮助模型更关注更具代表性的词,从而提升分类效果。
-
影响:
- 通过增加
min_df,减少了模型中包含的特征数量,降低了模型的复杂度和过拟合的风险。这使得模型能够更专注于常见的、有用的特征,避免被稀有词语的噪声干扰。 - 此外,去除了低频词有助于 LSVM 这种敏感于噪声的模型表现更好,因为它不再需要处理大量无意义的稀疏特征。
- 通过增加
2. max_df 参数的修改:
-
原代码:
max_df=1max_df=1表示包括所有单词,不论它们在多少文档中出现。即使一个单词出现在所有文档中(如非常常见的停用词 “the”, “is”, “and”),这些高频词也会被包括在内。然而,这些非常常见的词往往对分类任务的贡献非常小,因为它们不能有效地区分不同类别的文本。
-
修改后的代码:
max_df=0.5max_df=0.5表示排除在超过 50% 的文档中出现的词。这意味着那些非常常见的词语(如常见的停用词)不会被纳入特征向量。这种做法避免了模型将注意力集中在对分类没有帮助的常见词上,使得模型更加专注于区分性更强的特征。
-
影响:
- 通过排除这些在大部分文档中出现的常见词,模型变得更关注具有区分性的词汇。常见词的去除不仅减少了无效的特征,还使模型能够更好地区分类别,尤其是对于 LR 和 MNB 这类依赖词频和词语分布的模型,去除高频无效词可以显著提升模型性能。
- 对于 LSVM,去除高频词也有助于模型更容易找到有效的决策边界,因为它不会被冗余的特征影响。
3. ngram_range 参数的修改:
-
原代码:
ngram_range=(1, 3)- 使用 1-gram 到 3-gram 生成特征,这意味着单词的组合(如 “good movie”, “not very good movie”)也会被作为特征。虽然更大的
ngram范围可以捕捉到更多的上下文信息,但会导致特征数量爆炸性增长,尤其在小数据集上,这可能增加过拟合的风险。
- 使用 1-gram 到 3-gram 生成特征,这意味着单词的组合(如 “good movie”, “not very good movie”)也会被作为特征。虽然更大的
-
修改后的代码:
ngram_range=(1, 2)- 使用 1-gram 和 2-gram 限制了特征的数量,减少了数据的稀疏性。2-gram 能够捕捉到一些常见的词组搭配,同时避免了生成过多冗余的 3-gram 特征。
-
影响:
- 限制
ngram_range后,减少了不必要的特征数量,降低了过拟合的风险。尤其对于 LSVM,减少特征维度有助于找到更清晰的决策边界。而对于 LR 和 MNB,减少特征稀疏性可以使模型更加高效。
- 限制
总结三个参数的修改对模型的影响:
- 去除低频词(
min_df=2) 减少了无用或噪声特征,使模型更加稳健,尤其对 LSVM 和 MNB 这种容易受到稀疏特征影响的模型尤为重要。 - 去除高频词(
max_df=0.5) 使模型专注于更具区分性的特征,这对 LR 和 MNB 非常有用,因为它们依赖于词语的分布信息。对于 LSVM,去除高频词可以减少冗余信息的干扰。 - 减少 n-gram 范围(
ngram_range=(1,2)) 控制了特征空间的规模,避免了过多无效特征带来的计算开销和过拟合风险。适度的 n-gram 能捕捉到上下文信息而不过度稀释数据。
为什么 LSVM 的正类样本识别问题也修复了?
-
低频和高频词的去除 大大减少了无关紧要的噪声特征,使得 LSVM 能够更好地专注于有效特征,从而修复了之前无法识别正类样本的问题。过多的稀疏特征使得 LSVM 无法在有限的数据中找到有效的分类边界。通过减少稀疏性,模型变得更加鲁棒。
-
之前的配置(
min_df=0, max_df=1)会导致大量无用的特征被纳入,这些特征可能会给模型带来干扰,使得模型过拟合某些无关特征,而忽视了真正有用的特征。现在去除了低频词和高频词,模型更好地学习到了有效的区分特征,从而提升了正类样本的识别能力。
总结:
修改 min_df、max_df 和 ngram_range 后,大幅减少了特征中的噪音和冗余信息,使得模型更加专注于有用的区分特征。这一优化提升了所有模型的性能,尤其是之前 LSVM 无法识别正类样本的问题也得到了修复。
结尾:如何进一步提升准确率?
我尝试了进一步手动优化TFIDF的参数,比如将min_df从2改为3,max_df从0.5改为0.4,但是效果差不多,没有怎么提升。
这是我的第一个AI项目,已经达到了我想要的学习目的和实践效果,所以下面的这些可能的优化思路和方向,由于可能要花费更多的时间以及需要更多的知识技能储备,已经超过了对入门者的要求,我打算在以后更合适的项目中再尝试,毕竟杀鸡焉用牛刀,这个项目就到此为止了,后面等我学到了更多的技能和知识后,并且有时间的话,可能会考虑再顺便优化一下。
为了进一步提升准确率,你可以从以下几个方面入手,包括优化特征工程、模型调优、数据扩充、集成学习等。以下是具体的方法和策略:
1. 进一步优化特征工程
-
调整 n-gram 范围:
- 你已经将
ngram_range设置为(1, 2)。你可以尝试调整这个范围来捕捉更复杂的词组结构。例如,尝试(1, 3)或(2, 3)来捕捉更多长词组。 - 需要注意的是,过大的
ngram范围可能会导致特征空间维度爆炸,需要平衡计算复杂度和准确率。
- 你已经将
-
词形还原(Lemmatization)和词干提取(Stemming):
- 使用词形还原可以减少词语的不同形式之间的冗余,例如将 “running” 和 “ran” 归一化为 “run”。
- spaCy 提供了强大的词形还原工具,而 nltk 提供了词干提取工具。可以根据你的需求选择。
- 示例:
import spacy nlp = spacy.load('en_core_web_sm') def lemmatize_text(text): doc = nlp(text) return ' '.join([token.lemma_ for token in doc if not token.is_punct]) imdb_data['review'] = imdb_data['review'].apply(lemmatize_text)
-
处理停用词:
- 你可以通过试验来决定是否保留停用词。某些情况下,停用词的删除可能导致丢失关键信息,因此可以尝试保留部分停用词,或者只删除那些常见但无关的词汇。
-
特征选择:
- 使用特征选择方法(如 卡方检验(chi-square) 或 互信息(Mutual Information))来选择最有区分度的特征,减少无效特征对模型的干扰。
- 示例:
from sklearn.feature_selection import SelectKBest, chi2 X_new = SelectKBest(chi2, k=10000).fit_transform(X_train, y_train)
2. 调优超参数
-
网格搜索或随机搜索超参数调优:
- 可以使用 GridSearchCV 或 RandomizedSearchCV 来优化模型的超参数。对于逻辑回归和多项式朴素贝叶斯模型,超参数调优可以显著提升准确率。
- 对于逻辑回归,调整正则化参数
C和正则化方式(L1 或 L2)。对于多项式朴素贝叶斯,调节alpha平滑参数。 - 示例:
from sklearn.model_selection import GridSearchCV from sklearn.linear_model import LogisticRegression param_grid = {'C': [0.1, 1, 10], 'penalty': ['l2']} grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5) grid_search.fit(X_train, y_train) print(grid_search.best_params_)
-
正则化:
- 尤其是在高维文本特征中,适当的正则化可以防止过拟合。对于 逻辑回归 和 SVM,可以使用 L1 或 L2 正则化。对于 L1 正则化,还可以让模型更稀疏,从而保留最重要的特征。
3. 使用预训练的词向量或深度学习模型
-
Word2Vec, GloVe, FastText:
- 使用预训练的词向量模型(如 Word2Vec、GloVe 或 FastText)来生成更丰富的文本表示,这些预训练模型能捕捉词汇的语义信息,尤其适用于小数据集的任务。
- 示例(使用 GloVe):
from gensim.models import KeyedVectors word_vectors = KeyedVectors.load_word2vec_format('path_to_glove_model.txt', binary=False)
-
BERT, GPT 等 Transformer 模型:
- BERT 等基于 Transformer 的预训练模型可以捕捉到更复杂的文本上下文关系,使用 BERT 或 GPT 可以显著提升文本分类任务的性能。
- Hugging Face 提供了简单的接口来使用预训练的 BERT 模型进行文本分类。
- 示例(使用 Hugging Face 的 BERT 模型):
from transformers import BertTokenizer, BertForSequenceClassification from transformers import Trainer, TrainingArguments tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
4. 模型集成:
-
集成学习:通过集成多个模型可以提升分类性能。常见的集成方法包括:
- 投票法(Voting Classifier):结合多个分类器的预测结果,采用多数投票作为最终结果。
- 堆叠法(Stacking):将多个模型的输出作为新的输入,训练一个更复杂的元学习器。
-
示例:
from sklearn.ensemble import VotingClassifier from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import MultinomialNB from sklearn.svm import SVC clf1 = LogisticRegression() clf2 = MultinomialNB() clf3 = SVC(probability=True) ensemble = VotingClassifier(estimators=[('lr', clf1), ('mnb', clf2), ('svc', clf3)], voting='soft') ensemble.fit(X_train, y_train)
5. 增强数据集(Data Augmentation)
-
数据扩充:
- 在分类任务中,更多的数据通常能帮助模型学习更好的决策边界。如果获取额外数据困难,可以使用数据扩充技术,例如同义词替换、翻译增强(back-translation)等,来生成更多训练样本。
- 翻译增强示例:
- 使用 Google Translate 将文本翻译为其他语言再翻译回原语言,可以生成新的样本。
- 例如,将英语文本翻译为法语,再翻译回英语,创造更多的样本变体。
-
平衡数据集:
- 如果你的数据集存在类别不平衡问题(即某个类别的样本远多于其他类别),可以通过 过采样(如 SMOTE) 或 欠采样 来平衡数据集。类别不平衡会导致模型偏向于预测多数类,进而影响分类性能。
6. 处理类别不平衡问题
-
调整
class_weight:- 对于逻辑回归、SVM 等模型,你可以通过设置
class_weight='balanced'来平衡类别权重,使得模型对少数类样本更加敏感。 - 示例:
from sklearn.linear_model import LogisticRegression model = LogisticRegression(class_weight='balanced') model.fit(X_train, y_train)
- 对于逻辑回归、SVM 等模型,你可以通过设置
-
重新采样:如前文所述,可以使用 SMOTE 或其他方法来平衡类别样本。
7. 进一步错误分析
- 分析错误样本:
- 仔细分析哪些样本被错误分类,并识别常见的误分类模式。你可以根据分析的结果决定是否需要修改特征工程、增加数据或调整模型架构。例如,某些错误可能是由于模型未能捕捉到某些关键的特征或上下文,可以通过调整特征表示来解决。
总结:
提升准确率可以通过多个途径同时进行:
- 特征工程优化:例如调整
ngram范围、使用词形还原、使用 TF-IDF 等。 - 超参数调优:通过网格搜索找到最佳模型参数。
- 使用更复杂的模型:如 BERT、GPT 等预训练语言模型。
- 模型集成:结合多个分类器提升性能。
- 增加数据或使用数据增强:特别是通过平衡类别数据解决类别不平衡问题。
- 深入的错误分析:根据误分类样本进一步调整模型。
通过这些方法,你可以逐步提升模型的分类性能,最终可能达到甚至超过 0.9 的准确率。