文章目录
- 链接: [原文章链接](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&tempkey=MTI4Nl8zM3FHVFU1NDRDL0p2SkplRTVidmhiNmh1ZWF3YXkwY3VYZlZNaWx0MXowdThFbVRUVEFEdEs5YlU2SUJLcmtXTHZpbnFmR2V6SG1rbGJyd01zYnRkdURWa1ZvNGtIU1piWDd5RFA4OUxkNmlaVmZ1QVpEd2tWR25IR1NLdzZRZF9zRWtabHhtendoQ2h5ZEo2WTlFczRfUkcyejZwbm0tM3hRdVlRfn4%3D&chksm=c2a06c00f5d7e51601e3fda8e6cf5b92d57101ba67f3aa7384a48fb4309b81f2f467921985ef&token=1472707715&lang=zh_CN#rd)
- 1、pandas简介
- 2、Series使用
- 3、iloc访问机制
- 4、DateFrame使用
- 5、Pandas CSV
- 6、Pandas 数据清洗
链接: 原文章链接
感兴趣的可以关注一下公众号,会第一时间给您推送更多精彩的内容,欢迎大家前来指正,欢迎欢迎~~

1、pandas简介
Pandas(Panel Data的缩写)是一个开源的Python数据处理库,它提供了高性能、易用的数据结构和数据分析工具,用于处理和分析结构化数据。
Pandas的核心数据结构是DataFrame和Series,它们使数据的清理、转换、分析和可视化变得非常便捷。
2、Series使用
2.1、Series是一种类似一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的标签组成。这些标签通常是索引,用于对数据进行分类和定位。而Pandas库是基于NumPy构建的,专门用于处理表格和混杂数据,与NumPy不同,它更适合处理带有复杂标签的数据。类似于字典
import numpy as np
from pandas import Series
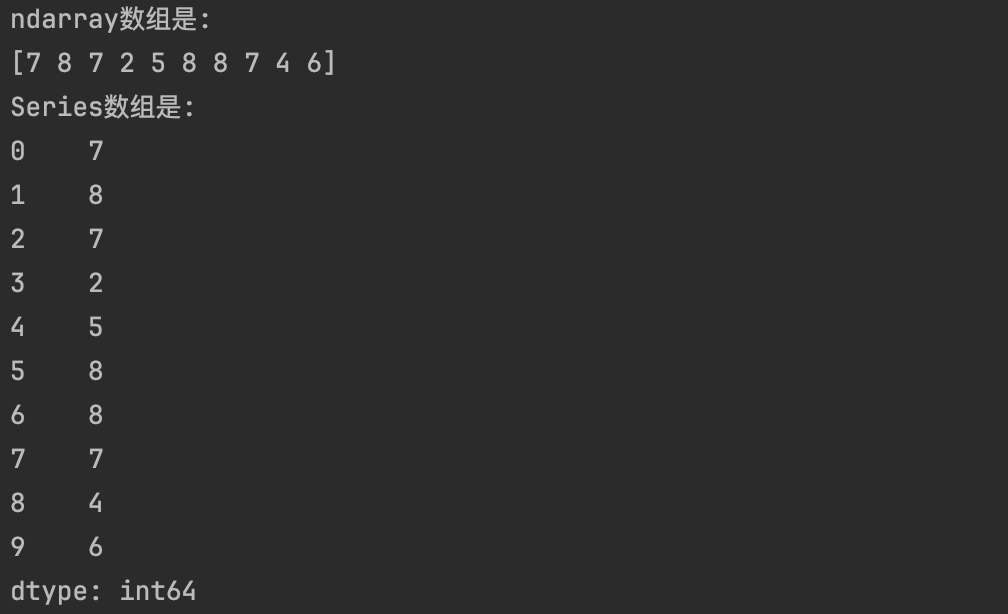
data1=np.random.randint(1,10,size=10)
print("ndarray数组是:")
print(data1)
data2=Series(data1)
print("Series数组是:")
print(data2)
2.2、创建出来的Series对象默认会有一个索引。如果你不想使用默认的索引(隐式索引),可以在创建Series对象时通过index参数指定自定义的索引(显示索引),用于分类或标记数据,numpy数组索引主要用来访问数组中的元素,但它并不提供额外的元数据或分类功能
data = [1, 2, 3, 4, 5]
index = ['a', 'b', 'c', 'd', 'e']
series = pd.Series(data, index=index)
print(series['a']) # 输出:1
print(series['c']) # 输出:3
2.3、 使用列表或数组创建,创建的Series数组则是副本,改变其中一个不会影响另一个。
import pandas as pd
data = [1, 2, 3, 4, 5]
series = pd.Series(data)
2.4、使用numpy创建出来的Series数组不是副本。这意味着当你改变原来的numpy数组时,Series也会跟着改变
import pandas as pd
import numpy as np
data = np.array([1, 2, 3, 4, 5])
series = pd.Series(data)
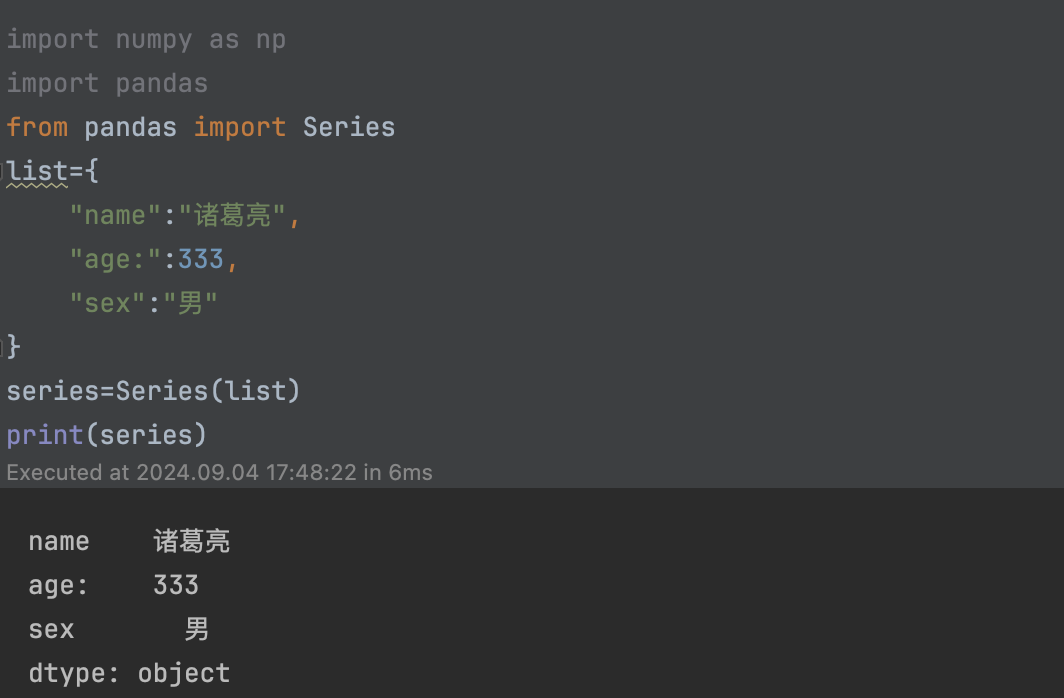
2.5、使用字典创建的Series对象也不是副本,而是与字典共享数据。因此,如果你修改了原始字典中的数据,那么对应的Series对象也会跟着改变。字典的键作为索引,值作为数据
import numpy as np
import pandas
from pandas import Series
list={
"name":"诸葛亮",
"age:":333,
"sex":"男"
}
series=Series(list)
print(series)
3、iloc访问机制
配合隐式的索引,官方推荐的访问机制
import numpy as np
import pandas
from pandas import Series
s1=Series(np.random.randint(1,10,size=5,),index=["A","B","C","D","E"])#用arrary创建一个Series数组
print(s1)
print(s1.iloc[[0,1]])
配合显式的索引,官方推荐的访问机制
import numpy as np
import pandas
from pandas import Series
s1=Series(np.random.randint(1,10,size=5,),index=["A","B","C","D","E"])#用arrary创建一个Series数组
print(s1)
print(s1.loc["A"])
4、DateFrame使用
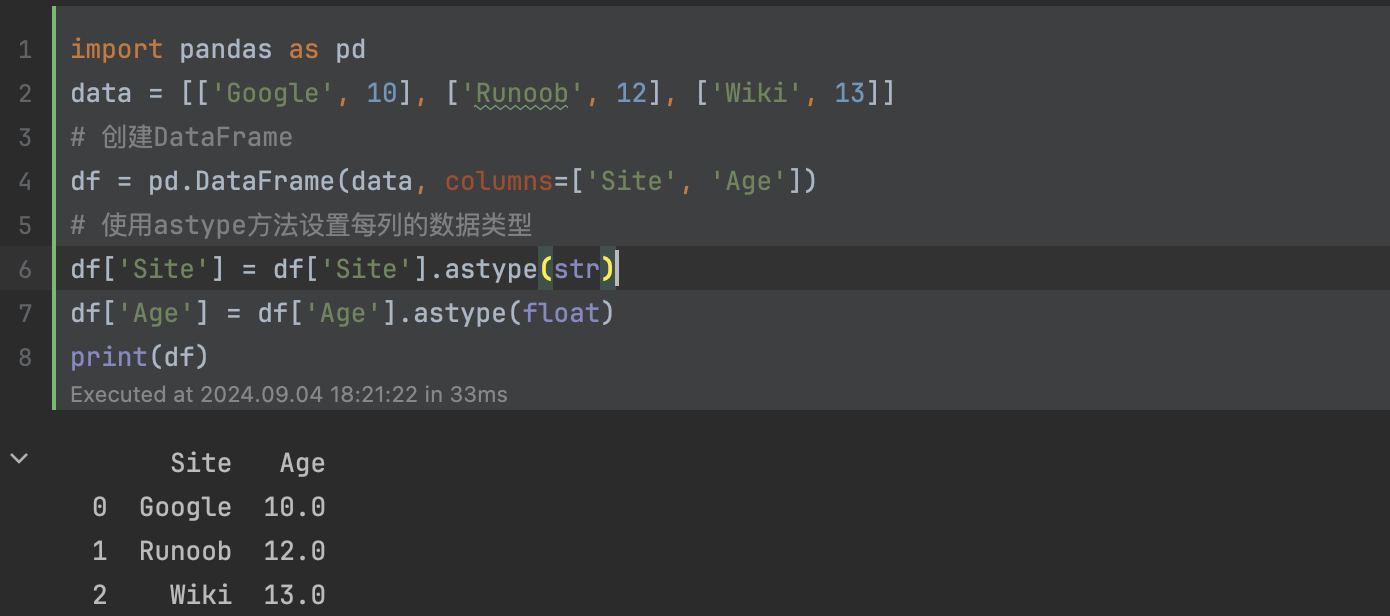
4.1、DataFrame是一个类似于二维数组或表格(如Excel表格)的对象 ,它的每列数据可以是不同的数据类型,与Series的结构相似,DataFrame也是由索引和数据组成的,不同的是,DataFrame的索引不仅有行索引,还有列索引 。
import pandas as pd
data = [['Google', 10], ['Runoob', 12], ['Wiki', 13]]
# 创建DataFrame
df = pd.DataFrame(data, columns=['Site', 'Age'])
# 使用astype方法设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)
print(df)
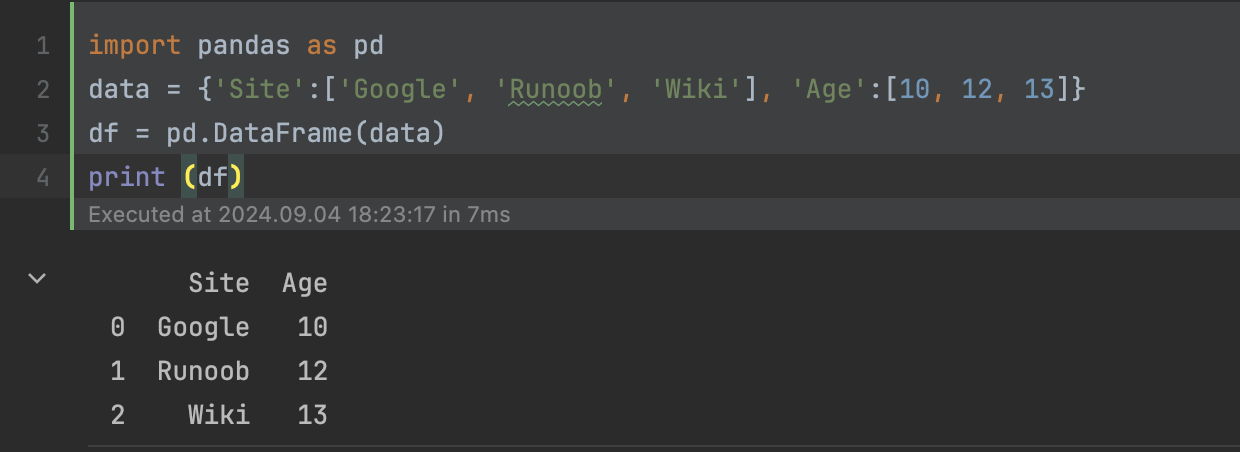
4.2、使用字典来创建
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
4.3、使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度
import numpy as np
import pandas as pd
# 创建一个包含网站和年龄的二维ndarray
ndarray_data = np.array([
['Google', 10],
['Runoob', 12],
['Wiki', 13]
])
# 使用DataFrame构造函数创建数据帧
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])
# 打印数据帧
print(df)

4.4、可以使用字典(key/value),其中字典的 key 为列名,没有对应的部分数据为 NaN。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
4.5、DataFrame 的属性和方法
# 从 Series 创建 DataFrame
s1 = pd.Series(['Alice', 'Bob', 'Charlie'])
s2 = pd.Series([25, 30, 35])
s3 = pd.Series(['New York', 'Los Angeles', 'Chicago'])
df = pd.DataFrame({'Name': s1, 'Age': s2, 'City': s3})
# DataFrame 的属性和方法
print(df.shape) # 形状
print(df.columns) # 列名
print(df.index) # 索引
print(df.head()) # 前几行数据,默认是前 5 行
print(df.tail()) # 后几行数据,默认是后 5 行
print(df.info()) # 数据信息
print(df.describe())# 描述统计信息
print(df.mean()) # 求平均值
print(df.sum()) # 求和
访问列:使用列名作为属性或通过 .loc[]、.iloc[] 访问,也可以使用标签或位置索引
# 通过列名访问
print(df['Column1'])
# 通过属性访问
print(df.Name)
# 通过 .loc[] 访问
print(df.loc[:, 'Column1'])
# 通过 .iloc[] 访问
print(df.iloc[:, 0]) # 假设 'Column1' 是第一列
# 访问单个元素
print(df['Name'][0])
5、Pandas CSV
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
5.1、to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
5.2、to_csv() 方法将 DataFrame 存储为 csv 文件
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
6、Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
上表包含了四种空数据:
n/a
NA
—
na
6.1、Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
6.2、isnull() 判断各个单元格是否为空
import pandas as pd
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
6.3、可以指定空数据类型
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
6.6、删除包含空数据的行
import pandas as pd
df = pd.read_csv('property-data.csv')
# dropna() 方法返回一个新的 DataFrame,不会修改源数据。
# 如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数:
new_df = df.dropna()
print(new_df.to_string())
6.6、可以移除指定列有空值的行
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
6.5、fillna() 方法来替换一些空字段
import pandas as pd
df = pd.read_csv('property-data.csv')
df.fillna(12345, inplace = True)
print(df.to_string())
清洗数据
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())

将 age 大于 120 的设置为 120
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())

将错误数据的行删除
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())













![[python]socket之网络编程基础知识](https://i-blog.csdnimg.cn/direct/e5d6dcb002bf40b9a90afa7bca920432.png#pic_center)