目录
一.堆(Heap)的基本介绍
二.堆的常用操作(以小根堆为例)
三.实现代码
3.1 堆结构定义
3.2 向下调整算法*
3.3 初始化堆*
3.4 销毁堆
3.4 向上调整算法*
3.5 插入数据
3.6 删除数据
3.7 返回堆顶数据
四.下篇内容
1.堆排序
2.TopK问题
一.堆(Heap)的基本介绍
了解堆之前我们要简单了解完全二叉树:
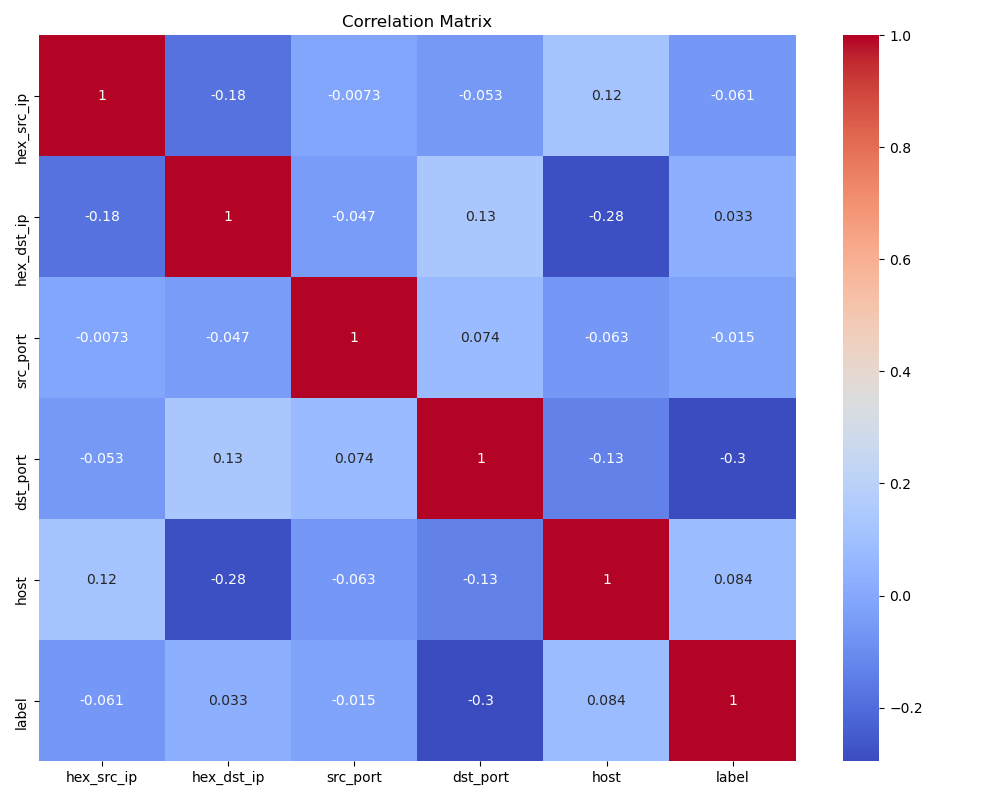
在二叉树中,我们使用指针来连接每一个结点,最后构成一颗二叉树。而堆是一种使用数组来表示完全二叉树。其满足以下两条规则。
1.堆中结点值总是大于或者小于其父结点的值。
2.堆总是一颗完全二叉树。
由此可以推出有两种堆:大根堆和小根堆。
大根堆:根节点的值最大。
小根堆:根节点的值最小。

在堆(二叉树)中,如果一个结点的下标为i
其父亲的结点的下标为 (i-1)/ 2
其左孩子结点的下标为 (i+1)*2 -1 即 i*2 +1
其右孩子结点的下标为 (i+1)*2 即 i*2 + 2
数组的下标由0开始,读者可根据下图进行理解

二.堆的常用操作(以小根堆为例)
//初始化堆
void HeapInit(Heap* php, DataType* arr, int n);
//数组建堆主要依赖的算法(这个算法要求数组的左右子树都是小堆)
//小堆,使用向下调整算法
void Adjustdown(DataType* arr, int n, int root);
//向上调整算法
void Adjustup(DataType* arr, int n, int root);
//销毁堆
void HeapDestory(Heap* php);
//插入数据
void HeapPush(Heap* php, DataType x);
//删除数据
void HeapPop(Heap* php, DataType x);
//求堆顶(根)数据
DataType HeadTop(Heap* php);
//交换两个数据
void swap(DataType* p1, DataType* p2);三.实现代码
3.1 堆结构定义
//以小根堆为例
typedef int DataType;
typedef struct Heap
{
DataType* arr; //数组
int capacity; //容量
int size; //元素大小
}Heap;
3.2 向下调整算法*
小根堆使用该算法的前提是左右子树都为小根堆,大根堆的前提是左右子树都为大根堆
该算法是从根结点依次向下找到比自己小(或者大)的结点,然后进行交换。
最后就能将新插入的根节点放到相应的位置
调整规则:
小根堆:根节点每一次与孩子结点中较小的一个交换
大根堆:根节点每一次与孩子结点中较大的一个交换
如下图

代码如下(以小根堆为例)
//向下调整算法
void AdjustDwon(DataType* arr, int n, int root)
{
//1.小根堆,找出左右孩子中较小的结点
int parent = root;
int child = root * 2 + 1; //表示左孩子
while (child < n)
{
//找到右孩子,如果右孩子比左孩子小,让child++。注意必须存在右孩子才能这么做
if (child + 1 < n && arr[child + 1] < arr[child])
{
child++;
}
//如果该孩子比父亲小,就要交换
if (arr[child] < arr[parent])
{
swap(arr[child], arr[parent]);
//向下继续调整
parent = child;
child = parent * 2 + 1;
}
else
{
//如果孩子比父亲大,交换结束
break;
}
}
}3.3 初始化堆*
初始化堆:将一个随机的数组(数组大小随机,元素大小也随机)转换为堆。
思路:
1.将一个数组拷贝到一个堆结构中
2.利用向下调整算法对整个数组进行调整,由于整个数组不能直接进行向下调整(左右子树不符合堆结构),所以我们使用向下调整算法堆 最后一个结点的父亲结点开始调整,然后依次对这个结点之前的结点开始调整。
3.最后得出完整的堆结构
流程图:

代码
//初始化堆
void HeapInit(Heap* hp, DataType* arr, int n)
{
//开辟空间,大小为 DataType*n
hp->arr = (DataType*)malloc(sizeof(DataType) * n);
assert(hp->arr != nullptr);
memcpy(hp->arr, arr, sizeof(DataType) * n);
hp->size = n;
hp->capacity = n;
//拷贝好数据后,由于数据是随机的,所以我们使用调整算法建堆
//我们从最后一个度为2的结点开始向前依次对每一个结点都进行向下调整
//最后一个结点下标为 n-1 则其父亲结点为(n-1-1)/2
for (int i = (n - 1 - 1) / 2; i > 0; i--)
{
Adjustdown(hp->arr, hp->size, i);
}
}
3.4 销毁堆
//销毁堆
void HeapDestory(Heap* php)
{
assert(php);
free(php->arr);
php->arr = NULL;
php->size = 0;
php->capacity = 0;
}3.4 向上调整算法*
当我们插入新数据时,这个数据会破坏堆结构(如插入到数组末尾),所以我们需要向上调整
和向下调整算法类似
思路:
让新增节点依次和自己的父亲比较,然后交换即可
小根堆:比父亲小,交换。直到比父亲大就结束
大根堆:比父亲大,交换。直到比父亲小就结束
流程图:

代码
//向上调整算法,以小根堆为例
void AdjustUp(DataType* arr, int n, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])
{
swap(arr[child], arr[parent]);
//继续向上调整
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}3.5 插入数据
//插入数据
void HeapPush(Heap* hp, DataType x)
{
assert(hp);
//1.增容
if (hp->size == hp->capacity)
{
hp->capacity *= 2;
DataType* tmp = (DataType*)realloc(hp->arr, sizeof(DataType) * hp->capacity);
assert(tmp != NULL);
hp->arr = tmp;
}
//2.在数组的插入数据
hp->arr[hp->size] = x;
hp->size++;
//对数组进行向上调整,将小的数据向上调整
Adjustup(hp->arr, hp->size, hp->size - 1);
}3.6 删除数据
删除堆顶的数据
我们交换第一个数据和最后一个数据,然后删除最后一个数据。再对堆顶进行向下调整
这样就能满足删除后,整个堆还是满足规则的
//删除数据(删掉堆顶的数据)
//类似于堆排序,交换第一个和最后一个数据。保证根节点的左右子树都是小根堆
void HeapPop(Heap* hp)
{
assert(hp);
assert(hp->arr);
swap(hp->arr[0], hp->arr[hp->size - 1]);
hp->size--;
Adjustdown(hp->arr, hp->size, 0);
}3.7 返回堆顶数据
直接返回0下标处的数据即可
//求堆顶(根)数据
DataType HeadTop(Heap* hp)
{
assert(hp);
assert(hp->size > 0);
return hp->arr[0];
}

![[线程]JUC中常见的类 及 集合类在多线程下的线程安全问题](https://i-blog.csdnimg.cn/direct/3ccfd8e69a8f44f0b994eb4cad0a98c3.png)