书接上文GaussDB关键技术原理:高弹性(二)从优化器剪枝、执行器两方面对hashbucket进行了解读,本篇将从段页式技术方面继续介绍GaussDB高弹性技术。
3 段页式
3.1 段页式存储
根据前文的介绍,hashbucket需要对文件进行分片,如果直接对单文件管理的数据文件进行切片,将会产生表数量*1024个文件,在表数量较多的场景下,产生的小文件数量多,导致文件管理系统的压力较大,因此,引入段页式管理,属于一个库表空间下的所有表共同使用一组段页式文件,防止bucket化拆分后小文件多的问题。
图1是存储引擎架构示意图,从整个数据库的组成架构看,段页式在其中是存储引擎中最底层的一种文件管理方式,和单文件管理相并列,通过一组段页式文件管理所有用户表,减少单文件数量,从而降低文件系统的压力。段页式管理和单文件管理通过smgr层(介质管理器)对上层提供相同的接口,实现和缓冲区的读写交互,上层业务不感知底层存储方式发生的变化。
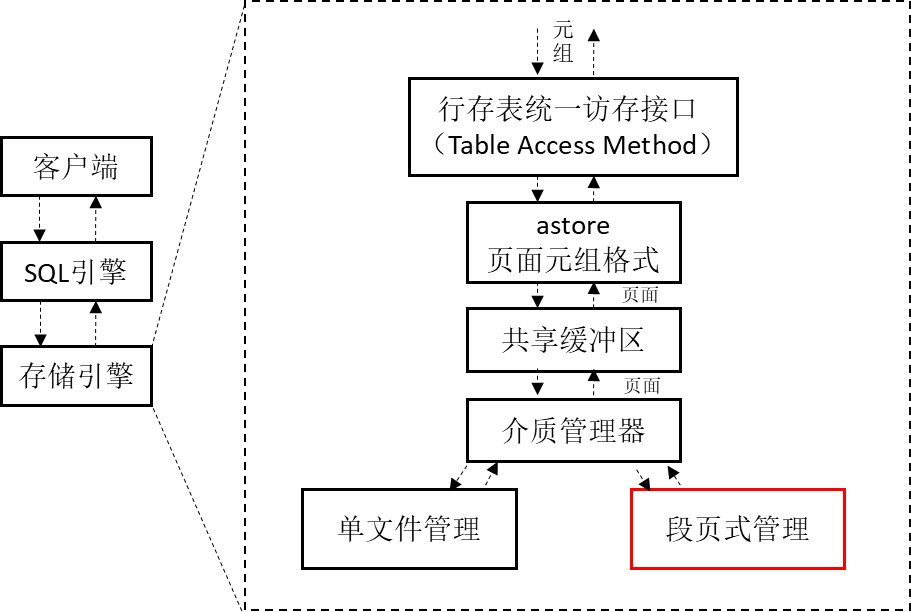
图1 存储引擎整体架构示意图
为了向SQL层提供一套接口,段页式表引入了逻辑block的概念,逻辑block是连续页号的page,上层逻辑访问段页式表使用的是逻辑block。每个段页式表都有一个对应的SegmentHeader,SegmentHeader维护了段页式表使用的逻辑block到实际的段页式物理block的映射关系。SegmentHeader管理了一个用户表的所有元数据信息,尤为重要,设计如下:
typedef struct SegmentHead {
uint64 magic;
XLogRecPtr lsn;
uint32 nblocks; // block number reported to upper layer
uint32 total_blocks; // total blocks can be allocated to table (exclude metadata pages)
uint64 reserved;
BlockNumber level0_slots[bmt_header_level0_slots];
BlockNumber level1_slots[bmt_header_level1_slots];
BlockNumber fork_head[segment_max_forknum + 1];
} SegmentHead;其中,比较重要的有:
-
nblocks指的是上层看到的最大逻辑页号,和页式存储中的文件大小的概念是一样的,smgrnblocks的返回值。
-
total_blocks指的是分配的所有extent,数据块的个数总和,当申请的extent的pages全部用完时,会再申请一个extent。
-
level0_slots和level1_slots存放的是逻辑block到物理block的映射关系,对于序号靠前的extent,起始位置直接存储在 level0_slots中。level0_slots存满之后,会使用level1_slots中存放的level0_slots页面记录。
-
fork_head指的是所有fork的segment head,也以数组的形式存储在main fork的segment head中。每个segment head中的 fork_head[0] 一定等于自己。
hashbucket表采用了段页式存储的方式。在段页式存储管理下,表空间和数据文件采用段(Segment)、区(Extent)以及页(Page/Block)作为逻辑组织,进行存储的分配和管理。具体来说,一个database在其所存在的每个表空间中,都拥有一组独立的段页式文件,如下图2所示:某个库下的一个表空间的段页式文件由1-5号文件组成。
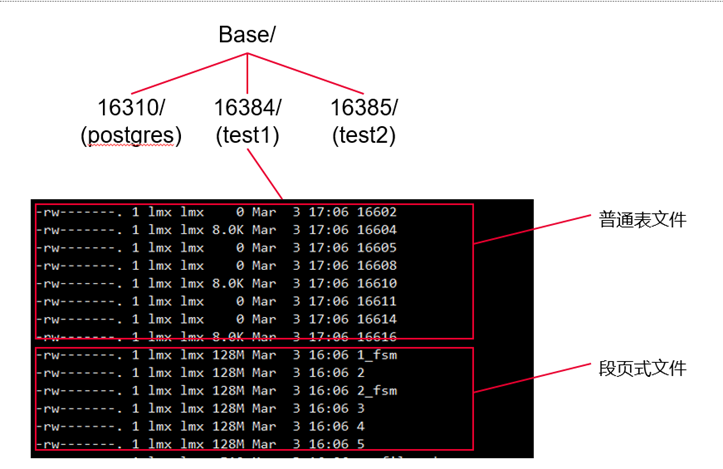
图2 段页式物理结构示意图
由于属于一个表空间下的所有段页式表的数据都会写到这几个段页式文件中,所以这几个文件会膨胀到TB量级,段页式文件仍然沿用GaussDB页式文件的切分方式,按照1GB进行切分,将一个物理文件称为一个slice,使用2.1, 3.1来表示。拥有相同前缀的一组slice组成一个段页式文件管理系统(SegLogicFile)。SQL层将每个SegLogicFile看作一个无限大的物理文件。
每个SegLogicFile称为一个ExtentGroup,文件组织格式如下图3。

图3 段页式逻辑文件组织格式
-
MapHeader:用来存放管理BitMap page的元信息;
-
BitMapPages:Bitmap页面,用来管理DataPages的extent使用情况,页面中的一个bit位表示代表1个extent,0表示空闲,1表示已使用。每个ExtentGroup中extent大小不一样,所以1个bit位表示的extent大小也不一样;
-
ReversePointerPages:reversepointer页面,用来管理DataPages的extent的属主信息,即属于哪个SegmentHeader管理。
-
DataPages:数据表记录存放区域,不同文件按照不同数量的block组成extent。
GaussDB中有fork的概念,用于管理每个表的数据和元数据信息,如表数据存的文件称作MAIN FORK,空闲页面信息称为FSM FORK,visibility map称为VM FORK。这些fork存储在各自的物理文件中,文件用后缀来区分,1_fsm, 1_vm,MAIN FORK不带后缀。所以,对于GaussDB单文件存储来说,只需要知道relfilenode和fork number,就能拼出物理文件名。
为了前向兼容,段页式保留了fork的概念,一个fork使用一组segment,依然用“relfilenode + fork number +逻辑页号”来访问数据。把MAIN FORK的SegmentHeader,作为该表的relfilenode,存储在系统表pg_class中;其它fork的SegmentHeader存储在MAIN FORK的SegmentHeader中。数据访问的流程如下图4所示:

图4 段页式数据访问流程示意图
其中,表t1在pg_class中的relfilenode是4157,通过访问段页式1号文件的4157页面可以访问到其SegmentHeader,根据上层传入的逻辑页面号0可以通过Block Map Tree找到物理页面的位置(2号文件的4157页面)。通过fork header中的fsm页面4160可以访问到fsm的segmentheader所在的物理信息(1_fsm文件的4160页面)。
由上可知,段页式表通过唯一的Segment Header进行表示,而段页式表中的数据则是存放在若干个Extent中,每个Extent都是由固定数量的Page组成的。所有Extent由1-5号文件组成段空间,所有表都从该段空间中分配数据。因此表的个数和实际物理文件个数无关。每个表有一个逻辑segment,该表所有的数据都存在该segment上。每个segment会挂载多个extent,每个extent是一块连续的物理页面。
在表或者分区数量较多的场景下, 段页式存储相比于页式存储生成的文件数量会大大减少,从而降低对文件系统的规格要求,减轻对操作系统IO栈产生的压力,提升数据库的吞吐能力。hashbucket表对数据文件进行切片,如果不采用段页式存储可能会产生大量的小文件,在进行CHECKPOINT这种IO重度操作的时候,需要对大量文件进行sync操作,此时很有可能造成长时间的IO等待,影响数据库的整体性能。
段页式目前支持五种大小的Extent,分别是8K/64K/1M/8M/32M,对应五种不同Extent大小的段页式文件(文件名1/2/3/4/5),称之为段页式文件组,这一组文件中1号文件用来管理段页式表元数据,2到5号文件用来存储用户表数据。对于一个segment来说,每一次扩展的Extent的大小是固定的。前16个extent大小为64K,第17到第143个extent大小为1MB,依次类推。具体参数如下表1所示。初始时表比较小,分配的Extent粒度较小,当表变得比较大的时候,分配的粒度较大。这样做的好处是可以在空间利用率和分配频率之间做一个很好的平衡。
表1 段页式支持的不同extend的参数表
| Group | Extent size | Extent page count | Extent count range | Total page count | Total size |
| 1 | 64K | 8 | [1, 16] | 128 | 1M |
| 2 | 1M | 128 | [17, 143] | 16K | 128M |
| 3 | 8M | 1024 | [144, 255] | 128K | 1G |
| 4 | 32M | 8192 | [256, …] | … | … |
因为Extent的扩展方式是固定的,因此任何一个Segment中的Extent的分布都相同,如下图5所示:Extent在逻辑上是连续的,物理上Segment分布在1号文件,Extent分布在段页式2-5号文件的任意位置。
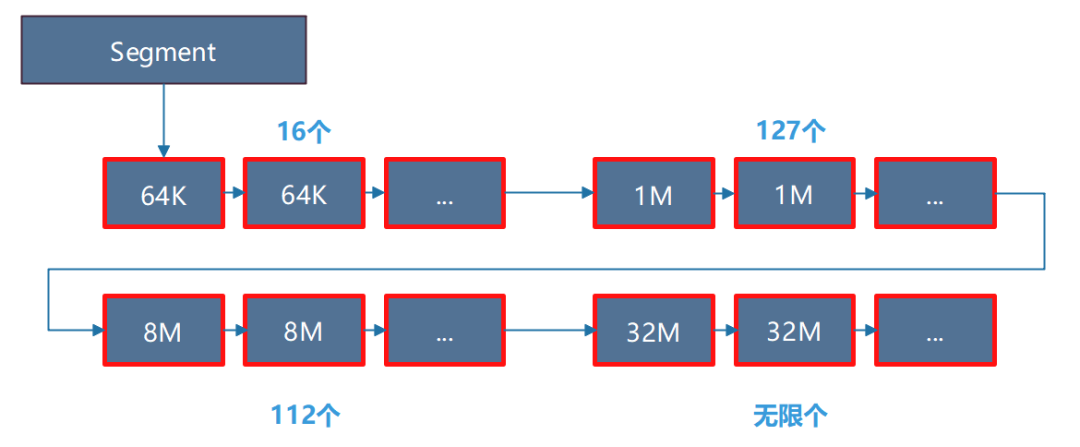
图5 segment中extend的分布示意图
3.2 hashbucket段页式
hashbucket位于段页式的下层,将段页式的文件组bucket化分片,如下图6所示:
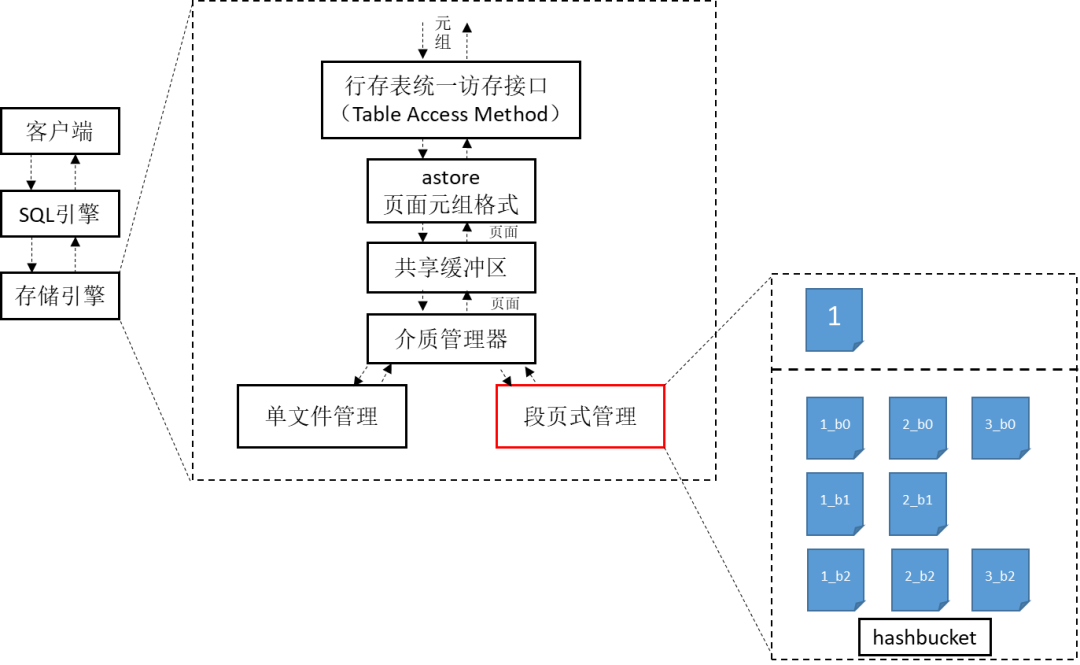
图6 hashbucket在存储引擎架构中的位置
hashbucket表的bucket桶个数固定为1024个。每个DN分片拥有的bucket数量为1024/DN分片数量个。将上一章节介绍的段页式文件(1-5号)进行切片,拥有相同hash值的数据存在一组bucket段页式文件中,命名方式为文件编号_bucketid_[vm/fsm],其中1号小bucket段页式文件仍然存储元数据信息,主要是SegmentHeader,管理属于bucket 0的数据Extent;2号小bucket段页式文件存储真正的用户数据。因此以tablespace为粒度,每个库的每个tablespace拥有1024组1-5号bucket段页式文件。
hashbucket表与段页式的寻址方式类似,在系统表pg_class的relfilenode表示1号段页式文件中的一个页面号,表示最上层的元数据管理页面,通过如下结构体实现:
typedef struct BktMainHead {
uint64 magic;
XLogRecPtr lsn;
BlockNumber bkt_main_head_map[BUCKETMAPLEN];
} SegmentHead;其中,bkt_main_head_map是4字节*1024的数组,下标表示hashbucket桶的编号,内容表示小段页式文件中SegmentHeader所在的页面号。
以创建一张hashbucket表t1为例,寻址过程如下图7所示:
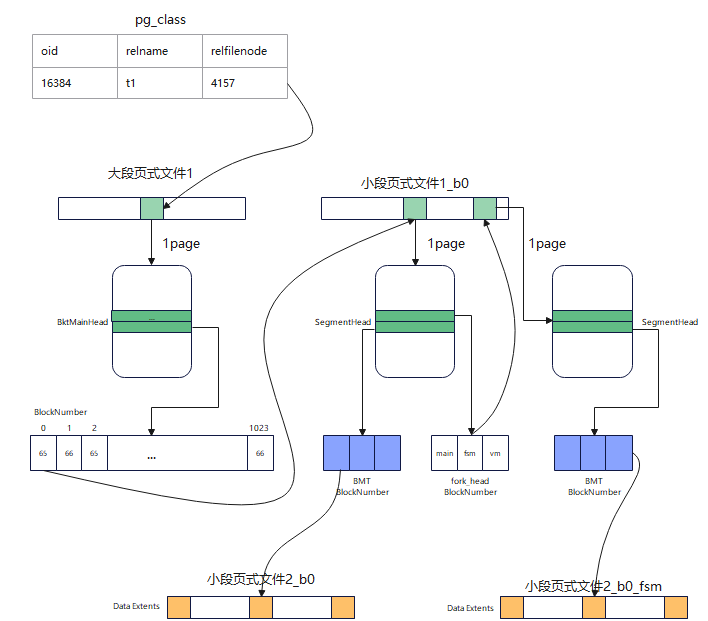
图7 hashbucket建表寻址过程示意图
-
P1:通过pg_class的relfilenode能够访问到段页式1号文件中的BktMainHead页面4157。
-
P2:从BktMainHead的内容找到对应bucket 0 SegmentHeader所在的页面号,访问对应bucket 0的1号文件1_b0的页面65。
-
P3:通过页面1_b0的页面65的SegmentHeader记录的Extent位置信息存入对应的数据,或者根据传入的逻辑页面号翻译出要访问的物理页面位置。
-
P4:根据要访问的物理页面信息访问对应的bucket段页式文件2_b0。
-
hashbucket的元数据管理采用上述方式主要为了后续扩容考虑,为了实现物理文件搬迁,我们需要直接把某个DN分片的bucket文件搬迁到新节点,为了保证文件搬迁后仍然可以寻址成功,需要在新DN build完元数据之后进行BktMainHead的更新,将即将搬迁至新节点的所有bucket 1号文件中的SegmentHeader所在的页面号更新到段页式1号文件的BktMainHead中。
hashbucket表的反向指针在bucket 1号文件中,SegmentHeader页面对应的反向指针存储的是1号段页式文件BktMainHead页面所在的页面号,因此需要在扩容期间基线数据搬迁完成时更新搬迁至新节点所有bucket 1号文件的SegmentHeader的反向指针。
3.3 TOAST
TOAST是GaussDB中一种存储大数据的机制。TOAST表是否创建是根据原表列类型决定的,数据是否存到TOAST表中是根据数据大小决定的。创建原表时如果包含变长类型(text类型等)的列就会自动创建并关联TOAST表一张TOAST表负责行外存储,如下图8所示。GaussDB不允许一行数据跨页存储,当单个元组大小超过2K时,会自动触发TOAST机制,对数据进行压缩和切片,将实际数据存储到TOAST表。TOAST表不支持用户手动创建,随原表一起创建和删除。TOAST表和索引的存储类型和原表保持一致,原表和TOAST表通过OID关联,pg_class中原表会记录reltoastrelid(与原表关联的TOAST表的OID,如果没有则为0),在pg_class中通过OID可以找到TOAST表。
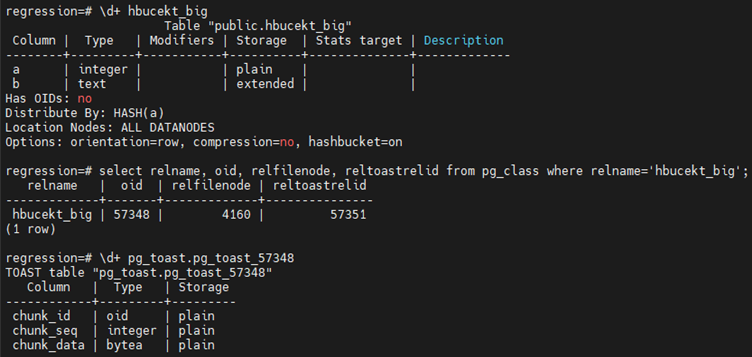
图8 hashbucket TOAST表元数据
3.3.1 hashbucket TOAST数据管理方式
由于hashbucket扩容会将属于老节点的文件直接搬迁至新节点,此时如果TOAST指针中记录了老节点的OID信息,由于OID是本地维护的,搬迁到新节点可能出现访问不到数据的问题。因此,hashbucket表TOAST数据管理方式是由产生TOAST的列存储TOAST指针,存储小段页式1号文件的relfilenode。对TOAST表操作时通过小段页式1号文件SegmentHead页面的反向指针查询到当前hashbucket表大段页式1号文件的页面号,再通过反向指针获取到所属TOAST表的OID,如下图9所示:
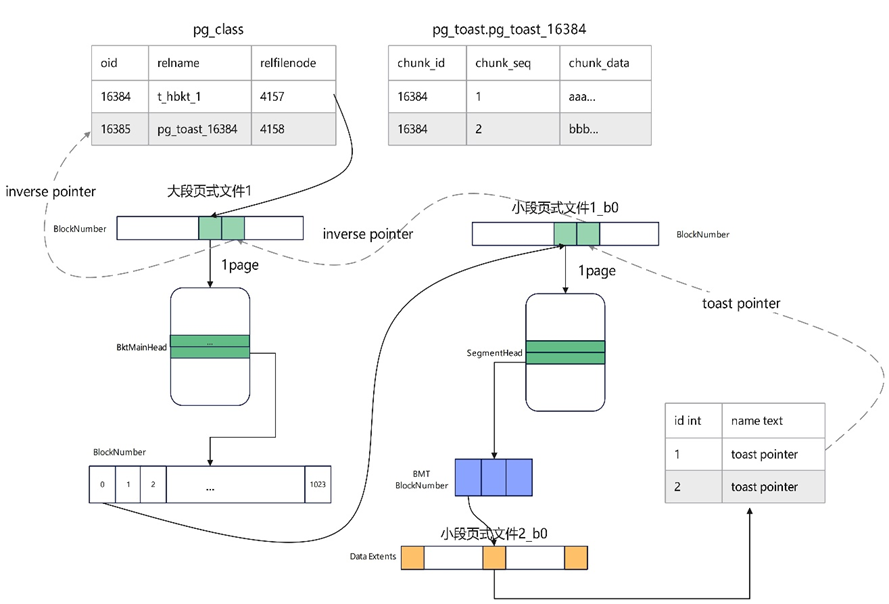
图9 hashbucket TOAST表寻址示意图
数据插入时会先对可压缩的列执行压缩,然后判断元组长度是否能触发TOAST以及类型是否可以执行外部存储,多数情况下压缩后的元组长度不满足2K的阈值所以不会触发TOAST机制。访问数据时需要访问TOAST表中的压缩数据,对该数据解压。
关键数据结构TOAST指针varatt_external,存储获取行外存储数据所需的信息,数据结构设计如下:
typedef struct varatt_external {
int32 va_rawsize; /* 原始数据大小(包括header) */
int32 va_extsize; /* 外部保存大小(不包括header) */
Oid va_valueid; /* TOAST表中值的唯一id */
Oid va_toastrelid; /* toast表id */
} varatt_external;其中va_extsize表示外部数据大小,va_rawsize表示原始未压缩数据大小,当且仅当va_extsize小于va_rawsize减var header大小时,数据会被压缩。
以上内容从段页式技术方面对GaussDB高弹性能力进行了解读,下篇将从hashbucket扩容方面继续介绍GaussDB高弹性技术,敬请期待!







![[SUCTF 2018]annonymous1](https://i-blog.csdnimg.cn/direct/0aa85775d0b84744b624abf2469f67ec.png)