首先感谢王晓老师的[ 接口优化的常见方案实战总结]一文总结,恰巧最近在对稳健理财BFF层聚合查询服务优化治理,针对文章内的串行改并行章节进行展开,分享下实践经验,主要涉及原同步改异步的过程、全异步化后衍生的问题以及治理方面的思考与改进。 希望通过分享这些经验,能够对大家的工作有所启发和帮助。如果有任何问题或建议,请随时提出。 感谢大家的关注和支持!
一、问题背景
将不同理财产品(如基金、券商、保险、银行理财等)针对不同投放渠道人群进行个性化商品推荐,每个渠道或人群看到的商品或特性数据又各不相同,为方便渠道快速对接,由BFF层统一对所有数据进行聚合下发,因此BFF层聚集依赖了大量底层原子服务,所以主要问题是在依赖大量上游接口的场景下保障TP99、以及可用率。
案例:
以其中比较典型的商品推荐接口为例,需要依赖本地商品池缓存、算法推荐服务、商品基础信息服务、持仓查询服务、人群标签服务、券配置服务,可领用券服务、其他数据服务ServN……等等,其中大部分上游原子接口对单次批量查询支持有限,所以极端情况,单个推品接口单次推荐1-n个推品,每个商品如果要绑定10个动态属性,至少需要发起(1~n)*10次io调用。
改造前的流程和问题:
流程:
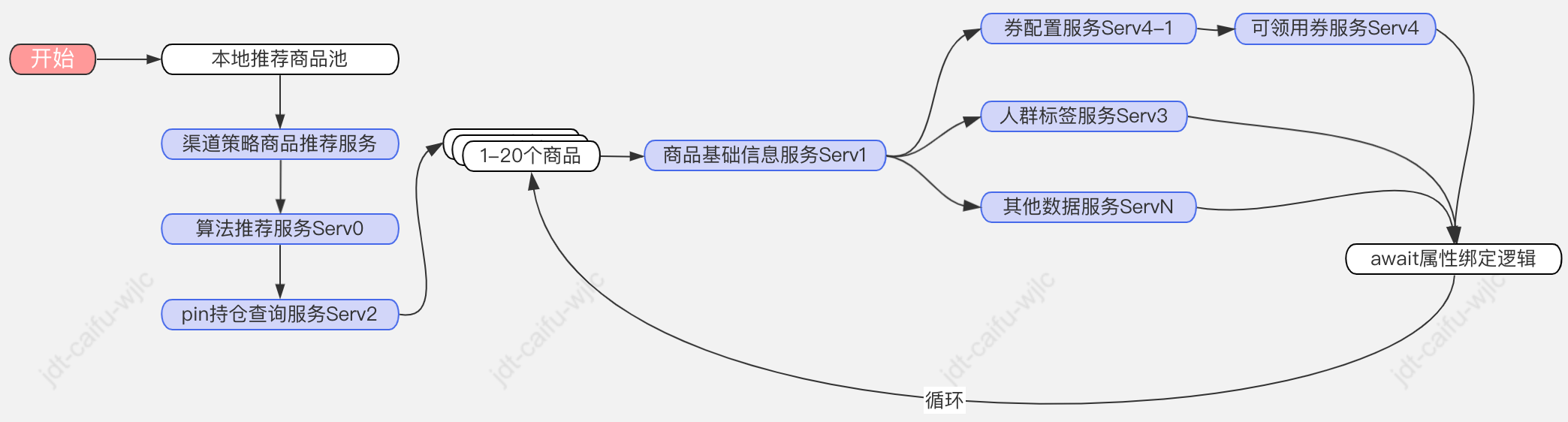
问题:
▪一是逻辑流程强耦合,很多上下游服务强同步依赖;
▪二是链路较长,其中某个上游服务不稳定时很容易造成整体链路失败。
改造后的流程和实现的目标:
流程:
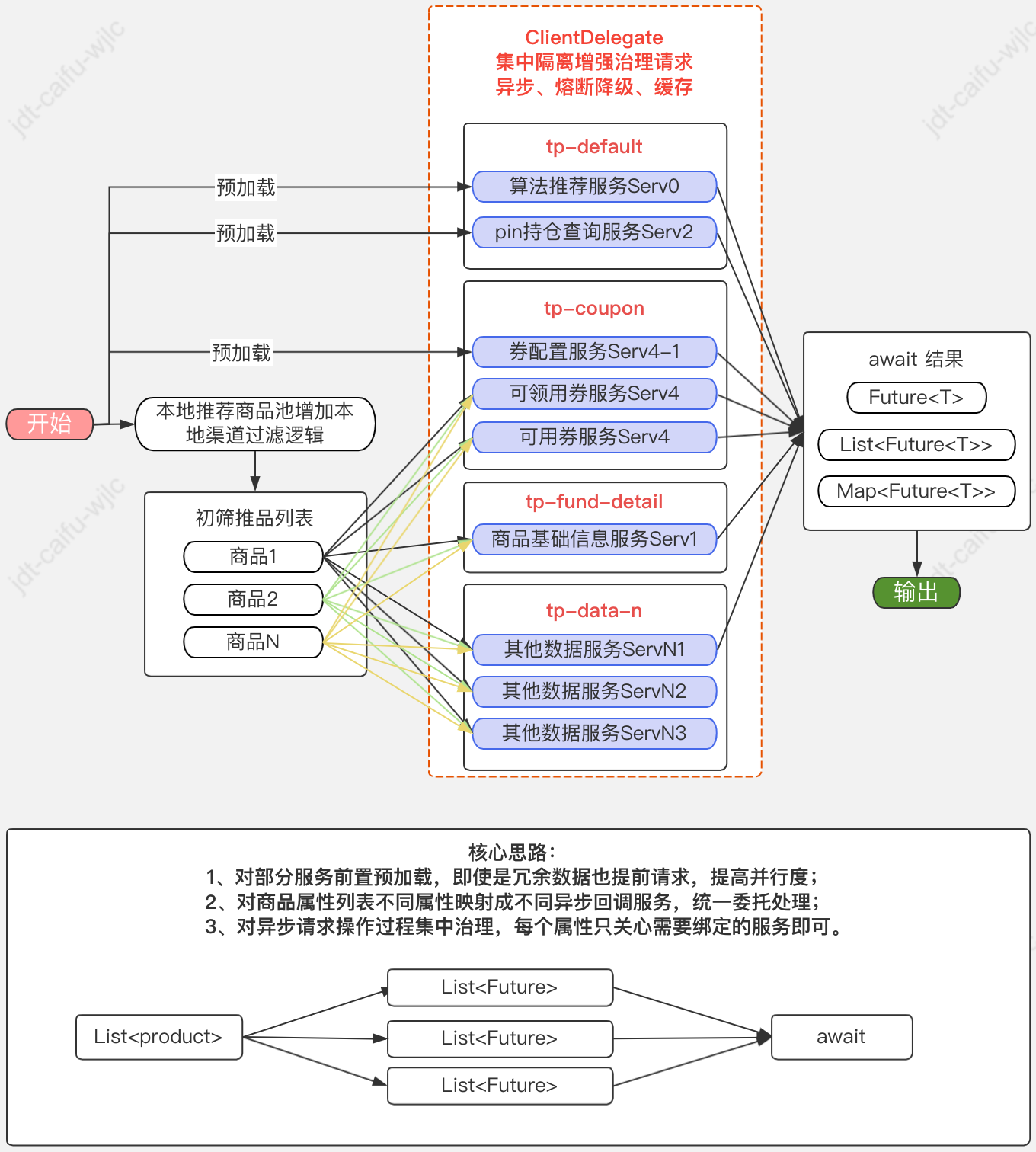
目标:
▪改造目标也很明确,就是对现有逻辑改造,尽可能增加弱依赖比例,一是方便异步提前加载,二是弱依赖代表可摘除,为降级操作奠定基础,减少因某个链路抖动影响整体链路失败;
初步改造后的新问题【【重点解决】】:
▪逻辑上解耦比较简单,无非就是前置参数或冗余加载,本次不展开探讨;
▪技术上改造前期异步逻辑主要是采用@Async("tpXXX")标注,这也是最快捷实现的方式,但也存在以下几个问题,主要是涉及治理方面:
1. 随着项目和人员不断迭代,造成@Async注解满天飞;
2. 不同人员在不熟悉其他模块的情况下,无法界定不同线程池的是否可公用,大多都会采用声明新的线程池,造成线程池资源泛滥;
3. 部分调用场景不合理造成@Async嵌套过多或注解失效问题;
4. 降级机制重复代码太多,需要频繁手动声明各种降级开关;
5. 缺少统一的请求级别的缓存机制,虽然jsf已经提供了一定程度的支持;
6. 线程池上下文传递问题;
7. 缺少线程池状态的统一监控报警,无法观测实际运行过程中的每个线程池状态,可能每次都是拍脑袋觉设置线程池参数。
二、整体改造路径
切入点:
鉴于大部分项目都会封装单独的io调用层,比如 com.xx.package.xxx.client,所以以此为切入点进行重点改造治理。
最终目标:
实现、应用简单,对老代码改造友好,尽可能降低改造成本;
1. 抽象io调用模板,统一io调用层封装规范,标准化io调用需要的增强属性声明并提供默认配置,如所属线程池分配、超时、缓存、熔断、降级等;
2. 优化@Async调用,所有io异步操作统一收缩至io调用层,在模板层实现回调机制,老代码仅继承模板即可实现异步回调;
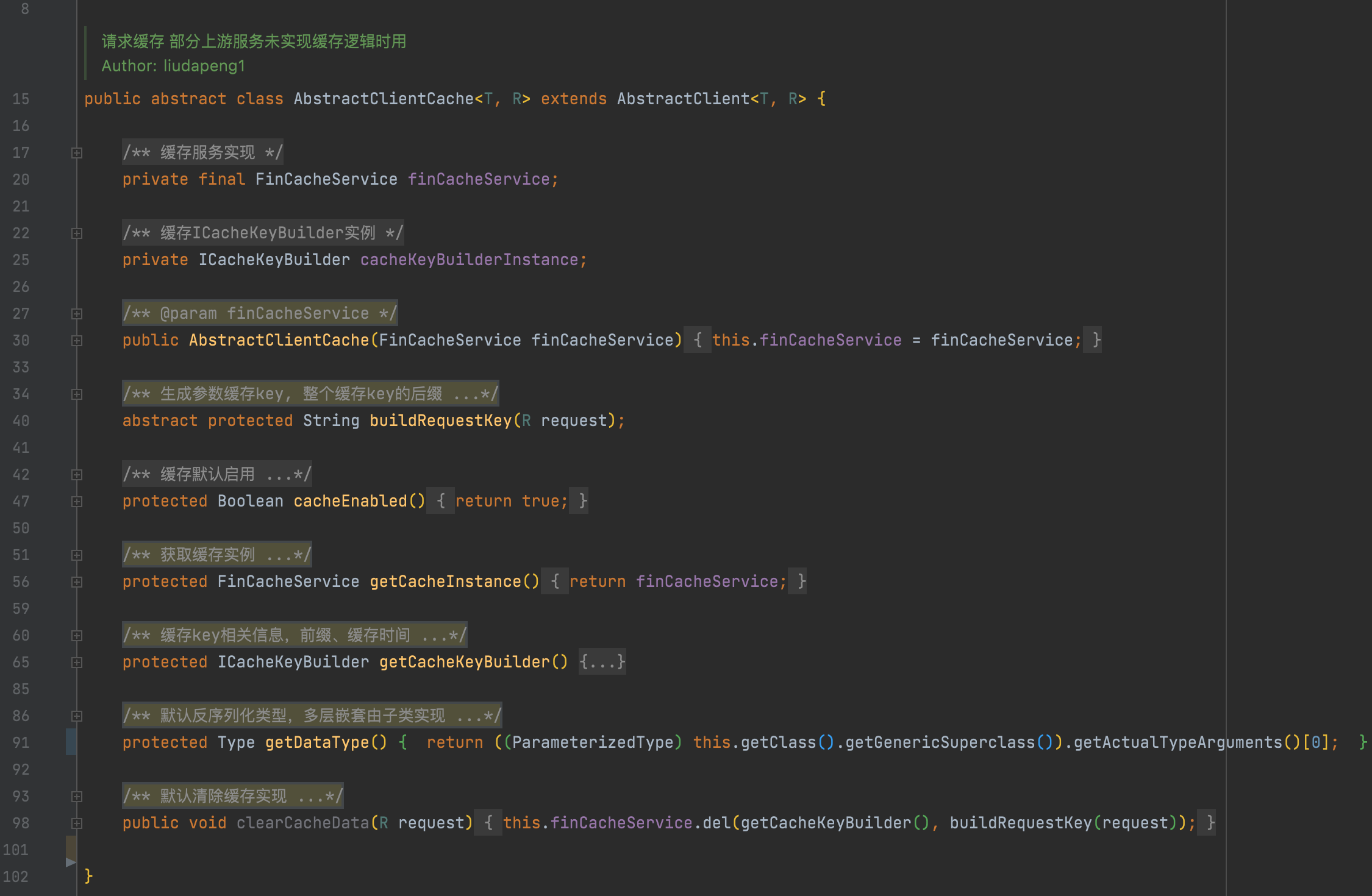
3. 请求级别的缓存实现,默认支持r2m;
4. 请求级别的熔断降级支持,在上游故障时使服务实现一定程度的自治理;
5. 线程池集中管理,对上下文自动传递MDC参数提供支持;
6. 线程池状态自动可视化监控、报警实现;
7. 支持配置中心动态设置。
具体实现:
1. io调用抽象模板
模板主要作用是进行规范和增强,目前提供两种模板,默认模板、缓存模板,核心思想就是对io操作涉及的大部分行为进行声明,比如当前服务所属线程池分组、请求分组等,由委托组件按照声明的属性进行增强实现,示例如下:
主要是提供代码级别的默认声明,从日常实践看大部分采用开发时的代码级别的配置即可。
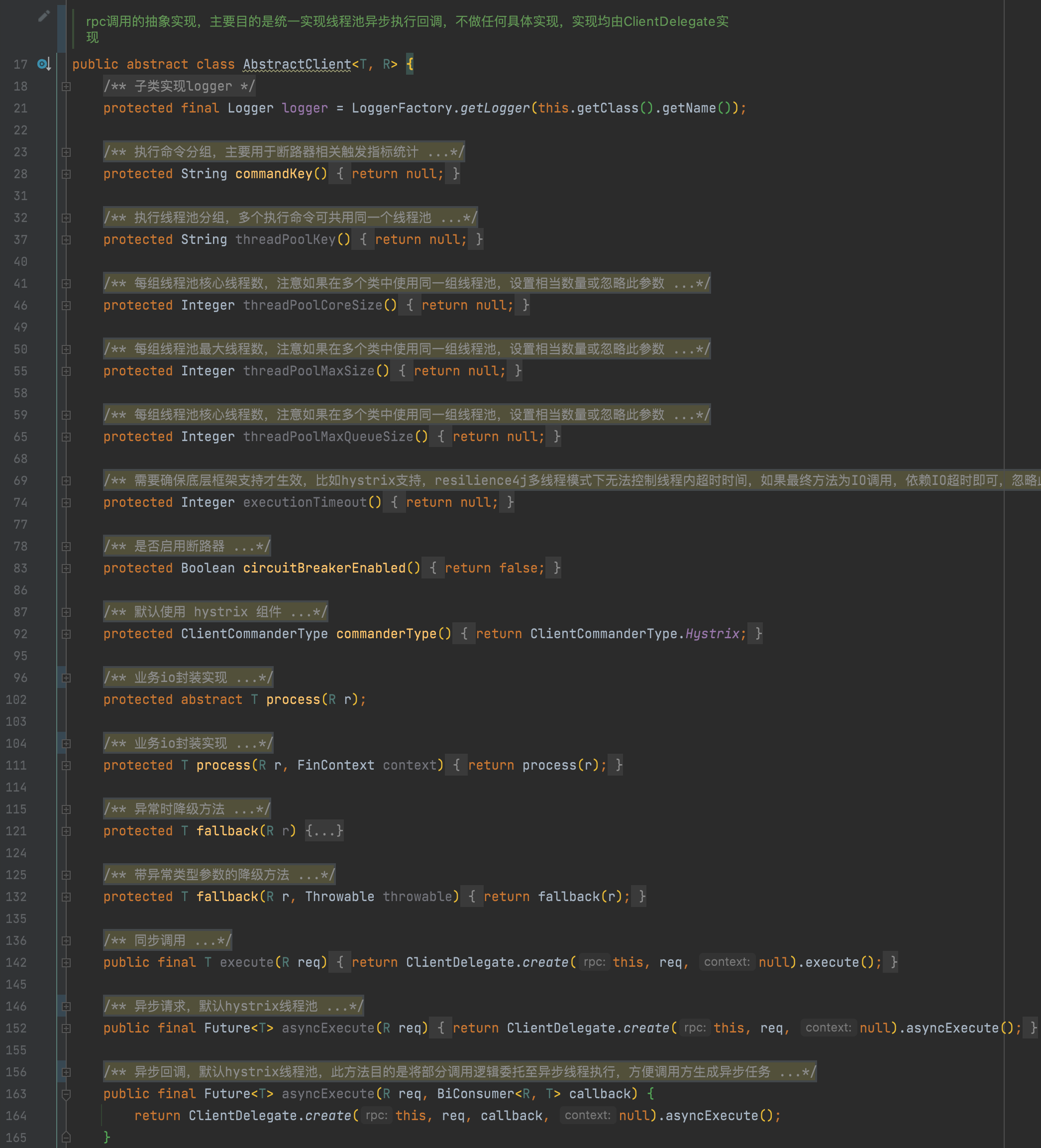
.
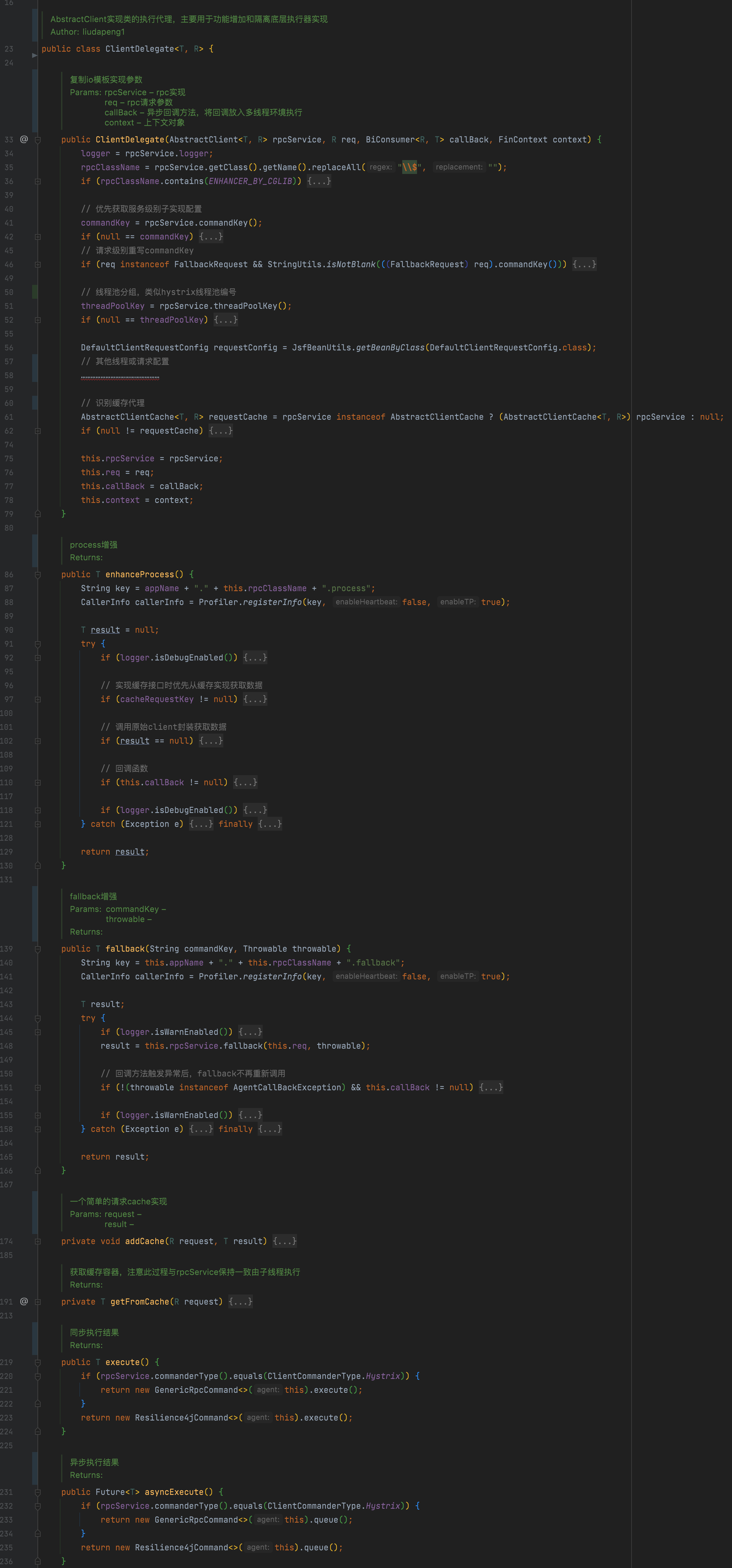
2. 委托代理
此委托属于整个执行过程的桥接实现,io封装实现继承抽象模板后,由模板创建委托代理实例,主要用于对io封装进行增强实现,比如调用前、调用后、以及调用失败自动调用声明的降级方法等处理。
可以理解为:模板专注请求行为,委托关注对象行为进行组合增强。
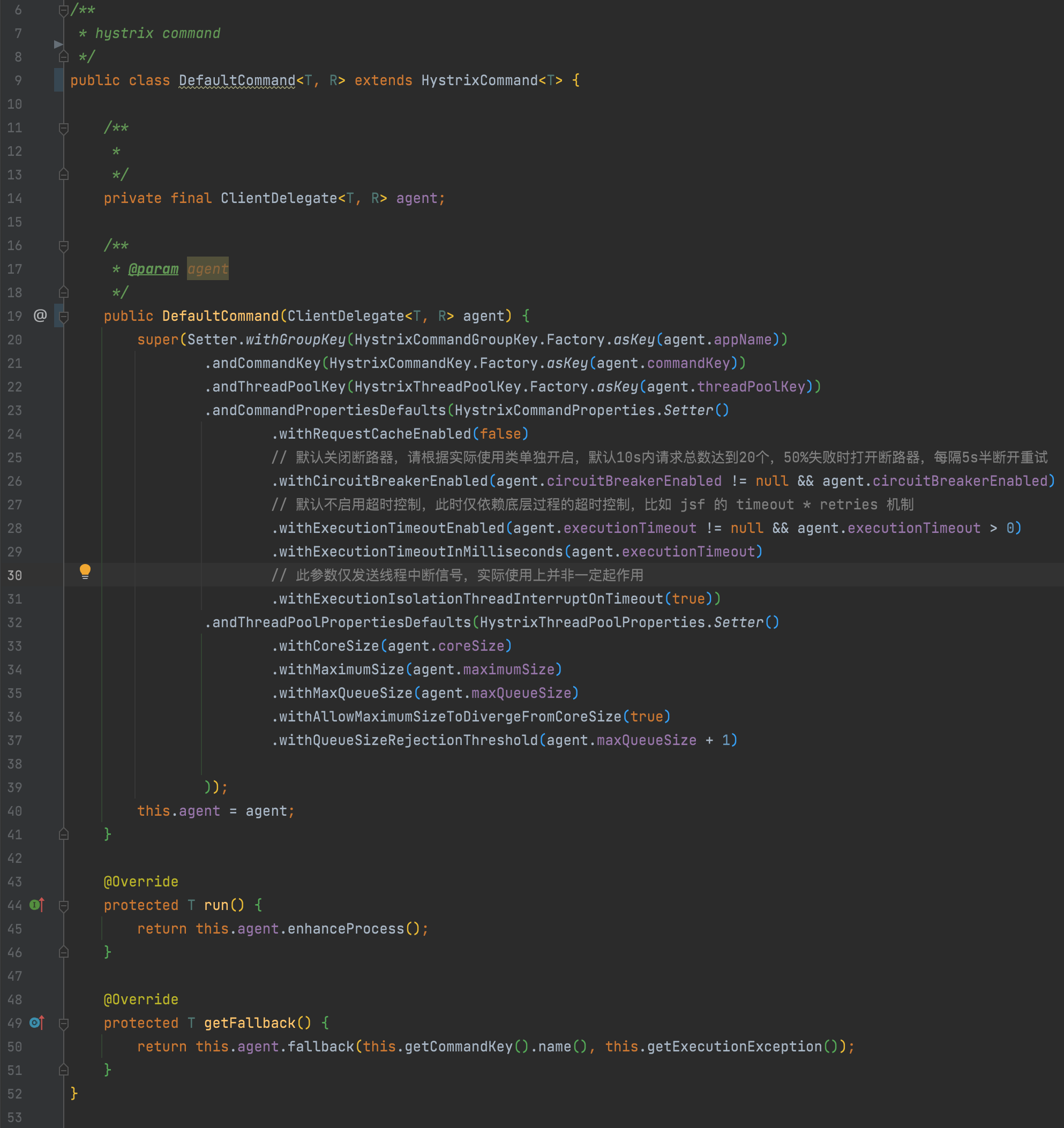
3. 执行器选型
基于前面的实现目标,减少自研成本,调研目前已有框架,如 hystrix、sentinel、resilience4j,由于主要目的是期望支持线程池级别的壁舱模式实现,且hystrix集成度要优于resilience4j,最终选型默认集成hystrix,备选resilience4j, 以此实现线程池的动态创建管理、熔断降级、半连接重试等机制,HystrixCommander实现如下:
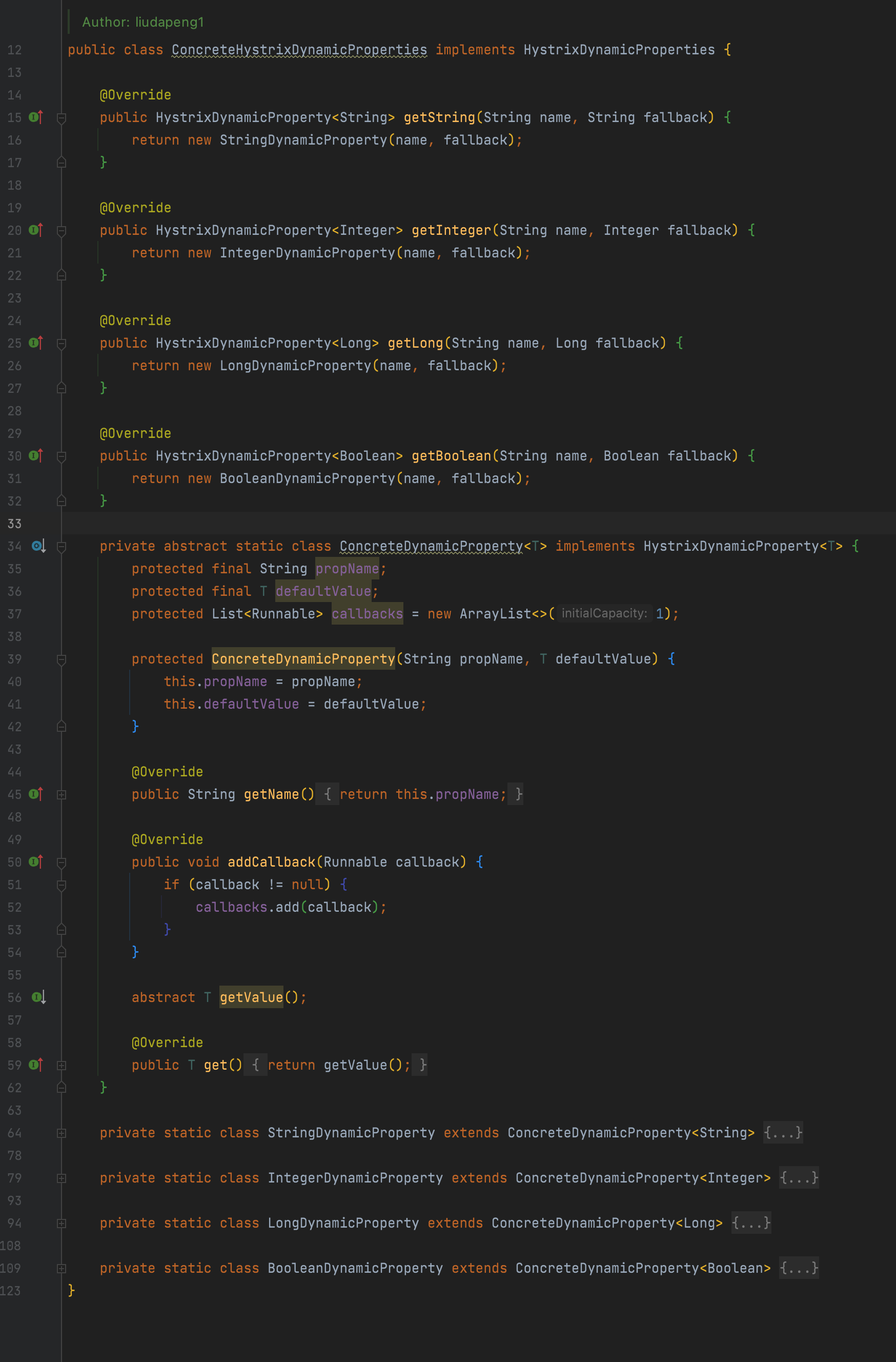
4. hystrix 适配 concrete 动态配置
1、继承concrete.PropertiesNotifier, 注册HystrixPropertiesNotifier监听器,缓存配置中心所有以hystrix起始的key配置;
2、实现HystrixDynamicProperties,注册ConcreteHystrixDynamicProperties替换默认实现,最终支持所有的hystrix配置项,具体用法参考hystrix文档。
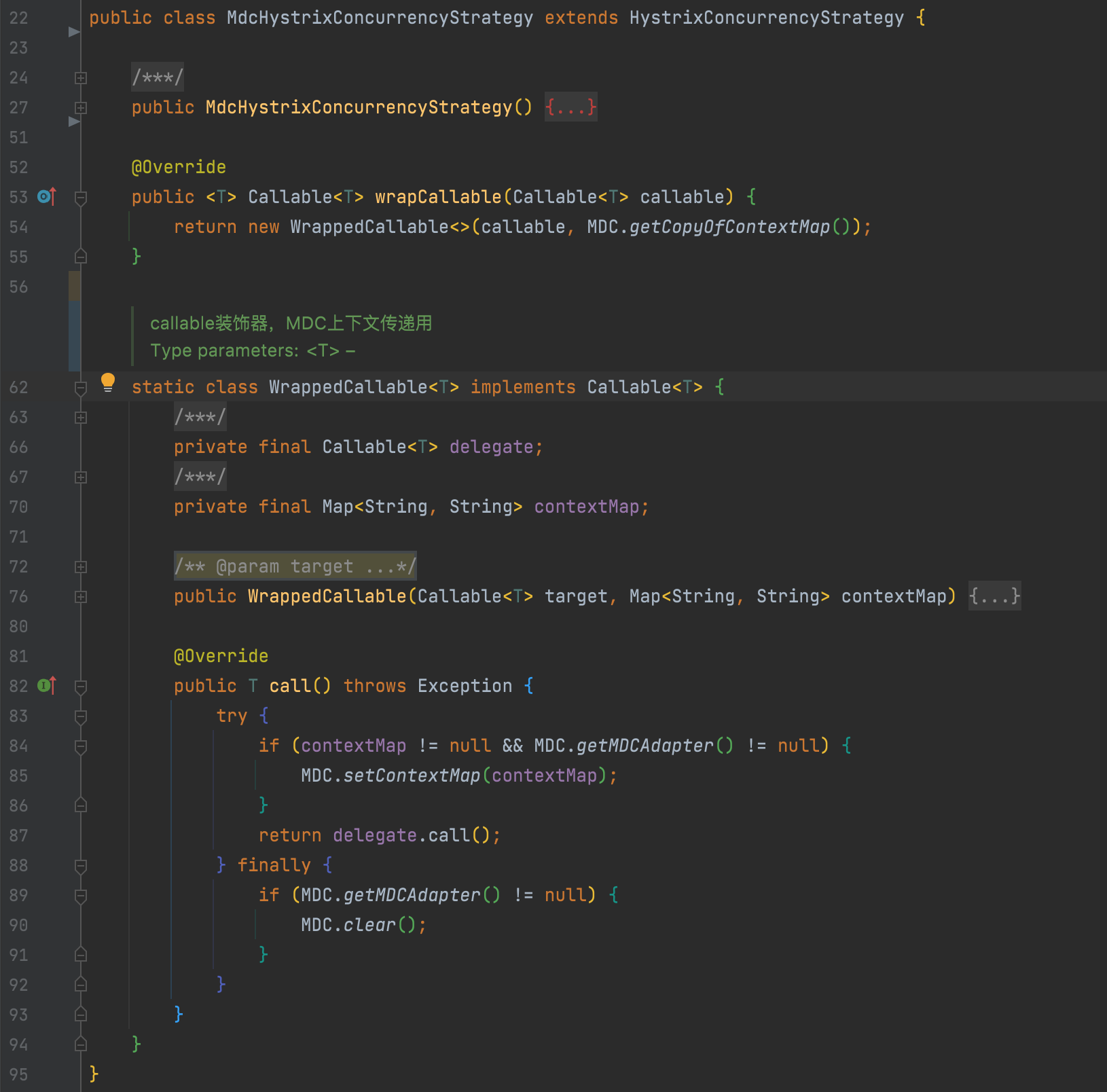
5. hystrix 线程池上下文传递改造
hystrix已经提供了改造点,主要是对HystrixConcurrencyStrategy#wrapCallable方法重写实现即可,在submit任务前暂存主线程上下文进行传递。
6. hystrix、jsf、spring注册线程池状态多维可视化监控、报警
主要依赖以下三个自定义组件,注册一个状态监控处理器,单独启动一个线程,定期(每秒)收集所有实现数据上报模板的实例,通过指定的通道实现状态数据推送,目前默认使用PFinder上报:
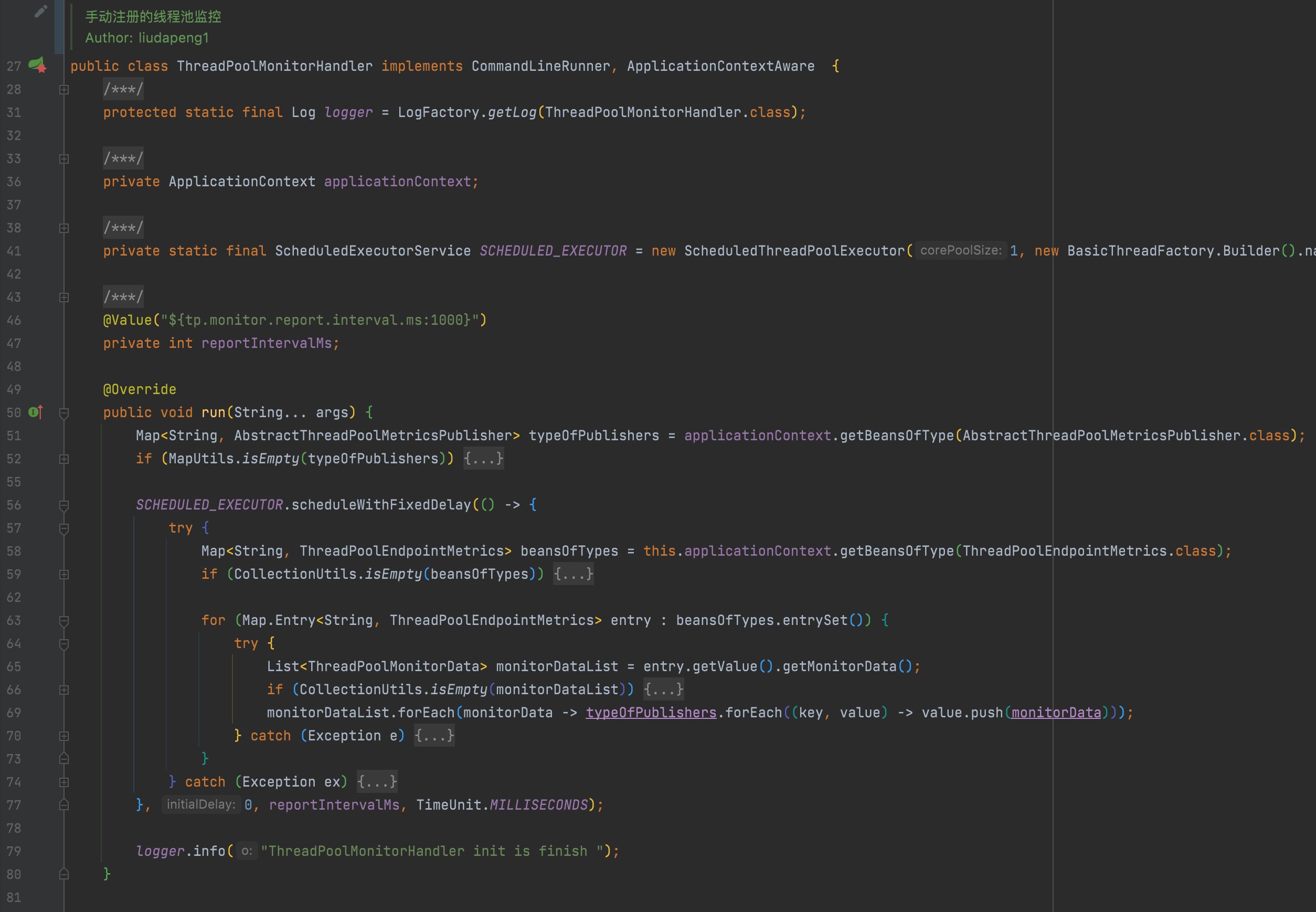
▪ThreadPoolMonitorHandler 定义一个线程状态监控处理器,定期执行上报过程;
▪ThreadPoolEndpointMetrics 定义要上报的数据模板,包括应用实例、线程类型(spring、jsf、hystrix……)、类型线程分组、以及线程池的几个核心参数;
▪AbstractThreadPoolMetricsPublisher 定义监控处理器执行上报时依赖的通道(Micrometer、PFinder、UMP……)。
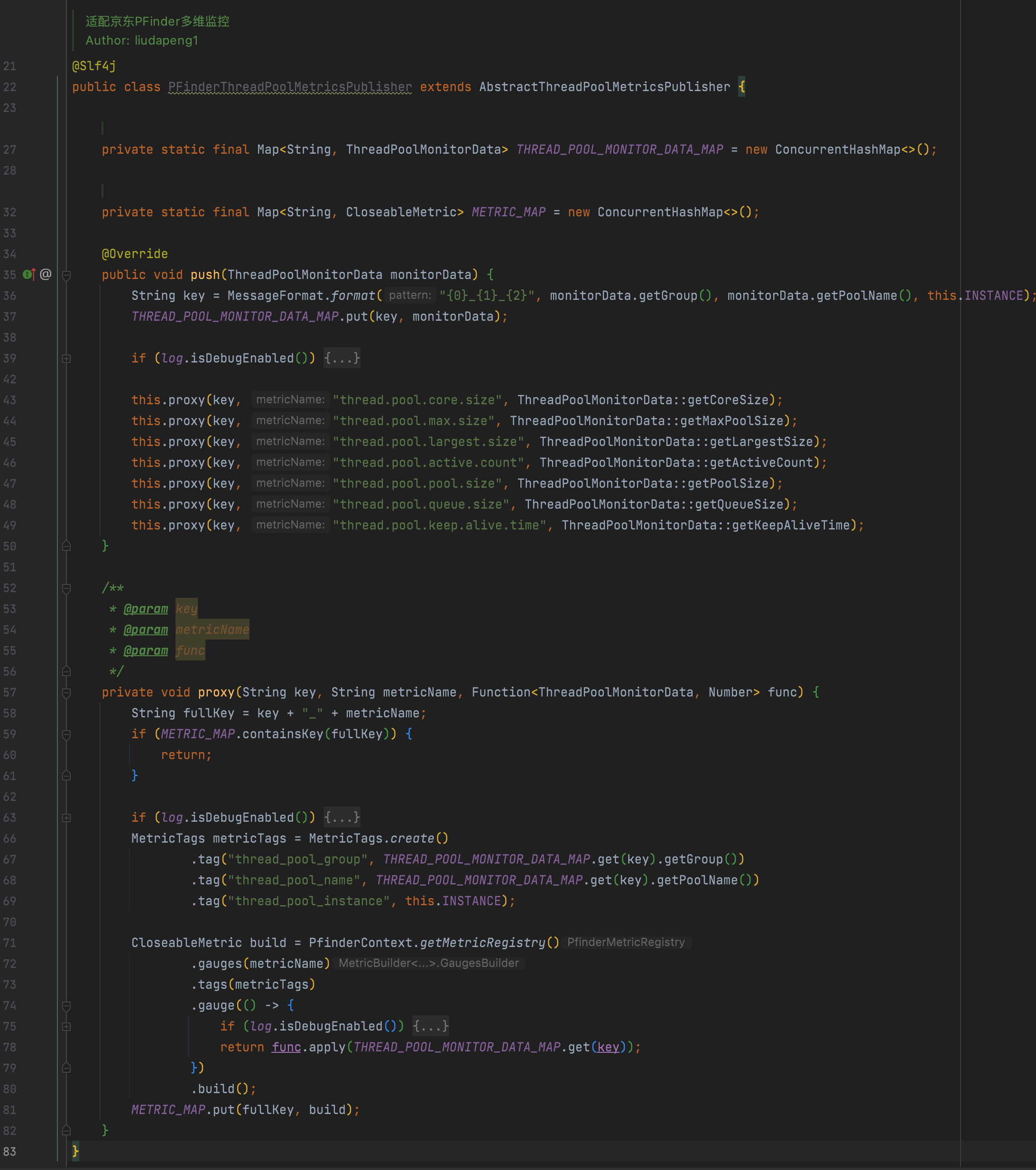
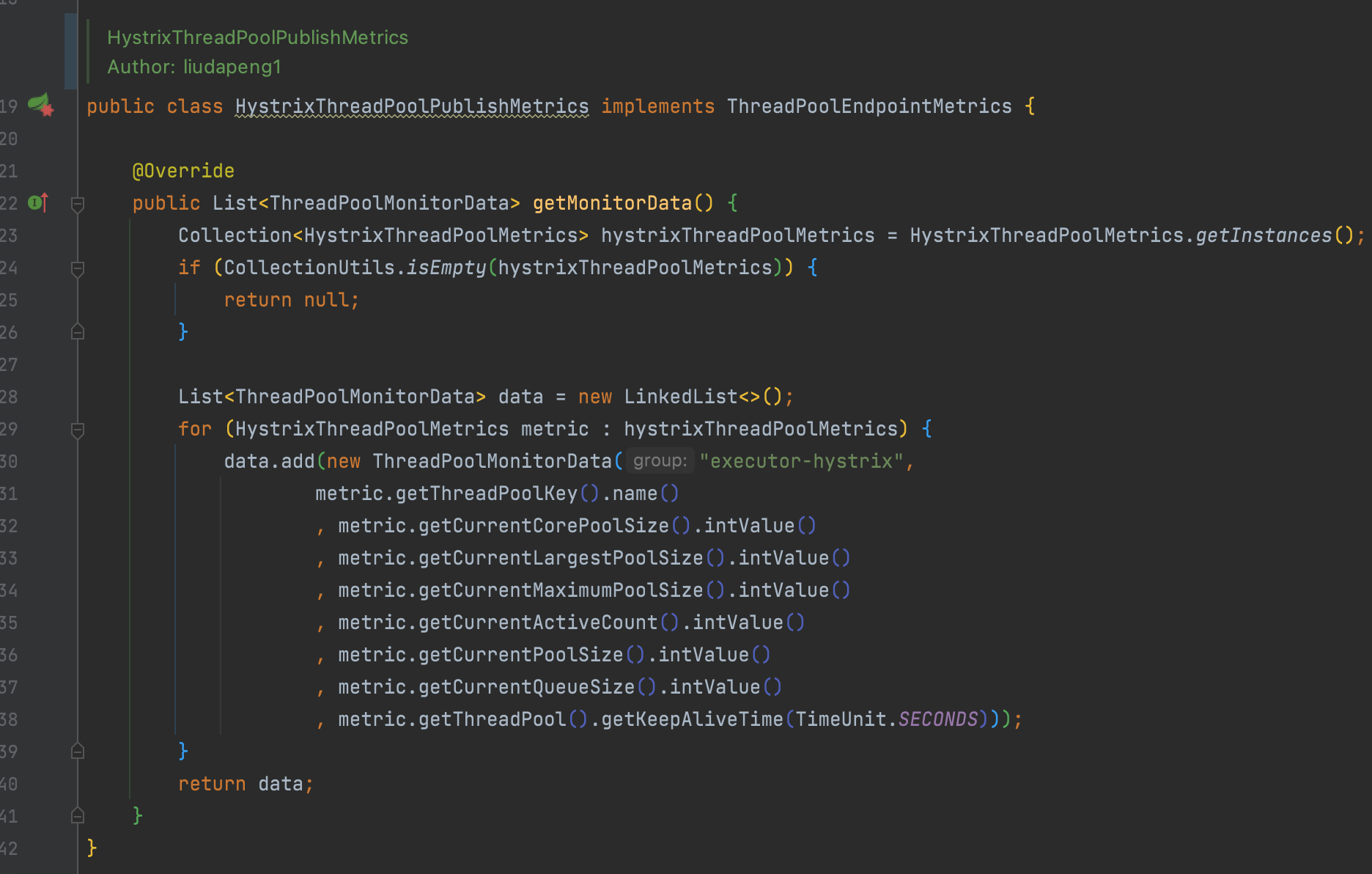
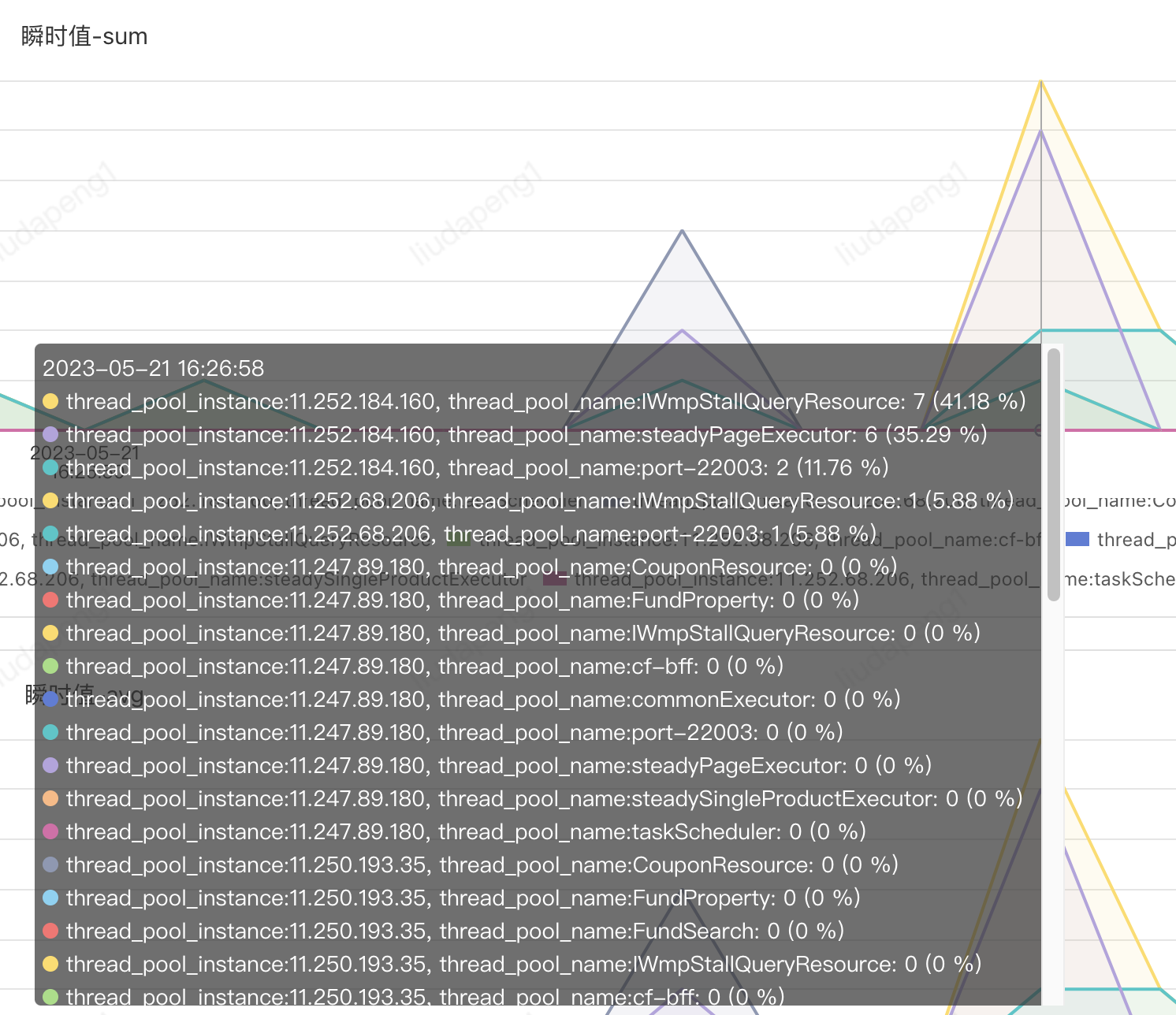
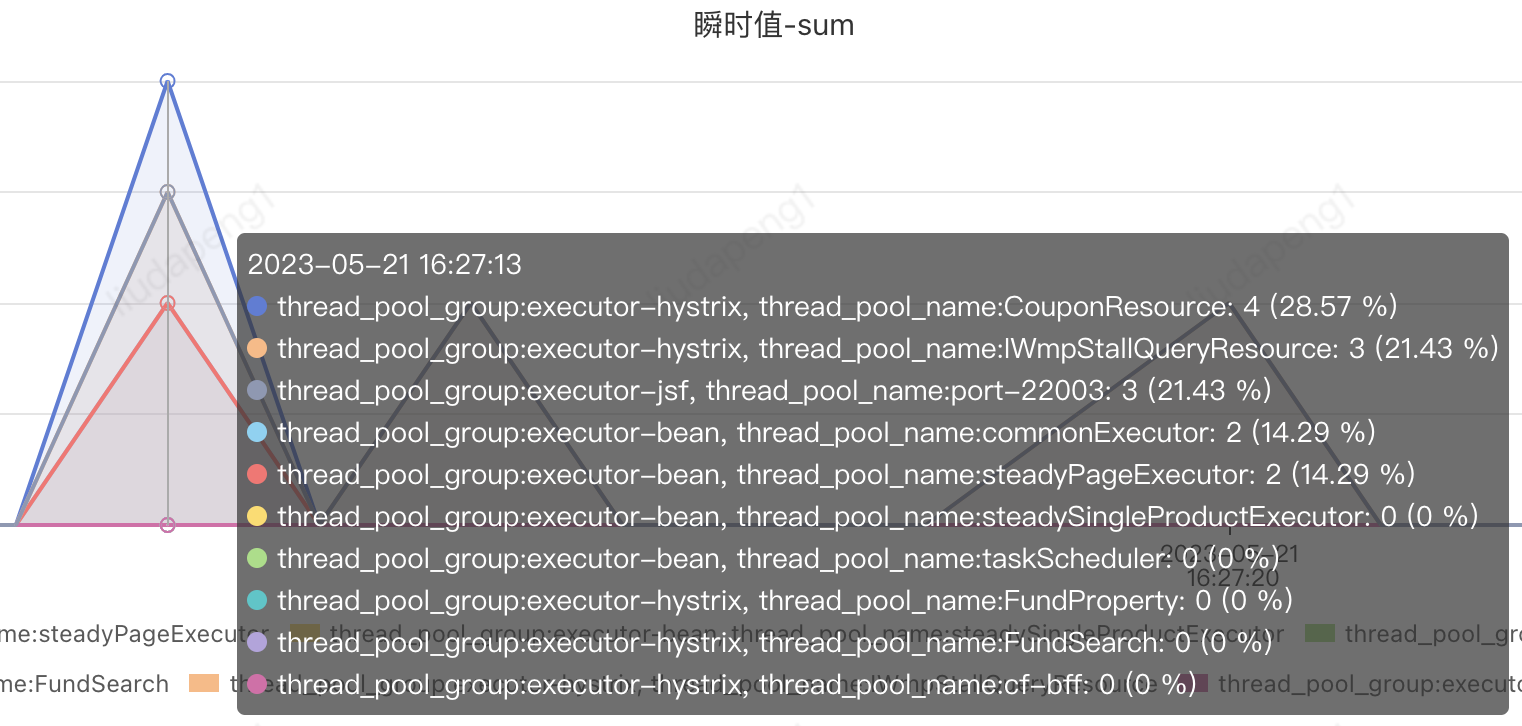
例如以下是hystrix的状态收集实现,最终可实现基于机房、分组、实例、线程池类型、名称等不同维度的状态监控:
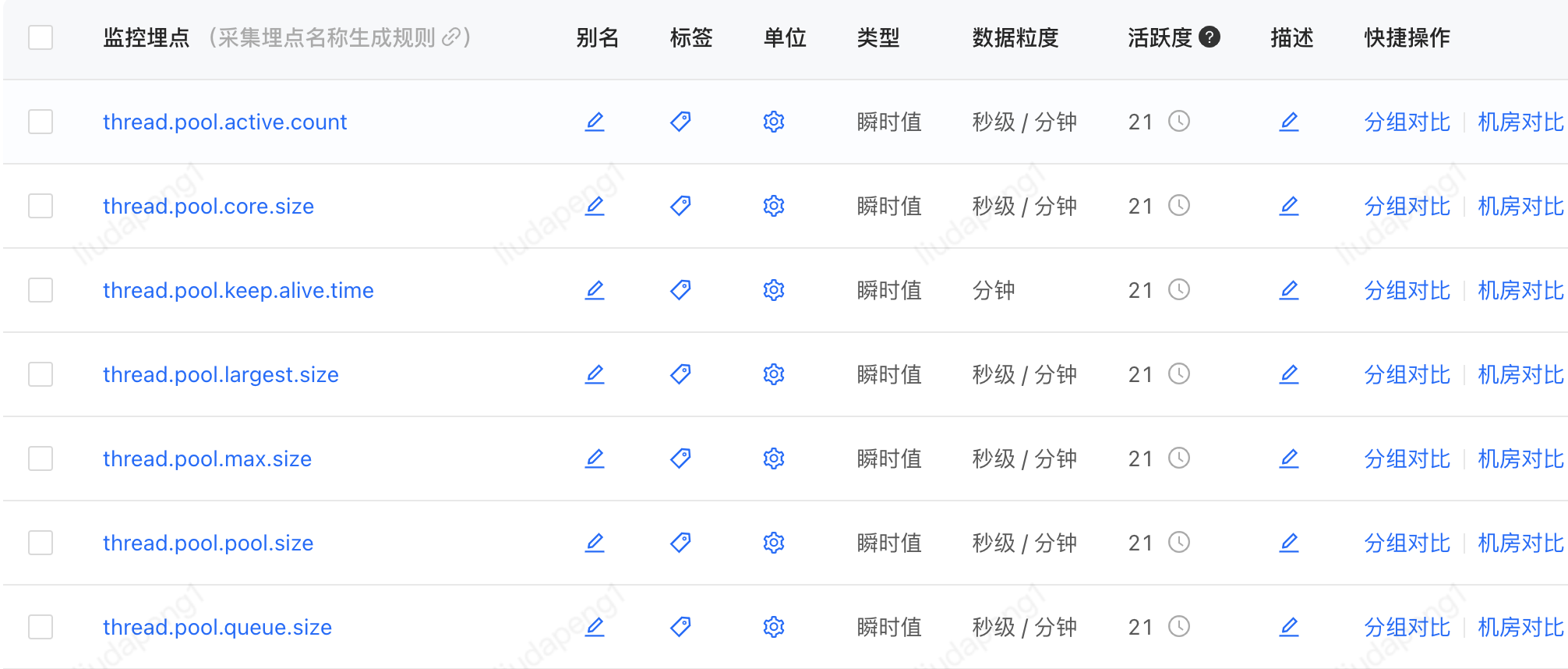
PFinder实际效果:支持不同维度组合查看及报警
7. 提供统一await future工具类
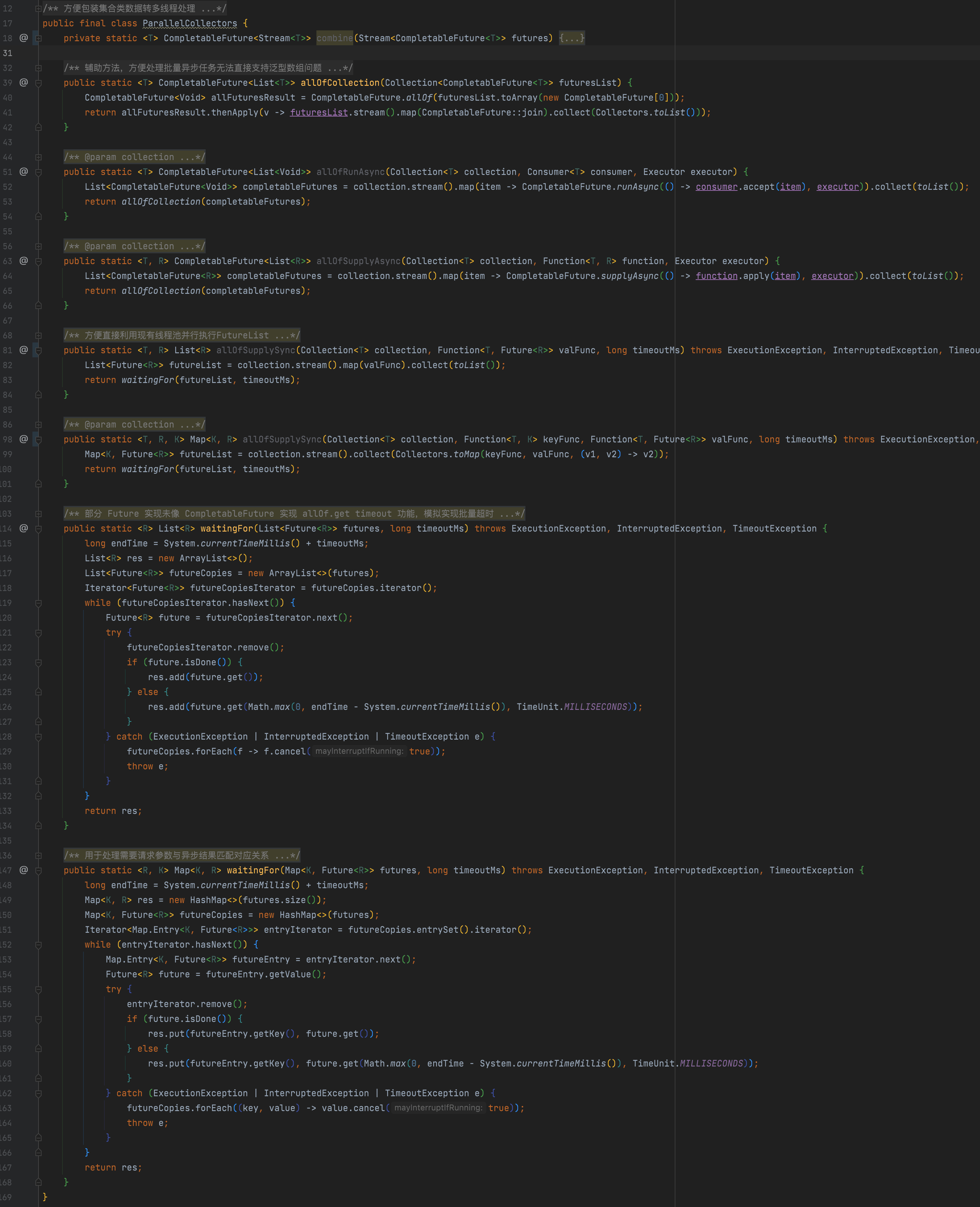
由于大部分调用是基于列表形式的异步结果List<Future<T>>、Map<String,Future<T>>,并且hystrix目前暂不支持返回CompletableFuture,方便统一await,提供工具类:
8. 其他小功能
1、除了sgm traceId支持,同时内置自定义的traceId实现,主要是处理sgm在子线程内打印traceId需要在控制台手动添加监控方法的问题以及提供对部分无sgm环境的链路Id支持,方便日志跟踪;
2、比如针对jsf调用,基于jsf过滤器实现跨应用级别的前后请求id传递支持;
3、默认增加jsf过滤器实现日志打印,同时支持provider、consume的动态日志打印开关,方便线上随时开关jsf日志,不再需要在client层重复logger.isDebugerEnabled();
4、代理层自动上报io调用方法、fallback等信息至ump,方便监控报警。
日常使用示例:
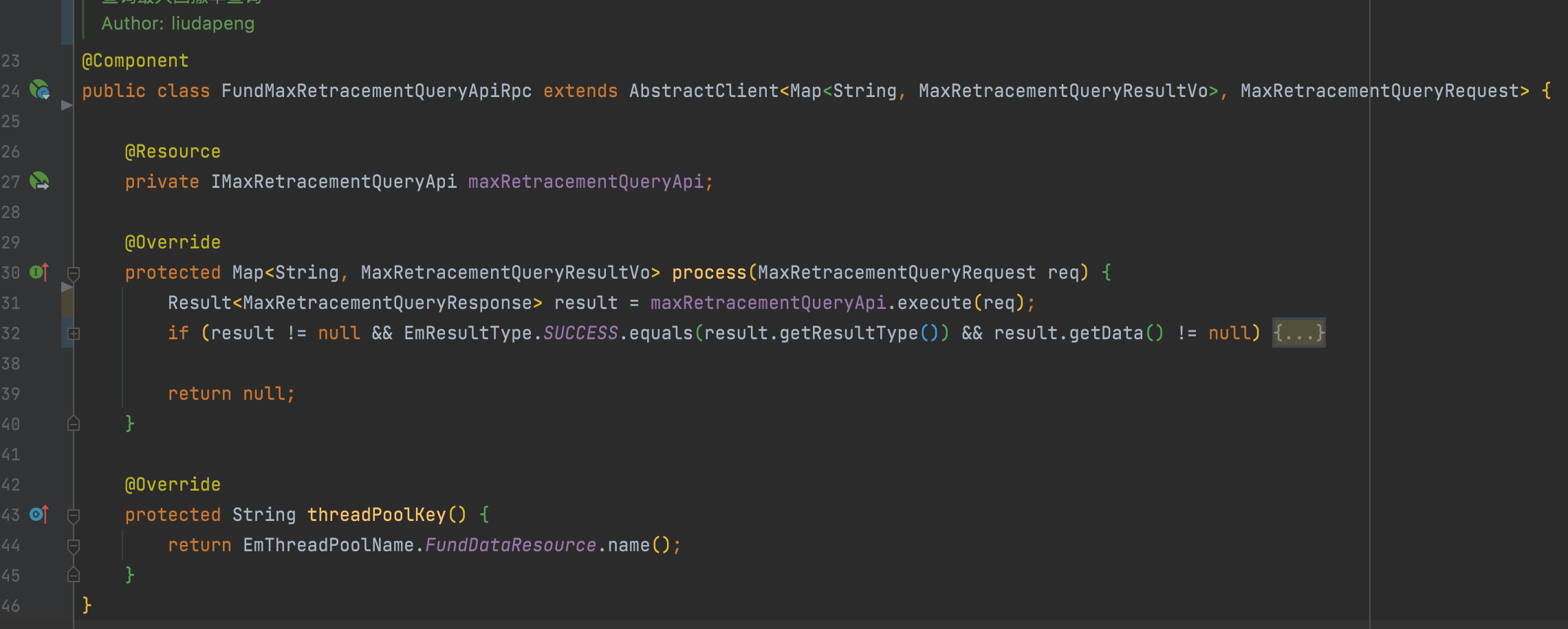
1. 一个最简单的io调用封装
仅增加继承即可支持异步回调,不重写线程池分组时使用默认分组。
2. 一个支持请求级别熔断的io调用封装
默认支持的熔断级别是服务级别,老服务仅需要继承原请求参数,实现FallbackRequest接口即可,可防止因为某一个特殊参数引起的整体接口熔断。

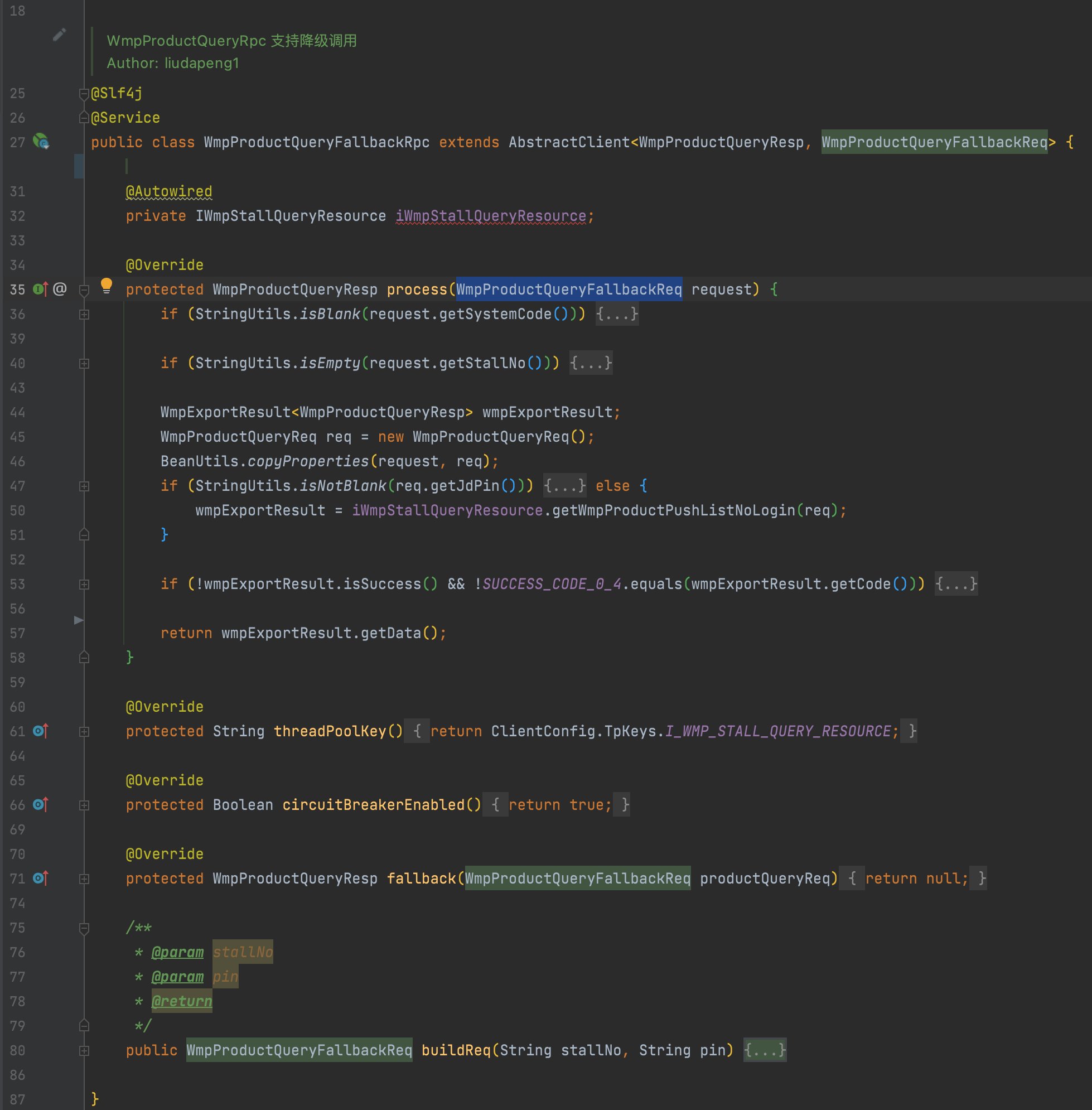
3. 一个支持请求级别缓存、接口级别熔断降级、独立线程池的io调用封装
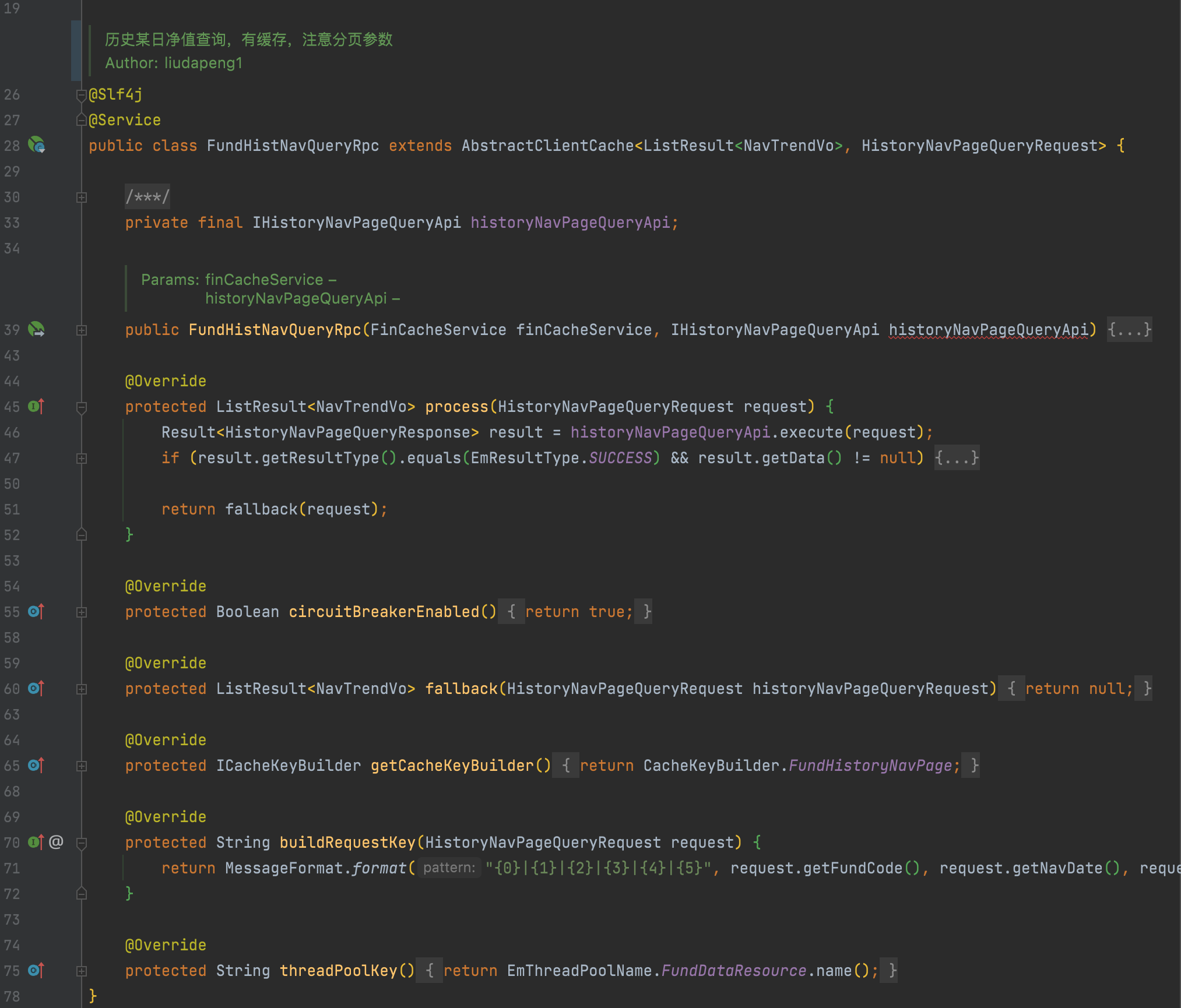
4. 上层调用,实际效果
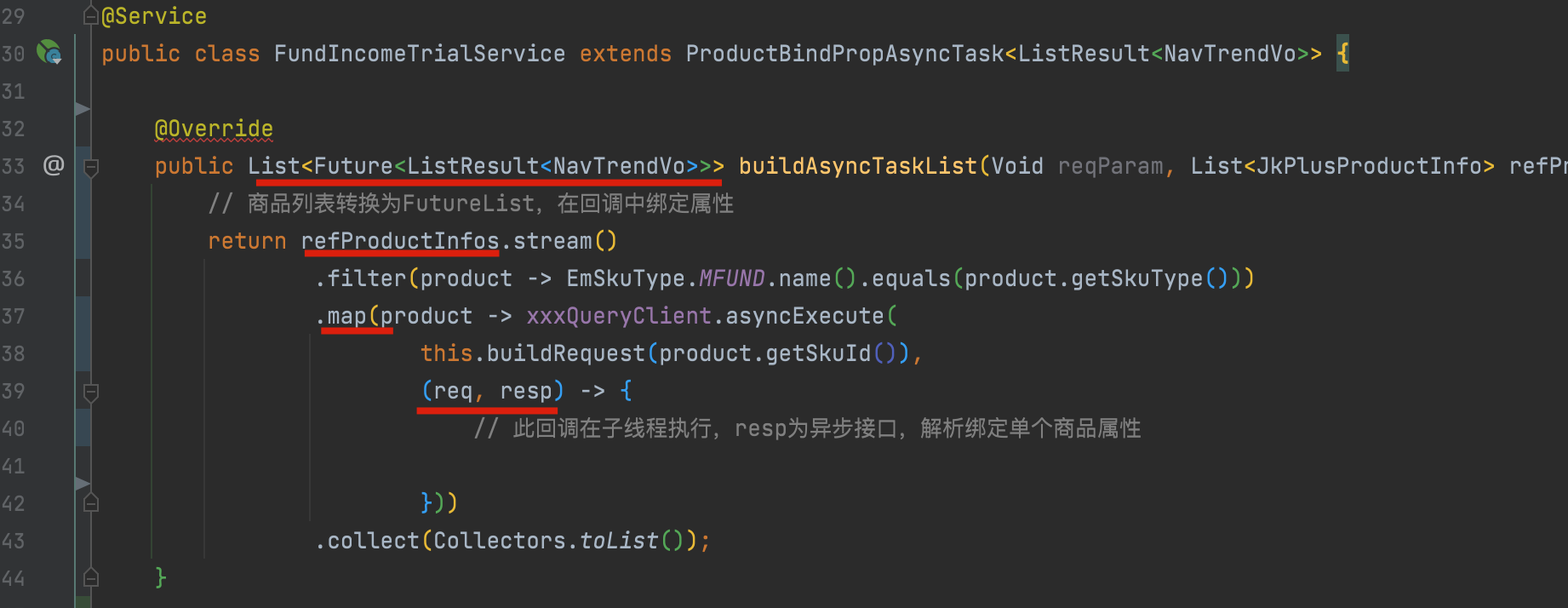
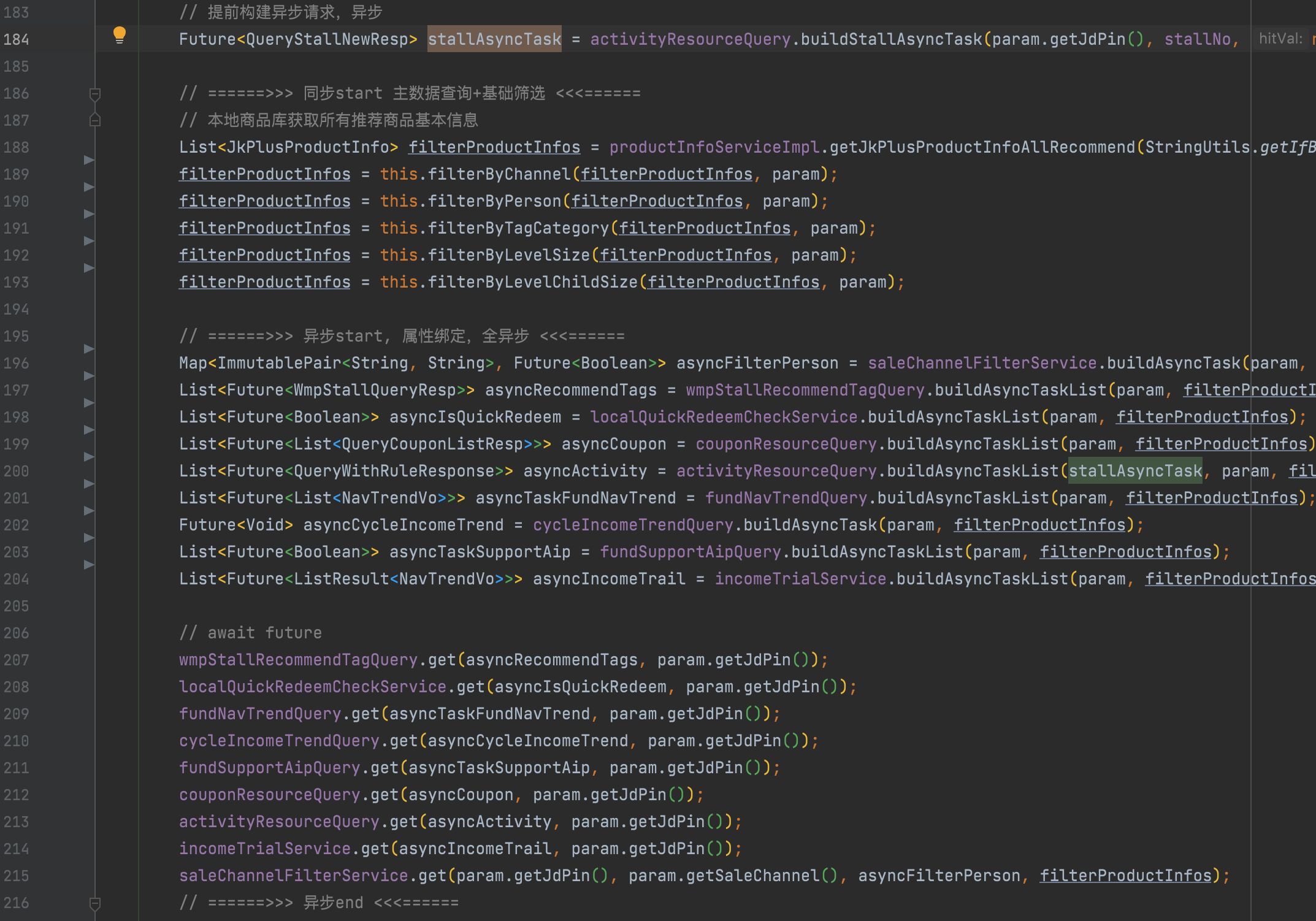
1、直接将一个商品列表转换成一个异步属性绑定任务;
2、利用工具类await List<Future<T>>;
3、在上层无感知的状态下,实现线程池的管理、熔断、降级、或缓存逻辑的增强,且可根据pfinder监控的可视化线程池状态,通过concrete实时调整线程池及超时或熔断参数;
4、举例:比如某接口频繁500ms超时,可通过配置直接打开短路返回降级结果,或者调低超时为100ms,快速触发熔断,默认10s内请求总数达到20个,50%失败时打开断路器,每隔5s半链接重试。
三、最后
本篇主要是思考如何依赖现有框架、环境的能力,从代码层面系统化的实现相关治理规范。
最后仍引用王晓老师文章结尾来结束
接口性能问题形成的原因思考我相信很多接口的效率问题不是一朝一夕形成的,在需求迭代的过程中,为了需求快速上线,采取直接累加代码的方式去实现功能,这样会造成以上这些接口性能问题。 变换思路,更高一级思考问题,站在接口设计者的角度去开发需求,会避免很多这样的问题,也是降本增效的一种行之有效的方式。 以上,共勉!



















