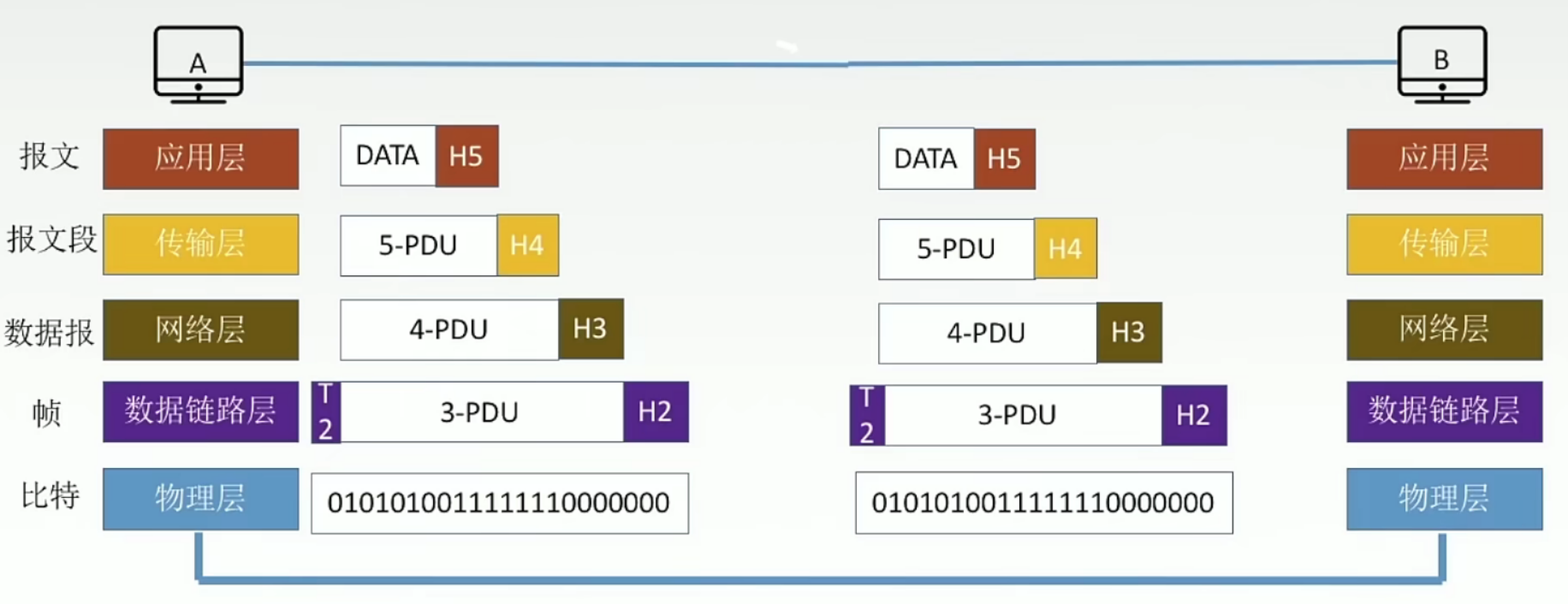
模拟k路归并
朴素思想,类比二路归并, k k k 路归并多了一些参与比较的链表。我们可以在循环体内多一层循环,找到值最小的结点,插入答案链表的尾部。
朴素算法的时间复杂度 O ( k × ∑ i = 0 k − 1 l i s t s i . s i z e ( ) ) O(k\times\sum_{i=0}^{k-1} lists_i.size()) O(k×∑i=0k−1listsi.size()) , k k k 是链表个数 , l i s t i . s i z e ( ) list_i.size() listi.size() 是第 i i i 个链表的长度。至少遍历每个结点一次,时间复杂度 O ( ∑ i = 0 k − 1 l i s t s i . s i z e ( ) ) O(\sum_{i=0}^{k-1} lists_i.size()) O(∑i=0k−1listsi.size()) 这是必须的。 找链表最小值 O ( k ) O(k) O(k) , 这一步可以用堆优化。
堆优化
建立小根堆,按链表值排序。将所有待比较结点加入堆,那么堆顶就是最小值 。
提示 : 优先队列默认大根堆 。 传入自定义的结构体,重载 “()” , 按链表值 , 建立小根堆 。 模板请背过。
class Solution {
public:
typedef struct Cmp{
bool operator () (ListNode* a,ListNode *b){
return a->val>b->val;//按链表值,建立小根堆
}
}Cmp;
ListNode* mergeKLists(vector<ListNode*>& lists) {
priority_queue<ListNode *,vector<ListNode*>, Cmp> heap;
for(auto &l:lists) if(l) heap.push(l);
auto dummy = new ListNode(-1);
auto tail = dummy;
while(heap.size()){
auto l = heap.top();
heap.pop();
if(l->next) heap.push(l->next);
tail->next = l;
tail = tail->next;
}
return dummy->next;
}
};
时间复杂度
O
(
l
o
g
k
×
∑
i
=
0
k
−
1
l
i
s
t
s
i
.
s
i
z
e
(
)
)
O(logk\times\sum_{i=0}^{k-1} lists_i.size())
O(logk×∑i=0k−1listsi.size()) ,
用堆优化了查找最小值的时间复杂度
O
(
l
o
g
k
)
O(logk)
O(logk) , 至少遍历每个结点一次,时间复杂度
O
(
∑
i
=
0
k
−
1
l
i
s
t
s
i
.
s
i
z
e
(
)
)
O(\sum_{i=0}^{k-1} lists_i.size())
O(∑i=0k−1listsi.size()) , 总时间复杂度
O
(
l
o
g
k
×
∑
i
=
0
k
−
1
l
i
s
t
s
i
.
s
i
z
e
(
)
)
O(logk\times\sum_{i=0}^{k-1} lists_i.size())
O(logk×∑i=0k−1listsi.size())
空间复杂度 O ( k ) O(k) O(k) , 堆中最多 k k k 个结点 , 空间复杂度 O ( k ) O(k) O(k) 。
博主致语
理解思路很重要!
欢迎读者在评论区留言,作为日更博主,看到就会回复的。
AC