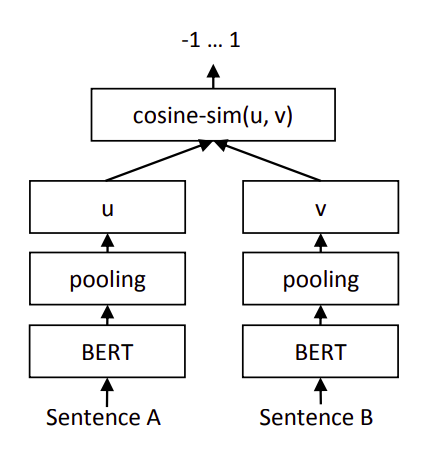
Hugging Face是一个致力于开源自然语言处理(NLP)和机器学习项目的社区。它由几个关键组件组成:
- Transformers:这是一个基于PyTorch的库,提供了各种预训练的NLP模型,如BERT、GPT、RoBERTa、DistilBERT等。它还提供了一个简单易用的API来加载这些模型,并进行微调以适应特定的下游任务。
- Datasets:这是一个用于加载和预处理NLP数据集的库,与Transformers配合使用,可以轻松地加载常见的数据集,如GLUE、SuperGLUE、SQuAD等。
- Hub:这是一个模型和数据集的存储库,用户可以上传自己的模型和数据集,并分享给社区。这使得研究人员和开发者可以轻松地访问和重用现有的资源。
- Coqa:这是一个用于问答系统研究的平台,提供了一个开放的数据集和工具,用于评估和比较不同的问答系统。
- PreTrained:这是一个用于预训练NLP模型的库,提供了各种预训练模型和数据集。
- Trainer:这是一个用于训练和评估NLP模型的库,提供了自动调整学习率、保存最佳模型、生成报告等功能。
Hugging Face社区致力于推动NLP和机器学习技术的发展,为研究人员和开发者提供了一个强大的工具和资源。通过这些工具和资源,研究人员可以更容易地构建和训练先进的NLP模型,而开发者可以更容易地将这些模型集成到他们的应用程序中。
使用PyTorch训练Transformer模型通常涉及以下步骤:
- 安装PyTorch:
如果您尚未安装PyTorch,可以使用以下命令进行安装:pip install torch pip install transformers - 准备数据:
- 加载数据集,例如使用
pandas库读取CSV文件。 - 对文本数据进行预处理,如分词、转换为小写、去除停用词等。
- 准备标签数据,确保它们是数值化的。
- 加载数据集,例如使用
- 定义模型:
- 使用PyTorch定义Transformer模型,包括编码器和解码器(如果需要)。
- 定义损失函数和优化器。
- 数据加载:
- 使用PyTorch的DataLoader将数据集分割为训练集和验证集。
- 设置批处理大小和采样器。
- 训练模型:
- 在训练循环中,将数据加载到GPU(如果可用)。
- 执行前向传播,计算损失。
- 反向传播,更新模型参数。
- 使用学习率调度器调整学习率。
- 评估模型:
- 在验证集上评估模型的性能。
- 计算准确率、召回率、F1分数等指标。
- 保存模型:
- 将训练好的模型保存到文件,以便将来使用。
以下是一个简化的代码示例,展示了如何使用PyTorch训练一个文本分类的Transformer模型:
- 将训练好的模型保存到文件,以便将来使用。
在这个代码示例中,我们首先定义了一个简单的Transformer文本分类模型,它使用了预训练的BERT模型作为编码器。然后,我们定义了一个数据集类,用于处理文本数据和标签。接着,我们创建了一个数据加载器,它将数据集分割为训练集和验证集。在训练循环中,我们使用优化器来更新模型参数,并使用学习率调度器来调整学习率。在评估循环中,我们计算模型的准确率。最后,我们将训练好的模型状态保存到文件中。
请注意,这只是一个简化的示例,实际代码可能会更复杂,具体取决于您选择的模型和配置。您还需要根据实际情况调整数据预处理和模型定义的步骤。此外,您可能需要根据您的硬件配置(如GPU可用性)来调整代码。
import torch
from torch import nn
from torch.optim import Adam
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer, BertModel, BertForSequenceClassification
# 定义Transformer模型
class TransformerTextClassifier(nn.Module):
def __init__(self, num_classes):
super(TransformerTextClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.classifier = nn.Linear(self.bert.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
logits = self.classifier(pooled_output)
return logits
# 定义数据集
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'input_ids': encoding['input_ids'],
'attention_mask': encoding['attention_mask'],
'label': torch.tensor(label, dtype=torch.long)
}
# 加载数据集
texts = ["这是一个测试文本。", "这是另一个测试文本。"]
labels = [0, 1]
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
max_len = 128
dataset = TextDataset(texts, labels, tokenizer, max_len)
dataloader = DataLoader(dataset, batch_size=16)
# 定义模型
num_classes = 2
model = TransformerTextClassifier(num_classes)
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=2e-5)
# 检查CUDA是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 训练模型
model.train()
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
# 评估模型
model.eval()
with torch.no_grad():
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
outputs = model(input_ids, attention_mask)
predictions = outputs.argmax(dim=1)
accuracy += (predictions == labels).sum().item()
print(f"Accuracy: {accuracy / len(dataset)}")
# 保存模型
torch.save(model.state_dict(), "model.pth")
在这个代码示例中,我们首先定义了一个简单的Transformer文本分类模型,它使用了预训练的BERT模型作为编码器。然后,我们定义了一个数据集类,用于处理文本数据和标签。接着,我们创建了一个数据加载器,它将数据集分割为训练集和验证集。在训练循环中,我们使用优化器来更新模型参数,并使用学习率调度器来调整学习率。在评估循环中,我们计算模型的准确率。最后,我们将训练好的模型状态保存到文件中。
提高Transformer模型准确率的方法有很多,以下是一些常见的策略:
- 数据预处理:
- 确保数据预处理步骤正确无误,包括文本清洗、分词、词干提取、词形还原等。
- 使用预训练的词向量(如BERT使用的预训练词向量),这可以提高模型对未见词汇的泛化能力。
- 模型设计:
- 调整模型结构,如增加或减少Transformer层的数量,改变自注意力机制的参数等。
- 使用注意力机制、多头注意力等高级特性来捕捉文本中的复杂关系。
- 训练策略:
- 使用更长的训练时间或更多的训练数据来提高模型对数据的拟合能力。
- 使用学习率调度器,如余弦退火(cosine annealing)或ReduceLROnPlateau,以避免过拟合并提高模型的收敛性。
- 采用dropout、正则化等技术来防止过拟合。
- 优化器选择:
- 尝试不同的优化器,如AdamW、SGD等,以找到最适合您模型的优化器。
- 调整学习率、动量、权重衰减等参数。
- 超参数调整:
- 调整批大小、学习率、权重衰减、正则化强度等超参数。
- 使用网格搜索、随机搜索或贝叶斯优化等技术自动搜索最佳超参数。
- 使用增强数据:
- 通过数据增强(如回译、同义词替换、句子混合等)来增加训练数据的多样性。
- 使用伪标签技术来扩充训练数据。
- 模型集成:
- 训练多个模型,并将它们的预测结果进行平均或投票,以提高准确率。
- 使用集成学习技术,如Bagging或Boosting。
- 特征工程:
- 考虑使用其他特征(如词频、词性等)来增强模型的表现。
- 探索文本数据的结构化表示,如词嵌入、向量空间模型等。
- 后处理:
- 考虑使用阈值调整、模型融合等技术来提高最终预测的准确率。
- 模型评估:
- 使用不同的评估指标来全面评估模型的性能,如精确率、召回率、F1分数等。
- 分析错误案例,了解模型在哪些情况下表现不佳,并针对性地进行改进。
通过上述方法,您可以逐步提高Transformer模型的准确率。需要注意的是,这些方法并不是孤立的,而是可以相互结合使用的。在实际应用中,您可能需要进行多次实验和调整,以找到最适合您任务的模型配置。
以下是一个简单的预测代码实例,展示了如何使用Hugging Face的Transformers库进行文本分类模型的预测:
from transformers import BertTokenizer, BertForSequenceClassification
# 加载模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 假设您有一段新的文本摘要
new_text = "这是一个新的测试摘要。"
# 使用tokenizer对文本进行编码
encoded_input = tokenizer.encode_plus(
new_text,
add_special_tokens=True,
max_length=512,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
truncation=True
)
# 获取编码后的结果
input_ids = encoded_input['input_ids']
attention_mask = encoded_input['attention_mask']
# 设置模型为评估模式
model.eval()
# 预测
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
# 获取预测结果
predicted_label = outputs.logits.argmax(dim=1).item()
# 打印预测结果
print(f"Predicted Label: {predicted_label}")
对于 加载模型和分词器,如果你已经拥有了自己的模型训练文件,把模型训练文件放在文件夹,填写文件夹路径即可。

如下使用GPU 开始预测:
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
# 设置模型路径和类别数量
model_path='D:/yolov8Project/transformer_txtclass/'
class_num=219
# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型和分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=class_num).to(device) # 将模型移到 GPU
def predict(new_text):
try:
# 使用tokenizer对文本进行编码
encoded_input = tokenizer.encode_plus(
new_text,
add_special_tokens=True,
max_length=512,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
truncation=True
)
# 获取编码后的结果,并将它们移到 GPU
input_ids = encoded_input['input_ids'].to(device)
attention_mask = encoded_input['attention_mask'].to(device)
# 设置模型为评估模式
model.eval()
# 预测
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
# 获取预测结果
predicted_label = outputs.logits.argmax(dim=1).item()
# 打印预测结果
print(f"Predicted Label: {predicted_label}")
return predicted_label
except Exception as e:
predicted_label='error'
return predicted_label
data2 = pd.read_csv('comb.csv', encoding='gbk')
# 在 DataFrame 上应用 predict 函数,并将结果存储在 'label' 列
data2['label'] = data2['Abstract'].apply(predict)
# print(data2)
data2.to_csv('comb-result.csv', index=False, encoding='gbk')
print('预测完毕,结束!')