评论服务
- 一、概述
- 二、单级评论模式
- 1、模型设计
- 2、分库分表必要性
- 3、高并发问题
- 三、二级评论模式
- 1、模型设计
- 2、评论审核与状态
- 3、按照热度排序
- 4、评论读取流程图
- 5、架构总览
- 四、盖楼评论模式
- 1、数据库递归查询
- 2、数据库保存完整楼层
- 3、图数据库
内容总结自《亿级流量系统架构设计与实战》
一、概述
评论作用:
- 增加社交互动
- 促进用户的参与和分享
- 促进用户生成内容
- 增加社交产品的流量
评论具备能力:
- 发布评论
- 删除评论
- 点赞评论
- 拉取内容评论列表
- 拉取用户评论列表
- 运营评论
评论模式:
- 单级评论模式
- 二级评论模式
- 盖楼评论模式
二、单级评论模式
1、模型设计
表名:comment
| 字段名 | 类型 | 含义 |
|---|---|---|
| id | bitint | 主键 |
| content_id | bitint | 内容id,代表评论区内容唯一标识 |
| comment_id | bitint | 评论id |
| user_id | bitint | 评论发布者id |
| reply_user_id | bitint | 如果时回复评论,则给出被回复的用户id,默认值为0 |
| reply_comment_id | bitint | 如果评论是回复,则给出被回复的评论id,默认值为0 |
| comment_time | datetime | 评论发布时间 |
索引:
- idx_user_list(user_id,comment_time)
- idx_comment_list(content_id,comment_time)
2、分库分表必要性
由于受限于分库分表的必要性,我们无法选择出合适的字段作为路由依据。我们可以进行数据表冗余设计:创建两个结构与comment数据表的结构完全一致的数据表content_comment和user_comment,前者将idx_comment_list(content_id,comment_time)作为索引,将content_id作为分库分表的路由依据;后者将idx_user_list(user_id,comment_time)作为索引,将user_id作为分库分表的路由依据。当查询某内容的评论列表时,评论服务会查询content_comment数据表;当查询某用户的评论列表时,评论服务则会查询user_comment数据表。
当用户发布评论、删除评论时,要同时更新content_id和user_comment这两个数据表。为了保证这两个数据表的数据一致性,我们可以选择content_comment作为主表,而user_comment数据表通过伪从技术自动同步最新的评论数据

3、高并发问题
评论是一个高并发读&高并发写的场景。
高并发读:
- 异步写
- 写聚合
高并发读:
这里的高并发读评论,特指拉取热门内容的评论列表。对于绝大部分用户来说,其拉取的评论列表是位于评论区的前几页的那些评论。所以可以为评论列表中的前N条评论构建Redis缓存。使用Redis的ZSET结构来优化,其中Key为内容ID,Member为评论ID,Score为评论发布时间。
三、二级评论模式
1、模型设计
评论元信息表:
| 字段名 | 类型 | 含义 |
|---|---|---|
| id | bitint | 主键 |
| content_id | bitint | 内容id,代表评论区内容唯一标识 |
| comment_id | bitint | 评论id |
| user_id | bitint | 评论发布者id |
| root_id | bitint | 如果评论是对内容的评论,则该字段值为内容ID;如果评论是一级评论下的评论,则该字段值为一级评论 |
| level | tinyint | 评论等级(1:一级评论;2:二级评论) |
| reply_count | bitint | 此评论被回复次数,仅一级评论需要记录 |
| like_count | bitint | 此评论被点赞次数 |
| reply_user_id | bitint | 如果评论是对内容的评论,则该字段值为0;如果评论是对某条一级评论的回复,则该字段值为此一级评论的用户ID;如果评论是对某条二级评论的回复,则该字段值为二级评论的用户ID |
| reply_comment_id | bitint | 如果评论是对内容的评论,则该字段值为0;如果评论是对某一条评论的回复,则该字段值为一级评论ID;如果评论是对某条二级评论的回复,则该字段值为此二级评论ID |
| comment_time | datetime | 评论发布时间 |
索引:
- idx_comment_list(root_id,level,comment_time):获取内容的评论区和某条评论的二级评论区的评论列表
- idx_user_comment(user_id,comment_time):用于获取用户的历史评价
2、评论审核与状态
可参考之前的内容发布系统
3、按照热度排序
热度评判维度:
- 点赞数
- 回复数
- 点赞数与回复数加权
对于按照热度排序的评论列表,有如下几个重点要说明:
- 按照热度排序,并不意味着一个评论区中的所有评论都遵循此规则。当我们打开评论区时,首先展示的是热度排名前1000(示例值)的评论,在评论区中刷完这1000条评论后,我们看到的依然是按照评论发布时间由远及近排序的评论
- 如果一条评论没有任何点赞,没有任何回复,即热度值为0,则不属于热门评论,故不参与热度排名。如果一个评论区中只有50条热门评论,那么用户打开评论区刷完这50条评论后,展示的是按照评论发布时间排序的评论列表
- 在刷完热门评论后,按照评论发布时间排序的评论列表中依然可能会包含热门评论,也就是说,用户会刷到重复的评论。比如,微博的评论列表就会发现,热门评论会重复出现在按照评论发布时间由近及远排序的评论列表中
流程图

4、评论读取流程图

5、架构总览

四、盖楼评论模式
1、数据库递归查询
借助数据库的递归查询能力,直接实现
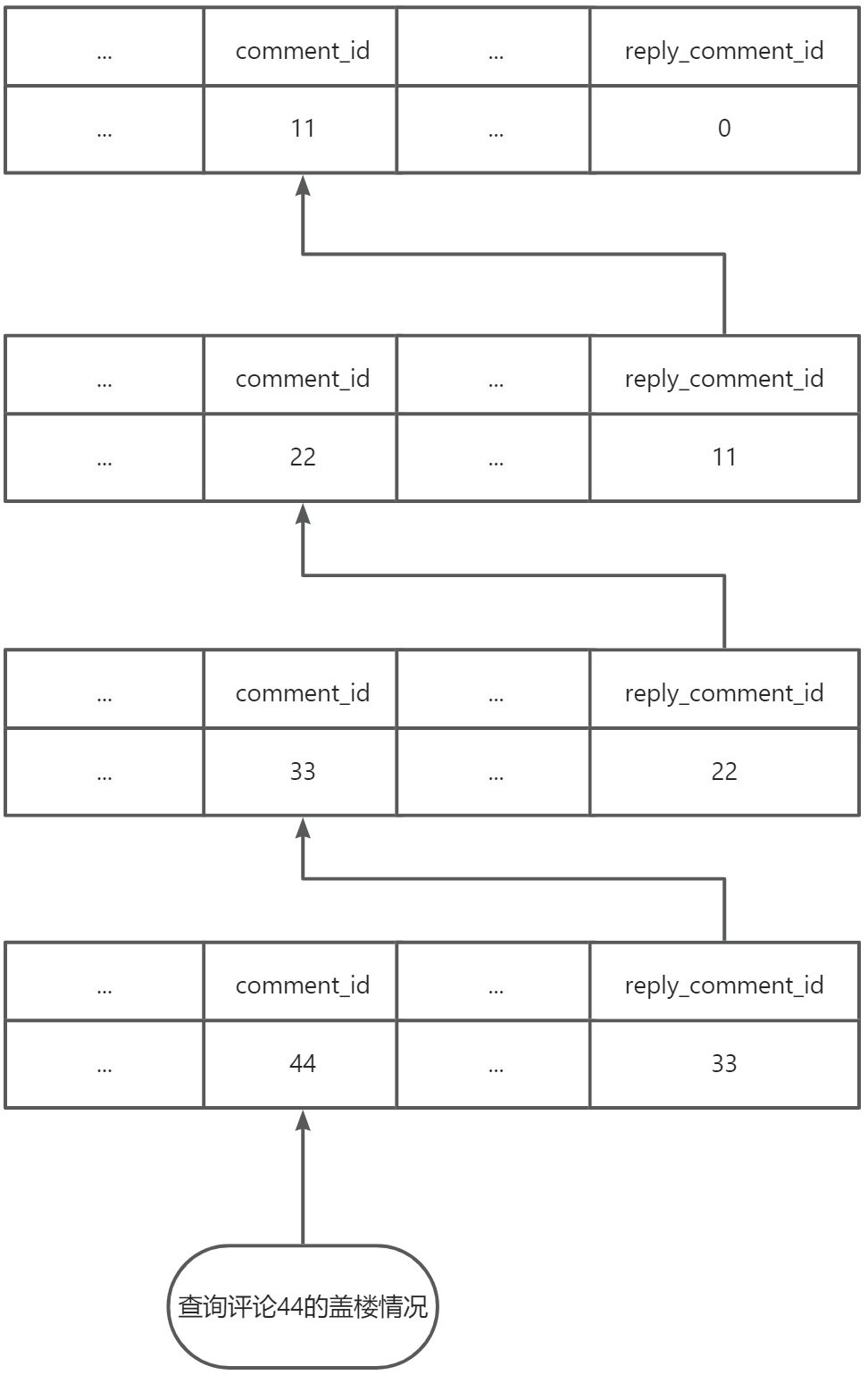
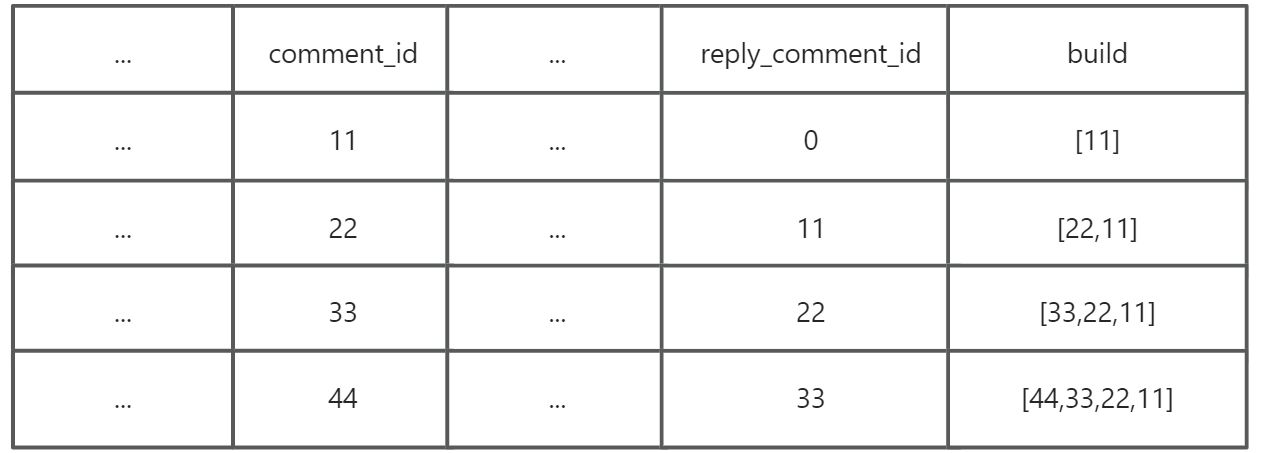
2、数据库保存完整楼层
单独新增一个build字段,用来保存所有的评论id
3、图数据库
评论间的回复关系本质上就是一个树形结构,所谓盖楼评论无非就是在此树形结构中对某个评论节点进行深度遍历,所以在盖楼模式下非常适合使用图数据库。