我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE课程笔记 第9课: 归约(也对应PMPP的第10章)
课程笔记

本节课的题目。

这节课的内容主要是 Chapter 10 of PMPP book ,Slides里面还给出了本节课的代码所在位置以及如何编译以及使用nsight compute进行profile。

这张slides给出了reduction(归约)操作的定义,reduction(归约)是减少输出大小的操作。最典型的reduction操作是将向量(vector)转换为标量(scalar)。然后还列举了一些常见的reduction操作,包括min(最小值),max(最大值),argmax(最大值的索引),argmin(最小值的索引),norm(范数),sum(求和),prod(乘积),mean(平均值),unique(唯一值)。https://github.com/cuda-mode/lectures/blob/main/lecture_009/torch_reductions.py 这个文件展示了一些 reduction 操作的例子。
def reduce(data, identity, op):
result = identity
for element in data:
result = op(result, element)
return result
# Example usage:
# Summation
data = [1, 2, 3, 4, 5]
print(reduce(data, 0, lambda a, b: a + b)) # Output: 15
# Product
print(reduce(data, 1, lambda a, b: a * b)) # Output: 120
# Maximum
print(reduce(data, float('-inf'), max)) # Output: 5
# Minimum
print(reduce(data, float('inf'), min)) # Output: 1
在PyTorch中有一个通用的Recuce算子来做所有的归约操作,所以你不能看到reduce_max这种单独的算子。

这张Slides强调了归约操作在深度学习和机器学习中的普遍性,例如:
- Mean/Max pooling(平均/最大池化):这是在卷积神经网络中常用的操作,用于减少特征图的空间尺寸,提取主要特征。
- Classification: Argmax(分类:最大值索引):在分类任务中,通常使用argmax来确定最可能的类别。
- Loss calculations(损失计算):在训练过程中,通常需要计算损失函数,这往往涉及到对多个样本损失的归约操作。
- Softmax normalization(Softmax归一化):在多分类问题中,Softmax用于将原始的输出分数转换为概率分布,这个过程也涉及归约操作。

这张Slides展示了一个PyTorch使用归约操作(在这个case中是求最大值)来处理张量数据的例子。我们可以看到torch.max这个算子的实现是在 https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/cuda/ReduceOps.cpp 这里,并不是一个单独的kernel实现,而是注册为通用的Reduce Op里面的其中一个。

这张Slides展示了一个"串行归约"(Serial reduction)的例子,具体是关于最大值(Max)操作的过程。
- 处理方法如下:
- “Go through elements 1 by 1”(逐个遍历元素)
- “Compare new number to old max if greater then update”(将新数字与当前最大值比较,如果更大则更新)
- 右侧图示展示了具体的迭代过程:
- 初始向量(Initial Vector)是 [5, 2, 8, 1]
- 迭代1:[5](第一个元素作为初始最大值)
- 迭代2:[5, 5](2小于5,最大值保持不变)
- 迭代3:[5, 5, 8](8大于5,更新最大值)
- 迭代4:[5, 5, 8, 8](1小于8,最大值保持不变)

这张Slides主要展示了数据处理中的两种策略:转换(Transformation)和归约(Reduction),以及它们各自的线程策略。继续看归约是怎么做的。

- 这张Slides展示了并行归约(Parallel Reduction)的可视化过程,主要讲解了如何通过并行计算找出一个向量中的最大值。
- 算法步骤:
- 每一步取一对元素,计算它们的最大值,并将新的最大值存储在新向量中。
- 重复这个过程,直到向量中只剩下1个元素。
- 整个过程需要 O(log n) 步完成,其中 n 是初始向量的元素数量。
- Slides右边的图展示了具体的归约过程:
- 初始向量:[5, 2, 8, 1, 9, 3, 7, 4, 6, 0]
- 第1步归约:[5, 8, 9, 7, 6]
- 第2步归约:[8, 9, 7]
- 第3步归约:[9, 9]
- 最终步骤:[9]
这个算法是后续cuda kernel实现的基础。
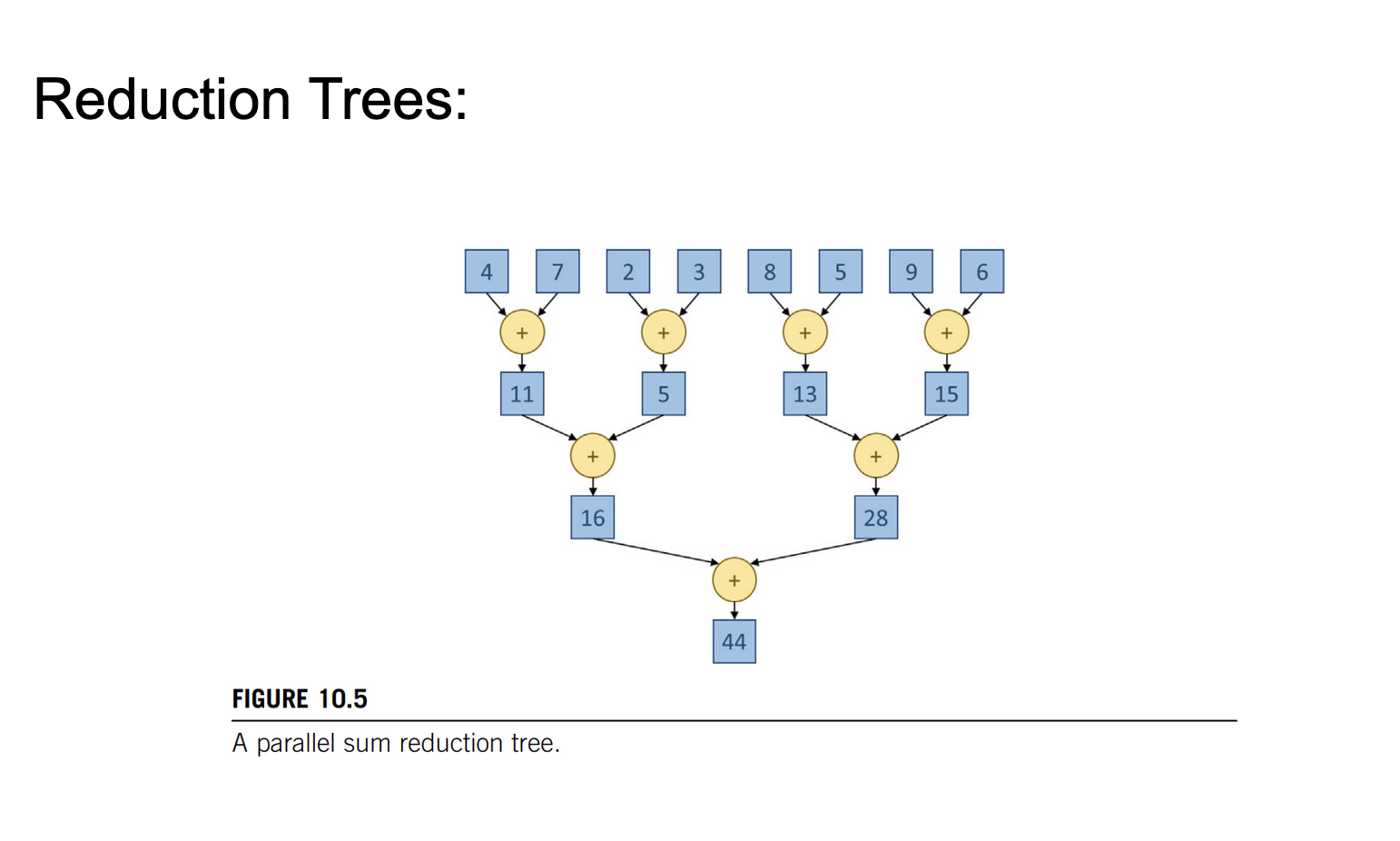
这张Slides以树的方式可视化了上面的并行Reduction算法,只不过这里是求和而不是求最大值了。这里需要注意的是,浮点数加法不满足交换律,即A=B不等于B+A,使用PyTorch时这一点经常引起混淆。在这个例子中,我们无法控制GPU线程执行的先后顺序,所以无法控制合并两个元素的顺序,这也是不确定性的源头之一。

PyTorch中使用torch.use_deterministic_algorithms(True)来控制使用确定性的算法,但是这种算法一般会降低运行速度。https://github.com/cuda-mode/lectures/blob/main/lecture_009/nondeterminism.py 这个文件举了一个例子说明由于浮点数精度问题导致求和结果的不确定性的问题。
# We'll use several small numbers that, when added together first, could show a difference
numbers = [1e-20] * 10 + [1e20, -1e20] # 10 small numbers followed by a large positive and negative number
# Sum the list from left to right
sum_left_to_right_adjusted = sum(numbers)
# Sum the list from right to left
sum_right_to_left_adjusted = sum(reversed(numbers))
# 0.0 9.999999999999997e-20
print(sum_left_to_right_adjusted, sum_right_to_left_adjusted)
另外想说明的问题是在《CUDA-MODE课程笔记 第7课: Quantization Cuda vs Triton》讲到过即使是进行INT4/INT8量化时,累加运算往往在更高的精度下运行,其原因在于如果你在float16中累加许多小的数值,最后可能会出现大数吃小数的情况。解决方法有两种:要么使用bf16这种具有更高动态范围的数据类型,要么在float32高精度上进行累加。例如当我们查看Triton矩阵乘法的教程时,我们会发现他的累加器一般都是float32。这个例子的代码为:https://github.com/cuda-mode/lectures/blob/main/lecture_009/accuracy.py
import torch
large_value = torch.tensor([1000.0], dtype=torch.float32) # Using float32 for initial value
# Define a smaller value that is significant for float32 but not for float16
small_value = torch.tensor([1e-3], dtype=torch.float32) # Small value in float32
# Add small value to large value in float32
result_float32 = large_value + small_value
# Convert large value to float16 and add the small value (also converted to float16)
result_float16 = large_value.to(torch.float16) + small_value.to(torch.float16)
# Convert results back to float32 for accurate comparison
result_float32 = result_float32.item()
result_float16_converted = result_float16.to(torch.float32).item()
# Print results
# 1000.0009765625 1000.0
print(result_float32, result_float16_converted)

这张Slides建议结合 https://github.com/cuda-mode/lectures/blob/main/lecture_009/simple_reduce.cu 实现代码来看:
__global__ void SimpleSumReductionKernel(float* input, float* output) {
unsigned int i = 2 * threadIdx.x;
for (unsigned int stride = 1; stride <= blockDim.x; stride *= 2) {
if (threadIdx.x % stride == 0) {
input[i] += input[i + stride];
}
__syncthreads();
}
if (threadIdx.x == 0) {
*output = input[0];
}
}
对于SimpleSumReductionKernel来说,每个线程负责处理两个相邻的元素,这就是为什么Slides中显示8个线程处理16个元素。然后for 循环实现了归约过程,对应图中的每一层。stride 从1开始,每次迭代翻倍,这解释了为什么每次迭代活跃线程数减半。
- 我们可以模拟一下归约的过程:
- 第一次迭代 (stride = 1): 每个线程将相邻的两个元素相加。
- 第二次迭代 (stride = 2): 每隔一个线程进行计算,将间隔为2的元素相加。
- 以此类推,直到最后只有一个线程(线程0)进行最后的加法。
- 此外,cuda代码中
__syncthreads()确保每次迭代后所有线程同步。 - 代码中的 if (threadIdx.x % stride == 0) 条件导致了Slides中提到的线程不活跃问题。
- CUDA中,线程以32个为一组(称为warp)执行。由于这种归约方式,很快就会有整个warp变得不活跃,这就是Slides提到的 “A lot of warps will be inactive” 的原因。
- kernel启动设置:SimpleSumReductionKernel<<<1, size / 2>>>(d_input, d_output); 启动了 size/2 个线程,对应图中的8个线程(假设 size 为16)。
- Slides建议使用 “ncu -set full” 进行性能分析,这可能会揭示更多关于线程和warp效率的详细信息。

这个版本的代码在T4 GPU上的分支效率为74%。

当我们尝试对上面的kernel进行优化时,我们要牢记在Lecture 8里讲到的CUDA性能检查清单。我们的优化将涉及到Control divergence,Memory divergence,最小化全局内存访问,线程粗化等等。
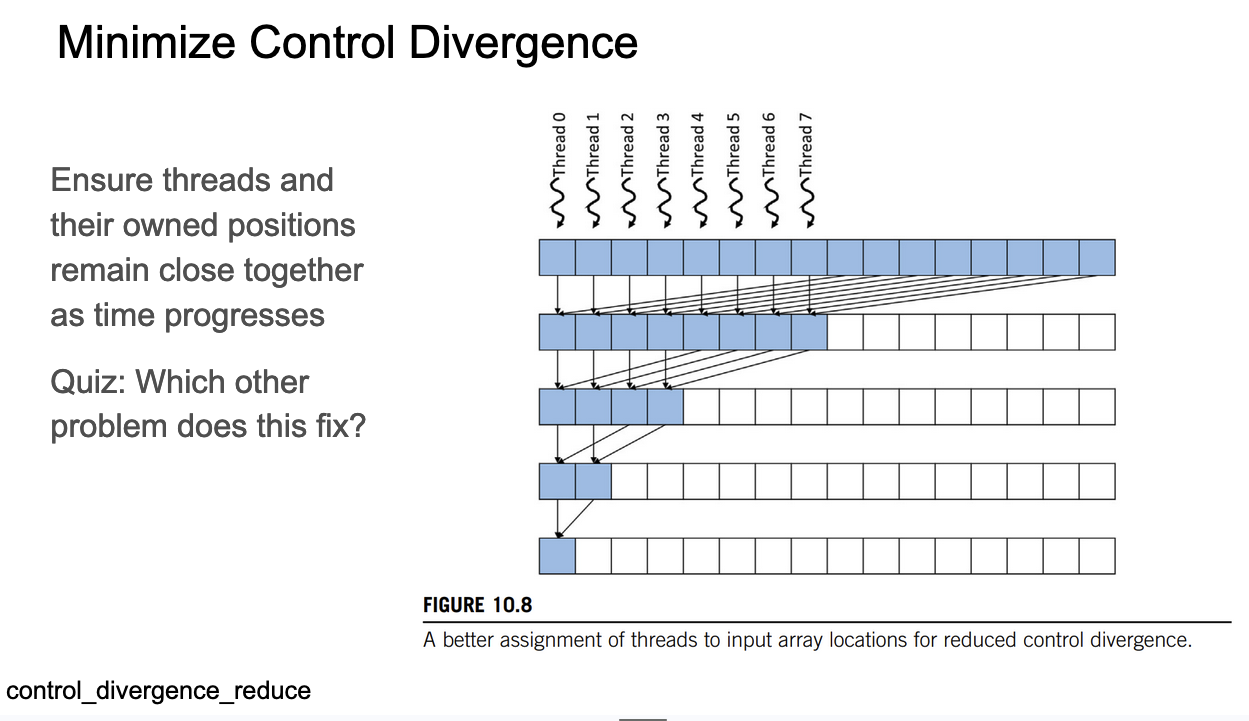
这张Slides对应的代码是:https://github.com/cuda-mode/lectures/blob/main/lecture_009/control_divergence_reduce.cu ,我们要结合代码中的kernel实现来看:
__global__ void FixDivergenceKernel(float* input, float* output) {
unsigned int i = threadIdx.x; //threads start next to each other
for (unsigned int stride = blockDim.x; stride >= 1; stride /= 2) { // furthest element is blockDim away
if (threadIdx.x < stride) { //
input[i] += input[i + stride]; // each thread adds a distant element to its assigned position
}
__syncthreads();
}
if (threadIdx.x == 0) {
*output = input[0];
}
}
Slides和对应的CUDA kernel代码都在讲解如何减少控制分歧(control divergence)并提高并行计算效率。
- Slides的关键点: “Ensure threads and their owned positions remain close together as time progresses” (确保线程及其拥有的位置随时间推移保持接近)。这正是kernel实现的核心思想。
- Slides图中展示了多个线程(Thread0到Thread7)如何协同工作。每一行代表一个时间步,蓝色方块表示活跃的线程。随着时间推移,活跃线程数量减少,但它们保持紧密相邻。
- 操作的实现方式为,步长从blockDim.x开始,并且在每次迭代中,我们把步长除以2,而不是以前那样乘以2,因此直觉上我们希望Stride随着时间推移逐渐减小,这样线程在内存中被合并处理的可能性大大增加。
- kernel的启动方式和之前的原始实现保持一致。
这里还解释了一下Slides图中的树状迭代的逻辑实际上是因为每次迭代之后的__syncthreads()来完成的。
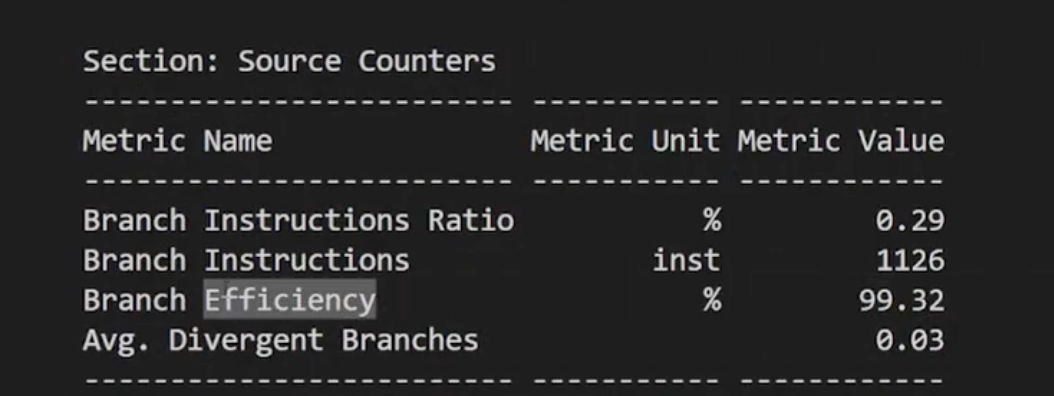
从ncu的结果可以看到,相比于初始版本,这里的分支效率为99%,相比于初始的74%,这种优化确实是有效的。

此外,ncu的结果还显示当前kernel的L1 Cache命中率为66.88%,这个和下一个shared memory优化相关。

这张Slides对应的代码是:https://github.com/cuda-mode/lectures/blob/main/lecture_009/shared_reduce.cu , kernel实现为:
#define BLOCK_DIM 1024
// This is the code from the book but I couldn't get this to run faster even with occupancy calculator
// L1 throughput is dramatically increased though
__global__ void SharedMemoryReduction(float* input, float* output) {
__shared__ float input_s[BLOCK_DIM];
unsigned int t = threadIdx.x;
input_s[t] = input[t] + input[t + BLOCK_DIM];
for (unsigned int stride = blockDim.x/2; stride >= 1; stride /=2) {
__syncthreads();
if (threadIdx.x < stride) {
input_s[t] += input_s[t + stride];
}
}
if (threadIdx.x == 0) {
*output = input_s[0];
}
}
这张Slides和对应的CUDA kernel代码主要讲解如何通过使用共享内存来最小化全局内存访问,从而提高性能。
- Slides的关键点:
- “Initial load from global memory”(初始从全局内存加载)
- “Subsequent writes and reads continue in shared memory”(后续的读写在共享内存中进行)
- Slides的图中展示了多个线程(Thread 0到Thread 7)如何协同工作。蓝色方块代表全局内存,绿色方块代表共享内存。箭头表示数据移动和计算过程。
- 代码解析:
__shared__ float input_s[BLOCK_DIM];声明了一个共享内存数组。input_s[t] = input[t] + input[t + BLOCK_DIM];从全局内存加载数据到共享内存,并进行初步计算。这对应Slides中的"Initial load from global memory"。__syncthreads();确保所有线程在进入下一迭代前完成当前操作。
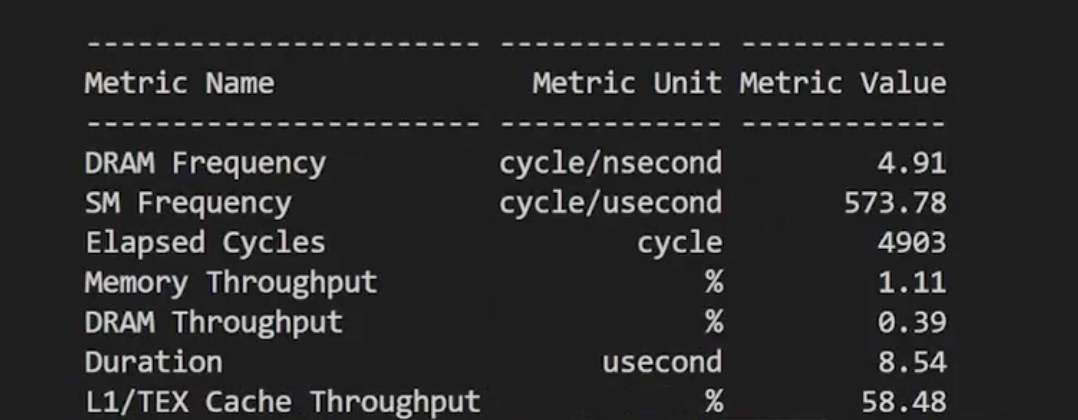
从ncu的结果来看,L1 Cache命中率提升到了60%。不过尽管L1缓存吞吐量显著提高,但实际运行速度可能没有明显提升。这可能是因为其他因素(如全局内存带宽、线程同步开销等)成为了新的瓶颈。
尝试增加这个kernel的输入数据量的时候我们发现kernel结果会出错,这是因为kernel里面的shared memory的大小限制为了1024。在GPU上一般不会做规模着么小的任务。
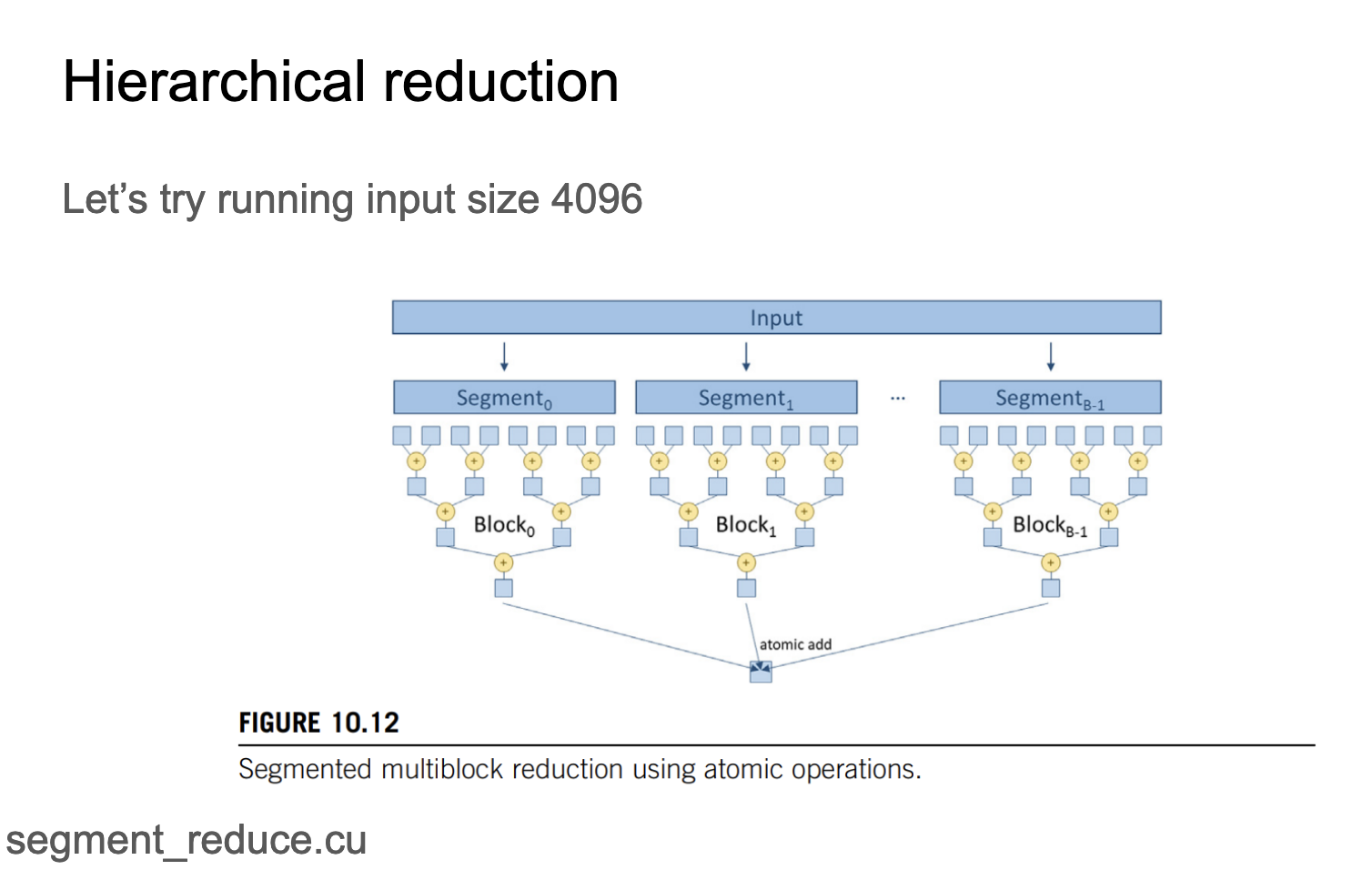
这张Slides实际上就是说在GPU上使用多个Block来分段处理数据,上面的2个版本的程序都只启动了一个Block,如下图所示:

这张Slides展示的做法就是启动多个Block,然后只要每个单独的Block可以容纳1024分元素,我们就可以在不同的Block中单独进行归约操作,最后再对所有的Block进行一次最后的归约。
这里对应的代码实现为:https://github.com/cuda-mode/lectures/blob/main/lecture_009/segment_reduce.cu ,贴一下这个代码:
#include <iostream>
#include <cuda.h>
#define BLOCK_DIM 1024
__global__ void SharedMemoryReduction(float* input, float* output, int n) {
__shared__ float input_s[BLOCK_DIM];
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x; // index within a block
unsigned int t = threadIdx.x; // global index
// Load elements into shared memory
if (idx < n) {
input_s[t] = input[idx];
} else {
input_s[t] = 0.0f;
}
__syncthreads();
// Reduction in shared memory
for (unsigned int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (t < stride && idx + stride < n) {
input_s[t] += input_s[t + stride];
}
__syncthreads();
}
// Reduction across blocks in global memory
// needs to be atomic to avoid contention
if (t == 0) {
atomicAdd(output, input_s[0]);
}
}
int main() {
// Size of the input data
const int size = 100000;
const int bytes = size * sizeof(float);
// Allocate memory for input and output on host
float* h_input = new float[size];
float* h_output = new float;
// Initialize input data on host
for (int i = 0; i < size; i++) {
h_input[i] = 1.0f; // Example: Initialize all elements to 1
}
// Allocate memory for input and output on device
float* d_input;
float* d_output;
cudaMalloc(&d_input, bytes);
cudaMalloc(&d_output, sizeof(float));
// Copy data from host to device
float zero = 0.0f;
cudaMemcpy(d_output, &zero, sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_input, h_input, bytes, cudaMemcpyHostToDevice);
// Launch the kernel
int numBlocks = (size + BLOCK_DIM - 1) / BLOCK_DIM;
SharedMemoryReduction<<<numBlocks, BLOCK_DIM>>>(d_input, d_output, size);
// Copy result back to host
cudaMemcpy(h_output, d_output, sizeof(float), cudaMemcpyDeviceToHost);
// Print the result
std::cout << "Sum is " << *h_output << std::endl;
// Cleanup
delete[] h_input;
delete h_output;
cudaFree(d_input);
cudaFree(d_output);
return 0;
}
代码中需要特别注意的是kernel的最后一句代码,这是当我们把所有的Block处理完之后,我们进行最后一层的归约操作。我们在Block层面做归约是跨global memory的,这个时候需要使用atomicAdd来避免多个Block在同一个位置写的时候出现竞争错误。
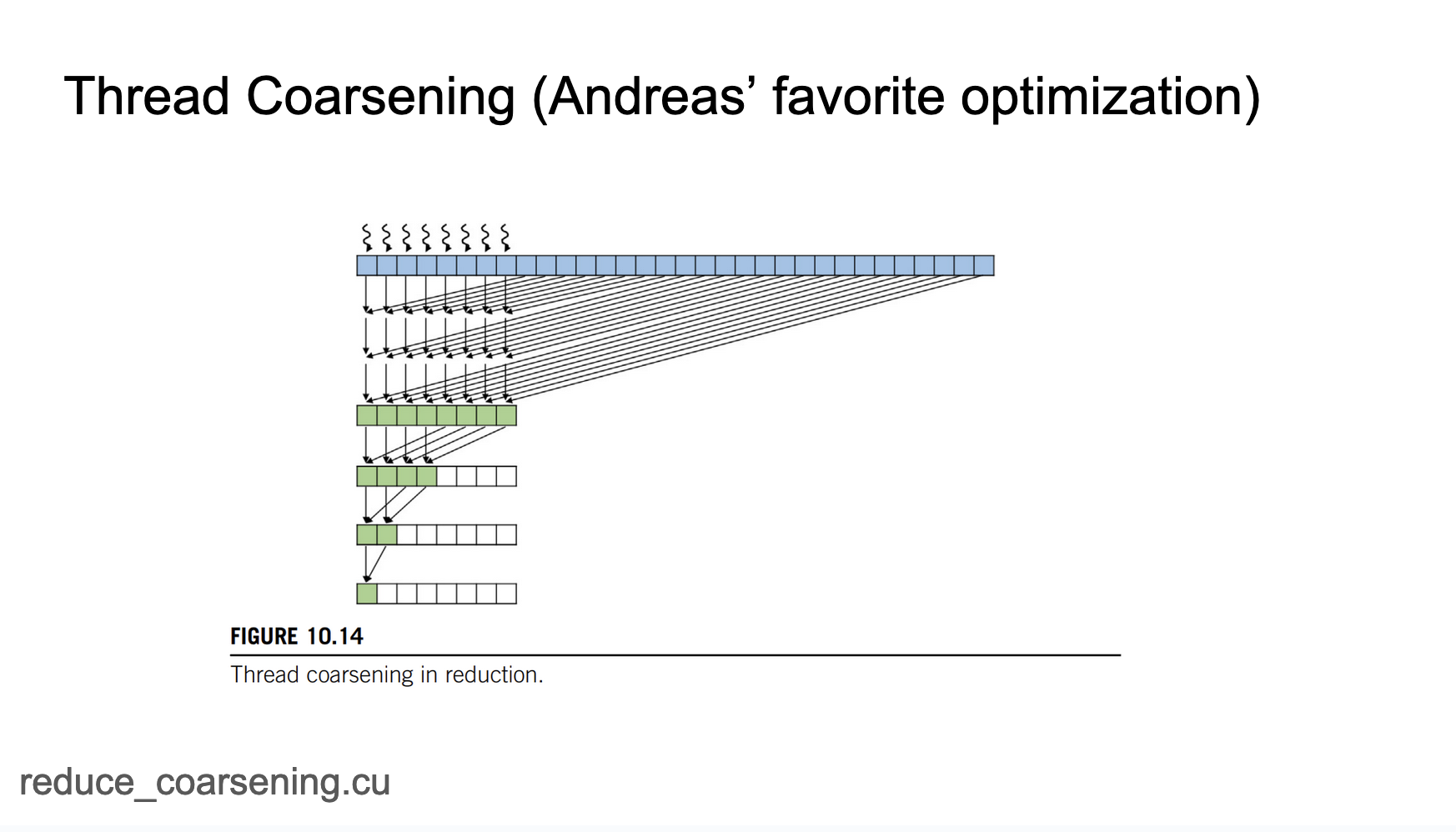
再介绍一种优化策略-线程粗化。我们之前的策略是确保每个线程基本上每次只累加2个元素,可以想一下如果每个线程累加4个或者8个元素会怎么样呢?这个优化对应的代码在 https://github.com/cuda-mode/lectures/blob/main/lecture_009/reduce_coarsening.cu ,kernel实现为:
#define BLOCK_DIM 1024
#define COARSE_FACTOR 2
__global__ void CoarsenedReduction(float* input, float* output, int size) {
__shared__ float input_s[BLOCK_DIM];
unsigned int i = blockIdx.x * blockDim.x * COARSE_FACTOR + threadIdx.x;
unsigned int t = threadIdx.x;
float sum = 0.0f;
// Reduce within a thread
for (unsigned int tile = 0; tile < COARSE_FACTOR; ++tile) {
unsigned int index = i + tile * blockDim.x;
if (index < size) {
sum += input[index];
}
}
input_s[t] = sum;
__syncthreads();
//Reduce within a block
for (unsigned int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (t < stride) {
input_s[t] += input_s[t + stride];
}
__syncthreads();
}
//Reduce over blocks
if (t == 0) {
atomicAdd(output, input_s[0]);
}
}
COARSE_FACTOR这个参数控制一个线程在一个iter里面累加多少次元素,一次就是累加2个元素,2次就是累加4个元素。这个kernel和上一个分段归约比较类似,不过现在的第一次归约是在单个线程内部进行归约,一旦一个线程上完成了归约,接下来就需要在一个线程块内进行归约,最后是在Block间进行最后的归约。
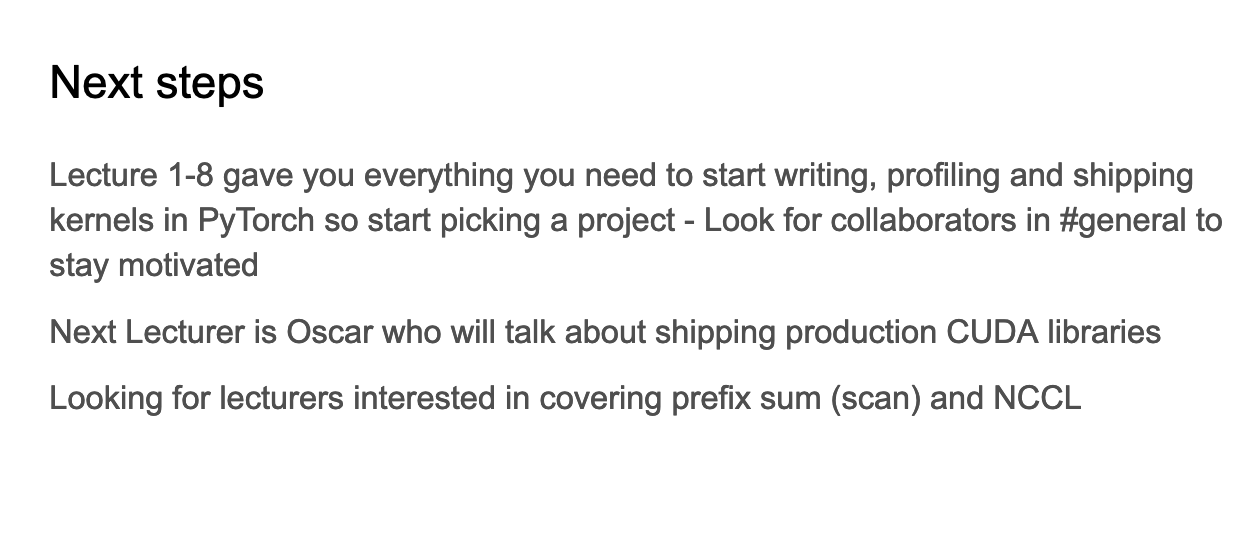
- 这张Slides标题为"Next steps"(下一步),主要内容包括:
- 回顾和建议:
- 讲座1-8已经提供了开始编写、分析和部署PyTorch内核所需的全部内容。
- 建议学生开始选择一个项目。
- 鼓励在#general频道寻找合作者以保持动力。
- 下一位讲师介绍:
- 下一位讲师是Oscar。
- Oscar将讲解如何部署生产级CUDA库。
- 寻找讲师:
- 正在寻找有兴趣讲解前缀和(scan)和NCCL的讲师。

作者还额外准备了几张Slides让大家了解一下深度学习框架中归约操作是如何实现的。

例如,以PyTorch为例子,已经有了一系列面向用户的归约操作,比如torch.max/torch.min,torch.mean等等。这些操作是如何用CUDA Kernel实现的呢?我们从上面最后两个版本的优化可以注意到,这些优化考虑是为了输入数据很大的时候做的,但如果输入数据很小,那么上面的所有考虑都变得没有意义了,使用非分段的Reduction算法更合理。对多个维度的数据进行归约应该怎么做?当输入和输出的数据类型发生变化时,我们需要的实现吗?我们是否应该考虑修改累加器的dtype呢?因此,如果你尝试写一个广泛适用的kernel,你需要考虑很多因素。因为如果你构建的kernel仅仅适用于特定的场景,这意味着你的二进制文件会非常庞大,因为你需要为每一种不同的排列组合都在代码库中加入一个kernel。而如果你拥有的是一个更侧重代码生成并具备启发式方法来选择适合kernel的系统,那么你的框架很可能会持续成为人们进行实验探索的平台。这正是PyTorch取得成功的一大关键因素。这种哲学理念在实践中的一个例子基本上就是我们的reduce kernel,所以PyTorch的reduction kernel并不是像我们有一个max.cuh/mean.cuh那样,而是只有一个单独的Reduce.cuh,因为所有的归约操作都具有相同的结构,它们在数学上是高度等价的。我们期望构建一个更为通用的基础设施,其中可以赋予它一个累加器以及一个操作符,然后通过代码生成来获得最优的算法。大家可以详细读一下这个实现 https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/cuda/Reduce.cuh

作者这里做了一些关于 https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/cuda/Reduce.cuh 的笔记,关键点为:
- 实现是累加器和归约操作无关的(Implementation is accumulator and reduction op agnostic)这意味着实现方式可以适用于不同类型的累加器和归约操作。
- 使用TensorIterator来迭代张量元素(TensorIterator to iterate over tensor elements)这是一种用于遍历张量数据的机制。
- ReduceConfig:包含内核启动参数(ReduceConfig: Has kernel launch parameters)如块大小、线程数、网格等,这些参数在setReduceConfig中设置。
- Reduce_kernel是启动的地方(Reduce_kernel is where it gets launched)
- 归约策略(Reduction strategies):
- 线程级(thread level)
- 块级x,y(block level x,y)
- 全局归约(global reduce)
- 矢量化(Vectorization):
- 可以应用于输入和/或输出
通过学习 https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/cuda/Reduce.cuh 可以掌握很多cuda,模板方面的有趣知识,强烈推荐大家学习一下。

最后,还想展示一下torch.compile生成的reduce kernel。代码为:
# TORCH_LOGS="output_code" python reduce_compile.py
import torch
@torch.compile
def f(a):
c = torch.sum(a)
return c
f(torch.randn(10).cuda())
作者展示了一下Triton生成的代码。对代码里面的ReductionHit以及启发式搜索算法在PyTorch中的实现(pytorch/torch/_inductor/triton_heuristics)做了简要浏览,从这里我们也可以发现针对不同的输入大小,调度的kernel类型是不同的。

最后一张Slides提了一下Triton里面是如何实现Reduction的,对应这段代码:
LogicalResult
matchAndRewrite(triton::ReduceOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
ReduceOpHelper helper(op);
assert(helper.isSupportedLayout() &&
"Unexpected srcLayout in ReduceOpConversion");
Location loc = op->getLoc();
auto srcValues = unpackInputs(loc, op, adaptor, rewriter);
std::map<SmallVector<unsigned>, SmallVector<Value>> accs;
std::map<SmallVector<unsigned>, SmallVector<Value>> indices;
// First reduce all the values along axis within each thread.
reduceWithinThreads(helper, srcValues, accs, indices, rewriter);
// Then reduce across threads within a warp.
reduceWithinWarps(helper, accs, rewriter);
if (helper.isWarpSynchronous()) {
// If all the values to be reduced are within the same warp there is
// nothing left to do.
packResults(helper, accs, rewriter);
return success();
}
// Compute a shared memory base per operand.
auto smemShape = helper.getScratchRepShape();
SmallVector<Value> smemBases =
getSmemBases(op, product<unsigned>(smemShape), rewriter);
storeWarpReduceToSharedMemory(helper, accs, indices, smemBases, rewriter);
sync(rewriter, loc, op);
// The second round of shuffle reduction
// now the problem size: sizeInterWarps, s1, s2, .. , sn
// where sizeInterWarps is 2^m
//
// Each thread needs to process:
// elemsPerThread = sizeInterWarps * s1 * s2 .. Sn / numThreads
accumulatePartialReductions(helper, smemBases, rewriter);
// We could avoid this barrier in some of the layouts, however this is not
// the general case.
// TODO: optimize the barrier in case the layouts are accepted.
sync(rewriter, loc, op);
// set output values
loadReductionAndPackResult(helper, smemShape, smemBases, rewriter);
return success();
}
算法流程总结为:
- 初始化和输入处理:
- 创建一个ReduceOpHelper对象来辅助操作。
- 解包输入值。
- 线程内归约:
- 在每个独立的线程内进行第一轮归约。
- 这一步可以并行执行,每个线程处理自己的数据部分。
- Warp内归约:
- 将线程内归约的结果在warp内进行进一步归约。
- Warp是GPU中的一个执行单元,通常包含32个线程。
- 如果所有要归约的值都在同一个warp内,算法在这里就可以结束。
- 共享内存处理:
- 如果归约需要跨越多个warp,则使用共享内存来协调更大范围的归约。
- 计算共享内存的形状和基地址。
- 将warp内归约的结果存储到共享内存中。
- 同步:
- 执行一次同步操作,确保所有线程都完成了前面的步骤。
- 跨warp归约:
- 使用共享内存中的数据,执行跨warp的归约操作。
- 这一步会将不同warp的部分结果进行累积。
- 再次同步:
- 再次执行同步操作,确保跨warp归约完成。
- 最终结果处理:
- 从共享内存中加载最终的归约结果。
- 打包结果,准备输出。
总结
这节课是对Redcutions的算法进行了介绍,之前我在【BBuf的CUDA笔记】三,reduce优化入门学习笔记 这里也写过一个Reduce优化的笔记,CUDA-MODE的这个课程更入门和详细一些,Slides的后半部分存在一些适合我们学习的资料,特别是PyTorch的Reducitons.cuh是我们学习Reduce的宝藏。