
告别杂乱输出,OpenAI引领大模型的精准时代
©作者|Steven
来源|神州问学
作为一名大模型的使用者,你是否曾通过编写极其复杂的提示词,以规范化模型输出的内容,然而结果普遍是模型输出格式与要求的格式相差甚远,导致无法使用。
而前不久,OpenAI公司宣布他们在OpenAI-API中新增了结构化输出的功能,这意味着开发者在使用OpenAI接口的过程中,能够根据你所提供的JSON字段,准确生成符合JSON中要求的输出结果。
此外,官方还宣布,借助这一功能,新推出的gpt-4o-2024-08-06模型在复杂JSON模式评估中达到了100%的准确率,完美匹配了预期的输出模式。相比之下,gpt-4模型的输出准确率仅不到40%。
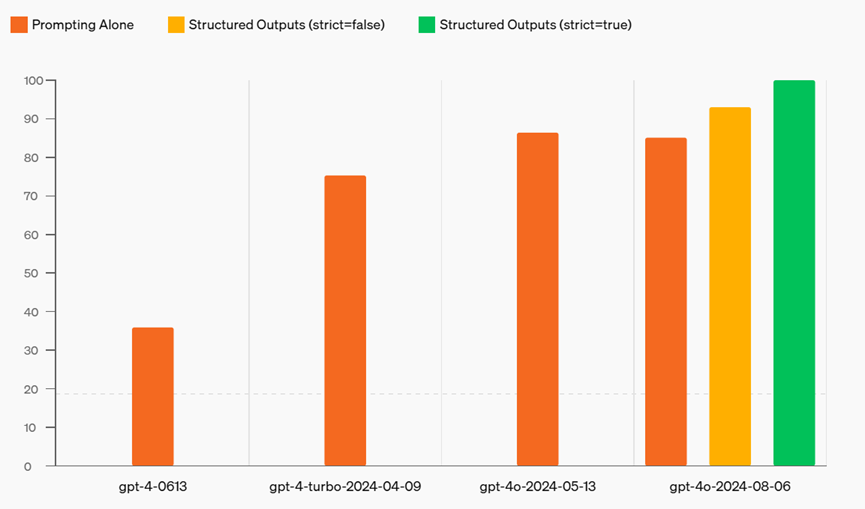
▲gpt-4o-2024-08-06实现了100%的可靠性(图源:OpenAI)
一、如何使用
OpenAI在API中以两种形式引入结构化输出,此外还支持更新了SDK的使用。
1、函数调用:
通过工具启用的结构化输出可以在函数定义中设置strict: true来实现。这一功能适用于所有支持工具的模型,包括gpt-4-0613和gpt-3.5-turbo-0613及其后续版本。当启用结构化输出时,模型输出将匹配提供的工具定义。
POST /v1/chat/completions
{
"model": "gpt-4o-2024-08-06",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant. The current date is August 6, 2024. You help users query for the data they are looking for by calling the query function."
},
{
"role": "user",
"content": "look up all my orders in may of last year that were fulfilled but not delivered on time"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "query",
"description": "Execute a query.",
"strict": true, # 启用结构化输出
"parameters": {
"type": "object",
"properties": {
"table_name": {
"type": "string",
"enum": ["orders"]
},
"columns": {
"type": "array",
"items": {
"type": "string",
"enum": [
"id",
"status",
"expected_delivery_date",
"delivered_at",
"shipped_at",
"ordered_at",
"canceled_at"
]
}
},
"conditions": {
"type": "array",
"items": {
"type": "object",
"properties": {
"column": {
"type": "string"
},
"operator": {
"type": "string",
"enum": ["=", ">", "<", ">=", "<=", "!="]
},
"value": {
"anyOf": [
{
"type": "string"
},
{
"type": "number"
},
{
"type": "object",
"properties": {
"column_name": {
"type": "string"
}
},
"required": ["column_name"],
"additionalProperties": false
}
]
}
},
"required": ["column", "operator", "value"],
"additionalProperties": false
}
},
"order_by": {
"type": "string",
"enum": ["asc", "desc"]
}
},
"required": ["table_name", "columns", "conditions", "order_by"],
"additionalProperties": false
}
}
}
]
}
Repsonse
{
"table_name": "orders",
"columns": ["id", "status", "expected_delivery_date", "delivered_at"],
"conditions": [
{
"column": "status",
"operator": "=",
"value": "fulfilled"
},
{
"column": "ordered_at",
"operator": ">=",
"value": "2023-05-01"
},
{
"column": "ordered_at",
"operator": "<",
"value": "2023-06-01"
},
{
"column": "delivered_at",
"operator": ">",
"value": {
"column_name": "expected_delivery_date"
}
}
],
"order_by": "asc"
}
2、响应格式的新选项:
开发者现在可以通过json_schema提供JSON Schema,这是response_format参数的新选项。当模型不调用工具而是以结构化方式响应用户时,这一功能非常有用。这一功能适用于OpenAI最新的GPT-4o模型:gpt-4o-2024-08-06和gpt-4o-mini-2024-07-18。当提供response_format并设置strict: true时,模型输出将匹配提供的架构。
POST /v1/chat/completions
{
"model": "gpt-4o-2024-08-06",
"messages": [
{
"role": "system",
"content": "You are a helpful math tutor."
},
{
"role": "user",
"content": "solve 8x + 31 = 2"
}
],
"response_format": {
"type": "json_schema", # 规范输出
"json_schema": {
"name": "math_response",
"strict": true,
"schema": {
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": {
"type": "string"
},
"output": {
"type": "string"
}
},
"required": ["explanation", "output"],
"additionalProperties": false
}
},
"final_answer": {
"type": "string"
}
},
"required": ["steps", "final_answer"],
"additionalProperties": false
}
}
}
}Response
{
"steps": [
{
"explanation": "Subtract 31 from both sides to isolate the term with x.",
"output": "8x + 31 - 31 = 2 - 31"
},
{
"explanation": "This simplifies to 8x = -29.",
"output": "8x = -29"
},
{
"explanation": "Divide both sides by 8 to solve for x.",
"output": "x = -29 / 8"
}
],
"final_answer": "x = -29 / 8"
}3、原生SDK支持:
OpenAI的Python SDK已更新,提供对结构化输出的原生支持。提供工具或响应格式的架构与提供Pydantic或Zod对象一样简单,SDK将处理将数据类型转换为支持的JSON架构,自动将JSON响应反序列化为类型化的数据结构,并在出现拒绝时解析它们。
示例:
from enum import Enum
from typing import Union
from pydantic import BaseModel
import openai
from openai import OpenAI
class Table(str, Enum):
orders = "orders"
customers = "customers"
products = "products"
class Column(str, Enum):
id = "id"
status = "status"
expected_delivery_date = "expected_delivery_date"
delivered_at = "delivered_at"
shipped_at = "shipped_at"
ordered_at = "ordered_at"
canceled_at = "canceled_at"
class Operator(str, Enum):
eq = "="
gt = ">"
lt = "<"
le = "<="
ge = ">="
ne = "!="
class OrderBy(str, Enum):
asc = "asc"
desc = "desc"
class DynamicValue(BaseModel
):
column_name: str
class Condition(BaseModel):
column: str
operator: Operator
value: Union[str, int, DynamicValue]
class Query(BaseModel):
table_name: Table
columns: list[Column]
conditions: list[Condition]
order_by: OrderBy
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are a helpful assistant. The current date is August 6, 2024. You help users query for the data they are looking for by calling the query function.",
},
{
"role": "user",
"content": "look up all my orders in may of last year that were fulfilled but not delivered on time",
},
],
tools=[
openai.pydantic_function_tool(Query),
],
)
print(completion.choices[0].message.tool_calls[0].function.parsed_arguments)
二、使用场景:
1、工具调用:
●具体场景:在开发一个电商在线客服聊天机器人时,开发者需要确保机器人能够根据用户的问题提供标准化的答案,比如产品价格、服务条款等。
●用户观点:在构建客服聊天机器人时,我们需要机器人能够准确地提供产品价格信息。通过结构化输出功能,我们定义了价格信息的JSON格式,包括产品ID、价格、促销信息等字段。这样,无论用户如何提问,机器人都能以统一的格式返回正确的价格信息,大大提升了用户体验和我们的工作效率。
●优势:
提高效率:避免手动编写复杂提示词,简化开发流程。
降低错误率:减少模型输出格式错误导致的工具调用失败。
增强可预测性:预期结果更加明确,方便开发者进行后续处理。
2、数据提取:
●具体场景:一家医疗研究机构需要从大量的病例报告中提取关键信息,如患者年龄、疾病类型、治疗结果等,以便进行数据分析。
●用户观点:研究团队每天都要处理成百上千份病例报告。使用结构化输出功能后,我们能够指导模型自动提取报告中的关键数据,并以表格形式输出。这不仅节省了大量的时间,还确保了数据分析的准确性,对于我们的研究至关重要。
●优势:
提高数据质量:确保提取的数据符合预期的格式和结构。
简化数据处理:结构化数据更易于存储、分析和应用。
增强自动化能力:自动化数据提取流程,提高效率。
3、多步操作:
●具体场景:在自动化客户关系管理(CRM)系统中,需要通过多个步骤来完成客户信息的录入、验证和更新。
●用户观点:CRM系统需要经过多个步骤来处理客户信息,从前端的录入到后端的验证。通过结构化输出功能,每个步骤的输出都被精确控制,保证了信息的正确流转。例如,在客户信息录入阶段,模型会按照我们定义的格式输出客户详情,后续步骤可以直接使用这些信息,无需额外的格式转换,极大提高了系统的效率和稳定性。
●优势:
提高流程可靠性: 避免因输出格式错误导致的流程中断。
简化流程设计: 预期结果更加明确,方便开发者设计流程。
增强流程可扩展性: 可以轻松地添加新的步骤或修改现有步骤。
三、技术细节:
OpenAI采用了双重方法来提高模型输出与JSON模式匹配的可靠性。首先,OpenAI对其最新的模型GPT-4o-2024-08-06进行了训练,使其能够理解复杂的模式,并生成最适配的输出。
其次,OpenAI采用了受限解码技术。尽管模型的性能显著提升,在基准测试中达到93%的准确性,但模型的固有不确定性仍然存在。为确保开发者构建应用的稳健性,OpenAI提供了一种确定性方法来约束模型输出,实现100%的可靠性。
默认情况下,模型在生成输出时没有约束,可能从词汇表中选择任何标记。这种灵活性可能导致模型生成无效的JSON字符。为了避免这种错误,OpenAI使用动态受限解码方法,强制模型仅选择符合提供模式的有效标记。在每次生成标记后,推理引擎根据前一个标记和模式规则确定下一个有效标记。这一方法通过屏蔽无效标记的可能性,确保生成的输出始终符合提供的模式。
实现这种约束可能具有挑战性,因为有效标记在整个模型输出中是动态变化的。例如,初始有效标记包括 {、{” 和 {\n等,但一旦模型生成了 {“val,那么 { 就不再是有效标记。因此,OpenAI需要在生成每个标记后动态确定哪些标记有效,而不是在响应开始时预先确定。
为此,OpenAI将提供的JSON模式转换为上下文无关语法(CFG)。CFG是一组定义语言的有效规则,开发者可以将JSON和JSON模式视为具有规则的特定语言。类似于英语中没有动词的句子是无效的,JSON中带有尾随逗号也是无效的。
因此,对于每个JSON模式,OpenAI计算出代表该模式的语法,并在采样过程中高效地访问预处理组件。这就是为什么首次使用新模式可能需要额外处理时间的原因——OpenAI必须对模式进行预处理,以生成可以在采样中有效使用的组件。
在采样时,OpenAI的推理引擎将根据先前生成的标记和语法规则(指示下一个标记是否有效)确定下一个生成的标记。OpenAI使用标记列表来屏蔽无效标记,将无效标记的概率降至0。由于模式已被预处理,OpenAI可以使用缓存的数据结构高效地完成此操作,同时将延迟开销降至最低。
除了CFG方法,有限状态机(FSM)或正则表达式也可以用于受限解码。它们的功能类似,都会在生成每个标记后动态更新哪些标记是有效的。但值得注意的是,CFG方法能够表达比FSM更广泛的语言类别。对于简单模式,这种差别可能不明显。然而,OpenAI发现对于涉及嵌套或递归数据结构的复杂模式,CFG方法表现更为出色。例如,FSM通常无法表达递归类型,因此可能难以匹配深度嵌套JSON中的括号,而支持递归模式的JSON模式在OpenAI API上已得到实现,但FSM方法难以处理。
四、局限性:
●仅支持JSON模式子集:结构化输出仅支持JSON模式的子集,以确保最佳性能。具体限制可参考OpenAI的官方文档。
●首次请求延迟:新模式的首次请求可能带来额外延迟,但后续响应将很快,不会有延迟损失。第一次请求期间,OpenAI会处理并缓存模式以供后续使用。通常模式在首次请求时可在10秒内处理完毕,但更复杂的模式可能需要长达一分钟。
●拒绝不安全请求:如果模型选择拒绝不安全请求,则模型可能无法遵循模式。当选择拒绝时,返回消息将包含一个拒绝布尔值以指示这一点。
●停止条件限制:如果生成过程中达到最大令牌数或其他停止条件,模型可能无法遵循模式。
●模型错误:结构化输出不能完全防止所有模型错误。例如,模型在JSON对象的值中仍可能犯错(如数学计算错误)。开发者可以通过提供系统指令中的示例或将任务拆分为更简单的子任务来减少错误。
●与并行函数调用不兼容:生成并行函数调用时,可能不符合提供的模式。开发者可以禁用并行函数调用,使用“parallel_tool_calls: false”设置。
●不符合零数据保留(ZDR)资格:结构化输出与JSON模式不符合零数据保留(ZDR)资格。
五、总结:
OpenAI 推出的结构化输出功能,让大模型的应用更加灵活和高效。通过定义 JSON 模式,开发者可以精确控制模型的输出格式,实现更可靠的数据处理和工具调用。这一功能的应用场景广泛,包括工具调用、数据提取和多步操作流程等,将为人工智能技术的发展带来新的可能性。
说完了好处和优点,如果我们换一个角度来看OpenAI的此次更新,作为AI龙头的OpenAI在GPT爆火后的近两年时间内,模型迭代速度和模型能力增长都十分迅速,反观这次大动干戈的从JSON格式化来规范模型输出,而没有从模型自身审视输出不规范的问题,这何尝不是一种“雕花”工作呢?
其实许多科技公司和初创企业推出的AI产品也和OpenAI一样,技术更新到一定的地步,可能会存在瓶颈,陷入同质化的困境。像Apple和Microsoft这样的大公司也在AI领域努力寻求创新,但效果有限。Apple Intelligence系统在实际功能展示上乏善可陈,而微软的Recall功能由于隐私问题被搁置。整体上,AI行业似乎进入了所谓的“雕花”时代,过分关注表面功能的堆砌,而缺乏根本性的技术突破。

![[米联客-XILINX-H3_CZ08_7100] FPGA程序设计基础实验连载-27浅谈XILINX BRAM的基本使用](https://i-blog.csdnimg.cn/direct/935b088c4f9f446694ad2ab5ce9ba56a.png)

















