点/击/蓝/字 关/注/我/们
一、背景
前段时间,公司的生产环境的clickhouse的cpu突然持续高压,持续时间大约5个小时,特写此文记录,深挖clickhouse的原理,持续学习。
题主所在的公司的一些历史数据会保存到clickhouse中,现在有业务需要对clickhouse里面的数据进行删除。因为这是一个批量的操作,暂且假设需要删除一批股票的全部的历史k线数据,k线包括分k,日k,周k,月k,季k,年k。
二、经过
好吧,简单还原一下事情的经过吧,在某天题主18点30发完版后得意洋洋收工下班吃饭中,突然接到运维大佬发信息说clickhouse的cpu打爆了。不可能,绝对不可能,我的程序不可能有~问~题。二话不说,坐上火箭弹射回家远程电脑。一顿操作猛如虎,一看cpu还是100%。各种指标分析:内存,流量,吞吐量。由于当时时段还是业务低峰期,实时吞吐,流量是比较少的,因此这些因素可以排除掉了。脑瓜子嗡嗡的,在阿里云的clickhouse管理后台将正在执行的任务杀掉了,代码回滚,服务重启,cpu还是100%。然后重点怀疑一个删除操作的任务,这个任务是一个逻辑比较简单的,任务流程如下:

第二步:服务A将需要删除的数据推送到kafka中
第三步:服务B消费对应topic中的数据,对clickhouse中的数据进行删除。
因此上文说的,服务B的代码回滚和重启后,clickhouse的cpu还是打满,不难看出是由于kafka中的消息没消费完,服务B还在不断执行消息kafka的数据,删除clickhouse中的数据。事实也是如此,登录上kowl工具,发现kafka中对应topic一共需要删除将近1w个股票的数据,现在只是服务B只是消费了大概2000个,还剩下8000个股票的历史数据没清除。
tips:
每个股票需要删除的k线,包括分k,日k,周k,月k,季k,年k。因此这个删除逻辑是比较重的,至少对应一个股票来说,删除的数据是比较多的,涉及的范围比较广。
既然定位到了问题的所在,我们就可以想对应的解决方法,这个任务一般是在周末业务低峰的时候执行的,这次是人为手动执行了一次。因此临时想的解决方法是注释服务B消费kakfa的代码,然后重新发布到生产环境。但是在服务B改造发布完成后,clickhouse的cpu还是高居不下。
三、分析
经过以上步骤,基本可以定位到触发问题的地方。但是有以下几个问题需要思考探讨一下
-
为什么相应的代码逻辑注释了,clickhouse的cpu还高居不下?
-
clickhouse是有什么隐含的比较耗cpu的操作嘛
tips:
之前题主也知道clickhouse对删除操作支持的不是很好,因此对clickhouse的删除操作都是放在周末,避开业务高峰期的。但是没深入探讨过底层的原理。因此刚才趁着此次机会,学习探讨一下。
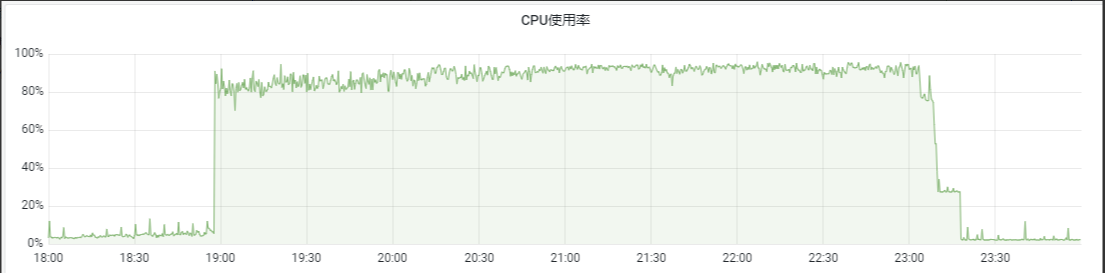
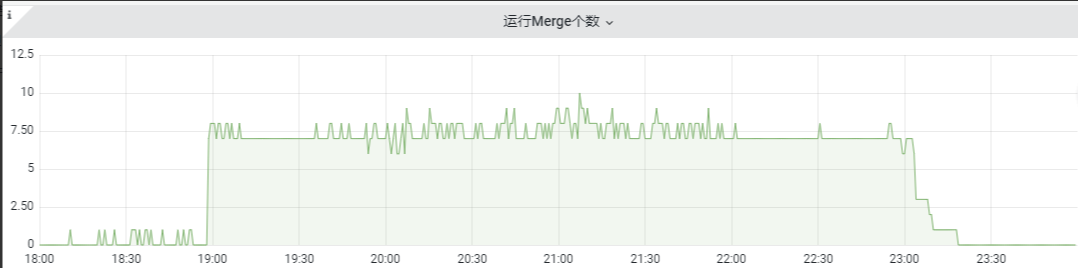
题主观察到阿里云上面的cpu暴增,但是内存使用率,磁盘使用率虽有徒增,并没达到预警值,属于预期的情况。但是运行Merge个数和运行Mutation个数这两个指标一下子吸引了我,这两个指标明显和cpu爆增的时机趋势一致。因此重点关注这两个指标:


-
运行的Merge个数是指正在运行的Merge的线程数量
-
运行Mutation个数是指正在运行的mutation的线程的数量
merge和mutation使用的是同一个线程池,默认是16个线程。
既然定位到了clickhouse出问题的地方了,那么我们可以一起来看看merge和mutation操作到底是什么。
3.1 mutation操作
mutation基本概念
clickhouse将update和delete的操作统称为mutation操作,clickhouse虽然提供了更新和删除的操作,但是mutation的代价比较大,因为ClickHouse使用了LSM的底层存储结构,文件是不可修改、不可变的,新操作只会写到新文件中。因此哪怕只更新一条记录,也需要重新生成一个新的数据片段,会将该记录修改后的内容以及该记录所在的分区中其他未修改的所有记录写入到新的数据片段。因此mutation操作最好是批量操作,涉及的分区数尽量少,这样性能会比较高。
mutation核心源码解读
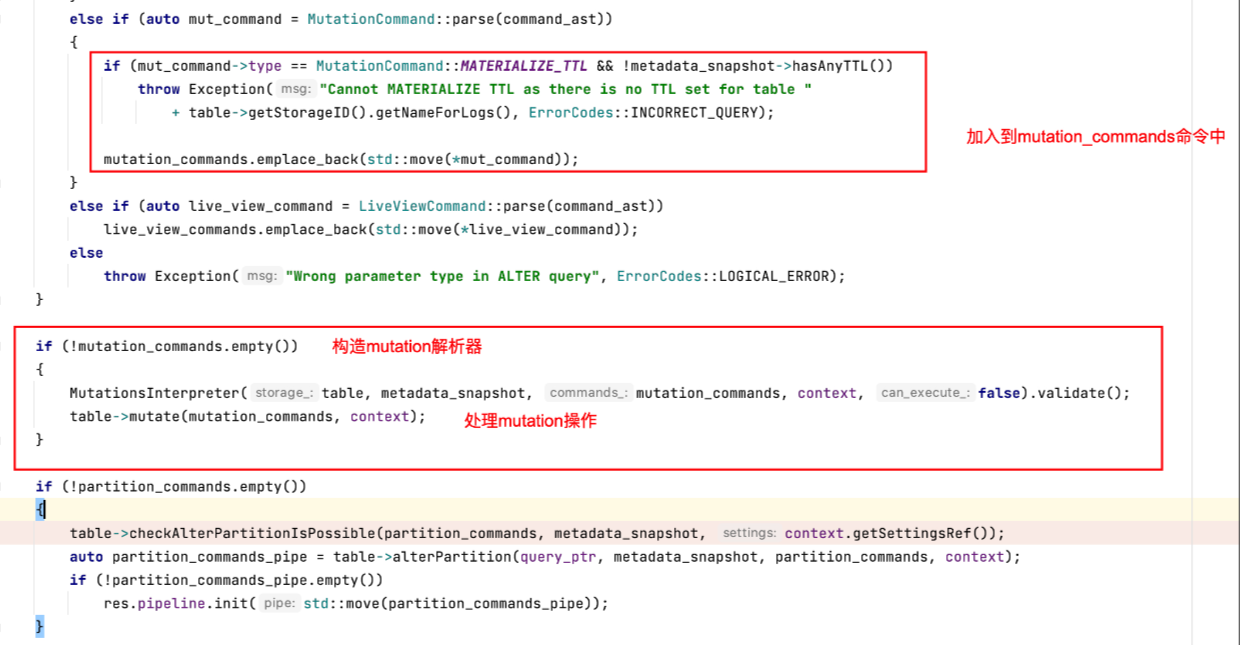
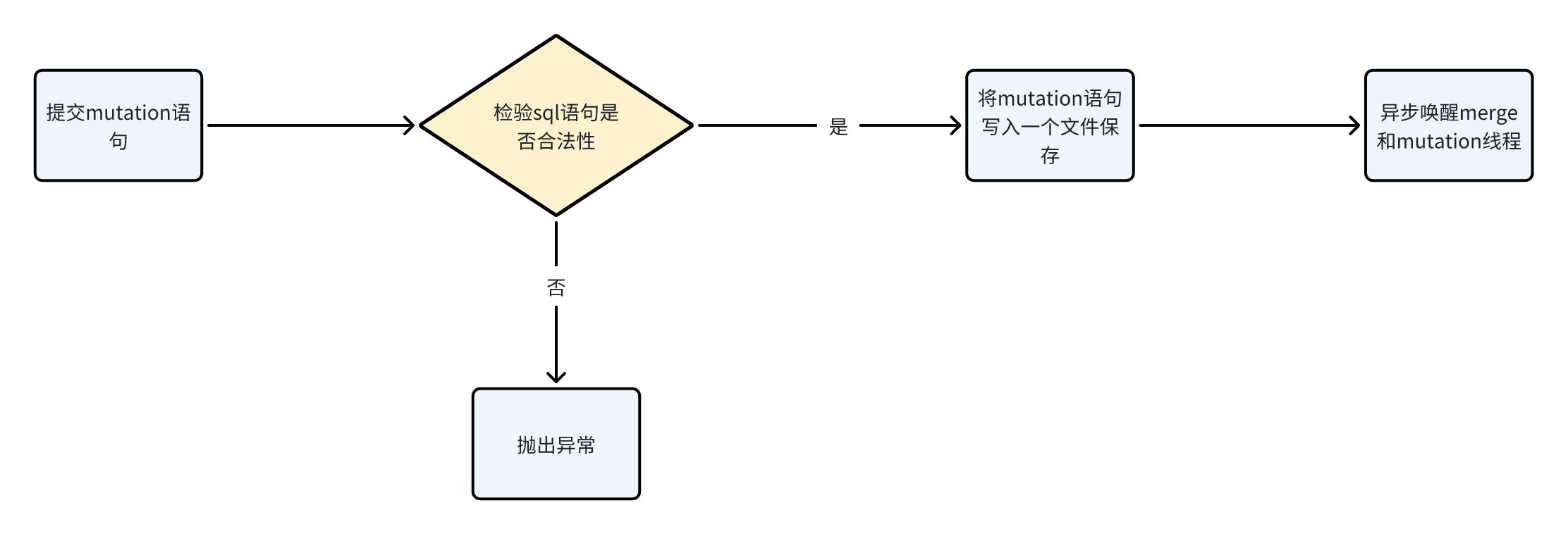
ClickHouse的方言把Delete和Update操作也加入到了Alter Table的范畴中,它并不支持裸的Delete或者Update操作。当用户执行一个如上的Mutation操作获得返回时,ClickHouse内核其实只做了两件事情:
1.检查Mutation操作是否合法;
2.保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
-
检查mutation操作是否合法:主体逻辑在MutationsInterpreter::validate函数,主要是不能修改分区键和order by的字段。
-
保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程:主体逻辑在StorageMergeTree::mutate函数中。
核心流程图如下:
样例
对于第一点,举个例子,假如你的创表语句如下:
CREATE TABLE user (
`user_id` Int64 COMMENT '用户id',
`user_type` Int 32 COMMENT '用户类型',
`create_time` DateTime COMMENT '创建时间',
`update_time` DateTime COMMENT '更新时间',
)ENGINE = ReplacingMergeTreePARTITION BY toStartOfInterval(create_time, toIntervalYear(1))ORDER BY (user_id, user_type)SETTINGS index_granularity = 8192;那么因为用到了create_time作为分区字段,用了user_id和user_type作为排序字段,因此create_time,user_id和user_type这三个字段,在提交sql语句的时候clickhouse会检查sql的合法性,不能对这三个字段进行更新,删除,否则会报错。
mutation过程
系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。
核心源码如下:


核心流程如下:

3.2 merge操作
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool: 决定当空闲线程数最大时可处理的数据量上限(默认150GB)max_bytes_to_merge_at_max_space_in_pool: 决定只剩下一个空闲线程时可处理的数据量上限(默认1MB)当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
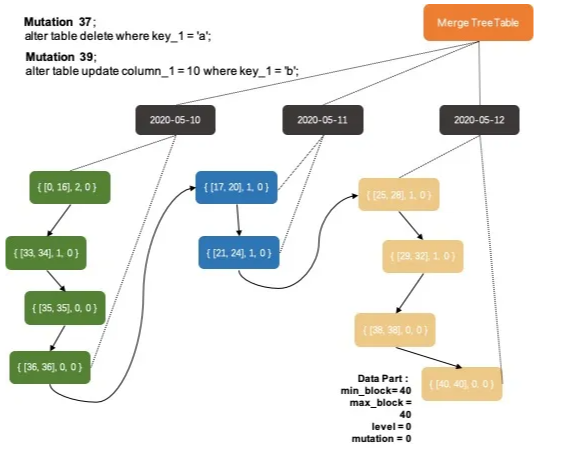
Merge的处理逻辑,首先是通过MergeTreeDataMergerMutator::selectPartsToMerge函数筛选出本次merge要合并的Data Parts,这个筛选过程需要准守三个原则:
-
跨数据分区的Data Part之间不能合并;
-
合并的Data Parts之间必须是相邻(在上图的有序组织关系中相邻),只能在排序链表中按段合并,不能跳跃;
-
合并的Data Parts之间的mutation状态必须是一致的,如果Data Part A 后续还需要完成mutation-23而Data Part B后续不需要完成mutation-23(数据全部是在mutation命令之后写入或者已经完成mutation-23),则A和B不能进行合并;
所以我们上面的Data Parts组织关系逻辑示意图中,相同颜色的Data Parts是可以合并的。虽然图中三个不同颜色的Data Parts序列都是可以合并的,但是合并工作线程每次只会挑选其中某个序列的一小段进行合并(系统会限定每次合并的Data Parts的数据量)。对于如何从这些序列中挑选出最佳的一段区间,ClickHouse抽象出了IMergeSelector类来实现不同的逻辑。当前主要有两种不同的merge策略:TTL数据淘汰策略和常规策略。
-
TTL数据淘汰策略:TTL数据淘汰策略启用的条件比较苛刻,只有当某个Data Part中存在数据生命周期超时需要淘汰,并且距离上次使用TTL策略达到一定时间间隔(默认1小时)。TTL策略也非常简单,首先挑选出TTL超时最严重Data Part,把这个Data Part所在的数据分区作为要进行数据合并的分区,最后会把这个TTL超时最严重的Data Part前后连续的所有存在TTL过期的Data Part都纳入到merge的范围中。这个策略简单直接,每次保证优先合并掉最老的存在过期数据的Data Part。
-
常规策略:这里的选举策略就比较复杂,基本逻辑是枚举每个可能合并的Data Parts区间,通过启发式规则判断是否满足合并条件,再有启发式规则进行算分,选取分数最好的区间。启发式判断是否满足合并条件的算法在SimpleMergeSelector.cpp::allow函数中,其中的主要思想分为以下几点:系统默认对合并的区间有一个Data Parts数量的限制要求(每5个Data Parts才能合并);如果当前数据分区中的Data Parts出现了膨胀,则适量放宽合并数量限制要求(最低可以两两merge);如果参与合并的Data Parts中有很久之前写入的Data Part,也适量放宽合并数量限制要求,放宽的程度还取决于要合并的数据量。第一条规则是为了提升写入性能,避免在高速写入时两两merge这种低效的合并方式。最后一条规则则是为了保证随着数据分区中的Data Part老化,老龄化的数据分区内数据全部合并到一个Data Part。中间的规则更多是一种保护手段,防止因为写入和频繁mutation的极端情况下,Data Parts出现膨胀。启发式算法的策略则是优先选择IO开销最小的Data Parts区间完成合并,尽快合并掉小数据量的Data Parts是对在线查询最有利的方式,数据量很大的Data Parts已经有了很较好的数据压缩和索引效率,合并操作对查询带来的性价比较低。
四、归纳总结
经过以上分析,可知clickhouse对于delete和update的操作支持得不是很好,因此对于需要进行频繁或者大量删除或者更新的操作,在数据库选型的时候就需要兼顾考虑,如果实在是需要进行数据删除或更新的,务必在业务低峰期进行,这也是无奈折中之举。
好了,由于篇幅有限,这一期的分享就到这里了,如果大家有技术相关的问题,可以点个关注一起交流探讨。
重点~重点~,听说题主开通了公众号:有理唔理,可以关注一下。
参考文章:
https://www.cnblogs.com/ya-qiang/p/13680283.html
https://cloud.tencent.com/developer/article/1911598
https://developer.aliyun.com/article/762090
https://blog.csdn.net/ClickHouseDB/article/details/133657544
https://blanklin030.github.io/2022/02/03/clickhouse-crud/
https://aop.pub/artical/database/clickhouse/mutation-detail/




![[python]面向对象示例:学生管理系统](https://i-blog.csdnimg.cn/direct/e6237f53238a48c9b9b9698146a65435.png#pic_center)