0. 引言
距离ChatGPT已经发布1年半了,距离我们训练出自己的大模型也已经1周年了。目前仍然有很多同学在咨询如何训练自己的大模型。这个东西和男/女朋友一样。当你不认识TA,距离TA很远,不敢接触TA的时候,TA就是很神秘,也很难接触。但是一旦当你愈发了解TA的时候,你就知道其实上手也很容易。之前我已经撰写了一个简单的训练baichuan大模型的代码,用于阐述大模型训练其实和原来的训练没什么两样。但是随着大模型深入到了每一个研究者的手上,这时候,训练部署的代码框架就更为重要了。
1. 框架选择
时隔半年,大模型的生态体系也逐渐完善,包括huggingface在内的库都已经跟上来了。例如,huggingface自己出的alignment handbook,中文的Firefly,以及今天要讲的LLAMA_factory。LLaMA-Factory早期确实是面向LLaMA系列的模型的,但是后来其他模型也都支持上了。而且,本来是为了更快的指令微调,后来不仅在流程上补全了预训练和强化学习,而且在配置上,也增加了各种训练方法和部署等。
1.1. 环境安装
安装LLAMA_factory相对来讲比较容易,但是依赖项很多,需要安装很久。
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
安装完以后,就可以尽情的去训练了。因此在本文中,我们将快速的带大家过一遍整个大模型的全流程,从数据准备、模型训练和部署使用三个步骤开始讲解,保证让不懂大模型具体怎么做的兄弟姐妹都能够在1个下午搞定整体流程,当然预训练和强化学习这个框架都能够使用,本文以指令微调为例进行说明。
2. 数据准备
大模型的训练离不开数据集,目前随着许多优秀的基座模型发布,例如Llama3和Phi-3都已经显著超越它们的前辈,因此英文上的基础对话能力基本上是没啥问题了。如果一定要再微调的话,都是朝着特定任务或者缺陷来补足,或者是来汉化等等。这里,我们主要介绍一些数据来源。
例如,最新的吵的沸沸扬扬的ruozhi吧数据也还不错的COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning,提供了一个高质量的中文数据集。当然,也有一些经典的指令数据集可以用,例如alpaca-gpt-4和sharegpt-4的汉化版等等,可以用于汉化微调。
当然,这里都是使用的sharegpt的格式存储的。需要提一句的是,一般指令数据有两类,一类是alpaca的数据格式,一类是sharegpt的数据格式,目前的微调框架大部分适配了这两类。当然也可以自己撰写指定的格式,都是可以的。
两者的格式区别如下所示:
- alpaca的数据集格式如下:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
- sharegpt的数据集格式如下:
[
{
"conversations": [
{
"from": "human",
"value": "用户指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
也就是说,只要将自己的数据转换成上述的指令微调数据的形式,都是可以进行大模型微调的。这就非常简单。当然llama_factory也内置了许多常用的数据集,可以在data中找到相应的数据集。也可以自己构建属于自己的文件,放到data下或者任意一个地方都可以,只要是类似的结构就可。
然后,最重要的数据处理过程来了,那就是需要将自己的数据集的格式告诉给框架,通过dataset_info.json进行一个编辑。
例如,官方给出的数据集描述格式如下:
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的 SHA-1 哈希值(可选,留空不影响训练)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system 列)"
}
}
但是实际上我们可能需要的简单的数据集是这样的:
"sharegpt_4_multi": {
"file_name": "sharegpt_4_multi.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt"
}
}
这里需要关注的就是tags这部分,user_tag可以是"human"也可以是"user",主要看自定义的数据集里的用户的标签是什么,同理assistant_tag也是如此,这部分可以从dataset_info文件里的其他数据集描述中参考。因此,只需要将我们需要的数据集处理成这种形式,放到data文件夹下即可。
3. 模型训练
作为最为关键的一部分,llama_factory已经将模型训练简化成非常傻瓜式的一键训练了,其训练代码可以在example里找到,这里我们看一个全量微调的脚本
example/full_multi_gpu/single_node。
deepspeed --num_gpus 4 ../../src/train_bash.py \
--deepspeed ../deepspeed/ds_z3_config.json \
--stage sft \
--do_train \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset alpaca_gpt4_en,glaive_toolcall \ ## 可以多个数据集一起训练,保证具有自然的对话的同时还能有针对性的训练
--dataset_dir ../../data \
--template default \ ## 这里的模板如果是通用的一些模型,都可以使用default,或者自定义模版如果有需要的话
--finetuning_type full \ ##这里指定是全量微调还是LORA微调。
--output_dir ../../saves/LLaMA2-7B/full/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \ ## 最长长度
--preprocessing_num_workers 16 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 100 \ ## 评估用
--evaluation_strategy steps \ ## 评估用
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--max_samples 3000 \
--val_size 0.1 \ ## 评估用
--ddp_timeout 180000000 \
--plot_loss \
--report_to wandb \ ## 这行为笔者添加,可以看到wandb的记录
--fp16
可以看到这里其实是使用deepspeed框架在4块GPU上进行的训练。如果是训练百川模型遇到了问题,可以参考这个解决方案注释掉验证的那几行参数即可。
另外一个需要注意的是,如果使用的是chat模型进行再微调的话,一定要看看template文件里的描述是否与原模型一致。如果是base模型的话,使用default或者自定义模板都可以。
如果真的想看训练的底层代码,可以直接看它的sft源码,也没什么神秘的地方。
当你用上wandb训练后,会得到如下的训练过程图:
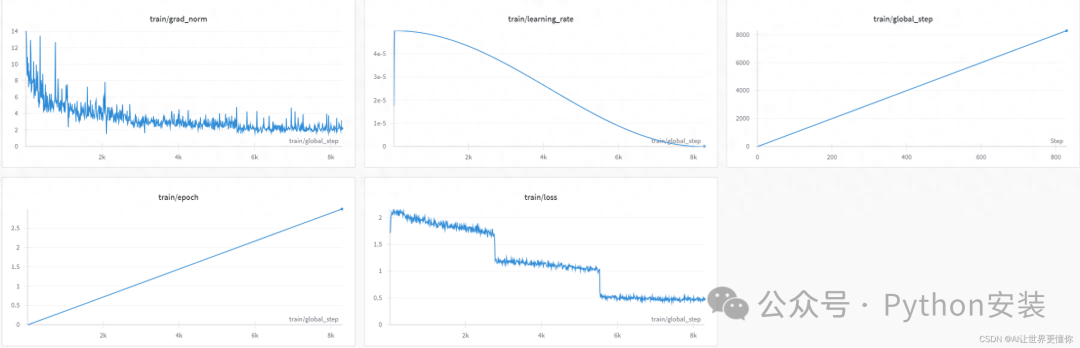
一定要记得提前使用下面的命令登录wandb
wandb login
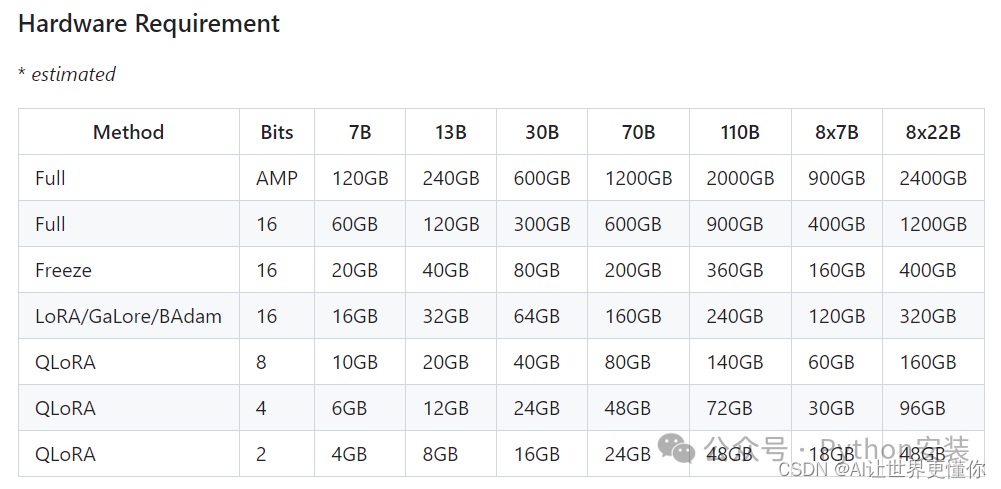
这里也放出训练各个模型大小所需要的内存量,以评估当前设备能训练什么样的模型:
3.2 LORA训练
这里我也放一个LORA训练的命令,用于进行对比:
CUDA_VISIBLE_DEVICES=0 python ../../src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset alpaca_gpt4_en,glaive_toolcall \
--dataset_dir ../../data \
--template default \
--finetuning_type lora \ ## lora 新加
--lora_target q_proj,v_proj \ ## lora 新加
--output_dir ../../saves/LLaMA2-7B/lora/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 100 \
--evaluation_strategy steps \
--load_best_model_at_end \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--max_samples 3000 \
--val_size 0.1 \
--plot_loss \
--fp16
其实可以看到和全量微调的差异不大,就是指定了lora的训练。但是这里需要阐述的是lora_target是有要求的,根据不同的模型填写的内容也不一样。
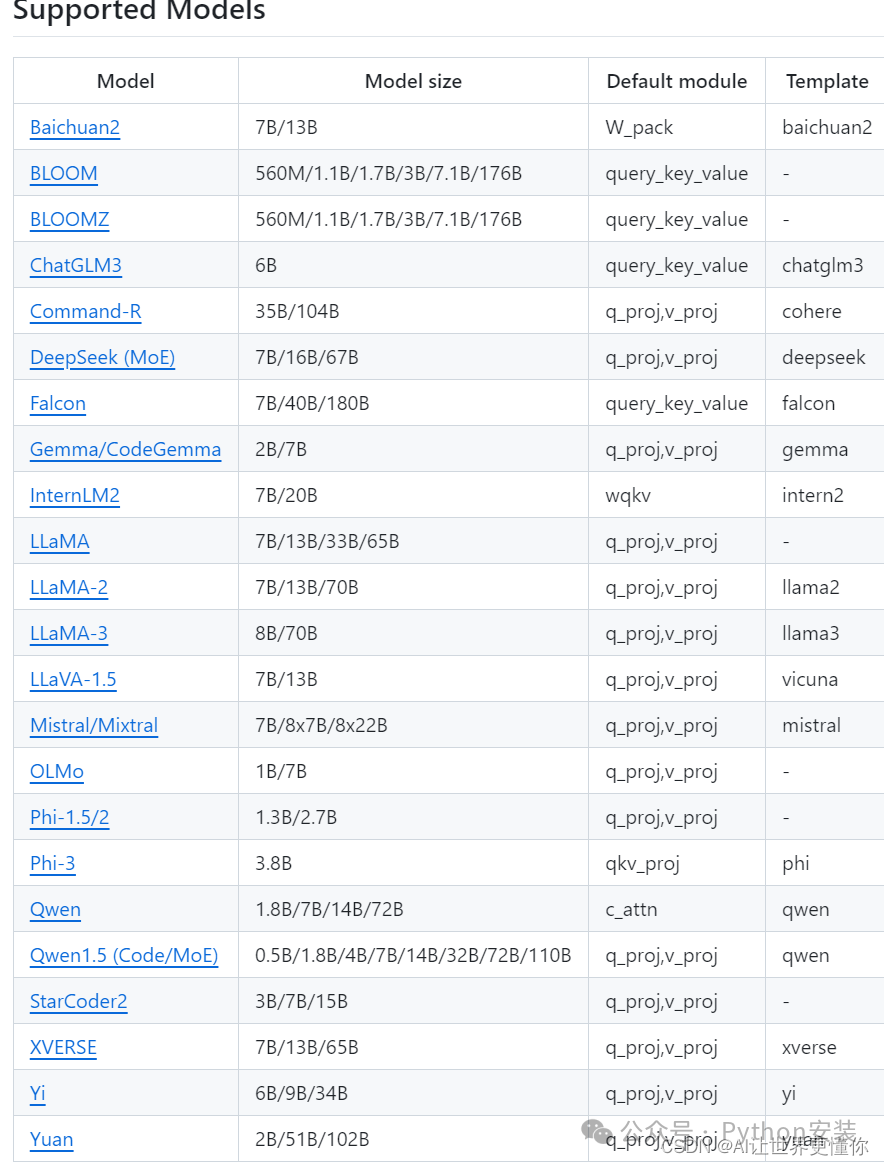
3.3 模型合并
如果是使用LORA等方法训练的话,还需要对模型进行一个合并,这里只需要三个关键地址:path_to_base_model,path_to_adapter以及path_to_export。
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \
--model_name_or_path path_to_base_model \
--adapter_name_or_path path_to_adapter \
--template default \
--finetuning_type lora \
--export_dir path_to_export \
--export_size 2 \
--export_legacy_format False
3.4 预训练代码和强化学习的训练代码
预训练和强化学习的训练代码与微调的差异不大,大家可以看一下,如果需要的话,后面会再详细阐述这两个部分的训练过程。
预训练的代码:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage pt \ # Pre——Training预训练模式
--model_name_or_path path_to_llama_model \ # 模型地址
--do_train \ # 表示进行训练
--dataset wiki_demo \ # 使用的数据集
--finetuning_type lora \ # 微调的方法
--lora_target W_pack \ # LoRA作用模块:Baichuan为W_pack
--output_dir path_to_pt_checkpoint \ # 断点保存:保存模型断点的位置
--overwrite_cache \ # 表示是否覆盖缓存文件
--per_device_train_batch_size 4 \ # 批处理大小:每块 GPU 上处理的样本数量
--gradient_accumulation_steps 4 \ # 梯度累积:梯度累积的步数(节省显存的方法)
--lr_scheduler_type cosine \ # 学习率调节器:采用的学习率调节器名称
--logging_steps 10 \ # 日志间隔:每两次日志输出间的更新步数
--save_steps 1000 \ # 保存间隔:每两次断点保存间的更新步数
--learning_rate 5e-5 \ # 学习率:AdamW优化器的初始学习率
--num_train_epochs 3.0 \ # 训练轮数:需要执行的训练总轮数
--plot_loss \ # 绘制损失函数图
--fp16 # 计算类型:是否启用fp16或bf16混合精度训练。
强化学习的代码(DPO):
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage dpo \
--model_name_or_path path_to_llama_model \
--do_train \
--dataset comparison_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target W_pack \
--resume_lora_training False \
--checkpoint_dir path_to_sft_checkpoint \
--output_dir path_to_dpo_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
4. 部署使用
当我们训练模型完成后,可以用llama_factory自带的测试代码构建起一个简易的命令行UI或者webUI。
但是我们有时候不仅需要批量的测试,更多的时候,希望的是可以部署起来,让我们大家都亲自用一用体验一下。那么部署有很多可以使用的前端,早期可以使用caht-next-web[5]其部署方案我们之前已经写过了。当然,最近比较流行的是open webui[6]。部署的前端是不需要任何GPU资源的,和很多常见的前端UI一样,之前我们部署过chat-next-web,那个是专门给chatgpt使用的,当然也适配其他的openai风格的api,就是设置起来麻烦一些。
这次我们使用open webui作为前端UI,相比较chat-next-web,它拥有更加广泛的后端接口方式以及丰富的前端支持,包括图片的输入输出和语音的输入输出。本质上,它就是一个完全模仿openai的官方界面的一个项目。但是可以选择官方提供的模型、ollama后端提供的模型,或者是自己构建的模型。
当然也有其他的前端供大家使用,在ollama里提供了大量的仓库供大家挑选,我这里就不一一列举了。

4.1 准备条件
根据官方教程,使用docker启动它:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
这时候,会拉取oepn-webui的镜像进行下载。稍等片刻后,就能够直接访问了,这里访问端口是服务器的IP:3000端口,8080是docker的端口,注意避免冲突就可以。
4.2 登录系统
第一次在浏览器输入服务器IP:3000后,会有这样一个界面。
这时候点击sign up进行用户注册。
当注册完毕后,第一个登录系统的用户是管理员权限,可以在左下角的用户头像里能够看到一个管理员面板(Admin Panel),单击后可以对于用户实现角色的管理。据官方说实现了RBAC(Role-Based Access Control, 基于角色的访问控制)功能。还记得RBAC第一次听说这个名词的时候还是十年前做用户管理系统的时候,满满的回忆。
4.3 设置模型
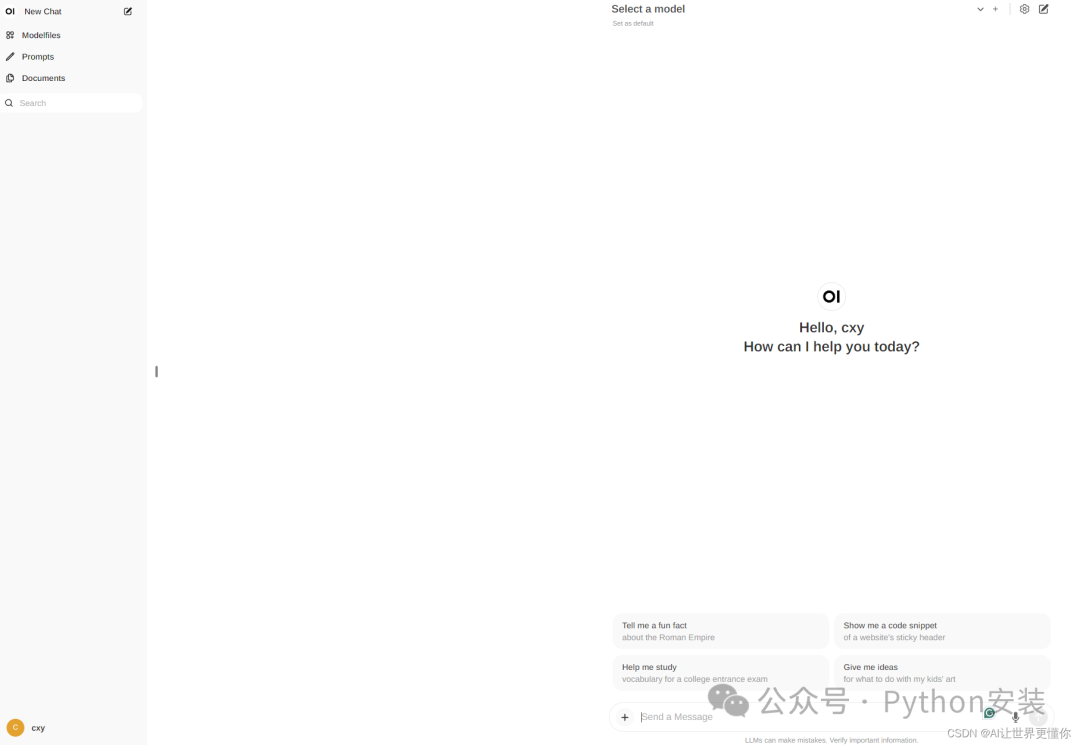
登录完毕以后,面板如图所示,特别像openai的官方界面,这时候可以注意到最上面的select a model,但是点击后,是没有任何模型的。需要点击右边的齿轮进行一系列的配置。需要注意的是,这些只有在管理员界面可以看到,普通用户角色是无法设置的。
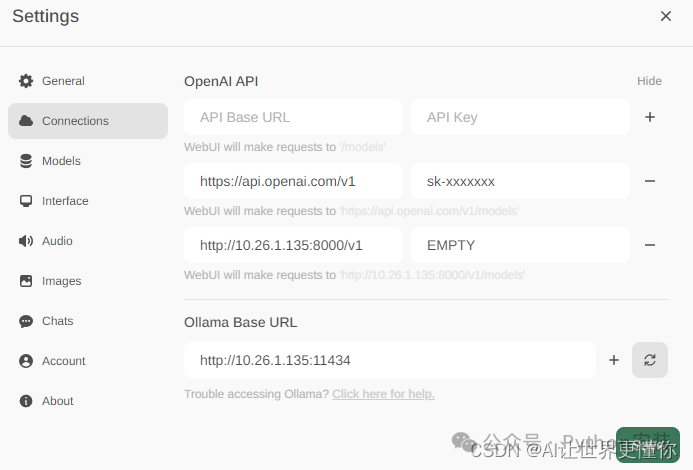
在点击齿轮后,可以点击connections,这里我列举了3个模型构建的方式。
第一种就是使用带有apikey的第三方的api的方式,这里我填写的是官方的https://api/openai.com/v1,也可以换成任意一个api供应商的地址。(不然的话,需要科学上网才能够使用。)
第二种则是自己构建的模型,也就是可以通过例如vllm等后端框架构建的自己的模型后端接入,如果没有设置apikey的访问的话,就填写EMPTY就可以。这里简单提及如何使用vllm构建一个后端的代码,也是非常容易。
第三种则是利用Ollama进行自动化构建已有的模型。ollama严格意义上讲更像是一个模型管理系统,它运行后能够拉取已有的模型(所有支持的模型列表)进行部署,而且也可以把自定义的模型包装起来,进行统一的伺服。它的官方github介绍了很多运行的方式,我这里就简单提简单的使用。
安装代码
curl -fsSL https://ollama.com/install.sh | sh
构建llama3模型
ollama run llama3
然后就可以把构建模型的机器的ip地址:11434放置到Ollama Base URL中。之所以这两个需要区分,我们看ollama的调用方式就可以发现了:
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
它并不是和openai的api兼容的,更多代码详情参见它的开发文档,这里不多赘述。
当我们都设置好模型了以后,我们点击保存后,可使用的模型列表就如图所示。

当我们选定一个模型后,我们就可以愉快的对话了。它同时也支持语音、图像、文档等接口。都可以进行设置。
4.4 自定义配置
如果想自定义整个webui的名字、登录进来的用户角色等等,则需要对docker的镜像进行一定的修改。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓