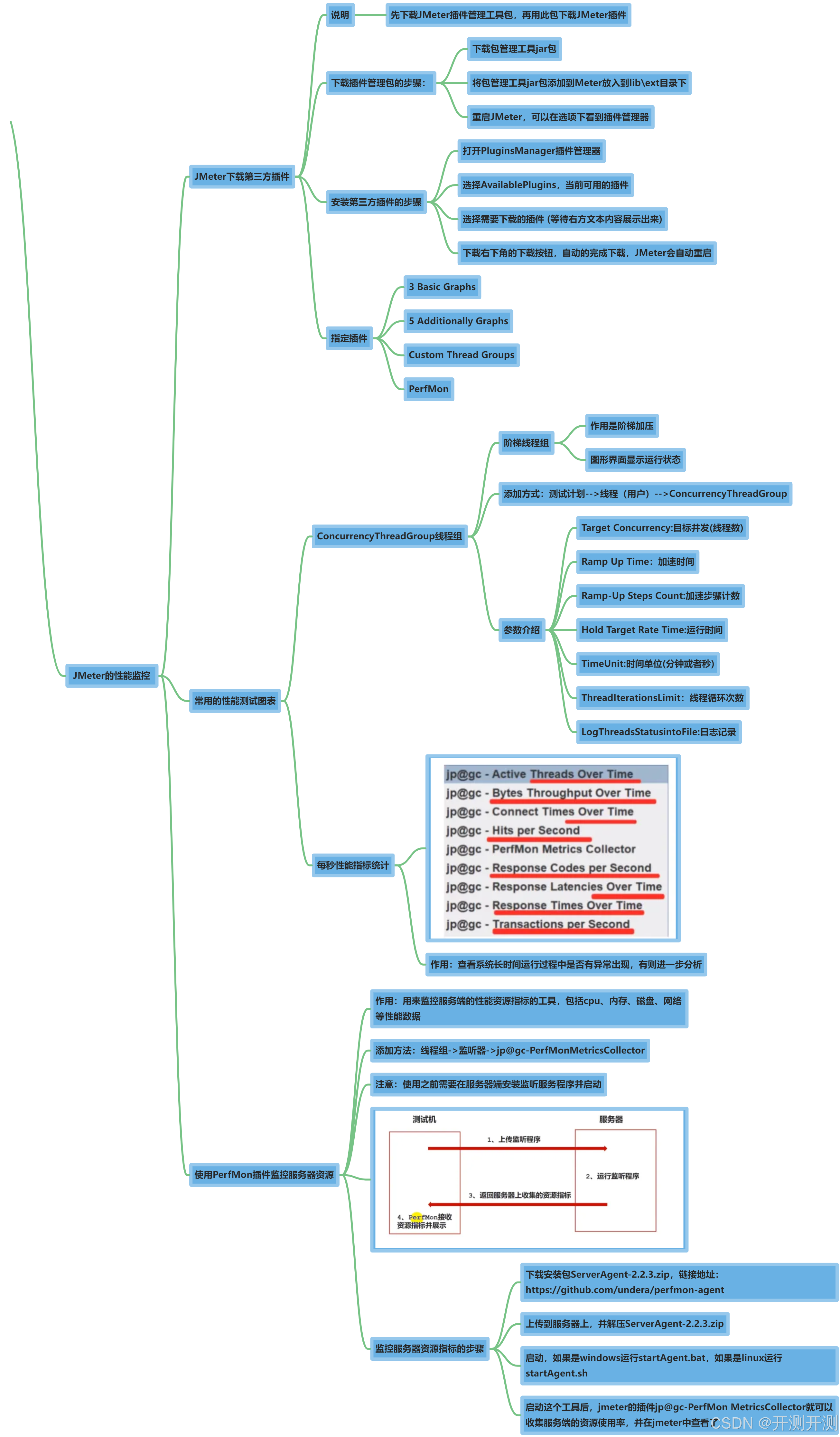
文章目录
- 1. 引言:
- 2. 精读
- 2.1 背景
- 2.2 模型应用
- 2.3 基本原理
- 2.4 其他
- 3. 总结
1. 引言:
在本期的精读会中,我们将深入探讨一篇具有里程碑意义的论文——《MapReduce: Simplified Data Processing on Large Clusters》。这篇论文不仅奠定了大数据时代分布式处理的基石,更以其创新的数据处理模式,成为大数据处理架构的核心组成部分。MapReduce的设计哲学和实现机制,对于揭示现代大规模数据处理的内在逻辑具有不可估量的价值。
本文将引导读者:
- 探讨MapReduce在大规模数据集中的应用场景。
- 深入剖析MapReduce的核心架构和基本原则。
- 解析MapReduce在数据容错方面的挑战。
- 展望MapReduce在未来技术发展中的潜在演变和应用。
无论您是大数据领域的资深专家,还是刚刚迈入数据科学领域的新兵,我们都将一同踏上这段探索之旅,深入挖掘MapReduce的深层次魅力和实用价值。
2. 精读
2.1 背景
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
首先,介绍了MapReduce是一种编程模型及其配套的实现框架,专门设计用于处理和生成大规模数据集。在这个模型中,用户定义两个关键函数:map函数和reduce函数。Map函数负责处理输入的键/值对,并通过一定的逻辑转换生成一组中间键/值对。随后,reduce函数的作用是将所有具有相同中间键的值合并起来,从而实现数据的汇总和归纳。
Hundreds of MapReduce programs have been implemented, and upwards of one thousand MapReduce jobs are executed on Google’s clusters every day.
然后,说了一下已经投入的使用情况,强调MapReduce在Google内部的广泛应用和高效性。具体来说:
- 应用广泛:已经实现了数百个
MapReduce程序,说明该模型被广泛用于各种任务。 - 规模宏大:每天在
Google集群上执行超过一千个MapReduce作业,显示出其在处理大规模数据时的效率和可靠性。
The issues of how to parallelize the computation, distribute the data, and handle failures conspire to obscure the original simple computation with large amounts of complex code to deal with these issues.
接着,指出,尽管计算本身可能很简单,但在并行化计算、分发数据和处理故障时,会产生大量复杂的代码,从而使得原本简单的计算变得复杂。这强调了在大规模数据处理中,基础设施管理和代码复杂性是主要挑战。这也是本文需要解决的问题。
We realized that most of our computations involved applying a map operation to each logical “record” in our input to compute a set of intermediate key/value pairs, and then applying a reduce operation to all the values that shared the same key, in order to combine the derived data appropriately.
随后,他们发现大多数计算任务可以通过两个步骤来完成:首先,对每个输入记录应用一个map操作,生成一组中间键值对;然后,对所有具有相同键的值应用reduce操作,以适当的方式合并派生的数据。这描述了MapReduce模型的核心流程,简化了复杂的数据处理任务。
The major contributions of this work are a simple and powerful interface that enables automatic parallelization and distribution of large-scale computations, combined with an implementation of this interface that achieves high performance on large clusters of commodity PCs.
最后,点出本文工作的主要贡献在于提供了一个简单而强大的接口,该接口能自动实现大规模计算的并行化和分布式处理。同时,这个接口的实现能够在由普通PC组成的大型集群上达到高性能。这强调了MapReduce模型的简洁性、易用性和高效性。
Section 2 describes the basic programming model and gives several examples.
Section 3 describes an implementation of the MapReduce interface tailored towards our cluster-based computing environment.
Section 4 describes several refinements of the programming model that we have found useful.
Section 5 presents performance measurements of our implementation for a variety of tasks.
Section 6 explores the use of MapReduce within Google, including our experiences in using it as the basis for a rewrite of our
production indexing system.
Section 7 discusses related and future work.
以及介绍了本文的论文结构,本文重点探讨第二、三章
- 第2节:介绍了基本的编程模型,并给出了几个示例。
- 第3节:描述了针对集群计算环境的MapReduce接口实现。
- 第4节:介绍了在编程模型中的一些有用改进。
- 第5节:展示了我们实现的各种任务的性能测量。
- 第6节:探讨了MapReduce在Google内部的使用,包括将其用于改写生产索引系统的经验。
- 第7节:讨论了相关工作和未来的发展方向。
2.2 模型应用
在MapReduce框架中,计算过程从一组输入键/值对开始,并最终产生一组输出键/值对。这一过程由用户通过定义两个关键函数来实现:Map和Reduce。
Map函数由用户编写,它接收一个输入键/值对,并负责生成一组中间键/值对。MapReduce库随后负责将所有具有相同中间键的中间值聚集在一起,为下一步处理做好准备。
Reduce函数同样由用户定义,它接收一个中间键以及与该键相关联的所有中间值。Reduce函数的职责是将这些值进行合并处理,通常会产生一组数量更少的输出值。在通常情况下,每次Reduce函数调用仅生成零个或一个输出值。中间值通过迭代器的形式提供给用户的Reduce函数,这种设计允许MapReduce框架处理那些太大而无法一次性载入内存的值列表。
通过这种分阶段的处理模式,MapReduce库能够有效地处理大规模数据集,同时保持了用户代码的简洁性和易于管理。
// Map函数处理输入的文档,将每个单词映射为一个键/值对,其中值是“1”。
map(String key, String value) {
// key: 文档名称
// value: 文档内容
for each word w in value:
// 为每个单词w发射一个中间键/值对,键是单词本身,值是字符串"1"。
EmitIntermediate(w, "1");
}
// Reduce函数接收一个单词和该单词所有出现次数的迭代器,
// 然后合并这些次数以产生最终的单词计数。
reduce(String key, Iterator values) {
// key: 一个单词
// values: 该单词出现次数的列表
int result = 0;
for each v in values:
// 将字符串值解析为整数并累加到结果中
result += ParseInt(v);
// 生成最终的单词计数
Emit(AsString(result));
}
map(k1,v1) -> list(k2,v2)
reduce(k2,list(v2)) -> list(v2)
还有其他的一些应用场景如下所示:
1. 分布式字符串匹配 grep
map 函数负责输出匹配某个模式的每一行,而 reduce 函数则不进行任何计算,仅将这一行输出。最终,得到的结果是所有匹配的文本行。
2. 计算 URL 的访问频率
map 函数记录每个请求,输出形式为 (url, 1);而 reduce 函数则将相同 URL 的访问计数相加,最终生成 (url, sum_of_count)。
3. 倒转网络链接关系
搜索引擎排序算法 PageRank 需要使用爬虫获取所有页面的 source 及其内部链接 target。每个 source 内可能会有多个 target,在门户网站中,一个 source 拥有上千个 target 是很常见的。
这就要求网络爬虫统计每个链接 target 被哪些 source 引用。最初,我们得到的是 (source, target) 数据对,如何将其转换为 (target, list(source)) 呢?这时,MapReduce 的作用便凸显出来。
map 函数负责输出 (source, target) 对,而 reduce 函数则将相同的 target 进行归并,生成 (target, list(source))。
4. 确定每个 Host 的检索词向量(Term-Vector)
检索词向量是一系列(单词,词频)对,这些数据能够总结一篇文档或一系列文章中最重要的单词(假设词频越高,单词越重要)。
一个 Host 可能包含大量文档,如何确定该 Host 的检索词向量呢?
map 函数负责输出每个输入文档的 (host, term-vector),而 reduce 函数则汇总给定 Host 的所有 term-vector,过滤掉低频词,最终输出唯一的 (host, term-vector)。
5. 倒排索引
正排索引的形式为 (document, {keys}),从文档出发以检索关键词。
然而,正排索引在搜索引擎中的作用有限,因为我们需要根据关键词检索对应的所有文档。因此,更需要的是 (key, {documents}) 这种索引形式。
倒排索引是关键词到文档的映射,每个关键词都对应着一系列文档。
map 函数分析每个文档,为每个单词生成 (word, document) 的映射;而 reduce 函数则汇总所有相同单词的数据对,输出形式为 (word, {documents}),并可能进行排序。
2.3 基本原理

MapReduce框架的执行过程可以概述为以下几个关键步骤:
-
输入分割:用户程序中的
MapReduce库首先将输入文件分割成M个片段,每个片段通常大小在16MB到64MB之间,用户可以通过可选参数控制。 -
启动作业:程序在集群的多台机器上启动多个副本,其中一个机器作为
master,其余作为worker。 -
任务分配:
master负责分配M个map任务和R个reduce任务给空闲的worker。 -
Map任务执行:被分配
map任务的worker读取相应输入片段的内容,解析出键/值对,并将其传递给用户定义的Map函数。Map函数生成的中间键/值对在内存中缓冲。 -
中间数据写入:缓冲的中间数据定期写入本地磁盘,并根据分区函数划分为R个区域。这些缓冲数据在本地磁盘上的位置信息被发送回
master。 -
Reduce任务执行:
master通知reduce worker这些位置信息,reduce worker使用远程过程调用从map worker的本地磁盘读取缓冲数据。读取完所有中间数据后,reduce worker按中间键排序,并将每个唯一的中间键及其对应的值集合传递给用户定义的Reduce函数。 -
输出结果:
Reduce函数的输出被追加到最终输出文件中,每个reduce任务对应一个输出文件。 -
作业完成:所有
map和reduce任务完成后,master唤醒用户程序,MapReduce调用在用户程序中返回。
MapReduce的工作流程就像是在厨房里准备一场大型宴会:首先,大厨(Master节点)将大量的食材(数据)切成小块(分割数据),然后分配给一群厨师(Worker节点)去处理。每个厨师根据食谱(Map函数)进行初步烹饪,比如统计每种食材的使用量。接着,他们将处理好的食材暂时存放起来。随后,大厨将相同类型的半成品收集起来,交给另一组厨师进行最终烹饪(Reduce函数),比如将所有相同的食材合并成一道菜。最后,当所有菜肴都准备好后,大厨将它们端上桌,供宾客享用(输出结果)。如果某个厨师无法完成任务,大厨会迅速找其他厨师来替补,确保宴会能够顺利进行。整个过程是自动化的,每个步骤都紧密协调,以确保最终的菜肴既美味又及时。
Hadoop MapReduce的执行流程与Google MapReduce有许多相似之处,因为Hadoop的设计受到了Google MapReduce论文的启发。以下是Hadoop MapReduce执行流程的概述图。

在 Hadoop 3.x 版本中,MapReduce 作业的执行流程分为两个主要阶段:Map 阶段和 Reduce 阶段。以下是这两个阶段的详细描述:
Map 阶段:
- 作业提交:用户通过客户端提交 MapReduce 作业,包括
Map和Reduce任务。 - 资源申请:
ApplicationMaster向ResourceManager申请执行Map任务所需的资源。 - 任务分配:
ResourceManager根据集群资源情况,将Map任务分配给NodeManager执行。 Map任务执行:NodeManager在分配的容器中启动Map任务,Map任务读取输入数据,处理后生成中间键/值对。- 中间数据输出:
Map任务将处理结果输出到本地磁盘,为后续的 Shuffle 和 Sort 阶段做准备。
Reduce 阶段:
- Shuffle 阶段:
Map任务的输出被传输到Reduce任务。这个过程称为 Shuffle,它包括排序和合并Map任务的输出,以便为Reduce任务提供有序的输入。 - 资源申请:
ApplicationMaster向ResourceManager申请执行Reduce任务所需的资源。 - 任务分配:
ResourceManager将Reduce任务分配给NodeManager执行。 Reduce任务执行:NodeManager在分配的容器中启动Reduce任务,Reduce任务读取经过 Shuffle 阶段排序的中间数据,进行汇总和处理。- 输出结果:
Reduce任务将最终结果写入到 HDFS(Hadoop Distributed File System)中。
在整个过程中,ApplicationMaster 负责协调 Map 和 Reduce 任务的执行,监控任务进度,并与 ResourceManager 和 NodeManager 进行通信。此外,Hadoop 3.x 引入了更多的优化和改进,例如改进的 Shuffle 机制、更好的资源隔离和更高效的数据本地化,以提高 MapReduce 作业的性能和可靠性。
JobTracker是 Hadoop 1.x 版本中的关键组件,它负责管理和调度 MapReduce 作业。在 Hadoop 1.x 版本中,JobTracker与TaskTracker配合工作,其中JobTracker负责作业的调度和监控,而TaskTracker则在各个节点上执行实际的任务。
随着 Hadoop 生态系统的发展,为了解决 Hadoop 1.x 版本中的可扩展性和资源管理问题,Hadoop 2.x 版本引入了 YARN(Yet Another Resource Negotiator)作为集群资源管理器。在 Hadoop 2.x 版本中,JobTracker的职责被拆分,其中作业调度和监控的职责由ResourceManager组件承担,而任务的执行则由NodeManager组件负责。
// 设置Hadoop用户名为"hadoop"
System.setProperty("HADOOP_USER_NAME","hadoop");
// 创建Hadoop配置对象
Configuration configuration= new Configuration();
// 设置默认的文件系统为HDFS,并指定HDFS的地址
configuration.set("fs.defaultFS","hdfs://192.168.1.200:8020");
// 创建一个Job对象
Job job = Job.getInstance(configuration);
// 设置Job的Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置Job的Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出的Key和Value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer输出的Key和Value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 获取FileSystem对象
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.1.200:8020"),configuration,"hadoop");
// 设置输出路径
Path output=new Path("/map/output");
// 如果输出路径已存在,则删除它
if(fs.exists(output)){
fs.delete(output,true);
}
// 设置作业的输入路径
FileInputFormat.setInputPaths(job,new Path("/map/input"));
// 设置作业的输出路径
FileOutputFormat.setOutputPath(job,new Path("/map/output"));
// 提交作业并等待作业完成
boolean result=job.waitForCompletion(true);
// 根据作业执行结果退出程序,成功返回0,失败返回-1
System.exit( result ? 0:-1);
详细见:Hadoop基础-07-MapReduce概述
https://blog.csdn.net/jankin6/article/details/109060857
2.4 其他
2.4.1 Master Data Structures
描述了 Master 节点在 MapReduce 框架中维护的数据结构。
-
任务状态信息:
Master节点记录每个Map和Reduce任务的状态,包括它们是否处于空闲、进行中或已完成。 -
工作节点信息:
Master节点跟踪每个Worker节点的状态,以便在它们空闲时分配任务。 -
中间数据位置:起到了一个管道的作用,对于每个完成的
Map任务,Master节点存储了中间数据的位置和大小信息,这些信息对于后续的Reduce任务是必要的。 -
任务调度信息:
Master节点负责任务调度,确保任务在集群中的机器上得到有效分配。 -
容错机制:
Master节点处理节点故障,确保任务在失败时能够重新调度。
这些数据结构使得Master节点能够有效地管理和协调MapReduce作业的执行。
2.4.2 Fault Tolerance
描述了MapReduce框架如何处理故障,以确保数据处理的高可用性和容错性。
-
Worker节点故障:
Master节点定期向所有Worker节点发送心跳信号,以检测它们的状态。- 如果某个
Worker节点在一定时间内没有响应,Master节点会将其标记为失败。 - 失败的
Worker节点上已完成的Map任务需要重新执行,因为它们的输出可能存储在失败节点的本地磁盘上,而无法访问。 - 失败的
Worker节点上正在进行的Map或Reduce任务会被重新调度到其他节点上执行。
-
Master节点故障:Master节点会定期保存其数据结构的检查点(checkpoints),以便在Master节点失败时可以从最后一个检查点恢复。- 由于
Master节点通常是单点,它的失败可能会影响整个作业的执行。当前的实现中,如果Master节点失败,MapReduce作业将被中止。
-
故障情况下的语义:
- 当用户提供的
Map和Reduce操作是确定性的,即对于给定的输入总是产生相同的输出时,MapReduce的分布式实现将产生与无故障顺序执行相同的结果。 - 为了实现这一属性,MapReduce依赖于原子提交任务输出。每个任务的输出被写入私有的临时文件中,任务完成时,这些文件会被原子地重命名或移动到最终位置。
- 当用户提供的
-
数据完整性:
- 即使在出现故障的情况下,MapReduce也确保数据处理的原子性和一致性,从而保证了数据处理结果的正确性。
2.4.3 Refinements
描述了对基本MapReduce模型的一些扩展和改进,以提高其灵活性和实用性。
-
分区函数(Partitioning Function):
- 用户可以指定一个分区函数来决定如何将中间键分配到不同的Reducer上。默认使用哈希函数,但也可以根据特定需求定制分区逻辑。
-
排序保证(Ordering Guarantees):
- MapReduce保证了在同一个分区内的键/值对是按照键的顺序排序的。这有助于生成有序的输出文件,特别是当输出格式需要支持高效的随机访问查找时。
-
组合器函数(Combiner Function):
- 为了减少网络传输量,用户可以定义一个Combiner函数在Map任务完成后进行局部聚合。这通常与Reducer函数使用相同的代码,但输出到中间文件而不是最终输出。
-
输入和输出类型(Input and Output Types):
- MapReduce支持多种输入和输出格式,用户可以根据需要实现自定义的读写器。
-
副作用(Side-effects):
- 用户的Map或Reduce函数可能会产生额外的输出文件。系统依赖于用户确保这些副作用是原子的和幂等的。
-
跳过错误的记录(Skipping Bad Records):
- 当Map或Reduce函数因为某些输入记录而崩溃时,MapReduce提供了一种模式来检测并跳过这些记录,以便作业可以继续执行。
-
本地执行(Local Execution):
- 为了便于调试和测试,MapReduce提供了一个可以在本地机器上顺序执行所有任务的模式。
-
状态信息(Status Information):
Master节点提供了状态页面,显示作业的进度和资源使用情况,帮助用户监控作业执行。
-
计数器(Counters):
- MapReduce提供了一个计数器机制,允许用户在Map和Reduce函数中创建和更新计数器,以跟踪特定事件的发生次数。
3. 总结
综上所述,MapReduce编程模型通过用户定义的map和reduce函数,将复杂的数据处理任务转化为直观的操作,并自动并行化处理,极大提高了计算效率,尤其在大规模集群环境中表现出色。其内置的容错机制确保了数据处理的可靠性,使得MapReduce在文本分析、数据挖掘和网页索引等多个领域得到广泛应用。
更重要的是,MapReduce降低了大数据技术的使用门槛,推动了数据处理效率的提升,并促进了大数据生态系统的发展,催生了诸如Hadoop等关键技术框架,为大数据的发展做出了深远的贡献。
最后,由于篇幅限制,一些数据验证的深入讨论并未在此展开。对于有兴趣进一步探索的读者,我建议精读全文以获得更全面的了解。
获取原文
- GItHub:https://github.com/hiszm/BigDataWeekly/tree/main/资料
- 公众号回复:003
如果你想参与讨论,请 点击这里👉https://github.com/hiszm/BigDataWeekly,每周都有新的主题,周末或周一发布。
大数据精读,探索知识的深度。
关注 大数据精读周刊 微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)