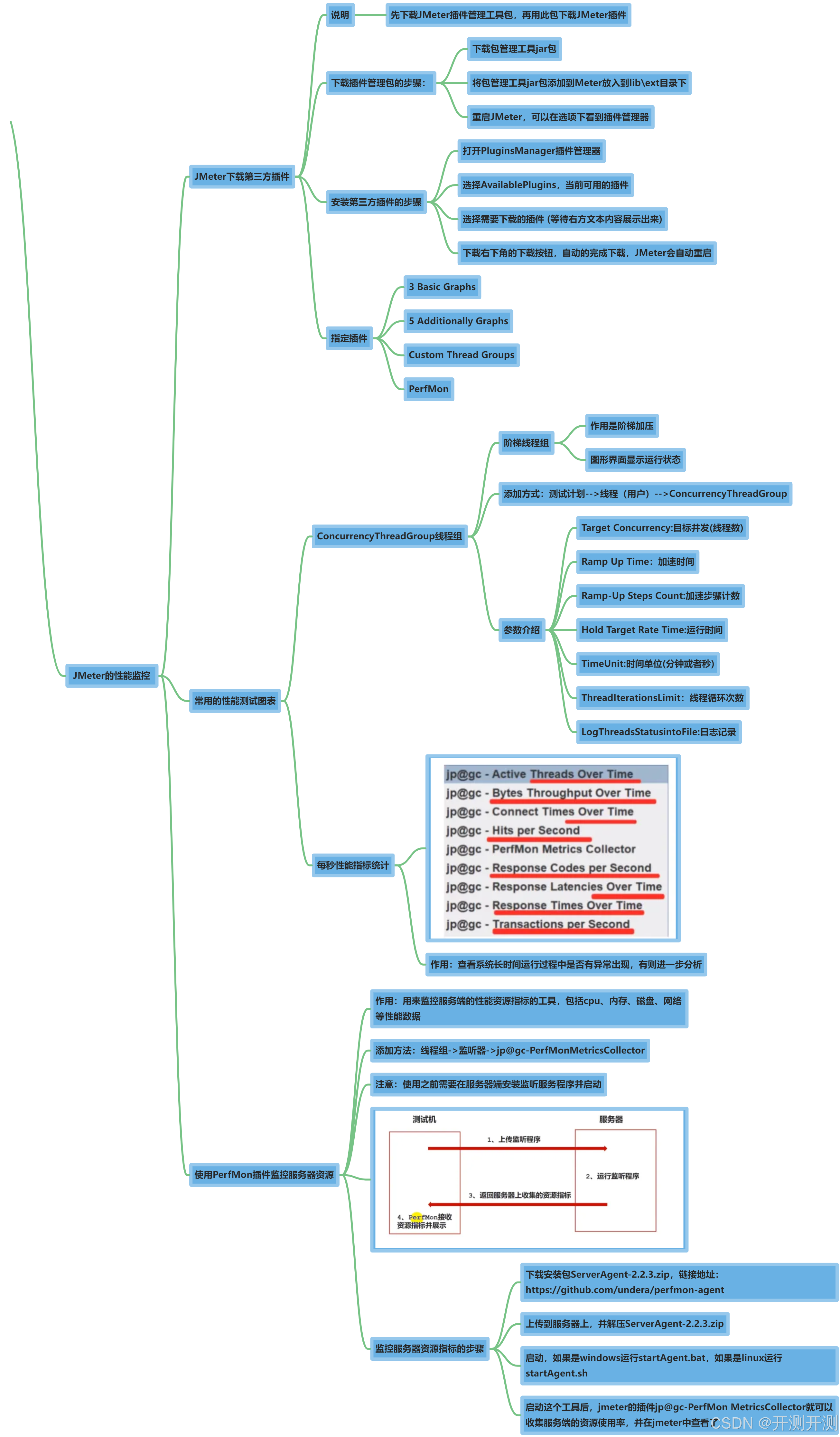
Disjoint-set data structure
不相交集, 通常称作并查集的一种数据结构。
- 应用范围:处理不相交集合的合并查询问题,它在处理这两种的时间复杂度在实际应用上往往认为是 O ( 1 ) O(1) O(1),稍后本篇会略加说明。
- 接受两种操作:判断两元素是否在同一集合里(
isSameSet), 合并两个不相交的集合(Union)。
3.应用算法: 无向图的连通分量, 网络连接 , 图的最小生成树算法(Kruskal)。
不过这里我们直接说明优化版本的不相交集, 舍去一些繁琐的步骤, 把最佳的方式呈现出来。
优化方式: 路径压缩和按秩合并。-----不过这些篇幅在靠后, 前面我们还得为并查集铺垫一会儿。
前言
学习难度:完成初阶数据结构 - 重点哈希表。 略微涉及图的术语和表示(若您看过有关概念,学习过离散数学,那么您不会有任何障碍。否则请自行)
编程语言:Java为主, Python(方便引入举例, 会比较详细地说明)–C语言版本未写。
序幕
首先,我们先要把单个对象封装成集合, isSameSet , Union ,都是作为集合之间的运算。
也许你可以实现这一样一个接口makeSet ,将单个对象封装成只要该对象的集合。
为什么要这样做?而不是单独地就认为它是一个集合
逻辑上简单处理:无论对象的类型是什么,并查集永远地对自身内的集合操作,避免了不必要的类型检查。
将单个对象弄成集合,避免了单个对象和多对象集合之间操作的讨论。
其次,为每个单对象建立一个新集合,可以确定集合之间肯定不相交,因为它们在内存中分配了不同的地址。假设不这么做,如一个对象就是一个单独的字符串"Malan",另一个对象是字符串"Malan",但认为两者是不同的人,可能重名了,执行合并操作时。可能会出现误判的情况,即两个相同的字符串被认为是同一个对象,从而错误地合并它们,而封装成集合就没事了。
对象是什么类型不关心,因为内部接口始终操作的是自定义的集合类型element,这也给并查集带来极强的拓展性和更方便维护。
-
下面解释
isSameSet这个函数,判断两个元素是否在同一集合里。
isSameSet(V x,V y),传递两个对象,如果这两个对象在现有集合里,那么判断两个集合是否是一个。
可能有点抽象,不过下面会配图理解。 -
union操作, 将包含两个对象的集合合并在一起(如果它们在集合里,且不在同一个集合里)。假设x对象对应的集合有 S x S_x Sx,y对象对应集合是 S y S_y Sy, 那么相当于 S x U S y S_x U S_y SxUSy。, 一般通过,销毁其中一个集合,把集合元素放入另一个集合 。 -
下面我们谈谈如何设计集合, 当我们为单个元素执行
makeSet操作时,需要一个指针指向自身。
当我们连接两个集合时,只要更改指针指向即可。
每个集合均有一个代表元素,类似树的根节点,判断两个对象是否在同一集合就是看其代表元素根节点是不是同一个。
下面举一个例子理解。
并查集动画
举例
图1a

并查集求解图的连通分量
连通分量(Connected Components)是图论中的一个重要概念, 图1a是原图,那么从左往右的三部分就是一个一个的连通分量。因此, 连通分量是原图的子图, 原图是不连通的, 而其各个顶点两两连通的最大子图就是它其中之一的连通分量,图·1a的连通分量数量有三个。
无向图中,一个连通分量是一个极大连通子图。
显然,若原图本身就是一个连通图, 那么连通分量就是它本身。
接下来,方便叙述,我们采用python实现一下。
这里用到了图的邻接表表示,这里python一个字典(哈希表)就能实现。
表示图1a
graph = {
'a': ['b', 'c'],
'b': ['a', 'c', 'd'],
'c': ['a', 'b'],
'd': ['b'],
'e': ['f', 'g'],
'f': ['e'],
'g': ['f'],
'h': ['i'],
'i': ['h'],
'j': []
}
忽略并查集的实现, 求解连通分量
# 实现一个函数,统计图所有连通分量的个数
# @param: graph-图
def count_connected_components(graph):
# 将图的所有顶点(即键key的集合)传参,并查集初始化其为一个个集合
uf = UnionFind(graph.keys())
# 合并关联的所有顶点
for v in graph:
for nei in graph[v]:
uf.union(v, nei)
# 将各个连通分量加入集合中
root_set = set()
for v in graph:
root_set.add(uf.find(v))
# 返回连通分量的个数
return len(root_set)
- python解释:
uf = UnionFind(graph.keys())
这里未提供UnionFind这个类的实现细节。,
graph.keys() 是python字典(内置哈希表)的一个方法, 这里返回所有的键,它是一个字典视图对象, 而不是一个所谓的动态数组(列表), 它会根据内容改变实时更新。- 如同上面序幕所说, ′ a ′ 'a' ′a′ 成为了 { a } \{ a \} {a} , ′ b ′ 'b' ′b′成为了 { b } \{b \} {b}等等。
# 合并关联的所有顶点
for v in graph:
for nei in graph[v]:
uf.union(v, nei)
依次遍历每个顶点,将每个顶点与它相邻的顶点合并成一个集合。
或许你可能问, 万一有重复的两顶点关联呢?别担心union方法内部细节已经判断了重复的情形。—不过具体实现union在下文展开。
# 将各个连通分量加入集合中
root_set = set()
for v in graph:
root_set.add(uf.find(v))
set():创建一个空集合, 集合的特点是不允许添加重复元素。
依次遍历图的顶点, 并取该顶点所在集合的代表元素(根节点)。
比如:a,b,c,d的代表元素假设是a, 那么调用uf.find(v)的结果都是a,那么相当于set只记录一次。 同理,e,f,g的代表元素假设为e,那么这三个点调用find方法结果都是e,那么set也只记录一次。后面,h,i为1次, j是单独的孤立点也记录一次。 那么set里面有4个元素。
# 返回连通分量的个数 return len(root_set),那么对于这个图1a的连通分量结果为4,显然也是符合图中的结果。
结果

实现
🆗,举例完成,让我们讨论一下实现细节。
列表版本的并查集
事先声明,这是一个糟糕的设计。
集合列表(List of Sets)来实现并查集。
有关于python中的set。
class SetUnionFind:
# 将对象们转化成单元素集合,挨个存放在列表里
def __init__(self, elements):
self.set_list = [{element} for element in elements]
# 找每个集合的代表元素
def find_head(self, value):
# 遍历集合列表
for s in self.set_list:
if value in s: # 判断对象是否在对应集合里。
return s
return None
# 合并
def union(self, head1, head2):
set1 = self.find_head(head1)
set2 = self.find_head(head2)
if set1 != set2:
set1.update(set2)
self.set_list.remove(set2)
# 判断两对象是否在同一集合。
def is_same_set(self, head1, head2):
return self.find_head(head1) == self.find_head(head2)
时间复杂度分析, 其中n输入elements个数。 m为单个集合的平均长度。
| Init | find_head | union | is_same_set |
|---|---|---|---|
| O ( n ) O(n) O(n) | O ( n × m ) O(n\times m) O(n×m) | O ( n × m ) O(n\times m) O(n×m) | O ( n × m ) O(n\times m) O(n×m) |
当然,这种实现方式处理小规模的合并还可以, 至于大规模数据效率非常低下。
快速查找
find_head方法查询根节点速度太慢了,所以我们尝试用哈希表实现一个快速查找的并查集。
🆗,让我们把语言切换到Java。
使用两个哈希表, 一个elementMap封装成集合,另一个fatherMap记录每个节点所在集合的代表元素。
//QuickFindUnionFindSet.java
import java.util.Collection;
import java.util.HashMap;
public class QuickFindUnionFindSet<T> {
public static class Element<T>{
T value;
public Element(T value) {
this.value = value;
}
}
public HashMap<T,Element<T>> elementMap;
public HashMap<Element<T>,Element<T>> fatherMap;
public QuickFindUnionFindSet(Collection<? extends T> list) {
//初始化哈希表
elementMap = new HashMap<>();
fatherMap = new HashMap<>();
for(T x: list) {
Element<T> elem = new Element<>(x);
elementMap.put(x, elem);
fatherMap.put(elem, elem);
}
}
//查询速度O(1)
private Element<T> findHead(T x){
Element<T> elemX = elementMap.get(x);
return fatherMap.get(elemX) ;
}
//判断速度O(1)
public boolean isSameSet(T x, T y) {
Element<T> elemX = elementMap.get(x);
Element<T> elemY = elementMap.get(y);
return fatherMap.get(elemX) == fatherMap.get(elemY);
}
//合并操作,O(n)因为要遍历哈希表
public void union(T x, T y) {
if(!isSameSet(x, y)) {
Element<T> headX = findHead(x);
Element<T> headY = findHead(y);
for(Element<T> key: fatherMap.keySet()) {
if(fatherMap.get(key) == headX) {
fatherMap.put(key, headY);
}
}
}
}
}
由于fatherMap存储的是每个集合的代表元素。
findHead查询速度为
O
(
1
)
O(1)
O(1),内部只是调用了哈希表获取父节点的地址, isSameSet内部调用了两次findeHead函数,时间复杂度同样是
O
(
1
)
O(1)
O(1)。
union将所有父节点为headX的节点更改为headB, 逻辑图来看效果等同于合并了两个集合了, 不过由于要更改所有,不得不遍历整个哈希表,所以时间复杂度是
O
(
n
)
O(n)
O(n)。
不过只追求查询速度, 可不是并查集的最终形态。
快速合并
加快合并速度。
我们重新设计fatherMap,使得其不是表示元素到根节点的映射,而是元素到其父节点的映射。
import java.util.HashMap;
import java.util.Collection;
public class QuickUnion<T> {
// 内部类,用于表示集合中的元素
public static class Element<T> {
T value; // 元素的值
public Element(T value) {
this.value = value;
}
}
// 映射:元素值到元素对象的映射
public HashMap<T, Element<T>> elementMap;
// 映射:元素对象到父节点的映射
public HashMap<Element<T>, Element<T>> fatherMap;
// 构造函数:初始化并查集
public QuickUnion(Collection<? extends T> list) {
elementMap = new HashMap<>();
fatherMap = new HashMap<>();
// 遍历输入集合,为每个元素创建一个新的 Element 对象
// 并将其自身作为父节点
for (T value : list) {
Element<T> elemV = new Element<>(value);
elementMap.put(value, elemV); // 将元素值映射到元素对象
fatherMap.put(elemV, elemV); // 每个元素的父节点指向自身
}
}
// 查找操作:找到元素 x 的根节点
private Element<T> findHead(T x) {
Element<T> elem = elementMap.get(x); // 获取元素对象
if (elem == null) {
return null; // 如果元素不存在,返回 null
}
// 路径压缩:将查找路径上的所有节点直接连接到根节点
if (fatherMap.get(elem) != elem) {
fatherMap.put(elem, findHead(fatherMap.get(elem)));
}
return fatherMap.get(elem); // 返回根节点
}
// 判断两个元素是否在同一个集合中
public boolean isSameSet(T x, T y) {
return findHead(x) == findHead(y); // 比较两个元素的根节点是否相同
}
// 合并操作:将两个元素所在的集合合并
public void union(T x, T y) {
Element<T> headX = findHead(x); // 查找 x 的根节点
Element<T> headY = findHead(y); // 查找 y 的根节点
// 如果 x 和 y 不在同一个集合中,将 x 的根节点的父节点指向 y 的根节点
if (headX != null && headY != null && headX != headY) {
fatherMap.put(headX, headY);
}
}
}
| Init | findHead | union | isSameSet |
|---|---|---|---|
| O ( n ) O(n) O(n) | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
findHead由于需要循环fatherMap往上爬找到根节点, 循环次数取决于树的高度,最坏情况要走
O
(
n
)
−
类
似
链
表
最
坏
情
况
。
O(n)-类似链表最坏情况。
O(n)−类似链表最坏情况。
isSameSet的时间复杂度取决于findHead,时间复杂度也是
O
(
n
)
O(n)
O(n)。
union,单论合并这个操作确实是常数时间, 但实际上调用findHead时间开销也是
O
(
n
)
O(n)
O(n)。
上述分析说明,findHead这个函数是影响整体时间的罪魁祸首。
对比篇二的QuickFind,findHead函数为常数时间,所以isSameSet`也是常数时间,但这样设计合并要遍历整个哈希表。而该篇的快速合并,合并操作确实快了但受了findHead的牵连,速度被拖累了。
结论:快速合并确实减少了Union的时间开销, 它可能是
O
(
1
)
O(1)
O(1)~
O
(
n
)
O(n)
O(n)取决于findHead函数,但论合并操作次数即使在
O
(
n
)
O(n)
O(n)也比快速查找的Union的
O
(
n
)
O(n)
O(n)快。
这种写法有点像哈希表实现链式结构, 合并组装成一个一个的树,从逻辑结构,它也确实是一棵树。
不过, 合并没有保证
O
(
1
)
O(1)
O(1),这样findHead带来的负面影响让我们很是不爽,而且查询和合并总是一优一劣,难道要我们看应用场景择一吗?
最优版本的并查集
并查集历史
初期发展
并查集的概念最早可以追溯到20世纪60年代。1964年,Bernard A. Galler和Michael J. Fischer在一篇名为《An Improved Equivalence Algorithm》的论文中首次提出了并查集的思想。这篇论文讨论了如何更高效地处理等价关系问题,其中就提到了“合并”和“查找”操作。优化版本
最初的并查集并不高效,就像我们前面的快速查找和快速合并操作,不完美。后来的研究者为了提高效率开发了优化版本。
-
路径压缩(Path Compression): 由
Robert Endre Tarjan在1975年提出, 在查找操作中,将节点直接链接到根节点,从而有效缩短了路径。 -
按秩合并(Union by Rank): 同样由
Tarjan提出。该优化在合并两个集合时,将秩(即树的高度)较小的集合连接到秩较大的集合,减少了树的高度,从而加快了查找操作。
这两种优化带来了什么效果呢? 时间复杂度均为
O
(
1
)
O(1)
O(1)的查找和合并操作。
事实上, 其时间复杂度为近似线性的
O
(
α
(
n
)
)
O(α(n))
O(α(n)),其中
α
(
n
)
α(n)
α(n)是反阿克曼函数,增长非常缓慢,在实际应用中可视为常数。
关于反阿克曼函数,关于具体数学证明可以阅读相关论文或者算法导论(第三版的在21章不相交集21.4部分)
优化过程
我们先说明快速合并这种算法, 前面说过平均调用union时间复杂度
O
(
n
)
O(n)
O(n),因为我们总是要找一个节点的根节点,最坏情况会跑单个表的长度查找路径,同样另一个节点也要该集合的根节点。若两者不是同一集合,那么就让其中一方根节点指向另一方根节点。
为了保证最终逻辑结构中的树相对比较均衡。显然, 我们让小树连接大树,这样合并得到树高比较好,反过来想,一个大树连接小树,这树看起来就要’倒‘了(最坏来看会极度倾斜一方)。
为什么要这么做呢?
这是为了保证节点的查找路径平均摊下来减少了。
这种改进运行时间的策略叫做按秩排序:
按秩合并是一种优化并查集的数据结构的方法,其中“秩”(rank)通常表示树的高度。合并两个集合时,总是将秩较小的树合并到秩较大的树上,以防止树的高度增加过快。
简单来说,就是统计每个集合树的高度(
h
e
i
g
h
t
height
height)或者权重(
s
i
z
e
size
size)。
显然,这是非常方便维护的,我们只需要一个哈希表记录每个集合的权重即可。
为方便实现,我们秩采用树结点的多少来近似替代高度。
引入sizeMap这个哈希表维护集合的大小,这个代码基于原先快速合并的代码拓展的。
注意我将类名改为了WeightQuickUnion。你应该新建一个同名的.java文件。
注释部分是区别。
//WeightQuickUnion.java
import java.util.Collection;
import java.util.HashMap;
public class WeightQuickUnion<T> {
public static class Element<T>{
T value;
public Element(T value) {
this.value = value;
}
}
public HashMap<T,Element<T>> elementMap;
public HashMap<Element<T>,Element<T>> fatherMap;
public HashMap<Element<T>, Integer> sizeMap;//维护集合权重
public WeightQuickUnion(Collection<? extends T> list) {
elementMap = new HashMap<>();
fatherMap = new HashMap<>();
for(T value: list) {
Element<T> elemV = new Element<>(value);
elementMap.put(value, elemV);
fatherMap.put(elemV, elemV);
sizeMap.put(elemV, 1);// 初始化集合大小为1.
}
}
private Element<T> findHead(T x){
Element<T> elem = elementMap.get(x);
if(elem==null) {
return null;
}
while(fatherMap.get(elem) != elem) {
elem = fatherMap.get(elem);
}
return elem;
}
public boolean isSameSet(T x, T y) {
return findHead(x) == findHead(y);
}
public void union(T x, T y) {
if(elementMap.containsKey(x) && elementMap.containsKey(y)) {
Element<T> headX = findHead(x);
Element<T> headY = findHead(y);
//比较那个树更大--权重谁最大
Element<T> greater = sizeMap.get(headX) >= sizeMap.get(headY) ? headX:headY;
Element<T> less = greater == headX ? headY : headX;
if(headX!=headY) {
fatherMap.put(less, greater);
//更新sizeMap,--由于小的跟大的合并了, 先更新大集合的size,然后记得销毁小集合的sizeMap
sizeMap.put(greater, sizeMap.get(greater) + sizeMap.get(less));
}
}
}
}
| Init | findHead | union | isSameSet |
|---|---|---|---|
| O ( n ) O(n) O(n) | O ( l o g 2 n ) O(log_2n) O(log2n) | O ( l o g 2 n ) O(log_2n) O(log2n) | O ( l o g 2 n ) O(log_2n) O(log2n) |
由于相对保证平衡了高度,合并操作时间复杂度最坏降为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)。
这是由于我们让高度维持到对数级别, findHead降到了对数,因此查询和合并也均是对数时间。
对数时间固然可观, 但是完全体并查集可以做到全
O
(
1
)
O(1)
O(1)的时间复杂度。
组合优化
我们已经完成了按秩排序的优化了, 下面在此基础上继续优化。
图片-路径压缩
图片演示的是并查集的另一种优化方案—路径压缩法。
回忆findHead方法每次都会向上寻址找根节点,我们可以在这个函数内部过程做些什么。
做什么呢?将该集合除根节点本身的节点的前继节点全部改为根节点。
private Element<T> findHead(T x){
Element<T> elem = elementMap.get(x);
if(elem==null) {
return null;
}
Stack<Element<T>> stack = new Stack<>();
while(fatherMap.get(elem) != elem) {
stack.push(elem);
elem = fatherMap.get(elem);
}
//elem表示该集合的根节点。
while(!stack.empty()) {
Element<T> tmp = stack.pop();
fatherMap.put(tmp, elem);
}
return elem;
}
通过栈这一容器, 将除根结点外的所有结点的父节点改为了根节点。这意味着下次调用findHead方法,时间复杂度
O
(
1
)
O(1)
O(1)。虽然第一次调用仍然是
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n), 但我们每次调用都作调整, 这意味该优化使得查询根节点的速度是越用越快。那么多次调用摊还这个时间消耗, 就可以认为是
O
(
1
)
O(1)
O(1)。
那么最终的时间复杂度呢?
在样本量可观的情况下, 时间复杂度为:
| Init | findHead | union | isSameSet |
|---|---|---|---|
| O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
。
前面说明并查集历史说过, 时间复杂度是
O
(
α
(
n
)
)
O(\alpha(n))
O(α(n)),l里面是一个反阿克曼函数,这意味操作时间还是和数据规模有关,但其增长速度缓慢。
有多慢呢? ,在实际数据规模内(例如
n
<
=
1
0
12
n<=10^{12}
n<=1012 ,
α
(
n
)
\alpha (n)
α(n) 通常都不会超过 5)
何时视为常数时间?
- n < = 1 0 12 n<=10^{12} n<=1012 , α ( n ) \alpha (n) α(n) 通常都不会超过 5
- 哪怕现实可能存在的数据规模,都视为常数时间
何时将其视为对数时间?
- 几乎不需要。现实不可能有那么大的数据规模。
- 第一次调用findHead函数可以近似认为是对数时间, 但平均来看很小。
何时将其视为线性时间?
- 完全不需要, 现实世界不可能出现。非要形容的话,至少是 1 0 80 个 数 据 规 模 10^{80}个数据规模 1080个数据规模。
结论:最优版并查集的时间复杂度就认为是O(1)。
结尾
分享一下,个人初次学习并查集的代码
public class Coding_UnionFindCode {
public static class Element<V>{
V value;
public Element(V value){
this.value = value;
}
}
/**
*
* @param <V> 元素类型
*/
public static class UnionFindSet<V>{
//3个哈希表搞定完结。
//将元素封装成集合
public HashMap<V,Element<V>> ElemMap;
//跟踪父亲节点
public HashMap<Element<V>,Element<V>> fatherMap;
//存储集合的数据大小
public HashMap<Element<V>,Integer> sizeMap;
/**
* 给定一个有序表将其封装成并查集。
* 时间复杂度:O(N).
* @param list---有序表(实现list接口的均可)可以改成Collection接口,这样可以放栈,队列,堆了.
*/
public UnionFindSet(List<V> list) {
ElemMap = new HashMap<V, Element<V>>();
fatherMap = new HashMap<Element<V>, Element<V>>();
sizeMap = new HashMap<Element<V>, Integer>();
for (var value : list) {
Element<V> elem = new Element<V>(value);
ElemMap.put(value, elem);
fatherMap.put(elem, elem);
sizeMap.put(elem, 1);
}
}
/**
* 寻找某个元素所在集合的根节点,同时进行路径压缩优化,提高查询效率,知道什么叫做O(1)吗。
* @param element
* @return
*/
private Element findHead(Element<V> element){
//用栈,用队列,递归都可以。
Deque<Element<V>> queue = new ArrayDeque<>();
while(element != fatherMap.get(element)){
queue.offer(element);
element = fatherMap.get(element);
}
//摊还数据。并查集结构越用越快。
while(!queue.isEmpty()){
fatherMap.put(queue.poll(),element);
}
return element;
}
public boolean isSameSet(V a,V b){
if(ElemMap.containsKey(a) && ElemMap.containsKey(b)){
return findHead(ElemMap.get(a)) == findHead(ElemMap.get(b));
}
else {
return false;
}
}
public void union(V a, V b){
//给定两个元素必须在对应的集合里
if(ElemMap.containsKey(a) && ElemMap.containsKey(b)){
//找最上面的根节点
Element<V> aF = findHead(ElemMap.get(a));
Element<V> bF = findHead(ElemMap.get(b));
//不相交集合,开始合并,否则跳过直接往后返回。
if(aF != bF){
//小的集合挂大的集合
//先假设最大,代码简单
Element<V> greater = sizeMap.get(aF) >= sizeMap.get(bF) ? aF:bF;
Element<V> less = greater == aF ? bF : aF;
//更新小集合的上集
fatherMap.put(less,greater);
//更新sizeMap的数据。
sizeMap.put(greater, sizeMap.get(aF) + sizeMap.get(bF));
sizeMap.remove(less);
}
}
}
}
}
关于其它语言实现,如C/C++,Go?
个人精力有限,无法兼顾其它语言。
C语言需要调用自己写的通用数据结构容器, 不过框架太复杂了, 不好说明。
C++语法太复杂了, 停留在STL库就没学了, 一般都把C++当成CwithClasses用。
Go语言目前还在基本语法阶段学习。
关于并查集的再次出现
下次出现, 估计会在个人博客的最小生成树(K)算法实现吧, (▽)。
参考
算法导论数据结构与算法分析-C语言描述- ChatGpt—修改代码, 加注释。
最后,谢谢你看到最后。ㄟ(≧◇≦)ㄏ