为什么要使用缓存?
在日常开发中,通常使用Redis来做MySQL的缓存。究其原因,首先,根据二八定律,20%的数据可以应对80%的请求;其次,对于MySQL这样的关系型数据库来说,性能普遍都不是很高。一旦承载的并发量过高,那么就很容易造成宕机,这对生产环境造成的影响是巨大的。但是,对于缓存来说,响应速度是比较迅速的,因而就想到了使用缓存来代替数据库。

首先,想要使用缓存,那么就一定要将缓存放入到Redis中,这就涉及到了缓存的更新策略;其次,Redis的内存并不是无限的,因此就涉及到了缓存的淘汰策略;并且,热点数据可能是暂时的,因此我们在设置缓存时,还给予了一个淘汰时间,从而就涉及到了缓存的超时剔除策略。在把这些八股了解完之后,又出现了缓存预热、缓存穿透、缓存击穿、缓存雪崩四个重要的概念。最后,由于我们学习Redis并不只是为了八股,因此我们还要掌握代码的书写。
更新策略
在日常开发中,一般使用MySQL作为持久层来存储数据,Redis则作为缓冲层来减少对于MySQL的访问,从而防止MySQL因请求过多而宕机的危险。所以,对于Redis中的所有数据,都是来源于MySQL的,这就导致Redis可以存在不同的更新策略,例如定期更新或者实时更新。
定期生成
对于用户访问的数据,以日志的形式进行记录。对日志进行统计(统计时间不定,看具体的业务场景,统计任务可以使用定时任务的方式实现),把出现的数据进行排序,再取出前20%的数据,就认为这些数据是热点数据。再把这些数据同步到缓存服务器上,控制缓存服务器进行重启即可。
至于如何进行统计?在数据量较小的情况下,可以自制一个简单程序进行统计;在数据量较大的情况下,就需要使用大数据的一套技术栈来做。
优点是实现比较简单,缺点就是实时性差一点。
实时生成
当客户端发送请求之后,先在Redis中进行查询。如果存在数据,那么就直接返回;如果没查到,那么就去MySQL中进行查询。当查询到之后,就返回客户端,并写入到Redis中;如果没有查到,那么就属于是缓存穿透了,可以根据实际情况来做出处理。
在实际工作中,对于实时生成的更新策略一般有三种解决方案:
1. 由缓存的调用者,在修改数据库的同时,更新缓存。
2. 缓存与数据库整合成一个服务,由服务来维护一致性。调用者调用该服务,无需考虑缓存一致性问题。
3. 调用者只调用缓存,由其他线程异步的将缓存数据持久化到数据库,保持最终一致,
在三种解决方案中,一致性是由弱到强,维护成本也是由弱到强。
淘汰策略
Redis是一款内存型数据库,但是内存并不和硬盘一样,其价格是比较高昂的。因此我们在使用Redis的过程中,就要考虑当内存占满之后,如何进行淘汰才是最优的解决方案,即我们要找到对程序的性能影响是最小的方案。
通用策略
1. FIFO(first in first out):先进先出
2. LRU(least recently used):淘汰最久未使用的。记录每个key的最近访问时间,把最近访问时间最老的数据给淘汰掉。
3. LFU(least frequently used):淘汰访问次数最少的。记录每个key最近一段时间的访问次数,把访问次数最少的给淘汰掉。
4. Random:随机淘汰。从数据中随机选取数据进行淘汰。
Redis配置项
1. volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU算法进行淘汰。
2. allkeys-lru:当内存不足以容纳写入新数据时,从所有key中使用LRU算法进行淘汰。
3. volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使⽤LFU算法进⾏删除key。
4. allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使⽤LFU算法进⾏淘汰。
5. volatile-random:当内存不⾜以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据。
6. allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
7. volatile-ttl:在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰(相当于FIFO,只不过是局限于过期的key)。
8. noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
总的来说,Redis提供的过期策略和上述介绍的通用策略是基本一致的。只不过Redis会基于有过期时间key和全部key做分别处理。
过期策略
在Redis中,是可以给key设置过期时间的。因此我们就要考虑当key到达到期时间之后,如何对其进行删除。而Redis中,采用了定期删除+惰性删除的方式。
定期删除
定期删除并不是把所有的key都遍历一次,然后将过期的删除。而是每次抽取一小部分,进行验证是否过期(所谓的小部分,就是要保证检查过期的时间足够短)。
这里对于定期删除的时间,是有明确的要求。因为Redis是单线程的程序,如果扫描过期key消耗的时间太长。那么就会导致其他正常的请求被阻塞,从而造成其他的影响。
惰性删除
假设某个key已经到达了过期时间,但是由于定时删除还没有扫描到该key,因此仍然存在于Redis中。此时恰好要使用这个key,这次使用就会让Redis触发删除key的操作,同时再返回一个nil。
定期删除 + 惰性删除两种策略结合,仍然会有一大部分过期key被残留,没有及时删除。
定时器删除
首先,Redis并没有采用定时器来实现过期key删除。但是,如果使用定时器的方式来实现key过期删除也是一个不错的策略。所谓定时器,就是在某个时间到达之后,执行指定的任务。
对于定时器的实现,可以使用优先级队列或者时间轮的方式来实现较高效的定时器。对于Redis中没有使用定时器,可能是因为遵从了Redis单线程的基调。一旦使用定时器,那势必要引入多线程,这就可能打破设计者的初衷。
优先级队列
在Redis中,可以利用key过期时间越早,优先级就越高的方式来进行设置。将队列设置好之后,使用一个线程来扫描队首元素。只要队首没过期,那么后续的key也一定没过期。因此这个扫描线程只需要盯着队首即可。如果扫描线程发现队首key距离过期时间还很长,那么扫描线程就可以进入休眠状态,等到快过期时,再唤醒进行删除即可。如果在休眠过程中来了新的key,也需要唤醒扫描线程,再次检查队首元素是否发生了变化。
时间轮
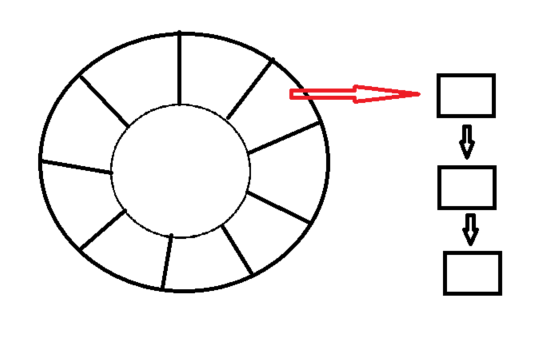
时间轮就是把时间划分成一小段一小段,至于划分区间的大小,就具体看实际需求的多少。对于每一段时间来说,上面都是一个链表,而链表上面就挂着许许多多的key。在时间轮中,存在一个指针,这个指针首先对所在区间进行尝试,看看有没有过期的key,然后等待一定时间间隔之后,就会走到下一个区间去探测,一直循环往复。
值得注意的是,假设规定某一个为1区间,时间间隔为100ms,有10个区间,那么过期时间是1100ms的话,那也是存在于1区间。因此,指针走到某个区间并不是全部过期,而是进行测试哪个过期,哪个还在运行中。并且区间大小,区间多少等也是根据实际需求来的,并不是说规定。
缓存更新策略最佳实践方案
1. 低一致性需求:使用Redis自带的内存淘汰策略。
2. 高一致性需求:主动更新,并以超时剔除作为兜底方案。对于读操作,缓存命中则直接返回;缓存未命中则查询数据库,并写入缓存,设定超时时间。对于写操作,先写数据库,再删除缓存;并且要确保数据库与缓存操作的原子性。
数据库和缓存操作的前后性


由图看出,先操作数据库,再操作缓存。反之,如果先删除缓存,那么就有可能导致缓存和数据库数据的不一致。
在本篇文章中,介绍了内存更新策略、内存淘汰策略以及内存过期策略。在此文章的续篇中,主要来介绍缓存的应用以及缓存预热、缓存穿透、缓存雪崩、缓存击穿的概念及其代码中的解决方案。







![while (r > b[i].r) del(a[r--]); while (r < b[i].r)](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fflowus.cn%2Fpreview%2F8bfd4119-efea-4086-a4b7-a79c71729416&pos_id=img-XBONbYxR-1725195479633)