目录
1.实验知识准备
1.1 NumPy
1.2 Matplotlib 库
1.3 scikit-learn 库:
1.4 TensorFlow
1.5 Keras
2.波士顿房价的数据分析及可视化
2.1波士顿房价的数据分析
2.1.1 步骤一:导入所需的模块和包
2.1.2 步骤二:从 Keras 库中加载波士顿房价数据集
2.1.3 步骤三:加载本地 CSV 数据集
2.1.4 步骤四:划分特征和目标变量
2.1.5 步骤五:划分训练集和测试集
2.1.6 步骤六:查看数据集的特征值和标签值的类型
2.1.7 步骤七:查看数据集的特征值和标签值的属性
2.1.8 步骤八:显示数据集的部分数据
2.2 数据可视化
2.2.1步骤一:设置图形属性
2.2.2步骤二:绘制特征与房价的散点图
2.3 总体代码与结果
2.3.1代码
2.3.2结果
3.鸢尾花数据分析及可视化
3.1鸢尾花数据分析及可视化
3.1.1 步骤一:使用 load_iris() 函数导入 scikit-learn 库中的鸢尾花数据集
3.1.2 步骤二:获取特征值和标签值
3.1.3. 步骤三:访问数据集数据
3.1.4 步骤四:显示数据集的前10条特征值和标签值数据
3.1.5 步骤五:绘制花瓣长度和花瓣宽度与鸢尾花品种的散点图
3.2总体代码和效果
3.2.1代码
3.2.2效果
1.实验知识准备
1.1 NumPy
- 简介:NumPy 是一个高性能科学计算和数据分析的基础库,提供了多维数组对象(ndarray)及其操作函数。它极大地简化了多维数组的操作和处理过程,在数据处理、科学计算、机器学习等领域广泛使用。
- 关键功能:数组创建、数组运算、线性代数、数组形状变换、随机数生成等。
1.2 Matplotlib 库
- 简介:Matplotlib 是 Python 的一个 2D 绘图库,广泛用于数据可视化。借助 Matplotlib,可以绘制各种图表,如折线图、散点图、直方图、饼图、热图等。
- 关键功能:图形绘制、坐标轴设置、图形美化、图例添加、子图排列、图形保存等。
1.3 scikit-learn 库:
- 简介:scikit-learn 是基于 NumPy、Matplotlib 和 SciPy 的机器学习算法库,封装了大量的机器学习算法(包括有监督学习、无监督学习及半监督学习),并内置了许多标准数据集。
- 关键功能:数据预处理(如归一化、标准化)、模型训练、模型选择、模型评估、模型调优等。
1.4 TensorFlow
- 简介:TensorFlow 是一个以张量(Tensor)为基础,并对其进行各种运算的深度学习框架。它是由谷歌开发的开源软件库,广泛用于机器学习和深度学习应用。
- 关键功能:张量定义与运算、自动求导、构建神经网络模型、训练与评估模型等。
1.5 Keras
- 简介:Keras 是一个使用 Python 编写的开源人工神经网络库,作为 TensorFlow 的高阶应用程序接口,简化了深度学习模型的设计、调试、评估、应用和可视化等过程。
- 关键功能:模型构建(Sequential API 和 Functional API)、模型编译、模型训练与评估、模型保存与加载等。
2.波士顿房价的数据分析及可视化
机器学习的项目中都需要大量的数据,这些数据来源于现实生活、scikit-learn库或 Keras 库等,然后对数据进行探索是训练模型的必修课。因此,本次实验打 算从波士顿房价数据集入手,开始学习这部分内容波士顿房价数据集统计的是 20 世纪 70 年代中期波士顿郊区的房屋数据。该数据集一共有 506 条数据,每条数据包含 13 个特征值和 1 个标签值。特征值包括城镇人均犯罪率、住宅用地所占比例、每栋住宅的平均房间数、到达高速公路的便利指数、城镇非零售业的商业用地所占比例等。标签值是房价的平均值。数据集中各列说明如表 1 所示。

2.1波士顿房价的数据分析
2.1.1 步骤一:导入所需的模块和包
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf解释:
matplotlib.pyplot:用于绘制数据图表,如散点图、柱状图等。numpy:用于处理数值计算和数组操作。tensorflow:用于加载数据集,并构建和训练机器学习模型。
2.1.2 步骤二:从 Keras 库中加载波士顿房价数据集
(x_train, y_train), (_, _) = tf.keras.datasets.boston_housing.load_data(test_split=0)解释:
tf.keras.datasets.boston_housing.load_data():加载波士顿房价数据集。test_split=0:表示不保留测试集,所有数据都作为训练集使用。(x_train, y_train):接收训练集的数据,包括特征(x_train)和目标值(y_train)。(_, _):忽略返回的测试集数据,因为我们在此实验中不需要测试集。
2.1.3 步骤三:加载本地 CSV 数据集
import pandas as pd
from sklearn.model_selection import train_test_split
file_path = r'E:/AI/Jupyter/实验任务/实验任务二/data/boston_housing.csv'
boston_data = pd.read_csv(file_path)
print(boston_data.columns)
print(boston_data.head())
解释:
pandas(pd):用于数据处理,特别是读取 CSV 文件和操作结构化数据。train_test_split:用于将数据集划分为训练集和测试集。pd.read_csv(file_path):从指定路径加载 CSV 文件为DataFrame格式(boston_data)。boston_data.columns:输出数据集的列名。boston_data.head():显示数据集的前五行,帮助我们快速查看数据结构和内容。
2.1.4 步骤四:划分特征和目标变量
X = boston_data.drop('MEDV', axis=1) # 特征 y = boston_data['MEDV'] # 目标变量解释:
X = boston_data.drop('MEDV', axis=1):从数据集中删除MEDV列(即房价),其余列作为特征变量X。y = boston_data['MEDV']:将MEDV列单独提取出来,作为目标变量y。MEDV通常表示房屋的中位价格。
2.1.5 步骤五:划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)解释:
train_test_split(X, y, test_size=0.2, random_state=42):将数据集划分为训练集和测试集。test_size=0.2:表示20%的数据将用于测试,其余80%用于训练。random_state=42:设置随机种子,保证每次划分结果一致。
- 返回值:
x_train:训练集的特征数据。x_test:测试集的特征数据。y_train:训练集的目标数据(房价)。y_test:测试集的目标数据(房价)。
2.1.6 步骤六:查看数据集的特征值和标签值的类型
print("特征值的类型:", type(x_train))
print("标签值的类型:", type(y_train))解释:
type(x_train)和type(y_train):分别输出特征值和标签值的类型,通常为pandas.DataFrame和pandas.Series。
2.1.7 步骤七:查看数据集的特征值和标签值的属性
print("特征值的维度:", x_train.ndim)
print("标签值的维度:", y_train.ndim)
print("特征值的形状:", x_train.shape)
print("标签值的形状:", y_train.shape)
print("特征值的元素类型:", x_train.dtypes)
print("标签值的元素类型:", y_train.dtype)
解释:
x_train.ndim和y_train.ndim:分别显示特征值和标签值的维度。x_train.shape和y_train.shape:显示特征值和标签值的形状,帮助我们了解数据的结构。x_train.dtypes和y_train.dtype:查看特征和标签的数据类型,通常为float64。
2.1.8 步骤八:显示数据集的部分数据
print("特征值的最后6行数据:")
print(x_train.tail(6)) # 使用 tail() 显示最后几行数据
print("标签值的最后6行数据:")
print(y_train.tail(6))
解释:
x_train.tail(6)和y_train.tail(6):分别显示训练集特征值和标签值的最后6行数据,帮助我们了解数据集的末尾数据。
2.2 数据可视化
2.2.1步骤一:设置图形属性
plt.rcParams['font.sans-serif'] = ['SimHei']解释:
plt.rcParams['font.sans-serif'] = ['SimHei']:设置 Matplotlib 图表中的字体为“黑体”,以便显示中文标签。
2.2.2步骤二:绘制特征与房价的散点图
titles = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT", "MEDV"]
# 创建画布并设置画布的大小
plt.figure(figsize=(16, 16))
# 绘制子图
for i in range(13):
plt.subplot(4, 4, (i+1))
plt.scatter(x_train.iloc[:, i], y_train)
plt.xlabel(titles[i])
plt.ylabel("Price ($1000's)")
plt.title(str(i+1) + ". " + titles[i] + "-Price")
# 自动调整子图参数,使之填充整个图像区域
plt.tight_layout()
plt.show()
解释:
titles:存储每个特征的名称,用于设置子图的标题。plt.figure(figsize=(16, 16)):创建一个16x16的画布。for i in range(13):循环遍历13个特征,并为每个特征绘制一个散点图。plt.subplot(4, 4, (i+1)):将画布划分为4x4的网格,并选择当前的子图位置。plt.scatter(x_train.iloc[:, i], y_train):绘制散点图,x轴为特征值,y轴为房价。plt.xlabel(titles[i])和plt.ylabel("Price ($1000's)"):分别设置x轴和y轴的标签。plt.title(str(i+1) + ". " + titles[i] + "-Price"):设置每个子图的标题。
plt.tight_layout():自动调整子图参数,使之填充整个图像区域。plt.show():显示绘制的图表。
2.3 总体代码与结果
2.3.1代码
# 参考代码
# 导入所需要的模块与包
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# 导入波士顿房价数据集
(x_train, y_train), (_, _) = tf.keras.datasets.boston_housing.load_data(test_split=0)
# 继续导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
# 替换为你的文件路径
file_path = r'E:/AI/Jupyter/实验任务/实验任务二/data/boston_housing.csv'
boston_data = pd.read_csv(file_path)
# 查看数据集的列名和前几行数据
print(boston_data.columns)
print(boston_data.head())
# 假设目标变量是房价,特征变量是其他列
X = boston_data.drop('MEDV', axis=1) # 特征
y = boston_data['MEDV'] # 目标变量
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 查看数据集特征值和标签值的类型
print("特征值的类型:", type(x_train))
print("标签值的类型:", type(y_train))
# 查看数据集特征值和标签值的属性
print("特征值的维度:", x_train.ndim)
print("标签值的维度:", y_train.ndim)
print("特征值的形状:", x_train.shape)
print("标签值的形状:", y_train.shape)
print("特征值的元素类型:", x_train.dtypes) # 使用 dtypes 来查看每一列的数据类型
print("标签值的元素类型:", y_train.dtype)
# 显示数据集的部分数据
print("特征值的最后6行数据:")
print(x_train.tail(6)) # 使用 tail() 显示最后几行数据
print("标签值的最后6行数据:")
print(y_train.tail(6))
# 参考代码
# 设置图形中的中文字体为“黑体”
plt.rcParams['font.sans-serif'] = ['SimHei']
titles = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT", "MEDV"]
# 创建画布并设置画布的大小
plt.figure(figsize=(16, 16))
# 绘制子图
for i in range(13):
plt.subplot(4, 4, (i+1))
plt.scatter(x_train.iloc[:, i], y_train)
plt.xlabel(titles[i])
plt.ylabel("Price ($1000's)")
plt.title(str(i+1) + ". " + titles[i] + "-Price")
# 自动调整子图参数,使之填充整个图像区域
plt.tight_layout()
plt.show()
2.3.2结果
Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'MEDV'],
dtype='object')
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO \
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7
4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7
B LSTAT MEDV
0 396.90 4.98 24.0
1 396.90 9.14 21.6
2 392.83 4.03 34.7
3 394.63 2.94 33.4
4 396.90 5.33 36.2
特征值的类型: <class 'pandas.core.frame.DataFrame'>
标签值的类型: <class 'pandas.core.series.Series'>
特征值的维度: 2
标签值的维度: 1
特征值的形状: (404, 13)
标签值的形状: (404,)
特征值的元素类型: CRIM float64
ZN float64
INDUS float64
CHAS int64
NOX float64
RM float64
AGE float64
DIS float64
RAD int64
TAX int64
PTRATIO float64
B float64
LSTAT float64
dtype: object
标签值的元素类型: float64
特征值的最后6行数据:
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
71 0.15876 0.0 10.81 0 0.413 5.961 17.5 5.2873 4 305
106 0.17120 0.0 8.56 0 0.520 5.836 91.9 2.2110 5 384
270 0.29916 20.0 6.96 0 0.464 5.856 42.1 4.4290 3 223
348 0.01501 80.0 2.01 0 0.435 6.635 29.7 8.3440 4 280
435 11.16040 0.0 18.10 0 0.740 6.629 94.6 2.1247 24 666
102 0.22876 0.0 8.56 0 0.520 6.405 85.4 2.7147 5 384
PTRATIO B LSTAT
71 19.2 376.94 9.88
106 20.9 395.67 18.66
270 18.6 388.65 13.00
348 17.0 390.94 5.99
435 20.2 109.85 23.27
102 20.9 70.80 10.63
标签值的最后6行数据:
71 21.7
106 19.5
270 21.1
348 24.5
435 13.4
102 18.6
Name: MEDV, dtype: float64

3.鸢尾花数据分析及可视化
3.1鸢尾花数据分析及可视化
3.1.1 步骤一:使用 load_iris() 函数导入 scikit-learn 库中的鸢尾花数据集
from sklearn.datasets import load_iris
# 使用 load_iris() 函数导入鸢尾花数据集
iris = load_iris()
解释:
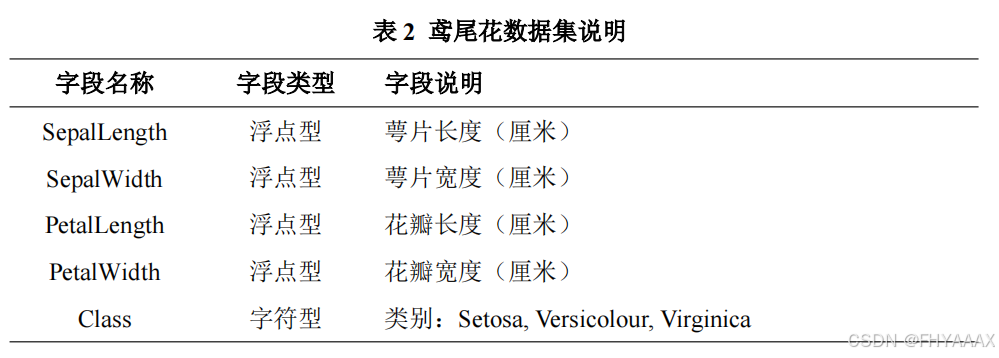
load_iris():scikit-learn提供的函数,用于加载鸢尾花数据集。该数据集包含 150 个样本,每个样本有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),以及对应的标签(鸢尾花的品种:Setosa、Versicolor、Virginica)。
3.1.2 步骤二:获取特征值和标签值
features = iris.data # 特征值
labels = iris.target # 标签值解释:
iris.data:存储鸢尾花数据集的特征值,形状为(150, 4),每个样本有 4 个特征。iris.target:存储鸢尾花数据集的标签值,形状为(150,),表示 150 个样本的类别标签。
3.1.3. 步骤三:访问数据集数据
查看数据集的特征值和标签值的类型
print("特征值的类型:", type(features))
print("标签值的类型:", type(labels))解释:
type(features)和type(labels):输出特征值和标签值的类型,通常为numpy.ndarray。
查看数据集的特征值和标签值的属性
print("特征值的维度:", features.ndim)
print("标签值的维度:", labels.ndim)
print("特征值的形状:", features.shape)
print("标签值的形状:", labels.shape)
print("特征值的元素类型:", features.dtype)
print("标签值的元素类型:", labels.dtype)
解释:
features.ndim和labels.ndim:查看特征值和标签值的维度。特征值通常为二维(2D),标签值为一维(1D)。features.shape和labels.shape:显示特征值和标签值的形状,帮助了解数据集的大小和结构。features.dtype和labels.dtype:查看数据元素的类型,通常特征值为浮点数 (float64),标签值为整数 (int64)。
3.1.4 步骤四:显示数据集的前10条特征值和标签值数据
print("前10条特征值数据:")
print(features[:10])
print("前10条标签值数据:")
print(labels[:10])
解释:
features[:10]和labels[:10]:分别显示数据集中前 10 个样本的特征值和对应的标签值,帮助快速了解数据的内容。
3.1.5 步骤五:绘制花瓣长度和花瓣宽度与鸢尾花品种的散点图
import matplotlib.pyplot as plt
# 创建绘图窗口
plt.figure(figsize=(8, 6))
# 设置颜色映射,分别表示Setosa, Versicolor, Virginica
colors = ['blue', 'red', 'green']
for i in range(3):
plt.scatter(features[labels == i, 2], features[labels == i, 3],
c=colors[i], label=iris.target_names[i])
# 设置图形的标题和标签
plt.title('鸢尾花数据集\n(蓝色->Setosa | 红色->Versicolor | 绿色->Virginica)', fontsize=14)
plt.xlabel('花瓣长度 (cm)', fontsize=12)
plt.ylabel('花瓣宽度 (cm)', fontsize=12)
# 添加图例
plt.legend()
# 显示图形
plt.show()
解释:
plt.figure(figsize=(8, 6)):创建一个 8x6 英寸的图形窗口。colors = ['blue', 'red', 'green']:定义颜色列表,分别代表 Setosa(蓝色)、Versicolor(红色)、Virginica(绿色)三种鸢尾花品种。for i in range(3):循环遍历三种鸢尾花品种,并绘制对应的散点图。features[labels == i, 2]和features[labels == i, 3]:分别提取第 i 种鸢尾花品种的花瓣长度和宽度。c=colors[i]:为不同品种的鸢尾花设置不同的颜色。label=iris.target_names[i]:为不同的品种添加标签。
plt.xlabel()和plt.ylabel():分别设置 x 轴和 y 轴的标签为花瓣长度和花瓣宽度。plt.title():设置图形的标题,并注明颜色与品种的对应关系。plt.legend():添加图例,显示每种颜色代表的鸢尾花品种。plt.show():显示绘制的散点图。
3.2总体代码和效果
3.2.1代码
# 导入所需的库
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
# 步骤一:使用 load_iris() 函数导入 scikit-learn 库中的鸢尾花数据集
iris = load_iris()
features = iris.data # 特征值
labels = iris.target # 标签值
# 步骤二:查看数据集的特征值和标签值的类型
print("特征值的类型:", type(features))
print("标签值的类型:", type(labels))
# 步骤三:查看数据集的特征值和标签值的属性
print("特征值的维度:", features.ndim)
print("标签值的维度:", labels.ndim)
print("特征值的形状:", features.shape)
print("标签值的形状:", labels.shape)
print("特征值的元素类型:", features.dtype)
print("标签值的元素类型:", labels.dtype)
# 步骤四:显示数据集的前10条特征值和标签值数据
print("前10条特征值数据:")
print(features[:10])
print("前10条标签值数据:")
print(labels[:10])
# 步骤五:绘制花瓣长度和花瓣宽度与鸢尾花品种的散点图
plt.figure(figsize=(8, 6))
# 设置颜色映射,分别表示Setosa, Versicolor, Virginica
colors = ['blue', 'red', 'green']
for i in range(3):
plt.scatter(features[labels == i, 2], features[labels == i, 3],
c=colors[i], label=iris.target_names[i])
# 设置图形的标题和标签
plt.title('鸢尾花数据集\n(蓝色->Setosa | 红色->Versicolor | 绿色->Virginica)', fontsize=14)
plt.xlabel('花瓣长度 (cm)', fontsize=12)
plt.ylabel('花瓣宽度 (cm)', fontsize=12)
# 添加图例
plt.legend()
# 显示图形
plt.show()
3.2.2效果
特征值的类型: <class 'numpy.ndarray'> 标签值的类型: <class 'numpy.ndarray'> 特征值的维度: 2 标签值的维度: 1 特征值的形状: (150, 4) 标签值的形状: (150,) 特征值的元素类型: float64 标签值的元素类型: int32 前10条特征值数据: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1]] 前10条标签值数据: [0 0 0 0 0 0 0 0 0 0]


![[线程]阻塞队列](https://i-blog.csdnimg.cn/direct/0026d860e0c648f991b63ae3b868b427.png)