在商业分析中,"时间"是一个核心概念。我们基于时间组件来分析销售数据、收入、利润、增长,甚至进行预测。然而,对于初学者来说,这可能是一个复杂的主题。在处理时间敏感的数据集时,需要考虑时间序列数据的多个细微方面。

在这个领域,没有放之四海而皆准的方法。我们不必总是强制使用传统的时间序列技术,如ARIMA(从经验中得出这个结论)。在某些项目中,如需求预测或点击预测,可能需要依赖监督学习算法。这就是时间序列特征工程发挥作用的地方。它有潜力将时间序列模型从一个良好的模型提升为一个强大的预测工具。
在本文中,我们将探讨使用日期时间列提取有用信息的各种特征工程技术。
1、时间序列简介
在深入特征工程技术之前,让我们先回顾一些基本的时间序列概念。这些概念将贯穿全文,因此提前熟悉它们很有帮助。是什么使时间序列项目区别于传统机器学习问题呢?
在时间序列中,数据以等间隔捕获,且序列中的每个连续数据点都依赖于其先前的值。
让我们通过一个简单的例子来理解这一点。如果想预测某公司今天的股票价格,了解昨天的收盘价会有帮助,这是肯定的,如果我们有过去几个月或几年的数据,预测网站的流量会容易得多。
我们还需要考虑另一个因素 - 时间序列数据可能存在某些趋势或季节性。下面这张显示某航空公司多年来预订票数的图表:
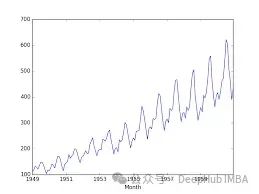
我们可以清晰地看到一个上升趋势。这类信息可以用于做出更准确的预测。
2、设置时间序列数据的问题
我们将处理一个有趣的问题来学习时间序列的特征工程技术。
我们有’JetRail’的历史数据,这是一种使用先进技术高速运行的公共铁路交通系统。JetRail的使用量最近有所增加,我们需要根据过去的数据预测未来7个月JetRail的客流量。
加载数据集:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data.dtypes
这里有两列 - 这是一个典型的单变量时间序列。日期变量的数据类型被识别为对象,即它被当作分类变量处理。我们需要将其转换为DateTime变量。可以使用pandas中的datetime函数来实现这一点:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data.dtypes
现在已经准备好了数据,让我们探讨可以从这个变量中提取的不同特征。在介绍每种特征工程技术时,将讨论该技术可能有用的不同场景。
注意:本文中使用了一个简单的时间序列问题来演示不同的特征工程技术。只要存在日期时间列,就可以在自选的数据集上应用这些技术。
3、日期相关特征
如果你熟悉预测特定产品销售的任务。我们就可以根据历史数据分析工作日和周末的销售模式,获取关于日、月、年等的信息可能对预测值有重要意义。
我们的任务是预测未来7个月内每小时使用JetRail的人数。 这个数字在工作日可能会较高,而在周末或节假日期间可能会较低。因此一周中的具体日期(工作日或周末)或月份将是重要的因素。
在Python中提取这些特征相对简单:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['year']=data['Datetime'].dt.year
data['month']=data['Datetime'].dt.month
data['day']=data['Datetime'].dt.day
data['dayofweek_num']=data['Datetime'].dt.dayofweek
data['dayofweek_name']=data['Datetime'].dt.weekday_name
data.head()
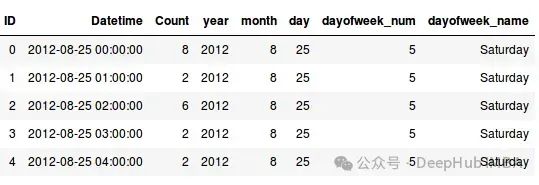
4、 时间相关特征
如果有时间戳,就可以提取更细粒度的特征。例如可以确定记录数据的一天中的具体小时或分钟,并比较营业时间和非营业时间的趋势。
如果能够从时间戳中提取’小时’特征,就可以对数据进行更深入的分析。JetRail的客流量是在早晨、下午还是晚上更高,或者可以使用该值来计算整周的平均每小时客流量,即上午9-10点、10-11点等时间段(贯穿整周)使用JetRail的人数。
提取基于时间的特征与提取日期相关特征的方法类似。可以首先将列转换为DateTime格式,然后使用.dt访问器。以下是在Python中的实现方法:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['Hour'] =data['Datetime'].dt.hour
data['minute'] =data['Datetime'].dt.minute
data.head()
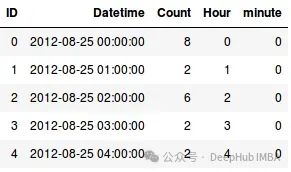
同样可以从日期列中提取多种特征。以下是可以生成的特征的完整列表:

5、滞后特征
在处理时间序列问题时,有一个关键点,可以利用目标变量进行特征工程!
考虑这样一个场景 —正在预测一家公司的股票价格。那么前一天的股票价格对做出预测很重要,对吧?换句话说,t时刻的值极大地受到t-1时刻值的影响。这些过去的值被称为滞后,所以t-1是滞后1,t-2是滞后2,依此类推。
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['lag_1'] =data['Count'].shift(1)
data=data[['Datetime', 'lag_1', 'Count']]
data.head()
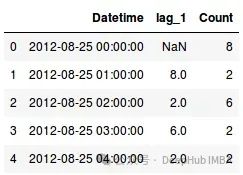
我们为序列生成了滞后一特征。但为什么选择滞后一?为什么不是五或七?这是一个值得思考的问题。
我们选择的滞后值应该基于个别值与其过去值的相关性。
如果序列呈现每周趋势,即上周一的值可以用来预测这周一的值,那么创建七天的滞后特征可能更合适。
还可以创建多个滞后特征!假设想要从滞后1到滞后7的特征则可以让模型决定哪个是最有价值的。例如训练一个线性回归模型,它会为滞后特征分配适当的权重(或系数):
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['lag_1'] =data['Count'].shift(1)
data['lag_2'] =data['Count'].shift(2)
data['lag_3'] =data['Count'].shift(3)
data['lag_4'] =data['Count'].shift(4)
data['lag_5'] =data['Count'].shift(5)
data['lag_6'] =data['Count'].shift(6)
data['lag_7'] =data['Count'].shift(7)
data=data[['Datetime', 'lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6', 'lag_7', 'Count']]
data.head(10)
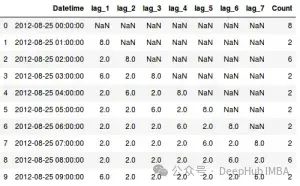
确定相关性显著的滞后有多种方法。例如可以使用ACF(自相关函数)和PACF(偏自相关函数)图。
- ACF: ACF图衡量时间序列与其滞后版本之间的相关性
- PACF: PACF图衡量时间序列与其滞后版本之间的相关性,但在消除了已由中间比较解释的变异之后
对于我们的例子,这里是ACF和PACF图:
fromstatsmodels.graphics.tsaplotsimportplot_acf, plot_pacf
plot_acf(data['Count'], lags=10)
plot_pacf(data['Count'], lags=10)

偏自相关函数显示与第一个滞后高度相关,与第二个和第三个滞后的相关性较低。自相关函数显示缓慢衰减,这表明未来值与其过去值有很强的相关性。
需要注意的是 — 移动的次数等于数据中减少的值的数量。这样在开始处看到一些包含NaN的行。这是因为第一个观察没有滞后值。在训练模型时,需要从训练数据中移除这些行。
6. 滚动窗口特征
在上一节中,我们讨论了如何使用前面的值作为特征。
那么,如何根据过去的值计算一些统计量呢?这种方法被称为滚动窗口法,因为每个数据点的窗口都是不同的。
下面这个动图很好地解释了这个概念:

由于这看起来像是一个随每个新数据点滑动的窗口,使用这种方法生成的特征被称为"滚动窗口"特征。
现在需要考虑的问题是 — 如何在这里进行特征工程?让我们从简单的开始。将选择一个窗口大小,计算窗口内值的平均值,并将其用作特征。下面是在Python中的实现:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['rolling_mean'] =data['Count'].rolling(window=7).mean()
data=data[['Datetime', 'rolling_mean', 'Count']]
data.head(10)
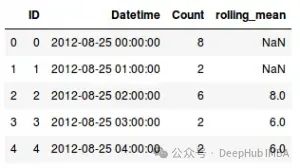
类似地,可以考虑计算选定窗口内的总和、最小值、最大值等作为特征。
在时间序列中,近期性是一个重要因素。越接近当前日期的值通常包含更多相关信息。
因此我们可以使用加权平均值,给予最近的观察值更高的权重。数学上,过去7个值在时间t的加权平均值可以表示为:
w_avg = w1*(t-1) + w2*(t-2) + . . . . + w7*(t-7)
其中,w1>w2>w3> . . . . >w7。
7、扩展窗口特征
这是滚动窗口技术的一个高级版本。在滚动窗口中,窗口的大小是固定的,而窗口随时间推移而滑动。因此只考虑最近的一组固定数量的值,忽略了更早的数据。
扩展窗口特征的核心思想是考虑所有过去的值。
下图展示了扩展窗口函数的工作原理:

每一步窗口的大小都会增加一个单位,因为它考虑了序列中的每个新值。这可以在Python中使用expanding()函数轻松实现。让我们使用相同的数据来编写代码:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['expanding_mean'] =data['Count'].expanding(2).mean()
data=data[['Datetime','Count', 'expanding_mean']]
data.head(10)

8、领域特定特征
这是特征工程的精髓所在。
对问题陈述有深入理解,对最终目标有清晰认识,以及对可用数据有充分了解,这些都是为模型设计有效的领域特定特征的关键。
让我们通过一个例子来深入探讨这一点。
以下是零售商提供的多个商店和产品的数据。我们的任务是预测产品的未来需求。可以考虑various characteristic,如lag特性或过去值的平均值等。
但是,让我们思考一个问题 — 在整个数据集中从滞后1到滞后7构建滞后特征是否真的合适?

显然不是。不同的商店和产品的需求模式可能有显著差异。在这种情况下,我们可以考虑基于商店-产品组合来创建滞后特征。 此外,如果我们了解产品特性和市场趋势,将能够生成更准确、更有针对性的特征。
不仅如此,对领域和数据的深入理解还将帮助我们更好地选择滞后值和窗口大小。基于领域知识,可能能够引入外部数据集,为模型增添更多价值。
例如,可以考虑以下问题:销售是否受当天天气的影响?销售是否会在国定假日期间出现显著变化?如果是,那么可以利用外部数据集,将节假日信息作为一个特征纳入模型。
时间序列的验证技术
我们讨论的所有特征工程技术都可以用来将时间序列问题转化为监督机器学习问题。完成这一步后,就可以应用线性回归和随机森林等机器学习算法。但在进入模型构建过程之前,还有一个关键步骤需要注意 — 为时间序列创建合适的验证集。
对于传统的机器学习问题,我们通常随机选择数据子集作为验证集和测试集。但在时间序列问题中,每个数据点都依赖于其过去的值。如果我们随机打乱数据,我们可能会在未来数据上训练模型,而用过去的数据进行预测,这显然是不合理的。
在处理时间序列问题时,关键是要仔细构建验证集,保持数据的时间顺序。
让我们为我们的问题创建一个验证集。首先需要检查拥有的数据跨度:
importpandasaspd
data=pd.read_csv('Train_SU63ISt.csv')
data['Datetime'] =pd.to_datetime(data['Datetime'],format='%d-%m-%Y %H:%M')
data['Datetime'].min(), data['Datetime'].max(), (data['Datetime'].max() -data['Datetime'].min())
(Timestamp('2012-08-25 00:00:00'), Timestamp('2014-09-25 23:00:00'), Timedelta('761 days 23:00:00'))
我们有大约25个月的数据。保留最后三个月的数据用于验证,使用剩余的数据进行训练:
data.index=data.Datetime
Train=data.loc['2012-08-25':'2014-06-24']
valid=data.loc['2014-06-25':'2014-09-25']
Train.shape, valid.shape
((16056, 3), (2232, 3))
很好!我们现在已经准备好了训练集和验证集。可以使用这些特征工程技术,并在这些数据上构建和评估机器学习模型了。
总结
时间序列分析常被视为一个具有挑战性的主题。这是可以理解的,因为在处理日期和时间组件时涉及许多复杂的因素。但一旦掌握了基本概念并能够熟练运用特征工程技术,将能够更加得心应手地处理时间序列项目。
在本文中,我们讨论了一些可以用来处理时间序列数据的实用技术。通过使用这些特征工程技术,可以将时间序列问题转化为监督学习问题,并构建有效的回归模型。
本文数据集:
https://avoid.overfit.cn/post/e6ef4e7e0c0e4af486d684dfd438cef2
作者:Vidhya












![[vue] jszip html-docx-js file-saver 图片,纯文本 ,打包压缩,下载跨域问题](https://i-blog.csdnimg.cn/direct/8827abcedae14f95a967630319ce090e.png)





