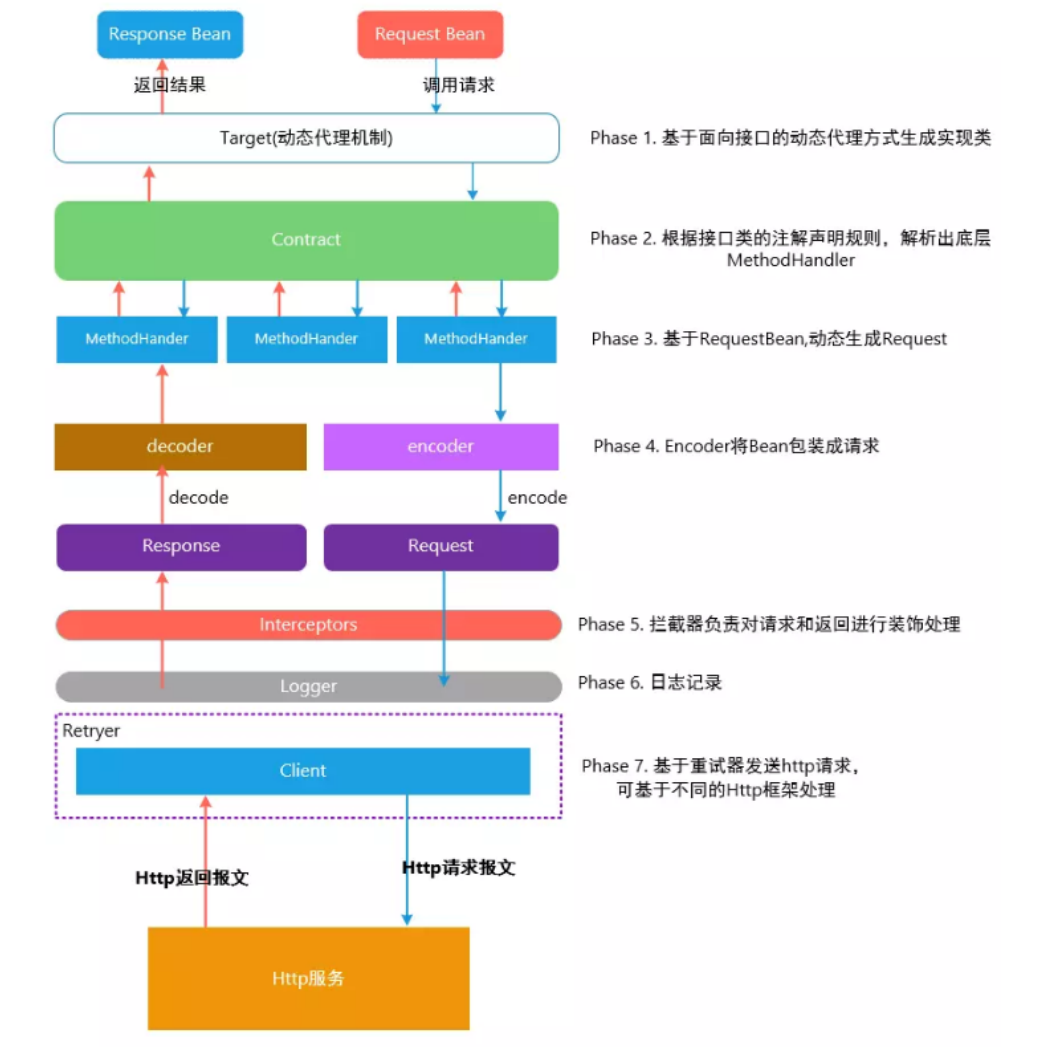
Your Diffusion Model is Secretly a Zero-Shot Classifier论文阅读笔记
这篇文章我感觉在智源大会上听到无数个大佬讨论,包括OpenAI Sora团队负责人,谢赛宁,好像还有杨植麟。虽然这个文章好像似乎被引量不是特别高,但是和AI甚至人类理解很本质的问题很相关,即是不是要通过生成来构建理解的问题,文章的做法也很巧妙,感觉是一些学者灵机一动的产物,好好学习一个!
摘要
这篇文章的摘要也是比较吸引人的,就好好理解一下好了。
第一句:现在的文生图模型能够生成很真实的图像了。(大家都认可)
第二句:但是呢,大家都用文本to图像模型来做生成,其实呢,文生图模型还可以生成概率分布,其应用不局限于图像的生成。(大家没听过的概念,很震惊)
第三句:这个文章展示了,通过利用大规模的文生图模型生成的概率密度估计可以实现zero-shot的分类,不需要经过任何的训练。
第四句:作者提出的Diffusion Classifier取得了很好的结果,比过了其他从diffusion model里提取知识的方法。
第五句:尽管在zero-shot 分类任务上,基于生成式模型的算法仍然与判别式的模型存在一些差距,但是本文的模型有着较强的多模态组合推理能力。
第六句:最后,本文又基于class conditional的模型提取了一个在imagenet上的Diffusion Classifier,实验证明了这个Diffusion Classifier通过弱的增强就可以得到较好的结果,并且有很好的鲁棒性。
第七句:因此呢,本文在下游任务应用上生成式over判别式的重要一步。
一、引言
第一段:一上来就是一句hiHton的名言:To Recognize Shapes, First Learn to Generate Images。Hinton强调生成式模型是实现判别式任务类似目标识别等重要的一个策略。尽管生成式模型应对的是一个更复杂的任务,即模拟数据的分布,但是他们可以对事物建立一个更完整的表示,这样就可以应用到各种下游任务上。所以生成式模型很火,但是大家更多是关注于生成特定的物体。因此呢,在本文重新回顾了判别式vs生成式这项已久的讨论。对比基于diffusion的模型与SOTA的判别式模型。
第二段:简单回顾了一下Diffusion的原理,主要强调了ELBO这个东西(后面可能会用到)
第三段:作者开始使用小学二年级知识:贝叶斯公式了!也是论文的一个核心!作者先说,条件生成模型其实很容易转换为一个分类器。给定一个输入 x \mathbf x x,和一个类别集合(也可以理解文生图模型的文)$\mathbf c ,我们可以用文生图模型很容易得到 ,我们可以用文生图模型很容易得到 ,我们可以用文生图模型很容易得到p(\mathbf x |\mathbf c) 。接着,通过选择一个合适的先验概率 。接着,通过选择一个合适的先验概率 。接着,通过选择一个合适的先验概率p(\mathbf c) ,并使用贝叶斯公式,就可以得到 ,并使用贝叶斯公式,就可以得到 ,并使用贝叶斯公式,就可以得到p(\mathbf c|\mathbf x ) 。而通过 E L B O 就可以拟合 。而通过ELBO就可以拟合 。而通过ELBO就可以拟合p(\mathbf x |\mathbf c)$。实践上呢,作者会通过不断的加噪声,来实现通过蒙特卡洛估计的方式来进行估计。作者就把这一系列操作称之为Diffusion Classifier。通过这个方法就可以实现zero-shot的分类,不需要经过任何的训练。后面作者还提供了一些关于选择合适的timestamp的方法去降低误差和加速训练。
第四段:就讲了讲实验,先重复了下摘要里的作者提出的Diffusion Classifier取得了很好的结果,比过了其他从diffusion model里提取知识的方法。又说到在一个很有挑战性的组合推理的benchmark上,比过了最强的模型。此外,又重复摘要,本文基于class conditional的模型提取了一个在imagenet上的Diffusion Classifier,实验证明了这个Diffusion Classifier通过弱的增强就可以得到较好的结果,并且有很好的鲁棒性。不过最后一句写得也挺有意思:是时候去在分类任务上回顾生成式模型了
二、方法
相关工作部分就跳过了。
2.1 diffusion model的一些前置条件
其实这里比较重要的一个公式是 log ( p ( x ∣ c ) ) ≥ − E t , ϵ [ ∥ ϵ − ϵ θ ( x t , c ) 2 ] + C \log \left ( p(\mathbf x | \mathbf c )\right )\geq -E_{t,\epsilon}[\|\epsilon-\epsilon_\theta(\mathbf x _t,\mathbf c)^2]+C log(p(x∣c))≥−Et,ϵ[∥ϵ−ϵθ(xt,c)2]+C,这个被称为ELBO,好像翻译为置信下界什么,反正就是一个下界。
2.2 基于diffusion model的分类
这里就开始使用贝叶斯公式了!得到
p
(
c
i
∣
x
)
=
p
(
c
i
)
p
(
x
∣
c
i
)
∑
j
p
(
c
j
)
p
(
x
∣
c
j
)
(
1
)
p( \mathbf c_i | \mathbf x ) = \frac {p(\mathbf c_i)p(\mathbf x | \mathbf c_i)} {\sum_jp(\mathbf c_j)p(\mathbf x | \mathbf c_j)}\ \ \ \ \ \ \ \ (1)
p(ci∣x)=∑jp(cj)p(x∣cj)p(ci)p(x∣ci) (1)
作者给了一个
p
(
c
i
)
=
1
/
N
p(\mathbf c_i)=1/N
p(ci)=1/N的假设,相当于上下就除掉了,并且用2.1说到的ELBO来替换
p
(
x
∣
c
)
p(\mathbf x | \mathbf c)
p(x∣c)得到
p
(
c
i
∣
x
)
=
exp
{
−
E
t
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
x
t
,
c
i
)
2
∥
}
]
}
∑
j
exp
{
−
E
t
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
x
t
,
c
j
)
2
∥
]
}
(
2
)
p( \mathbf c_i | \mathbf x ) = \frac {\exp \{-E_{t,\epsilon}[\|\epsilon-\epsilon_\theta(\mathbf x _t,\mathbf c_i)^2\|\}]\}} {\sum_j\exp \{-E_{t,\epsilon}[\|\epsilon-\epsilon_\theta(\mathbf x _t,\mathbf c_j)^2\|]\}} \ \ \ \ \ \ \ \ (2)
p(ci∣x)=∑jexp{−Et,ϵ[∥ϵ−ϵθ(xt,cj)2∥]}exp{−Et,ϵ[∥ϵ−ϵθ(xt,ci)2∥}]} (2)
通过采样不同的
t
t
t和
ϵ
\epsilon
ϵ,可以将期望转换为
1
N
∑
i
N
∥
ϵ
i
−
ϵ
θ
(
α
ˉ
t
i
x
+
1
−
α
ˉ
t
i
ϵ
i
,
c
j
)
∥
2
(
3
)
\frac 1 N \sum_i^N \|\epsilon_i-\epsilon_\theta(\sqrt{\bar{\alpha}_{t_i}} \mathbf x+\sqrt{1-\bar{\alpha}_{t_i}} \epsilon_i ,\mathbf c_j)\|^2 \ \ \ \ \ \ \ \ (3)
N1i∑N∥ϵi−ϵθ(αˉtix+1−αˉtiϵi,cj)∥2 (3)
把上面这个式子代入,就可以得到作者一直在说的Diffusion Classifier啦。
2.3 一种减少方差的方法
作者提到,蒙特卡洛采样就算采样很多轮可能也不收敛,所以先做一个变化把(2)式的上面除下去,可以得到:
p
(
c
i
∣
x
)
=
1
∑
j
exp
{
E
t
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
x
t
,
c
i
)
2
∥
−
E
t
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
x
t
,
c
j
)
2
∥
]
}
(
4
)
p( \mathbf c_i | \mathbf x ) = \frac {1} {\sum_j\exp \{E_{t,\epsilon}[\|\epsilon-\epsilon_\theta(\mathbf x _t,\mathbf c_i)^2\| -E_{t,\epsilon}[\|\epsilon-\epsilon_\theta(\mathbf x _t,\mathbf c_j)^2\|]\}} \ \ \ \ \ \ \ \ (4)
p(ci∣x)=∑jexp{Et,ϵ[∥ϵ−ϵθ(xt,ci)2∥−Et,ϵ[∥ϵ−ϵθ(xt,cj)2∥]}1 (4)
作者说,这样的话只需要关心期望的差了,而且更重要的是,这样在估计不同的
c
i
\mathbf c_i
ci的时候,可以用同样的一组
S
=
{
t
i
,
ϵ
i
}
S=\{t_i,\epsilon_i\}
S={ti,ϵi}。作者说这样类似于配对检验,好像可以减少误差或者什么的(文中的表述是increase statistical power)
而且作者这里还做了一个实验证明,不同时间步的$\epsilon $ loss区别很大,但是两个期望的差却很稳定,因此用这种方式更好。
三、实践上的一些考量
这里提到了一些可以加速甚至优化结果的trick,其实说trick倒还是感觉这些都是对于深度学习和算法很了解的人才能提出来的东西。
3.1 sample时的timestemp的重要性
作者先做了个实验,就是如果sample的时候固定timestemp,那么哪个timestemp误差最低,显然t=500时最低(因为T=1000,即加噪声有1000轮)
接着作者做了另外一个有意思的实验,就是下面这个表。首先作者是选定一个t的集合,每个集合重复实验K次。显然如果t=1~1000全部构成的集合肯定是答案最好的(即图里的uniform),然后发现只用t=0和t=1000非常差,t=500就很好了。然后有一个even的,是假设集合大小为N,选取t=500-N/2到500+N/2里所有的,发现N=10的时候就差不多可以有N=1000也就是uniform的结果了,还是很不错的。

3.2 高效的分类
这个也很trival啦。其实相当于最初如果说要进行N次采样,那么对于C个类别,总共就要采样CxN轮。很多时候其实只关心最有可能的类别是哪一个,这样的话在采样前几轮的时候,可以发现某些类别根本不可能成为可能性最大的类别,就剔除就好了,就可以节约开支。比如说N=250 C=10的时候,前25轮都是10个类别一起算,然后在算完第25轮就可以剔除概率最低的5个,剩下225轮只需要计算剩下的5个的概率即可。
四、实验
实验做得倒是挺精彩,可以简单提一提。
回答第一个问题:How does Diffusion Classifier compare against zero-shot state-of-the-art classifiers such as CLIP?
这个问题问的是比clip之类的zero-shot模型更好吗
答案:是的,甚至比利用stable diffusion得到的特征再训练还好。
回答第二个问题:How well does our method do on compositional reasoning tasks?
这个问题问的是组合推理上好不好
这里作者使用了一个比较challenging的benchmark叫Winoground,如下图,它的特点是上下看的,就是词都一样,但是词的顺序不一样,导致图片也不一样。还挺有意思的。在这个任务上本文提出的模型依然是最好的。

回答第三个问题:How well does our method compare to discriminative models trained on the same dataset?
这个问题问的是不是比一些直接在分类任务上监督的模型好
这个还是有点意思的,居然比大多数方法还好,但是没比过比较大的基于vit的。但是似乎在有分布外的情况下表现得更为良好(即使都在imagenet数据上进行训练)