引言
在SVM中,通过引入拉格朗日乘子,可以将原始问题转化为对偶问题,这种转换具有几个重要的优点,包括简化计算和提供更直观的优化问题的解释
文章目录
- 引言
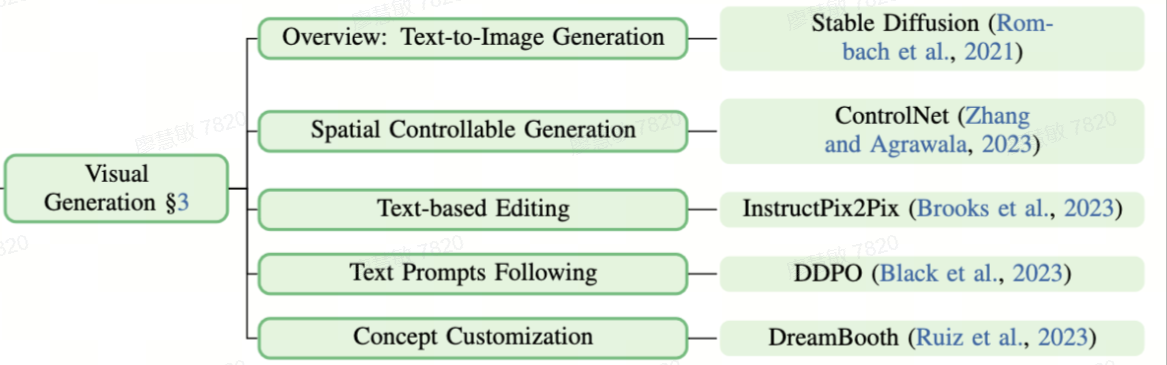
- 一、支持向量机(SVM)的对偶性
- 1.1 原始问题(Primal Problem)
- 1.2 对偶问题(Dual Problem)
- 1.3 对偶性的优点
- 1.4 总结
- 二、核方法
- 2.1 基本概念
- 2.1.1核函数
- 2.1.2 隐式映射
- 2.2 应用
- 2.2.1 支持向量机(SVM)
- 2.2.2 核岭回归(Kernel Ridge Regression)
- 2.2.3 核主成分分析(Kernel PCA)
- 2.3 优点
- 2.4 局限性
- 2.5 总结
- 三、核技巧
- 3.1 理解问题
- 3.2 映射到高维空间
- 3.3 核函数
- 3.4 应用核技巧
- 3.5 决策函数
- 3.6 总结

一、支持向量机(SVM)的对偶性
支持向量机(SVM)的对偶性是指原始优化问题与对偶优化问题之间的等价性
1.1 原始问题(Primal Problem)
SVM的原始问题是寻找一个超平面,使得不同类别的样本被正确地分开,并且间隔最大。这可以表示为一个凸二次规划问题:
min
w
,
b
1
2
∥
w
∥
2
\min_{\mathbf{w}, b} \frac{1}{2} \|\mathbf{w}\|^2
w,bmin21∥w∥2
subject to:
y
i
(
w
⋅
x
i
+
b
)
≥
1
,
∀
i
\text{subject to: } y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1, \quad \forall i
subject to: yi(w⋅xi+b)≥1,∀i
其中,
w
\mathbf{w}
w 是超平面的法向量,
b
b
b是偏置项,
x
i
\mathbf{x}_i
xi是第
i
i
i个样本的特征向量,
y
i
y_i
yi是对应的标签(取值为 +1 或 -1)
1.2 对偶问题(Dual Problem)
通过引入拉格朗日乘子
α
i
≥
0
\alpha_i \geq 0
αi≥0,我们可以为每个约束构建拉格朗日函数
L
(
w
,
b
,
α
)
L(\mathbf{w}, b, \mathbf{\alpha})
L(w,b,α):
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
α
i
[
y
i
(
w
⋅
x
i
+
b
)
−
1
]
L(\mathbf{w}, b, \mathbf{\alpha}) = \frac{1}{2} \|\mathbf{w}\|^2 - \sum_i \alpha_i [y_i (\mathbf{w} \cdot \mathbf{x}_i + b) - 1]
L(w,b,α)=21∥w∥2−i∑αi[yi(w⋅xi+b)−1]
接下来,通过求解拉格朗日对偶问题,我们可以得到原始问题的等价形式:
max
α
∑
i
α
i
−
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
x
i
⋅
x
j
\max_{\mathbf{\alpha}} \sum_i \alpha_i - \frac{1}{2} \sum_i \sum_j \alpha_i \alpha_j y_i y_j \mathbf{x}_i \cdot \mathbf{x}_j
αmaxi∑αi−21i∑j∑αiαjyiyjxi⋅xj
subject to:
∑
i
α
i
y
i
=
0
,
α
i
≥
0
,
∀
i
\text{subject to: } \sum_i \alpha_i y_i = 0, \quad \alpha_i \geq 0, \quad \forall i
subject to: i∑αiyi=0,αi≥0,∀i
1.3 对偶性的优点
- 简化计算:在对偶问题中,我们只需要优化关于 α \alpha α 的二次规划问题,而不是关于 w \mathbf{w} w和 b b b的原始问题
- 稀疏性:在最优解中,大多数 α i \alpha_i αi将为零,这意味着只有少数样本(支持向量)对决策函数有贡献
- 核技巧:通过对偶问题,可以方便地引入核函数,允许SVM在非线性特征空间中寻找最优超平面,而不需要显式地计算这些特征
- 解释性:对偶问题中的拉格朗日乘子 α i \alpha_i αi可以被解释为每个样本的重要性或权重
1.4 总结
总的来说,SVM的对偶性是机器学习中一个重要的理论结果,它不仅简化了SVM的训练过程,还为我们提供了对模型更深入的理解。通过利用对偶性,SVM在处理高维数据和复杂问题时表现出了强大的能力和灵活性
二、核方法
核方法(Kernel Methods)是一类在机器学习中使用的技术,它们利用核函数来隐式地在高维特征空间中执行计算,而无需直接在高维空间中进行操作。核方法广泛应用于支持向量机(SVM)、核岭回归(Kernel Ridge Regression)、核主成分分析(Kernel PCA)等多种学习算法中
2.1 基本概念
2.1.1核函数
核函数是核方法的核心,它能够计算两个输入样本在隐式映射到高维空间后的内积。常见的核函数包括:
- 线性核: K ( x i , x j ) = x i T x j K(\mathbf{x}_i, \mathbf{x}_j) = \mathbf{x}_i^T \mathbf{x}_j K(xi,xj)=xiTxj
- 多项式核: K ( x i , x j ) = ( γ x i T x j + r ) d K(\mathbf{x}_i, \mathbf{x}_j) = (\gamma \mathbf{x}_i^T \mathbf{x}_j + r)^d K(xi,xj)=(γxiTxj+r)d
- 径向基函数(RBF)核: K ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) K(\mathbf{x}_i, \mathbf{x}_j) = \exp(-\gamma \|\mathbf{x}_i - \mathbf{x}_j\|^2) K(xi,xj)=exp(−γ∥xi−xj∥2)
- Sigmoid核:
K
(
x
i
,
x
j
)
=
tanh
(
γ
x
i
T
x
j
+
r
)
K(\mathbf{x}_i, \mathbf{x}_j) = \tanh(\gamma \mathbf{x}_i^T \mathbf{x}_j + r)
K(xi,xj)=tanh(γxiTxj+r)
其中, γ \gamma γ、 r r r和 d d d是核函数的参数
2.1.2 隐式映射
隐式映射指的是将原始特征空间中的数据点映射到一个高维特征空间的过程,这个过程通常是非线性的。在核方法中,我们不需要显式地知道这个映射函数,只需要知道如何计算核函数
2.2 应用
2.2.1 支持向量机(SVM)
在SVM中,核方法用于处理非线性分类问题。通过将数据映射到高维空间,并在该空间中寻找一个最优的超平面来分隔数据
2.2.2 核岭回归(Kernel Ridge Regression)
核岭回归是一种使用核方法的回归算法,它通过引入核函数来处理非线性回归问题
2.2.3 核主成分分析(Kernel PCA)
核PCA是一种使用核方法的降维技术,它可以将数据映射到高维空间,并在该空间中执行主成分分析,以捕获数据的非线性结构
2.3 优点
- 处理非线性问题:核方法能够处理在原始特征空间中非线性可分的数据
- 避免维度灾难:由于不需要显式地计算高维空间中的特征向量,核方法可以避免维度灾难问题
2.4 局限性
- 计算复杂度:核矩阵的计算和存储可能会非常昂贵,特别是对于大规模数据集
- 参数选择:选择合适的核函数和参数需要经验和实验
2.5 总结
核方法是机器学习中非常强大和灵活的工具,它们在处理复杂数据关系时显示出其独特的优势。通过巧妙地利用核函数,核方法能够将线性学习算法扩展到非线性领域,从而在多种不同的应用中发挥重要作用
三、核技巧
核技巧(Kernel Trick)是支持向量机(SVM)中的一个关键概念,它允许SVM在非线性特征空间中有效地进行学习,而无需显式地计算这些特征
3.1 理解问题
在许多实际问题中,数据不是线性可分的,这意味着无法通过一个简单的线性超平面来分隔不同类别的数据点。在这种情况下,我们需要将数据映射到一个更高维的空间,在这个空间中,数据可能是线性可分的
3.2 映射到高维空间
核技巧的核心思想是将原始特征向量 x \mathbf{x} x通过一个非线性映射函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)映射到一个高维特征空间 H \mathcal{H} H。在这个高维空间中,我们希望找到一个线性超平面,能够分隔不同类别的数据
3.3 核函数
直接计算映射后的特征向量
ϕ
(
x
)
\phi(\mathbf{x})
ϕ(x)并在高维空间中求解线性SVM是一个计算上昂贵的过程。核技巧通过使用核函数
K
(
x
i
,
x
j
)
K(\mathbf{x}_i, \mathbf{x}_j)
K(xi,xj)来避免这一步骤,核函数能够隐式地计算两个映射后特征向量的内积:
K
(
x
i
,
x
j
)
=
ϕ
(
x
i
)
⋅
ϕ
(
x
j
)
K(\mathbf{x}_i, \mathbf{x}_j) = \phi(\mathbf{x}_i) \cdot \phi(\mathbf{x}_j)
K(xi,xj)=ϕ(xi)⋅ϕ(xj)
这意味着我们不需要知道具体的映射函数
ϕ
(
⋅
)
\phi(\cdot)
ϕ(⋅),只需要知道如何计算两个映射后特征向量的内积
3.4 应用核技巧
在SVM训练过程中,核技巧的应用步骤如下:
- 选择一个合适的核函数
- 使用核函数计算训练集中所有样本对的内积,构建核矩阵 K K K
- 将核矩阵 K K K代入到对偶问题的优化公式中
- 解对偶问题,找到最优的拉格朗日乘子 α \alpha α
- 使用支持向量来构建决策函数
3.5 决策函数
最终,SVM的决策函数可以表示为:
f
(
x
)
=
∑
i
∈
SV
α
i
y
i
K
(
x
i
,
x
)
+
b
f(\mathbf{x}) = \sum_{i \in \text{SV}} \alpha_i y_i K(\mathbf{x}_i, \mathbf{x}) + b
f(x)=i∈SV∑αiyiK(xi,x)+b
其中,SV 表示支持向量的集合
3.6 总结
通过核技巧,SVM能够高效地处理非线性问题,而不需要显式地计算高维空间中的特征向量。这使得SVM成为一个强大的机器学习工具,适用于多种复杂的数据集