零、文章目录
Python进阶06-Web服务器
1、HTTP协议
- HTTP协议相关请参考HTTP协议详解
- 网络相关内容请参考计算机网络详解
(1)HTTP协议
- HTTP 协议的全称是(HyperText Transfer Protocol),翻译过来就是超文本传输协议。
- 超文本是超级文本的缩写,是指超越文本限制或者超链接,比如:图片、音乐、视频、超链接等等都属于超文本。
- HTTP 协议的制作者是蒂姆·伯纳斯-李,1991年设计出来的,HTTP 协议设计之前目的是传输网页数据的,现在允许传输任意类型的数据。
- 传输 HTTP 协议格式的数据是基于 TCP 传输协议的,发送数据之前需要先建立连接。
(2)HTTP协议的作用
- HTTP规定了浏览器和 Web 服务器通信数据的格式,也就是说浏览器和web服务器通信需要使用http协议。
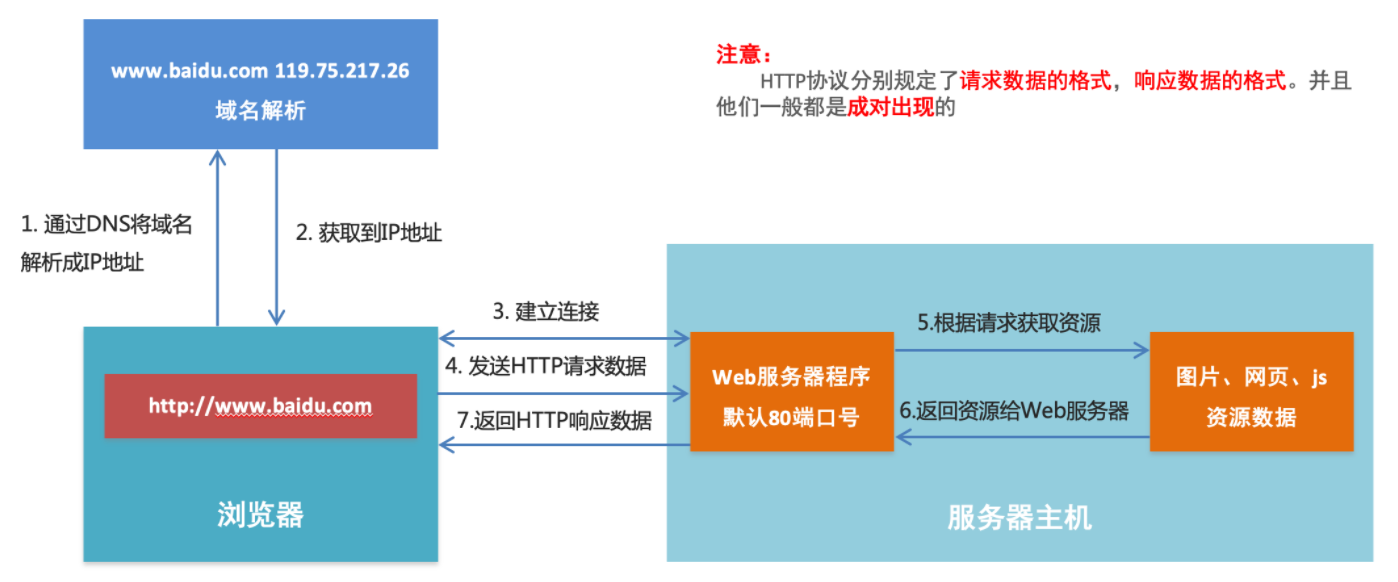
(3)浏览器访问Web服务器的过程
2、URL
(1)URL概念
- URL的英文全拼是(Uniform Resoure Locator),表达的意思是统一资源定位符。
- 通俗理解就是网络资源地址,也就是我们常说的网址。
(2)URL组成
- URL的样子:https://news.163.com/18/1122/10/E178J2O4000189FH.html
- URL的组成部分:
- ① 协议部分: https://、http://、ftp://
- ② 域名部分: news.163.com => 转换为IP地址(有了IP地址就能找到这个计算机了)
- ③ 资源路径部分: /18/1122/10/E178J2O4000189FH.html
(3)域名与URL扩展
- 域名:域名就是IP地址的别名,它是用点进行分割使用英文字母和数字组成的名字,使用域名目的就是方便的记住某台主机IP地址。
- URL的扩展:https://news.163.com/hello.html?page=1&count=10
- 查询参数部分: ?page=1&count=10
- 参数说明:? 后面的 page 表示第一个参数,后面的参数都使用 & 进行连接
3、查看HTTP协议的通信过程
(1)谷歌浏览器开发者工具的使用
- 首先需要安装Google Chrome浏览器
- Windows和Linux平台按F12调出开发者工具
- mac OS选择 视图 -> 开发者 -> 开发者工具或者直接使用 alt+command+i
- 多平台通用:网页右击选择检查。
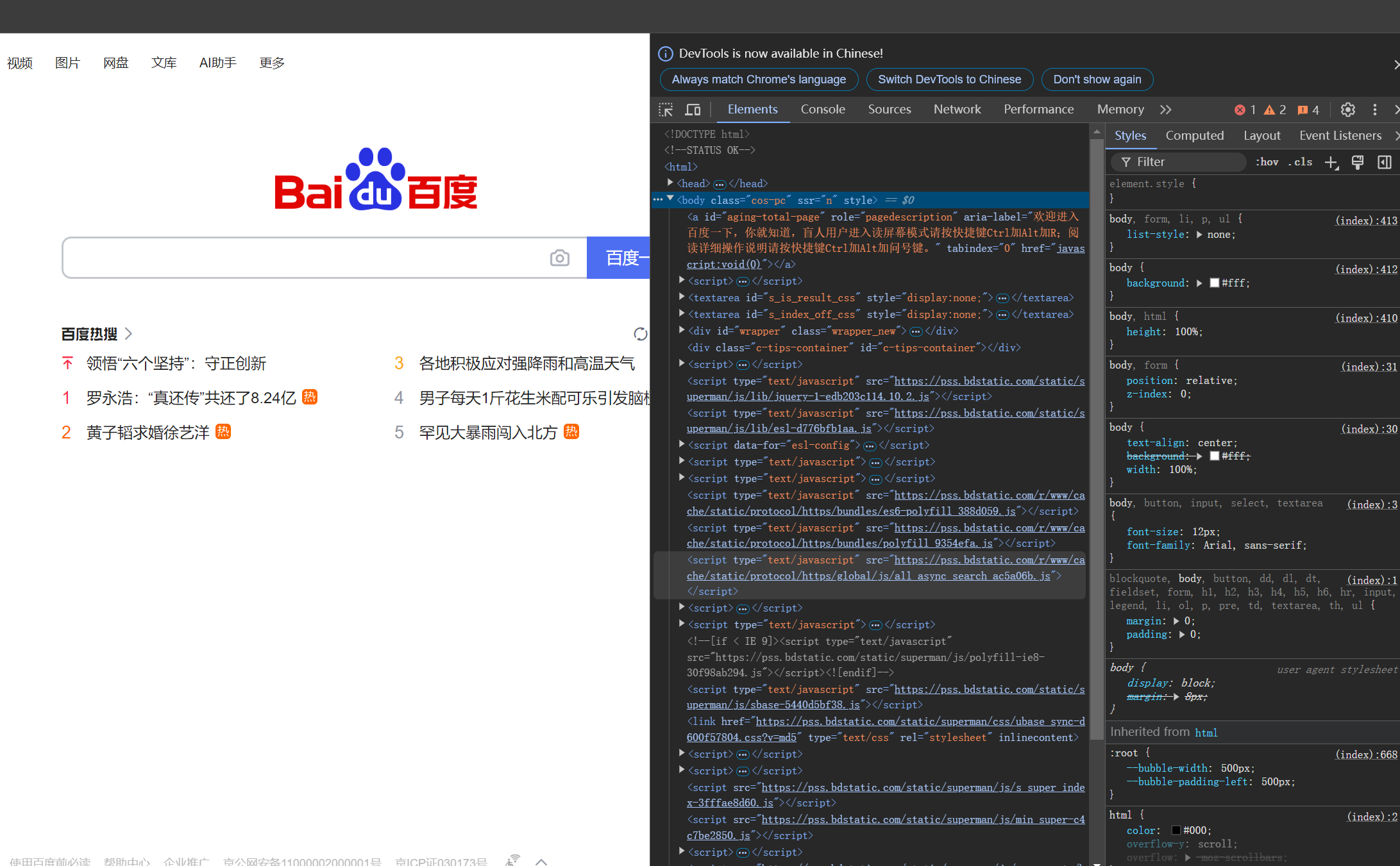
- 开发者工具的标签选项说明:
- 元素(Elements):用于查看或修改HTML标签
- 控制台(Console):执行js代码
- 源代码(Sources):查看静态资源文件,断点调试JS代码
- 网络(Network):查看http协议的通信过程
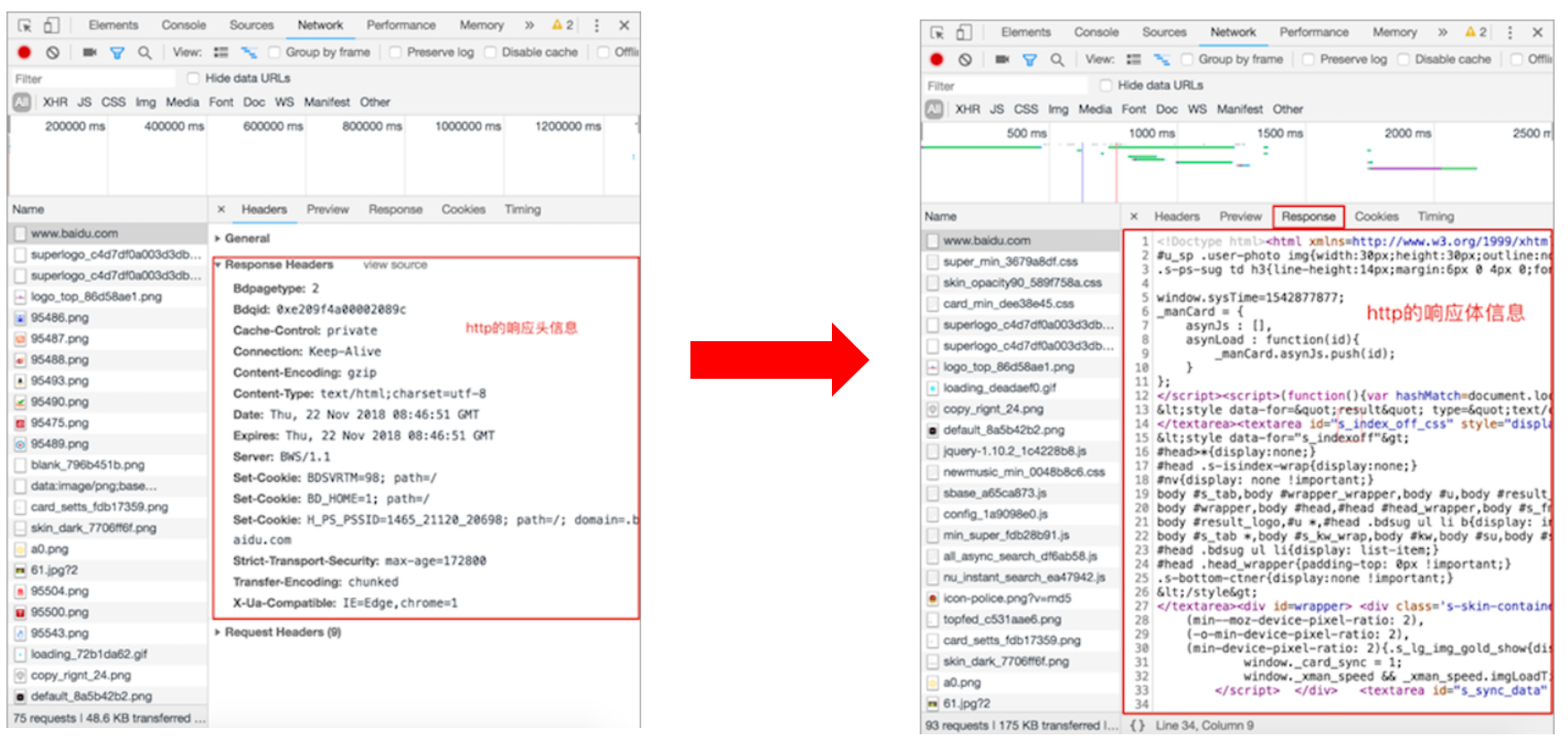
(2)查看HTTP协议的通信过程(请求)
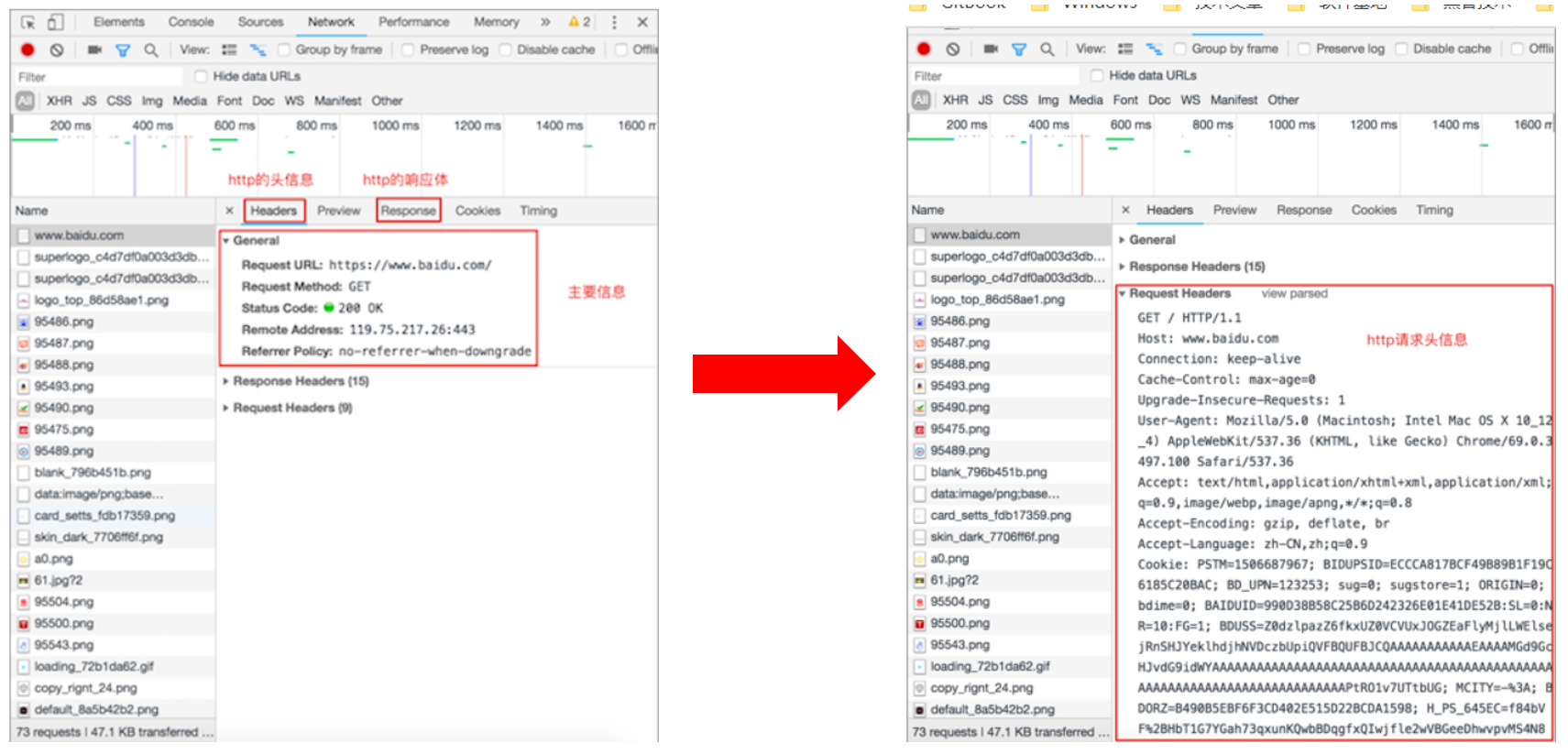
(3)查看HTTP协议的通信过程(响应)
4、HTTP请求报文
(1)HTTP请求报文介绍
- HTTP最常见的请求报文有两种:
- GET 方式的请求报文:获取web服务器数据
- POST 方式的请求报文:向web服务器提交数据
(2)HTTP GET 请求报文格式

---- 请求行 ----
GET / HTTP/1.1 # GET请求方式 请求资源路径 HTTP协议版本
---- 请求头 -----
Host: www.itcast.cn # 服务器的主机地址和端口号,默认是80
Connection: keep-alive # 和服务端保持长连接
Upgrade-Insecure-Requests: 1 # 让浏览器升级不安全请求,使用https请求
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 # 用户代理,也就是客户端的名称
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 # 可接受的数据类型
Accept-Encoding: gzip, deflate # 可接受的压缩格式
Accept-Language: zh-CN,zh;q=0.9 #可接受的语言
Cookie: pgv_pvi=1246921728; # 登录用户的身份标识
---- 空行 ----
(3)HTTP GET 请求报文说明
-
在HTTP请求中,每个选项结束后,其后面都要添加一个标签\r\n(代表一行的结束)。
-
在Windows系统中,换行符使用\n来实现。但是在Linux以及Unix系统中,换行符需要使用\r\n来实现。
GET / HTTP/1.1\r\n
Host: www.itcast.cn\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
Cookie: pgv_pvi=1246921728; \r\n
\r\n (请求头信息后面还有一个单独的’\r\n’不能省略)
(4)HTTP POST 请求报文格式

---- 请求行 ----
POST /xmweb?host=mail.itcast.cn&_t=1542884567319 HTTP/1.1 # POST请求方式 请求资源路径 HTTP协议版本
---- 请求头 ----
Host: mail.itcast.cn # 服务器的主机地址和端口号,默认是80
Connection: keep-alive # 和服务端保持长连接
Content-Type: application/x-www-form-urlencoded # 告诉服务端请求的数据类型
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 # 客户端的名称
---- 空行 ----
---- 请求体 ----
username=hello&pass=hello # 请求参数
(5)HTTP POST 请求报文说明
- 每项数据之间使用
\r\n进行结束
5、HTTP 响应报文
(1)HTTP响应报文组成
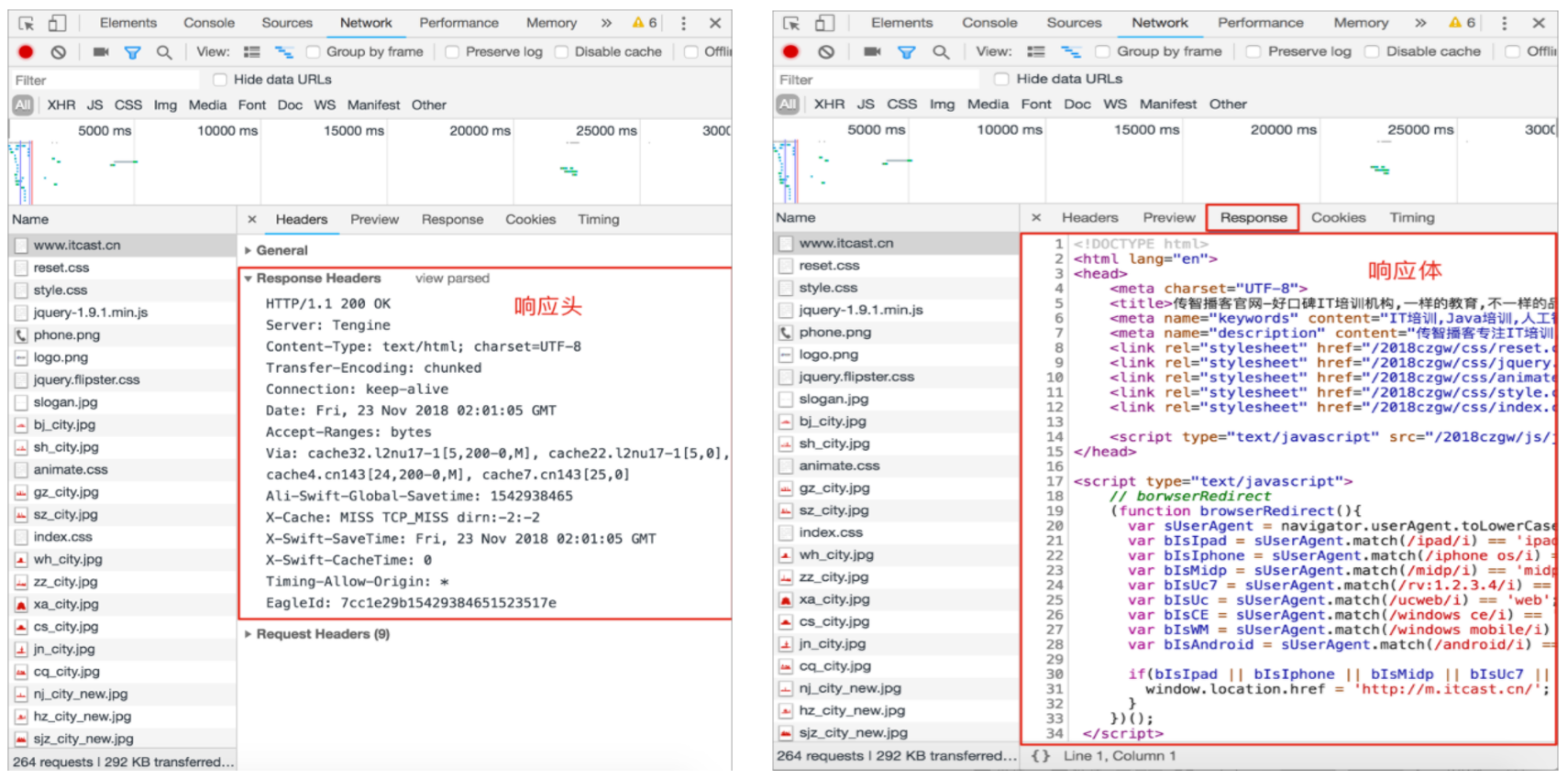
(2)响应报文格式

--- 响应行/状态行 ---
HTTP/1.1 200 OK # HTTP 协议版本 状态码 状态描述
--- 响应头 ---
Server: Tengine # 服务器名称
Content-Type: text/html; charset=UTF-8 # 内容类型
Transfer-Encoding: chunked # 发送给客户端内容不确定内容长度,发送结束的标记是0\r\n, Content-Length表示服务端确定发送给客户端的内容大小,但是二者只能用其一。
Connection: keep-alive # 和客户端保持长连接
Date: Fri, 23 Nov 2018 02:01:05 GMT # 服务端的响应时间
--- 空行 ---
--- 响应体 ---
<!DOCTYPE html><html lang=“en”> …</html> # 响应给客户端的数据
(3)响应报文说明
- 每项数据之间使用:\r\n
(4)HTTP响应状态码
- HTTP 状态码是用于表示web服务器响应状态的3位数字代码。
| 状态码 | 说明 |
|---|---|
| 200 | 请求成功 |
| 301 | 重定向 |
| 400 | 错误的请求,请求地址或者参数有误 |
| 404 | 请求资源在服务器上不存在 |
| 500 | 服务器内部源代码出现错误 |
6、搭建Python静态Web服务器
(1)静态Web服务器是什么
- 可以为发出请求的浏览器提供静态文档(HTML+CSS)的程序。
- 平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,页面的数据不会发生变化。
(2)搭建静态Web服务器
-
通过执行如下命令创建一个最简单的 HTTP 服务器:
python -m http.server -
服务器默认监听端口是 8000,支持自定义端口号:
python -m http.server 9000 -
服务器默认绑定到所有接口,可以通过 -b/–bind 指定地址,如本地主机:
python -m http.server --bind 127.0.0.1 -
服务器默认工作目录为当前目录,可通过
-d/--directory参数指定工作目录:python -m http.server --directory /tmp/ -
此外,可以通过传递参数 --cgi 启用 CGI 请求处理程序:
python -m http.server --cgi -
http.server 也支持在代码中调用,导入对应的类和函数即可。
from http.server import SimpleHTTPRequestHandler from http.server import CGIHTTPRequestHandler from http.server import ThreadingHTTPServer from functools import partial import contextlib import sys import os class DualStackServer(ThreadingHTTPServer): def server_bind(self): # suppress exception when protocol is IPv4 with contextlib.suppress(Exception): self.socket.setsockopt(socket.IPPROTO_IPV6, socket.IPV6_V6ONLY, 0) return super().server_bind() def run(server_class=DualStackServer, handler_class=SimpleHTTPRequestHandler, port=8000, bind='127.0.0.1', cgi=False, directory=os.getcwd()): """Run an HTTP server on port 8000 (or the port argument). Args: server_class (_type_, optional): Class of server. Defaults to DualStackServer. handler_class (_type_, optional): Class of handler. Defaults to SimpleHTTPRequestHandler. port (int, optional): Specify alternate port. Defaults to 8000. bind (str, optional): Specify alternate bind address. Defaults to '127.0.0.1'. cgi (bool, optional): Run as CGI Server. Defaults to False. directory (_type_, optional): Specify alternative directory. Defaults to os.getcwd(). """ if cgi: handler_class = partial(CGIHTTPRequestHandler, directory=directory) else: handler_class = partial(SimpleHTTPRequestHandler, directory=directory) with server_class((bind, port), handler_class) as httpd: print( f"Serving HTTP on {bind} port {port} " f"(http://{bind}:{port}/) ..." ) try: httpd.serve_forever() except KeyboardInterrupt: print("\nKeyboard interrupt received, exiting.") sys.exit(0) if __name__ == '__main__': run(port=8000, bind='127.0.0.1') -
http.server 也支持在代码中调用,导入对应的类和函数即可。
(3)返回固定页面数据
- 编写一个TCP服务端程序
- 获取浏览器发送的HTTP请求报文数据
- 读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器。
- HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字。
'''
实现步骤:
编写一个TCP服务端程序(七步走)
获取浏览器发送的HTTP请求报文数据
读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器。
HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字。
'''
import socket
if __name__ == '__main__':
# 第一步:创建套接字对象
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 第二步:绑定IP和端口
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
tcp_server_socket.bind(('', 8000))
# 第三步:设置监听
tcp_server_socket.listen(128)
# 第四步:接收客户端连接
while True:
new_socket, ip_port = tcp_server_socket.accept()
# 第五步:接收接收客户端发送过来的数据
content = new_socket.recv(4096).decode('utf-8')
print(content)
# 第六步:返回数据给浏览器客户端
with open('html/index.html', 'rb') as f:
file_data = f.read()
# 关键点:我们需要把以上数据拼接为HTTP响应报文(响应行、响应头、空行、响应体)
response_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server:PWB/1.1\r\nContent-Type:text/html; charset=utf-8\r\n'
# 空行 => \r\n
response_body = file_data
# 组装HTTP响应数据
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response_data)
# 关闭套接字对象
new_socket.close()
(4)返回指定页面数据
- 获取用户请求资源的路径
- 根据请求资源的路径,读取指定文件的数据
- 组装指定文件数据的响应报文,发送给浏览器
- 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器
'''
基本Web服务器:
编写一个TCP服务端程序(七步走)
获取浏览器发送的HTTP请求报文数据
读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器。
HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字。
要想返回指定页面:
获取用户请求资源的路径
根据请求资源的路径,读取指定文件的数据
组装指定文件数据的响应报文,发送给浏览器
'''
import socket
if __name__ == '__main__':
# 第一步:创建套接字对象
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 第二步:绑定IP和端口,设置端口复用
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
tcp_server_socket.bind(('', 9000))
# 第三步:设置监听
tcp_server_socket.listen(128)
# 第四步:接收客户端连接
while True:
new_socket, ip_port = tcp_server_socket.accept()
# 第五步:接收客户端传递过来的数据
client_request_data = new_socket.recv(4096)
# 判断(易错点)=> 新版的很多浏览器都带了一个自动刷新功能(每隔一段时间不操作,浏览器会自动刷新1次)=> 发送了一个空数据包过来
if client_request_data:
# 如果浏览器发送过来了数据,则我们对HTTP请求数据进行解析
client_request_data = client_request_data.decode('utf-8')
# print(client_request_data)
# 获取用户请求的资源页面
request_data = client_request_data.split(' ', maxsplit=2)
request_path = request_data[1] # /index.html
# 解决域名直接访问首页问题
if request_path == '/': # 代表用户期望访问首页
request_path = '/index.html'
# 第六步:返回数据给浏览器客户端
try:
with open('html' + request_path, 'rb') as f: # html/index.html
file_data = f.read()
except:
# 如果以上文件不存在,则返回404,返回错误信息
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server:PWB/1.1\r\nContent-Type:text/html; charset=utf-8\r\n'
response_body = '很抱歉,您要访问的页面不存在!'
response_data = (response_line + response_header + '\r\n' + response_body).encode('utf-8')
new_socket.send(response_data)
else:
# 拼接HTTP响应报文 => 响应行、响应头、空行、响应体
response_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server:PWB/1.1\r\n'
# 空行\r\n
response_body = file_data
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response_data)
finally:
# 第七步:关闭新产生的套接字对象
new_socket.close()
(5)案例-商城项目
'''
HTTP之Web服务器开发 => TCP七步走
'''
import socket
if __name__ == '__main__':
# 第一步:创建套接字对象
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 第二步:绑定IP与端口
tcp_server_socket.bind(('', 8080))
# 第三步:设置监听
tcp_server_socket.listen(128)
# 第四步:接收客户端连接请求
while True:
new_socket, ip_port = tcp_server_socket.accept()
# 第五步:接收客户端发送过来的数据
client_request_data = new_socket.recv(4096)
if client_request_data:
request_data = client_request_data.decode('utf-8')
# 针对字符串进行切割,获取请求路径
request_path = request_data.split(' ', maxsplit=2)[1]
# 如果用户向直接访问首页,不输入资源路径
if request_path == '/':
request_path = '/index.html'
# 判断文件是否存在,存在返回200,不存在就返回404
try:
with open('shoping'+request_path, 'rb') as f:
file_data = f.read()
except:
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server:PWB2.0\r\nContent-type:text/html; charset=utf-8'
response_body = '很抱歉,您要访问的商城页面不存在!'
response_data = (response_line + response_header + '\r\n' + response_body).encode('utf-8')
new_socket.send(response_data)
else:
response_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server:PWB2.0\r\n'
response_body = file_data
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response_data)
finally:
new_socket.close()
(6)静态Web服务器多线程版本
- 目前的Web服务器,不能支持多用户同时访问,只能一个一个的处理客户端的请求,可以使用多线程开发多任务版的web服务器同时处理多个客户端的请求,比进程更加节省内存资源。
- 多任务版静态web服务器实现步骤
- 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞。
- 把创建的子线程设置成为守护主线程,防止主线程无法退出。
import socket
import threading
def son(get_sock):
# 接收数据 数据一定要接收
ret = get_sock.recv(4096)
# 完善:判断用户是否离开
if len(ret) == 0:
print('用户下线')
get_sock.close()
return
# 解析请求报文,得到请求资源中的资源路径
ret_road = ret.decode().split('\r\n')[0].split(' ')[1]
# 判断当/时候返回主页面
if ret_road == '/':
ret_road = '/index.html'
try:
# 响应报文和发送
# 读取网页资源 rb读取时候本身为二进制,所以在发送数据那块不用再进行编码转换
file = open('./html' + ret_road, 'rb')
body_data = file.read()
file.close()
# with open写法
# with open('./html/index.html','rb')as file:
# body_data = file.read()
except Exception as e:
# 如果以上文件不存在,则返回404,返回错误信息
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server:PWB/1.1\r\nContent-Type:text/html; charset=utf-8\r\n'
response_body = '很抱歉,您要访问的页面不存在!'
response_data = (response_line + response_header + '\r\n' + response_body).encode('utf-8')
get_sock.send(response_data)
else:
response_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server:PWB2.0\r\n'
response_body = body_data
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
get_sock.send(response_data)
finally:
# 关闭
get_sock.close()
def main():
web_sock = socket.socket()
web_sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1)
web_sock.bind(('',9999))
web_sock.listen(128)
while True:
#接收一个新的连接请求
get_sock, get_adress = web_sock.accept()
# print('用户%s 进入' % str(get_adress))
thd = threading.Thread(target=son, args=(get_sock,))
#设置守护主线程
thd.setDaemon(True)
thd.start()
if __name__ == '__main__':
main()
(7)静态Web服务器面向对象版本
- ① 把提供服务的Web服务器抽象成一个类(HTTPWebServer)
- ② 提供Web服务器的初始化方法,在初始化方法里面创建socket对象
- ③ 提供一个开启Web服务器的方法,让Web服务器处理客户端请求操作。
import socket
import threading
class HTTPWebServer(object):
def __init__(self):
web_sock = socket.socket()
web_sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
web_sock.bind(('', 9999))
web_sock.listen(128)
self.web_sock = web_sock
def start(self):
while True:
# 接收一个新的连接请求
get_sock, get_adress = self.web_sock.accept()
print('用户%s 进入' % str(get_adress))
thd = threading.Thread(target=self.son, args=(get_sock,))
# 设置守护主线程
thd.setDaemon(True)
thd.start()
@staticmethod
def son(get_sock):
# 接收数据 数据一定要接收
ret = get_sock.recv(4096)
# 完善:判断用户是否离开
if len(ret) == 0:
print('用户下线')
get_sock.close()
return
# 解析请求报文,得到请求资源中的资源路径
ret_road = ret.decode().split('\r\n')[0].split(' ')[1]
# 判断当/时候返回主页面
if ret_road == '/':
ret_road = '/index.html'
try:
# 响应报文和发送
# 读取网页资源 rb读取时候本身为二进制,所以在发送数据那块不用再进行编码转换
file = open('./html' + ret_road, 'rb')
body_data = file.read()
file.close()
# with open写法
# with open('./html/index.html','rb')as file:
# body_data = file.read()
except Exception as e:
# 如果以上文件不存在,则返回404,返回错误信息
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server:PWB/1.1\r\nContent-Type:text/html; charset=utf-8\r\n'
response_body = '很抱歉,您要访问的页面不存在!'
response_data = (response_line + response_header + '\r\n' + response_body).encode('utf-8')
get_sock.send(response_data)
else:
response_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server:PWB2.0\r\n'
response_body = body_data
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
get_sock.send(response_data)
finally:
# 关闭
get_sock.close()
def main():
option = HTTPWebServer()
option.start()
if __name__ == '__main__':
main()
7、FastAPI框架
(1)FastAPI是什么
-
FastAPI是一个现代的,快速(高性能)python web框架. 基于标准的python类型提示,使用python3.6+构建API的Web框架。
-
简单讲FastAPI就是把做web开发所需的相关代码全部简化, 我们不需要自己实现各种复杂的代码, 例如多任务,路由装饰器等等. 只需要调用FastAPI提供给我们的函数, 一调用就可以实现之前需要很多复杂代码才能实现的功能。
-
FastAPI的特点
- 性能快:高性能,可以和NodeJS和Go相提并论
- 快速开发:开发功能速度提高约200%至300%
- 更少的Bug:
- Fewer bugs: 减少40%开发人员容易引发的错误
- 直观:完美的编辑支持
- 简单: 易于使用和学习,减少阅读文档的时间
- 代码简洁:很大程度上减少代码重复。每个参数可以声明多个功能,减少bug的发生
- 标准化:基于并完全兼容API的开发标准:OpenAPI(以前称为Swagger)和JSON Schema
-
搭建环境
- python环境:Python 3.6+
(2)PIP详解
-
PIP(Python Package Installer):是一个Python的包管理工具,它允许用户安装和管理Python库。以下是一些关于PIP的基本概念和使用方法:
-
安装PIP:如果你使用的是Python 2.7.9+ 或 Python 3.4+,那么PIP已经内置在Python中。否则,你可能需要单独安装它。
-
基本命令:
-
pip install package_name:安装一个包。 -
pip uninstall package_name:卸载一个包。 -
pip list:列出已安装的包。 -
pip show package_name:显示包的详细信息。 -
pip search keyword:搜索包。
-
-
版本控制:
-
pip install package_name==version:安装特定版本的包。 -
pip install package_name>=version:安装版本大于或等于指定版本的包。
-
-
依赖管理:当你安装一个包时,PIP会自动处理依赖关系,安装所有必需的包。
-
虚拟环境:使用虚拟环境(如venv或virtualenv)可以创建隔离的Python环境,每个环境可以有自己的一套包和Python版本,互不影响。
-
缓存:PIP会缓存下载的包,以加快未来的安装过程。可以通过
pip cache命令管理缓存。 -
配置文件:PIP使用配置文件(pip.conf或pip.ini),可以设置默认的源、代理等。
-
常用镜像源:
- 豆瓣(douban):
https://pypi.douban.com/simple/ - 阿里云(aliyun):
https://mirrors.aliyun.com/pypi/simple/ - 中国科技大学(ustc):
https://pypi.mirrors.ustc.edu.cn/simple/ - 清华大学(Tsinghua):
https://pypi.tuna.tsinghua.edu.cn/simple/
- 豆瓣(douban):
-
源(Repository):可以通过修改配置文件或使用命令行参数
-i来指定使用不同的源,例如使用PyPI(默认)或阿里云镜像。 -
升级PIP:使用
pip install --upgrade pip来升级PIP本身。 -
安全:使用
pip install --trusted-host或配置文件中的[global]部分来信任特定的源,以避免安全警告。 -
脚本:可以使用
pip install package_name==version --target=/path/to/dir将包安装到指定目录。
(3)FastAPI安装
-
安装方式1:
-
安装fastapi
-
pip install fastapi -i https://mirrors.aliyun.com/pypi/simple/
-
-
如果用于生产,那么你还需要一个ASGI服务器,如Uvicorn或Hypercorn
-
pip install uvicorn -i https://mirrors.aliyun.com/pypi/simple/
-
-
-
安装方式2 :
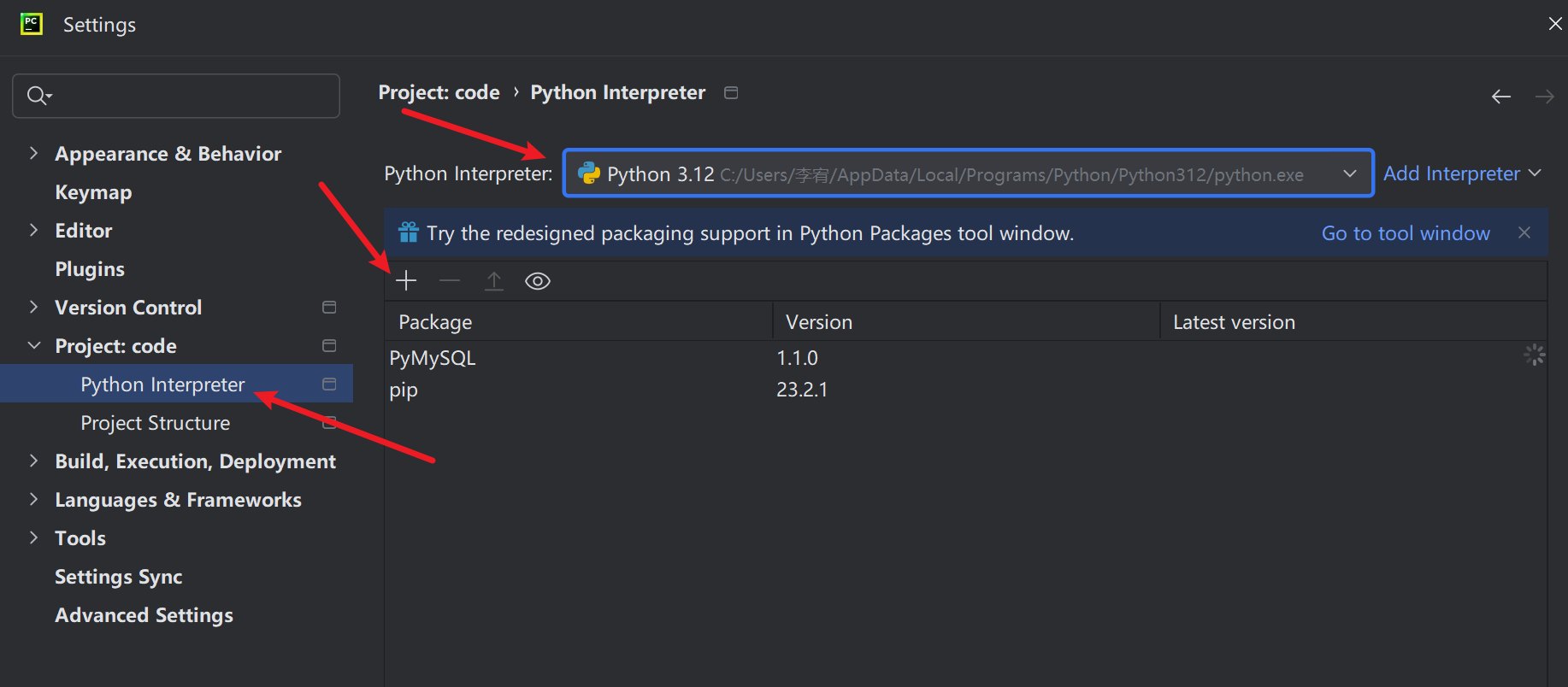
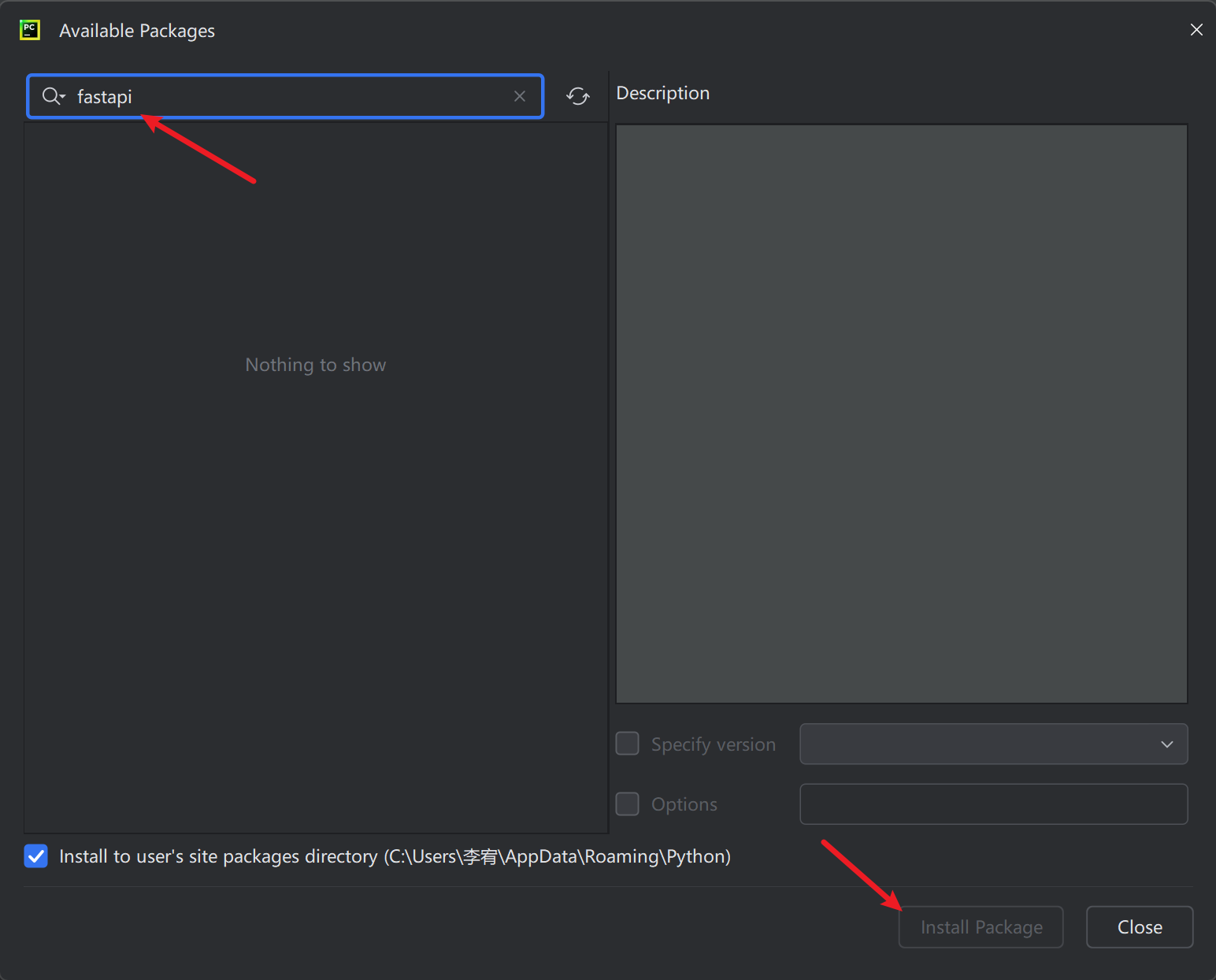
- 选择File->Settings
- 选择Project:code->Project Interpreter -> 搜索需要安装的包 -> install package按钮 -> 等待安装完成
(4)FastAPI的基本使用
- 导入模块
- 创建FastAPI框架对象
- 通过@app路由装饰器收发数据
- 运行服务器
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("./html/index.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
(5)FastAPI访问多网页
- 通过路由装饰器,实现访问不同页面返回对应页面
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index1.html")
def main():
with open("./html/index1.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
@app.get("/index2.html")
def main():
with open("./html/index2.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)