关联比赛: 阿里云数智服务创新挑战赛——服务调度比赛
下面我们将从赛题场景、核心算法以及算法的场景拓展对我们的解决方案进行说明。
1 赛题场景
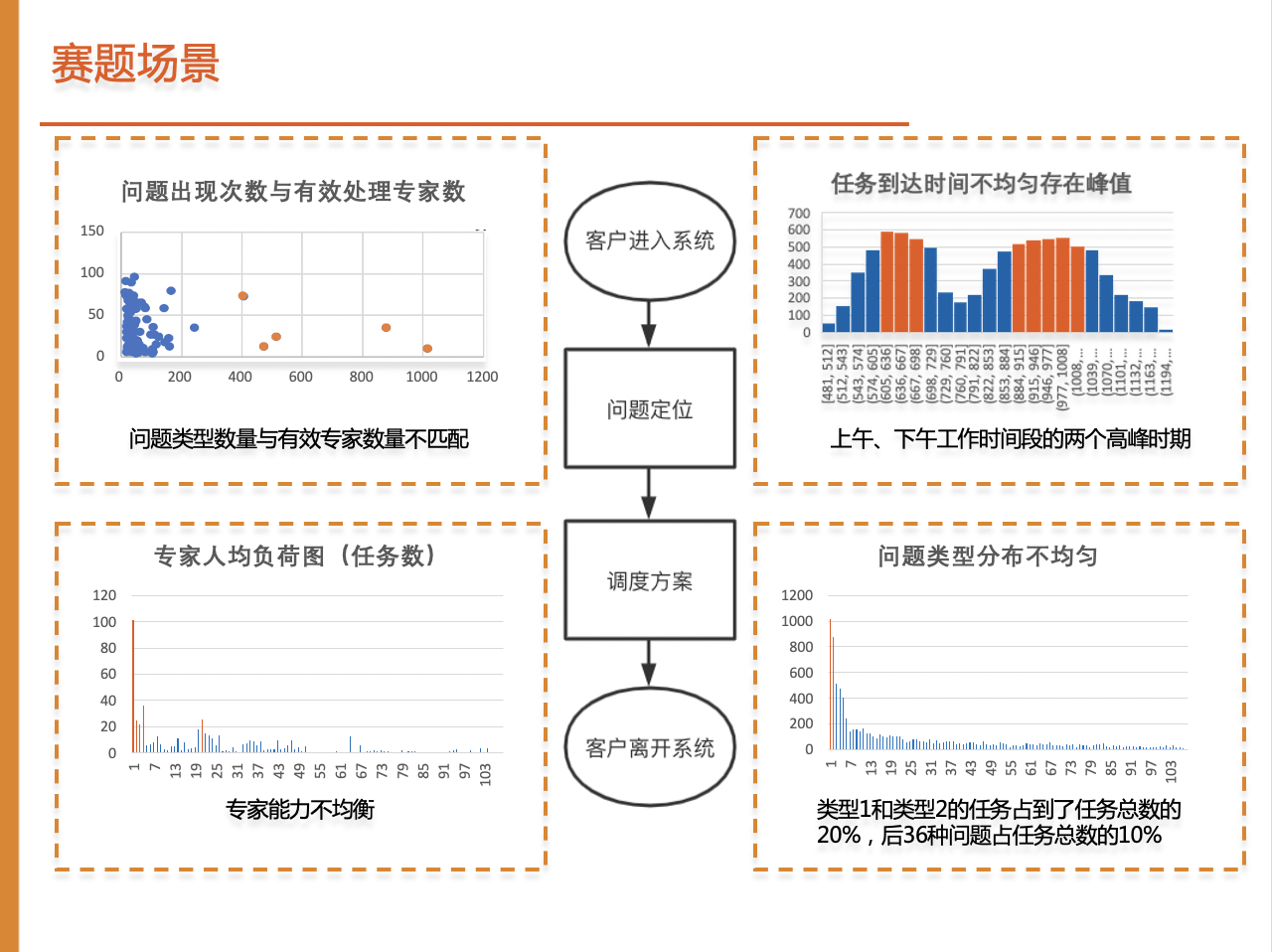
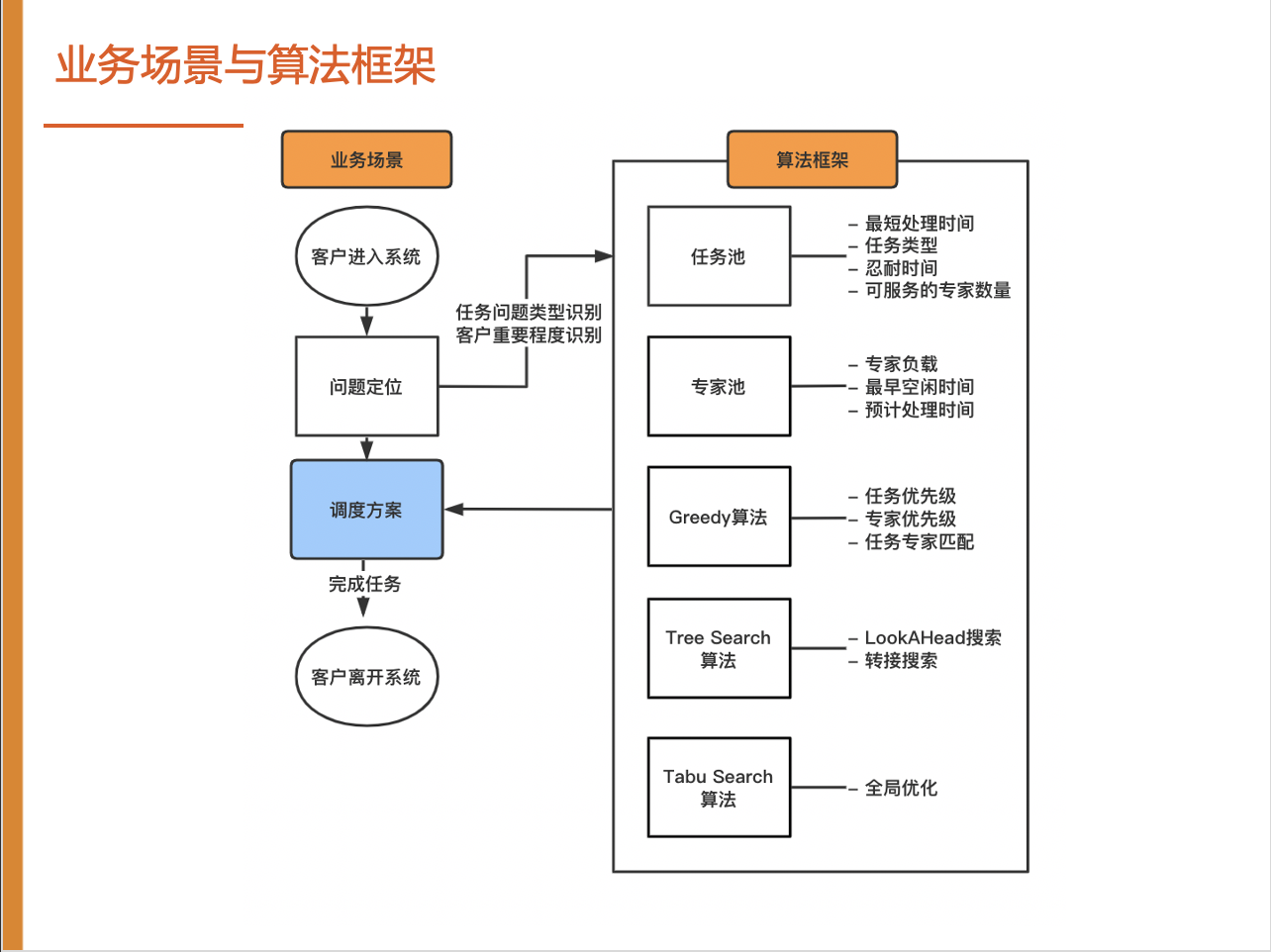
首先对赛题场景进行分析。我们建立流程图,梳理整体的调度流程。首先客户会先进入系统,定位问题明确问题的类型后,进行调度决策。
我们针对问题的分布情况以及专家的能力进行分析,发现目前场景存在着以下几点问题:
(1) 客户到达时间不均匀,存在两个到达峰值
(2) 问题类型分布不均匀,类型1和类型2的任务占总体比重20%以上,后36种问题类型只占10%
(3)问题类型出现数量与有效专家数量不匹配,出现次数多的问题类型对应的专家数量少
(4)专家能力不均衡,掌握技能范围,熟练度有差异,导致负载不均衡
2 赛题算法
针对以上问题,我们设计了调度算法,对任务响应时间、任务处理效率、专家负载均衡三个方面进行优化。下面我来介绍下算法的整体框架。
(1)首先通过Greedy算法和调参算法,快速对参数组合进行评分,找到最佳参数组合
(2)随后用最佳参数组合来构造质量较高的初始解,为每个任务安排处理和转接专家,得到初始解
(3)最后,用禁忌搜索,设计多种算子来对解进行优化得到最终解。实现时,每个模块都进行时间控制,合理安排时间资源

下面我们将针对调度、转接、禁忌搜索和参数优化四个部分进行详细介绍。
2.1 调度算法
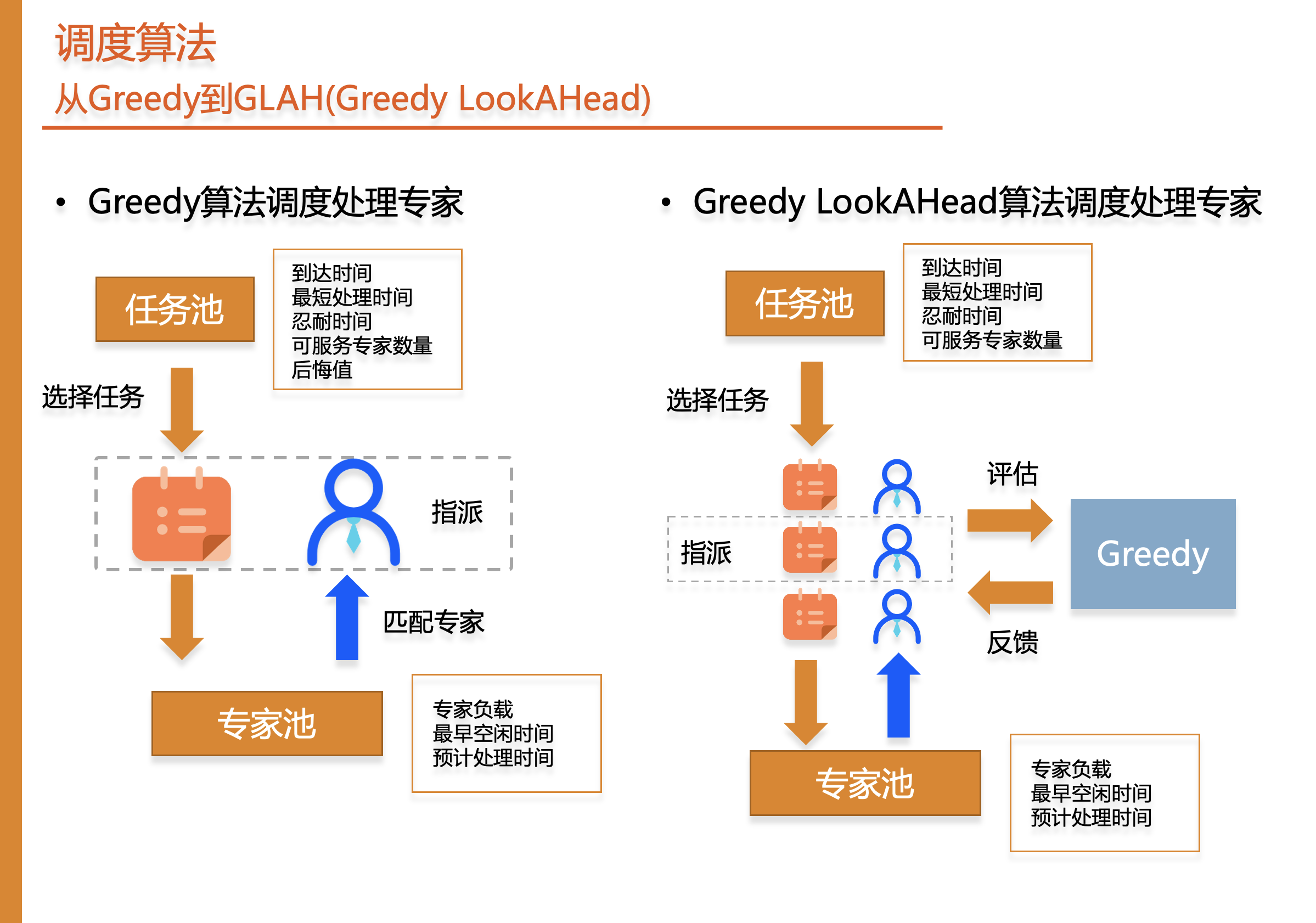
首先是调度算法,分为两个模块Greedy算法以及LookAHead算法。
Greedy 算法的流程是我们为待处理的任务计算优先级,考虑到达时间、最短处理时间、忍耐时间、可服务专家数量和后悔值五个因素,选择优先级最高的任务进行专家匹配。举个例子,对于任务1和任务2,我们从算例中获取信息,其中后悔值表示第二短的处理时间与最短处理时间的差值,将优先级的5个指标乘以权重,得到的分数越低,优先级越高。这样我们选择任务1进行指派。
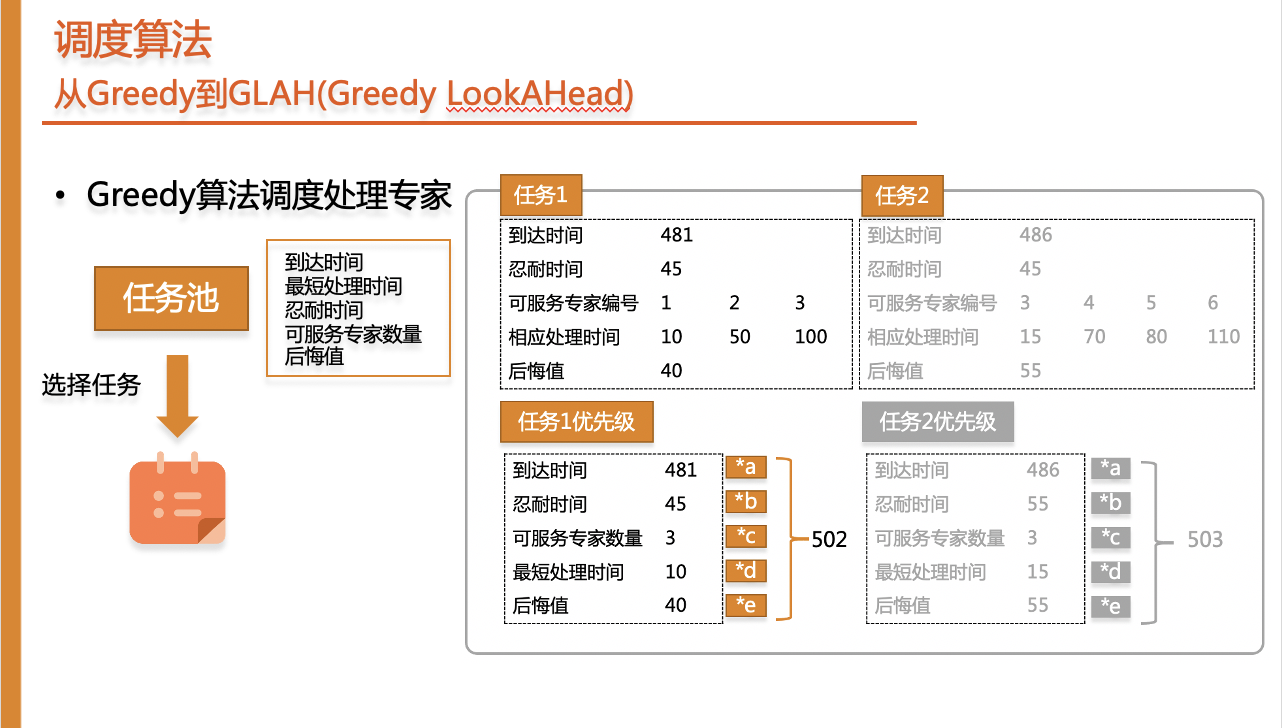
随后我们从专家池中选择专家,其优先级计算考虑三个因素,专家负载、最早空闲时间、预计处理时间,最终选择优先级最高的专家作为任务的处理专家。对于任务1的可服务专家1,2,3,我们计算得到的分数越低优先级越高。最终选择专家1处理任务1。
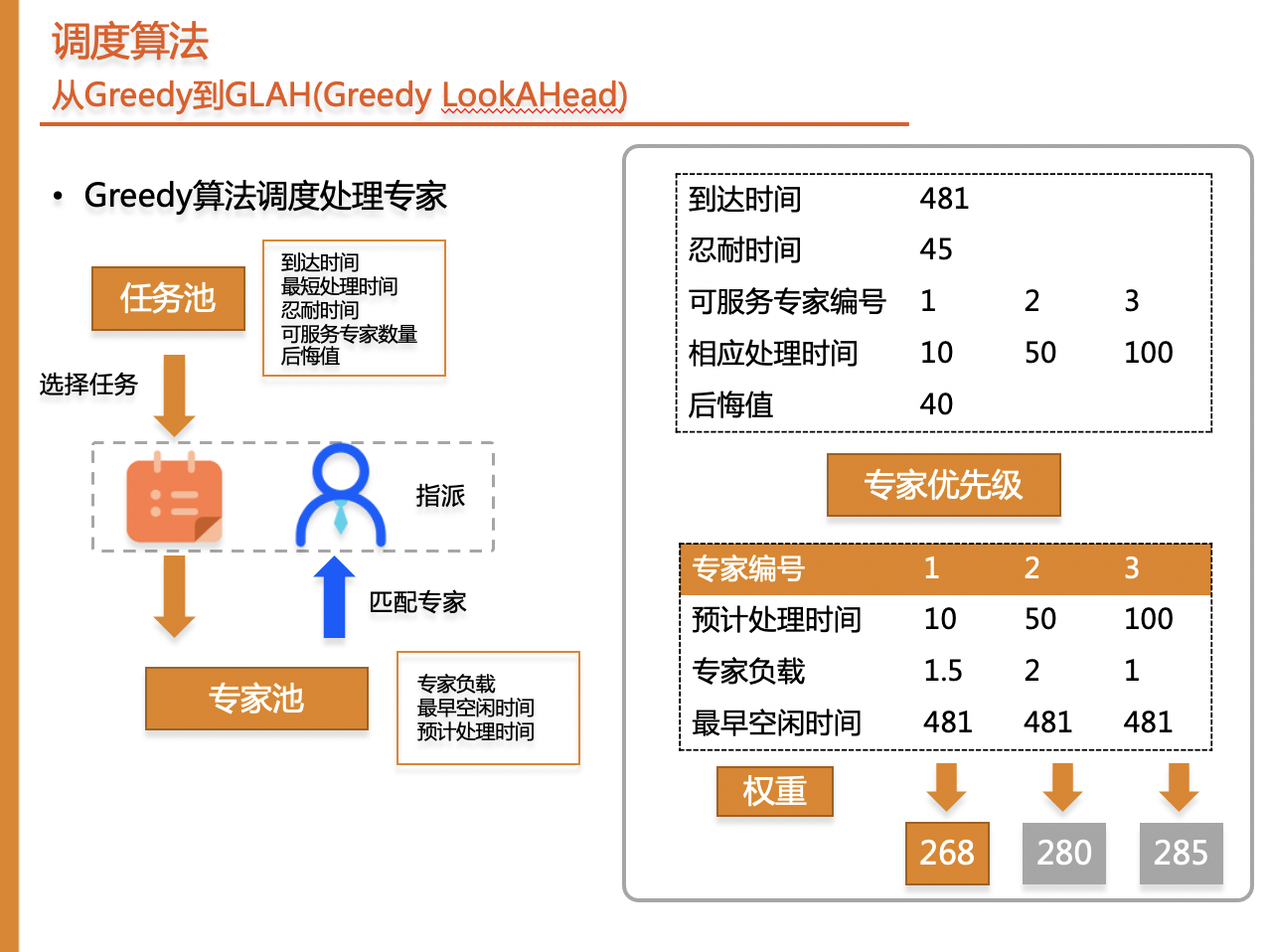
为了综合考虑未来的任务调度,我们在此基础上设计了Greedy lookahead算法,其逻辑是在选择任务时考虑多个任务,每个任务匹配多个专家,后续使用Greedy算法得到最终解进行评估,选择得分最高的方案作为这一步的指派策略。
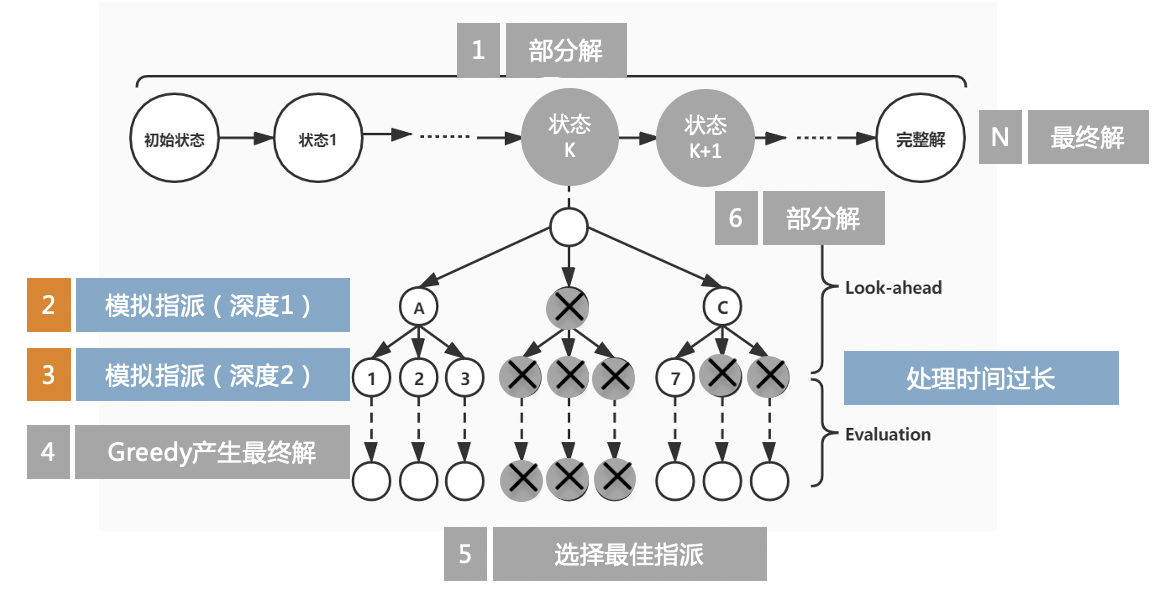
算法示意图如图所示:
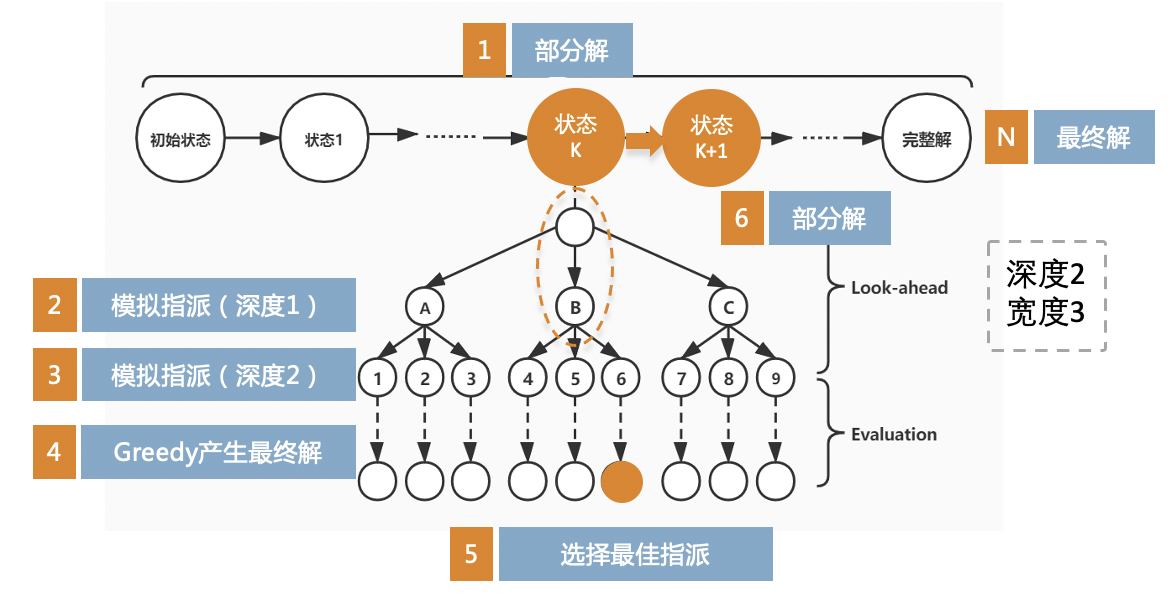
每一个状态代表了部分解,这一步要做的就是为哪个任务指派哪个专家,比如我们在状态K,我们以深度为2,宽度为3进行搜索,深度为2代表在状态k下向后考虑2个状态转移,宽度为3表示每一步转移考虑多少种指派方案。进行两步搜索后使用Greedy算法得到最终解,最终选择得分最高解回溯选择指派方案,转移到状态K+1。
随着搜索进程向后,算法速度会越来越快。
2.2 转接算法
调度处理专家后我们将调度转接专家。调度转接专家也有两种算法模块,Greedy算法和tree search算法, Greedy算法是从任务池中根据超时时间选择超时时间最大的任务,然后从专家池中选择负载最低的任务进行转接。同样站在长远角度考虑,tree search转接算法,每一步转接时考虑多个专家转接方案,最终选择得分最高的转接方案。
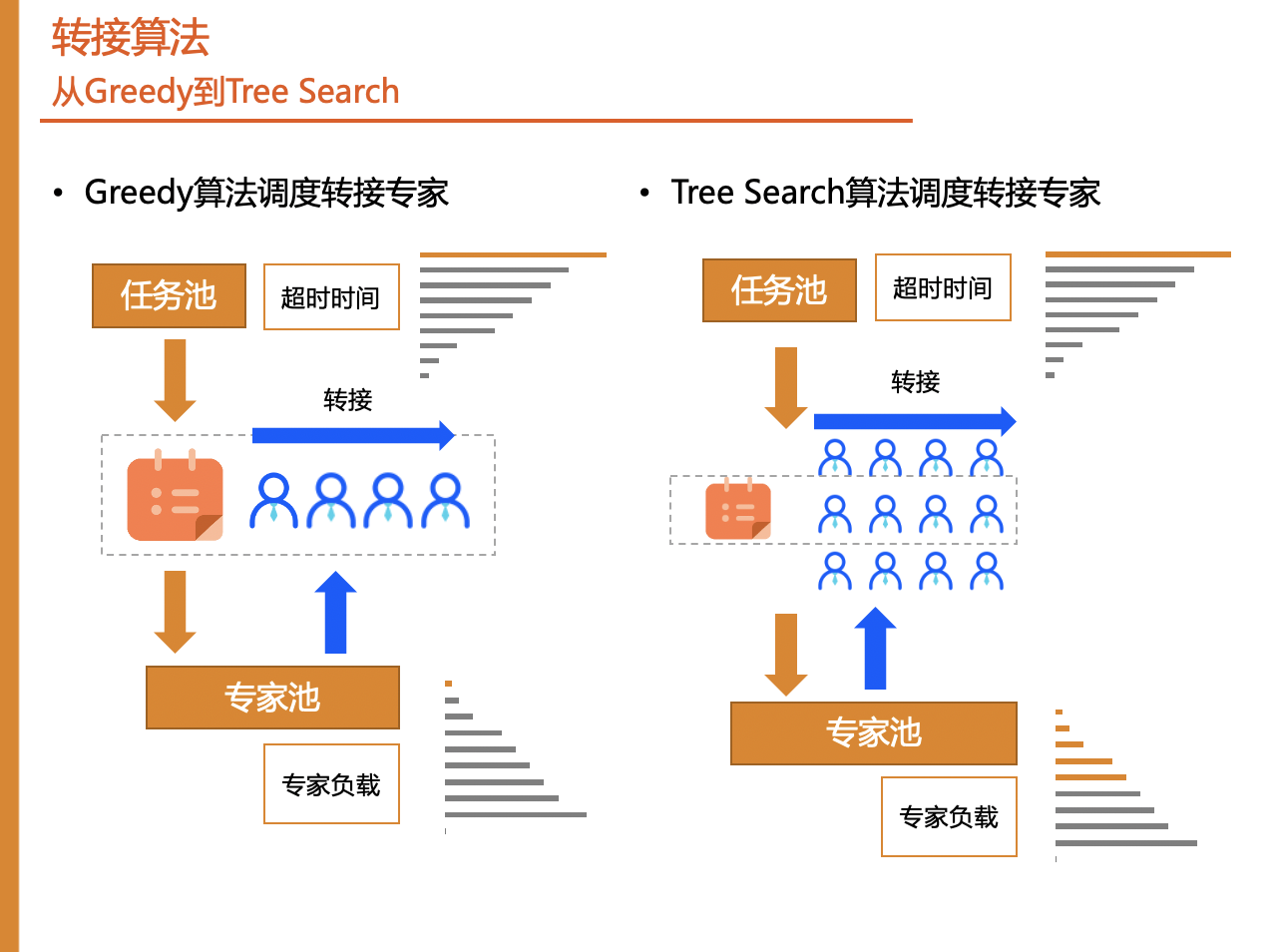
算法示意图如图所示:
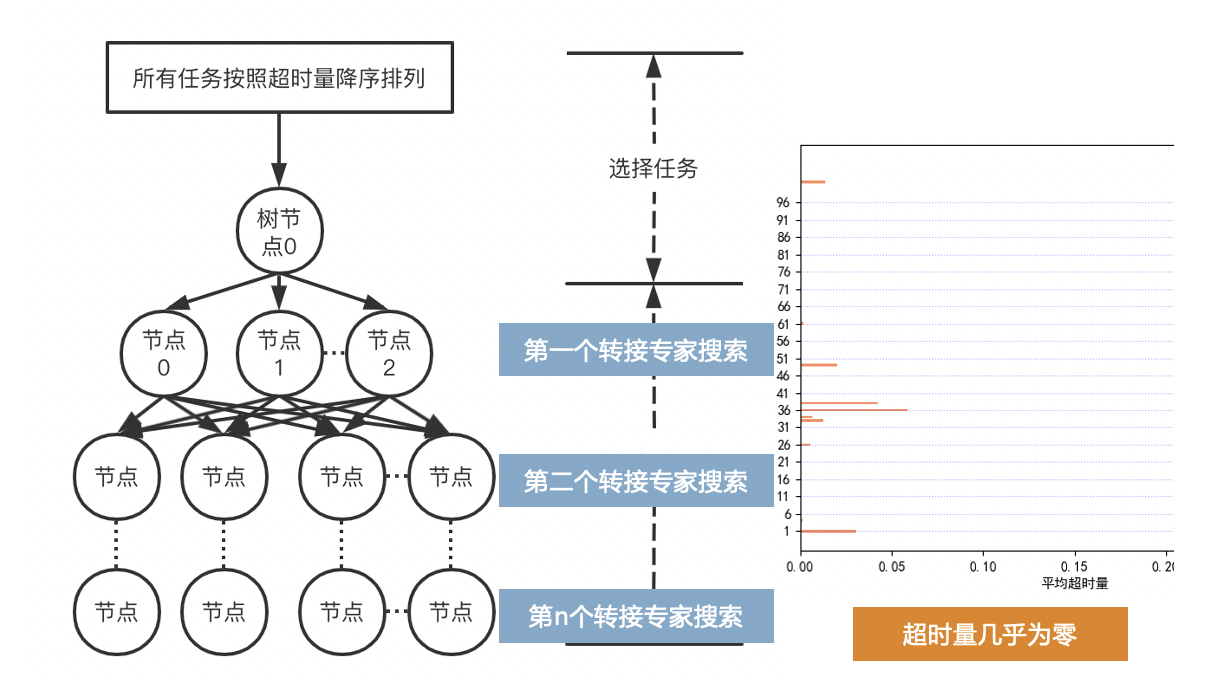
每个节点代表着考虑转接安排的专家,我们通过设置搜索转接专家的数量来控制搜索宽度,最终选择评分最高的转接方案。
通过这个方案我们最终结果的超时响应时间几乎为零。
2.3 禁忌搜索
接下来我们使用禁忌搜索算法来进行全局优化。
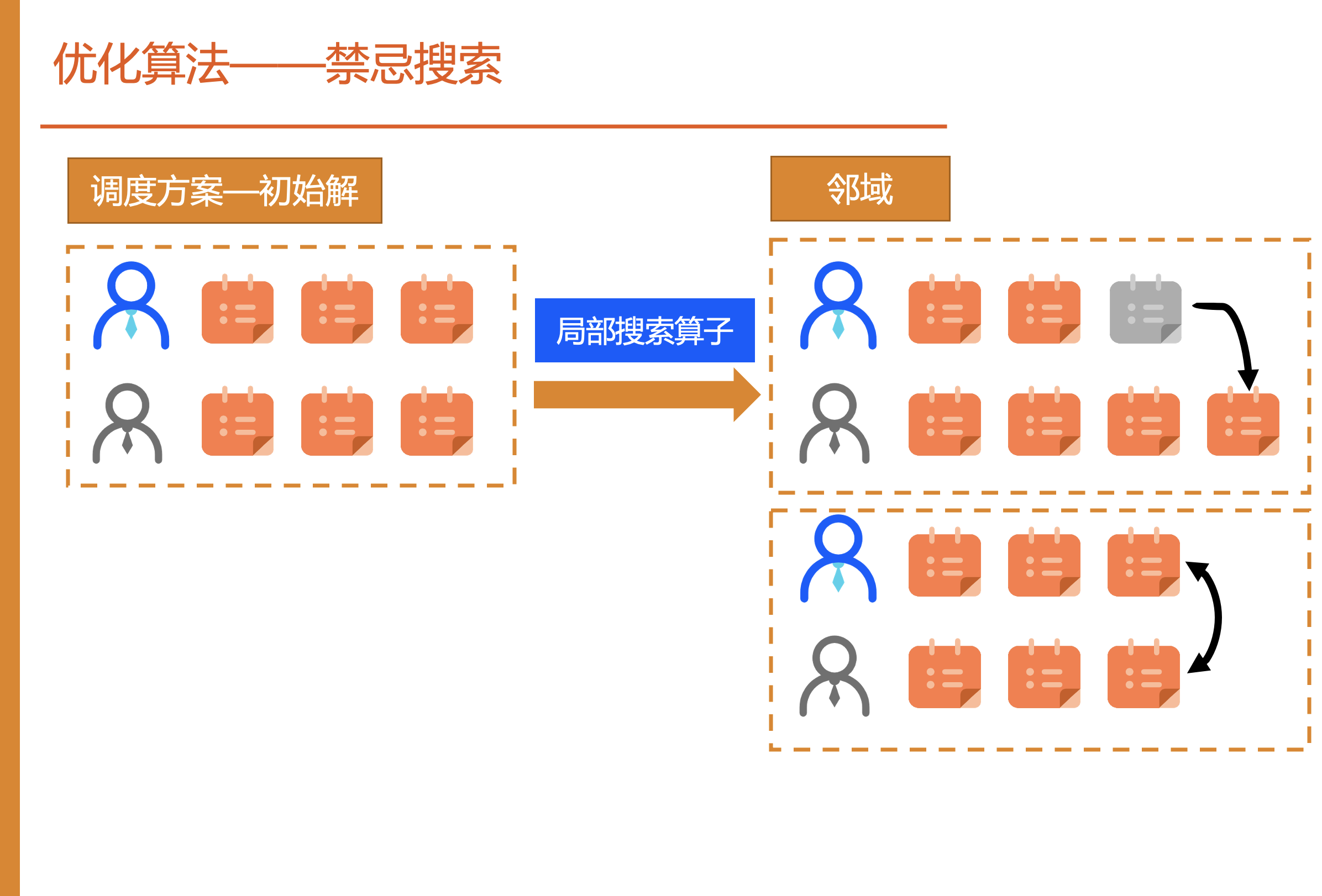
禁忌搜索伪代码如下所示,我们使用上述算法得到的解作为初始解,随后使用局部搜索算子搜索产生邻域解,提高解的质量,通过禁忌表和扰动机制防止陷入局部最优。

应用于本赛题的流程如下:我们使用上述算法得到了一个调度方案,即每位专家在何时开始到何时结束处理某个任务,随后我们使用多种局部搜索算子修改当前方案产生其他方案即邻域,如图所示,我们每次选择得分最高的邻域替代当前方案,这样经过多次迭代,每一步修改方案来提高得分。
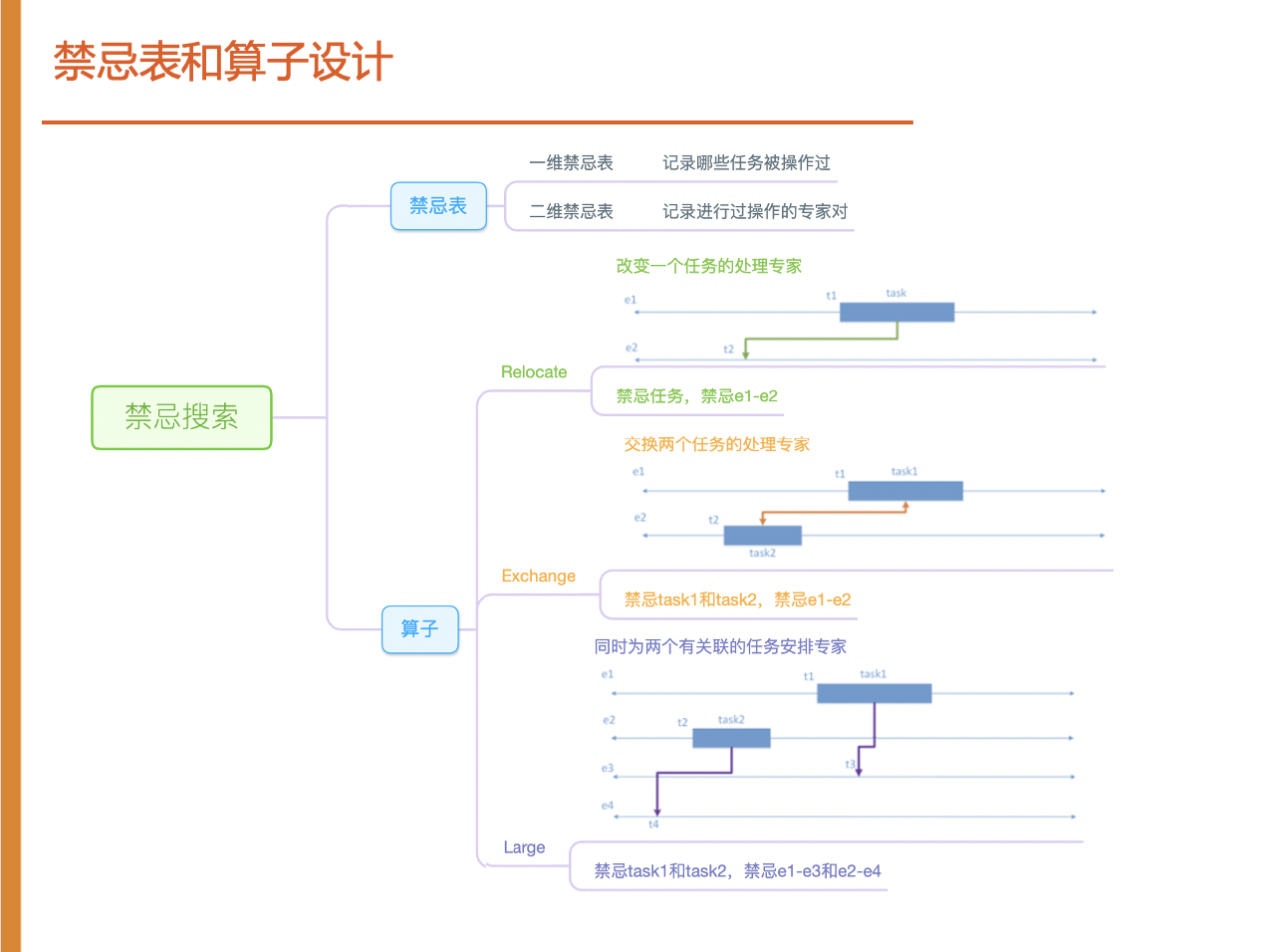
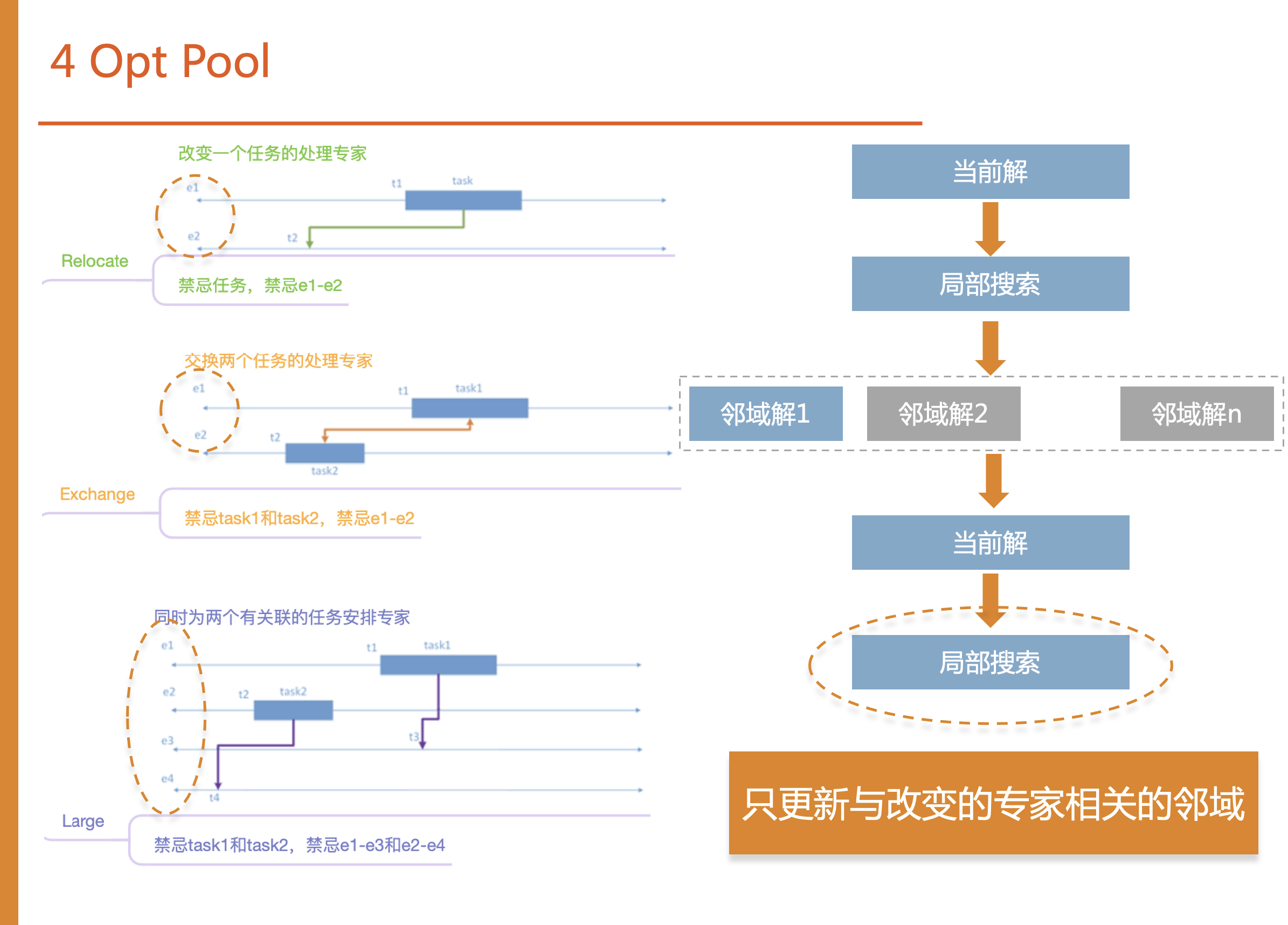
为此我们设计的禁忌表和算子,禁忌表的设计为一维禁忌表记录哪些任务被操作过,二维禁忌表来记录操作过的专家任务对。我们设计了3种算子:
-
Relocate算子
从专家1中选取一个任务task插入专家2中,专家2从t2时间开始处理该任务,即改变一个任务的处理专家。取出任务时,该任务的处理专家和转接专家全部清空。
-
Exchange算子
从专家1中选取一个任务task1与专家2的任务task2进行交换,即交换两个任务的处理专家。
-
Large算子
同时抽出两个有关联的任务task1和task2,task1原处理专家是e1,被交给e3专家处理,task2原处理专家是e2,被交给e4专家处理。同时抽出多个任务,对解的改变较大,能放入的位置也更多。
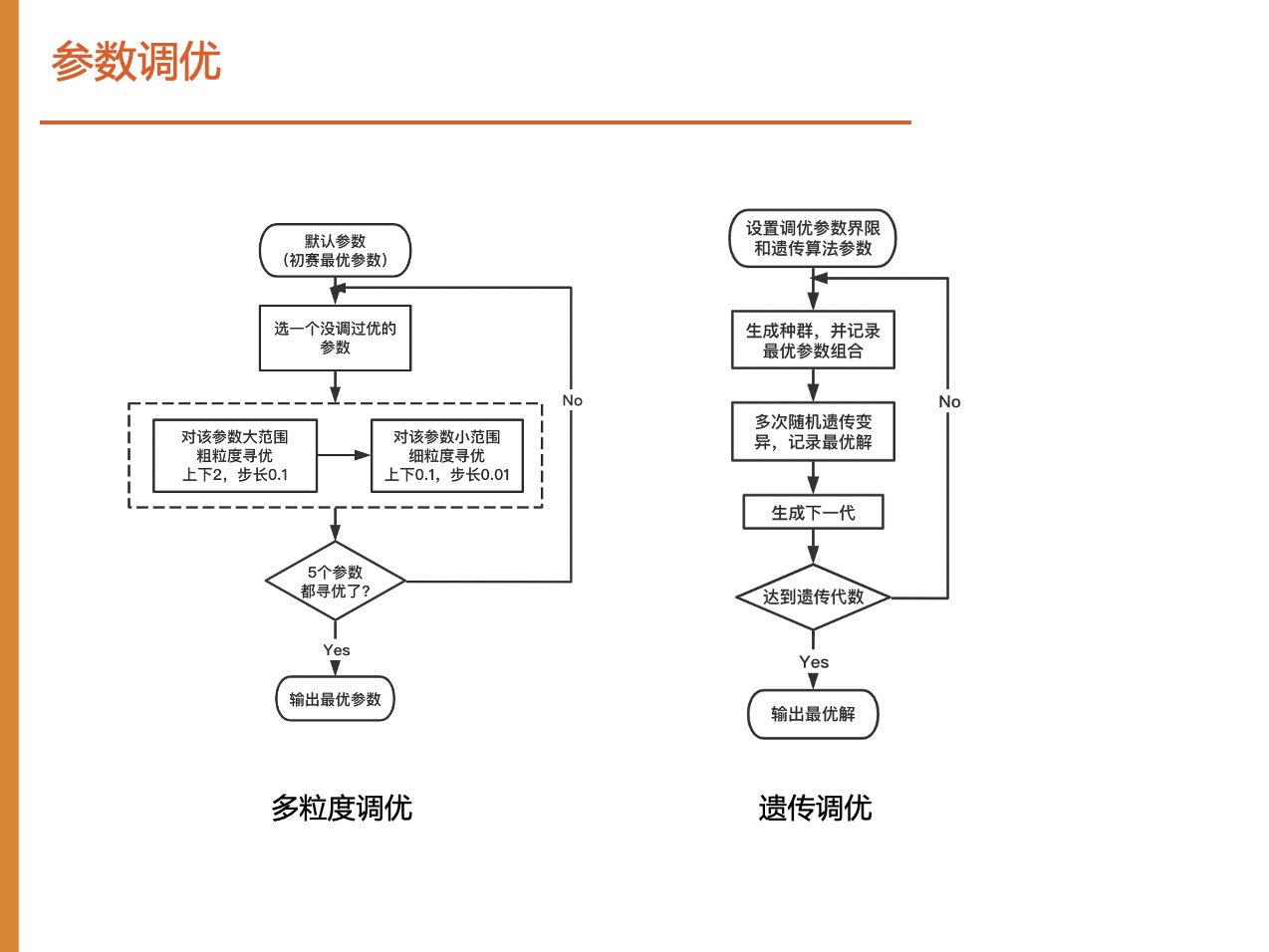
2.4 参数调优
为了保证算法适应不同的算例集,我们设计了参数调优模块。
因为基于规则鲁棒性差,我们通过两个调参算法解决这个问题挖掘适用于不同算例的规则。多粒度调参保证短时间内产生优质的参数组合,而遗传调参则跳出人类思维定式,我们会从两个算法产生的结果中选择一个最佳的参数组合。
3 算法优势
以上就是核心算法介绍,下面我将介绍我们算法的优势分别是加速机制和模块化定制。
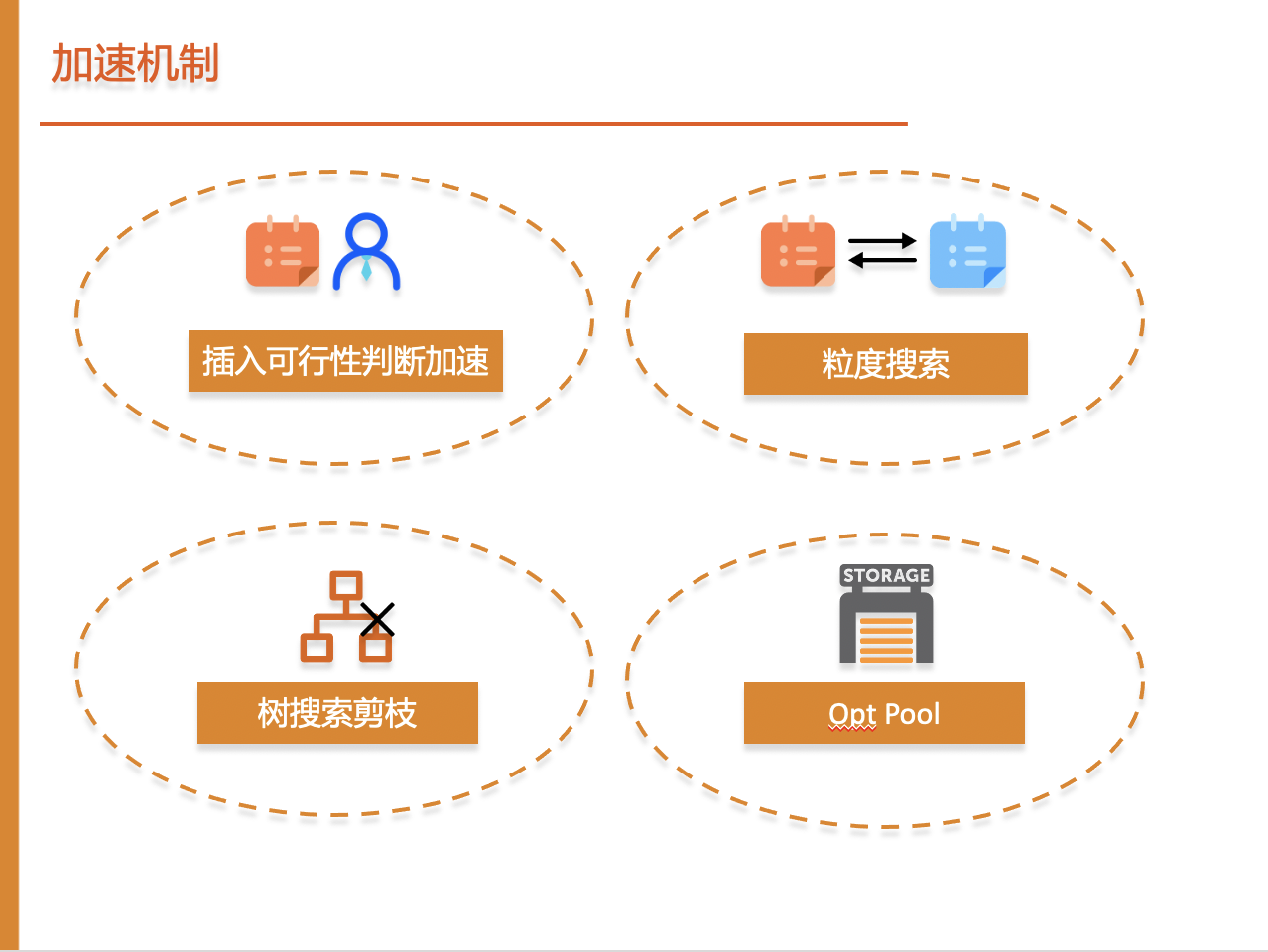
3.1 加速机制
我们设计了4种机制来加快算法,分别在于插入可行性判断,粒度搜索,树搜索剪枝和Opt Pool。
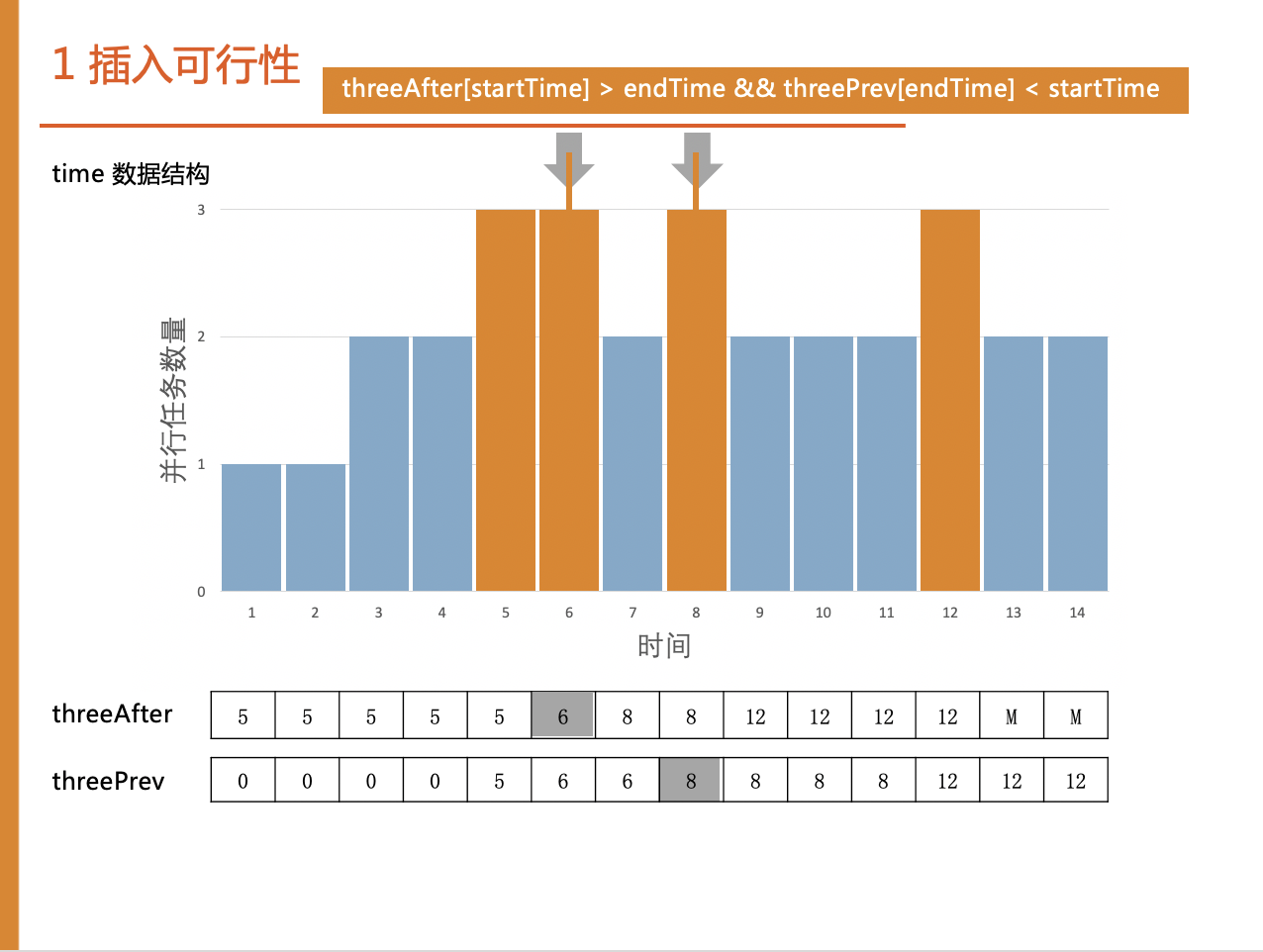
3.1.1 插入可行性判断
可行性判断主要是判断任务插入专家时并行任务数量不超过3,这里我们使用三个数组保证判断时间在O(1)内完成。
time数组记录专家每个时间的并行任务数量,threePre数组记录每个时间点之前最近的达到最大并行任务数的时间点,threeAfter记录每个时间点之后的最近时间点。举个例子,比如判断这个任务的插入位置时,只需要三次迭代就完成了插入操作,不需要原始地逐个遍历时间点,这需要7次,有明显加速效果。
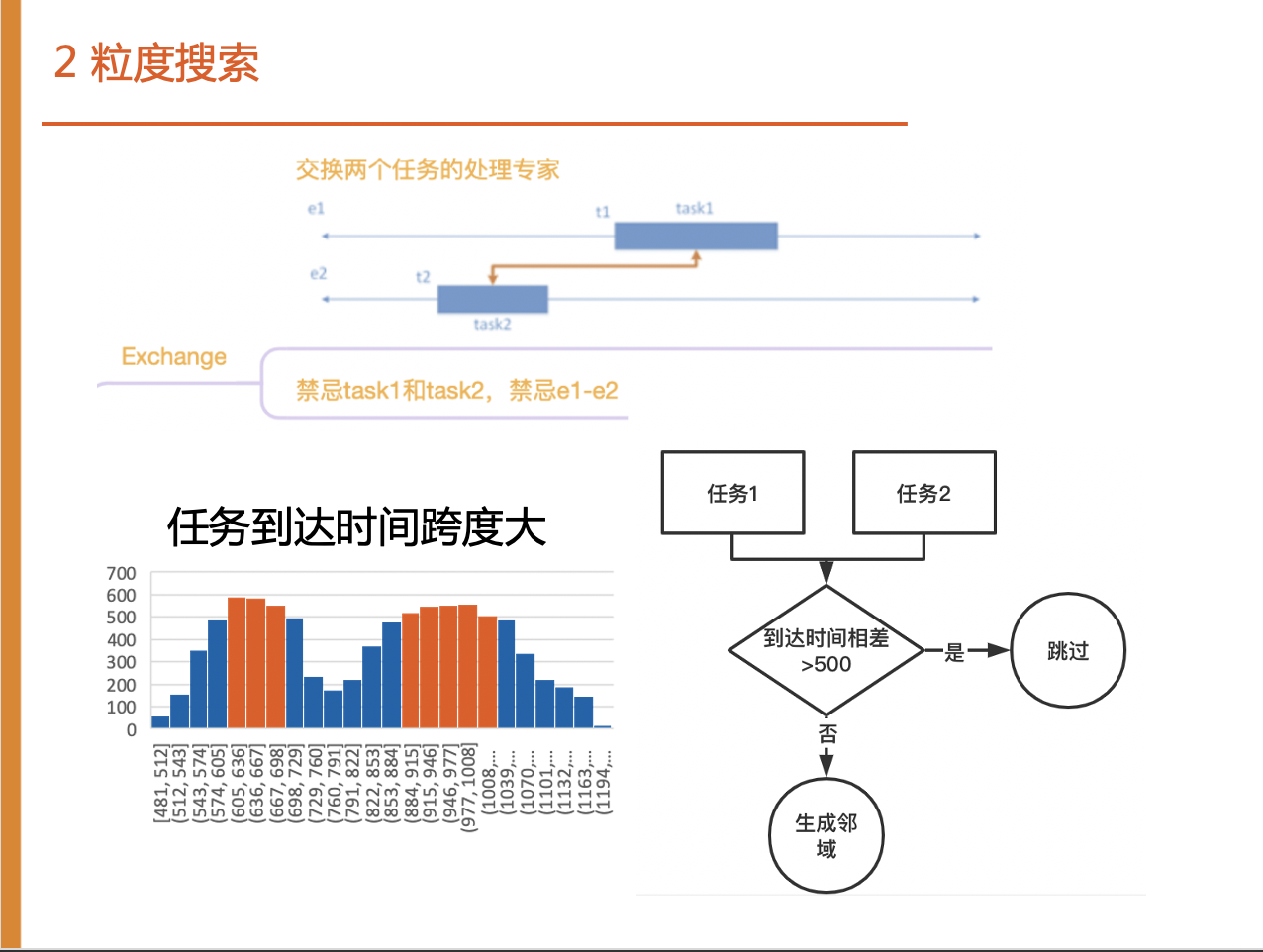
3.1.2 粒度搜索
第二个是粒度搜索机制,因为我们考虑到任务到达时间跨度较大,所以我们在禁忌搜索时,如果两个任务到达时间相差大于500,不产生邻域,加快算法的速度。
3.1.3 树搜索剪枝
第三个是树搜索的剪枝,在匹配专家环节我们对于处理时间过长的专家进行剪枝,加快速度。
3.1.4 Opt Pool
第四个是opt pool,在禁忌搜索产生邻域解时,因为存在8000多个任务和100多个专家每一次进行局部搜索的邻域是巨大的。因为我们算子的特性,在选择邻域更改当前解时只改变若干个专家的解的结构,所以每次只针对这些专家进行邻域的更新就可以大大加快禁忌搜索的时间。
3.2 模块化定制
我们算法的第二大优势是模块化定制。
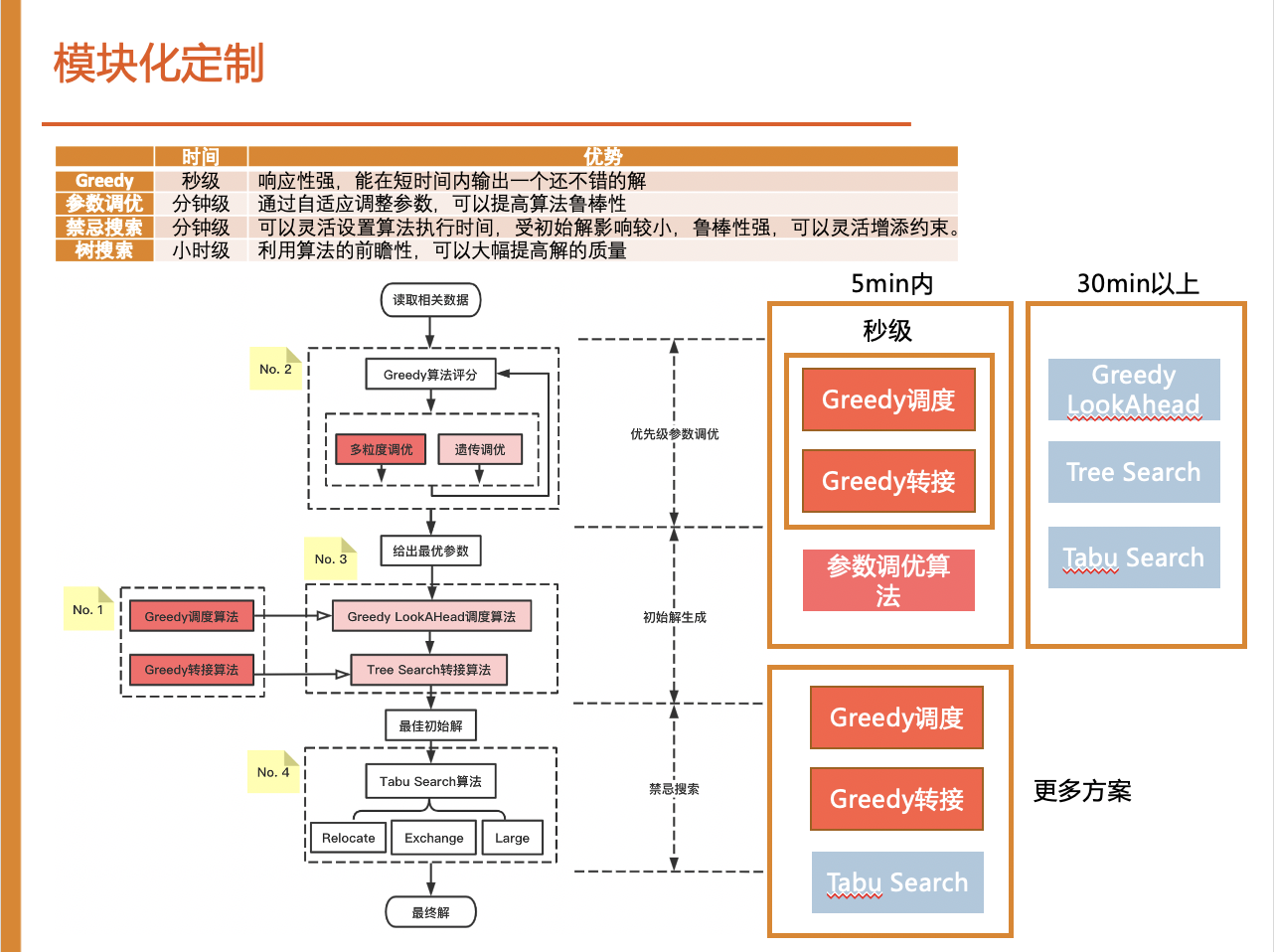
(1) 利用了多种算法的优势,并且互相弥补其短板。贪婪算法具有很好的拓展性并且可以快速产生初始解,使用树搜索算法考虑多种方案弥补了贪婪算法的短视缺陷,提高初始解的质量。禁忌搜索算法在全局进行优化,进一步提高算法结果
(2) 算法可以模块化定制,每个模块相对独立,可以根据业务场景的不同进行组合搭配
3.3 算法总结
以上就是我们结合赛题业务场景设计的算法框架,下图是总结示意。
查看更多内容,欢迎访问天池技术圈官方地址:阿里云数智服务创新挑战赛总决赛铜奖比赛攻略_NJUSME队_天池技术圈-阿里云天池