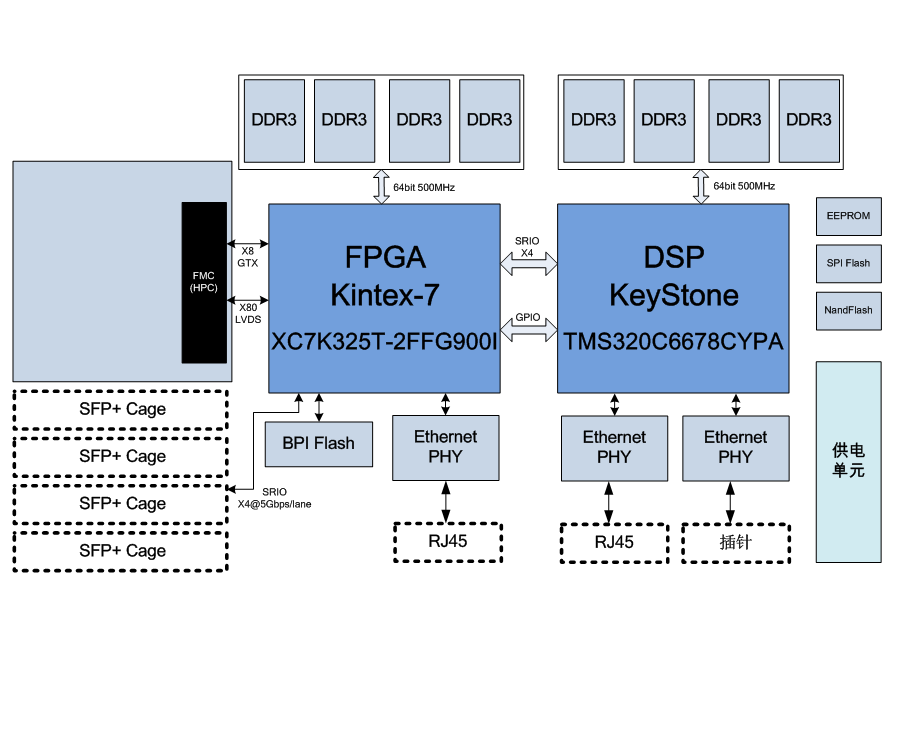
Apache Flink 是一个开源流处理框架,以其高吞吐量、低延迟和事件驱动的处理能力著称。随着大数据和实时处理需求的不断增加,Flink 在许多行业和应用场景中得到了广泛应用,如金融风控、物联网数据处理、实时数据分析等。然而,随着数据规模和业务复杂度的提升,Flink 应用的性能优化问题也变得愈发重要。在实际应用中,Flink 的性能直接影响到系统的响应速度和资源利用效率。因此,如何高效地优化 Flink 的性能,成为了大数据工程师和开发者们关注的焦点。性能优化不仅可以提高系统的处理能力,还能降低硬件资源的消耗 ,从而降低运营成本。
性能优化主要包括任务并行度调整、资源分配优化、数据传输和序列化的优化、状态管理优化、垃圾回收调整等多个方面。每个优化点都需要根据具体应用场景和系统配置进行细致的调优,以达到最佳的性能表现。本次背景研究旨在深入探讨 Apache Flink 性能优化的各种策略和方法,帮助开发者更好地理解和应用这些优化技巧,以提升实际业务系统的性能和稳定性,今天我们要介绍的是在实时数仓架构中对读取的数据进行旁路缓存和异步IO。
旁路缓存优化
在本案例实时数仓的搭建中,我们是将数仓中的维度数据存储在Hbase中,外部数据源的查询常常是流式计算的性能瓶颈。以本程序为例,每次查询都要连接 HBase,数据传输需要做序列化、反序列化,还有网络传输,严重影响时效性。可以通过旁路缓存对查询进行优化。
旁路缓存模式是一种非常常见的按需分配缓存模式。所有请求优先访问缓存,若缓存命中,直接获得数据返回给请求者。如果未命中则查询数据库,获取结果后,将其返回并写入缓存以备后续请求使用。
1)旁路缓存策略应注意两点
(1)缓存要设过期时间,不然冷数据会常驻缓存,浪费资源。
(2)要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
2)缓存的选型
一般两种:堆缓存或者独立缓存服务(memcache,redis)
堆缓存,性能更好,效率更高,因为数据访问路径更短。但是难于管理,其它进程无法维护缓存中的数据。
独立缓存服务(redis,memcache),会有创建连接、网络IO等消耗,较堆缓存略差,但性能尚可。独立缓存服务便于维护和扩展,对于数据会发生变化且数据量很大的场景更加适用,此处选择独立缓存服务,将 redis 作为缓存介质。
3)实现步骤
(1)查询时
从缓存中获取数据。
Ø 如果查询结果不为null,则返回结果。
Ø 如果缓存中获取的结果为null,则从HBase表中查询数据。
Ø 如果结果非空则将数据写入缓存后返回结果。
Ø 否则提示用户:没有对应的维度数据
Ø 注意:缓存中的数据要设置超时时间,本程序设置为1天。此外,如果原表数据发生变化,要删除对应缓存。
为了实现此功能,需要对维度分流程序做如下修改:
(2)维度变更时
Ø 如果维度数据的变更类型为insert,则对缓存无影响。
Ø 如果维度数据的变更类型为update或delete,则清除缓存。
旁路缓存图解

异步IO
在Flink 流处理过程中,经常需要和外部系统进行交互,如通过维度表补全事实表中的维度字段。
默认情况下,在Flink 算子中,单个并行子任务只能以同步方式与外部系统交互:将请求发送到外部存储,IO阻塞,等待请求返回,然后继续发送下一个请求。这种方式将大量时间耗费在了等待结果上。
为了提高处理效率,可以有两种思路。
(1)增加算子的并行度,但需要耗费更多的资源。
(2)异步 IO。
Flink在1.2中引入了Async I/O,将IO操作异步化。在异步模式下,单个并行子任务可以连续发送多个请求,按照返回的先后顺序对请求进行处理,发送请求后不需要阻塞式等待,省去了大量的等待时间,大幅提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的特性,呼声很高,可用于解决与外部系统交互时网络延迟成为系统瓶颈的问题。
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,因此单个并行子任务可以连续发送多个请求,从而提高并发效率。对于涉及网络IO的操作,可以显著减少因为请求等待带来的性能损耗。

异步IO+旁路缓存部分代码示例
(1)所须依赖
Jedis不支持异步读取Redis,所以我们使用支持异步查询的Redis客户端:lettuce。此处需要引入lettuce相关依赖,如下。
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</dependency>(2)在Redis方法中中补充异步查询相关方法
/**
* 获取到 redis 的异步连接
*
* @return 异步链接对象
*/
public static StatefulRedisConnection<String, String> getRedisAsyncConnection() {
RedisClient redisClient = RedisClient.create("redis://hadoop102:6379/2");
return redisClient.connect();
}
/**
* 关闭 redis 的异步连接
*
* @param redisAsyncConn
*/
public static void closeRedisAsyncConnection(StatefulRedisConnection<String, String> redisAsyncConn) {
if (redisAsyncConn != null) {
redisAsyncConn.close();
}
}
/**
* 异步的方式从 redis 读取维度数据
* @param redisAsyncConn 异步连接
* @param tableName 表名
* @param id id 的值
* @return 读取到维度数据,封装的 json 对象中
*/
public static JSONObject readDimAsync(StatefulRedisConnection<String, String> redisAsyncConn,
String tableName,
String id) {
RedisAsyncCommands<String, String> asyncCommand = redisAsyncConn.async();
String key = getKey(tableName, id);
try {
String json = asyncCommand.get(key).get();
if (json != null) {
return JSON.parseObject(json);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
return null;
}
/**
* 把维度异步的写入到 redis 中
* @param redisAsyncConn 到 redis 的异步连接
* @param tableName 表名
* @param id id 的值
* @param dim 要写入的维度数据
*/
public static void writeDimAsync(StatefulRedisConnection<String, String> redisAsyncConn,
String tableName,
String id,
JSONObject dim) {
// 1. 得到异步命令
RedisAsyncCommands<String, String> asyncCommand = redisAsyncConn.async();
String key = getKey(tableName, id);
// 2. 写入到 string 中: 顺便还设置的 ttl
asyncCommand.setex(key, Constant.TWO_DAY_SECONDS, dim.toJSONString());
}这就是flink的简单优化,综合来看,旁路缓存和异步IO的引入不仅解决了传统计算中存在的瓶颈问题,还为系统的可扩展性和稳定性提供了坚实的保障。


![[Java]MyBatis轻松拿下](https://img-blog.csdnimg.cn/img_convert/4c5409eb30375c9ff474185d262db9ed.png)