目录
一、NPU的由来
二、RKNPU介绍
三、RKNPU单核框架
3.1 AHB/AXI 接口
3.2 卷积神经网络加速单元(CNA)
3.3 数据处理单元(Data Processing Unit,DPU)
3.4 平面处理单元(Planar Processing Unit,PPU)
四、 NPU性能计算
五、RKNPU 应用领域 RKNPU
一、NPU的由来
NPU(Nerual Processing Unit)是一种专门用于加速神经网络计算的处理器。
在深度学习技术刚开始流行的时候,人们主要使用通用计算设备,如 CPU 和 GPU,来执行神经网络计算。但是,随着神经网络的复杂度和规模不断增加,传统的计算设备已经不能满足快速、高效地执行神经网络计算的需求。因此,研究人员开始探索如何设计一种专门用于加速神经网络计算的处理器,这就是 NPU 的由来。
早期的 NPU 主要是基于 FPGA(Field Programmable Gate Array)实现的。FPGA 是一种可编程逻辑器件,可以通过编程实现各种不同的电路功能。由于 FPGA 具有高度的灵活性和可编程 性,可以用于实现各种不同类型的神经网络处理器。2010 年,斯坦福大学的研究人员提出了一种基于 FPGA 的神经网络加速器,可以实现高效的神经网络计算。此后,越来越多的研究人 员开始尝试使用 FPGA 实现 NPU。
随着深度学习技术的不断发展和普及,NPU 的研究和开发也取得了越来越多的进展。2013 年,Google 发布了一篇论文,介绍了一种名为“Tensor Processing Unit”(TPU)的定制芯片,专 门用于加速深度学习模型的训练和推理。TPU 采用了特定的硬件架构和优化算法,可以实现高 效、低功耗的神经网络计算。TPU 的成功引起了业界的广泛关注,也促进了 NPU 的发展。 随后,其他公司也开始研发自己的 NPU。2015 年,华为发布了一款名为“Kirin 950”的处理 器,集成了一种名为“Neural Processing Unit”(NPU)的模块,用于加速神经网络计算。2018 年,华为推出了全新的“昇腾”(Ascend)系列处理器,其中包括专门用于加速深度学习计算的 NPU 模块。同年,英伟达推出了名为“TensorCore”的加速器,用于加速深度学习模型的训练和推理。
随着 NPU 技术的不断发展和普及,越来越多的公司开始将 NPU 集成到自己的芯片中,以 加速神经网络计算。例如,苹果公司在 2017 年发布的 A11 芯片中集成了神经网络处理器,用 于支持人脸识别等功能。而瑞芯微为了满足人工智能的需要,瑞芯微的处理器也逐渐集成了 NPU,而瑞芯微处理器内置的 NPU,就被称之为 RKNPU。

二、RKNPU介绍
到目前为止,RKNPU 已经经过了几代的发展,趋近成熟。RK3399pro 和 RK1808 初次引入了 RKNPU,相比传统的 CPU 和 GPU ,在深度学习运算能力上有比较大幅度的提升。接下来在 RV1109 和 RV1126 上使用了第二代 NPU,提升了 NPU 的利用 率。第三代 NPU 应用在 RK3566 和 RK3568 上,搭载全新 NPU 自研架构,而 RK3588 搭载的 为第四代 NPU,提高了带宽利用率,支持了多核扩展。RKNPU 具体发展过程如下图所示:

RKNPU1.0 和 RKNPU2.0 被划分为了 RKNPU,而 RKNPU3.0、RKNPU4.0 和 RKNPU5.0 被划分为了 RKNPU2,RKNPU 和 RKNPU2 所使用的 SDK 和工具套件不同。
RK3568 和 RK3588 的 NPU 具有的功能如下:

RKNN三核架构如下图所示:

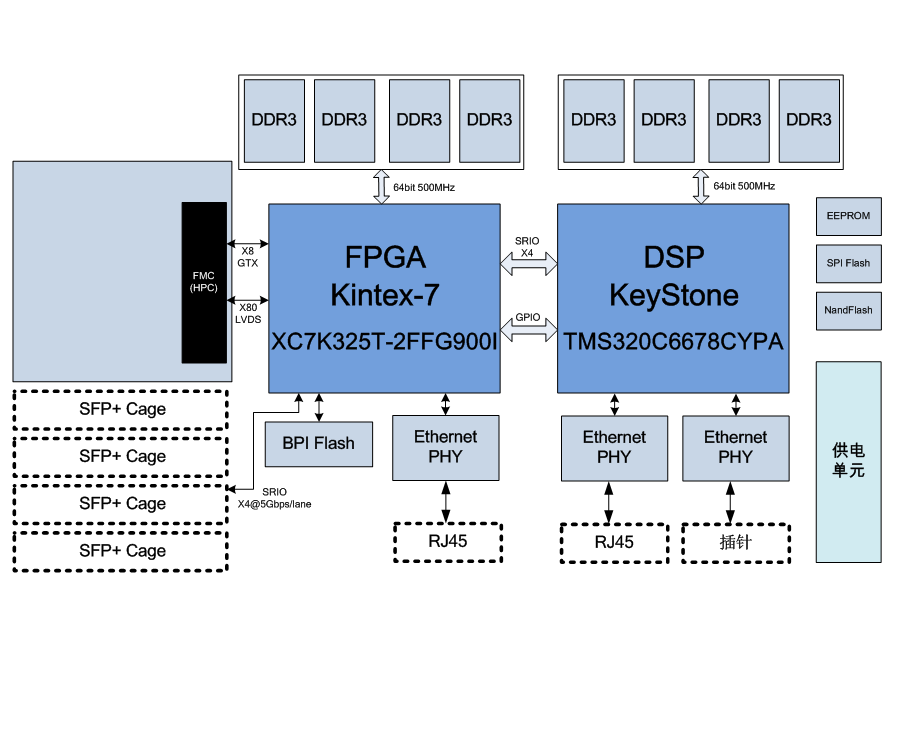
三、RKNPU单核框架
RKNPU 单核心架构如下图所示:
3.1 AHB/AXI 接口
AXI 主接口【用来和内存进行连接,从中获取模型、图像的相关参数和数据】(AXI Master Interface)用于从连接到 SoC AXI 互联的内存中获取数据。AXI 是 一种高性能、低延迟、可扩展的总线接口,常用于连接处理器和外设,并支持多个主设备和从 设备。AXI 主接口通常用于从内存中获取数据,例如从 DRAM 或其他存储器中读取程序和数据, 并将其传输到处理器或其他外设中进行处理和计算。
AHB 从接口【用于访问寄存器,从而对RKNPU进行配置、调试和测试】(AHB Slave Interface)用于访问寄存器进行配置、调试和测试。AHB 是一种标 准化的系统总线接口,通常用于连接处理器、内存和外设等硬件电路。AHB 从接口通常用于访问寄存器,例如控制和配置处理器、外设和其他硬件电路的参数和状态,以实现系统的配置、 调试和测试。
在 SoC 系统中,AXI 主接口和 AHB 从接口通常被用于连接处理器、内存、外设和其他硬件电路,以实现数据传输、控制和配置等功能。AXI 接口通常用于高速数据传输和处理,而 AHB 接口通常用于配置、调试和测试等低速控制操作。
3.2 卷积神经网络加速单元(CNA)
卷积神经网络加速单元(Convolutional Neural Network Accelerator,CNA)是 RKNPU 中重要的组成部分之一。包括卷积预处理控制器、NPU 内部缓存区、序列控制器、乘加运算单元和累 加器,下面对各个部分进行介绍:
(1)卷积预处理控制器
卷积预处理控制器是 CNA 中用于预处理卷积计算的硬件单元,可以对输入的模型权重进行 解压缩之后加载进 NPU 的内部缓冲区,并且可以判断零节点加速运算速度,最后将要推理的数据加载进 NPU 的内部缓冲区中。
(2)NPU 内部缓存区(Internal Buffer)
NPU 内部缓存区是 CNA 中用于存储中间计算结果的缓存区。它可以高效地存储和管理卷积 神经网络中的各种数据,包括输入数据、卷积核、卷积结果等。NPU 内部缓存区采用了多级缓 存和数据重用技术,可以高效地利用计算资源和存储资源,从而进一步提高计算速度和效率。
(3)序列控制器(Sequence Controller)
序列控制器是 CNA 中用于控制卷积计算序列的硬件单元。它可以根据卷积神经网络的结构和参数,自动地配置和控制 CNA 中各个硬件单元的工作模式和参数。序列控制器还可以实现卷积计算的并行化和流水化,从而提高计算速度和效率。
(4)乘加运算单元(Multiply-Accumulate Unit,MAC)
乘加运算单元是 CNA 中用于执行卷积计算的硬件单元。它可以对输入数据和卷积核进行乘 法和累加运算,从而得到卷积计算结果。乘加运算单元采用了高度并行的设计,可以同时执行多个卷积计算操作,从而大大提高计算速度和效率。
(5)累加器(Accumulator)
累加器是 CNA 中用于累加卷积计算结果的硬件单元。它可以高效地累加卷积计算结果,从 而得到最终的输出结果。累加器可以采用多种精度,可以适应不同的计算精度要求。
3.3 数据处理单元(Data Processing Unit,DPU)
数据处理单元(Data Processing Unit)主要处理单个数据的计算,例如 Leaky ReLU、ReLU、 ReluX、Sigmoid、Tanh 等。它还提供了一些功能,例如 Softmax、转置、数据格式转换等。
数据处理单元是一种硬件电路,用于加速神经网络的计算过程。它通常被用于处理前向计 算过程中的单个数据,例如卷积层和全连接层中的激活函数计算。不同的激活函数需要不同的 计算操作,例如 ReLU 需要计算 max(0,x),Sigmoid 需要计算 1/(1+exp(-x)),而数据处理单元可 以通过硬件电路来实现这些计算操作,从而提高神经网络的计算性能和效率。
除了激活函数计算之外,数据处理单元还提供了一些其他的函数,例如 Softmax、转置、 数据格式转换等。这些函数通常被用于神经网络模型的构建和优化过程中,例如将模型的输出 转换为概率分布、重新排列张量的维度、将数据从一种格式转换为另一种格式等。
3.4 平面处理单元(Planar Processing Unit,PPU)
平面处理单元(Planar Processing Unit)主要提供对数据处理单元的输出数据进行平面操作的功能,例如平均池化、最大值池化、最小值池化等。
平面处理单元是一种硬件电路,用于加速神经网络的计算过程。它通常被用于对数据处理 单元的输出数据进行平面操作,例如在卷积神经网络中,对卷积层的输出进行池化操作,以降 低数据维度和减少计算量。平面处理单元可以通过硬件电路来实现这些操作,从而提高神经网 络的计算性能和效率。
平面处理单元支持多种平面操作,例如平均池化、最大值池化、最小值池化等。这些操作 可以通过不同的参数来控制池化窗口的大小和步幅等,从而适应不同的应用场景和要求。
四、 NPU性能计算
NPU(Neural Processing Unit)是专门用于神经网络计算的处理器,其算力是指每秒可以处 理的运算次数,通常以 TOPS(Tera Operations Per Second)为单位进行衡量。
每个周期的理论峰值性能为 Perf=MACs*2(ops/cycle)。其中 MACs 表示每个周期内可以达到的乘加操作次数,在前面 RKNPU 介绍 章节已经对单个周期的每个数据类型可以进行的乘加操作次数进行了列举,而算力指的是运算的次数,所以要将乘加操作分解为一次乘法和一次加 法,也就是最后乘以 2 的由来。当 NPU 的频率为 f 时,则每秒的理论峰值性能为 Perf=MACs*2*f(ops/s)。
以 RK3588 int 8 数据类型为例进行性能计算演示:
(1)RK3588 每个周期可进行 1024x3 个 int8 MAC 操作
(2)RK3588 的 NPU 算力为 1G HZ
(3)理论峰值性能计算公式为 Perf=MACs*2*f(ops/s)
综上 RK3588 int 8 理论峰值性能为 Perf=1024x3x1G×2 = 6 TOPS。其他类型以及 RK3568 的算 力计算同理。
6TOPS即每秒处理6万亿次操作!!!
五、RKNPU 应用领域 RKNPU
(Rockchip NPU)是一种专门用于深度学习应用的高性能处理器,并且在多个应用场景中都有广泛的应用。以下是一些常见的 RKNPU 应用场景:
(1)计算机视觉
计算机视觉是 RKNPU 最常见的应用场景之一。其主要应用包括:
1)图像分类:将图像分成不同的类别。例如,将一张图片分成猫、狗、马等不同的类别。
2)目标检测:检测图像中不同物体的位置和类别。例如,检测图像中的人、汽车、建筑 等。
3)图像分割:将图像中的不同物体分割出来。例如,将一张街景图片分割成不同的车辆、 建筑、行人等。
4)人脸识别:识别图像中的人脸并将其与已知的人脸进行匹配。
5)行为识别:识别视频中的不同行为,例如人的走路、跑步、跳舞等。
(2)语音识别
语音识别是另一个常见的 RKNPU 应用场景。其主要应用包括:
1)语音识别:将语音信号转换成文字。
2)语音合成:根据文字生成语音信号。
3)说话人识别:识别语音信号的说话人身份。
(3)自然语言处理
RKNPU 也可以用于自然语言处理。其主要应用包括:
1)情感分析:判断一段文本表达的情感是正面、负面还是中性。
2)文本分类:将文本分成不同的类别。例如,将一封电子邮件分为垃圾邮件和非垃圾邮 件。
3)文本生成:根据给定的文本生成新的文本,例如自动写作、机器翻译等。
4)机器翻译:将一种语言的文本翻译成另一种语言的文本。
(4)医疗保健
在医疗保健领域,可以用于:
1)疾病预测:利用患者的病历和生理数据等信息预测患者的疾病风险和病情发展。
2)医学影像分析:对医学影像数据进行分析和识别,例如 CT、MRI 等。
3)药物发现:利用深度学习模型预测分子与靶点之间的相互作用,从而加速药物研发。
4)基因组学:利用深度学习模型对基因序列进行分析和预测,例如基因突变、基因表达 等。
(5)金融服务
在金融服务领域,可以用于:
1)风险评估:利用深度学习模型对客户信用、还款能力等进行评估。
2)欺诈检测:利用深度学习模型检测信用卡欺诈、账户盗用等非法行为。
3)股票预测:利用深度学习模型预测股票价格和趋势。
4)投资组合优化:利用深度学习模型对投资组合进行优化,降低风险并提高收益。
该笔记仅用来自学!!!